

这篇 AI 论文探索了利用和优化工业应用多模态 RAG 系统的新方法
作者:Nikhil
多模态检索增强生成(RAG)技术为人工智能(AI)在制造、工程和维护行业的应用开辟了新的可能性。这些领域严重依赖于结合复杂文本和图像的文档,包括手册、技术图表和原理图。能够解释文本和视觉效果的人工智能系统有潜力支持复杂的、特定于行业的任务,但此类任务提出了独特的挑战。在视觉效果对于理解复杂指令或配置至关重要的环境中,有效的多模式数据集成可以提高任务的准确性和效率。
人工智能系统使用文档中基于文本和图像的信息提供准确、相关答案的能力是工业环境中的一个独特挑战。传统的大语言模型 (LLM) 通常需要更多特定领域的知识,并且在处理多模式输入时面临限制,导致生成的响应容易出现“幻觉”或不准确。例如,在需要文本和图像的问答任务中,纯文本 RAG 模型可能无法解释技术领域常见的关键视觉元素,例如设备原理图或操作布局。这凸显了对一种解决方案的需求,该解决方案不仅可以检索文本数据,还可以有效地集成图像数据,以提高人工智能驱动的见解的相关性和准确性。
当前的检索和生成技术通常单独关注文本或图像,导致在处理需要两种类型输入的文档时出现空白。一些纯文本模型试图通过访问大型数据集来提高相关性,而纯图像方法则依赖于光学字符识别或直接嵌入等技术来解释视觉效果。然而,这些方法在支持文本和图像的集成至关重要的工业用例方面受到限制。可以检索和处理多种输入类型的多模式系统已经成为弥合这些差距的重要进步。尽管如此,仍需要探索针对工业环境优化此类系统。

慕尼黑大学的研究人员与西门子合作开发了一种多模式 RAG 系统,专门用于解决工业环境中的这些挑战。他们提出的解决方案结合了两个多模态 LLM(GPT-4 Vision 和 LLaVA),并使用两种不同的策略来处理图像数据:多模态嵌入和基于图像的文本摘要。这些策略使系统不仅可以根据文本查询检索相关图像,还可以利用这两种模式提供更准确的上下文响应。多模态嵌入方法利用 CLIP 在共享向量空间中对齐文本和图像数据,而图像摘要方法将视觉效果转换为与其他文本数据一起存储的描述性文本,确保两种类型的信息均可用于合成。
多模式 RAG 系统采用这些策略来最大限度地提高检索和解释数据的准确性。在纯文本 RAG 设置中,工业文档中的文本使用基于矢量的模型嵌入,并与最相关的部分匹配以生成响应。对于纯图像 RAG,研究人员使用 CLIP 将图像嵌入到文本问题旁边,从而可以计算跨模式相似性并找到最相关的图像。同时,组合的 RAG 方法利用了这两种模式,创建了一个更加集成的检索过程。图像摘要技术将图像处理成简洁的文本摘要,方便检索,同时保留原始视觉效果以进行答案合成。每种方法都经过精心设计,旨在优化 RAG 系统的性能,确保法学硕士可以提供文本和图像以生成全面的答复。
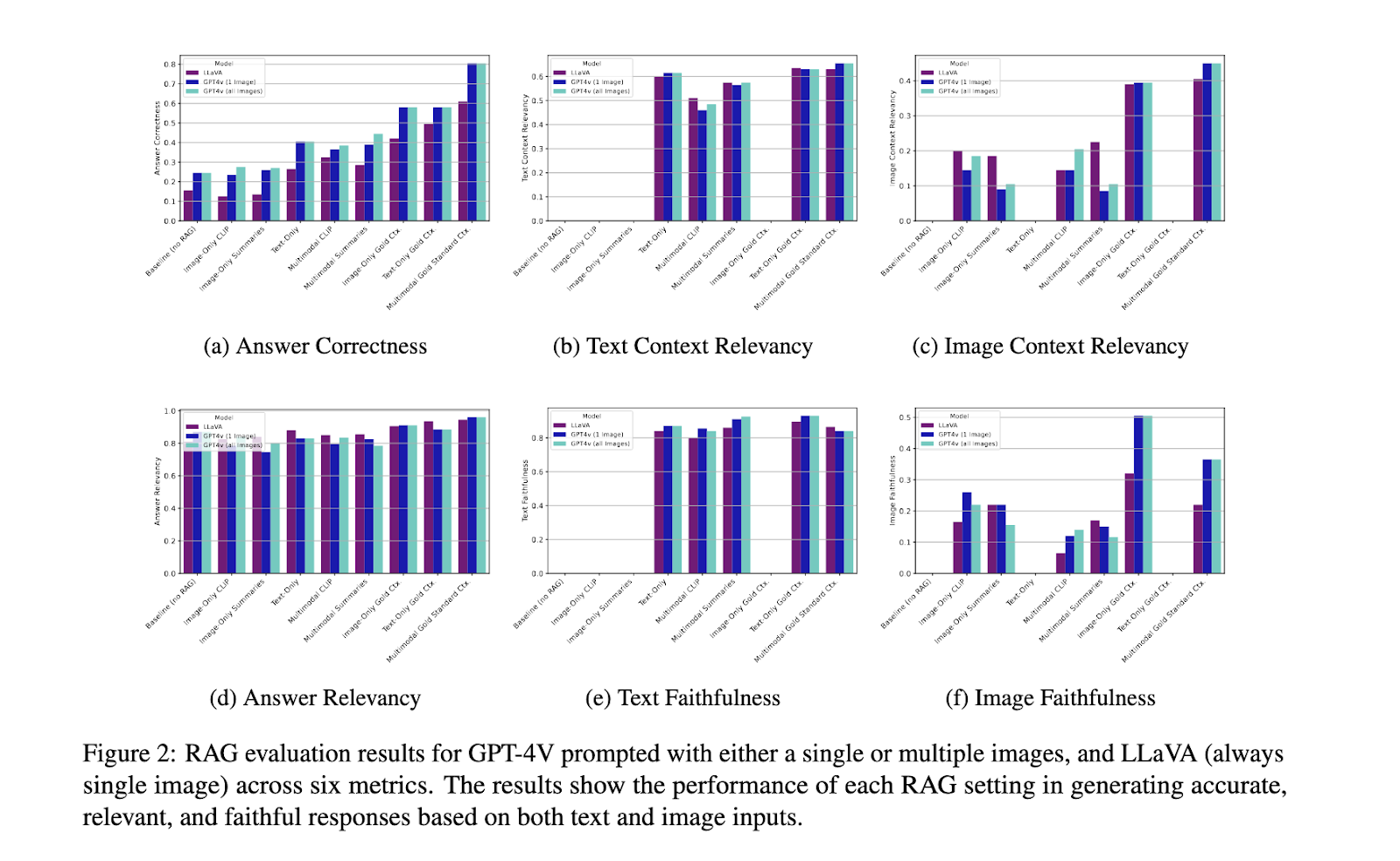
所提出的多模式 RAG 系统的性能得到了显着改进,特别是在处理复杂工业查询的能力方面。结果表明,多模态方法比纯文本或纯图像 RAG 设置显着提高了准确性,并且组合方法显示出明显的优势。例如,与仅文本的准确率相比,当检索过程中将图像与文本一起包含时,准确率提高了近 80%。此外,图像摘要方法被证明特别有效,在上下文相关性方面超越了多模态嵌入技术。该系统的性能通过六个关键评估指标进行衡量:答案准确性和上下文一致性。结果表明,图像摘要为细化检索和生成组件提供了增强的灵活性和潜力。此外,该系统还面临图像检索质量的挑战,需要进一步改进以实现完全优化的多模态 RAG。
研究团队的工作表明,工业应用中多模态 RAG 的集成可以显着提高需要视觉和文本解释领域的人工智能性能。通过解决纯文本系统的局限性并引入创新的图像处理方法,研究人员提供了一个框架,该框架支持对复杂的多模式查询提供更准确、更适合上下文的答案。结果强调了多模态 RAG 作为人工智能驱动的工业应用中关键工具的潜力,特别是随着图像检索和处理的不断进步。这种潜力为该领域的未来开辟了令人兴奋的可能性,激发了该领域的进一步研究和开发。
查看 纸。。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。如果您喜欢我们的工作,您就会喜欢我们的新闻通讯..不要忘记加入我们的 55k+ ML SubReddit。
[流行趋势]LLMWare 推出 Model Depot:适用于英特尔 PC 的小语言模型 (SLM) 的广泛集合

Nikhil 是 Marktechpost 的实习顾问。他正在印度理工学院卡拉格普尔分校攻读材料综合双学位。Nikhil 是一位 AI/ML 爱好者,一直在研究生物材料和生物医学等领域的应用。凭借深厚的材料科学背景,他正在探索新的进步并创造贡献的机会。