
使用电子病历的自然语言处理进行抗癌药物的上市后监测
作者:Aramaki, Eiji
介绍
上市后监测(PMS)是一种用于监测药品上市后安全性的方法。需要长期的 PMS 来识别上市前未识别的不良事件 (AE),并在上市后持续监测药物安全性。然而,PMS主要依赖于医疗专业人员和患者的报告;因此,上市后 AE 被认为报告不足1,2,3,4。2008年,食品药品监督管理局响应《食品药品监督管理局修正案》,启动了“哨兵计划”,建立了国家电子系统,主动监测药品安全5。该项目的目的是建立一个分布式数据库网络,以每个医院设施的电子病历(EMR)和管理数据为信息源,通过数据库搜索快速识别不良事件。同样,在日本,2018 年修订的良好上市后研究实践批准了使用基于 EMR 的数据库作为信息源的 PMS。医疗信息数据库网络(MID-NET)6为此开发的“Sentinel Initiative”是一个类似于 Sentinel Initiative 的分布式数据库网络,截至 2024 年 4 月,其信息来源是来自日本 33 家医院的 EMR 和管理数据。
Sentinel Initiative 和 MID-NET 都定义了通用数据模型 (CDM),以将通用分析程序应用于不同设施的数据库7,8。尽管两种情况下的 CDM 不同,但主要信息类型包括患者人口统计信息(例如出生日期、性别、种族)、处方信息(住院患者、门诊患者)、诊断代码(ICD-9、ICD-10、SNOMED-CT)、体检信息、入院和出院信息、标本检测结果。AE 结果主要由诊断代码和样本测试结果(例如血液和尿液)的组合来定义。然而,诊断代码主要用于保险理赔而非临床诊断;因此,AE覆盖率较低9,10。此外,提示 AE 的患者体征和症状以及医生的发现通常以自由文本形式记录;因此,通过组合这些结构化数据可以表达的AE类型是有限的。尽管如此,EMR 文本包含大量有关 AE 的信息,是主动 PMS 的重要信息来源。因此,从电子病历中挖掘数据的自然语言处理 (NLP) 技术变得越来越重要11,12,13,14,15,16。
从 EMR 文本中准确提取 AE 需要识别与 AE 相关的症状和发现,确定患者是否发生 AE,并对提取的变量表达式进行标准化。在 NLP 领域,这些过程分别被指定为命名实体识别(NER)、事实分析(FA)和实体规范化(EN)任务。通过使用 Transformers 的双向编码器表示 (BERT),这些 NLP 任务的性能得到了显着提高17 号,于 2017 年发布,包含变形金刚18。各种BERT模型19 号,20,21在这一成功之后出现了针对医学文本进行预训练的模型,并提高了从医学文本中提取 AE 的性能22 号,23,24,25,26,27,预计将带来更多的实际应用。然而,在 PMS 中利用提取的 AE 不仅需要汇总 AE 或查找文本中提及前后药物的关联,还需要排除患者疾病和文本外记录的其他处方药物的影响。之前关于使用 NLP 提取 AE 的研究主要集中在提取暗示 AE 的表达式的准确性上。然而,目前尚不清楚 NLP 提取的 AE 是否对 PMS 有用。
因此,我们的目标是利用纵向 EMR 数据,并使用 NLP 结合其他结构化数据,对从 EMR 中包含的临床文本中提取的 AE 进行统计分析,以开发将 AE 检测为信号的框架。在本研究中,我们使用该框架回顾性评估了三种常用抗癌药物类别(铂类化合物、紫杉烷类和嘧啶类似物)与四种 AE 组(周围神经病变,PN;口腔粘膜炎,OM;味觉异常,TA;不良事件,TA)之间的关联。众所周知,食欲减退(AL)与这些抗癌药物有关。这些 AE 组缺乏既定的支持,在临床上很重要,并且在评估其发生时很难通过血液检测结果或疾病名称来确定。此外,临床文本是这些不良事件的重要信息来源。我们对癌症患者总共进行了 12 项分析,以表明使用临床文本检测到的 AE 反映了已知的 AE 发生频率,并讨论了临床文本在 PMS 中的有用性和局限性。此外,为了证明具体的适用性,我们旨在检查两种不同情况下与两类抗癌药物相关的 AE 的差异风险。
结果
收集到的数据摘要
桌子1显示所收集数据的细分。总共对 44,502 名独特患者(男性:59.6%,女性:40.4%)进行了评估。诊断程序组合 (DPC) 数据以及处方和注射订单的总数分别为 175,624、3,911,157 和 11,259,143,每个患者的值分别为 3.9、87.9 和 253.0。进展记录、护理记录和出院小结的总数分别为 4,856,533、3,607,590 和 122,231,每名患者的值分别为 109.1、81.0 和 2.7。所有患者的中位随访期为 1874 天。
患者特征
桌子2显示 DPC 数据的描述性统计(氮–= –175,624)。大多数患者年龄≤65岁(104,423例,59.5%),为男性(102,717例,58.5%),初次发生癌症(63,118例,63.1%),吸烟指数<400(101,942 例,80.0%)。在日常生活活动(ADL)方面,大多数患者能够独立进餐(140,062例,98.3%)、行走(134,999例,94.9%)和排便(138,836例,97.6%)。最常见的癌症部位是消化器官(62,266例,40.8%);不明确、次要和未指定的部位(16,165 例,10.6%);女性生殖器官(15,854例,10.4%);其他站点(<10% 的案例)。最常见的合并症是消化系统疾病(28,744例,21.5%),其次是循环系统疾病(27,954例,20.9%)和内分泌、营养和代谢疾病(24,680例,18.4%),其他合并症(<10)案例的百分比)。
不良事件的风险比
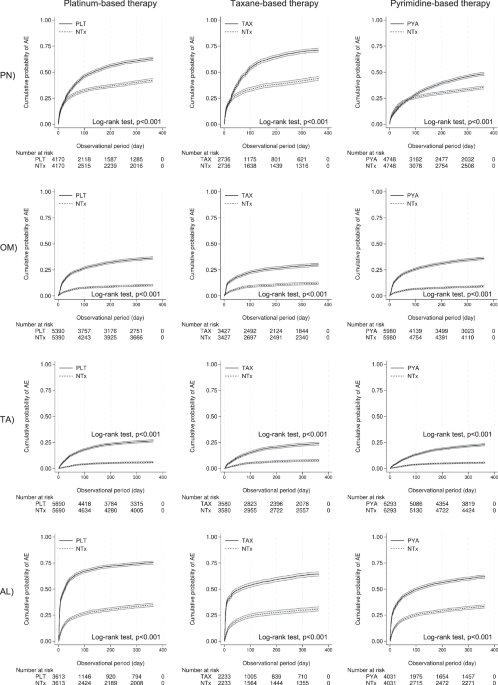
对于倾向得分匹配 (PSM),所有分析中 33 个变量的平均绝对标准化差 (ASD) 为 1.7%(最大 2.1%),表明匹配结果良好。此外,多变量逻辑回归的平均曲线下面积为 0.81(最小值 0.77,最大值 0.86)。桌子3显示每个分析的风险比 (HR) 和置信区间 (CI) 的摘要。如图。1显示 PSM 后的累积发生率曲线和对数秩检验结果。铂类治疗 (PLT) 和非治疗 (NTx) 组之间的比较显示 HR 显着较高,按降序排列:TA (HR, 4.71 [95% CI: 4.14, 5.35])、OM (HR, 3.85 [95% CI: 3.47, 4.26])、AL (HR, 3.34 [95% CI: 3.11, 3.59]) 和 PN (HR, 1.63 [95% CI: 1.53, 1.74])。紫杉烷类治疗 (TAX) 和 NTx 组之间的比较显示 HR 显着较高,按降序排列:AL(HR,3.84 [95% CI:3.50,4.22])、TA(HR,3.67 [95% CI:3.18]),4.24])、OM(HR,3.11 [95% CI:2.75,3.50])和 PN(HR,1.95 [95% CI:1.80,2.10])。基于嘧啶的治疗 (PYA) 和 NTx 组之间的比较显示,HR 显着较高,按降序排列:OM(HR,3.70 [95% CI:3.33,4.11])、TA(HR,3.48 [95% CI:3.05]),3.97])、AL(HR,1.98 [95% CI:1.84,2.13])和 PN(HR,1.15 [95% CI:1.07,1.24])。补充表1—24显示每次分析的 Cox 比例风险 (Cox PH) 模型分析的基线特征和详细结果。表3 三类抗癌药物不良事件风险比汇总
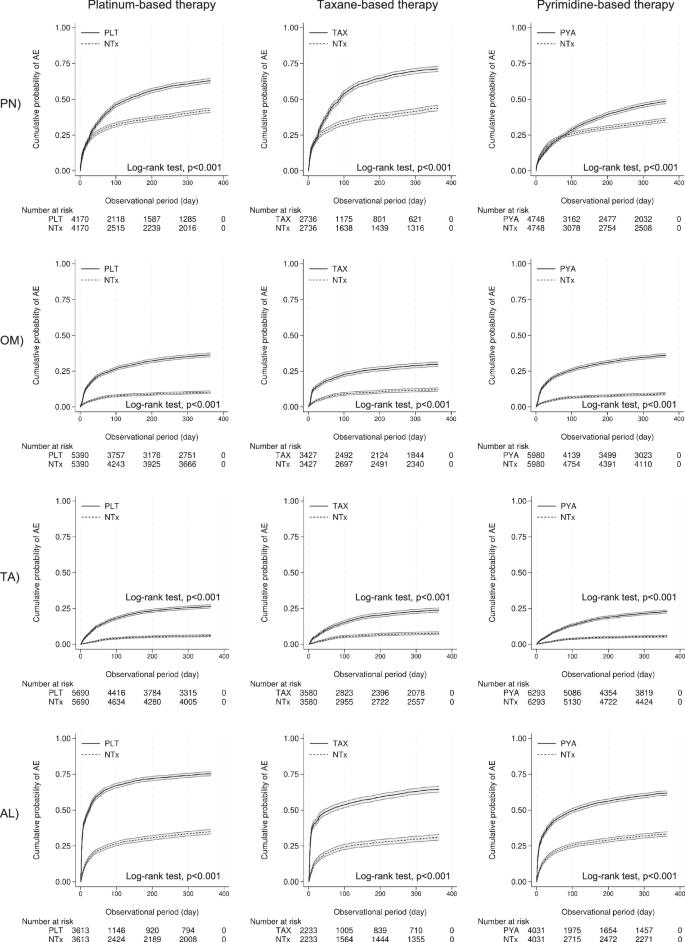
基础治疗(PYA)与各自的非治疗(NTx)组进行比较。每个面板显示特定不良事件的累积发生率,x- 轴表示以天为单位的观察期,y 轴表示累积发生率。每个图表下方提供了不同时间点处于危险中的患者人数。
以下抗癌药物类别未纳入 Cox PH 模型分析,因为与分析的抗癌药物的相关系数 > 0.3: TAX 和 PYA 未纳入 PLT 组中所有 AE 的分析,PLT 和 PYA 未纳入TAX 组所有 AE 分析中均未纳入 PLT,PYA 组所有 AE 分析中均未纳入 PLT。
抗癌药物AE比较
补充表25—26显示每个场景的基线特征。我们在两种情况下都从 PSM 中排除了三个 ADL 变量,因为两组中几乎所有病例的得分均为 1(表明不需要帮助)。在场景 1 中,八个变量(消化器官、不明确的次要和未指定位点、嘧啶类似物、紫杉烷和 Top I、HER2、EGFR 和 VEGF/VEGFR 抑制剂)的 ASD >10%。在情景 2 中,九个变量(消化器官、呼吸和胸内器官、乳房、女性生殖器官、不明确的次要和未指定部位、氮芥和嘧啶类似物、蒽环类药物和相关物质以及铂化合物)的 ASD >10%。因此,我们在后续分析中利用多元Cox PH模型分析对这些变量进行了调整。
桌子4总结了两种情况下的 HR。场景 1:与顺铂相比,奥沙利铂 PN 的 HR 为 3.28 [95% CI:2.79, 3.85](p–< –0.001)。场景 2:与紫杉醇相比,使用多西紫杉醇的 OM 的 HR 为 2.34 [95% CI:1.91, 2.88](p–< –0.001)。如图。2显示累积发生率曲线和基于天数和处方数量的双对数转换累积发生率曲线。使用对数秩检验进行的所有比较均观察到显着差异。累积发生率曲线(图 2)2a、b)和基于处方数量的累积发病率曲线(图 2)。2c、d)在所有比较中都显示出相似的趋势。从初始给药日起,奥沙利铂的 PN 风险高于顺铂(e)到第 12 天(e02.5)在基于天数的双对数转换累积发病率曲线中,之后两组之间的 HR 保持恒定(图 2)。2e)。在多西紫杉醇和紫杉醇的比较中,OM的HR在第一次给药后最初是恒定的;然而,多西紫杉醇的 HR 从第 4 天开始增加(e1.4)到第 10 天(e2.3),之后又变得恒定(图 2)。2f)。基于处方数量的双对数转换发生率曲线(图 1)2克,小时)在两次比较中都保持了比例风险,表明观察到的 AE 与抗癌药物处方数量成比例。补充表27—28提供每个场景的 Cox PH 模型分析的全面概述。
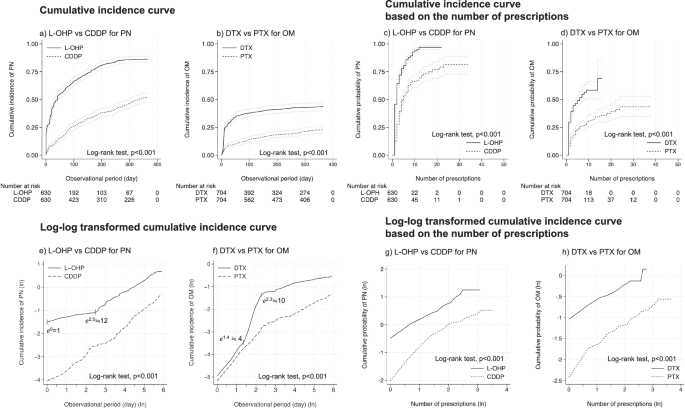
左上:基于天数的累积发病率曲线。一个奥沙利铂与顺铂治疗周围神经病变的比较。乙多西紫杉醇和紫杉醇治疗口腔粘膜炎的比较。右上:基于处方数量的累积发病率曲线。c奥沙利铂与顺铂治疗周围神经病变的比较。d多西紫杉醇和紫杉醇治疗口腔粘膜炎的比较。左下:基于天数的双对数转换累积发病率曲线。e奥沙利铂与顺铂治疗周围神经病变的比较。f多西紫杉醇和紫杉醇治疗口腔粘膜炎的比较。右下角:克奥沙利铂与顺铂治疗周围神经病变的比较。小时多西紫杉醇和紫杉醇治疗口腔粘膜炎的比较。在双对数变换的累积发生率曲线中,横轴表示天数或处方数的自然对数,而纵轴表示不良事件的累积发生率的自然对数。对于水平轴,e1大约对应于2.7e2至 7.4,以及e3至 20.1。敏感性分析对于第一次敏感性分析,表5
显示 NLP 性能评估的结果。
召回值为 0.74、0.73、0.46 和 0.62;精度值为 0.92、0.94、0.95 和 0.97;所有特异性均为 1.00;PN、OM、TA 和 AL 的 F 值分别为 0.82、0.82、0.62 和 0.75。桌子6展示 NLP 误差分析的结果。关于误报 (FP),观察到五种类型的错误,归因于 NER 和 FA 任务。“将缺席判定为存在”是指否定的 AE 被确认的情况,PN 为 12 段,OM 为 11 段,TA 为 3 段,AL 为 10 段。“既往症状”表示确认 AE 作为病史,出现在 PN 的 3 个段落中、OM 的 1 个段落、TA 的 0 个段落和 AL 的 6 个段落中。“未来可能性”表示对未来潜在 AE 的肯定,在 PN 的四个段落、OM 的两个段落、TA 的三个段落和 AL 的五个段落中找到。“即将进行的观测”是指对未来观测计划的确认,PN 出现 10 个段落,OM 出现 0 个段落,TA 出现 1 个段落,AL 出现 2 个段落。“确定改善为存在”表示对不良事件改善的确认,在 PN 的四段、OM 的三段、TA 的一段和 AL 的一段中发现。“归一化错误”,其中 NER 和 FA 成功,但 EN 错误导致对不同不良事件的归一化,在 PN 的 8 个段落、OM 的 4 个段落以及 TA 和 AL 的 0 个段落中观察到。在 PN 的 7 个段落中发现了“明显不同的原因”,其中的影响明显是由手术或放疗引起的,在 OM 中发现了 1 个段落,在 TA 和 AL 中都发现了 0 个段落。“明显不同的症状”在 PN 中提取了 11 个段落,在 OM 中提取了 2 个段落,在 TA 和 AL 中提取了 0 个段落。关于假阴性(FN),由于 NER 任务错误而未提取 AE 的段落数量,PN 为 124 个,OM 为 46 个,TA 为 122 个,AL 为 427 个。此外,包含相关不良事件但由于实体粒度较大等原因而未标准化为任何不良事件的提取实体的段落数量为:PN 102 个、OM 96 个、TA 63 个、AL 35 个。
7显示 NLP 错误对结果的影响。在每种 AE 的 200 例病例中,未受结果变化影响的病例数(类型:1)为 PN 163 例(81.5%)、OM 191 例(95.5%)、AT 176 例(88.0%)、AT 152 例(76.0%)。)对于 AL。由于 FN 导致事件发生日期缩短的病例(类型:2A)中,PN 16 例(8.0%),OM 3 例(1.5%),AT 10 例(5.0%),AL 27 例(13.5%)。同样,由于 FN(类型:2B)而从不发生组变为发生组的病例为 PN 6 例(3.0%)、OM 1 例(0.5%)、AT 10 例(5.0%)、AT 19 例(9.5%)。)对于 AL。FP 导致事件发生日期延长的病例(类型:3A)为 PN 8 例(4.0%)、OM 3 例(1.5%)、AT 1 例(0.5%)和 AL 1 例(0.5%)。因 FP 而从发生组变为未发生组的病例(类型:3B)为 PN 7 例(3.5%)、OM 2 例(1.0%)、AT 3 例(1.5%)、AT 1 例(0.5%)AL。根据手动提取的 AE 确定的结果,PN、OM、TA 和 AL 的 HR 为 1.33 [0.82, 2.15](p≤=≤0.25), 4.14 [1.75, 8.81] (p≤<0.01), 13.54 [3.73, 49.19] (p≤<0.001), 2.91 [1.91, 4.44] (p分别≤<≤0.001)。由于 NLP FN,主要分析中提出的 TA HR 被低估。尽管 PN 显示出与主要分析相似的趋势,但由于病例数减少,显着性消失。其他 AE 显示的结果与主要分析相同。
至于第二次敏感性分析,在总共12次分析中,PLT、TAX和PYA组的平均体检天数为64.6天,NTx组为31.6天,这种差异是显着的(p–< –0.001)。桌子8显示了假设在 NTx 组中 AE 非事件病例中观察到 AE 时的 HR,对应于同一 NTx 组中 AE 事件病例的 10-50%。即使病例数量增加相当于 AE 事件病例的 50%,除 PN 外,HR 也观察到显着差异。
至于第三个敏感性分析,附表29和30分别提供 30 天和 180 天观察期的 HR 总结。在 30 天的观察期内,PLT、TAX 和 PYA 引起的 PN 的 HR 为 1.18 [95% CI:1.07,1.30](p≤<≤0.05), 1.26 [95% CI: 1.13, 1.41] (p≤<≤0.001) 和 0.80 [95% CI: 0.72, 0.89] (p分别≤<≤0.001)。与主要分析结果相比,这些值往往较低,PYA 显示 HR 显着下降。对临床文本的目视检查显示,每个 NTx 组都包含手术病例,术后 30 天内的神经系统症状(例如甲状腺切除术后手足抽搐症状或骨科手术后下肢神经系统症状)被提取为 PN,可能导致 HR 估计值较低对于每个抗癌药物组。PLT 引起的 TA 和 AL 的 HR 为 6.38 [95% CIL 4.99, 8.16](p≤<≤0.001) 和 4.08 [95% CI: 3.71, 4.50] (p≤<≤0.001),与主要分析结果相比,两者均表现出较高的趋势。同样,TAX 引起的 TA 和 AL 的 HR 为 4.49 [95% CI:3.40,5.92](p≤<≤0.001) 和 4.80 [95% CI: 4.23, 5.45] (p≤<≤0.001),与主要分析结果相比也分别表现出较高的趋势。这些结果被认为是合理的,因为在初次服用抗癌药物后 30 天内,很可能会高频率地观察到 TA 和 AL。其他结果与主要分析基本相同。180天观察期的HR与主要分析结果基本相当,但PYA引起的PN的HR除外,没有显着差异。
讨论
本研究的目的是证明从文本中提取的 AE 反映了使用 EMR 已知的 AE 发生频率。尽管一些研究已经使用 NLP 从医学文本中提取 AE22 号,23,24,25,26,27据作者所知,没有研究将提取的 AE 评估为事件发生时间结果。我们发现在本研究的所有 12 项分析中均显着检测到 AE,这表明 NLP 提取的 AE 可能对 PMS 有用。由于化疗采用多种抗癌药物的组合,因此估计特定抗癌药物引起的 AE 风险需要调整伴随抗癌药物以及导致延迟 AE 的抗癌药物的作用。然而,由于多重共线性,表现出一定相关性的抗癌药物并未纳入我们分析的解释变量中。因此,TAX和PYA对PLT的影响、PLT和PYA对TAX的影响以及PLT对PYA的影响均未调整。因此,本研究中的 HR 应被解释为 AE 信号,而不是定量指示风险的值。理想情况下,患者应无抗癌药物使用史并接受单一药物治疗;然而,常规临床数据中此类病例的数量有限,这影响了AE的检测能力。鉴于这些局限性,我们检查了获得的 AE HR 是否与现有研究的结果一致。
所有抗癌药物类别均与低至中度 PN 风险相关。已知 PLT(HR:1.63)会导致 PN,这与奥沙利铂治疗密切相关28。在一项调查晚期胃癌患者的随机对照试验 (RCT) 中,S-1 + 奥沙利铂 (SOX) 组报告的 PN 率为 59.0%,S-1 + 顺铂 (SP) 组为 34.8%29。然而,如果仅评估奥沙利铂,该值可能会更高。同样,已知 TAX(HR:1.95)会导致 PN30。一项针对非小细胞肺癌患者的 3 期随机对照试验报告紫杉醇诱发的 PN 发生率为 13%~62%,而另一项针对晚期胃癌患者的随机对照试验报告紫杉醇诱发的 PN 发生率为 57.4%31,32。因此,本研究的结果与这些发现是一致的。相反,PYA(HR:1.15)的 HR 较低,与此类药物相关的 PN 被认为是罕见事件33,34。然而,由于未对PLT的影响进行调整,我们得出结论,该结果与上述研究并不矛盾。
所有抗癌药物类别均与 OM 的高风险相关。引起 OM 的抗癌药物包括烷化剂、蒽环类药物、抗代谢药物(包括氟尿嘧啶 (5-FU))、紫杉烷类、抗肿瘤抗生素和长春花生物碱35。对于PLT(HR:3.85),在一项晚期胃癌患者的RCT中,SOX组和SP组中OM的发生率分别为17.9%和29.9%29。此外,一项系统评价显示,头颈癌患者因基于顺铂的化疗而导致 OM 的发生率为 22%,当同时进行放射治疗时,该发生率达到 89%36。尽管本研究包括头颈癌,但由于所用数据的限制,我们没有对放射治疗的影响进行调整。因此,这些结果可能表明比单独化疗的风险更高。关于TAX(HR:3.11),在一项转移性乳腺癌患者的RCT中,多西他赛组和紫杉醇组的OM发生率分别为51.4%和16.2%;此外,在一项针对转移性软组织肉瘤患者的随机对照试验中,接受多西他赛+吉西他滨治疗的患者中OM的发生率为49.0%。因此,多西紫杉醇被认为是比紫杉醇更可能引起 OM 的原因37,38。然而,在本研究中,多西紫杉醇和紫杉醇的风险并没有区分,并且PYA的作用也没有进行调整;因此,风险可能高于单独使用 TAX 的风险。此外,我们发现 PYA(HR:3.70)与相对较高的 OM 风险相关。先前的研究发现,接受 5-FU 治疗的患者中约有 40%–66% 出现 OM39。此外,据报道,S-1 与非氟嘧啶抗癌药物的 OM 比值比为 4.39 [95% CI:1.05, 18.37]40;本研究的结果与这些结果一致。
所有抗癌药物类别均与相对较高的 TA 风险相关。据报道,接受化疗的患者 TA 患病率高达 69.9%41。对于 PLT(HR:3.70),据报道接受基于顺铂化疗的癌症患者在味觉方面有更多主观变化42。然而,一些研究报告称,接受铂类化疗和非铂类化疗的患者的嗅觉和味觉功能没有显着差异43。这种差异可能是由于未接受任何抗癌药物的 NTx 组被用作比较对象,并且 PLT 分析没有针对 TAX 和 PYA 效应进行调整,从而与 PLT 相比风险增加独自的。然而,一项系统评价发现,接受化疗(包括多西他赛、紫杉醇、白蛋白结合型紫杉醇、卡培他滨或口服 5-FU 类似物)的患者中 TA 患病率在 17% 至 86% 之间44,支持 TAX (HR: 3.67) 和 PYA (HR: 3.48) 的当前研究结果。
所有抗癌药物类别均与 AL 风险从低到高相关。对于 PLT(HR:3.33)和 PYA(HR:1.98),在胆道癌患者的随机对照试验中,吉西他滨+顺铂(GC)组和吉西他滨+组的 AL 发生率相对较高,分别为 40.9% 和 39.5%S-1(GS)组,分别45。同样,在晚期胃癌患者的随机对照试验中,SOX 组和 SP 组的 AL 发生率分别为 50.9% 和 56.1%29。此外,对于TAX(HR:3.84),本研究结果显示AL风险中等,尽管晚期胃癌患者的随机对照试验报告紫杉醇组AL发生率为46.3%32,这与本研究的结果并不矛盾。
我们研究了两种情况下抗癌药物 AE 特征的差异。在第一种情况下,使用 HR,我们证明奥沙利铂比顺铂引起 PN 的频率更高。此外,使用对数转换累积发生率曲线,我们发现奥沙利铂在给药后立即对 PN 具有更高的风险(图 1)。2e)。这一结果与奥沙利铂诱导的急性 PN 的已知特征一致,后者通常发生在给药期间或给药后数小时内,并呈现短暂、可逆的症状46。在第二种情况下,我们证明多西紫杉醇比紫杉醇引起 OM 的频率更高,如 HR 所示。我们的结果还揭示了更详细的概况,表明多西紫杉醇在给药后第 4 天至第 10 天之间的风险增加(图 1)。2f)。虽然确切原因尚不清楚,但这种模式可能与 OM 的典型发作有关,发生在给药后数天至约 10 天内,多西他赛更强的骨髓抑制作用与此时期相符,可能导致 OM 发生频率增加。感染相关的 OM。基于处方数量的对数转换累积发生率曲线(图 2)2-克,小时)建议对两种情况均保持比例风险,确认 AE 的发生与处方数量成比例。基于时间和基于处方计数的分析之间比例风险的差异可能归因于本研究中缺乏治疗方案信息,这阻碍了抗癌药物给药间隔的调整。因此,在无法获得治疗方案信息的情况下,根据处方数量比较危险可能有助于更详细地了解毒性概况。总之,使用 NLP 从临床文本中提取的结果证明了结果与临床实践中随时间变化的毒性特征一致。因此,这种方法也可以应用于多种抗癌药物毒性特征的综合评估。
NLP 是从医学文本中提取可分析的结构化数据的重要技术。本研究中使用的Mednern内置的BERT已在日语Wikipedia上进行了预培训,但是用医学文本进行微调导致医学文本中的高性能NER。但是,超越NLP,使用机器学习模型与FPS和FNS相关联。对于首次灵敏度分析,我们在段落级别的PLT实验中手动评估了总共800例病例的文本。结果表明,四种AE类型的高平均精度为0.95。但是,平均召回率为0.64不足,尤其是TA的召回率相对较低,为0.46。召回率的减少归因于FNS,这是由于未能提取AE表达式的NER误差引起的,或者将误差错误地归一化提取的AE。值得注意的是,TA和AL显示了由NER错误引起的几个案例,其中许多情况下,患者主要的投诉表明无法提取AES。这可能部分是因为用于微调Mednern的数据集不包含具有这种口语患者表达的足够段落。此外,研究NLP错误对结果发生的影响和发生时间的影响表明,受FPS影响的病例(表7â3a,3b)有限,而案件受FNS的影响(表7â2a,2b)对于PN,TA和AL的范围从10%(PN)到23%(Al)。对PN,OM,TA和AL的HRS重新估计表明,TA的HR为13.54 [3.73,49.19](Pâ<0.001),这表明主要分析中提出的HR的HR是被低估并可能具有较高的实际人力资源。但是,其他AE的结果与主要分析相似,表明PN,OM和AL的主要分析结果具有一定的鲁棒性。这表明NLP错误不会直接影响结果错误识别,与Zhou等人的观点保持一致。47NLP误差对使用NLP衍生数据的流行病学研究中下游分析的影响是有限的。
最近的生成语言模型,例如生成预训练的变压器(GPT),就神经网络参数大小和训练数据量表而言,在本研究中使用的BERT模型显着超过了,这可能证明在不良事件提取中的性能较高。但是,GPT模型在这些任务中有一定的局限性。GPT模型旨在预测下一步的标记,使其本质上不适合NER等令牌分类任务。此外,GPT模型采用单向左右学习,这可能会限制上下文理解与Bert的双向编码器结构相比。实际上,一项研究表明,具有及时工程的GPT模型在医疗任务中表现不佳的BERT模型48。此外,EN任务需要了解标准化的术语设置。如果GPT模型未学习此术语集,则可能导致不正确的归一化或幻觉。因此,据报道,GPT模型不适合医学术语。49。此外,本研究中使用的AE词典是定制的,可能是GPT模型无法学到的,从而增加了这种风险。尽管有这些限制,但如果用于NER微调的数据集和本研究中用于EN任务的AE词典可能会微调为GPT模型,则可以预期NER和EN任务的高性能,因为其优越的基础模型表现。但是,医疗数据的安全要求通常排除使用基于云的GPT模型的使用,即使在可用的情况下,微型GPT模型也需要巨大的计算资源。因此,对于从医学文本中提取AE的特定任务,本研究中采用的BERT模型被认为是平衡计算效率和任务适用性的解决方案。相比之下,GPT模型与提示(包括少数示例的提示)的使用,可以预期与微调的BERT相当地执行,这可能会减少对注释的Corpora的需求。在这方面,GPT模型具有巨大的临床任务潜力,并且是预计将来进一步发展的解决方案。
关于第二次灵敏度分析,这项研究是使用EMR的回顾性观察性研究,导致PLT,税收和PYA治疗组与NTX组之间体检天的平均天数显着差异。这表明,PLT,税收和PYA组中的患者比NTX组的患者更频繁地访问医疗机构,这表明对深度随访需要更多的护理。同时,由于在EMR中观察并记录了AE的机会相对减少,因此NTX组的AE发生率风险可能被低估了。因此,在这种敏感性分析中,我们估计了HR,假设在NTX组的AE非生物病例中观察到AE在一定数量的情况下观察到了AE。因此,即使假设案件增加了相当于AE生成病例数量的50%,但观察到HR的显着差异,除了PN。因此,本研究的结果在信号检测应用中具有一定程度的鲁棒性。
关于第三个灵敏度分析,当观测周期设置为30天时,与主要分析相比,结果趋于较低,尤其是PYA观察到的HR显着下降。但是,当观察期设置为180天时,由PY引起的PN的HR不再显示出显着差异。对临床文本的检查表明,NTX组手术后30天内的神经系统症状被提取为PN。原因之一是,由于可用数据的限制,我们无法针对手术或放射治疗的影响进行调整。因此,不能明确指出,所鉴定的AE完全归因于抗癌药物的使用。因此,当解释估计的HRS时,应注意,两组之间的手术和放疗的影响没有调整,这是本研究的局限性之一。另一个原因是本研究中应用的NLP的NER和FA任务无法区分被识别的AE的原因。因此,由手术,放疗或其他疾病引起的AE也被视为结果。这是因为医学文本中患者症状的直接原因可以在远处,远处或根本不存在的情况下描述。因此,NLP技术的开发能够处理长篇小说输入并提取在这种情况下引起AE的事件仍然是一个挑战。但是,可以通过使用这种NLP技术提取AE来估算抗癌药物的更准确的HR,并进一步调整手术和放射疗法的影响。
用于AE信号检测的资源包括医疗设施和公司的自发报告系统(SRS),例如FDA不良事件报告系统。报告的优势比(ROR)用于使用SRS进行信号检测,这是根据存在或不存在药物使用以及特定AE报告的存在或不存在95%置信区间计算出的几率。SRS用于各种AE信号检测中,因为它包括更大规模和更广泛的AE范围的报告。但是,SRS报告并不意味着药物与AE之间的因果关系,并且由于偏见(例如报告不足和缺乏可能用作发病率的分母)而引起的解释受到限制。50。此外,ROR不能考虑协变量的影响。由于患者背景而导致的检测错误的可能性仍然存在。同时,使用分布式EMR衍生的数据库(例如Sentinel intiative和Mid-NET)具有相对较大且详细的患者背景信息,但要求通过诊断代码和试样测试结果的组合来定义AES。尽管如此,与临床实践中不是主要诊断的症状或发现相对应的AE可能不会注册为ICD-10代码;因此,无法分析这样的AE。此外,与这两种方法相比,本研究中使用的单个机构的EMR在规模和单中心数据方面具有局限性。但是,它包括患者背景信息和医学文本;因此,在调整患者背景后,可以估计未注册为ICD-10代码的AE的风险。此外,将AE视为事件时间结果允许在观察期间停止医学检查的病例将HR计算纳入审查案例;因此,也可以评估治疗的长期影响。提出方法的应用的示例包括比较某种药物与另一种药物(例如Oxaliptin + oxaliptin +辛伐他汀组与奥沙利帕素组相比)的组之间的AE HR,以将结果应用于药物重新定位,以发现新现有药物的药理作用51,52,或者使用累积发病率曲线可视化与抗癌药物治疗相关的AES风险,并将结果开发到向医疗专业人员和患者提供信息的应用中。
此外,我们利用了长期EMR并比较了在不同时间段中治疗的病例。考虑到此期间发生的重大医学进步,一个限制是无法调整这些影响。例如,支持护理的改善,例如PN或Neurokinin-1受体拮抗剂的前gabalin,以及伴有恶心和呕吐的食欲丧失的奥氮平的奥氮平可能会降低AES的患病率。此外,非药物医学技术的进步,例如针对预防OM和口腔感染的口腔护理广泛采用,可能会降低AES的患病率。此外,对EMR系统的更新可能改变了AE记录的方法和细节,可能会影响通过NLP提取AE的准确性。我们没有针对这些因素进行调整,这可能会在两组之间的比较中引起偏见。因此,在解释提出的HRS时要谨慎行事。将来阐明这些效果的一种方法是将数据分为多个时期,计算每个时期的HR,并比较它们以评估随着时间的推移的HR变化。在分析长期EMR数据时,这种偏见应被视为需要考虑的挑战。
总之,这项使用EMR数据的回顾性纵向观察研究证实,我们研究中NLP从临床文本中提取的四种AE类型的AE与三种类型的抗癌药物类别显着相关,并且显示与已知发生频率一致的HR。作为NLP性能评估进行的灵敏度分析表明,与精确度相比,所有四种AE的回忆均相对较低。但是,除了ta之外,对结果的影响受到限制。由于召回率低,在主要分析中提出的HR被低估了。我们还证明了所提出的方法在详细评估不同抗癌药物的毒性谱的详细评估中的潜在适用性。这些表明,使用NLP从临床文本中提取的AE可以用于信号检测的目的,并且EMR文本也可以在PM中使用。但是,有必要进行进一步的研究以确定是否可以使用其他设施的EMR获得同等结果。此外,NLP技术的开发能够提取导致AE的事件提出的挑战,这是将来必须解决的挑战。
方法
数据收集和以下所有实验均由东京大学和东京大学医院的机构审查委员会批准(批准编号2022251NI)。使用退出方法获得了知情同意,该方法是由机构伦理委员会批准的,这是由于研究的回顾性。所有实验均根据相关的道德准则和法规进行。
研究设计
这项回顾性纵向观察性研究使用了来自东京大学医院的EMR的数据。
数据库
我们在2004年1月1日至2021年12月31日的18年期间,使用了来自东京大学医院的患者的DPC数据。2003年,日本在全国范围内推出了基于DPC的付款系统53。DPC数据包括由医疗专业人员输入的信息,例如患者人口统计,主要诊断,入院时合并症,住院期间并发症以及进行的手术和手术。诊断和疾病名称根据ICD-10进行编码。DPC数据已被广泛用于临床流行病学研究,据报道,在DPC中注册的诊断敏感性为50%,特异性超过96%54,55,56,57。
除DPC以外使用的其他数据源包括处方和注射订单,进度和护理记录以及放电摘要。除DPC和出院摘要以外的信息是从涵盖患者病史的其他来源(例如住院和门诊护理)获得的。通过与解剖学治疗化学(ATC)分类代码相匹配的全国标准药物代码来分析药物类型。DPC,处方订单和注射订单是结构性信息;但是,进度记录,护理记录和出院摘要是用自由文本编写的;因此,使用下面描述的NLP工具提取AE。NLP工具
NLP工具Mednern
58由合着者发布的人被用来从进度和护理记录中提取AE,并出院摘要。该工具使用机器学习模型进行NER,该模型在大约2,000个日本医学文本的语料库上进行了微调59这是对从日语维基百科收集的1700万次刑期进行培训的。此后,通过将提取的命名实体标准化为内置词典中的术语来进行EN。在NER步骤中,分配了12个指定的实体类别,包括疾病名称(包括症状和发现)和时间表达。特别是,疾病名称类别被分配了与其事实性属性相关的四种类型的属性(正,负,可疑,一般)。在这些事实属性中,正面与命名实体的存在或观察相对应,而否定对应于否认其存在或观察。可疑的对应于诸如鉴别诊断之类的可疑疾病,并且普遍用于疾病的一般知识。尽管公开可用的Mednern包含ICD-10枚举的词典,但在本研究中创建了一个新的标准化字典并用于AES。该字典由AE的表面形式及其相应的归一化形式组成。例如,刺痛(表面形式)对应于两个下肢(表面形式)的超敏反应(归一化形式),对应于周围神经病(归一化形式)。该归一化字典是通过注册从进度和护理记录中提取的疾病名称类别的命名实体进行的,并由NER作为表面形式和手动分配的归一化表格进行排除的摘要,以确保未经常出现的命名实体被注册为表面字典中的形式。因此,作为对此类实体的度量,计算了字典中所有表面形式的Levenshtein距离,并分配了与最接近表面形式的归一化形式。表中显示了与本研究中针对的四种AE相关的标准化字典的一部分912。如图。3使用Mednern显示NER和EN的概述。
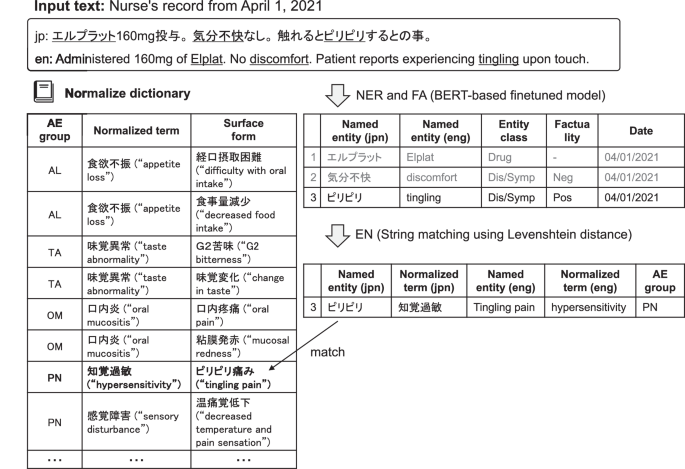
该过程始于NER和FA,使用基于BERT的微型模型。此步骤从输入文本中提取命名实体,并分类实体类型(例如药物,症状)和事实类型。在此示例中,â€â«â€ââ(Elplat)被识别为药物,«(不适)是一种负面症状,而‪(刺痛)是一种积极的症状。接下来,EN步骤利用与Levenshtein距离匹配的字符串将命名实体与字典中的归一化项对齐。例如,将叮叮当当(刺)与 - (超敏反应)相匹配,并归一化为刺痛疼痛,属于AE组的Pnâ(周围神经病)。在这一数字中,JPN指的是日语,英语指的是英语。与英语相对应的字符串是出于解释性目的,并且没有出现在实际分析中。
患者
该研究中包括的参与者是年龄16岁的患者,其中有所有类型的恶性肿瘤(ICD-10:C00-C96),该患者在数据库中注册为主要诊断或合并症。该疾病的所有阶段都包括在研究中,而没有基于疾病进展或特定分类的限制。此外,不论其治疗史,都包括患者,包括接受手术干预,放疗或任何其他癌症治疗方式的患者。总共确定了四个患者组:处方三类的三类抗癌药物(铂化合物,紫杉虫,嘧啶类似物),而一组患者在治疗过程中未开处方任何抗癌药。桌子13根据ATC分类显示每个药物类别的定义。排除标准是:1)只有可疑诊断为癌症的患者,2)在入院后24小时内死亡的患者,3)没有医学文本的患者,4)4)在该患者中发生结果。在观察开始之前的前180天。
暴露/比较
接受了含有铂化合物,紫杉烷或嘧啶类似物的治疗的患者组被指定为基于铂的治疗组,基于紫杉烷的治疗组和基于嘧啶的治疗组,并被称为PLT组,PLT组,税收组和PYA集团分别。没有开处方的患者的组被指定为NTX组。在PLT组和NTX组,税组和NTX组以及PYA组和NTX组之间进行了比较。
结果
PLT,税收和PYA组的观察开始日期是每种抗癌药物的首次处方日期,并且在365天内将PN,OM,TA和AL的发生定义为结果。相反,NTX组的观察开始日期是根据癌症首次诊断后的多个可能的住院日期确定的,并且在365天内将PN,OM,TA和AL的发生定义为结果。NTX组的观察开始日期是PSM匹配的DPC住院日期60。如果NER提取的疾病名称类别的命名实体具有正面属性,并且与表中显示的任何表面形式匹配,则认为PN,OM,TA和AL的AE被认为发生了912。发生日期是文件记录日期。在对性能的分析中,案例报告的Mednern阳性疾病名称类提取的宏F值为59.21%,放射学报告为84.88%58。
协变量
从DPC获得的总共33个项目用作PSM的协变量:年龄,性别,吸烟指数,初始癌症发生,三种类型的ADL(进食,步行,排便),14种癌症部位(由ICD-10定义),以及12种合并症(由ICD-10定义)。将二进制变量设置为“ 65日元”,年龄<65岁,吸烟指数为400日元,<400日元,独立和其他ADL的独立性。除观察开始日期以外的180天(即,l01aa氮芥末类似物)以外的180天,共有51个在ATC 5位单位中汇总的抗癌药物的协变量,这些协变量是为抗癌药物的。pH模型。
倾向得分匹配
通过比较PLT和NTX组,税收组和NTX组以及PYA和NTX组的PSM来评估PN,OM,TA和AL的发生。使用多变量逻辑回归估算了PLT,税收和PYA的倾向评分(PS),从DPC获得的33个项目作为解释变量。估计的PS使用一对一的邻居匹配,而无需更换,卡尺宽度为0.2标准偏差60。NTX组的患者曾经被排除在池之外。使用PSM前后的ASD比较两组之间的协变量。当ASD> 10%时,两组之间变量的不平衡被认为可以忽略不计61。在协变量,复发,吸烟指数和三种ADL类型中,丢失值约为19%43%。因此,在PSM之前使用链式方程方法进行多个插定,以进行多个插补20次的丢失值62。如图。4显示了时间序列上各种数据的布置的示例以及匹配的概述。

该图说明了接触组候选者的选择(患者开出了正在研究的抗癌药物)和无治疗组候选者(在整个观察期内,患者没有开任何抗癌药物)。每个患者的时间表包括初始抗癌药处方,DPC数据库中的数据点以及临床文本记录。使用DPC数据,使用PSM来识别暴露组和无治疗组之间的最接近匹配。活动时间分析测量了从第一个处方日期到初始AE发生的天数。在观察开始前180天内记录的AES患者被排除在分析之外。活动时间分析
PSM之后,使用COX pH模型来建模AE发生的时间。
在观察开始之前,AES可能是由其他抗癌药物引起的可能性不能被排除在PLT,税收和PYA组中。因此,除了分析的抗癌药物外,在观察开始前的180天内开了51种其他抗癌药物作为协变量,以调整这些作用。但是,排除处方频率> 1%的抗癌药物以稳定模型。此外,通过计算分析的抗癌药物与其他抗癌药物与其他抗癌药物之间的变量组合的Pearson相关系数避免了多重共线性,在分析中排除了绝对值0.3的相关性¥0.3。估计了具有95%CI的HRS,以检查分析的抗癌药物的使用与12个月后的结局之间的关联。累积发生率曲线和对数秩检验用于事件分析。显着性水平设定为p<0.05。所有测试都是双面的。所有分析均使用Stata/MP 18.0版本软件(StataCorp,美国德克萨斯州,美国德克萨斯州)进行。如图。5显示了从患者选择到活动时间分析的流程图。图5:从患者选择到活动时间分析的流程图。
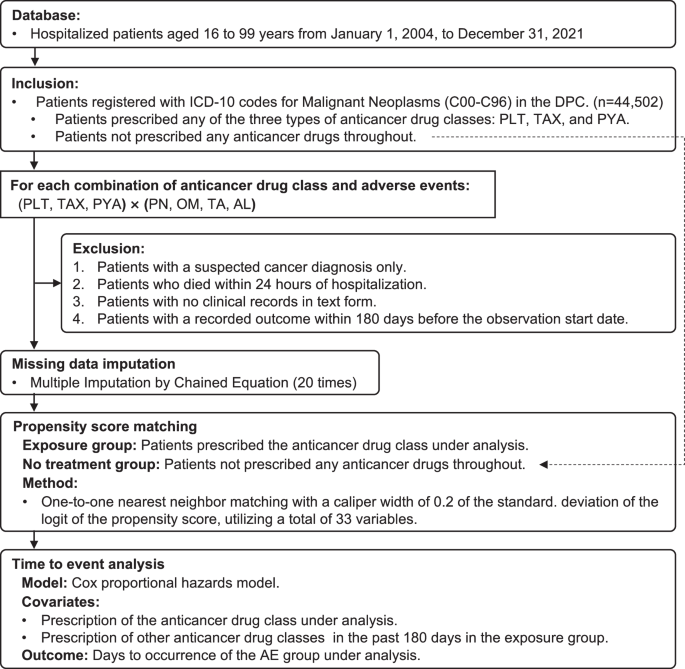
纳入标准涵盖了三种抗癌药物中的任何一个,这些患者在整个过程中没有开任何抗癌药。排除标准仅适用于仅怀疑癌症诊断的患者,在住院后24小时内死亡的患者,没有临床记录的患者,以及在观察开始日期前180天内记录结果的患者。使用链式方程式多个插补的数据进行了20次处理。然后进行倾向分数匹配,使用一对一的邻居匹配方法将暴露组与无治疗组配对。最后,使用COX pH模型进行了事实分析。该模型考虑了过去180天作为协变量,在分析中考虑了抗癌药物类别和其他抗癌药物类别的处方,其结果是在分析中发生不良事件组的几天。
应用于AE抗癌药物之间的AE比较
我们在两种情况下在同一类中研究了两种不同类别的AES的HRS,以证明更具体的应用:1)我们评估了Oxaliptin和cisplatin之间PN的风险差异,因为已经知道Oxaliplatin的PN发生率更高63。具体而言,我们使用顺铂给药作为分类变量,构建了一个逻辑回归模型,以计算接受顺铂或奥沙利铂的患者的PS。通过PSM鉴定了两组患者后,我们估计了在初次服用顺铂或奥沙利铂后360天内PN发生的HR。2)同样,我们评估了多西他赛和紫杉醇之间OM的风险差异,因为多西他赛与较高的OM频率有关64。在这两种情况下,我们都使用PSM鉴定并比较了两组具有相似背景的患者。与初级分析不同,我们使用逻辑回归模型计算了PS分数,该模型不仅包括从DPC数据库获得的33个协变量,还包括多达51种抗癌药物的历史,因为两组都有抗癌药物的历史。此外,我们将ASD用作PSM协变量调整的指标。对于ASD超过10%的协变量,我们使用PSM后使用多元COX pH模型调整了HR估计。所有其他分析设置均与主要分析一致。此外,我们根据抗癌药物的处方数量和视觉检查的对数转换的累积发生率曲线来检查累积发生率曲线,以确认比例危害假设。我们使用了处方的数量,而不是抗癌药物的剂量,因为本研究中使用的处方数据不包含有关给患者的实际剂量的信息。
敏感性分析
首先,我们评估了NLP提取AES的性能,并检查了NLP错误对结果的影响。通过从PSM后PLT和NTX组中的每个AES(PN,OM,TA和Al)的每个比较中随机选择100对匹配对(总共800例)来评估NLP性能。我们使用段落断裂作为段落边界,手动注释跨越段落级别的临床文本,以确定相关AE的存在。对于具有完全重复的段落的患者,仅考虑了第一个记录的段落。段落没有任何AE的表达的段落被标记为负。此外,如果段落包含表明出现AE的表达,我们将段落归为积极,不包括明显否定抗癌药物的影响的情况(例如,当显而易见其他治疗或疾病的影响时)。专门从事癌症药物治疗(MT)的药剂师进行了注释,然后由具有癌症药物治疗经验的医生(YK)对此进行了审查。NLP预测也在段落级别进行,并使用二进制分类指标评估结果:回忆,精度和F值。关于对结果的影响,我们将基于手动提取的AES的发生日期确定为黄金标准。然后,我们检查了NLP误差对结果的存在和发生时间的影响。
其次,由于NTX组未接受抗癌药物治疗,因此在观察期内,这些患者接受了较少的体检。因此,可能估计AE发生的风险为低。因此,计算了与NTX组中NTX组中N%相对应的病例数,并进行了模拟,并使用COX pH模型再次计算HR,假设AE发生在M病例从不发生AE的NTX组中随机选择65。在假定AE发生的情况下发生事件发生的天数是使用参数COX pH模型估算的,在该模型中,事件的时间遵循Weibull分布。n值增加了10%,最高50%,每种N值的平均HR和95%CI的平均HR和95%的CI显示。最后,我们评估并检查了每个比较实验的HR,观察周期为30和180天。除观察期外,所有其他设置与主要分析保持一致。
数据可用性
由于医学院研究生院和东京大学医学院研究生院的限制,由于当前研究中分析的数据集无法公开获得,因为它们包含敏感的患者信息。根据东京大学医院的政策,数据披露尚未包含在伦理申请中,也不允许在本研究中。For the other specific information, please contact the corresponding author.
代码可用性
The underlying NLP tool, MedNERN, and the Dictionary of Adverse Events for MedNERN used in this study can be accessed via the following links:https://huggingface.co/sociocom/MedNERN-CR-JA。https://github.com/sociocom/MedDic-ADE。参考Gough, S. Post-marketing surveillance: a UK/European perspective.
电流。
医学。资源。意见。 21, 565–570 (2005).
Hazell, L. & Shakir, S. A. Under-reporting of adverse drug reactions: a systematic review.毒品安全。 29, 385–396 (2006).
Alomar, M., Tawfiq, A. M., Hassan, N. & Palaian, S. Post marketing surveillance of suspected adverse drug reactions through spontaneous reporting: current status, challenges and the future.瑟尔。副词。毒品安全。 11, 2042098620938595 (2020).
科斯塔,C.等人。Factors associated with underreporting of adverse drug reactions by patients: a systematic review.国际。J.克林。医药。 45, 1349–1358 (2023).
Platt, R. et al. The new Sentinel Network-improving the evidence of medical-product safety.N. 英格兰。J. Med。 第361章, 645–647 (2009).
Yamaguchi, M. et al. Establishment of the MID-NET® medical information database network as a reliable and valuable database for drug safety assessments in Japan.Pharmacoepidemiol.毒品安全。 28, 1395–1404 (2019).
Sentinel Common Data Model.https://www.sentinelinitiative.org/methods-data-tools/sentinel-common-data-model(2024)。
Current status and practices of quality management for MID-NET.https://www.pmda.go.jp/files/000244339.pdf(2019)。
Nadkarni, P. M. Drug safety surveillance using de-identified EMR and claims data: issues and challenges.J. Am.医学。通知。副教授。 17 号, 671–674 (2010).
Classen, D. C. et al. Global trigger tool’ shows that adverse events in hospitals may be ten times greater than previously measured.健康事务部。 30, 581–589 (2011).
罗,Y.等人。Natural Language Processing for EHR-Based Pharmacovigilance: a structured review.毒品安全。 40, 1075–1089 (2017).
李,Y.等人。Artificial intelligence-powered pharmacovigilance: a review of machine and deep learning in clinical text-based adverse drug event detection for benchmark datasets.J.生物医学。通知。 152, 104621 (2024).
库希德,S.等人。Cohort design and natural language processing to reduce bias in electronic health records research.NPJ Digit.医学。 5, 47 (2022).
Sheu, Y. et al. AI-assisted prediction of differential response to antidepressant classes using electronic health records.NPJ Digit.医学。 6, 73 (2023).
Lee, H. J. et al. StrokeClassifier: ischemic stroke etiology classification by ensemble consensus modeling using electronic health records.NPJ Digit.医学。 7, 130 (2024).
Guevara, M. et al. Large language models to identify social determinants of health in electronic health records.NPJ Digit.医学。 7, 6 (2024).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding.在过程中。2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,Volume 1 (Long and Short Papers), 4171–4186. (Association for Computational Linguistics, 2019).
瓦斯瓦尼,A.等人。您所需要的就是关注。副词。神经信息。过程。系统。 30, 5998–6008 (2017).
谷歌学术一个
李,J.等人。BioBERT:用于生物医学文本挖掘的预训练生物医学语言表示模型。生物信息学 36, 1234–1240 (2020).
Kawazoe, Y., Shibata, D., Shinohara, E., Aramaki, E. & Ohe, K. A clinical specific BERT developed using a huge Japanese clinical text corpus.公共图书馆一号 16, e0259763 (2021).
Kim, Y. et al. A pre-trained BERT for Korean medical natural language processing.科学。代表。 12, 13847 (2022).
Zhou, S., Kang, H., Yao, B. & Gong, Y. An automated pipeline for analyzing medication event reports in clinical settings.BMC 医学。通知。决定。麦。 18, 113 (2018).
El-allaly, E., Sarrouti, M., En-Nahnahi, N. & Ouatik El Alaoui, S. MTTLADE: a multi-task transfer learning-based method for adverse drug events extraction.信息。流程管理。 58, 102473 (2021).
Mahendran, D. & McInnes, B. T. Extracting adverse drug events from clinical notes.AMIA Jt Summits Transl.科学。过程。 2021年, 420–429 (2021).
吴,H.等人。Chinese-named entity recognition from adverse drug event records: radical embedding-combined dynamic embedding-based BERT in a Bidirectional Long Short-term Conditional Random Field (Bi-LSTM-CRF) model.JMIR 医学。通知。 9, e26407 (2021).
Narayanan, S. et al. A contextual multi-task neural approach to medication and adverse events identification from clinical text.J.生物医学。通知。 125, 103960 (2022).
金,S.等人。Automatic extraction of comprehensive drug safety information from adverse drug event narratives in the Korea adverse event reporting system using natural language processing techniques.药品。萨夫。 46, 781–795 (2023).
Oun, R., Moussa, Y. E. & Wheate, N. J. The side effects of platinum-based chemotherapy drugs: a review for chemists.道尔顿跨。 47, 6645–6653 (2018).
Lee, K. W. et al. SOPP study investigators. Multicenter phase III trial of S-1 and cisplatin versus S-1 and oxaliplatin combination chemotherapy for first-line treatment of advanced gastric cancer (SOPP trial).胃癌 24, 156–167 (2021).
Burgess, J. et al. Chemotherapy-induced peripheral neuropathy: epidemiology, pathomechanisms and treatment.安科尔。瑟尔。 9, 385–450 (2021).
Bridges, C. M. & Smith, E. M. What about Alice? Peripheral neuropathy from taxane-containing treatment for advanced nonsmall cell lung cancer.支持护理癌症 22 号, 2581–2592 (2014).
Hironaka, S. et al. Randomized, open-label, phase III study comparing irinotecan with paclitaxel in patients with advanced gastric cancer without severe peritoneal metastasis after failure of prior combination chemotherapy using fluoropyrimidine plus platinum: WJOG 4007 trial.J.克林。安科尔。 31, 4438–4444 (2013).
Stein, M. E. et al. A rare event of 5-fluorouracil-associated peripheral neuropathy: a report of two patients.是。J.克林。安科尔。 21, 248–249 (1988).
Saif, M. W. et al. Peripheral neuropathy associated with weekly oral 5-fluorouracil, leucovorin and eniluracil.Anticancer Drugs 12, 525–531 (2001).
Naidu, M. U. et al. Chemotherapy-induced and/or radiation therapy-induced oral mucositis-complicating the treatment of cancer.瘤形成 6, 423–431 (2004).
Trotti, A. et al. Mucositis incidence, severity and associated outcomes in patients with head and neck cancer receiving radiotherapy with or without chemotherapy: a systematic literature review.Radiother.安科尔。 66, 253–262 (2003).
Jones, S. E. et al. Randomized phase III study of docetaxel compared with paclitaxel in metastatic breast cancer.J.克林。安科尔。 23, 5542–5551 (2005).
Seddon, B. et al. Gemcitabine and docetaxel versus doxorubicin as first-line treatment in previously untreated advanced unresectable or metastatic soft-tissue sarcomas (GeDDiS): a randomized controlled phase 3 trial.柳叶刀 Oncol。 18, 1397–1410 (2017).
Popescu, R. A., Norman, A., Ross, P. J., Parikh, B. & Cunningham, D. Adjuvant or palliative chemotherapy for colorectal cancer in patients 70 years or older.J.克林。安科尔。 17 号, 2412–2418 (1999).
Abdel-Rahman, O., ElHalawani, H. & Essam-Eldin, S. S-1-based regimens and the risk of oral and gastrointestinal mucosal injury: a meta-analysis with comparison to other fluoropyrimidines.专家意见。毒品安全。 15, 5–20 (2016).
Zabernigg, A. et al. Taste alterations in cancer patients receiving chemotherapy: a neglected side effect?肿瘤科医生 15, 913–920 (2010).
Wickham, R. S. et al. Taste changes experienced by patients receiving chemotherapy.安科尔。护士。论坛 26, 697–706 (1999).
Steinbach, S. et al. Qualitative and quantitative assessment of taste and smell changes in patients undergoing chemotherapy for breast cancer or gynecologic malignancies.J.克林。安科尔。 27, 1899–1905 (2009).
Buttiron Webber, T., Briata, I. M., DeCensi, A., Cevasco, I. & Paleari, L. Taste and Smell Disorders in Cancer Treatment: Results from an Integrative Rapid Systematic Review.国际。J.莫尔。科学。 24, 2538 (2023).
Morizane, C. et al. Members of the Hepatobiliary and Pancreatic Oncology Group of the Japan Clinical Oncology Group (JCOG-HBPOG). Combination gemcitabine plus S-1 versus gemcitabine plus cisplatin for advanced/recurrent biliary tract cancer: the FUGA-BT (JCOG1113) randomized phase III clinical trial.安.安科尔。 30, 1950–1958 (2019).
Argyriou, A. A., Polychronopoulos, P., Iconomou, G., Chroni, E. & Kalofonos, H. P. A review on oxaliplatin-induced peripheral nerve damage.癌症治疗。牧师。 34, 368–377 (2008).
Lan, Z. & Turchin, A. Impact of possible errors in natural language processing-derived data on downstream epidemiologic analysis.贾米亚公开赛 6, ooad111 (2023).
胡,Y.等人。Improving large language models for clinical named entity recognition via prompt engineering.J. Am.医学。通知。副教授。 31, 1812–1820 (2024).
Soroush, A. et al. Large Language Models Are Poor Medical Coders—Benchmarking of Medical Code Querying. NEJM AI.1, AIdbp2300040 (2024).
Fusaroli, M. et al. The REporting of A Disproportionality Analysis for DrUg Safety Signal Detection Using Individual Case Safety Reports in PharmacoVigilance (READUS-PV): explanation and elaboration.毒品安全。 47, 585–599 (2024).
Zamami, Y. et al. Identification of prophylactic drugs for oxaliplatin-induced peripheral neuropathy using big data.生物医学。药剂师。 148, 112744 (2022).
Imai, S. et al. Using Japanese big data to investigate novel factors and their high-risk combinations that affect vancomycin-induced nephrotoxicity.Br。J.克林。药理学。 88, 3241–3255 (2022).
Yasunaga, H., Ide, H., Imamura, T. & Ohe, K. Impact of the Japanese Diagnosis Procedure Combination-based Payment System on cardiovascular medicine-related costs.国际。心 J。 46, 855–866 (2005).
Yamana, H. et al. Validity of diagnoses, procedures, and laboratory data in Japanese administrative data.J.流行病学。 27, 476–482 (2017).
Ishikawa, H., Yasunaga, H., Matsui, H., Fushimi, K. & Kawakami, N. Differences in cancer stage, treatment and in-hospital mortality between patients with and without schizophrenia: retrospective matched-pair cohort study.Br。J. Psychiatry 208, 239–244 (2016).
Sasabuchi, Y. et al. The volume-outcome relationship in critically Ill patients in relation to the ICU-to-hospital bed ratio.暴击。护理医学。 43, 1239–1245 (2015).
Yamana, H., Matsui, H., Sasabuchi, Y., Fushimi, K. & Yasunaga, H. Categorized diagnoses and procedure records in an administrative database improved mortality prediction.J.克林。流行病。 68, 1028–1035 (2015).
Yada, S., Nakamura, Y., Wakamiya, S. & Aramaki, E. Cross-lingual natural language processing on limited annotated case/radiology reports in English and Japanese: Insights from the Real-MedNLP workshop.Methods Inf.医学。(2024)。https://doi.org/10.1055/a-2405-2489
tohoku-nlp/bert-base-japanese-whole-word-masking.https://huggingface.co/tohoku-nlp/bert-base-japanese-whole-word-masking(2020)。
Rosenbaum, P. R. & Rubin, D. B. Constructing a control group using multivariate matched sampling methods that incorporate the propensity score.是。统计。 39, 33–38 (1985).
Austin, P. C. Balance diagnostics for comparing the distribution of baseline covariates between treatment groups in propensity-score matched samples.统计。医学。 28, 3083–3107 (2009).
Azur, M. J. et al. Multiple imputation by chained equations: what is it and how does it work?国际。J. 精神病学方法。资源。 20, 40–49 (2011).
Yamada, Y. et al. Phase III study comparing oxaliplatin plus S-1 with cisplatin plus S-1 in chemotherapy-naïve patients with advanced gastric cancer.安.安科尔。 26, 141–148 (2015).
Lai, J. I., Chao, T. C., Liu, C. Y., Huang, C. C. & Tseng, L. M. A systemic review of taxanes and their side effects in metastatic breast cancer.正面。安科尔。 12, 940239 (2022).
Bender, R., Augustin, T. & Blettner, M. Generating survival times to simulate Cox proportional hazards models.统计。医学。 24, 1713–1723 (2015).
致谢
This study was funded by JST CREST [grant number JPMJCR22N1], JSPS KAKENHI [grant number 23H03492], and partially funded by the Progress of the Next Cross-ministerial Strategic Innovation Promotion Program (SIP) on “Integrated Health Care System†[grant number JPJ012425].资助者在研究设计、数据收集、数据分析和解释或本手稿的撰写中没有发挥任何作用。
道德声明
利益竞争
Y.K., K.S., and E.S. belong to the Artificial Intelligence and Digital Twin in Healthcare, Graduate School of Medicine, University of Tokyo, which is an endowment department, and was supported by an unrestricted grant from EM Systems, EPNextS, MRP CO., LTD., SHIP HEALTHCARE HOLDINGS, INC., SoftBank Corp., and NEC Corporation; these organizations had no control over the interpretation, writing, or publication of this work. The other authors declare no financial or non-financial competing interests.
附加信息
Publisher’s note施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
补充资料
权利和权限
开放获取本文获得 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License 的许可,该许可允许以任何媒介或格式进行任何非商业使用、共享、分发和复制,只要您给予原作者适当的署名即可和来源,提供知识共享许可的链接,并指出您是否修改了许可材料。根据本许可,您无权共享源自本文或其部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

Kawazoe, Y., Shimamoto, K., Seki, T.
等人。Post-marketing surveillance of anticancer drugs using natural language processing of electronic medical records.npj Digit.医学。 7, 315 (2024). https://doi.org/10.1038/s41746-024-01323-1
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41746-024-01323-1