

ModeLeak:Vertex AI 中 LLM 模型渗透的权限升级
作者:Ofir Balassiano, Ofir Shaty
执行摘要
为了获得竞争优势,组织越来越多地利用敏感数据训练人工智能 (AI) 模型。但如果看似无害的人工智能模型成为攻击者的门户怎么办?
恶意行为者可以将中毒模型上传到公共存储库,并且您的团队可能在没有意识到的情况下将其部署在您的环境中。一旦激活,该模型可能会泄露您敏感的机器学习 (ML) 模型和微调的大型语言模型 (LLM) 适配器。通过访问这些适配器,攻击者可以复制您的自定义调整和优化,从而暴露微调模式中嵌入的敏感信息。
Palo Alto Networks 研究人员最近发现了 Google Vertex AI 平台中的两个漏洞。这些漏洞可能允许攻击者升级权限并窃取模型。
我们已与 Google 的合作伙伴分享了这些发现,他们随后实施了修复程序,以消除 Google 云平台 (GCP) 上 Vertex AI 的这些特定问题。请继续阅读以了解这些漏洞的工作原理以及如何保护您的环境免受类似威胁。
在本文中,我们概述了发现 Vertex AI 平台中两个漏洞的步骤:
- 通过自定义作业提升权限
通过利用自定义作业权限,我们能够升级权限并获得对项目中所有数据服务的未经授权的访问。 - 通过恶意模型进行模型泄露
在 Vertex AI 中部署中毒模型会导致所有其他经过微调的模型被泄露,从而构成严重的专有和敏感数据泄露攻击风险。
我们对第一个漏洞的检查以经典的权限升级结束,但第二个漏洞代表了一个更有趣的“模型到模型”感染场景,需要深入探索。
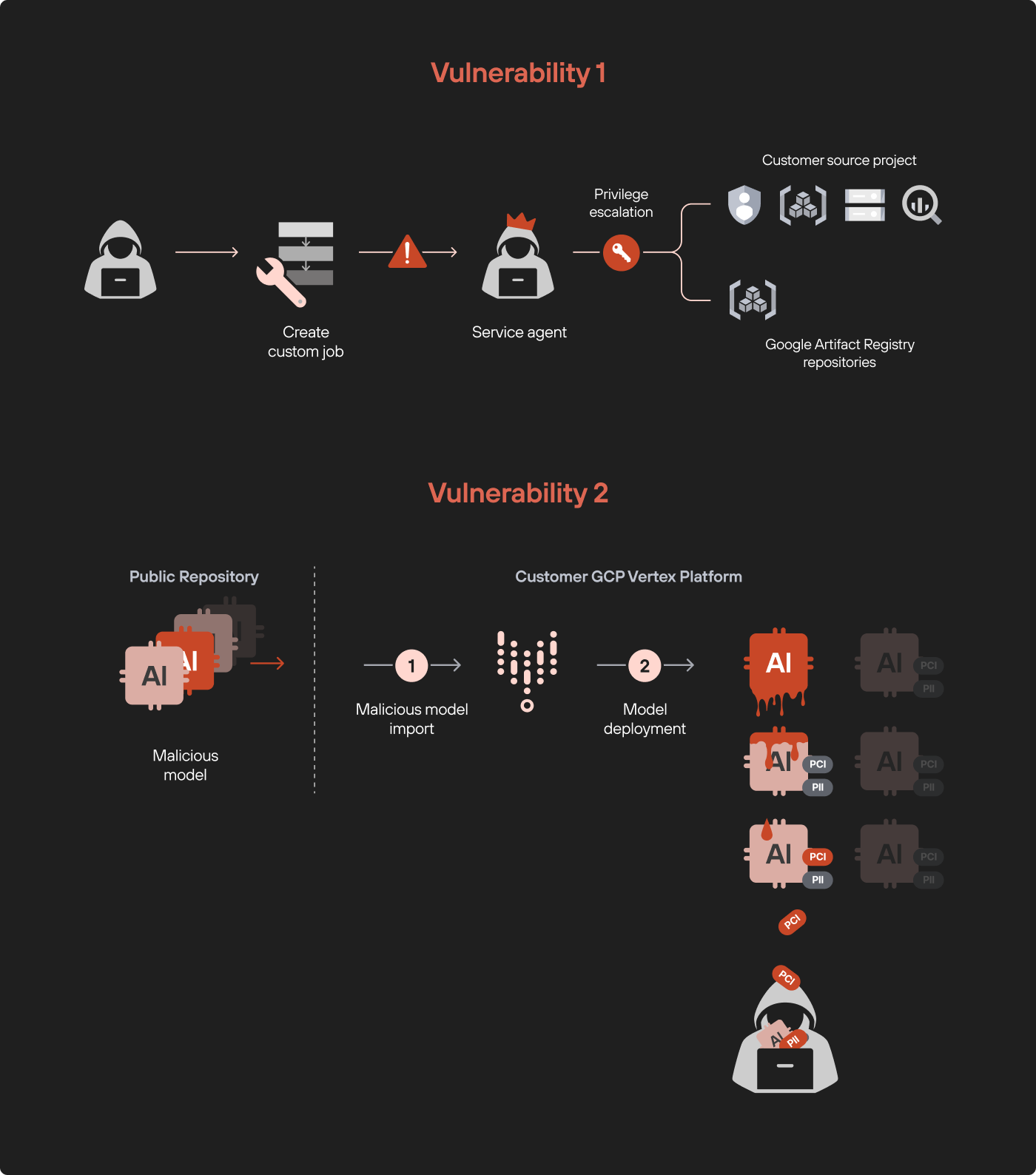
图 1 显示了两个漏洞的示意图。
通过我们的服务,Palo Alto Networks 客户可以更好地免受本文讨论的威胁棱镜云供品。
如果您认为自己可能已受到威胁或有紧急事务,请联系Unit 42 事件响应小组。
| 相关单元 42 主题 | 云网络安全研究,权限提升权限提升 |
时间通过自定义代码注入我们发现的第一个漏洞是通过自定义代码注入进行权限升级。
为了正确解释这个方法,我们必须首先了解模型调优Vertex AI 管道。
背景:了解使用 Vertex AI Pipelines 进行模型调整
Vertex AI 是一个用于开发、训练和部署 ML 和 AI 模型的综合平台。该平台的一个关键功能是 Vertex AI Pipelines,它允许用户使用定制作业,也称为定制培训作业。
这些自定义作业本质上是在管道内运行的代码,可以以各种方式修改模型。虽然这种灵活性很有价值,但它也为潜在的利用打开了大门。
我们的研究重点是攻击者如何滥用自定义作业。通过操纵自定义作业管道,我们发现了一条权限升级路径,使我们能够访问远远超出预期范围的资源。
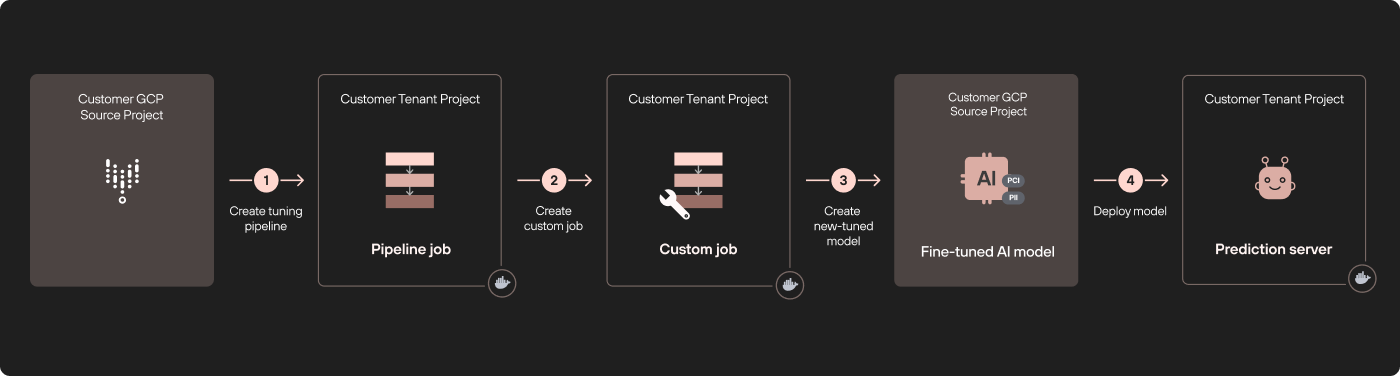
在图 2 中,调整 Vertex AI 模型(ML 或 LLM)发生在专用于源项目的远程租户项目中(步骤 1)。调整过程使用 Vertex AI Pipelines 中定义的自定义作业,这些作业在不同的租户项目上运行(步骤 2)。
调整过程完成后,将在原始项目的模型注册表中创建一个新的调整模型(步骤 3)。此时,我们将模型部署在第三个不同的租户项目中(步骤 4)。
提权漏洞攻击流程
运行时,自定义作业在租户项目中执行服务代理身份。默认情况下,服务代理对源项目中的许多服务拥有过多的权限,例如源项目的所有服务云存储和大查询数据集。借助服务代理的身份,我们可以列出、读取甚至导出我们本不应该访问的存储桶和数据集中的数据。
深入研究:注入自定义代码
对于运行特定代码的自定义作业,我们可以将命令注入到容器规范 JSON配置或创建打开反向 shell 的映像。在我们的例子中,我们创建了一个自定义图像作为后门,使我们能够访问环境。下面的图 3 显示了我们用于创建此自定义图像的命令。

通过在租户项目中运行此自定义作业,我们发现我们的身份如下:
服务-<PROJECT_NUMBER>@gcp-sa-aiplatform-cc.iam.gserviceaccount[.]com
该服务代理是AI平台自定义代码服务代理。通过充当此角色的服务代理,我们可以执行以下活动:
- 访问元数据服务
- 获取服务凭证
- 提取用户数据脚本
该帐户拥有广泛的权限,包括以下内容:
- 列出所有服务帐户的能力
- 创建、删除、读取、写入所有存储桶
- 访问所有 BigQuery 表
图 4 列出了特定权限我们的服务代理在测试期间在源项目中拥有该信息。

用户数据脚本使我们能够了解虚拟机 (VM) 创建情况,并为我们提供有关 GCP 内部的元数据Artifactory 存储库。
我们使用元数据访问内部 GCP 存储库并下载我们原始服务帐户没有权限的图像。尽管我们获得了对受限制的内部 GCP 存储库的访问权限,但我们无法了解所发现的漏洞的严重程度,因为存储库的权限是在存储库级别授予的。
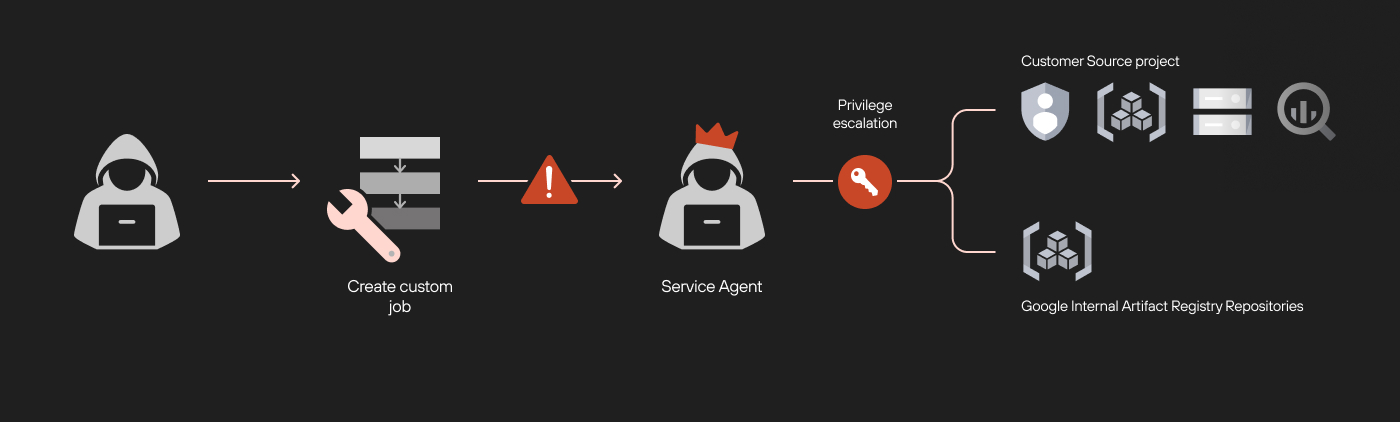
这是一个经典的权限提升,只需单一权限aiplatform.customJobs.create使我们能够访问原始项目中的其他资源。这是我们在 Vertex AI 平台中发现的第一个漏洞。图 5 显示了通过自定义作业利用此漏洞进行权限升级的流程图。
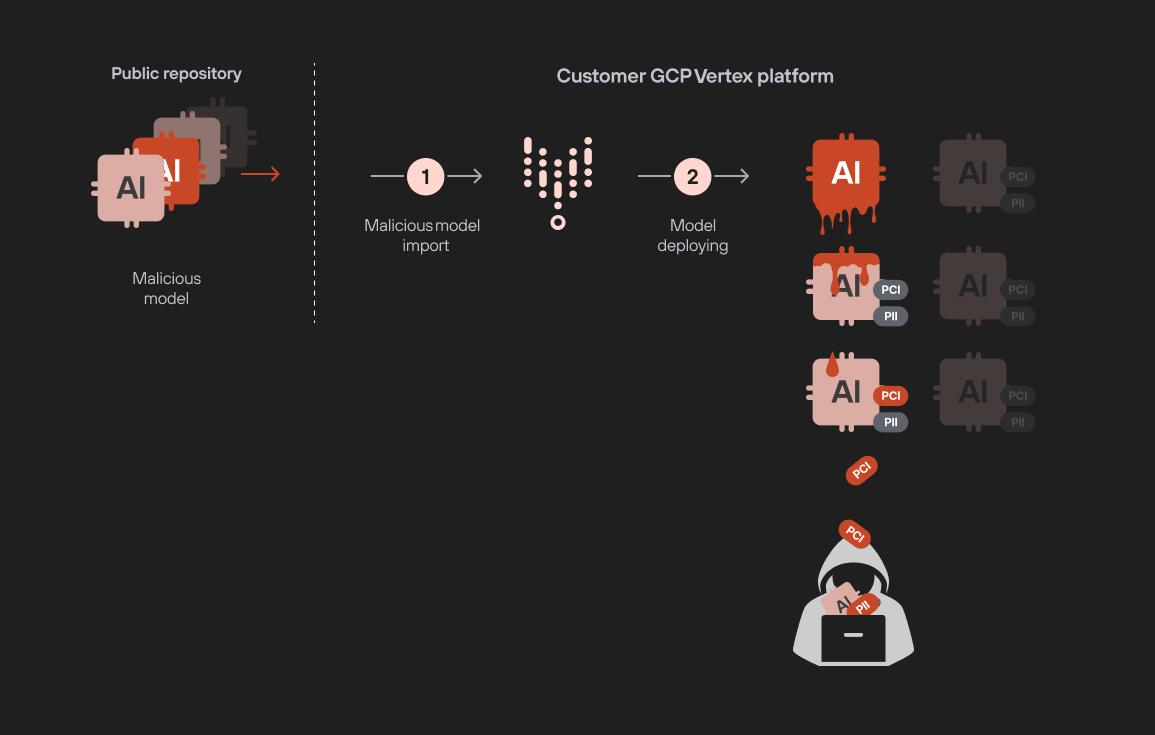
通过恶意模型部署进行模型渗透攻击
本节探讨我们在 Vertex AI 中发现的第二个漏洞。我们演示了部署恶意模型如何导致严重后果,包括环境中其他模型的渗透。
想象一下,一个恶意行为者将中毒的模型上传到公共模型存储库。您组织内的数据科学家在没有意识到威胁的情况下,在 Vertex AI 中导入并部署了该模型。一旦部署,恶意模型就可以渗透到项目中的所有其他 ML 和 LLM 模型,包括敏感的微调模型,从而使您的组织最关键的资产面临风险。
我们通过在我们部署用于测试的 Vertex AI 环境中部署中毒模型来制定此场景。在我们的测试过程中,我们获得了访问定制在线预测服务帐户,使我们能够从我们的测试项目中查看和窃取其他人工智能和机器学习模型。
模型渗透攻击的攻击流程
攻击流程由两个步骤组成。首先,我们在租户项目中部署了中毒模型,这使我们能够访问受限制的 GCP 存储库和敏感模型数据。第二步,我们使用中毒模型来窃取专有的人工智能模型,包括微调的 LLM 适配器。
深入研究:准备恶意顶点模型
在我们深入准备模型和讨论顶点平台之前,让我们先介绍一下 Vertex 的一些基础知识。
在我们的上一节在讨论使用 Vertex AI Pipelines 进行模型调整时,我们概述了调整模型的流程。为了创建恶意模型,我们从“无辜”模型开始。当我们完成训练过程后,我们将在Vertex AI 模型注册表。
Vertex AI 模型注册表包含所有导入或训练的模型。这允许 GCP 控制台中的多项功能,例如部署到端点。图 6 显示这些功能之一是将模型导出到存储桶的导出功能。
导出图 6 中所示的模型表明该模型是由向量并运行指定的图像。下面,图7标识了导出模型的具体图像环境.json文件。
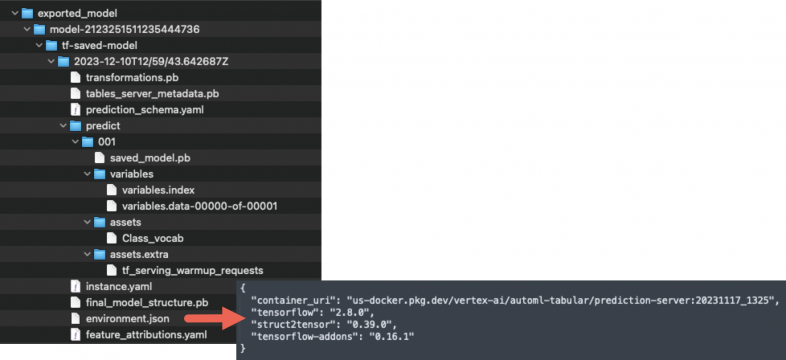
通过更改模型中的图像,我们可以对其进行自定义以创建反向 shell,然后将新修改的模型导入到模型注册表中。将此更改后的模型部署到端点将触发反向 shell,从而允许我们导航测试环境的租户项目。
获得外壳后,我们发现我们正在以定制在线预测该环境下的service-account,如下图8所示。

使用这个方法,我们没有权限使用cloudresourcemanager.projects.getIamPolicy,因此我们无法在租户项目中列出我们的权限。但是,我们可以使用cloudresourcemanager.projects.testIamPermissions枚举我们在租户项目中的权限。尽管此服务帐户的权限是只读的,但只需一点想象力,这种访问级别就可以产生巨大的力量,正如我们将说明的那样。
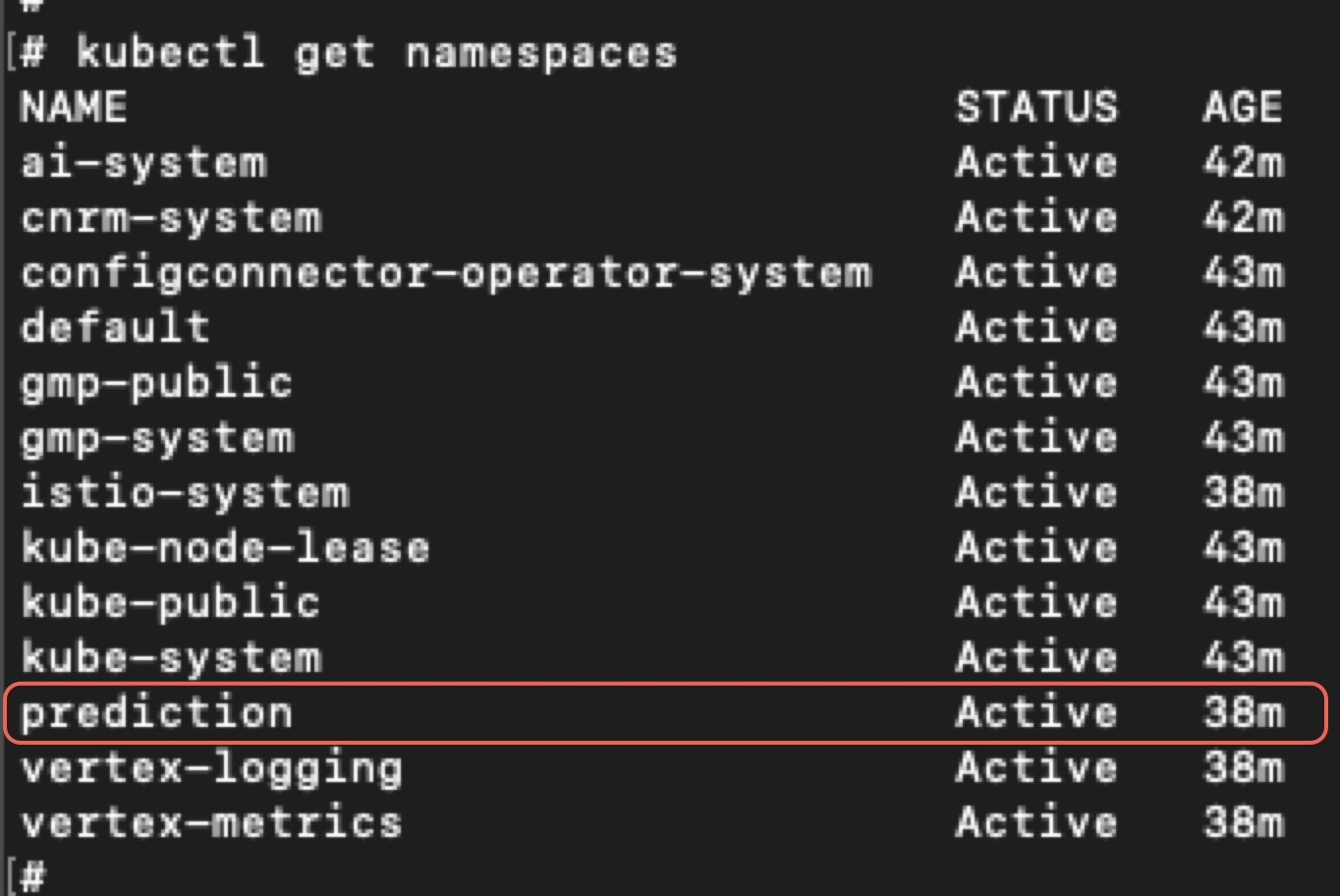
图 9 显示了列出该项目中所有资源的结果,枚举了三个 Kubernetes 集群。

在该项目的三个 Kubernetes 集群中,我们的恶意模型在第三个集群上运行,这是端点的部署过程。稍后我们将回顾前两个集群,但现在让我们检查第三个集群。
运行库贝克特尔要在这些集群上执行命令来检索有关 pod 和命名空间的信息,我们需要适当的权限。我们通过执行以下命令实现了这一目标获取集群凭证使用我们在图 9 的上一个枚举步骤中收集的集群名称,在 GCP 中运行命令。下面的图 10 显示了结果。

有了这些凭证,我们就可以使用 kubectl 来探索集群,列出命名空间、pod、容器和服务帐户。这一步使我们能够从 GCP 领域转移到 Kubernetes。这种横向移动是可能的,因为 GCP 和 GKE 之间的权限是通过IAM 工作负载身份联合。
我们发现自己在一个新创建的集群中运行,我们的命名空间名称是预言如下图11所示。
返回 GCP,我们列出了服务帐号。通过分析 GCP 服务帐户的 IAM 权限,我们注意到附加到它的 Kubernetes 服务帐户。图 12 显示了此列表,其中显示了我们新创建的服务帐户预言簇。

在我们集群的默认命名空间中,仅存在默认服务帐户。但是,根据我们收集的信息,我们推断我们的 GCP 服务帐户也可以访问其他 Kubernetes 集群。通过检查 pod 详细信息并检查图像,我们确认我们正在预测命名空间中 pod 内的容器内运行,很可能是在预测/默认服务。下面的图 13 说明了这一点。

既然我们已经确定了自己的身份,那么下一个问题就是确定我们能做什么。
我们尝试创建、删除、更新、附加、执行等操作,但由于没有权限而失败。然而,我们可以枚举所有集群,这为我们提供了大量信息,并增加了我们尝试更多攻击向量的范围。
通过我们的只读权限,我们可以在新创建的容器中列出 Pod预言集群使用列出 Pod命令。图 14 显示了此输出中的两个特定条目。

图 14 显示了我们的预测命名空间中的以下两个 pod:
- 预测器资源池-3882551479537500160-867655f99c-2dhhc
- 预测器资源池-7628701944579620864-ccc8d8b94-f2chw
两个 Pod 都有使用来自租户项目中存储库的图像的容器。这些图像是:
- us-central1-docker.pkg.dev/s154574aecb0c9653-tp/dm-2118255330398830592-pipeline-6604364906047209472/lala:最新
- us-central1-docker.pkg.dev/s154574aecb0c9653-tp/dm-1402464464623632384-pipeline-1229318750780522496/lala:最新
上面的两个图像条目均显示拉拉:最新每个名称的末尾,表明这些是我们自己的恶意图像。值得注意的是,我们的恶意图像存储在不同的存储库中,代表同一图像的不同版本。
对于每个新部署,GCP 都会自动将映像上传到租户项目内的专用存储库中。尽管我们是在我们自己的部署上下文中运行(dm-2118255330398830592-管道-6604364906047209472),我们现在可以了解集群中存在的其他部署。
提取模型图像
虽然我们可以在 Kubernetes 集群中查看新创建的映像,但问题仍然存在,我们可以提取或拉取它吗?我们通过在 Kubernetes 上下文中检查该映像来确认该映像的存在。然而,为了检索有关图像的更多详细信息,我们使用 GCP 命令来描述它,如下图 15 所示。

这一步揭示了一个关键信息。虽然图像名称以拉拉:最新,我们无法成功使用该字符串最新的在我们的命令中,因为这不是有效的版本标识符。相反,我们的尝试返回了图像摘要,作为镜像版本的唯一标识符。
有了摘要,理论上我们可以提取图像,但过程并不简单。我们缺乏创建新容器的权限,并且由于 Docker 套接字未安装到我们的容器,因此我们无法使用 Docker 来提取映像。
相反,我们使用克里特尔,一个轻量级容器运行时接口 (CRI) 工具,与我们的 GCP 服务帐户身份验证令牌相结合。这允许我们使用容器的权限从容器外部提取图像在线预测服务帐户。
通过设置身份验证令牌在线预测服务帐户作为环境变量,我们能够使用图 16 中所示的命令提取图像。

提取这些图像后,我们可以列出结果,如图 17 所示。

拉取后,我们将图像导出到。焦油文件使用点击率,允许我们将它们移动并加载到其他地方。
切换上下文:探索其他集群
现在我们已经从第一个集群中收集了信息,是时候探索我们之前发现的其他集群了。由于我们可以访问获取集群凭证命令并且我们的 GCP 服务帐户已通过 IAM 工作负载联合身份验证绑定到集群,我们将上下文切换到集群 2,如下图 18 所示。

现在我们在集群 2 的上下文中进行操作。图 19 显示了集群 2 的命名空间。
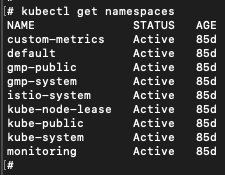
在这个集群中,预言命名空间不再存在。我们首先枚举 Pod 和容器。集群的大部分由默认的 Kubernetes 资源组成,我们发现具有预测服务器存储在我们的租户项目存储库中的名称,如图 20 所示:
- us-central1-docker.pkg.dev/s154574aecb0c9653-tp/ucaip-deployed-model-1558744649349201920/预测服务器:20231117_1325

在聚类 2 中,我们识别了一张这样的图像。以此为基础,我们在集群 1 中发现了另外两个镜像,其名称中具有相同的生产服务器字符串:
- us-central1-docker.pkg.dev/s154574aecb0c9653-tp/ucaip-deployed-model-1932543418420953088/预测服务器:20231117_1325
- us-central1-docker.pkg.dev/s154574aecb0c9653-tp/ucaip-deployed-model-6762636426589765632/预测服务器:20231117_1325
这些图像代表其他团队在我们的项目中创建的其他部署。令人惊讶的是,使用前面描述的相同方法,我们可以从其他集群下载这些图像。事实上,我们可以下载项目中所有已部署模型的图像。
Vertex AI 微调适配器层提取
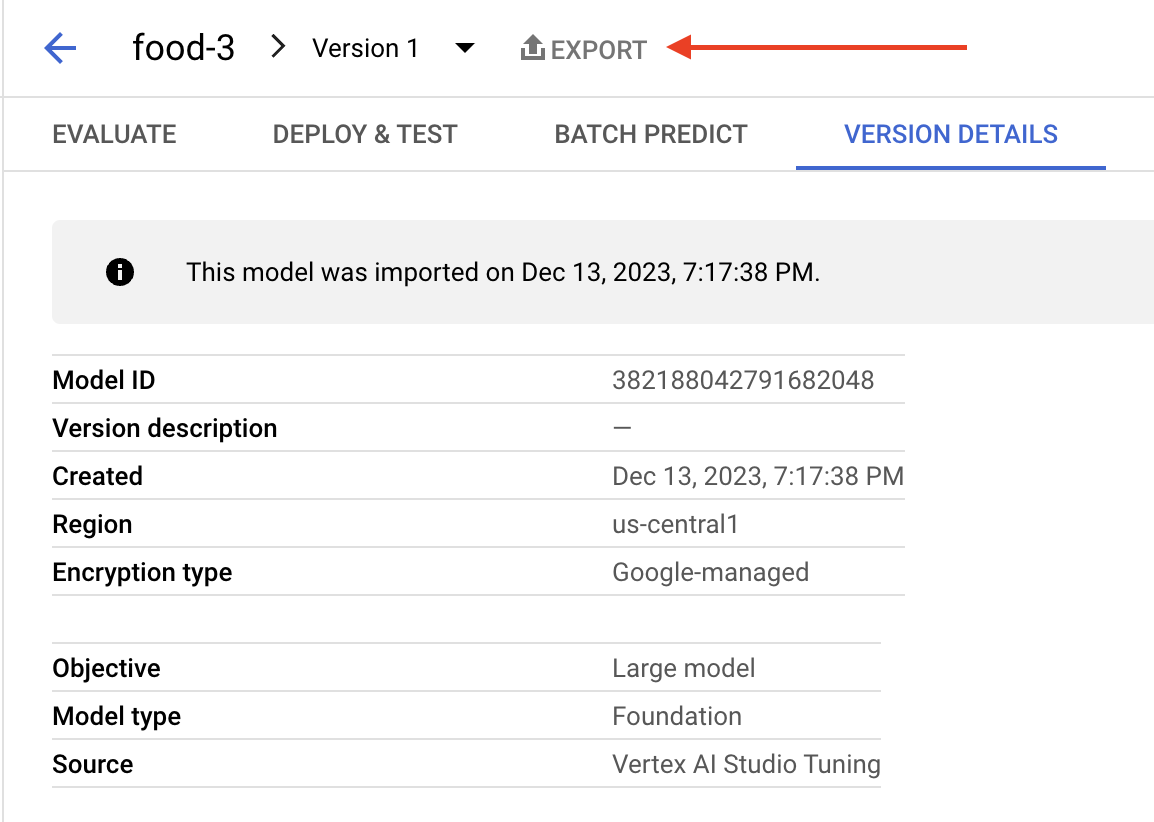
由于上述方法对于 ML 模型图像有效,因此我们还想访问基于 LLM 的 Vertex AI 模型。正如我们刚才演示的那样,ML 模型可以从 GCP 导出,但 LLM 模型在 GCP 中有更多限制。例如,图 21 显示了带有 LLM 模型的 GCP 面板的屏幕截图,其中导出功能呈灰色显示。
创建微调的 LLM 模型时,GCP 会添加一个称为适配器的微调层。该适配器层是由微调数据创建的附加权重。
通过列出租户项目中的所有存储桶,我们发现所有部署的模型都上传到那里。由于我们的 GCP 服务帐户具有查看者权限,因此我们不仅可以列出这些存储桶,还可以复制它们。在存储桶中,我们发现了类似于机器学习模型的目录结构。图22和图23显示这些桶标识符都以字符串开头蔡普。
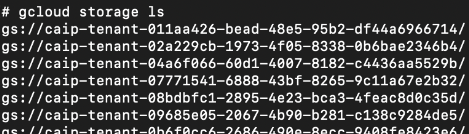
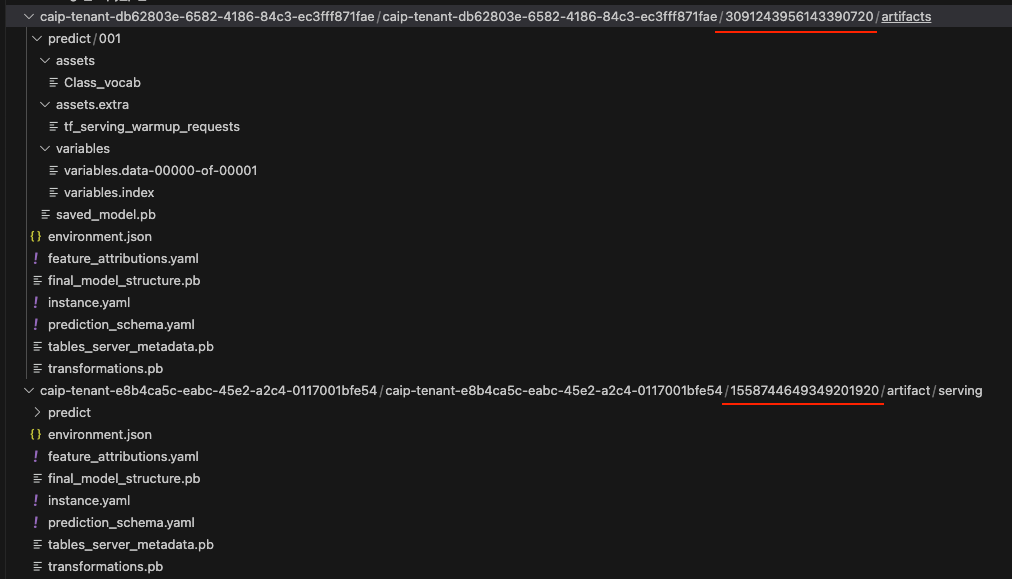
图 23 突出显示了存储桶路径中的两串数字,它们充当每个存储桶的已部署模型 ID。我们可以使用此信息将这些存储桶追溯到源项目模型注册表中的原始模型 ID。
使用图 23 中的第一个示例3091243956143390720,我们将此存储桶追溯到我们的源项目模型注册表,如下图 24、25 和 26 所示。
在图 24 中,我们的搜索显示了一个端点,其 ID 字符串与图 23 中列出的第一个存储桶中部署的模型 ID 相同。其正下方是关联的模型 ID。
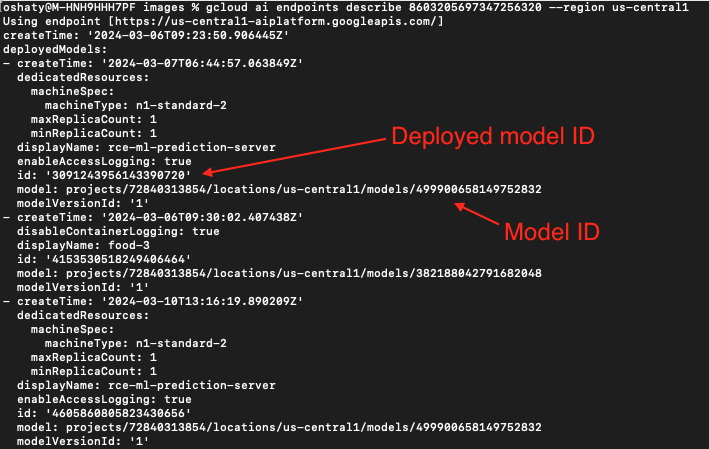
在图 25 中,我们以同一个部署的模型 ID 为基础来查找另一个关联的模型 ID。
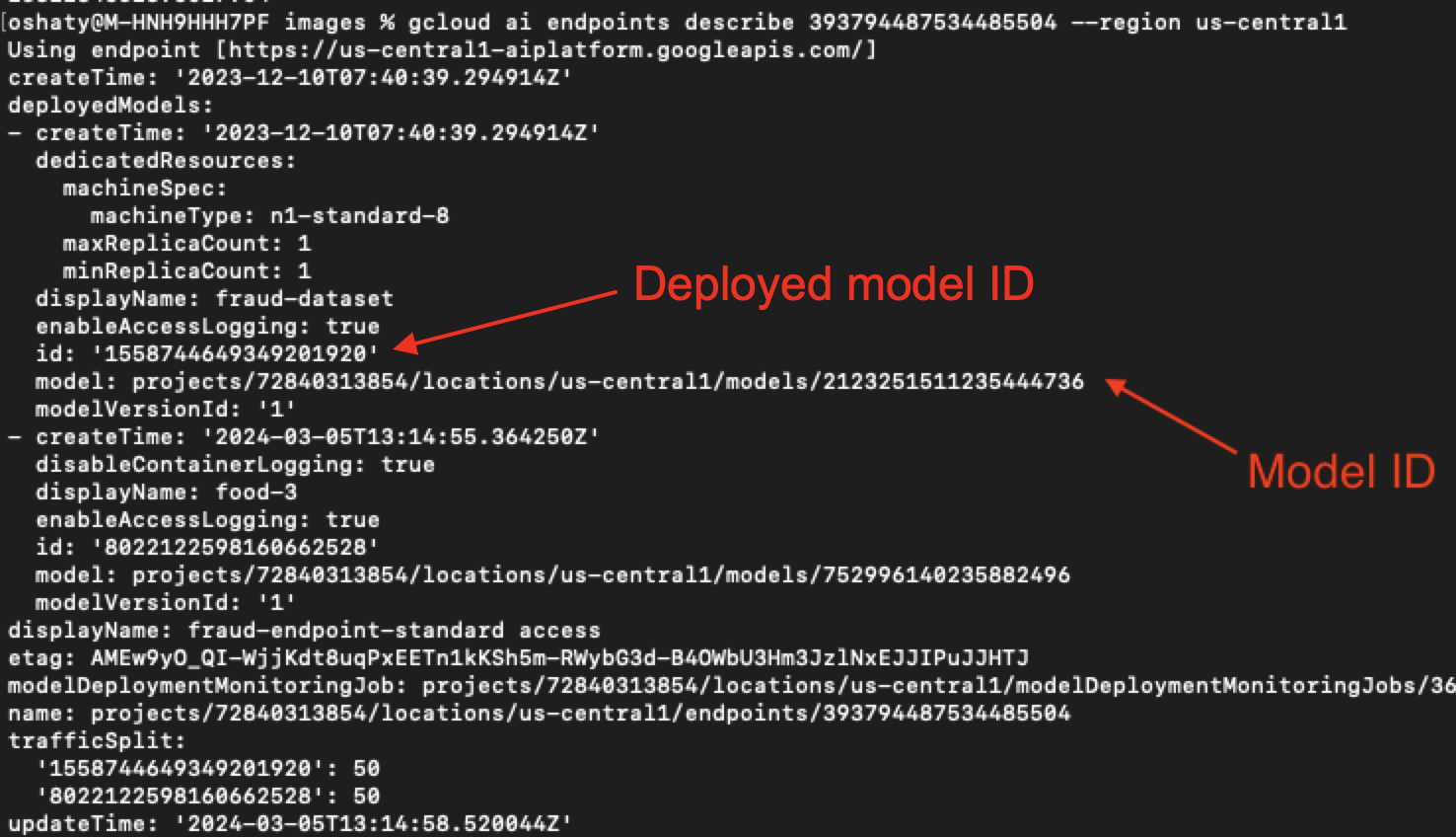
图 26 显示了当我们检查源项目时存在这些相同的关联模型 ID。
影响
我们发现我们拥有已部署到端点的所有机器学习模型。所以一开始我们有模型的所有图像,现在我们也有所有的 ML 模型。
更令人震惊的是,我们在这些存储桶中发现了适配器文件,如下图 27 所示。这些适配器文件是 LLM 模型微调过程的关键组成部分,它们包含直接改变基本模型行为的权重。
虽然图 27 中示例的名称是适配器.txt,内容不是可读的文本。然而,这些适配器文件的内容包含代表高度敏感的专有数据的权重,这使得它们成为攻击者的宝贵目标。

总之,通过部署恶意模型,我们能够访问租户项目中的资源,从而使我们能够查看和导出跨项目部署的所有模型。这包括 ML 和 LLM 模型,以及它们的微调适配器。
这种方法为模型到模型的感染场景带来了明显的风险。例如,您的团队可能在不知不觉中部署了上传到公共存储库的恶意模型。一旦活跃,它可能会泄露项目中的所有 ML 和微调的 LLM 模型,使您最敏感的资产面临风险。
图 28 中的流程图显示了使用以下步骤的此模型感染攻击的示例:
- 准备好中毒模型并将其上传到公共存储库
- 数据工程师下载并导入模型
- 模型已部署,授予攻击者访问权限
- 攻击者下载模型图像
- 攻击者下载经过训练的模型和LLM适配器层
结论
这项研究强调了单个恶意模型部署如何危害整个人工智能环境。攻击者甚至可以使用生产系统上部署的一个未经验证的模型来泄露敏感数据,从而导致严重的模型泄露攻击。
部署模型所需的权限可能看起来无害,但实际上,该单一权限可以授予对易受攻击项目中所有其他模型的访问权限。只有极少数人有权在没有严格监督的情况下在包含敏感或生产模型的项目中部署新模型。
为了防范此类风险,我们必须对模型部署实施严格的控制。基本的安全实践是确保组织的开发或测试环境与其实时生产环境分开。这种分离降低了攻击者在完全审查模型之前访问潜在不安全模型的风险。无论它来自内部团队还是第三方存储库,在部署之前验证每个模型都至关重要。
这凸显了迫切需要Prisma Cloud AI 安全态势管理(AI-SPM),帮助确保对人工智能管道进行强有力的监督。
如果您认为自己可能已受到威胁或有紧急事项,请联系Unit 42 事件响应小组或致电:
- 北美免费电话:866.486.4842 (866.4.UNIT42)
- 欧洲、中东和非洲:+31.20.299.3130
- 亚太地区:+65.6983.8730
- 日本:+81.50.1790.0200
Palo Alto Networks 已与我们的网络威胁联盟 (CTA) 成员分享了这些发现。CTA 成员利用这些情报快速为其客户部署保护措施,并系统地破坏恶意网络行为者。了解更多关于网络威胁联盟。Cyber Threat Alliance.