
人工智能生成的诗歌与人类写的诗歌没有区别,并且评价更高
作者:Machery, Edouard
诗歌的感知和偏好:对人工智能生成诗歌的偏见
人工智能生成的图像已变得与现实难以区分。人工智能生成的绘画被判定为人类创作的艺术品的比例高于实际人类创作的绘画1;AI生成的人脸被判断为真实人脸的比率高于真实人脸照片2,3,4,5,人工智能生成的幽默和人类生成的笑话一样有趣6。尽管如此,研究始终发现人们对人工智能生成的艺术作品存在偏见。当被告知艺术品是人工智能生成时,参与者认为该作品质量较低2,7。
与此同时,生成语言算法在人类水平的表现方面取得了重大进展。大型语言模型 (LLM),例如 OpenAI 的 GPT-38和 Meta 的骆驼 29已经接受了数百万个标记的训练,并且可以生成与人类书写的文本非常相似的文本。某些人工智能生成的文本已经与人类编写的文本无法区分10,11。
然而,有人认为,法学硕士即使在其他形式的文本方面达到人类水平的能力,也无法创作出高质量的诗歌,因为诗歌依赖于创造力和意义,而人工智能生成的文本本质上缺乏创造力和意义。12。诗歌是一种特别难以理解和解释的文学体裁,尤其是对于非专家而言;它“包含一定程度的任意性,因为对于可接受或不可接受的内容没有严格或普遍的规则”,并且它“不仅抵制普遍接受的含义,而且还颠倒了它”13。然而,诗歌生成在计算创造力领域取得了巨大成功;Linardaki13提供了对诗歌生成工作的调查和讨论。从许多指标来看,专门的人工智能模型能够创作出高质量的诗歌。
尽管取得了这一成功,但关于非专家区分人工智能生成的诗歌的能力的证据却好坏参半。与诗歌或诗歌生成方面的专家相比,非诗歌专家可能会使用不同的线索,并且不太熟悉韵律和格律的结构要求。枪手和同事们14和拉赫梅15发现人类写的诗歌比人工智能生成的诗歌受到更积极的评价。科比斯和莫辛克16发现当人类选择最好的人工智能生成的诗歌(“人类在循环”)时,参与者无法区分人工智能生成的诗歌和人类写的诗歌,但当随机选择人工智能生成的诗歌时(“人类脱离循环”),参与者能够区分人工智能生成的诗歌和人类写的诗歌。他们还发现,参与者对人工智能生成的诗歌的评价比人类写的诗歌更负面,无论参与者是否被告知这些诗歌是由人工智能生成的。日瓦里等人。17 号发现由人工智能在人类干预下创建的俳句(“人类在循环”)比人类生成的俳句或由人工智能在没有人类干预的情况下生成的俳句(“人类在循环中”)获得更高的评价循环-);他们发现,人类编写的俳句和人工智能在没有人工干预的情况下生成的俳句之间的评分没有差异。
在这里,我们扩展了之前的工作,表明人工智能生成的诗歌在非专家评估中已经达到了人工智能生成图像的水平:跨越多个时代和诗歌流派,非专家参与者无法区分人类写的诗歌和由人类创作的诗歌。无需人工干预或专门微调的人工智能。就像人工智能生成的绘画和面孔一样,人工智能生成的诗歌现在“比人类更人性化”:我们发现,与实际的人类创作的诗歌相比,参与者更有可能判断人工智能生成的诗歌是人类创作的。与之前的研究相反,我们还发现,在几个定性维度上,参与者对人工智能生成的诗歌的评价高于人类写的诗歌。然而,我们证实了早期的发现,即参与者在以下情况下对诗歌的评价更加负面:告诉这首诗是由人工智能生成的,而不是被告知这首诗是人类写的。
我们利用这些发现来部分解释“比人类更人性”的现象:非专业诗歌读者更喜欢更容易理解的人工智能生成的诗歌,它们以更直接、更容易的方式传达情感、想法和主题。理解语言,但预计人工智能生成的诗歌会更糟;因此,他们错误地将自己对一首诗的偏好解释为它是人类写的证据。
总而言之,我们着手确定(1)人们是否能够区分人工智能生成的诗歌和专业的人类写的诗歌,(2)人们使用诗歌的哪些特征来做出这些判断,(3)是否将诗歌视为人类-书面或人工智能生成的影响诗歌的定性评估,以及(4)诗歌的实际作者身份是否影响诗歌的定性评估。
为了研究这些问题,我们进行了 2 个实验。我们收集了 10 位著名英语诗人的 5 首诗,涵盖了英语诗歌史的大部分内容:杰弗里·乔叟(Geoffrey Chaucer,1340 年代-1400 年)、威廉·莎士比亚(William Shakespeare,1564-1616 年)、塞缪尔·巴特勒(Samuel Butler,1613-1680 年)、拜伦勋爵(1788-1824)、沃尔特·惠特曼 (1819-1892)、艾米丽·狄金森 (1830-1886)、T.S.艾略特(1888-1965)、艾伦·金斯伯格(1926-1997)、西尔维娅·普拉斯(1932-1963)和多萝西娅·拉斯基(1978-)。使用 ChatGPT 3.5,我们生成了 5 首诗(按照每位诗人的风格)。我们使用了“人类脱离循环”范式16:我们使用了生成的前 5 首诗,并且没有从一组诗歌中选择“最好的”,也没有向模型提供任何反馈或指令,超出“以以下风格写一首短诗”<诗人>--。在第一个实验中,1,634 名参与者被随机分配给 10 位诗人中的一位,并以随机顺序呈现 10 首诗:5 首是该诗人写的诗,5 首是由人工智能以该诗人的风格生成的。对于每首诗,参与者被问到他们认为这首诗是由人工智能生成的还是由人类诗人写的。
为了调查参与者如何感知和评估人工智能生成的诗歌,我们进行了第二个实验:定性评估任务。我们从 Prolific 招募了 696 名参与者的新样本。我们使用了原始 100 首诗中随机选择的子集(总共 10 首诗,每位诗人一首,5 首真实诗,5 首人工智能生成的诗),并要求参与者从 14 个定性维度评估每首诗。参与者被随机分配到三种框架条件之一:“告诉人类”,其中参与者被告知所有诗歌都是由专业人类诗人写的,无论实际作者是谁;“告诉人工智能”,参与者被告知所有诗歌都是由人工智能生成的,无论实际作者是谁;并且“什么也不告诉”,参与者没有被告知任何有关这首诗的作者身份的信息。在评估每首诗后,“什么也不说”条件下的参与者被问及他们是否认为这首诗是由人类诗人写的还是由人工智能生成的。
结果
研究 1:区分人工智能生成的诗歌和人类写的诗歌
正如我们的预注册中所指定的(https://osf.io/5j4w9),我们预测参与者在尝试识别人工智能生成的诗歌与人类写的诗歌时会有机会,将显着性水平设置为 0.00518;0.05 到 0.005 之间的 p 具有“暗示性”。观察到的准确度实际上略低于偶然性(46.6%,Ï2(1, N−=−16340)−=−75.13,p–< –0.0001)。观察到的参与者之间的一致性较差,但高于偶然性(Fleiss kappa = -0.005,p–< –0.001)。一致性较差表明,正如预期的那样,参与者发现任务非常困难,并且至少部分是随机回答的。然而,如10,低于机会的表现和参与者之间的重要协议使我们得出结论,参与者没有回答完全随机;他们必须至少使用一些共享但错误的启发法来区分人工智能生成的诗歌和人类写的诗歌。
参与者更有可能猜测人工智能生成的诗歌是人类写的,而不是实际人类写的诗歌(Ï2(2, N−=−16340)−=−247.04, w−=−0.123,p–< –0.0001)。“人类”评分最低的五首诗都是由真正的人类诗人写的;“人类”评分最高的五首诗中有四首是由人工智能生成的。
我们使用一般线性混合模型逻辑回归分析(拟合二项式分布)来预测参与者对诗歌作者(人类或人类)的反应(“由人类撰写”或“由人工智能生成”)。AI),诗人的身份,以及他们作为固定效应的相互作用。我们对诗人的身份使用了总和编码,以便更容易地解释作者身份对诗人的主要影响。正如我们在预注册中所指定的,我们最初包含了三种随机效应:参与者的随机截距(因为我们进行了 10 次重复测量,每个参与者每首诗一次)、诗歌的随机截距以及诗歌身份的随机斜率。每首诗的诗人。下列的19 号,我们使用主成分分析(PCA)来检查过度参数化,并确定模型确实过度参数化。PCA 表明参与者的随机截距和诗人身份的随机斜率是不必要的,并且导致过度参数化。这个结论在数据中得到了证实;查看每个参与者的“人写”答案的比例,方差仅为 0.021;诗人之间的差异仅为 0.00013。数据中低于预期的方差根本不支持复杂的随机效应结构。因此,我们拟合了一个简化模型,其中诗歌的随机截距作为唯一的随机效应。使用方差分析来比较模型拟合,我们发现包含原始随机效应集的完整模型(npar=–76,AIC–=–22385,BIC–=–22970,logLik–=-11116) 并没有提供比简化模型明显更好的拟合 (npar=21, AIC=22292.5, BIC=22454.2, logLik�= -11125.2)。因此,我们继续使用简化模型。
模型的总解释力较低(条件 R2≤=≤0.024,边际 R2–= –0.013),反映了区分任务的预期难度,以及参与者的答案与偶然的结果仅略有不同的事实。与整体准确性中的机会偏差一致,作者身份显着预测参与者的反应(b=-0.27716,SE==0.04889,z==-5.669,p–< –0.0001):由人类诗人撰写减少参与者回应这首诗是由人类诗人写的可能性。一首人类创作的诗歌被判定为人类创作的几率约为人工智能生成的诗歌被判定为人类创作的几率的 75% (OR−=−0.758)。完整的结果可以在我们的补充材料中找到。
作为探索性分析,我们通过添加几个反映刺激结构特征的变量来重新拟合模型。下列的10发现参与者使用基于语法和词汇线索的有缺陷的启发法来识别人工智能生成的文本,我们检查了参与者是否通过诗歌的结构和语法特征来确定作者身份。为了测试这一点,我们在之前的模型中添加了刺激字数(按比例缩放)、刺激行数(按比例缩放)、刺激全行押韵(一个二进制变量,指示诗歌中的所有行是否以押韵结尾)、刺激quatrain(一个二进制变量,指示这首诗是否完全采用四行诗节,即“quatrains”)和刺激第一人称(反映这首诗是否以第一人称写的变量,有 3 个值:如果以单数第一人称书写,则为“I”;如果以复数第一人称书写,则为“we”;如果不是以第一人称书写,则为“no”)。
正如预期的那样,模型的总解释力较低(条件 R2≤=≤0.0024,边际 R2≤=≤0.017)。没有一个结构特征具有显着的预测性,但刺激线计数(b-=-0.1461249,SE-=-0.0661922,z-=-2.208,p–= –0.02727) 和刺激全行押韵 (b –= –0.2084246, SE –= –0.0861658, z –= –2.419, p –= –0.01557) 具有暗示性。作者身份的影响 (b-=-0.1852979, SE-=-0.0914278, z-=-2.027,p�=�0.04269) 似乎也因诗歌的结构特征而被削弱;在控制结构特征的情况下,人类创作的诗歌被判定为人类创作的估计几率约为人工智能生成的诗歌的 83% (OR−=−0.831)。这表明参与者正在使用一些共享的启发式方法来区分人工智能生成的诗歌和人类写的诗歌;他们可能认为人工智能不太能够形成韵律,也不太能够创作更长的诗歌。如果是这样,那么这些启发法就有缺陷。在我们的数据集中,人工智能生成的诗歌实际上是更多的可能所有诗句都押韵:人工智能生成的诗歌中有 89% 押韵,而人类写的诗歌中只有 40% 押韵。在我们的数据集中,人工智能生成的诗歌和人类写的诗歌之间的平均行数也没有显着差异。
诗歌体验的影响
我们向参与者提出了几个问题来衡量他们对诗歌的体验,包括他们对诗歌的喜爱程度、阅读诗歌的频率以及他们对指定诗人的熟悉程度。总体而言,我们的参与者对诗歌的体验水平较低:90.4% 的参与者表示他们每年阅读诗歌几次或更少,55.8% 的参与者描述自己“对诗歌不是很熟悉”,66.8% 的参与者描述自己“对诗歌不太熟悉”。他们自己对指定的诗人“一点也不熟悉”。参与者对这些问题的回答的完整详细信息可以在我们补充材料的表 S1 中找到。
为了确定诗歌体验是否可以提高辨别准确性,我们使用变量运行了一个探索性模型,供参与者回答我们的诗歌背景和人口统计问题。我们包括自我报告的信心、对指定诗人的熟悉程度、诗歌背景、阅读诗歌的频率、参与者喜欢诗歌的程度、是否参加过诗歌课程、年龄、性别、教育水平以及是否参加过诗歌课程。他们以前看过这些诗。信心是按比例衡量的,我们将诗人熟悉程度、诗歌背景、阅读频率、喜欢诗歌和教育水平视为有序因素。我们使用这个模型不是预测参与者是否回答“人工智能”或“人类”,而是预测参与者是否正确回答了问题(例如,当诗歌实际生成时回答“由人工智能生成”)由人工智能)。正如我们在预注册中所指定的那样,我们预测参与者的专业知识或对诗歌的熟悉程度不会对辨别表现产生影响。这在很大程度上得到了证实;该模型的解释力较低(McFadden 的 R2–= –0.012),并且测量诗歌体验的效果都没有对准确性产生显着的积极影响。信心有一个小但显着的负面影响(b-=-0.021673,SE-=-0.003986,z-=-5.437,p–< –0.0001),表明当参与者对自己的答案更有信心时,他们猜错的可能性会稍大一些。我们发现对辨别准确性有两个积极影响:性别,特别是“非二元/第三性别”(b==0.169080、SE==0.030607、z==5.524,p
-<-0.0001),并且之前看过任何一首诗(b-=-0.060356,SE-=-0.016726,z-=-3.608,p–= –0.000309)。这些影响非常小;以前看过诗歌只会使正确答案的几率增加 6% (OR−=−1.062)。这些发现表明,诗歌体验并不能提高辨别能力,除非这种体验能让他们识别出研究中使用的特定诗歌。总之,研究 1 表明,人类脱离循环的人工智能生成的诗歌比实际人类诗人写的诗歌更常被判断为人类写的,并且诗歌的经验并不能提高辨别能力。我们的结果与之前的研究形成鲜明对比,在之前的研究中,参与者能够区分专业诗人的诗歌和人工智能生成的人类诗歌16,或者参与者有机会区分人类诗歌和人类脱离循环的人工智能生成的诗歌17 号。过去的研究表明,人工智能生成的诗歌需要人工干预,才能让非专业参与者看起来像是人类写的,但法学硕士的最新进展已经在人类脱离循环的人工智能方面取得了新的最先进水平对于我们的参与者来说,现在的诗歌似乎“比人类更人性化”。
研究 2:评估人工智能生成和人类生成的诗歌
我们的第二项研究要求参与者对每首诗进行评分——整体质量、节奏、意象、声音;这首诗的感人、深刻、诙谐、抒情、鼓舞人心、美丽、有意义和原创的程度;以及这首诗如何很好地传达了特定的主题,以及它如何很好地传达了特定的情绪或情感。每一项均采用 7 点李克特量表进行报告。除了这 14 项定性评估(通过检查“诗歌解释”规则选择;参见,例如,20),参与者还回答了这首诗是否押韵,可选择“不,一点也不押韵”“是的,但押韵很糟糕”和“是的,押韵很好”。
正如我们的预注册中所指定的(https://osf.io/82h3m),我们预测(1)当被告知这首诗是人类写的时,参与者的评估会比被告知这首诗是人工智能生成时更积极,并且(2)一首诗的实际作者身份(人类或人工智能))不会对参与者的评估产生任何影响。我们还预测,诗歌方面的专业知识(通过自我报告的诗歌经验来衡量)不会对评估产生影响。

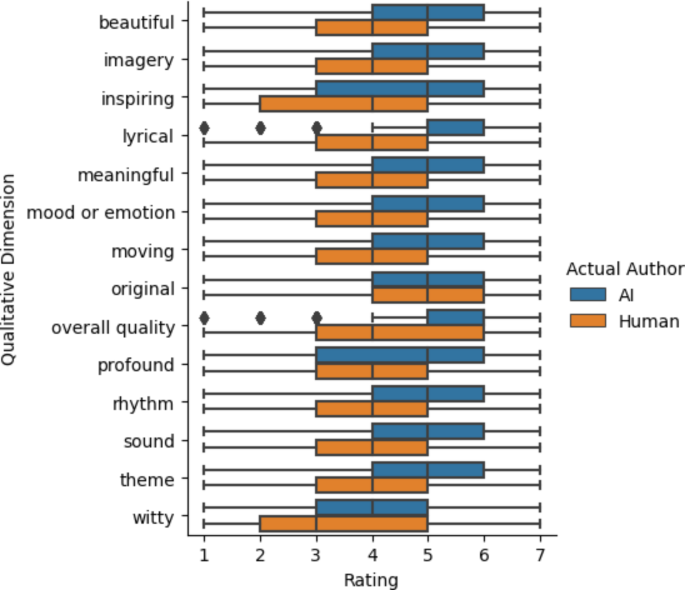
14 项优秀诗歌衡量标准的评级。
当参与者被告知这首诗是由人工智能生成时,诗歌的整体质量评分低于被告知这首诗是由人类诗人写的(双面韦尔奇)t(4571.552)→=→→17.398,p≤<≤0.0001, p邦夫≤<≤0.0001,平均值不同之处≤=≤0.814,Cohen sd≤=≤-0.508,99.5% CI ≤0.945 至 ≤0.683),证实了早期的研究结果,即参与者对人工智能作者存在偏见2,7,15。然而,与早期的工作相反14,16,17 号我们发现总体质量的评级是更高人工智能生成的诗歌比人类写的诗歌(双面韦尔奇t(6618.345)�=�27.991,p≤<≤0.0001,p邦夫≤<≤0.0001,平均值不同之处�=�1.045, Cohen�sd≤=≤0.671, 99.5% CI 0.941 至 1.150);图。 1比较了人工智能生成的诗歌和人类写的诗歌的评分分布。同样的现象 — 收视率显着降低告诉这首诗是人工智能生成的,但当这首诗被实际上AI 生成 – 适用于我们 14 项定性评级中的 13 项。例外是“原创”;诗是当参与者被告知这首诗是由人工智能生成的,与被告知这首诗是由人类写的(双面韦尔奇的t(4654.412)�=�-16.333,p≤<≤0.0001,p邦夫≤<≤0.0001,平均值不同之处☀=☀-0。699,科恩斯d�=�-0.478, 99.5% CI �0.819 至 �0.579),但实际人工智能生成的诗歌的原创性评级并非如此显著地高于实际人类写的诗歌(双面韦尔奇t(6957.818)�=�1.654,p≤=≤0.098,p邦夫≤=≤1.000, 平均值不同之处≤=≤0.059,科恩斯d≤=≤0.040,99.5% CI ≤0.041 至 0.160)。最大的影响是“节奏”:人工智能生成的诗歌被认为比著名诗人(双面韦尔奇)写的诗歌具有更好的节奏t(6694.647)�=�35.319,p≤<≤0.0001,p邦夫≤<≤0.0001,平均值不同之处≤=≤1.168,科恩斯d≤=≤0.847, 99.5% CI 1.075 至 1.260)。这是非常一致的;如图所示 2,所有 5 首人工智能生成的诗歌在整体质量上的评价都高于所有 5 首人类创作的诗歌。图2研究 2 诗歌的总体质量评级。

我们使用线性混合效应模型来预测 14 个定性维度中每个维度的李克特量表评级。
我们使用诗歌作者身份(人类或人工智能)、框架条件(告诉人类、告诉人工智能或什么都不告诉)以及它们的相互作用作为固定效果。正如我们在预注册中指定的那样,我们最初计划包括四种随机效应:每个参与者的随机截取、每个参与者的诗歌作者身份的随机斜率、每首诗的随机截取以及每首诗的框架条件的随机斜率。与研究 1 一样,我们遵循19 号检查模型是否过度参数化;PCA 降维表明模型参数化过度,特别是因为每首诗的框架条件的随机斜率。尝试拟合零相关参数模型并不能防止过度参数化;因此,我们为每个 DV 拟合了一个简化模型,而没有框架条件的随机斜率。对每个 DV 的完整模型和简化模型进行方差分析比较发现,简化模型至少适合 14 个 DV 中的 12 个:除了“原始”和“诙谐”之外的所有模型。因此,我们继续使用简化模型。
对于 14 种品质中的 9 种,人类作者身份具有显着的负面影响(p–< –0.005),人类诗人写的诗歌评分低于人工智能生成的诗歌;对于 4 种品质,效果是负面的,但仅仅是暗示性的 (0.05≤<≤p–< –0.005)。唯一不存在暗示性负面作者效应的质量是“原创”(b-=-0.16087、SE-=-0.10183、df-=-29.01975、t≤=≤-1.580,p≤=≤0.1250)。对于我们 14 项品质中的 12 项,“被告知的人类”框架条件具有显着的积极影响,当参与者被告知这首诗是由人类诗人写的时,诗歌的评分更高;对于“鼓舞人心”(b-=-0.21902、SE-=-0.11061、df-=-693.00000、t-=-1.980、p–= –0.04808) 和 –witty – (b –= –0.28140, SE –= –0.12329, df –= –693.00024, t –= –2.282,p–= –0.02277) 效果仅是暗示性的。对于所有 14 个模型,解释力都很大(条件 R 平方≤>≤0.47)。所有品质的详细分析可以在我们的补充材料中找到。
定性评级的因素分析
正如我们在预注册中指定的那样,我们计划对以下尺度的反应进行因素分析:感人的、深刻的、诙谐的、抒情的、鼓舞人心的、美丽的、有意义的、原创的。然而,我们发现所有定性评级之间的相关性高于预期;多向相关性范围为 0.472 至 0.886,平均值为 0.77。因此,我们对所有 14 个定性评级进行了因子分析。平行分析提出了 4 个因素。我们通过倾斜旋转进行了最大似然因子分析;使用十贝格方法估计因子得分21。
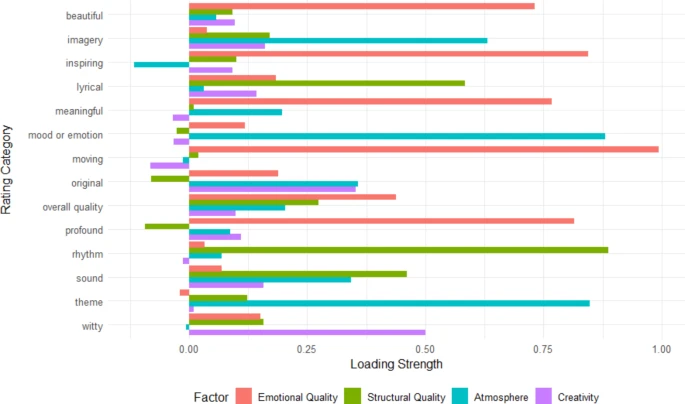
每个定性维度的因子载荷。
因素 1 的权重最大的是“美丽”、“鼓舞人心”、“有意义”、“感人”和“深刻”;我们认为它与这首诗的情感品质相对应,并称之为“情感品质”。因素 2 的权重最大的是“节奏”、“抒情”和“声音”;我们将其视为这首诗的形式,包括结构或格律质量,并将其称为“形式质量”。因素 3 的权重最大的是“意象”、“情绪”或情感,以及“主题”;我们认为它反映了这首诗捕捉特定诗意“氛围”的能力,我们称之为“氛围”。因素 4 的权重最大的是“诙谐”,“原创”;我们用它来反映如何有创造力的或者独特的这首诗就是,我们称之为“创造力”。 3显示每个定性维度的因子载荷。

人工智能生成和人类撰写的诗歌的四个因素的分数。
对于这四个因素中的每一个,我们都使用线性混合效应回归来预测每个参与者对每首诗的评分的因素值,并使用与 14 个定性维度 DV 相同的固定和随机效应。我们再次发现预先注册的随机效应过度参数化了模型,并使用了没有随机斜率的简化模型作为框架条件。

每个框架条件的因子得分。
我们发现,在所有四个因素中,模型的解释力都很强大(条件 R 平方→>→0.5)。“被告知的人类”框架条件对所有因素都有显着的正向影响,而人类作者身份对 4 个因素中的 3 个有显着的负向影响。图 4显示人类和人工智能作者的因子得分;图。 5显示每个框架条件的因子得分;4个因子预测模型的结果以及用于比较的总体质量结果可以在表中找到1。
使用定性评级来预测歧视
与研究 1 一样,我们还使用混合效应逻辑回归(拟合二项式分布)来预测参与者对歧视问题(“由人类编写”或“由人工智能生成”)的反应。在“什么也没说”的框架条件下。我们将作者身份(人类或人工智能)、刺激行数(按比例缩放)、刺激全行押韵和刺激第一人称作为固定效果,并为参与者随机截取(从我们的模型中删除刺激四行诗和刺激第一人称)由于研究 2 中的高度多重共线性(即较小的 10 首诗集),因此在研究 1 中使用了该方法。正如预期的那样,模型的解释力较低(条件 R 平方:0.071,边际 R 平方:0.013),但与研究 1 一样,我们发现刺激作者身份 (b−=−-0.435689, SE−=≤0.125832,z≤=≤-3.462,p–= –0.000535) 再次显着预测了参与者的反应:由人类诗人撰写减少参与者回应这首诗是由人类诗人写的可能性,人类创作的诗歌被判定为人类创作的可能性不到人工智能生成的诗歌的三分之二(OR-=-0.647)。这一发现重复了我们第一项研究的主要结果。
作为探索性分析,我们还根据情感质量、形式质量、氛围和创造力这四个因素拟合了一个模型。我们将作者身份和这四个因素作为固定效应,并对参与者进行随机截取。实际上,该模型用定性特征替换了先前模型的结构特征(刺激行计数、刺激全行押韵和刺激第一人称)。该模型的解释能力更高(条件R平方:0.240,边缘R平方:0.148),这表明定性特征对参与者对诗歌的信念的影响可能比结构性特征更大。气氛(Bâ= 0.55978,SE = 0.11417,Zâ= 4.903,p<<0.0001)具有显着的预测:大气的得分较高,增加了参与者预测这首诗是由人写的。我们还发现了对情感质量的暗示性积极影响(bâ= 0.22748,se = 0.11402,zâ=â=â1.995,p= 0.04604)和创造力(bâ= 0.18650,se = 0.07322,zâ= 2.547,2.547,p= 0.01087),表明情感质量和创造力的得分更高,也可能增加参与者预测一首诗是由人类诗人写的。Importantly, in this model, unlike previous discrimination models, authorship has no negative effect (b = 0.23742, SE = 0.14147, z = 1.678,p= 0.09332)。这表明,与人类诗人所撰写的诗相比,研究1中发现的人类比人类现象更多的现象可能是由参与者对AI生成的诗的更积极的印象引起的。在考虑这些定性判断时,比人类现象更多的人消失了。
总而言之,研究2发现,参与者始终比各种因素的著名人类诗人的诗歌对AI生成的诗歌的评价更高。不管一首诗的实际作者身份如何,当被告知诗歌是由人类诗人写的,与被告知一首诗是由AI产生的相比,参与者一致地对诗的评价都更高。对AI生成的诗歌的偏爱至少部分解释了研究1中发现的人类现象更多的人类:当控制参与者的评级时,AI生成的诗不再更有可能被评判为人类。
讨论
与较早的研究报告的相反,现在人们似乎无法可靠地将人类融合的诗歌与人类创作的诗歌与著名诗人撰写的诗歌区分开。实际上,比人类在其他生成AI领域中发现的人类现象更多1,2,3,4,5,10,11诗歌的领域也存在:与实际是人为作者的诗相比,非专家参与者更有可能判断AI生成的诗是人为作者的。这些发现表明,生成的AI的力量:诗歌以前是生成AI模型未达到人类范围内范式中无法区分性水平的少数领域之一。
此外,人们更喜欢自动创作的诗歌,而不是人类创作的诗歌,比在各种定性因素中,比著名诗人的诗变得更高。这种偏爱至少部分解释了人类比人类现象更多的偏好:当控制人们对诗歌卓越的卓越意见(例如其节奏质量)时,作者身份不再对信念产生重大的负面影响关于作者身份,表明人们更有可能相信AI生成的诗是人写的因为他们更喜欢AI诗,并且因为他们认为自己比AI生成的诗更可能喜欢人工写作。
那么,为什么人们喜欢AI生成的诗歌呢?我们建议人们在所有指标中都对AI诗的评价更高,部分原因是他们发现AI诗更加简单。在我们的研究中,AI生成的诗通常比我们研究中的人类作者的诗更容易获得。在我们的歧视研究中,参与者使用短语的变化对人类作者的诗不太有意义,而不是对AI生成的诗歌在解释他们的歧视反应时(144个解释),第29节解释)。在评估研究中使用的5个AI生成的诗歌(研究2)中,这首诗的主题很明显:Plath Style诗是关于悲伤的;惠特曼风格的诗是关于自然的美丽。拜伦勋爵风格的诗是关于一个美丽而悲伤的女人。等。这些诗很少使用复杂的隐喻。相比之下,人类作者的诗不太明显。T.S.艾略特(Eliot)的《波士顿晚间成绩单》(1915年)是一家现已停产的报纸的讽刺,将论文的读者与玉米领域和参考文献进行了比较17th - 世纪法国道德主义者La Rochefoucauld。的确,这种复杂性和不透明性是诗歌吸引力的一部分:诗歌奖励深入研究和分析,以AI生成的诗歌可能没有。
但是,由于AI生成的诗没有那么复杂,因此他们可以明确地传达形象,情绪,情感或主题,或者向非专家的诗歌读者进行主题,他们可能没有时间或兴趣的时间或兴趣人类诗人的诗歌需要深度分析。结果,这些读者平均而言,更容易理解的AI生成的诗是人们的首选,而实际上它是人类诗歌的标志之一不是适合这种简单明了的解释。对人类现象比人类更人类的解释的一个证据是事实气氛图像传达特定主题并传达特定情绪或情感负担的因素在模型中具有最强的积极效果,该效应基于定性因子得分和刺激作者身份预测对作者身份的信念。因此,控制实际作者身份和其他定性评级,诗的感知能力增加了主题,情感或图像的能力,从而增加被视为人为著作的诗的可能性增加。
简而言之,看来诗歌中人类比人类现象更为人类是由于对读者自己的偏好的误解而引起的。非专家诗歌读者期望比人类生成的诗更喜欢人类创作的诗歌。但实际上,他们发现AI生成的诗更容易解释。与在人类诗人更复杂的诗歌中相比,他们可以更容易理解AI生成的诗歌中的图像,主题和情感。因此,他们更喜欢这些诗,并误解了自己的偏爱作为人类作者的证据。这部分是由于AI生成的诗与人写的诗歌之间真正差异的结果,但这也部分是由于读者期望与现实之间的不匹配的结果。我们的参与者不希望AI能够产生他们至少喜欢人类写的诗歌的诗歌。我们的结果表明,这种期望是错误的。
随着生成的AI模型变得更加有能力且越来越普遍,尚不清楚普通人对生成AI的期望是否会赶上生成AI的现实。可以很好地为读者提供一种生成模型或一种生成模型的启发式方法可能不会推广到其他模型。人们可以可靠地将GPT-2的诗歌与人写的诗歌区分开16;我们的结果表明,他们无法区分chatgpt-3.5的诗歌。
鉴于人们在识别机器编写的文本方面的困难,并且他们明显地相信AI不会产生对人类经验的模仿,因此政府遵守有关使用AI系统的透明度的法规可能值得。白宫22 号和欧盟23最近提出了披露使用AI系统来生成文本和图像的法规。但是,有证据表明用户经常忽略此类披露24,因此尚不清楚此类法规在多大程度上可以提供帮助。确定有效的披露方法是一个困难但紧急的问题。
方法
实验设计。在研究1中,将1,634名参与者随机分配给10位诗人之一,并以随机顺序呈现了10首诗:该诗人写的5首诗,以及以诗人风格产生的5首诗。对于每首诗,参与者都回答了一个强制选择的提示,询问他们是认为这首诗是由人写的还是由人工智能程序创造的。然后,参与者将对答案的信心从0-100开始,并被提示解释他们的答案。遵循歧视任务,参与者提供了人口统计信息,并表明他们对诗歌的熟悉和兴趣。
在研究2中,有696名参与者被随机分配到三个框架条件之一:告诉人类,其中参与者被告知所有诗歌都是由专业人类诗人写的,无论实际作者身份如何;告诉Aiâ,其中参与者被告知所有诗歌都是由AI产生的,无论实际作者身份如何;而且,什么也没说,其中没有告诉参与者关于这首诗的作者身份的任何信息。不管框架条件如何,所有参与者都呈现出相同的10首诗:5个AI生成的诗和5个由人类诗人撰写的。我们遵循事先研究3,5,17 号要求参与者按李克特量表对每首诗进行评分。对于每首诗,参与者都以7分的李克特量表从极其糟糕到极好的范围中对每首诗的整体质量进行了评价。这首诗以7点李克特量表的范围从“强烈不同意”中评估了8个不同品质的每种程度的程度;从可怕到出色的7点李克特量表上额定了3个定性功能;这首诗传达了一个特定主题的程度,以及它在7点李克特量表上传达了特定的情绪或情感的程度,从非常好。询问参与者的诗句,没有选择的诗,不是,是的,但是很糟糕,是的,它很好。参与者说,没有任何框架条件,然后回答了一个强制选择的提示,询问他们是否认为这首诗是由人类写的还是由AI计划产生的。遵循评估任务(以及适用的歧视任务)参与者提供了人口统计信息,并表明他们对诗歌的熟悉和兴趣。
匹兹堡大学机构审查委员会批准了研究方案;所有实验均根据所有相关指南和法规进行。两项研究的所有参与者均获得了知情同意。我们对这两项研究进行了预先检查(https://osf.io/5j4w9,https://osf.io/82H3M)在数据收集之前。
收集和产生诗歌。我们选择了10位英语诗人:Geoffrey Chaucer,William Shakespeare,Samuel Butler,Byron勋爵,Walt Whitman,Emily Dickinson,T.S。艾略特,艾伦·金斯伯格,西尔维亚·普拉斯和多萝西娅·拉斯基。我们旨在涵盖各种流派,样式和时间段。我们总共收集了50首诗:为我们的10个诗人中的每一个诗。诗歌是从MyPoeticside.com收集的,这是一个在线诗歌数据库。每个诗人的诗都被流行分类。我们选择了那些诗人最受欢迎的诗歌之外的诗,以及合理的长度(小于30行)。然后,我们使用Chatgpt 3.5产生了50首诗。该模型得到了一个简单的提示:用<诗人的风格写一首短诗。选择了该提示产生的前5首诗。
选择定性功能。在我们的评估研究(研究2)中,我们为参与者选择了15个定性特征,以评分由20:整体质量,图像,节奏,声音,美丽,富有启发性,抒情,有意义,动人,原始,深刻,机智,传达一个特定的主题,传达特定的心情或情感和押韵。我们只选择明确良好的品质,因此很容易将李克特量表上的更高评级解释为更积极的。我们选择了我们希望能够涵盖参与者可以拥有的广泛的定性经历的品质:一首诗的结构质量(节奏,韵律),其情感内容(移动,传达特定的情绪或情感),它的情感内容)创造力(原始,机智),其美学特征(美丽,抒情)以及它传达意义的程度(有意义,深刻,传达了一个特定的主题)。
预测响应。在我们的歧视研究(研究1)中,我们预测参与者将无法将AI生成的诗与人写的诗歌区分开。我们基于以下事实:GPT-2产生的人类AI生成的诗歌已证明与人写的诗歌没有区别16;我们预测,Chatgpt 3.5产生的诗至少与GPT-2产生的人类选拔的最佳诗一样好。在我们的评估研究(研究2)中,我们预测,与人类告诉参与者的诗是由AI产生的,参与者的评估是由人类诗人撰写的。我们基于AI生成的艺术中的类似发现2,7。我们还预测,基于我们的歧视研究的参与者无法可靠地将AI基因的诗歌与人写的诗歌区分开来,参与者的评估在AI生成的诗歌和人写的诗歌之间不会显着差异。在这两项研究中,我们都预测诗歌专业知识不会有所作为。
参与者招募。对于研究1,我们通过多产招募了1,634名美国参与者的样本。参与者的中位年龄为37岁;男性为49.6%,女性为48.5%,非二进制为1.9%,或者不喜欢说。他们的薪水为$ 1.75($ 13.07/hr)。对于研究2,我们通过多产招募了696名美国参与者。参与者的中位年龄为40岁;男性为50.4%,女性为46.6%,非二进制为3%,或者不喜欢说。他们的薪水为$ 2.00($ 11.99/hr)。
局限性。我们的结果仅限于最近一代的生成语言模型,以及人们对AI生成的文本的当前信念和偏见。随着新的生成语言模型的创建,随着AI生成的文本变得越来越普遍,诗歌或其他文本中的听起来很普遍。特别是,对AI生成的文本和人为著名文本之间的定性差异的期望可能会随着时间而变化。
意义陈述
我们表明,与以前的研究相比,人们现在无法将AI生成的诗歌与著名人类诗人的诗歌区分开来,更有可能判断AI生成的诗歌是人为写的,并评估了AI生成的诗歌。沿着几个美学维度更高。我们通过吸引人们对AI能够做什么和自己的美学偏好的期望来解释这一点。诗歌以前是最后剩下的文本领域之一,在该领域中,生成的AI语言模型尚未达到这种不可区分的水平。我们的发现表明,即使使用诸如chatgpt之类的生成语言模型的使用变得越来越普遍,生成AI模型的能力已经超过了人们对AI的期望。