
剧透警告:RAG 的魔力并非来自 AI
作者:Frank Wittkampf
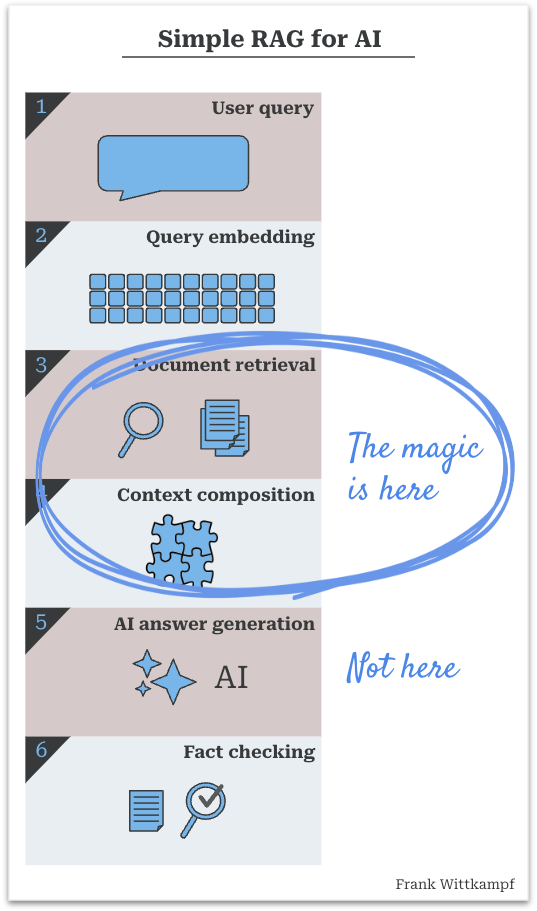
为什么 RAG 系统的神奇之处在于检索,而不是生成
![]()
![]()
快速 POC
最快速的概念证明 (POC) 允许用户在对话式 AI 的帮助下探索数据,这会让您大吃一惊。当您突然可以与文档、数据或代码库进行对话时,感觉就像是纯粹的魔法。
这些 POC 在文档数量有限的小型数据集上创造了奇迹。然而,与几乎任何事情一样,当您将其投入生产时,您很快就会遇到大规模问题。当您深入研究并检查人工智能给您的答案时,您会注意到:
- 您的代理未回复完整信息。它遗漏了一些重要的数据
- 您的代理无法可靠地给出相同的答案
- 您的代理无法告诉您它如何以及在哪里获得哪些信息,从而使答案的用处大大降低
事实证明,RAG 中的真正魔法不是发生在生成人工智能步骤中,而是发生在检索和合成过程中。一旦你深入了解,原因就很明显了……
* RAG = 检索增强生成 –维基百科 RAG 的定义
快速回顾一下简单的 RAG 流程的工作原理:
- 这一切都始于一个询问。用户提出了问题,或者某些系统正在尝试回答问题。
- 一个搜索查询完成。大多数情况下,您会嵌入查询并进行相似性搜索,但您也可以进行经典的弹性搜索或两者的组合,或者直接查找信息
- 搜索结果是一组文件(或文档片段,但现在我们简单地称它们为文档)
- 将文档和查询的本质组合成一些易于阅读的内容语境以便人工智能可以与之合作
- 这人工智能解读问题和文档并生成答案
- 理想情况下这个答案是事实已核实,看看人工智能是否基于文档给出答案,和/或是否适合受众
肮脏的小秘密是,RAG 过程的本质是你必须向人工智能提供答案(在它做任何事情之前),这样它才能给你你正在寻找的答案。
换句话说:
- AI 所做的工作(步骤 5)是运用判断并正确阐明答案
- 工程师所做的工作(步骤 3 和 4)是找到答案并将其组合起来以便人工智能可以消化它
哪个更重要?答案当然是,这取决于情况,因为如果判断是关键因素,那么人工智能模型就可以发挥所有作用。但对于无数的业务用例,找到并正确组合构成答案的各个部分是更重要的部分。
运行 RAG 流程时要解决的第一组问题是数据摄取、拆分、分块、文档解释问题。我在《中》中写过其中一些内容之前的文章,但我在这里忽略它们。现在,我们假设您已经正确解决了数据摄取问题,您有一个可爱的矢量存储或搜索索引。
典型挑战:
- 复制– 即使是最简单的生产系统也经常有重复的文档。更重要的是,当您的系统很大、拥有广泛的用户或租户、连接到多个数据源或处理版本控制等时。
- 接近重复– 大部分包含相同数据但有微小变化的文档。近似重复有两种类型:
– 有意义 – 例如一个小的修正,或者一个小的补充,例如带有更新的日期字段
– 无意义 – 例如:较小的标点符号、语法或间距差异,或者只是时间或摄入处理引入的差异 - 体积– 某些查询具有非常大的相关响应数据集
- 数据新鲜度与质量– 响应数据集中的哪些片段具有可供人工智能使用的最高质量内容,以及哪些片段从时间(新鲜度)角度来看最相关?
- 数据多样性– 我们如何确保搜索结果多样化,以便人工智能得到正确的通知?
- 查询措辞和歧义– 触发 RAG 流程的提示的措辞方式可能无法产生最佳结果,甚至可能不明确
- 响应个性化– 根据提问者的不同,该查询可能需要不同的响应
这个清单还在继续,但你已经明白了要点。
简短的回答:不。
不应低估使用极大上下文窗口的成本和性能影响(您可以轻松地将每次查询成本增加 10 倍或 100 倍),这不包括用户/系统进行的任何后续交互。
不过,先把这个放在一边。想象一下以下情况。
我们把安妮和一张纸放在房间里。报纸上写着:*病人乔:复杂的足部骨折。*现在我们问安妮,病人有足部骨折吗?她的回答是“是的,他愿意”。
现在我们给安妮一百页有关乔的病史。她的回答变成了“好吧,取决于你所指的时间,他已经……”
现在我们给安妮提供了数千页有关诊所所有患者的信息……
您很快就会注意到,我们如何定义问题(或在我们的例子中是提示)开始变得非常重要。上下文窗口越大,查询需要的细微差别就越多。
此外,上下文窗口越大, 可能的答案越来越多。这可能是一件积极的事情,但在实践中,这种方法会引发懒惰的工程行为,如果处理不当,可能会降低应用程序的功能。
当您将 RAG 系统从 POC 扩展到生产时,以下是如何使用特定解决方案解决典型数据挑战的方法。每种方法都经过调整以适应生产要求,并包含有用的示例。
复制
在多源系统中重复是不可避免的。通过使用指纹识别(哈希内容)、文档 ID 或语义哈希,您可以在摄取时识别精确的重复项并防止冗余内容。然而,跨重复项整合元数据也很有价值;这可以让用户知道某些内容出现在多个来源中,这可以增加可信度或突出数据集中的重复内容。
# 用于重复数据删除的指纹识别
def 指纹(doc_content):
返回 hashlib.md5(doc_content.encode()).hexdigest()# 存储指纹并过滤重复项,同时合并元数据
指纹={}
唯一文档 = []
对于文档中的文档:
fp = 指纹(doc['内容'])
如果 fp 不在指纹中:
指纹[fp] = [文档]
unique_docs.append(doc)
别的:
Fingerprints[fp].append(doc) # 合并来源
接近重复
接近重复的文档(相似但不相同)通常包含重要的更新或小的添加。鉴于状态更新等微小变化可能携带关键信息,因此在过滤接近重复项时,新鲜度变得至关重要。一种实用的方法是使用余弦相似度进行初始检测,然后在每组近似重复项中保留最新版本,同时标记任何有意义的更新。
从 sklearn.metrics.pairwise 导入 cosine_similarity
从 sklearn.cluster 导入 DBSCAN
将 numpy 导入为 np# 使用 DBSCAN 进行聚类嵌入以查找近似重复项
聚类 = DBSCAN(eps=0.1, min_samples=2, metric="cosine").fit(doc_embeddings)
# 按簇标签组织文档
集群文档 = {}
对于 idx,枚举中的标签(clustering.labels_):
如果标签==-1:
继续
如果标签不在 clustered_docs 中:
clustered_docs[标签] = []
clustered_docs[标签].append(docs[idx])
# 过滤集群以仅保留每个集群中最新的文档
过滤文档 = []
对于 clustered_docs.values() 中的 cluster_docs:
# 选择具有最新时间戳或最高相关性的文档
freshest_doc = max(cluster_docs, key=lambda d: d['timestamp'])
Filtered_docs.append(freshest_doc)
体积
当查询返回大量相关文档时,有效处理是关键。一种方法是**分层策略**:
- 主题提取:预处理文档以提取特定主题或摘要。
- Top-k 过滤:综合后,根据相关性分数过滤汇总内容。
- 相关性评分:在检索之前使用相似性度量(例如 BM25 或余弦相似性)对最重要的文档进行优先级排序。
这种方法通过检索人工智能更易于管理的合成信息来减少工作量。其他策略可能涉及按主题对文档进行批处理或预先分组摘要,以进一步简化检索。
数据新鲜度与质量
平衡质量与新鲜度至关重要,尤其是在快速发展的数据集中。许多评分方法都是可能的,但这里有一个通用策略:
- 综合评分:使用源可靠性、内容深度和用户参与度等因素计算质量得分。
- 新近度加权:用时间戳权重调整分数,强调新鲜度。
- 按阈值过滤:只有满足综合质量和新近度阈值的文档才能进行检索。
其他策略可能涉及仅对高质量来源进行评分或对旧文档应用衰减因子。
数据多样性
确保检索中的数据源多样化有助于创建平衡的响应。按来源(例如不同的数据库、作者或内容类型)对文档进行分组并从每个来源中选择热门片段是一种有效的方法。其他方法包括通过独特的观点进行评分或应用多样性限制以避免过度依赖任何单一文档或观点。
# 通过分组和选择每个来源的热门片段来确保多样性从 itertools 导入 groupby
k = 3 # 每个来源的热门片段数量
文档 = 排序(文档, key=lambda d: d['source'])
grouped_docs = {key: list(group)[:k] for key, group in groupby(docs, key=lambda d: d['source'])}
多样化_docs = [grouped_docs.values() 中的文档的文档,用于文档中的文档]
查询短语和歧义
不明确的查询可能会导致检索结果不理想。使用确切的用户提示通常并不是检索他们所需结果的最佳方法。例如。之前的聊天中可能存在相关的信息交换。或者用户粘贴了大量带有相关问题的文本。
为了确保您使用精确的查询,一种方法是确保为模型提供的 RAG 工具要求其将问题重新表述为更详细的搜索查询,类似于人们为 Google 精心设计搜索查询的方式。这种方法提高了用户意图和 RAG 检索过程之间的一致性。下面的措辞不是最理想的,但它提供了要点:
工具=[{
“名称”:“搜索我们的数据库”,
"description": "在我们的内部公司数据库中搜索相关文档",
“参数”: {
“类型”:“对象”,
“特性”: {
“询问”: {
“类型”:“字符串”,
"description": "搜索查询,就像谷歌搜索一样,采用句子形式。请注意提供问题的任何重要细微差别。"
}
},
“必填”:[“查询”]
}
}]响应个性化
对于定制响应,将用户特定的上下文直接集成到 RAG 上下文组合中。通过向最终上下文添加特定于用户的层,您可以允许人工智能考虑个人偏好、权限或历史记录,而无需改变核心检索过程。
通过解决这些数据挑战,您的 RAG 系统可以从引人注目的 POC 发展成为可靠的生产级解决方案。最终,RAG 的有效性更多地依赖于精心设计,而不是人工智能模型本身。虽然人工智能可以生成流畅的答案,但真正的魔力在于我们检索和构建信息的能力。因此,下次当您对人工智能系统的对话能力印象深刻时,请记住,这很可能是在幕后精心设计的检索过程的结果。
我希望本文能让您深入了解 RAG 过程,以及为什么您在与数据交谈时所体验到的魔力不一定来自 AI 模型,而是在很大程度上取决于检索过程的设计。
请评论说出你的想法。