
预测血液透析患者的早期死亡率:使用韩国全国前瞻性队列的深度学习方法
作者:Yoo, Kyung Don
介绍
血液透析(HD)是终末期肾病(ESKD)患者的一种行之有效的挽救生命的治疗方法1,2。然而,HD 开始后的死亡率仍然是改善患者预后和寿命的一个挑战。随着接受偶发透析患者年龄的增加,准确评估与死亡相关的危险因素对于及时干预和优化患者管理至关重要3,4,5。最近的研究调查了老年 ESKD 患者护理的不同方面,例如 HD 和腹膜透析 (PD) 之间的选择4、通路放置时机以及 ESKD 对预期寿命和生活质量的影响6。这些研究为影响透析开始、生存率和合并症负担的趋势和因素提供了宝贵的见解,特别是在高危人群中。在世界范围内,开始血液透析后不久的死亡风险很高。通过分析来自 11 个国家的 86,886 名患者的死亡率模式,使用透析结果和实践模式研究 (DOPPS) 的数据重点关注早期透析期,这是一项中心血液透析的前瞻性队列研究7观察到透析周期和年龄之间的相互作用。此外,开始血液透析后的死亡率轨迹显示,美国的死亡率较早达到峰值8和中国人口9。对此的一个可能的解释是 HD 开始后第一年心血管事件 (CVE) 发生率较高。我们评估了费森尤斯医疗透析中心开始血液透析 (HD) 后第一年的每周心血管事件 (CVE) 综合发生率以及头两年的每月综合发生率10。在 7 天内开始透析的 6,308 名患者中,有 1,449 名患者在接下来的两年内经历了 2405 次心血管事件。第一年的 CVE 发生率(30.2/100 人年;95% CI,28.7–31.7)大大超过第二年的发生率(19.4/100;95% CI,18.1–20.8)10。随着年龄的增长,这种趋势更加明显;因此,早期死亡率峰值随着年龄的增长而更加明显10。然而,目前尚不清楚这是否是由于年龄或老年人有更多合并症所致。然而,仍然需要更全面、更准确的模型来评估和预测 HD 患者过早死亡的风险,需要个体化考虑各个国家的 ESKD 治疗模式,特别是 HD 治疗模式11。
机器学习模型,特别是深度学习,在肾脏病学领域,特别是在不同肾病人群的风险预测和结果分析方面显示出了有希望的结果12,13。这些先进的计算方法可以增强我们对各种因素之间复杂关系及其对诊断、治疗和预后影响的理解14,15,16。然而,这些研究有局限性,因为它们经常采用不同的算法。他们未能利用血液透析患者的具体信息,也没有纳入重复的测量数据。这些问题突出表明需要进一步研究来解决这些差距并改进血液透析患者的风险评估和管理。
在这项研究中,我们旨在利用深度学习方法在韩国全国前瞻性队列中调查 HD 患者过早死亡的危险因素。通过利用深度学习模型的力量,我们的目标是提供对风险因素更全面、更准确的理解,最终有助于更好的临床决策和 HD 患者的患者护理。这项研究提出了一种新颖的机器学习方法,用于临床结果,使用多中心前瞻性队列预测 HD 患者的早期死亡率。
材料和方法
数据来源和研究参与者
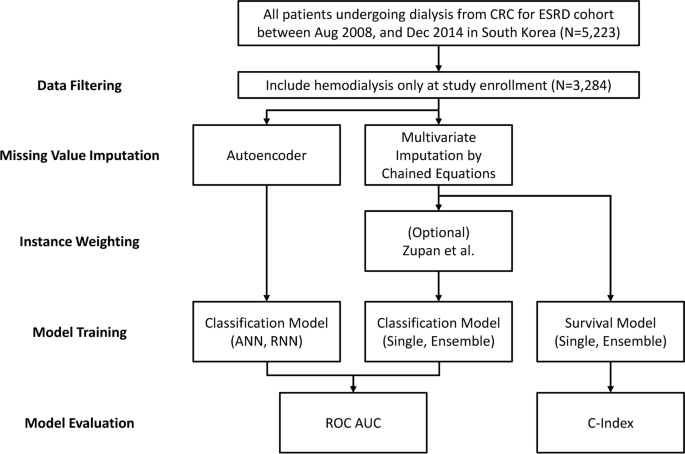
我们的分析是使用来自终末期肾病临床研究中心(CRC for ESRD,NCT00931970)数据库的数据进行的,该数据库是韩国 ESRD 患者的唯一全国性、多中心、前瞻性队列。数据收集自韩国 36 家综合医院和教学医院。我们纳入了 5223 名来自 CRC 的患者进行 ESRD 研究,其中 3284 名正在接受血液透析(图 1)。 1)。该研究的纳入标准规定,所有参与者均年满 18 岁,并在 2008 年 8 月至 2014 年 12 月期间开始透析。之前已描述过关于识别和将透析患者纳入 CRC 的 ESRD 队列的详细信息17 号,18。数据收集是使用基于网络的平台进行的(http://webdb.crc-esrd.or.kr),遵循早期研究中概述的既定方法。在最初可用的 72 个属性中,我们采用机器学习算法分析了 3284 名患者的记录,重点关注了 50 多个相关属性。从这个属性池中,我们选择了 24 个自变量,这些变量被认为对预测模型构建的全因死亡率具有潜在影响。值得注意的是,其中三个属性是在两个时间点(0 个月和 3 个月)跟踪的时间序列变量:RAAS 封锁使用情况、反映尿量 (ml) 的 24 小时尿液研究以及通过 KT/V 测量的透析充分性。桌子1提供用于模型开发的选定属性的完整列表。改良的查尔森合并症指数 (mCCI) 已针对透析患者进行了验证,该指数是通过检查患者入组时的病史来确定的19。我们之前的研究也讨论了机器学习在 CRC-ESRD 中的应用20。所有参与者都被告知该研究;他们自愿参与并提供书面知情同意书。该研究得到了每个中心的机构审查委员会的批准。所有研究人员均按照 2008 年赫尔辛基宣言的指导方针进行了这项研究。这项研究得到了首尔国立大学医院机构审查委员会的批准(IRB 号 H-0905-047-281)。
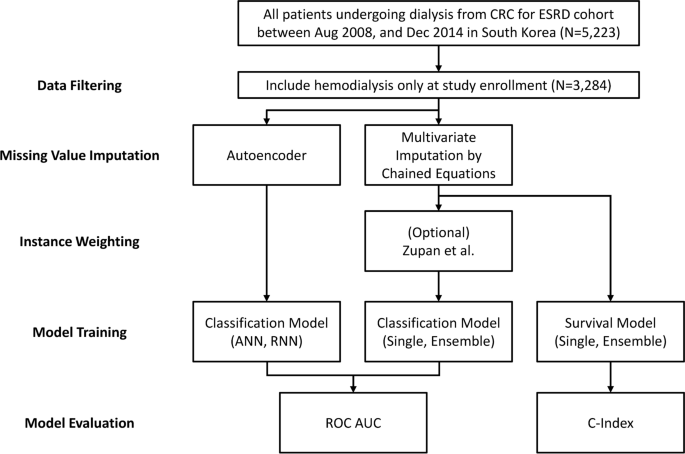
数据预处理、模型训练和评估过程的综合工作流程。在本研究中,我们应用了 Zupan 等人研究中的加权方法。23。
问题陈述
我们努力根据上述数据集预测患者的死亡风险,实现两个不同的目标:
-
1.
分类:我们的首要目标是预测患者是否会在一年内死亡。此分类问题需要开发一个预测模型来估计患者一年内死亡的概率。为了评估模型的有效性,我们将采用 AUC(接收者操作特征曲线下的面积)作为性能指标。
-
2.
生存分析:我们的第二个目标涉及预测风险比,它表示死亡的相对风险。此生存分析任务包括构建一个预测模型,该模型根据各种因素估计风险比。我们将使用 C 指数(一致性指数)来评估预测模型的准确性,C 指数是模型对个体生存时间进行排名的能力的衡量标准。
通过解决这两个不同的挑战,我们的目标是加深对血液透析患者死亡风险的了解,并为预后和临床决策提供有价值的见解。
数据预处理
我们对给定的数据集实施了几个数据预处理步骤,如下:
-
1.
缺失值插补:缺失值得到了解决,因为我们的数据是从 2008 年到 2014 年的七年时间里收集的,某些值的缺失是不可避免的。在 24 个变量中,大约 32.9% 的患者(1,081 人)至少有一个缺失值。对于缺失值较少的患者,我们使用可用的变量值进行插补。我们设置了四个或更少缺失值的阈值,结果是 999 名患者。应用插补技术后,数据集包含 3202 名患者,占总数据集的 97.5%。链式方程多元插补 (MICE)21使用决策树(CART)的方法22 号主要用于插补,对于神经网络模型,使用了可选的自动编码器方法。关于自动编码器方法的更全面的细节将在模型部分提供。
-
2.
数据分割:为了确保维持结果(死亡)比例,我们在将数据分为训练集、验证集和测试集时进行了分层随机抽样。在 3202 个数据样本中,962 个样本(30%)被分配给测试集。剩下的2240个样本被分为1600个训练集和640个验证集。
-
3.
审查数据:在分类问题的背景下,由于右审查数据而出现了挑战。这意味着对于随访期不到一年的患者,结果(死亡)仍然未知。在数据集中,有 801 名患者的数据经过右删失,其中测试集中有 264 名患者,训练集和验证集中有 537 名患者。我们从测试集中排除了 264 名患者,并采用排除或加权方法23用于训练和验证集。加权方法将每条右删失数据复制为 0 和 1,根据生存函数分配权重。对于生存分析,使用右删失数据,而不影响可用数据样本的总数(图 1) 2)。
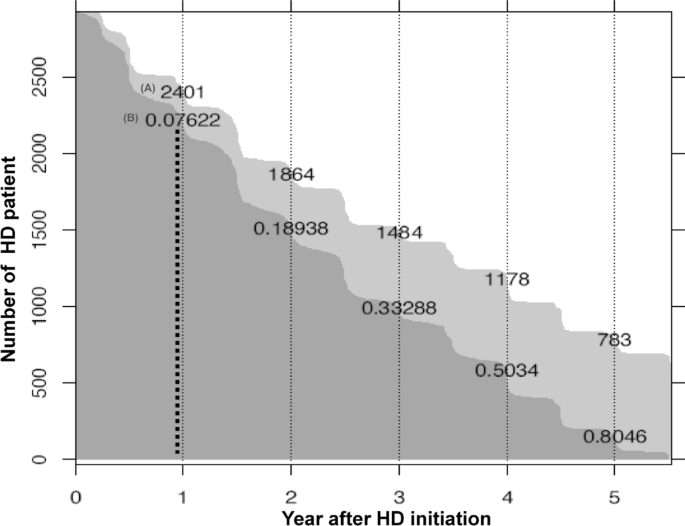
患者在 HD 开始后进行随访。(A) 透析开始后随访年份的患者人数。(B) 开始透析后,比较非幸存者与幸存者的年生存率。
模型
为了解决分类和生存分析问题,我们采用了一系列机器学习模型。对于分类问题,我们使用单一模型,例如逻辑回归24,岭/套索回归25,和决策树(CART)22 号。此外,集成模型(例如 bagging)26和随机森林27被利用了。在生存分析的情况下,我们采用了为生存分析设计的相应模型,包括cox回归28, 生存山脊/套索25, 生存决策树22 号,29, 套袋26,和生存随机森林27。除了这些模型之外,我们还考虑了人工神经网络(ANN)的应用30和用于分类问题的循环神经网络(RNN)。特别选择 RNN 来有效处理前面提到的时间序列变量:RAAS 封锁的使用、反映尿量 (ml) 的 24 小时尿液研究以及通过 KT/V 测量的透析充分性。这些变量在不同的时间步长(0/3 个月)与其他变量连接起来,并作为每个 RNN 单元的输入。在 RNN 的各种变体中,我们选择了长短期记忆 (LSTM) 架构31。此外,我们还集成了一个可选的自动编码器 (AE)32用于神经网络模型(ANN 和 RNN)。自动编码器是一种神经网络,旨在将输入值预测为输出值。通过将隐藏层中的节点数量限制为少于输入层中的节点数量,AE 可以学习输入数据的压缩表示。此约束可实现高效的数据表示,并有助于利用 AE 来处理缺失值。在训练阶段,一些输入变量被随机删除(\(p = 0.2\)),并训练 AE 将它们重建为原始值。图 3描述了AE的综合训练和推理方法。

自动编码器训练和推理方法。在训练阶段,跨不同时间步长的时间序列变量与基本变量合并。在推理阶段,编码特征(\(Z\))从基础变量和时间步变量导出,作为相应 RNN 单元的输入。
特征重要性分析
最后,为了确定对患者死亡率最有影响力的预测因素,我们评估了五种机器学习模型的特征重要性:逻辑回归、岭回归、套索回归、决策树和随机森林。在线性模型(逻辑回归、岭回归和套索回归)中,特征重要性由模型系数的绝对大小决定。绝对系数越大,表明与目标变量的关联性越强。具体来说,岭回归采用 L2 正则化,它会惩罚系数的平方大小,从而将不太重要的特征权重缩小到零,而不消除它们。相比之下,Lasso 回归利用 L1 正则化,它可以强制某些系数恰好为零,通过从模型中排除不太重要的变量来有效地执行特征选择。对于基于树的模型(决策树和随机森林),特征重要性是根据每个特征在树中所有分割中贡献的杂质(即基尼杂质)的减少来计算的。持续导致杂质大幅减少的特征被认为更重要。随机森林将这些重要性分数聚合到集合中的多个决策树中,与单个决策树相比,提供了更稳定、更可靠的特征重要性度量。
每个模型识别的前 10 个重要特征如图 1 和 2 所示。S1到S5。
执行
神经网络模型是使用 TensorFlow 1.13 版实现的,而其余模型是在 R 3.4 版中开发的,利用 glmnet、rpart、randomForestSRC、ipred 和 mouse 包。
结果
人口统计
用于建模的基线特征是根据 HD 患者的死亡率显示的(表1)。在该前瞻性队列的 5223 名接受透析的患者中,最终分析包括 3,284 名接受 HD 的患者。观察期内共有 634 名参与者(19.3%)死亡,其中 183 名参与者(5.5%)在前 12 个月内死亡(图 1)。 2)。总体死亡组的平均年龄为 65.9±11.5 岁,幸存者组的平均年龄为 56.7±13.4 岁(p–< –0.001)。总死亡率组中男性患者为 62.9% (N=399),而第一年死亡率组为 62.8%;59.9%的患者因糖尿病而开始透析。
与幸存者组相比,第一年死亡率组的心血管疾病、糖尿病病史明显较高,mCCI 评分也较高。各组之间在吸烟史或肾素-血管紧张素-醛固酮系统阻断剂的使用方面不存在差异。关于透析开始时的实验室检查结果,非幸存者的血尿素氮(BUN)、肌酐和磷水平显着低于幸存者。
使用传统机器学习模型对第一年死亡率进行分类
首先,我们尝试使用传统的机器学习模型预测 HD 患者的第一年死亡率。测试集的 ROC AUC 值显示在表的下半部分2。如数据预处理部分所述,所有方法都通过链式方程多重插补 (MICE) 对缺失值进行插补21,并选择性地应用了 Zupan 等人提出的加权方法。23对于审查的例子。据观察,基于树的集成模型(例如随机森林和装袋)比单一模型表现更好,证明了集成效果。值得注意的是,随机森林的 AUC 显着高于单个决策树的 0.7571,为 0.8321。应用加权方法没有发现显着的性能差异。
使用神经网络对第一年死亡率进行分类
接下来,我们使用神经网络探索相同的预测任务,结果如表上半部分所示2。长短期记忆 (LSTM) 模型的性能优于仅由全连接层组成的人工神经网络 (ANN)。这表明 LSTM 在处理时间序列变量方面更有效。此外,在处理缺失值时,事实证明,经过端到端训练的自动编码器比 MICE 等现成方法更有效。最终,利用自动编码器的 LSTM 模型获得了最高的 AUC 0.8357,略微超过了性能最好的传统机器学习模型随机森林,其 AUC 为 0.8321。
风险比预测
接下来,我们解决预测风险比的挑战,该风险比代表 HD 患者死亡的相对风险水平。为此,我们采用了传统的机器学习模型来促进生存分析。例如,在基于树的方法中,我们使用生存分析统计数据而不是基尼系数或熵指数作为分割规则。桌子3显示这些模型的一致性指数 (C-index) 值。与分类任务类似,集成模型的性能优于单个模型,其中生存装袋模型表现出最高的性能,其 C 指数为 0.7756。图 4说明了生存决策树的结构(C 指数 0.7693),使我们能够确定哪些变量和值对于预测风险比至关重要。值得注意的是,叶节点的风险比 (HR) 值表示该组与整个患者群体相比的相对 HR,值越高表示风险组越高。该模型确定的最重要因素是透析时间不超过 14.9 个月的短透析患者的改良查尔森合并症指数 (mCCI),该指数与过早死亡密切相关。在该组中,合并症分为 6 级和 6 级,在所有患者中观察到的死亡率最高,表明 HR 为 7.78(不考虑包括年龄在内的其他因素)。
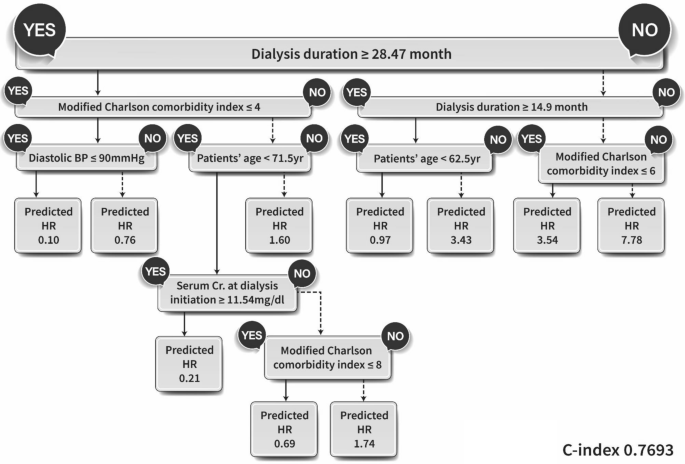
生存决策树架构。每个叶节点将相对死亡风险显示为生存风险比 (HR)。分裂条件标记为“是”表示真实结果,“否”表示错误结果(C 指数 0.7693)。
高危患者亚组分析结果
最后,我们使用传统的 Cox 回归对高风险亚组进行了额外分析,以确定年龄和 mCCI 风险对死亡率的相互影响。我们进行了多变量分析,并调整了混杂因素,例如年龄、性别、肾病的主要原因、吸烟史、透析持续时间、分类组的 BMI、DM、CVD 病史和 RAAS 阻断的使用。如表所示4,单变量分析显示年龄是总体死亡率的危险因素。然而,多变量分析显示,年龄组本身并没有提供显着的早期死亡风险(老年组(≤75岁,参考年龄组≤45岁),HR 2.44,95% CI 0.89-6.68,p≤=≤0.082)。更重要的是,唯一已证实影响透析开始后早期死亡率的预后因素是高 mCCI 组(老年组(≤75 岁,参考年龄组≤<45 岁)、HR9.84,95% CI 1.88-51.31,p≤=≤0.007)。表 4 CRC-ESRD 前瞻性队列中第一年死亡率和总体死亡率的危险因素分析。
在这项研究中,我们分析了全国范围内 5223 名接受 HD 治疗的前瞻性队列中的 3284 名血液透析 (HD) 患者。
该研究利用一系列机器学习算法来预测 HD 患者治疗第一年内的死亡率。其中,循环神经网络 (RNN) 与自动编码器 (AE) 相结合产生了最高的准确度,达到了 0.8357 的曲线下面积 (AUC)。此外,在预测风险比方面,生存装袋模型表现最好,其一致性指数(C 指数)为 0.7756。
对接受透析的 ESKD 患者进行早期预后预测的研究在该人群中有着悠久的历史。2009 年,Couchoud 等人。33使用法国肾脏流行病学和信息网络 (REIN) 队列数据仅根据临床特征预测开始透析的老年患者 6 个月死亡率。尽管选择了九个风险因素并对观察到的和预期的死亡进行了良好的验证,但该研究仅达到了 0.70 的中等 C 指数。一个限制是缺失插补造成的潜在选择偏差。相比之下,我们的研究应用了具有相同变量的相同模型,但使用了 MICE 插补方法进行增强。结果,我们的研究将 C 指数提高到了 0.7756,并表明 mCCI 仅对死亡率的影响比年龄的影响更显着。Sanmarchi 等人进行了系统综述。13人工智能和机器学习技术在预测、诊断和治疗慢性肾病(包括 ESKD)方面显示出前景;然而,未来的工作需要增强临床实践机器学习模型的可解释性、普遍性和公平性。值得注意的是,只有五项研究利用了 RNN,并且只有一项研究使用了自动编码器来进行数据增强。根据我们的研究结果,我们预计通过在未来的研究中使用血液透析特定信息的插补可以改善结果12。
我们的研究结果表明,无论年龄如何,合并症与预后的关系更为密切,即使在调整透析效率、随尿量表现的残余肾功能和 RAAS 阻断剂的使用后,这些发现仍然一致。许多研究人员怀疑,较高数量的合并症可能与透析患者的不良预后密切相关。刘等人。发表了一项关于合并症对老年透析患者生存预测影响的出色研究,该研究修改了现有的查尔森合并症指数(CCI)34并根据美国肾脏数据系统 (USRDS) 中使用的共病状况和管理数据开发了一种新的共病指数 (nCI),用于透析患者的死亡率分析35。nCI 是根据 2000 名美国发生透析的患者制定的,并使用 1999 年和 2001 年发生的美国透析人群以及 2000 年美国流行的透析人群进行了验证。有趣的是,刘等人。35合并症指数包括11种合并症(动脉粥样硬化性心脏病、充血性心力衰竭、脑血管意外/短暂性脑缺血发作、周围血管疾病、心律失常、其他心脏病、慢性阻塞性肺病、消化道出血、肝病、癌症和糖尿病),但没有包括年龄,它是原始 CCI 的组成部分。作者证明,在模型拟合、预测能力和对推理的影响方面,nCI 的表现与个体合并症的表现几乎相同,这表明 nCI 是比 CCI 更好的预测因子。准确的预测需要结合年龄和合并症,这可能具有挑战性。然而,我们的研究支持这样的发现:在高危患者(例如透析患者)中,合并症可能比年龄更重要。
科恩等人。还开发了一个预后模型,通过将选定的变量(例如 mCCI 和血清白蛋白)与肾脏病学家对一个令人惊讶的问题的回答相结合来评估透析患者的死亡风险(如果该患者在六个月内死亡,您会感到惊讶吗??)36。与单独使用这两种工具中的任何一种相比,这种用于预测六个月死亡率的简单床边工具显示出独立的优越预后价值。然而,有人可能会说,这一模型有局限性,因为它依赖于透析患者难以定义的主观参数(例如痴呆症)。此外,这个令人惊讶的问题可能是高度主观的,并且根据肾病专家的培训和患者知识的不同而变化。我们的研究存在一些缺点,例如前瞻性队列中患者的平均年龄较年轻(58.4 岁)以及缺乏有关认知障碍的信息。因此,Floege 等人。提出了另一种风险预测模型,该模型是在欧洲血液透析队列中开发的,平均年龄为 64 岁,仅使用客观测量结果,没有痴呆症信息37。该模型在 DOPPS 队列中进行了外部验证,并表现出中等程度的歧视(C 统计量 0.68–0.79)。该群体与我们的研究人群之间的相似性对我们的研究具有潜在的影响。
将机器学习引入患者预后预测的研究不断增加,以克服先前使用传统统计方法的研究的局限性13。我们研究的优势之一是,我们通过逐步验证迄今为止为透析患者引入的几乎所有 ML 算法,证明了性能的提高。传统统计死亡率预测模型的 AUROC 通常在 0.65 至 0.75 范围内38。使用电子病历 (EMR)(特别是随机森林模型)的复杂机器学习技术来预测接受 HD 的老年患者心源性猝死是这种方法的最初示例。该模型产生的 AUROC 高达 0.7939,40,这与我们的研究结果相当(表2)。使用 RNN 可以提高预测能力(AUC 0.8357),但在作者的搜索或本系统综述中未发现类似的研究。如前所述,第一个原因可能是使用自动编码器提高了插补有效性13,第二是 RNN 同时考虑额外的变量选择,这极大地影响了预后预测。此外,透析充分性以 KT/V 表示,这一点已在之前的许多研究中得到证实,包括 24 小时尿液研究作为尿量41和 RAAS 封锁使用17 号作为该前瞻性队列中的独立预后因素,可能有助于改善预测。因此,在应用和解释深度学习方法时必须考虑临床适用性。
结论
这项研究利用韩国全国前瞻性队列,利用机器学习算法来预测血液透析患者的早期死亡率并评估危险因素。带有自动编码器的循环神经网络在预测第一年死亡率方面具有最高的准确性(AUC 0.8357),而生存装袋模型在预测风险比方面表现最好(C 指数 0.7756)。值得注意的是,发现合并症在预测早期死亡率方面比年龄更有影响力,改良查尔森合并症指数评分高 (≤7) 是一个重要的预后因素,特别是对于透析时间较短的患者 (<≤7)14.9 个月)。该研究强调了透析充分性(KT/V)、肾素-血管紧张素-醛固酮系统抑制剂的使用以及残余尿量等监测因素对于评估血液透析患者早期预后的重要性。这些发现有助于更好地了解风险因素,并有助于血液透析患者的临床决策和患者护理。
数据可用性
要获取数据的访问权限,感兴趣的个人应联系通讯作者并提交合理的请求,解释他们对数据的需求。收到此类请求后,通讯作者将确定共享数据是否适当且可行。
参考
Kovesdy,C。P.慢性肾脏疾病的流行病学:2022年更新。肾脏国际。补编。 12(1),7 11(2022)。
Suriyong,P.,Ruengorn,C.,Shayakul,C.,Anantachoti,P。&Kanjanarat,P。亚洲低下和中等收入国家的慢性肾脏疾病阶段3年5年的流行:-分析。公共科学图书馆一号 17 号(2),E0264393(2022)。
Obi,Y。等。过渡到透析时早期死亡率的预测得分的发展和验证。梅奥·临床。过程。 93(9),1224 - 1235(2018)。
Thamer,M。等。预测老年透析患者的早期死亡:风险评分的发展和验证,以帮助共同的透析开始决策。是。J. 肾脏疾病。 66(6),1024 - 1032(2015)。
Couchoud,C。G.,Beuscart,J。B.,Aldigier,J。C.,Brunet,P。J.&Moranne,O。P.开发风险分层算法,以改善患者以患者为中心的护理和决策终末期肾脏肾脏疾病的患者。肾脏国际。 88(5),1178 - 1186(2015)。
Moss,A。H.修订后的透析临床实践指南促进了更明智的决策。临床。J. Am.苏克。肾病。 5(12),2380 2383(2010)。
Robinson,B。M.等。在世界范围内,开始血液透析后不久死亡风险就很高。肾脏国际。 85(1),158 - 165(2014)。
Foley,R。N.,Chen,S。C.,Solid,C。A.,Gilbertson,D。T.&Collins,A。J.开始透析的患者早期死亡率似乎未经注册。肾脏国际。 86(2),392â398(2014)。
Zhao,X.,Wang,M。&Zuo,L。中国血液透析患者的早期死亡风险:一项回顾性队列研究。任。失败。 39(1),526 - 532(2017)。
Eckardt,K。U.等。高心血管事件发生率发生在开始血液透析的头几周内。肾脏国际。 88(5),1117 - 1125(2015)。
Jung,J。Y.等。韩国肾脏学会执行摘要2021最佳血液透析治疗临床实践指南。肾脏。临床。练习。 40(4),578 - 595(2021)。
Chaudhuri,S。等。人工智能启用了肾脏疾病的应用。塞明。拨号。 34(1),5â16(2021)。
Sanmarchi,F。等。通过机器学习预测,诊断和治疗慢性肾脏疾病:系统文献综述。J.内弗罗尔。 36,1101年1117(2023)。
Garcia-Montemayor,V。等。使用机器学习分析预测血液透析患者的死亡率。临床。肾脏J. 14(5),1388年1395(2021)。
Rankin,S。等。一个机器学习模型,用于预测透析启动的90天内死亡率。肾脏360。3 (9),1556年1565(2022)。文章
瑟尔。副词。慢性病。 13,20406223221119616(2022)。
Yoo,K。D.等。肾素 - 血管紧张素 - 醛固酮系统阻断对ESRD患者的结局的影响:韩国的一项前瞻性队列研究。肾脏国际。代表。 3(6),1385年1393(2018)。
Yoo,K。D.等。韩国终末期肾病患者的癌症:一项为期7年的随访。公共科学图书馆一号。 12(7),E0178649(2017)。
Park,J。Y.等。在韩国事件血液透析患者中,查尔森合并症指数的重新校准和验证。公共科学图书馆一号。 10(5),E0127240(2015)。
Noh,J。等。使用机器学习模型的腹膜透析患者中死亡率风险的预测:韩国的全国前瞻性队列。科学。代表。 10(1),7470(2020)。
Buuren,S。&Groothuis-Oudshoorn,K。小鼠:R。JSS。 45,1â67(2011)。
谷歌学术一个
Breiman,L.,Friedman,J.,Stone,C.J。&Olshen,R.A。分类和回归树(CRC出版社,1984年)。
谷歌学术一个
Zupan,B。D. J.,Kattan,M。W.,Beck,J。R.&Bratko,I。生存分析的机器学习:关于前列腺癌复发的案例研究。阿蒂夫。英特尔。医学。 20,59 - 75(2000)。
Dobson,A。J.广义线性模型简介。J. 统计。计划。推理。 32(3),418 420(1992)。
弗里德曼(J.J.统计软件。 33(1),1 22(2010)。
Breiman, L. 装袋预测器。马赫。学习。 24,123â140(1996)。
Breiman L.随机森林。马赫。学习。(2001)。
Andersen,P。K.&Gill,R。D. Cox的回归模型用于计数过程:大型样本研究。安.统计。 10(4),1100â1121(1982)。
Leblanc,M。&Crowley,J。审查生存数据的相对风险树。生物识别技术411 425,(1992)。
Jain,A。K.,Mao,J。&Mohiuddin,K。M.人工神经网络:教程。电脑。 29,31â44(1996)。
Hochreiter,S。&Schmidhuber,J。长期记忆。神经计算。 9(8),1735年1780年(1997年)。
Kramer,M。A.使用自动社会神经网络的非线性主成分分析。AIChE J. 37(2),233â243(1991)。
Couchoud,C。等。临床评分可以预测老年患者的6个月预后,以开始终心肾脏疾病的透析。肾病。拨号翻译。 24(5),1553 - 1561(2009)。
查尔森(M. E.J.慢性疾病。 40(5),373â383(1987)。
Liu,J.,Huang,Z.,Gilbertson,D。T.,Foley,R。N.&Collins,A。J.合并症的改进,用于透析患者的结局分析。肾脏国际。 77(2),141 151(2010)。
科恩(L.临床。J. Am.苏克。肾病。 5(1),72â79(2010)。
Floege,J。等。欧洲血液透析队列的预测死亡风险评分的发展和验证。肾脏国际。 87(5),996 - 1008(2015)。
Ramspek,C。L.等。慢性透析患者死亡率风险的预测模型:系统审查和独立的外部验证研究。临床。流行病。 9,451â464(2017)。
戈德斯坦(B.临床。J. Am.苏克。肾病。 9(1),82â91(2014)。
Akbilgic,O。等。机器学习以识别处于高死亡风险的透析患者。肾脏国际。代表。 4(9),1219 - 1229(2019)。
Lee,M。J.等。在接受透析的患者中,残留尿量的预后价值,24小时尿液的GFR和EGFR。临床。J. Am.苏克。肾病。 12(3),426 - 434(2017)。
致谢
我们感谢所有临床研究中心的末期肾脏疾病研究者。这项研究由首尔国立大学医院研究基金的赠款03-2020-2130资助,并在韩国卫生技术研发项目的赠款中通过韩国健康行业发展研究所(KHIDI)提供了资助,该研究所由卫生与福利部资助。,大韩民国(赠款号:HR22C1832和HI22C1529)。Junhyug Noh得到了2023年EWHA Womans University Research Grant的支持,以及由韩国政府(MSIT)资助的信息与通信技术计划与评估研究所(IITP)赠款(RS-2022-00155966)。值得一提的是,在2020年,Kyung Don Yoo因本文提供的摘要内容而获得了韩国肾脏学学会(KSN)的杰出抽象奖。
道德声明
利益竞争
作者声明没有竞争利益。
附加信息
出版商的注释
施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
补充信息
权利和权限
开放获取本文获得 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License 的许可,该许可允许以任何媒介或格式进行任何非商业使用、共享、分发和复制,只要您给予原作者适当的署名即可和来源,提供知识共享许可的链接,并指出您是否修改了许可材料。根据本许可,您无权共享源自本文或其部分内容的改编材料。本文中的图像或其他第三方材料包含在文章的创意共享许可证中,除非在材料的信用额度中另有说明。如果文章的创意共享许可中未包含材料,并且您的预期用途不得由法定法规允许或超过允许的用途,则需要直接从版权所有者那里获得许可。要查看该许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

Noh,J.,Park,S.Y。,Bae,W。
等人。预测血液透析患者的早期死亡率:使用韩国全国前瞻性队列的深度学习方法。科学代表14 ,29658(2024)。https://doi.org/10.1038/s41598-024-80900-6
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41598-024-80900-6