

SEALONG:一种在大型语言模型中进行长上下文推理的自我改进人工智能方法
作者:Mohammad Asjad
具有长上下文处理能力的大型语言模型(LLM)彻底改变了多个领域的技术应用。最近的进步已经实现了复杂的用例,包括存储库级编码辅助、多文档分析和自主代理开发。这些模型在处理广泛的上下文信息方面表现出巨大的潜力,需要先进的机制来有效地检索和整合分散的细节。然而,当前的形势揭示了在复杂推理任务中保持一致性能的重大挑战。虽然法学硕士在大海捞针的场景中实现了近乎完美的准确性,但在面对更细致的长上下文推理挑战时,仍然存在巨大的性能限制。这种变化凸显了对创新方法的迫切需求,以增强人工智能系统的上下文理解和推理能力。
长上下文语言建模研究已成为人工智能的关键前沿,探索增强大型语言模型上下文处理能力的创新方法。两个主要的研究轨迹已经受到关注:以模型为中心的方法论和以数据为中心的方法论。以模型为中心的策略涉及对现有架构的有针对性的修改,包括对位置嵌入和注意力机制的细微调整。研究人员还提出了独特的架构设计,旨在提高计算效率和上下文理解。同时,以数据为中心的方法侧重于复杂的数据工程技术,例如对扩展序列的持续预训练以及利用专家模型或人工注释来精炼训练数据。这些多方面的研究工作共同旨在突破语言模型的界限——上下文理解和推理能力,解决人工智能系统的基本挑战。
香港中文大学、北京大学、清华大学、腾讯研究人员介绍海龙,一种强大的自我改进方法,旨在增强大型语言模型在长上下文场景中的推理能力。通过对多个推理轨迹进行采样并采用最小贝叶斯风险 (MBR) 评分,该方法可以对输出进行优先级排序,从而证明生成的响应具有更高的一致性。这种方法通过识别和优先考虑与集体模型输出更紧密结合的推理路径,解决了语言模型中幻觉的关键挑战。该方法提供了两种主要的优化策略:使用高分输出的监督微调和涉及高分和低分轨迹的偏好优化。对领先语言模型的实验评估表明,性能显着提高,长上下文推理能力显着增强,而无需依赖外部人类或专家模型注释。
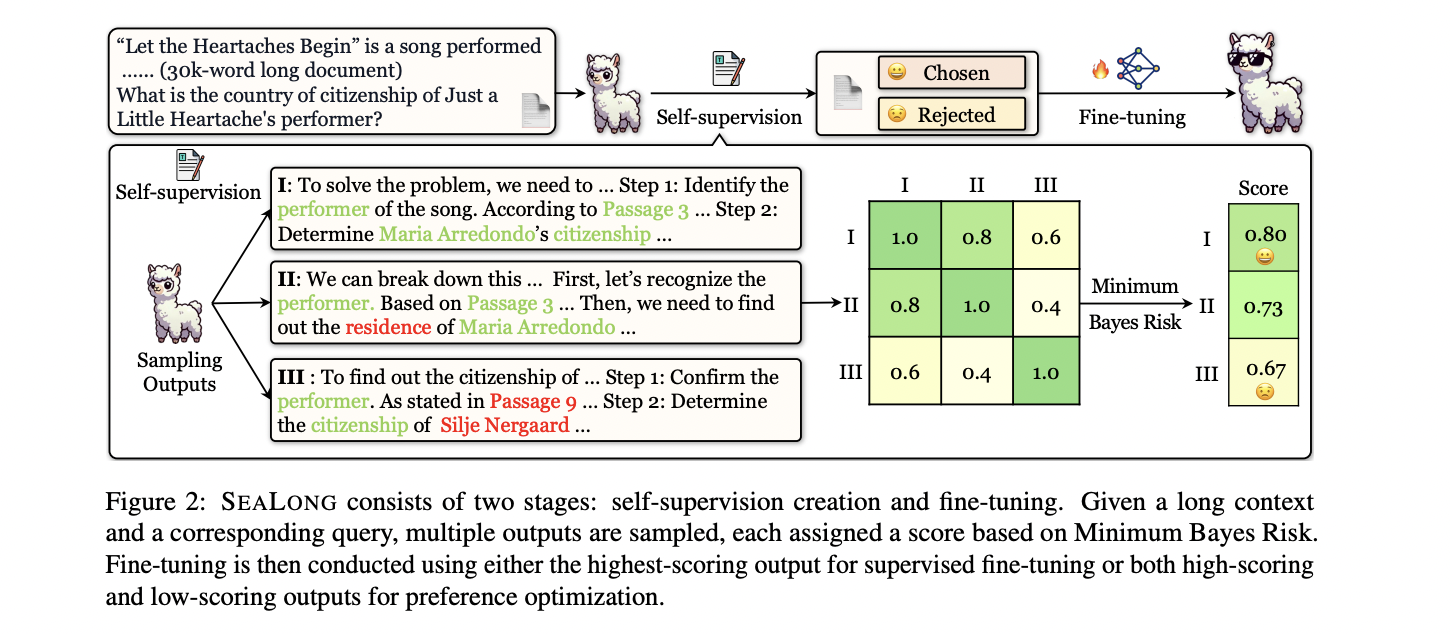
SEALONG 引入了一种创新的两阶段方法,用于增强大型语言模型中的长上下文推理。该方法以自我监督和模型微调为中心,利用基于 MBR 解码的稳健评估技术。通过为每个输入生成多个推理轨迹,该方法通过语义一致性和嵌入相似性来评估输出质量。这种方法使模型能够通过比较不同的生成输出来识别和优先考虑更可靠的推理路径。该技术采用蒙特卡罗方法对每个轨迹进行评分,有效地区分潜在的幻觉和更准确的反应。至关重要的是,SEALONG 在不依赖外部人工注释或专家模型干预的情况下展示了显着的性能改进。
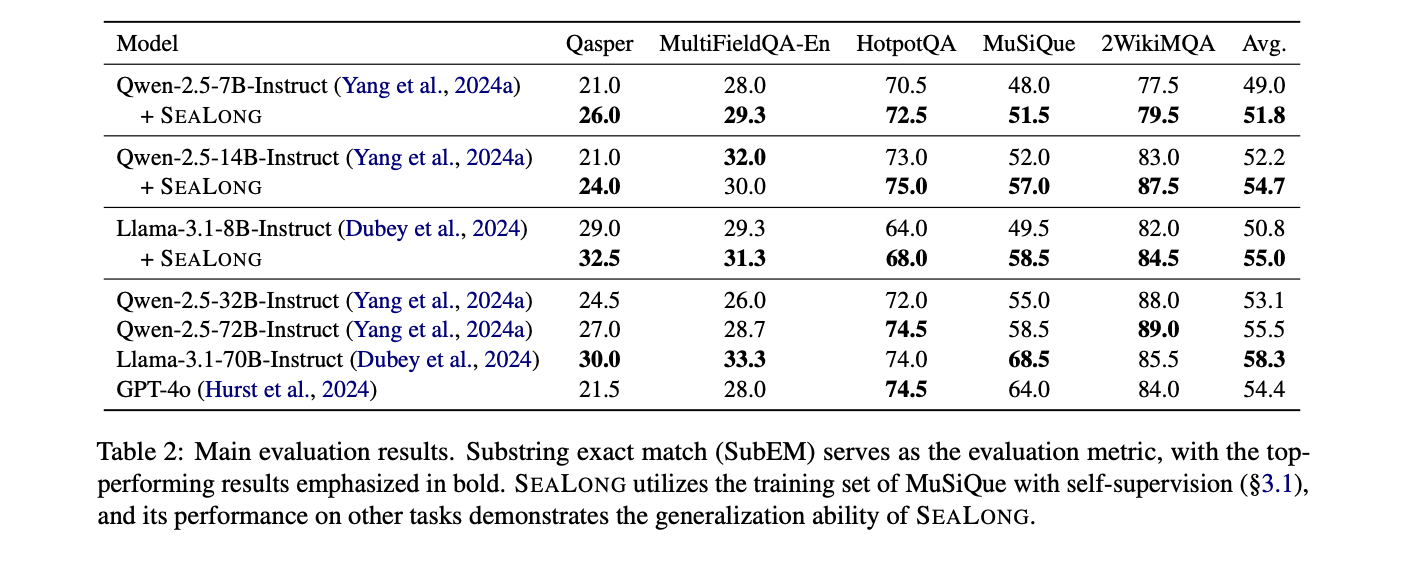
这项研究提出海龙,一种通过自我改进技术增强大型语言模型长上下文推理能力的创新方法。SEALONG 代表了在解决人工智能系统中与上下文理解和推理相关的关键挑战方面的重大进步。通过展示模型在无需外部专家干预的情况下完善自身推理过程的潜力,该研究为持续模型开发提供了一条有希望的途径。所提出的方法不仅提高了多个长上下文推理任务的性能,而且还为人工智能的未来研究提供了框架。这种创新方法对大型语言模型的持续发展具有重大影响,有可能缩小当前人工智能能力与更先进的类人推理之间的差距。
查看这纸和GitHub 页面。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。如果您喜欢我们的工作,您就会喜欢我们的新闻通讯..不要忘记加入我们的 55k+ ML SubReddit。
ðï¸ ðœ大型语言模型漏洞评估:红队技术的比较分析 — 阅读完整报告(已晋升)

Asjad 是 Marktechpost 的实习顾问。他正在卡拉格普尔印度理工学院攻读机械工程学士学位。Asjad 是一位机器学习和深度学习爱好者,一直在研究机器学习在医疗保健中的应用。