
在人工智能领域,越大越好吗?

作者:Jones, Nicola
互联网是人类知识的浩瀚海洋,但它并不是无限的。人工智能(AI)研究人员几乎已经把它吸干了。
过去十年人工智能的爆炸性进步在很大程度上是由使神经网络变得更大并用更多的数据对其进行训练。事实证明,这种扩展在构建大型语言模型 (LLM) 方面出人意料地有效——例如那些为聊天机器人 ChatGPT 提供支持的模型——既更能够复制会话语言,又能够开发推理等新兴属性。但一些专家表示,我们现在正在接近扩展的极限。这部分是因为计算能源需求不断增加。但这也是因为法学硕士开发人员正在耗尽用于训练模型的传统数据集。
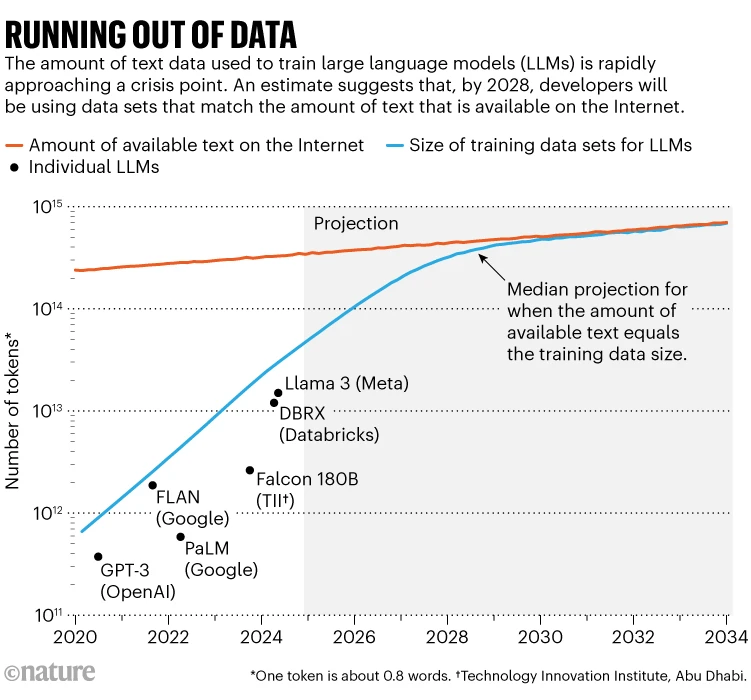
一项著名的研究1今年,虚拟研究机构 Epoch AI 的研究人员预测,到 2028 年左右,用于训练 AI 模型的数据集的典型大小将达到与估计的总数据集相同的大小。公共在线文本库存。换句话说,人工智能很可能大约四年内训练数据就用完了(请参阅“数据耗尽”)。与此同时,数据所有者(例如报纸出版商)开始限制其内容的使用方式,进一步收紧访问权限。剑桥麻省理工学院人工智能研究员谢恩·朗普雷 (Shayne Longpre) 表示,这导致了“数据共享”规模的危机,他领导着数据来源计划 (Data Provenance Initiative),这是一个进行审计的草根组织AI 数据集。
训练数据迫在眉睫的瓶颈可能开始变得紧张。“我强烈怀疑这种情况已经发生了,”朗普雷说。
资料来源:参考文献。1
尽管专家表示这些限制可能会减缓人工智能系统的快速改进,但开发人员正在寻找解决方法。“我认为没有人对大型人工智能公司感到恐慌,”Epoch AI 驻马德里研究员、预测 2028 年数据崩溃研究的主要作者 Pablo Villalobos 说道。——或者至少他们不会给我发电子邮件,如果他们是的话。——
例如,位于加利福尼亚州旧金山的 OpenAI 和 Anthropic 等著名人工智能公司都公开承认了这个问题,同时暗示他们有计划解决这个问题,包括生成新数据和寻找非常规数据源。OpenAI 发言人表示自然:“我们使用多种来源,包括公开数据和非公开数据合作伙伴、合成数据生成以及来自人工智能培训师的数据。”
即便如此,数据紧缩可能会迫使人们构建的生成人工智能模型类型发生剧变,可能会将景观从大型、通用的法学硕士转移到更小、更专业的模型。
LLM在过去十年的发展已经显示出其对数据的贪婪胃口。尽管一些开发商没有公布其最新模型的规格,但 Villalobos 估计,自 2020 年以来,用于训练法学硕士的“代币”或部分单词的数量已增加了 100 倍,从数千亿增加到数十万亿。
在人工智能领域,越大越好吗?
这可能是互联网上的很大一部分,尽管总数如此之大以至于很难确定——Villalobos 估计目前互联网上文本数据的总存量为 3,100 万亿个代币。各种服务使用网络爬虫来抓取这些内容,然后消除重复并过滤掉不需要的内容(例如色情内容)以生成更干净的数据集:一个名为 RedPajama 的常见数据集包含数十万亿个单词。一些公司或学术机构自行进行爬行和清理,以制作定制数据集来培训法学硕士。互联网的一小部分被认为是高质量的,例如可能在书籍或新闻中找到的人工编辑的、社会可接受的文本。
可用互联网内容的增长速度出人意料地缓慢:Villalobos 的论文估计其每年增长不到 10%,而人工智能训练数据集的规模每年增加一倍以上。对这些趋势的预测表明,这些趋势在 2028 年左右会趋于一致。
与此同时,内容提供商越来越多地包含软件代码或完善其使用条款,以阻止网络爬虫或人工智能公司抓取其数据进行训练。Longpre 和他的同事今年 7 月发布了一份预印本,显示阻止特定爬虫访问其网站的数据提供商数量急剧增加2。在三个主要清理数据集中的最高质量、最常用的网络内容中,受爬虫限制的令牌数量从 2023 年的不到 3% 上升到 2024 年的 20-33%。
目前正在进行几起诉讼,试图为人工智能训练中使用的数据提供者赢得赔偿。2023 年 12 月,纽约时报起诉OpenAI及其合作伙伴微软侵犯版权;今年4月,纽约市奥尔登环球资本旗下8家报纸联合提起了类似诉讼。反驳观点是,人工智能应该被允许以与人类相同的方式阅读和学习在线内容,这构成了对材料的合理使用。OpenAI曾公开表示它认为纽约时报诉讼是“没有法律依据的”。
如果法院支持内容提供商应获得经济补偿的观点,那么人工智能开发者和研究人员(包括财力不雄厚的学者)将更难获得他们所需要的东西。“学术界将受到这些交易的最大打击,”朗普雷说。“拥有一个开放的网络有很多非常有利于社会、有利于民主的好处,”他补充道。