

在企业人工智能中,跨多种语言的理解和工作不再是可有可无的——它对于满足全球员工、客户和用户的需求至关重要。
多语言信息检索(跨语言搜索、处理和检索知识的能力)在使人工智能能够提供更准确和全球相关的输出方面发挥着关键作用。
企业可以使用 NVIDIA NeMo Retriever 嵌入和重新排序 NVIDIA NIM 微服务,将其生成式 AI 工作扩展到准确的多语言系统,这些服务现已在NVIDIA API 目录。这些模型可以理解各种语言和格式的信息(例如文档),从而大规模地提供准确的、上下文感知的结果。
借助 NeMo Retriever,企业现在可以:
- 从大型且多样化的数据集中提取知识以获取更多上下文,以提供更准确的响应。
- 将生成式人工智能与全球大多数主要语言的企业数据无缝连接,以扩大用户群体。
- 通过将数据存储效率提高 35 倍,更大规模地提供可操作的情报新技术例如长上下文支持和动态嵌入大小。
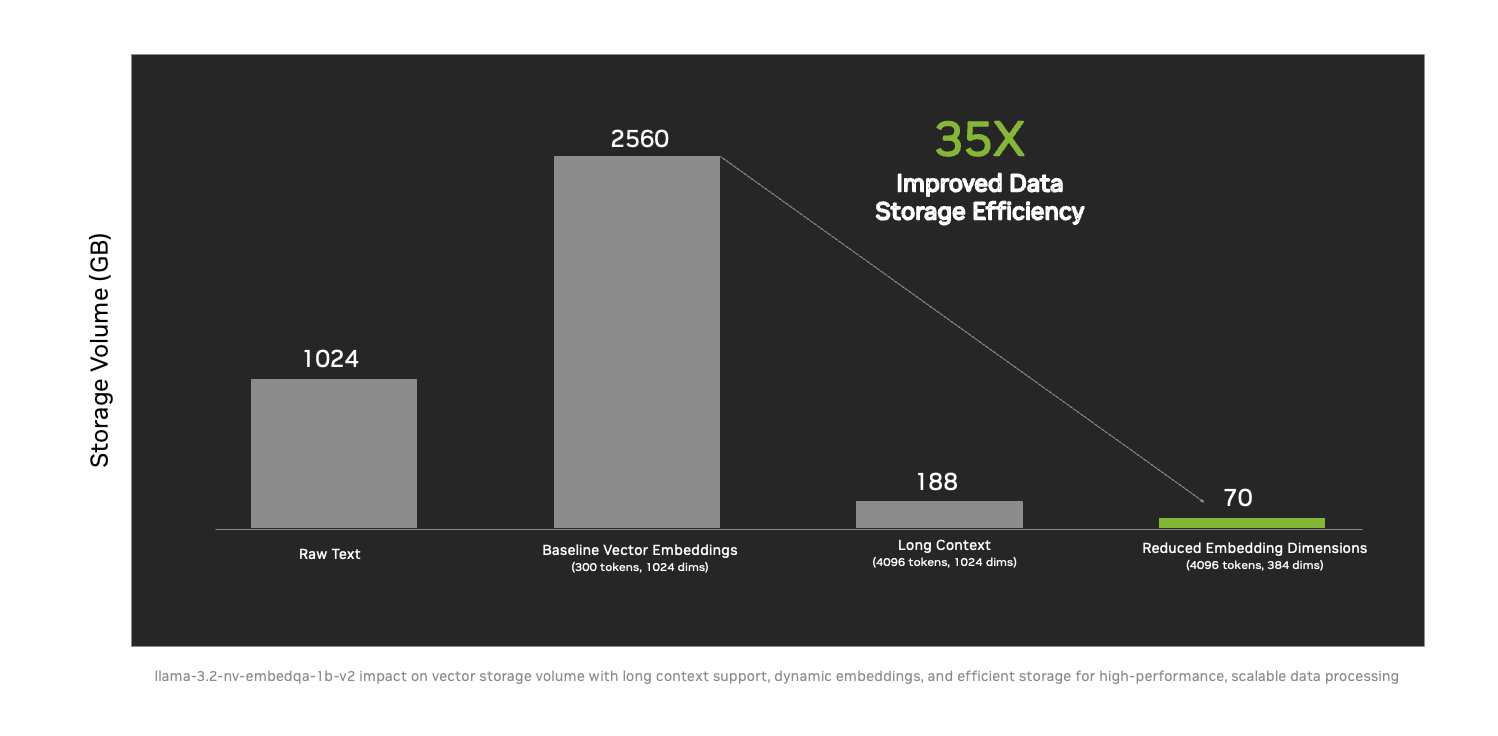
DataStax、Cohesity、Cloudera、Nutanix、SAP、VAST Data 和 WEKA 等领先的 NVIDIA 合作伙伴已经采用这些微服务来帮助各行业的组织将自定义模型安全地连接到多样化的大型数据源。通过使用检索增强生成(抹布)技术,尼莫寻回犬使人工智能系统能够访问更丰富、更相关的信息,并有效地弥合语言和上下文鸿沟。
Wikidata 将数据处理速度从 30 天缩短到不到三天
与合作伙伴数据统计,维基媒体实现了 NeMo Retriever 对维基百科的内容进行矢量嵌入,为数十亿用户提供服务。矢量嵌入 — 或 — 矢量化 — — 是将数据转换为 AI 可以处理和理解的格式的过程,以提取见解并推动智能决策。
维基媒体使用了NeMo 寻回犬嵌入和重新排列 NIM 微服务在三天内将超过 1000 万个维基数据条目矢量化为 AI 就绪格式,而这个过程过去需要 30 天。10 倍的加速实现了对世界上最大的开源知识图谱之一的可扩展的多语言访问。
这个开创性的项目可确保实时更新由数千名贡献者每天编辑的数十万个条目,从而增强开发人员和用户的全球可访问性。凭借 Astra DB 的无服务器模型和 NVIDIA AI 技术,DataStax 产品可提供接近零的延迟和卓越的可扩展性,以支持维基媒体社区的动态需求。
DataStax 正在使用NVIDIA 人工智能蓝图并整合NVIDIA NeMo将定制器、策展人、评估器和 Guardrails 微服务集成到 LangFlow AI 代码生成器中,使开发人员生态系统能够针对其独特的用例优化 AI 模型和管道,并帮助企业扩展其 AI 应用程序。
包容语言的人工智能推动全球商业影响
NeMo Retriever 帮助全球企业克服语言和上下文障碍,释放数据潜力。通过部署强大的人工智能解决方案,企业可以实现准确、可扩展和高影响力的结果。
NVIDIA 的平台和咨询合作伙伴在确保企业能够高效采用和集成生成式 AI 功能(例如新的多语言 NeMo Retriever 微服务)方面发挥着关键作用。这些合作伙伴帮助将人工智能解决方案与组织的独特需求和资源结合起来,使生成式人工智能更容易获得、更有效。它们包括:
- 云时代计划扩大 NVIDIA AI 在 Cloudera AI 推理服务中的集成。目前嵌入了 NVIDIA NIM 的 Cloudera AI Inference 将包括 NVIDIA NeMo Retriever,以提高多语言用例的洞察速度和质量。
- 凝聚力推出了业界首款基于人工智能的生成式对话搜索助手,该助手使用备份数据提供富有洞察力的响应。它使用 NVIDIA NeMo Retriever 重新排名微服务来提高检索准确性,并显着提高各种应用程序的洞察速度和质量。
- 树液正在使用 NeMo Retriever 的基础功能为其 Joule copilot 问答功能和从自定义文档检索的信息添加上下文。
- 海量数据正在与 NVIDIA 合作在 VAST Data InsightEngine 上部署 NeMo Retriever 微服务,以便立即可用于分析新数据。通过捕获和组织实时信息以进行人工智能驱动的决策,可以加速业务洞察的识别。
- 威卡正在将其 WEKA AI RAG 参考平台 (WARRP) 架构与 NVIDIA NIM 和 NeMo Retriever 集成到其低延迟数据平台中,以提供可扩展的多模式 AI 解决方案,每秒处理数十万个代币。
通过多语言信息检索打破语言障碍
多语言信息检索对于企业人工智能满足现实需求至关重要。NeMo Retriever 支持跨多种语言和跨语言数据集高效、准确的文本检索。它专为搜索、问答、摘要和推荐系统等企业用例而设计。
此外,它还解决了企业人工智能中的一项重大挑战——处理大量大型文档。借助长上下文支持,新的微服务可以处理冗长的合同或详细的医疗记录,同时在扩展交互中保持准确性和一致性。
这些功能可帮助企业更有效地使用数据,为员工、客户和用户提供精确、可靠的结果,同时优化资源以实现可扩展性。NeMo Retriever 等先进的多语言检索工具可以使人工智能系统在全球化世界中更具适应性、可访问性和影响力。
可用性
开发人员可以通过以下方式访问多语言 NeMo Retriever 微服务以及其他 NIM 微服务以进行信息检索:NVIDIA API 目录,或免费 90 天NVIDIA 人工智能企业开发者许可证。
了解更多关于新的 NeMo Retriever 微服务以及如何使用它们构建高效的信息检索系统。