
人类-人工智能反馈循环如何改变人类的感知、情感和社会判断
作者:Sharot, Tali
主要的
人类与人工智能 (AI) 系统之间的交互已变得普遍,以前所未有的速度改变着现代社会。一个重要的研究挑战是确定这些相互作用如何改变人类的信念。虽然数十年的研究已经描述了人类如何相互影响1,2,3,AI对人类的影响可能是质和量上不同的。这部分是因为人工智能的判断在几个方面与人类的判断不同(例如,它们往往噪音较小)4)并且因为人类对人工智能判断的感知可能与其他人类不同5,6。在这篇文章中,我们展示了人类如何—人工智能交互影响人类认知。特别是,我们发现,当人类反复与有偏见的人工智能系统互动时,他们会学会自己变得更加有偏见。我们在一系列领域和算法中展示了这一点,包括广泛使用的现实世界文本到图像人工智能系统。
现代人工智能系统依赖于机器学习算法,例如卷积神经网络7(CNN)和 Transformer8,识别大量数据集中的复杂模式,而不需要大量的显式编程。这些系统明显增强了人类在各个领域的自然能力,例如医疗保健9,10,11, 教育12, 营销13和金融14。然而,有充分证据表明,人工智能系统可以在从医疗诊断到招聘决策等领域实现自动化并延续现有的人类偏见15,16,17 号,甚至可能放大这些偏见18,19,20。虽然这个问题已经确定,但迄今为止,一个潜在的更深刻、更复杂的问题在很大程度上被忽视了。随着关键决策越来越多地涉及人工智能和人类之间的协作(例如,人工智能系统协助医生诊断并为人类提供有关各种主题的建议)21,22),这些交互提供了一种机制,通过这种机制,有偏见的人类不仅可以产生有偏见的人工智能系统,而且有偏见的人工智能系统可以改变人类的信念,使他们比最初更加有偏见。这种可能性是通过偏差放大和人类反馈学习的综合预测的,对我们的现代社会具有重大影响,但尚未经过实证检验。
偏差被定义为判断中的系统性错误,它可能在人工智能系统中出现,主要是由于算法训练所用的数据集中嵌入了固有的人类偏见(“偏差中的偏差”)23;另请参见参考文献。24)和/或当数据比另一类更能代表一类时25,26,27。例如,文本到图像技术和大型语言模型等生成式人工智能系统从互联网上的可用数据中学习,而人类生成的数据包含不准确和偏见,即使在存在基本事实的情况下也是如此。结果,这些人工智能系统最终反映了许多人类偏见(例如认知偏见)28,29以及种族和性别偏见30)。当人类随后与这些系统交互时(例如,通过生成图像或文本),他们可能会依次向它们学习。与其他存在偏见(包括社会偏见)的人工智能技术交互,例如基于 CNN 的面部识别算法31、推荐系统32, 招聘工具33和信贷分配工具34,也可能引起类似的循环。此外,即使个人没有直接与人工智能系统交互,而只是观察其输出,人类的偏见也会被放大。事实上,估计有 150 亿张人工智能生成的图像在网上传播35,用户通常在社交媒体、新闻网站和其他数字平台上被动消费。因此,人工智能生成的内容对人类偏见的影响可能会超出这些系统的直接用户。
在这里,通过一系列研究,我们证明,当人类和人工智能互动时,即使是源自人工智能系统或人类的微小感知、情感和社会偏见,也会使人类信念更加偏见,从而可能形成反馈循环。随着时间的推移,随着人类慢慢地向人工智能系统学习,人工智能对人类信仰的影响逐渐被观察到。我们发现人类的放大效应更大—人工智能交互优于人类—人类互动,归因于人类对人工智能的感知和人工智能判断的独特特征。特别是,由于人工智能系统拥有庞大的计算资源,因此它们可能比人类对数据中的微小偏差更加敏感36因此可能更有可能利用它们来提高预测准确性,特别是当数据有噪声时37。此外,经过训练,人工智能系统的判断往往比人类的判断噪音要小4。因此,人工智能系统提供了比人类更高的信噪比,这使得人类能够快速学习,即使信号存在偏差。事实上,如果人工智能被认为优于人类6,38,39(但请参阅参考文献。40),了解其偏见可以被认为是完全理性的。仅当系统中已经存在偏差时,偏差才会被放大:当人类与准确的人工智能系统交互时,他们的判断会得到改善。
结果
人类人工智能反馈循环会放大人类偏见
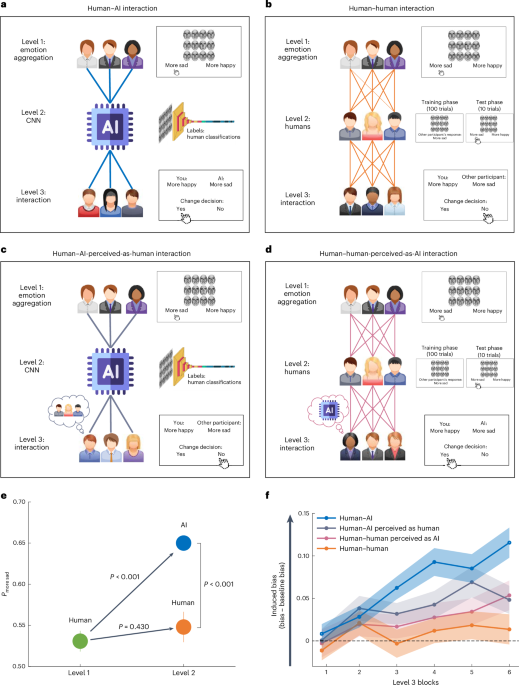
我们首先在情感聚合任务中收集人类数据,其中人类的判断略有偏差。然后,我们证明,在这个略有偏差的数据集上训练人工智能算法会导致算法不仅采用偏差,而且进一步放大偏差。接下来,我们表明,当人类与有偏见的人工智能互动时,他们的初始偏见会增加(图 1)。1a;人类—人工智能交互)。这种偏差放大不会发生在仅包括人类参与者的交互中(图 1)。1b;人与人之间的互动)。
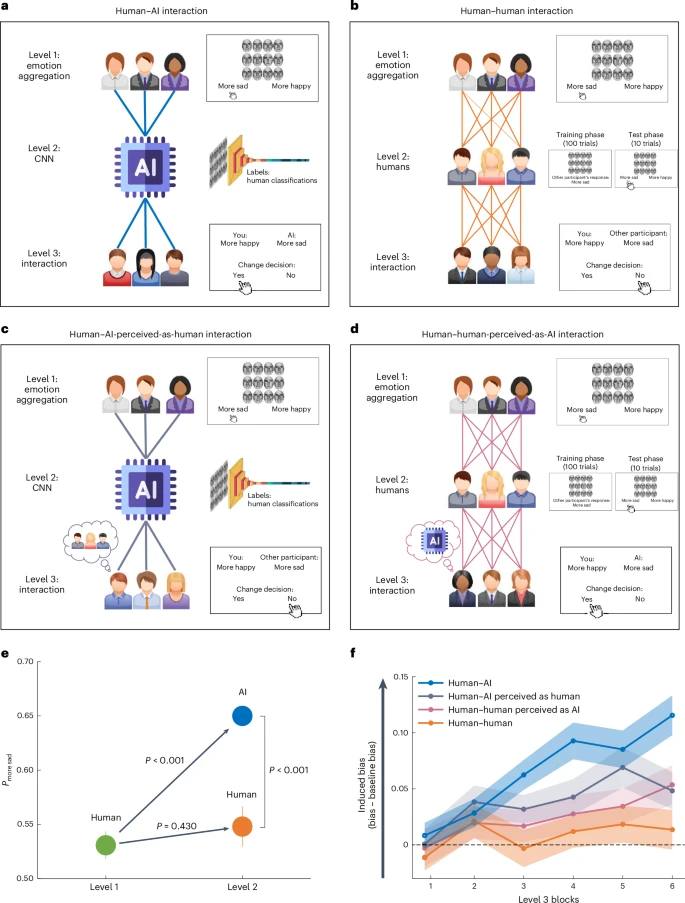
一个,人类—人工智能交互。收集情感聚合任务中的人类分类(第 1 级)并输入 AI 算法(CNN;第 2 级)。然后,新的人类参与者池(第 3 级)与人工智能进行交互。在第 1 级(情绪聚合)期间,参与者会看到一组 12 张面孔,并被要求将面孔表达的平均情绪分类为更悲伤或更快乐。在第 2 级 (CNN) 期间,CNN 根据第 1 级的人类数据进行训练。在第 3 级(人类—AI交互),一组新的参与者提供他们的情绪聚合反应,然后在被问到是否愿意改变他们的初始反应之前会看到人工智能的反应。乙,人与人之间的互动。这在概念上类似于人类与人工智能的交互,只不过人工智能(2 级)被人类参与者取代。向第 2 级参与者呈现第 1 级(训练阶段)参与者的数组和响应,然后自行判断新数组是更悲伤还是更快乐(测试阶段)。然后,向第 3 级的参与者呈现第 2 级人类参与者的响应,并询问他们是否愿意更改其初始响应。c, 人类—人工智能感知为人类交互。这种情况在概念上也类似于人类—人工智能交互条件,除了第 3 级的参与者被告知他们正在与另一个人交互,而实际上他们正在与人工智能系统交互(输入:人工智能;标签:人类)。d,人类与人类感知的人工智能交互。此条件类似于人与人之间的交互条件,不同之处在于,第 3 级的参与者被告知他们正在与 AI 交互,而实际上他们正在与其他人类交互(输入:人类;标签:AI)。e、1 级和 2 级结果。1 级参与者(绿色圆圈;n�=�50) 表现出轻微的偏向于更悲伤的反应。这种偏见在第 2 级(蓝色圆圈)中被人工智能放大,但在第 2 级(橙色圆圈;橙色圆圈;n≤=≤50)。这磷— 值是通过排列检验得出的。所有重要的磷— 应用 Benjamini–Hochberg 错误发现率修正后,值仍然显着α≤=≤0.05。f,3 级结果。当与有偏见的人工智能互动时,随着时间的推移,参与者变得更加偏见(人类与人工智能的互动;蓝线)。相比之下,在与人类互动时没有观察到偏差放大(人与人的互动;橙色线)。当与标记为人类的人工智能(人类 - 人工智能感知为人类交互;灰线)或标记为人工智能的人类(人类 - 人工智能感知为人类交互;粉红色线)进行交互时,参与者会产生偏见有所增加,但低于人类与人工智能的交互(n–= –200 名参与者)。阴影区域和误差线代表 s.e.m。
人类表现出轻微的判断偏差
五十名参与者执行了情感聚合任务(改编自参考文献)。41,42,43,44)。在 100 次试验的每一次中,参与者都会短暂地(500 毫秒)看到一组 12 张面孔,并被要求报告阵列中面孔所表达的平均情绪是更悲伤还是更快乐(图 1)。1a;级别 1)。这些面孔是从包含 50 张变形面孔的数据集中采样的,这些面孔是通过在悲伤和快乐表情之间进行线性插值创建的(方法)。根据变形比例,每张脸的排名从 1(100% 悲伤脸)到 50(100% 快乐脸)。当逐一观察时,这些排名与参与者自己对每张脸的排名密切相关(乙≤=≤0.8;t(50)≤=≤26.25;磷≤<≤0.001;看补充结果)。我们为每个参与者创建了 100 个独特的数组,每组有 12 张面孔。一半数组中12张脸的平均排名小于25.5(因此数组更悲伤),另一半大于25.5(因此数组更快乐)。
该任务中的偏差被定义为参与者在所有试验中的平均反应与实际平均值之间的差异。该任务的实际平均值为 0.5,因为响应被编码为 1(更悲伤)或 0(更快乐),并且恰好有一半的试验更悲伤,一半更快乐。在数学上,偏差表示为:
$${{\rm{偏差}}}=\frac{1}{n}\mathop{\sum }\limits_{i=1}^{n}{C}_{i}-0.5$$
在哪里n表示数据点的总数,C我表示分配给每个数据点的分类(C我�=�1 为更悲伤的分类C我–= –0 以获得更满意的分类)。正偏差表明倾向于将反应分类为更悲伤,而负偏差表明倾向于将反应分类为更快乐。例如,如果参与者将 0.7 个数组分类为更悲伤,则他们的偏差将为 0.7→→0.5→=→0.2,而如果他们将 0.3 个数组分类为更悲伤,则他们的偏差将为 0.7→→0.5→=→0.2。数组更悲伤,他们的偏见是0.3→→0.5→=→0.2。
与之前的研究一致,表明在短编码时间下,对模糊价态的解释更有可能是负面的45,46,参与者表现出轻微但显着的倾向,称面部表情更加悲伤。特别是,他们将 53.08% 的数组归类为更悲伤,这个比例比偶然预期的要大(针对 50% 的排列测试:磷≤=≤0.017;d≤=≤0.34;95% 置信区间 (CI)更悲伤≤=≤0.51至0.56;图中绿色圆圈。1e;参见补充结果用于通过心理测量函数分析估计偏差)。第一个块中的偏差比后续块中的偏差大得多(中号区块1≤=≤56.72%;中号块 2-4≤=≤51.87%;将第一个块与其余块进行比较的排列测试:磷≤=≤0.002;d≤=≤0.46;95% CI=0.02 至 0.08),表明参与者随着时间的推移纠正了他们的偏见。
基于有偏见的人类数据训练的人工智能放大了偏见
接下来,我们使用了 CNN7将每组面孔分类为更快乐或更悲伤。如下所述,CNN 放大了在人类参与者中观察到的分类偏差(参见方法有关模型的更多详细信息)。
首先,为了测试模型的准确性,我们在 1 级中向参与者提供的 5,000 个数组(5,000 个数组=—50 个参与者—100 个数组)上对其进行了训练,类别为基于数组的客观排名分数的标签(即,不是人工标签)。然后,该模型在 300 个样本外测试集上进行评估,显示分类准确率为 96%,这表明该模型非常准确,并且如果在无偏差数据上进行训练,则不会显示偏差(见表)1)。接下来,我们在基于人类分类定义的类标签上训练模型(5,000 个数组样本;图 1)。1a)并在样本外测试集中的 300 个数组上对其进行了评估。该模型将 65.33% 的案例的平均情绪分类为更悲伤,尽管只有 50% 的数组更悲伤。这个数字明显大于偶然预期(针对 50% 的排列测试:磷≤<≤0.001;95%置信区间更悲伤≤=≤0.60至0.71;图中蓝色圆圈1e)并且显着大于在人类数据中观察到的偏差(级别 1),仅为 53%(排列检验:磷≤<≤0.001;d≤=≤1.33;95% CI≤0.09 至 0.14;如图。1e)。换句话说,人工智能算法极大地放大了其训练数据中嵌入的人类偏见。具有不同架构的 CNN 也获得了类似的结果,包括 ResNet50(参考文献 1)。47;看补充结果)。
人工智能偏差放大的一个可能原因是它利用数据中的偏差来提高其预测准确性。当数据有噪声或不一致时,这种情况应该会发生更多。为了检验这个假设,我们使用两组新标签重新训练模型。首先,我们使用无噪音标签(即基于数组的客观排名分数),但通过切换 3% 的标签引起了轻微偏差。因此,53% 的标签被归类为更悲伤。其次,我们使用了非常嘈杂的标签(随机标签),其中我们还引入了 3% 的偏差。如果偏差放大是由于噪声造成的,则后一个模型的偏差应该高于前者。结果证实了这一假设(表1):在具有较小偏差的精确标签上训练的模型的平均偏差恰好是 3%,而在偏差为 3% 的随机标签上训练的模型的平均偏差为 50%(即,分类模型100% 的数组更悲伤)。这些结果表明CNN模型的偏差放大与数据中的噪声有关。
与有偏见的人工智能互动会增加人类偏见
接下来,我们开始研究与有偏见的人工智能算法交互是否会改变人类的判断(图 1)。1a;3级)。为此,我们首先测量了 150 次试验中参与者在情绪聚合任务上的基线表现,以便我们可以比较他们在与人工智能交互后和之前的判断。与第 1 级一样,我们发现参与者一开始有很小的偏见(中号区块1–= –52.23%),在后续区块中下降,(中号2-5 块≤=≤49.23%;排列测试将第一个块与其余块进行测试:磷≤=≤0.03;d≤=≤0.31;95% CI = =0.01 至 0.06)。下一个问题是,与人工智能互动是否会导致偏见在人类身上再次出现,甚至可能加剧。
为了检验这一假设,在 300 次试验中,参与者首先指出这 12 张面孔是更悲伤还是更快乐。然后,他们会看到人工智能对同一阵列的响应(参与者被告知“将看到经过训练来执行任务的人工智能算法的响应”)。然后他们被问到是否愿意改变最初的反应(即从更悲伤到更快乐,反之亦然)。在人工智能提供不同反应的试验中,参与者改变了 32.72% (±2.3%-s.e.) 的反应,在人工智能提供不同反应的试验中,参与者改变了 0.3% (±0.1%-s.e.) 的反应。提供了与他们相同的响应(这些比例显着不同:排列测试:磷≤<≤0.001;d≤=≤1.97;95% CI = =0.28 至 0.37)。进一步研究(补充实验1)表明,当不与任何同事互动时,参与者仅在 3.97% 的试验中改变了决定,这比与不同意见的 AI 互动时要少(排列测试:磷≤<≤0.001;d≤=≤2.53;95% CI = - 0.57 到 - 0.42)并且比与一致的 AI 交互时更高(排列测试:磷≤<≤0.001;d≤=≤0.98;95% CI = =0.02 至 0.05)。
然而,我们感兴趣的主要问题不是参与者在观察人工智能的反应后是否改变了他们的反应。相反,问题在于随着时间的推移,他们自己对阵列的反应(在观察人工智能对特定阵列的响应之前)是否会由于之前与人工智能的交互而变得越来越有偏见。也就是说,随着时间的推移,参与者是否学会变得更加偏见?
事实上,在基线区块中,参与者平均只有 49.9% (±1.1%–s.e.) 的阵列被归类为更悲伤,而当与 AI 交互时,这一比例显着增加到 56.3% (±1.1%–s.e.)s.e.;针对基线的交互块的排列测试:磷≤<≤0.001;d≤=≤0.84;95%置信区间更悲伤≤=≤0.54 至 0.59)。学习偏差随着时间的推移而增加:在第一个交互块中仅为 50.72%,而在最后一个交互块中为 61.44%。这种偏差的增加得到了线性混合模型的证实,该模型预测随着块数(固定因素)的增加,更悲伤的分类率更高,参与者级别的随机截距和斜率(乙≤=≤0.02;t(50)≤=≤6.23;磷≤<≤0.001;如图。1f)。
这些结果证明了算法偏差反馈循环;在一组略有偏差的人类数据上训练人工智能算法会导致算法放大它。其他人与该算法的后续交互进一步增加了人类的初始偏差水平,从而创建了反馈循环。
人与人之间的互动并没有放大偏见
接下来,我们研究了在仅涉及人类的互动中是否会发生相同程度的偏见传染。为此,我们使用了与上面相同的交互结构,只是人工智能系统被人类参与者取代了(图1)。1b)。
人类表现出轻微的判断偏差
人机交互第一级中使用的响应与上述人机交互中使用的响应相同。
经过人类数据训练的人类不会放大偏见
从概念上讲,与人工智能算法训练类似,我们的目标是利用人类数据来训练人类(图 1)。1b;级别 2)。向参与者展示了 100 个包含 12 张面孔的阵列。他们被告知,他们将看到之前执行过该任务的其他参与者的回答。对于 100 个阵列中的每一个,他们观察了从第 1 级伪随机选择的参与者的响应(参见方法了解更多详情)。此后,他们自行评判了十个新阵列(要么更悲伤,要么更快乐)。为了验证参与者是否关注其他 1 级参与者的反应,他们被要求报告 20% 的试验(随机选择)。在超过 10% 的试验中给出错误答案的参与者(因此没有参加任务;n‐=‐14),被排除在实验之外。54.8% 的参与者将阵列描述为更悲伤,这超出了偶然的预期(针对 50% 的排列测试:
磷≤=≤0.007;d≤=≤0.41;95%置信区间更悲伤≤=≤52 至 58%)。重要的是,这个结果与 1 级人类参与者的结果没有什么不同(排列测试 1 级人类与 2 级人类:磷≤=≤0.43;d≤=≤0.11;95% CI=0.02 至 0.06;如图。1e),但显着低于 AI 算法,后者将 65.13% 的数组描述为更悲伤(2 级人类与 2 级 AI 的排列测试:磷≤<≤0.001;d≤=≤0.86;95% CI≤0.07 至≤0.013;如图。1e)。这种差异不太可能是由训练样本大小的变化造成的,因为即使人工智能和人类参与者接受相同数据集的训练,也会观察到这种效果(补充实验2)。此外,结果被推广到不同的训练方法,其中参与者被激励积极预测其他参与者的反应(补充实验3)。
总之,与人工智能不同的是,在接受有偏见的人类数据训练后,人类偏见并没有被放大。这并不奇怪,因为 2 级参与者自然表现出的偏见程度可能与他们接受训练时的偏见程度相同。此外,与人工智能系统不同,人类的判断基于训练课程之外的因素,例如之前的经验和期望。
人与人之间的互动不会增加偏见
接下来,我们公开了新的参与者池(n–= –50) 与人类从第 2 级的判断相比。任务和分析与人类与人工智能交互的第 3 级描述的任务和分析相同(当然,除了参与者与人类交互之外,这他们被告知;1b)。
在接触其他人的反应之前,参与者完成了五个基线块。与第 1 级和第 3 级(人类与人工智能交互)一样,参与者在第一个区块中表现出显着的偏见(米区块1–= –53.67%)随着时间的推移而消失(中号2-5 块≤=≤49.87%;第一个基线块相对于其余基线块的排列测试:磷≤=≤0.007;d≤=≤0.40;95% CI = =0.01 至 0.06)。
接下来,参与者与其他人类参与者进行交互(人与人的交互;级别 2)。正如预期的那样,当其他参与者不同意他们的观点时(11.27±±1.4% - s.e.),参与者对分类的改变比他们同意他们的观点时(0.2±±0.03%)更多。s.e.)(比较两者的排列测试:磷≤<≤0.001;d≤=≤1.11;95% CI = -0.08 至 0.14),并且低于与不同意见的 AI 交互时的置信区间(CI 为 32.72%;排列测试比较与不同意见的 AI 交互时的响应变化与与不同意见的人类交互时的响应变化:磷≤<≤0.001;d≤=≤1.07;95% CI = =0.16 至 0.27)。
重要的是,没有证据表明人与人之间的互动存在习得性偏见(图 1)。1f)。与其他人互动时,分类率没有差异(中号更悲伤-=-51.45-±-1.3%-s.e.)比基线(50.6-±-1.3%-s.e.)(交互块相对于基线的排列测试:磷≤=≤0.48;d≤=≤0.10;95%置信区间更悲伤≤=≤0.01 至 0.03)并且不随时间变化(乙≤=≤0.003;t(50)≤=≤1.1;磷≤=≤0.27)。
总而言之,这些结果表明,人类偏见在人与人工智能的互动中显着放大,比人与人之间的互动更严重。这些发现表明,有偏见的人工智能系统的影响不仅限于它们自己的偏见判断,还包括它们影响人类判断的能力。这引起了人们对不同领域中可能存在偏见的算法的人类交互的担忧。
人工智能的输出和人类对人工智能的感知塑造了其影响力
出现的一个问题是,与人类相比,参与者在与人工智能系统交互时变得更加有偏见,因为人工智能提供了更多有偏见的判断,因为他们对人工智能系统的看法与其他人类不同,或者两者兼而有之。为了解决这个问题,我们进行了两次额外的实验迭代。在第一次迭代中(人工智能被视为人类),参与者与人工智能系统交互,但被告知他们正在与另一个人类参与者交互(图 1)。1c)。在第二次迭代中(人类被视为人工智能),参与者与人工智能系统交互,但被告知他们正在与另一个人类参与者交互(图 1)。1天)。
为此,新的参与者池(n每个条件招募了 �=�50)。首先,他们执行上述基线测试,然后与同事互动(3 级)。当与人工智能(被认为是人类)交互时,参与者的偏见随着时间的推移而增加:在第一个交互块中只有 50.5%,而在最后一个交互块中则为 55.28%(图 1)。1f)。线性混合模型证实了跨块偏差的增加,该模型预测随着块数(固定因素)的增加,更悲伤的分类率更高,参与者级别的随机截距和斜率(乙≤=≤0.01;t(50)≤=≤3.14;磷–< –0.001)。人类与人类感知的人工智能交互也获得了类似的结果。正如线性混合模型所证实的那样,各区块的偏差有所增加(从第一个区块的 49.0% 增加到最后一个区块的 54.6%)(乙≤=≤0.01;t(50)≤=≤2.85;磷≤=≤0.004;如图。1f)。在这两种情况下,偏差都大于基线(人类——人工智能被认为是人类:中号偏见≤=≤3.85(与基线比较的排列检验:磷≤=≤0.001;d≤=≤0.49;95% CI≤0.02 至 0.06);人类——人类被视为人工智能:中号偏见≤=≤2.49(与基线比较的排列检验:磷≤=≤0.04;d≤=≤0.29;95% CI=-0.01 至 0.05))。
引起的偏见是输入类型(人工智能与人类)还是对该输入的感知(被视为人工智能与被视为人类)的结果?为了调查这一点,我们将诱导偏差分数(更悲伤的判断的百分比减去更悲伤的判断的基线百分比)提交到 2(输入:人工智能与人类) - 2(标签:人工智能与人类)以时间(模块 1-6)作为协变量的方差分析 (ANOVA)(图 1)。1f)。结果揭示了输入和时间之间的相互作用(F(4.55, 892.35)→=→3.40;磷–= –0.006) 以及标签和时间之间 (F(4.55, 892.35)→=→2.65;磷≤=≤0.026)。此外,还有输入的主效应(F(1, 196)≤=≤9.45;磷≤=≤0.002) 和时间 (F(4.55, 892.35)→=→14.80;磷–< –0.001)。没有其他显着影响(所有磷— 值 —> —0.06)。因此,如图所示。1f随着时间的推移,人工智能的输入及其标签都加剧了人类的偏见。
最后,我们评估了参与者的决策改变率。当他们的同事不同意他们的观点时,参与者更有可能改变他们的分类。在人类——人工智能感知为人类的互动中,当存在分歧时,决策改变的发生率为 16.84%(±1.2%——s.e.),而这一比例仅为 0.2%(±0.05%)s.e.)当同意时(比较两者的排列测试:磷≤<≤0.001;d≤=≤1.22;95% CI = =0.13 至 0.20)。同样,对于人类——人类感知为人工智能的情况,当存在分歧时,观察到决策变化的比例为 31.84%(±2.5%——s.e.),而在存在分歧时,这一比例为 0.4%(±0.1%——s.e.)。)在一致的情况下(比较两者的排列测试:磷≤<≤0.001;d≤=≤1.7;95% CI = =0.26 至 0.36)。
为了量化在出现分歧时输入和标签对决策变更的影响,我们将决策变更的百分比提交为 2(输入:人工智能与人类)–2(标签:人工智能与人类)方差分析以时间(块 1-6)作为协变量。结果显示,人工智能的输入(F(1, 196)≤=≤7.05;磷–= –0.009) 及其标签 (F(1, 196)−=−76.30;磷–< –0.001) 增加了决策改变的可能性。在应用韦尔奇修正来解决方差同质性假设的违规问题后,这些结果保持一致:对于人工智能的输入F(1, 197.92)−=−5.11 且磷–= –0.02 以及 AI 的标签F(1, 175.57)−=−74.21 且磷≤<≤0.001。所有其他主要影响和相互作用都不显着(所有磷— 值 —> —0.13)。
有偏差的算法会影响决策,而准确的算法会改善决策
接下来,我们试图将上述结果推广到不同类型的算法和领域。特别是,我们的目标是模仿这样一种情况:人类不是先验偏见,而是人工智能因其他原因而出现偏见(例如,如果它接受了不平衡数据的训练)。为此,我们采用了随机点运动图(RDK)任务的变体48,49,50,51,其中向参与者展示了一系列移动的点,并要求参与者估计从左向右移动的点的百分比,范围从 0%(没有点从左向右移动)到 100%(所有点从左向右移动)从左到右)。为了估计基线表现,参与者首先自己执行 RDK 任务 30 次试验,并以从完全不自信到非常自信的范围报告他们的信心(图 1)。2a)。在所有试验中,向右移动的点的实际平均百分比为 50.13±±20.18% (s.d.),与 50% 没有显着差异(针对 50% 的排列测试:磷≤=≤0.98;d≤=≤0.01;95% CI=±42.93 至 57.33%),平均置信度为 0.56±±0.17 (s.d.)。

,基线块。参与者执行 RDK 任务,其中呈现一系列移动点,持续 1 秒。他们估计了从左向右移动的点的百分比并报告了他们的置信度。乙,算法。参与者与三种算法进行交互:准确(蓝色分布)、有偏差(橙色分布)和噪声(红色分布)。c,交互块。参与者提供了他们的独立判断和信心(自定进度),然后观察他们自己的反应和一个问号,其中人工智能算法的反应稍后会出现。参与者被要求为他们的反应和算法的反应分配权重(自定进度)。此后,算法的响应被揭示(2秒)。请注意,人工智能算法的响应仅在参与者表明其权重后才会显示。因此,他们不得不依赖基于之前试验的人工智能全球评估。d,人工智能引起的偏见。与有偏见的人工智能交互会导致相对于基线的显着人类偏见(磷以红色显示的值)以及相对于与其他算法的交互(磷值以黑色显示;n≤=≤120)。e,当与有偏见的算法交互时,人工智能引起的偏见会随着时间的推移而增加(n≤=≤50)。f,AI引起的精度变化。与准确的人工智能交互导致人类准确性相对于基线显着提高(即减少错误)(磷以红色显示的值)以及相对于与其他算法的交互(磷值以黑色显示;n≤=≤120)。克,当与准确的算法交互时,AI 引起的准确性会随着时间的推移而增加(n≤=≤50)。小时,我,参与者认为准确的算法对其判断的影响最大(小时;n–= –120),尽管精确算法和有偏差算法的实际影响是相同的(我;n≤=≤120)。细灰色线和圆圈对应于各个参与者。在d和f,圆圈对应于组平均值,中心线代表中值,底部和顶部边缘分别是第 25 个和第 75 个百分位数。在e和克,误差线代表 s.e.m。这磷— 值是通过排列检验得出的。所有重要的磷— 应用 Benjamini–Hochberg 错误发现率修正后,值仍然显着α≤=≤0.05。为了检查不同的算法响应模式是否以及如何影响人类决策,我们使用了三种简单的算法:准确、有偏差和噪声。准确的算法始终指示从左向右移动的点的正确百分比(图 1)。
2b;蓝色分布)。有偏差的算法提供了对向右移动的点的系统性向上偏差估计(图 1)。2b;橙色分布;中号偏见–= –24.96)。噪声算法提供的响应等于精确算法加上高斯噪声的响应(s.d.≤=≤30;图 1)。2b;红色分布)。有偏差和有噪声的算法具有相同的绝对误差(方法)。这里使用的算法是硬编码的,以允许完全控制他们的响应。
在每次试验中,参与者首先提供他们的判断和信心,然后观察他们自己的反应和一个问号,其中算法反应稍后会出现(图 1)。2c)。他们被要求为自己的回答和算法的回答分配权重,权重范围从 100% 你到 100% AI(方法)。因此,如果参与者分配的权重为w根据他们自己的回应,最终的共同决定将是:$$\begin{数组}{l}{{\rm{最终}}\;
{\rm{关节}}\;{\rm{决定}}}\\=w \times({{\rm{参与者}}}\mbox{'}{{\rm{s}}\; {\rm{响应}}})+(1-w)\times\,({{\rm{AI}}}\mbox{'}{{\rm{s}}\; {\rm{响应}}})\end{数组}$$
这个加权任务类似于实验1中的变更决策任务;然而,在这里我们使用连续量表而不是二元选择,使我们能够对参与者的判断进行更精细的评估。
参与者提供答案后,AI 算法的反应就会揭晓(图 1)。2c)。请注意,只有在参与者表明自己的权重后,人工智能算法的反应才会被曝光。这样做是为了防止参与者依赖算法在特定试验中的具体响应,而是让他们依赖对算法的全局评估。参与者与每种算法进行了 30 次交互试验。算法的顺序(偏差、噪声或准确)被平衡。
RDK 任务中的偏差定义如下:
$${\rm{偏差}}=\frac{{\sum }_{i=1}^{n}({\rm{参与者}}\mbox{'}{\rm{s}}\,{\rm{响应}}_{i}-{\rm{证据}}_{i})}{n}$$
在哪里我和n分别对应于当前试验的索引和试验总数。证据对应于图中向右移动的点的百分比我第-次审判。为了计算人工智能引起的参与者偏差,我们从交互块中的偏差中减去了基线块中参与者的偏差。
$${{\rm{AI}}{\mbox{-}}{\rm{诱导}}\;{\rm{偏差}}}={{\rm{偏差}}}_{{{\rm{AI}}\;{\rm{互动}}\;{\rm{块}}}}-{{\rm{偏差}}}_{{{\rm{基线}}}}$$
在群体水平上,未检测到基线响应的系统偏差(基线平均响应=±0.62;针对 0 的排列检验:磷≤=≤0.28;d≤=≤0.1;95% CI=0.48 至 1.76)。
为了定义准确性,我们首先计算每个参与者的错误分数:
$${\rm{错误}}=\frac{{\sum }_{i=1}^{n}|{\rm{参与者}}\mbox{'} s\,{\rm{响应}}_{i}-{\rm{证据}}_{i}|}{n}$$
然后,从基线块中的错误分数中减去该数量,表明准确性的变化。
$${{\rm{AI}}{\mbox{-}}{\rm{诱导}}\;{\rm{准确度}}\;{\rm{变化}}}={{\rm{错误}}}_{{{\rm{基线}}}}-{{\rm{错误}}}_{{{\rm{AI}}\;{\rm{互动}}\;{\rm{块}}}}$$
也就是说,如果与人工智能交互时的误差(第二个数量)小于基线误差(第一个数量),则变化将为正值,表明参与者变得更加准确。然而,如果与人工智能交互时的错误(第二个数量)大于基线期间(第一个数量),则变化将为负,表明参与者在与人工智能交互时变得不太准确。
结果显示,相对于基线表现,参与者在与有偏差的算法交互时变得更加有偏见(向右)(中号偏见(有偏见的AI)≤=≤2.66 且中号偏差(基线)≤=≤0.62;排列测试:磷≤=≤0.002;d≤=≤0.28;95% CI≤0.76 至 3.35;如图。2d)并且相对于与精确算法交互时(中号偏差(准确的AI)≤=≤1.26;排列测试:磷≤=≤0.006;d≤=≤0.25;95% CI≤0.42 至 2.37;如图。2d)和噪声算法(中号偏见(嘈杂的人工智能)≤=≤1.15;排列测试:磷≤=≤0.006;d≤=≤0.25;95% CI≤0.44 至 2.56;如图。2d)。在准确算法和噪声算法之间没有发现偏差差异,在与这些算法交互时相对于基线性能也没有发现偏差差异(所有磷— 值 —> —0.28)。参见补充结果用于在逐项试验的基础上分析人工智能引起的偏差。
人工智能引起的偏差在后续研究中得到了重复(n≤=≤50;方法)其中参与者专门与跨五个区块的有偏见的算法进行交互(中号偏见≤=≤5.03;排列测试:磷≤<≤0.001;d≤=≤0.72;95% CI≤3.14 至 6.98;如图。2e)。至关重要的是,我们发现随着时间的推移存在显着的线性关系(乙≤=≤1.0;t(50)≤=≤2.99;磷≤=≤0.004;如图。2e),表明参与者与有偏见的算法交互越多,他们的判断就越有偏见。人工智能引起的偏见学习也得到了计算学习模型的支持(补充型号)。
与基线性能相比,与准确算法的相互作用提高了参与者独立判断的准确性(中号错误(准确的AI)= 13.48,中号错误(基线)= 15.03和中号准确性变化(准确的AI)= 1.55;置换测试:磷<0.001;d= 0.32;95%ci = 0.69至2.42;如图。2f)并与与偏置算法相互作用时进行比较(中号错误(偏见AI)= 14.73和中号准确性变化(偏见AI)= 0.03;置换测试:磷<0.001;d= 0.33;95%ci = 0.58至1.94;如图。2f)和嘈杂的算法(中号错误(嘈杂的AI)= 14.36和中号准确性变化(嘈杂的AI)= 0.67;置换测试:磷= 0.01;d= 0.22;95%ci = 0.22至1.53;如图。2f)。在偏见和嘈杂算法之间没有发现诱导准确性变化的差异,与基线性能相对于这些算法相互作用时,错误也没有差异(所有磷值> 0.14;如图。2f)。
AI诱导的准确性变化在后续研究中得到了复制(n= 50;方法)其中参与者仅在五个块上与精确算法进行相互作用(中号准确性更改= 3.55;置换测试:磷<0.001;d= 0.64;95%ci = 2.14至5.16;如图。2克)。至关重要的是,我们发现随着时间的流逝,AI引起的精度变化有显着的线性关系(乙= 0.84;t(50)= 5.65;磷<0.001;如图。2克),表明参与者与准确算法相互作用的次数越多,他们的判断就越准确。对于参与者的信心评级和体重分配决策,请参阅补充结果。
重要的是,与精确AI相互作用时准确性的提高不能归因于参与者复制算法的准确响应,而与偏见算法相互作用时的偏见不能归因于复制算法的参与者,该算法的偏见响应响应是偏见的响应。。这是因为我们有目的地设计任务,以便参与者在观察算法的响应之前在每个审判中表明他们的判断。取而代之的是,参与者学会了在前一种情况下提供更准确的判断,并学会了在后一种情况下提供更多有偏见的判断。
参与者低估了有偏见的算法的影响
我们试图探索参与者是否意识到算法对它们的重大影响。为了测试这一点,要求参与者评估他们认为他们的回答在多大程度上受到与他们相互作用的不同算法的影响(方法)。如图所示。2小时,参与者报告说,与有偏见的算法相比,准确算法更受到精确算法的影响(置换测试:磷<0.001;d= 0.57;95%ci = 0.76至1.44)和嘈杂的一个(置换测试:磷<0.001;d= 0.58;95%ci = 0.98至1.67)。参与者如何看待偏见和嘈杂算法的影响之间没有明显差异(排列测试:磷= 0.11;d= 0.15;95%ci = 0.05至0.52)。
但是,实际上,与偏置算法相互作用时,它们变得更加偏见的大小等于它们在与精确算法相互作用时它们变得更加准确的幅度。我们使用两种不同的方法量化了影响(方法)并且两者都揭示了相同的结果(图。2i;z - 跨算法划分:置换测试:磷= 0.90;d= 0.01;95%ci = 0.19至0.17;相对于基线的百分比差异:置换测试:磷= 0.89;d= 0.02;95%ci = 1.44至1.90)。
这些结果表明,在不同的范式中,在不同的响应方案下,与偏见的算法偏见相互作用会使参与者独立的判断。此外,与准确的算法相互作用提高了参与者独立判断的准确性。令人惊讶的是,参与者没有意识到偏见算法对他们的强烈影响。
现实世界中的AI引起的社会判断偏见
到目前为止,我们已经证明,与偏见的算法相互作用会导致在基于感知和情感的任务中更加偏见的人类判断。这些任务允许进行精确的测量,并促进了我们分解影响的能力。接下来,我们旨在通过使用现实世界中常用的AI系统将这些发现推广到社会判断中,从而提高了我们结果的生态有效性52,53,54(另请参见补充实验5对于检查社会判断任务的受控实验)。为此,我们检查了与稳定扩散的相互作用后,对人类判断的更改55。
最近的研究报告说,稳定的扩散会扩大现有的社会失衡。例如,与其他人口群体相比30,56。这样的偏见可能来自不同的来源,包括有问题的培训数据和/或缺陷的内容审核技术30。稳定的扩散输出用于不同的应用程序,例如视频,广告和业务演示文稿。因此,即使个人不直接与AI系统互动,而只是观察其输出(例如,在社交媒体上,广告中或同事的演讲中,这些输出也可能影响人类信念系统)。在这里,我们测试与稳定扩散的输出相互作用是否增加了人类判断中的偏见。
为了测试这一点,我们首先提示稳定的扩散来创建:财务经理的颜色照片,头像,高质量的照片(方法)。如预期的那样,相对于人口中的代表,稳定扩散产生的图像过多的白人(占图像的85%)。例如,在美国,只有44.3%的财务经理是男人57,其中一小部分是白色的,在英国只有大约一半是男人58,其中一部分是白色的。在其他西方国家,白人的金融经理的百分比也不到85%,在许多非西方国家,这些人数甚至可能更低。
接下来,我们进行了一个实验(n= 100)要检查参与者对谁最有可能成为财务经理的判断如何在与稳定扩散进行互动后会改变。为此,在与稳定扩散互动之前和之后,参与者完成了100次试验。在每次审判中,都会向他们展示来自不同种族和性别群体的六个人的图像:(1)白人;(2)白人妇女;(3)亚洲男人;(4)亚洲妇女;(5)黑人;(6)黑人妇女(见图。3a;阶段1;基线)。图像取自芝加哥面部数据库59并且在年龄,吸引力和种族典型性方面保持平衡(方法)。在每个审判中,都要求参与者:哪个人最有可能成为财务经理?他们的回应是单击其中一个图像。在此之前,为参与者提供了财务经理的定义(方法)。我们对参与者的反应在与稳定的扩散输出互动后是否会吸引白人。

,实验设计。该实验包括三个阶段。在第1阶段,参与者的图像展示了来自不同种族和性别群体的六个人:白人,一个白人妇女,一个亚洲男人,一个亚洲女人,一个黑人男人和黑人妇女。在每个审判中,参与者选择了他们认为最有可能成为财务经理的人。在第2阶段,对于每个试验,由稳定扩散产生的三张财务经理的图像随机选择并呈现给参与者。在对照条件下,向参与者提供了三张分形图像。在第3阶段,参与者从第1阶段重复了任务,从而可以测量参与者在接触AI生成的图像之前的选择变化。乙,结果表明,参与者倾向于在暴露于AI生成的图像后选择白人作为财务经理,而在暴露于分形中性图像(对照)之后,参与者的倾向则显着增加。错误条代表S.E.M.面对刺激一个从参考文献中复制。59在创意共享许可下抄送4.0。在与稳定扩散互动之前,参与者选择了白人,白人女性,亚洲男性,亚洲妇女,黑人男性和黑人女性32.36、14.94、14.40、20.24、6.64、6.64和11.12%的时间分别为时间。
尽管这里没有确切的基础真相,但根据人口统计数据,白人估计不是规范性的回应(有关详细信息,请参阅补充结果)。接下来,将参与者暴露于稳定扩散的输出中(见图。3a;第2阶段;接触)。具体而言,参与者被告知,将向他们展示三张由AI(稳定扩散)产生的财务经理的图像,并收到了有关稳定扩散的简短说明(方法)。然后,在每个试验中,参与者都查看了三张财务经理的图像,这些图像是从稳定扩散产生的1.5 s产生的图像中随机选择的。这个简短的曝光时间模仿了社交媒体,新闻网站和广告等平台上的AI生成的内容的常见现实世界互动。这种相遇通常是简短的,用户迅速滚动浏览内容。例如,移动设备上图像的平均查看时间为1.7(参考。60)。
在第3阶段(图。3a;阶段3;暴露后),参与者从第1阶段重复了任务。感兴趣的主要衡量标准是参与者的判断的变化。使用混合模型的多项式逻辑回归分析数据,并作为固定因素(在接触AI图像之后与接触AI图像之后)进行分析,并在参与者级别进行随机拦截和斜率。之所以选择该模型,是因为因变量涉及从六个不同和无序类别中的选择(请参阅补充结果用于替代分析)。
调查结果显示对暴露有重大影响(F(5,62)= 5.89;磷<0.001;如图。3b),表明暴露于AI图像改变了人类判断。特别是,接触增加了选择白人作为财务经理的可能性(中号曝光前= 32.36%;中号接触后与白人妇女相比,= 38.20%)(中号曝光前= 14.94%;中号接触后= 14.40%;乙= 0.26;t= 2.08;磷= 0.04;95%ci = 0.01至0.50),亚洲妇女(中号曝光前= 20.24%;中号接触后= 17.14%;乙= 0.47;t= 3.79;磷<0.001;95%ci = 0.22至0.72),黑人(中号曝光前= 6.64%;中号接触后= 5.62%;乙= 0.65;t= 3.04;磷= 0.004;95%ci = 0.22至1.08)和黑人妇女(中号曝光前= 11.12%;中号接触后= 10.08%;乙= 0.47;t= 2.46;磷= 0.02;95%CI = 0.09至0.87)。白人和亚洲男人之间没有发现显着差异(中号曝光前= 14.70%;中号接触后= 14.56%;乙= 0.28;t= 2.01;磷= 0.051;95%ci = 0.001至0.57)。
我们还与另一组参与者进行了这项实验,以控制订单效应。这些控件从未暴露于财务经理的稳定扩散图像。取而代之的是,它们暴露于分形的中性图像(见图。3a;第2阶段;接触)。对照条件与治疗条件进行了相同的分析。正如预期的那样,在对照条件下未发现暴露于中性分形的显着影响(F(5,67)= 1.69;磷= 0.15;如图。3b)。此外,比较白人时没有观察到显着差异(中号曝光前= 28.42%;中号接触后每个人口组(全部)磷值> 0.06):白人妇女(中号曝光前= 15.64%;中号接触后= 15.36%),亚洲男人(中号曝光前= 12.00%;中号接触后= 11.18%),亚洲妇女(中号曝光前= 20.52%;中号接触后= 19.74%),黑人(中号曝光前= 8.78%;中号接触后= 9.30%)和黑人妇女(中号曝光前= 14.64%;中号接触后= 17.14%)。治疗和对照组的比较表明,在接触图像相对于以前的图像后选择白人时,前者的增加比后者大(比较置换测试比较跨组选择白人的变化:磷= 0.02;d= 0.46;95%ci = 0.01至0.13)。
这些结果表明,与常用的AI系统相互作用,该系统扩大了现实世界中的不平衡引起人类的偏见。至关重要的是,该实验中的AI系统牢固地植根于现实世界。稳定的扩散估计有1000万用户每天产生数百万张图像61,强调这种现象的重要性。这些发现在后续实验中复制了,对任务进行了轻微的更改(请参阅补充实验6)。
讨论
我们的发现表明,人AI相互作用会产生一个反馈回路,即使从任一侧出现的小偏见也会增加随后的人为错误。首先,AI算法放大了嵌入在培训的人类数据中的微小偏差。然后,与这些偏见算法的相互作用增加了最初的人类偏见。人类的互动没有观察到类似的效果。与AI不同,人类没有扩大数据中最初的小偏差,这可能是因为人类对数据中的次要偏见不太敏感,而AI则利用它们来提高其预测准确性(请参阅表1)。
AI引起的偏见的效果被推广到一系列算法(例如CNN和文本形象生成AI),任务和响应方案,包括运动歧视,情绪汇总和基于社会的偏见。随着时间的流逝,随着参与者反复与偏见的AI系统进行互动,他们的判断变得更加有偏见,这表明他们学会了采用AI系统的偏见。使用计算建模(补充模型),我们表明,人类从与AI算法的互动中学习以变得有偏见,而不仅仅是通过AI的判断本身。有趣的是,参与者低估了偏见算法对其判断的实质影响,这可能使他们更容易受到影响。
我们进一步证明了利用流行的现实AI系统稳定扩散的实验中的偏置反馈回路。当提示产生高功率和高收入专业人士的图像时30。在这里,我们表明暴露于这种稳定的扩散图像会偏见人类的判断。当个人直接与稳定扩散与/或遇到由稳定扩散在各种数字平台上(例如社交媒体和新闻网站)上创建的图像时,这可能发生在现实世界中。
总之,当前的一系列实验表明了人类的反馈回路,使人类比最初更有偏见,这既是AI的信号,又是由于人类对AI的看法62。这些发现超出了先前关于AI偏置扩增的研究18,19,20,63,64,65,66,揭示了与各种AI系统和决策环境(例如招聘或医学诊断)可能相关的问题。
当前的结果发现了人AI相互作用中偏置扩增的基本机制。因此,他们强调了算法开发人员在设计和部署AI系统时必须面对的高度责任。AI算法不仅可以表现出偏见,而且还可以扩大人类与它们相互作用的偏见,从而产生深刻的反馈回路。由于AI系统的广泛范围和迅速增长的流行率,这些含义可以广泛。特别关注的是偏见的AI对儿童的潜在影响67,他们具有更灵活和可延展的知识表示形式,因此可能会更容易采用AI系统。
重要的是要澄清,我们的发现并不建议所有AI系统都是有偏见的,也不建议所有AI人类互动都会造成偏见。相反,我们证明,当人类与准确的AI相互作用时,他们的判断变得更加准确(与表明人AI相互作用的研究一致68)。相反,结果表明,当系统中存在偏见时,它可能会通过反馈循环扩增。由于人类和AI系统都存在偏见,因此这是一个应该认真对待的问题。
我们的结果表明,参与者很容易学到了AI系统的偏见,这主要是由于AI判断的特征,也是由于参与者对AI的看法(见图。1f;有关广泛的讨论,请参见参考。62)。具体而言,我们观察到,当告诉参与者正在与人互动时,实际上他们正在与AI互动时,他们比他们认为与AI互动的程度较小的程度(尽管他们确实仍然大量学习偏见)。这可能是因为参与者认为AI系统在任务上优于人类6,38。因此,即使参与者以一种可能被认为是完全理性的方式更新信念的偏见。
当前发现提出的一个有趣的问题是,观察到的偏见的放大是否会随着时间的流逝而持久。需要进一步的研究来评估这种效果的寿命。几个因素可能会影响偏见的持续性,包括暴露于偏见的AI的持续时间,偏见的显着性和AI系统感知的个体差异69。但是,即使暂时的影响也可能带来重大的后果,特别是考虑到人类AI相互作用的规模。
总之,AI系统越来越多地整合到众多域中,因此了解如何在减轻其相关风险的同时有效地使用它们至关重要。当前的研究表明,有偏见的算法不仅会产生偏见的评估,而且会在人类判断中实质上扩大了这种偏见,从而产生了反馈循环。这强调了迫切需要提高研究人员,决策者和公众对AI系统如何影响人类判断的认识。旨在提高对AI系统引起的潜在偏见的认识的策略可能会减轻应测试的选择。重要的是,我们的结果还表明,与精确的AI算法相互作用会提高准确性。因此,减少算法偏见可能具有减少人类偏见的潜力,从而提高了从健康到法律的领域中人类判断的质量。
方法
道德声明
这项研究是按照所有相关道德法规进行的,并获得了伦敦大学学院伦理委员会的批准(3990/003和EP_2023_013)。在参与研究之前,所有参与者均提供了知情同意。
参加者
共有1,401个人参加了这项研究。对于实验1(1级),n= 50名(32名女性和18名男性;中号年龄= 38.74±11。17年(S.D.)。对于实验1(人类; 2级),n= 50(23名女性,25名男性和2名未报告;中号年龄= 34.58±11.87岁(S.D.)。对于实验1(人类AI; 3级),n= 50(24名女性,24名男性和2名未报告;中号年龄= 39.85±14.29岁(S.D.)。对于实验1(人类;第3级),n= 50(20名女性和30名男性;中号年龄= 40.16±13.45岁(S.D.)。对于实验1(人AI被视为人类; 3级),n= 50(15名女性,30名男性,4名未报告和1个非二元;中号年龄= 40.16±13.45岁(S.D.)。对于实验1(人类被视为AI; 3级),n= 50名(18名女性,30名男性,一名未报告,一个非二元;中号年龄= 34.79±10。80年(S.D.))。对于实验2,n= 120(57名妇女,60名男性,另一名男性,两名未报告;中号年龄= 38.67±13.19岁(S.D.)。对于实验2(准确算法),n= 50(23名女性和27名男性;中号年龄= 36.74±13.45岁(S.D.)。对于实验2(偏置算法),n= 50(26名妇女,23名男性和一名未报告;中号年龄= 34.91±8.87岁(S.D.))。对于实验3,n= 100(40名女性,56名男性和4名未报告;中号年龄= 30.71±12.07年(S.D.)。用于补充实验1,n= 50(26名女性,17名男性和7个未报告;中号年龄= 39.18±14.01岁(S.D.)。用于补充实验2,n= 50(24名女性,23名男性,另一个男人,两名未报告;中号年龄= 36.45±12。97年(S.D.)。用于补充实验3,n= 50名(20名女性,29名男性和一名未报告;中号年龄= 32.05±10.08岁(S.D.))。用于补充实验4,n= 386(241名女性,122名男性,七个和16个未报告;中号年龄= 28.07±4。65年(S.D.))。用于补充实验5,n= 45(19名妇女,23名男性,另一名男子,两名未报告;中号年龄= 39.50±14.55岁(S.D.)。用于补充实验6,n= 200(200名女性,98名男性,五名和12名未报告;中号年龄= 30.87±10.26岁(S.D.)。
根据试验研究确定样本量,以实现0.8的能力(±= 0.05)使用g*power70。在每个实验中,最大n使用检测关键效果所需的并舍入。参与者是通过多产的招募的(https://prolific.com/)并收到,以换取参与,直到2022年4月,每小时支付7.50英镑,此后付款增加到每小时9.00英镑。此外,实验1和2的参与者收到的奖金费用从0.50英镑到2,00英镑,这是根据绩效确定的。所有参与者的视力均正常或矫正至正常。实验是在Psychopy3(2022.2.5)中设计的,并在Pavlovia平台上托管(https://pavlovia.org/)。
任务和分析
情绪汇总任务
人类的互动
对于1级,参与者进行了100项情绪聚集任务的试验。在每次试验中,从悲伤到快乐的阵列阵列,持有500毫秒的介绍(图。1a)。参与者表明,平均而言,面孔更快乐还是更悲伤。向每个参与者提供100个独特的面孔,如下所述生成。
为了产生该任务中使用的个体面孔,参考文献中总共采用了50个变形的灰度面孔。41。这些面孔是通过匹配多个面部特征(例如,嘴角和眼角)在同一个人的极端悲伤和快乐表达之间(取自Ekman Gallery的极端悲伤和快乐的表情)创建的。71),然后在它们之间线性插值。根据变形比例,变形的面部范围从1(100%悲伤的面孔)到50(100%快乐的面孔)。每张面部的这些客观排名得分与参与者对面部表达的情感的主观看法息息相关。这是通过向参与者展示面对面一一来确定的,然后才能执行情感汇总任务,并要求他们按比例从非常悲伤到非常快乐(自节奏)的面孔进行评分。面孔的客观排名与参与者的主观评估之间的线性回归表明,参与者对情绪表达高度敏感(乙= 0.8;t(50)= 26.25;磷<0.001;右2= 0.84)。产生了100个情感面孔的100个阵列,如下所示。
对于阵列的50个,在间隔[1,50]中以平均值为25.5的间隔中,从均匀分布中随机采样了12个面(重复)。然后,对于这些阵列中的每个阵列,都创建了一个镜像阵列,其中每个面的排名得分等于原始试验中面部的排名分数等于51。例如,如果原始数组中的面孔的排名分数为21、44,25,则镜子阵列中的面孔的排名分数为51â=â=â30,51â€44 = 7,51 25 = 26。该方法确保在试验的一半中,阵列的客观平均排名高于均匀分布的平均值(平均值> 25.5;更快乐的面孔),而在另一半则较低(平均值)<25.5;如果阵列的客观平均排名恰好为25.5,则重新采样了。
情绪汇总任务的偏见定义为超过50%以上的更可悲的反应的百分比。如结果,在小组级别,参与者表现出将面部阵列分类为更悲伤的趋势(对50%的排列测试:磷= 0.017;d= 0.34;95%置信区间更悲伤= 0.51至0.56)。当使用心理测量功能分析对偏差进行定量时,观察到了相似的结果(请参阅补充结果了解更多详情)。
对于第2级,级别1(5,000个选择)中参与者的选择被送入CNN中,该CNN由五个卷积层组成(滤波器大小为32、64、128、256、512,并构成晶状线性单元(relu)激活功能)和三个完全连接的密集层(图。1a)。使用了0.5的辍学率。CNN的预测是在由300个新阵列面(即训练或验证集中未包含的阵列)组成的测试集上计算的。测试组中的一半的阵列的客观平均排名得分高于25.5(即更快乐的分类),而另一半的得分低于25.5(即更悲伤的分类)。
对于第3级,参与者首先执行了在第1级中描述的相同的程序,除了他们进行了150次试验,而不是100次试验。这些试验用于衡量参与者在情绪汇总任务中的基线表现。然后,参与者像以前的实验一样执行了情绪聚集任务。但是,在每个试验中,在指示他们的选择后,还向他们呈现了AI算法的响应2(图。1a)。然后,询问参与者是否想通过单击“是或否”按钮来更改他们的决定(即从更悲伤到更快乐,反之亦然)(图。1a)。在与AI互动之前,参与者被告知他们将向他们提供了经过训练执行任务的AI算法的响应。总体而言,参与者进行了300次试验,分为六个街区。
人类的互动
对于第1级,人类人类相互作用的第一层的反应与人类AI相互作用中的反应相同。
对于第2级,参与者首先执行了与1级相同的步骤。接下来,向他们提供了100个阵列的12个面,500 sms,然后是另一个参与者从1级到同一阵列的响应对于2 s(图。1b)。在每个试验中,在屏幕底部介绍了其他参与者(直到该试验)的更悲伤和更快乐的分类的总数。在第1级的50名参与者中的每个参与者中的每个参与者中,对两个试验进行了两个试验。对第一个试验进行了随机采样,第二个试验是其匹配的镜像试验。对响应进行采样,使它们保留了完整集合的偏差和准确性(偏差和准确性差异不超过1%)。
为了验证参与者参加任务,他们被要求报告其他玩家对20%的试验的反应,这些试验是随机选择的(也就是说,他们被询问了其他玩家的反应?来自进一步分析的参与者的数据低于90%的参与者的数据(n= 14名参与者)缺乏参与任务。完成实验的这一部分后,参与者再次自行执行了十项试验。
对于第3级,参与者执行了与人AI相互作用所述相同的程序(第3级),除了他们在这里与人类同事而不是AI助理进行了互动。
从人类网络(2级)对人类同事的反应进行了伪随机采样,因此从每个参与者中对六个响应进行了伪随机采样(总共300次试验)。在与人类同事互动之前,参与者将被告知他们将向其他已经执行该任务的参与者的回应介绍。
人类感知到人类的互动
对于第1级,第一层的反应与人类和人类人类互动的反应相同。
2级与人类AI相互作用中的级别相同。
对于第3级,参与者执行了与人类相互作用完全相同的程序。唯一的区别是,虽然他们被认为是他们将得到已经执行任务的另一个参与者的反应,但他们实际上与在第二级中接受过培训的AI系统进行了互动。
人类感知到的互动
第一层的反应与人类和人类人类互动的反应相同。
第二层与人类互动中的相同。
对于第3级,参与者执行了与人AI相互作用完全相同的程序。唯一的区别是,虽然他们被认为是他们将获得经过训练执行任务的AI算法的响应,但实际上,他们实际上与2级的参与者进行了互动。
RDK任务
主要实验
对于本实验的基线部分,参与者执行了RDK任务的版本48,49,50,51在30个试验中。在每个试验中,向参与者介绍了一系列在灰色背景下移动的100个白点。On each trial, the percentage of dots moving from left to right was one of the following: 6, 16, 22, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50 (presented twice), 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 78, 86 or 96%.The display was presented for 1 s and then disappeared.Participants were asked to estimate the percentage of dots that moved from left to right on a scale ranging from 0% left to right to 100% left to right, as well as to indicate their confidence on a scale ranging from not confident at all to very confident (Fig.2a,顶部面板)。
Interaction blocks were then introduced. On each trial, participants first performed the RDK task exactly as described above. Then, they were presented with their response (Fig.2c) and a question mark where the AI algorithm response would later appear. They were asked to assign a weight to each response on a scale ranging between 100% you to 100% AI (self-paced). The final joint response was calculated according to the following formula:
$$\begin{array}{l}{{\rm{Final}}\; {\rm{joint}}\; {\rm{response}}}\\=w\times({{\rm{participant}}}\mbox{'}{{\rm{s}}\; {\rm{response}}})+(1-w)\times({{\rm{AI}}}\mbox{'}{{\rm{s}}\; {\rm{response}}})\end{array}$$
在哪里wis the weight the participants assigned to their own response. For example, if the response of the participant was 53% of the dots moved rightward and the response of the AI was 73% of the dots moved rightward and the participants assigned a weight of 40% to their response, the final joint response was 0.4 × (53%) + 0.6 × (73%) = 65% of the dots moved rightward. Note that because the AI response was not revealed until the participants indicated their weighting, participants had to rely on their evaluation of the AI based on past trials and could not rely on the response of the AI on that trial. Thereafter, the AI response was revealed and remained on screen for 2 s. Participants completed three blocks each consisting of 30 trials.
The participants interacted with three different algorithms: an accurate algorithm, a biased algorithm and a noisy algorithm (Fig.2b)。The accurate algorithm provided the correct response on all trials.The biased algorithm provided a response that was higher than the correct response by 0–49% (mean bias = 24.96%).The noisy algorithm provided responses similar to those of the accurate algorithm, but with the addition of a considerable amount of Gaussian noise (s.d. = 28.46).The error (that is, the mean absolute difference from the correct response) of the biased and noisy algorithms was virtually the same (24.96 and 25.33, respectively).
The order of the algorithms was randomized between participants using the Latin square method with the following orders: (1) accurate, biased, noisy; (2) biased, noisy, accurate; and (3) noisy, accurate, biased. Before interacting with the algorithms, participants were told that they “will be presented with the response of an AI algorithm that was trained to perform the taskâ€. Before starting each block, participants were told that they would interact with a new and different algorithm. The algorithms were labelled algorithm A, algorithm B and algorithm C. At the end of the experiment, the participants were asked the following questions: (1) “To what extent were your responses influenced by the responses of algorithm A?â€; and (2) “How accurate was algorithm A?â€. These questions were repeated for algorithms B and C. The response to the first question was given on a scale ranging from not at all (coded as 1) to very much (coded as 7) and the response to the second question was given on a scale ranging from not accurate at all (coded as 1) to very accurate (coded as 7). To assist participants in distinguishing between the algorithms, each algorithm was consistently represented with the same font colour (A, green; B, blue; C, purple) throughout the whole experiment.
We used three main dependent measures: bias, accuracy (error) and the weight assigned to the AI evaluations.Bias was defined as the mean difference between a participant’s responses and the correct percentage of dots that moved from left to right.For each participant, the bias in the baseline block was subtracted from the bias in the interaction blocks.The resulting difference in bias was compared against zero.Positive values indicated that participants reported more rightward movement in the interaction blocks than at baseline, whereas negative values indicated the opposite.Error was defined as the mean absolute difference between a participant’s responses and the correct percentage of dots that moved from left to right.In all analyses, for each participant, the error in the interaction blocks was subtracted from the error in the baseline blocks.Thus, positive values of this difference score indicated increased accuracy due to interaction with the AI, whereas negative values indicated reduced accuracy.The weights assigned to the AI evaluations were defined as the average weight participants assigned to the AI response on a scale ranging from −1 (weight of 0% to the AI response) to 1 (weight of 100% to the AI response)。
The influences of the biased and accurate algorithms were quantified using two different methods: relative changes andz-scoring across algorithms. The relative change in bias was computed by dividing the AI-induced bias by the baseline bias, while the relative change in accuracy was computed by dividing the AI-induced accuracy change by the baseline error. A comparison of the relative changes in bias and accuracy yielded no significant difference (permutation test:磷 = 0.89;d = −0.02; 95% CI = −1.44 to 1.9). The same result was obtained forz-scoring across algorithms. In this method, wez-scored the AI-induced bias of each participant when interacting with each algorithm (that is, for each participant, wez-scored across algorithms and not across participants). Therefore, three z-scores were obtained for each participant, indicating the relative effect of the biased, accurate and noisy algorithms. The same procedure was repeated for the AI-induced accuracy, resulting in threez-scores indicating the relative influences of the different algorithms on the accuracy of each participant.然后,z-scores of the bias algorithm (for the AI-induced bias) and thez-scores of the accurate algorithm (for the AI-induced accuracy change) were compared across participants. No significant difference was found between them (permutation test:磷 = 0.90;d = −0.01; 95% CI = −0.19 to 0.17).
Effects across time
To examine the AI-induced bias and accuracy effects across time, we conducted two additional experiments. In the first one, participants performed the RDK task exactly as described above, except for one difference. Instead of interacting with accurate, biased and noisy algorithms, participants interacted only with a biased algorithm across five blocks. The second experiment was similar to the first, except for participants interacting with an accurate algorithm across five blocks.
实验3
This experiment aimed to investigate whether exposure to images generated by the popular AI system Stable Diffusion55, which is known to exemplify social imbalances30, increases judgement bias in humans. To assess this, participants completed a judgement task before and after viewing Stable Diffusion-generated images. Their performance was compared with that of a control group in which participants were presented with fractals images.
程序
A total of 100 participants were recruited for the experiment. Participants were randomly assigned to either the AI exposure group (n = 50) or a control fractal exposure group (n = 50).The study comprised three stages.In stage 1 (baseline assessment), the participants completed 100 trials in which they were shown an image featuring six individual headshots and were asked: “Who do you think is more likely to be a financial manager?†(see Fig。
3a;stage 1).Participants made their selection by clicking on the chosen image using their computer mouse.Before this stage, participants were provided with a definition of a financial manager (“a person responsible for the supervision and handling of the financial affairs of an organizationâ€; taken from the Collins Dictionary).
In stage 2 (exposure), participants in the AI condition completed 100 trials in which they were presented with Stable Diffusion-generated images of financial managers (three images per trial). The three images were randomly chosen and presented for 1.5 s. Before viewing the images, participants were presented with a brief description of Stable Diffusion. Participants in the control group were shown fractal images instead of financial manager images.
In stage 3 (post-exposure), participants completed 100 trials in which the judgement task from stage 1 was repeated.
The order of the trials was randomized for all stages across participants.
刺激
The stimuli in each trial consisted of images of six individuals (a White man, a White woman, an Asian man, an Asian woman, a Black man and a Black woman) selected from the Chicago Face Database (see the GitHub repository for the exact images used)59。From each demographic category, ten images of individuals aged 30–40 years were chosen.The chosen individuals were balanced in age, attractiveness and racial prototypicality (all磷 values > 0.16). Each image was presented against a grey background with a circle framing the face (see Fig.3a)。The locations of the individuals from each demographic group in the image within each trial were randomly determined.
In the AI exposure condition, Stable Diffusion (version 2.1) was used to generate 100 images of financial managers, using the prompt: “A color photo of a financial manager, headshot, high-qualityâ€. Images that contained multiple people, unclear faces or distortions were replaced with other images of the same race and gender. The control condition featured 100 fractal images of the same size and resolution as the images of the financial managers. Thirty naive observers categorized the faces according to race and gender (Cohen’sκ = 0.611). Each image was ultimately classified based on the majority categorization across the 30 participants. Of the Stable Diffusion-generated images, 85% were classified as White men, 11% as White women, 3% as non-White men and 1% as non-White women.
统计分析
All of the statistical tests were two sided. Mean comparisons utilized non-parametric permutation tests, with磷 values computed using 105random shuffles. When parametric tests were employed, normality was assumed based on the central limit theorem, as all conditions had sufficiently large sample sizes to justify this assumption. In repeated measures ANOVAs, the assumption of sphericity was tested using Mauchly’s test. In case of violation, Greenhouse–Geisser correction was applied. The equality-of-variances assumption was tested using Levene’s test. In case of violation, Welch correction was applied.
报告摘要
Further information on research design is available in theNature Portfolio Reporting Summarylinked to this article.
数据可用性
The data that support the findings of this study are available athttps://github.com/affective-brain-lab/BiasedHumanAI。参考
Centola, D. The spread of behavior in an online social network experiment.
科学第329章 , 1194–1197 (2010).文章
一个 中科院一个 考研一个 谷歌学术一个 Moussaïd, M., Herzog, S. M., Kämmer, J. E. & Hertwig, R. Reach and speed of judgment propagation in the laboratory.过程。
国家科学院。科学。美国 114, 4117–4122 (2017).
周,B.等人。Realistic modelling of information spread using peer-to-peer diffusion patterns.纳特。哼。行为。 4, 1198–1207 (2020).
Kahneman, D., Sibony, O. & Sunstein, C. R.噪音:人类判断力的缺陷(Hachette UK, 2021).
Araujo, T., Helberger, N., Kruikemeier, S. & de Vreese, C. H.In AI we trust? Perceptions about automated decision-making by artificial intelligence.人工智能协会。 35, 611–623 (2020).
Logg, J. M., Minson, J. A. & Moore, D. A. Algorithm appreciation: people prefer algorithmic to human judgment.Organ Behav.哼。决定。过程。 151, 90–103 (2019).
LeCun, Y.、Bengio, Y. 和 Hinton, G. 深度学习。自然 第521章, 436–444 (2015).
瓦斯瓦尼,A.等人。您所需要的就是关注。在过程。神经信息处理系统的进展 30 (NIPS 2017)。5998–6008 (Curran Associates, 2017).
Hinton, G. Deep learning-a technology with the potential to transform health care.J. Am.医学。副教授。 320, 1101–1102 (2018).
Loftus, T. J. et al. Artificial intelligence and surgical decision-making.贾玛外科医师。 155, 148–158 (2020).
Topol, E. J.High-performance medicine: the convergence of human and artificial intelligence.纳特。医学。 25, 44–56 (2019).
Roll, I. & Wylie, R. Evolution and revolution in artificial intelligence in education.国际。J.阿蒂夫。英特尔。教育。 26, 582–599 (2016).
Ma, L. & Sun, B. Machine learning and AI in marketing – connecting computing power to human insights.国际。J.Res。市场。 37, 481–504 (2020).
Emerson, S., Kennedy, R., O’Shea, L. & O’Brien, J. Trends and applications of machine learning in quantitative finance.在过程。8th International Conference on Economics and Finance Research(SSRN, 2019).
Caliskan, A., Bryson, J. J. & Narayanan, A. Semantics derived automatically from language corpora contain human-like biases.科学 第356章, 183–186 (2017).
Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations.科学 第366章, 447–453 (2019).
Omiye, J. A.、Lester, J. C.、Spichak, S.、Rotemberg, V. 和 Daneshjou, R. 大语言模型传播基于种族的医学。NPJ 数字。医学。 6, 195 (2023).
Hall, M., van der Maaten, L., Gustafson, L., Jones, M. & Adcock, A. A systematic study of bias amplification.预印本于https://doi.org/10.48550/arXiv.2201.11706(2022)。
Leino, K., Fredrikson, M., Black, E., Sen, S. & Datta, A. Feature-wise bias amplification.预印本于https://doi.org/10.48550/arXiv.1812.08999(2019)。
Lloyd, K. Bias amplification in artificial intelligence systems.预印本于https://doi.org/10.48550/arXiv.1809.07842(2018)。
Troyanskaya, O. et al. Artificial intelligence and cancer.纳特·癌症 1, 149–152 (2020).
Skjuve, M., Brandtzaeg, P. B. & Følstad, A. Why do people use ChatGPT?探索生成式对话人工智能的用户动机。第一个星期一 29(2024);https://doi.org/10.5210/fm.v29i1.13541
Mayson, S. G. Bias in, bias out.Yale Law J. 128, 2218–2300 (2019).
谷歌学术一个
Peterson, J. C., Uddenberg, S., Griffiths, T. L., Todorov, A. & Suchow, J. W. Deep models of superficial face judgments.过程。国家科学院。科学。美国 119, e2115228119 (2022).
Geirhos, R. et al.ImageNET-trained CNNs are biased towards texture;增加形状偏差可以提高准确性和鲁棒性。预印本于https://doi.org/10.48550/arXiv.1811.12231(2022)。
Benjamin, A., Qiu, C., Zhang, L.-Q., Kording, K. & Stocker, A. Shared visual illusions between humans and artificial neural networks.在Proc 2019 Conference on Cognitive Computational Neuroscience(2019)。
Henderson, M. & Serences, J. T. Biased orientation representations can be explained by experience with nonuniform training set statistics.J. 维斯。 21, 1–22 (2021).
Binz, M. & Schulz, E. Using cognitive psychology to understand GPT-3.过程。国家科学院。科学。美国 120, e2218523120 (2023).
Yax, N., Anlló, H. & Palminteri, S. Studying and improving reasoning in humans and machines.交流。心理。 2, 51 (2024).
Luccioni, A. S., Akiki, C., Mitchell, M. & Jernite, Y. Stable bias: evaluating societal representations in diffusion models.副词。神经信息。过程。系统。 36(2024)。
Buolamwini,J。&Gebru,T。性别阴影:商业性别分类的交叉准确性差异。过程。马赫。学习。资源。 81, 1–15 (2018).
谷歌学术一个
Morewedge, C. K. et al. Human bias in algorithm design.纳特。哼。行为。 7, 1822–1824 (2023).
Dastin, J. Amazon scraps secret AI recruiting tool that showed bias against women.路透社 https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G(2018)。
Nasiripour, S. & Natarajan, S. Apple co-founder says Goldman’s apple card algorithm discriminates.彭博社(10 November 2019).
Valyaeva, A. AI has already created as many images as photographers have taken in 150 years.Everypixel Journal https://journal.everypixel.com/ai-image-statistics(2024)。
Griffiths, T. L. Understanding human intelligence through human limitations.趋势认知。科学。 24, 873–883 (2020).
Geirhos, R. et al. Shortcut learning in deep neural networks.纳特。马赫。英特尔。 2, 665–673 (2020).
Bogert, E., Schecter, A. & Watson, R. T. Humans rely more on algorithms than social influence as a task becomes more difficult.科学。代表。 11, 8028 (2021).
Hou, Y. T. Y. & Jung, M. F. Who is the expert? Reconciling algorithm aversion and algorithm appreciation in AI-supported decision making.过程。ACM 嗡嗡声。计算。相互影响。 5, 1–25 (2021).
Dietvorst, B. J., Simmons, J. P. & Massey, C. Algorithm aversion: people erroneously avoid algorithms after seeing them err.J.Exp。心理。将军 144, 114–126 (2015).
Haberman, J., Harp, T. & Whitney, D. Averaging facial expression over time.J. 维斯。 9, 1–13 (2009).
Whitney, D. & Yamanashi Leib, A. Ensemble perception.安努。心理学牧师。 69, 105–129 (2018).
Goldenberg, A., Weisz, E., Sweeny, T. D., Cikara, M. & Gross, J. J. The crowd–emotion–amplification effect.心理。科学。 32, 437–450 (2021).
Hadar, B., Glickman, M., Trope, Y., Liberman, N. & Usher, M. Abstract thinking facilitates aggregation of information.J.Exp。心理。将军 151, 1733–1743 (2022).
Neta, M. & Whalen, P. J. The primacy of negative interpretations when resolving the valence of ambiguous facial expressions.心理。科学。 21, 901–907 (2010).
Neta, M. & Tong, T. T. Don’t like what you see? Give it time: longer reaction times associated with increased positive affect.情感 16, 730–739 (2016).
何K.,张X.,任S.和孙J.图像识别的深度残差学习。预印本于https://doi.org/10.48550/arXiv.1512.03385(2015)。
Bang, D., Moran, R., Daw, N. D. & Fleming, S. M. Neurocomputational mechanisms of confidence in self and others.纳特。交流。 13, 4238 (2022).
Kiani, R., Hanks, T. D. & Shadlen, M. N. Bounded integration in parietal cortex underlies decisions even when viewing duration is dictated by the environment.J.神经科学。 28, 3017–3029 (2008).
Newsome, W. T., Britten, K. H. & Movshon, J. A. Neuronal correlates of a perceptual decision.自然 第341章, 52–54 (1989).
Liang, G., Sloane, J. F., Donkin, C. & Newell, B. R. Adapting to the algorithm: how accuracy comparisons promote the use of a decision aid.认知。资源。王子。隐含的。 7, 14 (2022).
Campbell, D. T. Factors relevant to the validity of experiments in social settings.心理。公牛。 54, 297–312 (1957).
Kihlstrom, J. F. Ecological validity and “ecological validityâ€.透视。心理。科学。 16, 466–471 (2021).
Orne, M. On the social psychology of the psychological experiment.是。心理。 17 号, 776–783 (1962).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models.预印本于https://doi.org/10.48550/arXiv.2112.10752(2022)。
Bianchi, F. et al.Easily accessible text-to-image generation amplifies demographic stereotypes at large scale.预印本于https://doi.org/10.48550/arXiv.2211.03759(2023)。
Labor Force Statistics from the Current Population Survey(US Bureau of Labor Statistics, 2022);https://www.bls.gov/cps/aa2022/cpsaat11.htm
Women in Finance Director Positions(Office for National Statistics, 2021);https://www.ons.gov.uk/aboutus/transparencyandgovernance/freedomofinformationfoi/womeninfinancedirectorpositions
Ma, D. S., Correll, J. & Wittenbrink, B. The Chicago face database: a free stimulus set of faces and norming data.行为。资源。方法 47, 1122–1135 (2015).
Capturing attention in feed: the science behind effective video creative.Facebook IQ https://www.facebook.com/business/news/insights/capturing-attention-feed-video-creative(2016)。
Stability AI.Celebrating one year(ish) of Stable Diffusion … and what a year it’s been!(2024);https://stability.ai/news/celebrating-one-year-of-stable-diffusion
Glickman, M. & Sharot, T. AI-induced hyper-learning in humans电流。意见。心理。 60, 101900 (2024).
Zhao, J., Wang, T., Yatskar, M., Ordonez, V. & Chang, K. W. Men also like shopping: reducing gender bias amplification using corpus-level constraints.在过程。2017 Conference on Empirical Methods in Natural Language Processing(Association for Computational Linguistics, 2017).
Dinan, E. et al.Queens are powerful too: mitigating gender bias in dialogue generation.在过程。2020 Conference on Empirical Methods in Natural Language Processing(Association for Computational Linguistics, 2020).
Wang, A. & Russakovsky, O. Directional bias amplification.过程。马赫。学习。资源。 139, 2640–3498 (2021).
谷歌学术一个
Mansoury, M., Abdollahpouri, H., Pechenizkiy, M., Mobasher, B. & Burke, R. Feedback loop and bias amplification in recommender systems.预印本于https://doi.org/10.48550/arXiv.2007.13019(2020)。
Kidd,C。和Birhane,A。AI如何扭曲人类的信念。科学 380,1222 - 1223(2023)。
Tschandl, P. et al. Human–computer collaboration for skin cancer recognition.纳特。医学。 26, 1229–1234 (2020).
Pataranutaporn, P., Liu, R., Finn, E. & Maes, P. Influencing human–AI interaction by priming beliefs about AI can increase perceived trustworthiness, empathy and effectiveness.纳特。马赫。英特尔。 5, 1076–1086 (2023).
Erdfelder, E., FAul, F., Buchner, A. & Lang, A. G. Statistical power analyses using G*Power 3.1: tests for correlation and regression analyses.行为。资源。方法 41, 1149–1160 (2009).
Ekman, P. & Friesen, W. V. Measuring facial movement.环境。心理。Nonverbal Behav. 1, 56–75 (1976).
致谢
We thank B. Blain, I. Cogliati Dezza, R. Dubey, L. Globig, C. Kelly, R. Koster, T. Nahari, V. Vellani, S. Zheng, I. Pinhorn, H. Haj-Ali, L. Tse, N. Nachman, R. Moran, M. Usher, I. Fradkin and D. Rosenbaum for critical reading of the manuscript and helpful comments.T.S.is funded by a Wellcome Trust Senior Research Fellowship (214268/Z/18/Z).资助者在研究设计、数据收集和分析、出版决定或手稿准备中没有任何作用。
道德声明
利益竞争
作者声明没有竞争利益。
同行评审
同行评审信息
自然人类行为thanks Emily Wall and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
附加信息
Publisher’s note施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
补充资料
权利和权限
开放获取本文根据知识共享署名 4.0 国际许可证获得许可,该许可证允许以任何媒介或格式使用、共享、改编、分发和复制,只要您对原作者和来源给予适当的认可,并提供链接到知识共享许可证,并指出是否进行了更改。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by/4.0/。转载和许可
引用这篇文章

Glickman, M., Sharot, T. How human–AI feedback loops alter human perceptual, emotional and social judgements.
Nat Hum Behav(2024)。https://doi.org/10.1038/s41562-024-02077-2
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41562-024-02077-2