

微软和牛津大学的这篇人工智能论文介绍了奥林巴斯:用于计算机视觉任务的通用任务路由器
作者:Afeerah Naseem
计算机视觉模型在解决对象检测、分割和分类等单独任务方面取得了重大进展。自动驾驶汽车、安全和监控、医疗保健和医疗成像等复杂的现实应用需要多个视觉任务。然而,每个任务都有自己的模型架构和需求,使得统一框架内的高效管理成为重大挑战。当前的方法依赖于训练单个模型,因此很难将其扩展到需要组合这些任务的实际应用程序。研究人员在牛津大学和微软设计了一个新颖的框架,奥林巴斯,旨在简化各种视觉任务的处理,同时实现更复杂的工作流程和高效的资源利用。
传统上,计算机视觉方法依赖于特定于任务的模型。这些模型专注于一次有效地完成一项任务。然而,每个任务需要单独的模型会增加计算负担。多任务学习模型是存在的,但经常面临任务平衡不佳、资源效率低下以及复杂或代表性不足的任务性能下降的问题。因此,需要一种新的方法来解决可扩展性问题,动态适应新场景,并有效利用资源。
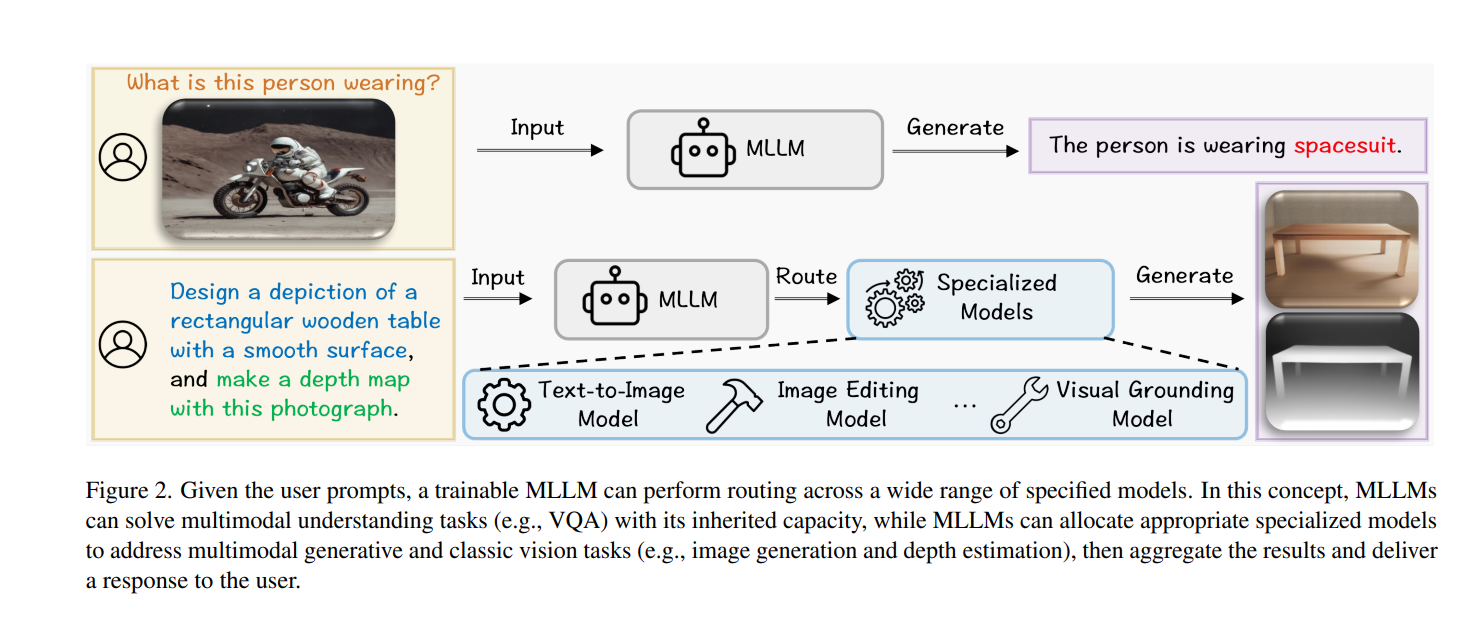
所提出的框架 Olympus 的核心是一个控制器,即多模式大型语言模型 (MLLM),负责理解用户指令并将其路由到适当的专用模块。奥林巴斯的主要特点包括:
- 任务感知路由:控制器 MLLM 分析传入的任务,并有效地将它们重新路由到最合适的专用模型,以优化计算资源。
- 可扩展框架:它可以同时处理多达 20 个任务,无需单独的系统,并与现有 MLLM 有效集成。
- 知识共享:奥林巴斯的不同组件相互分享所学到的知识,最大限度地提高输出效率。
- 行动链能力:奥林巴斯可以处理多种视觉任务,并且高度适应复杂的现实应用。
奥林巴斯在各种基准测试中都表现出了令人印象深刻的性能。它在 20 个单独的任务中实现了 94.75% 的平均路由效率,在需要多个任务完成一条指令的场景中实现了 91.82% 的精度。模块化路由方法能够以最少的重新训练添加新任务,展示了其可扩展性和适应性。
奥林巴斯:用于计算机视觉任务的通用任务路由器标志着计算机视觉领域的重大飞跃。其创新的任务感知路由机制和模块化知识共享框架解决了多任务学习系统中的低效率和可扩展性挑战。通过在链式动作场景中实现令人印象深刻的路由准确性、精确度以及跨不同视觉任务的可扩展性,奥林巴斯将自己打造为适用于各种应用的多功能且高效的工具。虽然需要进一步探索边缘情况任务、延迟权衡和现实世界验证,但奥林巴斯为更加集成和适应性更强的系统铺平了道路,挑战了传统的特定于任务的模型范式。通过进一步的开发和实施,奥林巴斯可以改变不同领域处理复杂视觉问题的方式。这将为未来计算机视觉和人工智能的发展提供坚实的基础。
查看这纸和GitHub 页面。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。不要忘记加入我们的 60k+ ML SubReddit。
ðě 趋势:LG AI Research 发布 EXAONE 3.5:三个开源双语前沿 AI 级模型,提供无与伦比的指令跟踪和长上下文理解,以实现卓越生成 AI 的全球领导地位……。

Afeerah Naseem 是 Marktechpost 的咨询实习生。她正在卡拉格普尔的印度理工学院 (IIT) 攻读学士学位。她对数据科学充满热情,并对人工智能在解决现实问题中的作用着迷。她喜欢发现新技术并探索它们如何使日常任务变得更轻松、更高效。