

认识 CoMERA:先进的张量压缩框架,重新定义速度和精度的 AI 模型训练
作者:Asif Razzaq
训练 Transformer 和语言模型等大规模 AI 模型已成为 AI 中不可或缺但要求很高的过程。这些模型拥有数十亿个参数,提供了突破性的功能,但在计算能力、内存和能耗方面代价高昂。例如,OpenAI 的 GPT-3 包含 1750 亿个参数,需要数周的 GPU 训练。如此巨大的需求将这些技术限制在拥有大量计算资源的组织中,加剧了人们对能源效率和环境影响的担忧。应对这些挑战对于确保人工智能进步的更广泛可及性和可持续性至关重要。
训练大型模型的低效率主要源于它们对密集矩阵的依赖,这需要大量的内存和计算能力。现代 GPU 对优化的低精度或低秩运算的支持有限,进一步加剧了这些要求。虽然已经提出了一些方法(例如矩阵分解和启发式降级)来缓解这些问题,但它们的实际适用性受到限制。例如,GaLore 可以在单批次设置上进行训练,但会受到不切实际的运行时开销的影响。 同样,采用低秩适配器的 LTE 在大规模任务的收敛方面也遇到了困难。由于缺乏一种能够在不影响性能的情况下同时减少内存使用、计算成本和训练时间的方法,因此迫切需要创新的解决方案。
来自纽约州立大学奥尔巴尼分校、加州大学圣塔芭芭拉分校、亚马逊 Alexa AI 和 Meta 的研究人员介绍钴计算与中号埃默里-乙高效的训练方法右安克-一个自适应张量优化(CoMERA),一种新颖的框架,通过等级自适应张量压缩将内存效率与计算速度结合起来。与仅关注压缩的传统方法不同,CoMERA 采用多目标优化方法来平衡压缩率和模型精度。它利用张量化嵌入和高级张量网络收缩来优化 GPU 利用率,减少运行时开销,同时保持稳健的性能。该框架还引入了 CUDA Graph,以最大限度地减少 GPU 操作期间的内核启动延迟,这是传统张量压缩方法的一个重要瓶颈。
CoMERA 的基础基于自适应张量表示,它允许模型层根据资源限制动态调整其等级。通过修改张量秩,该框架在不损害神经网络操作完整性的情况下实现了压缩。这种动态优化是通过两阶段训练过程实现的:
- 早期阶段专注于稳定收敛
- 后期微调排名以满足特定的压缩目标
在六编码器变压器模型中,CoMERA 实现了从早期阶段的 43 倍到后期优化中令人印象深刻的 361 倍的压缩比。此外,与 GaLore 相比,它的内存消耗减少了 9 倍,每个周期的训练速度提高了 2-3 倍。
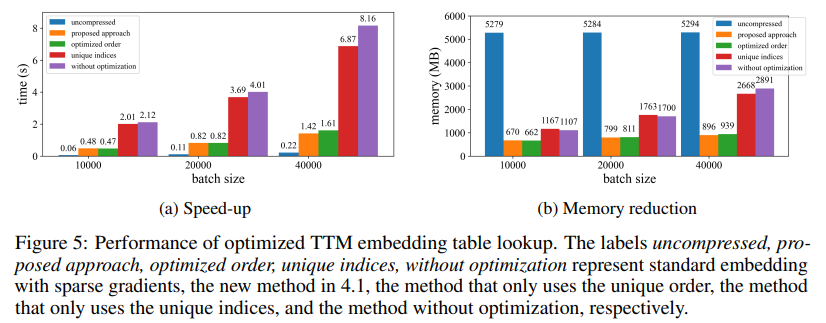
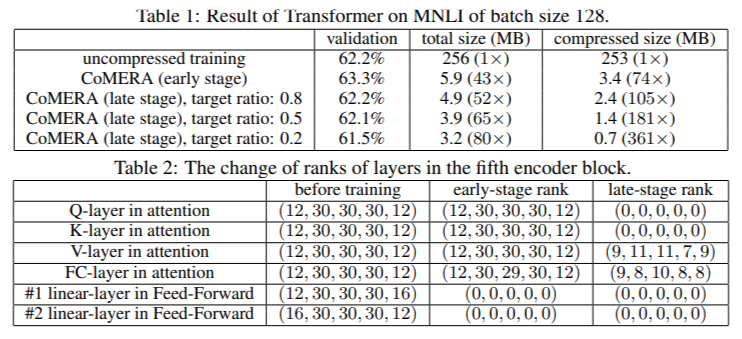
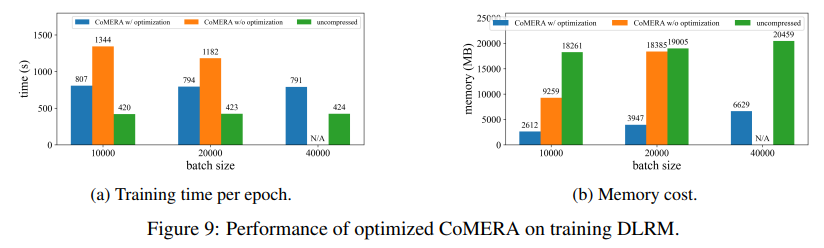
当应用于在 MNLI 数据集上训练的 Transformer 模型时,CoMERA 将模型大小从 256 MB 减少到 3.2 MB,同时保持准确性。在 DLRM 等大型推荐系统中,CoMERA 将模型压缩了 99 倍,并将峰值内存使用量降低了 7 倍。该框架在预训练 CodeBERT(一种特定领域的大型语言模型)方面也表现出色,获得了 4.23 倍的整体压缩比,并在某些训练阶段实现了 2 倍的加速。这些结果强调了其处理不同任务和架构的能力,从而扩展了其跨领域的适用性。
这项研究的主要结论如下:
- CoMERA 针对特定层实现了高达 361 倍的压缩比,针对完整模型实现了高达 99 倍的压缩比,从而大大降低了存储和内存需求。
- 该框架将 Transformer 和推荐系统的每个 epoch 的训练速度提高了 2-3 倍,从而节省了计算资源和时间。
- 使用张量化表示和 CUDA Graph,CoMERA 将峰值内存消耗降低了 7 倍,从而能够在较小的 GPU 上进行训练。
- CoMERA 的方法支持多种架构,包括转换器和大型语言模型,同时保持或提高准确性。
- 通过降低培训的能源和资源需求,CoMERA 有助于实现更可持续的人工智能实践,并使更广泛的受众能够使用尖端模型。
总之,CoMERA 通过实现更快、内存效率更高的训练,解决了人工智能可扩展性和可访问性的一些最重大障碍。其自适应优化功能以及与现代硬件的兼容性使其成为寻求在不产生过高成本的情况下训练大型模型的组织的绝佳选择。这项研究的结果为在分布式计算和资源受限的边缘设备等领域进一步探索基于张量的优化铺平了道路。
查看这纸。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。不要忘记加入我们的 60k+ ML SubReddit。
ðě 趋势:LG AI Research 发布 EXAONE 3.5:三个开源双语前沿 AI 级模型,提供无与伦比的指令跟踪和长上下文理解,以实现卓越生成型 AI 的全球领导地位…。

Asif Razzaq 是 Marktechpost Media Inc. 的首席执行官。作为一位富有远见的企业家和工程师,Asif 致力于利用人工智能的潜力造福社会。他最近的努力是推出人工智能媒体平台 Marktechpost,该平台因其对机器学习和深度学习新闻的深入报道而脱颖而出,技术可靠且易于广大受众理解。该平台月浏览量超过200万,可见其深受观众欢迎。