
全球临床研究人员在学术研究和出版中使用大型语言模型作为人工智能工具
作者:Zeeshan, Bushra
介绍
大型语言模型 (LLM) 代表了自然语言处理 (NLP) 和人工智能 (AI) 领域的重大突破1。2017 年之前,虽然 NLP 模型可以执行多种语言处理任务,但非领域专家并不容易访问它们。2017 年 Transformer 架构的推出彻底改变了该领域,使 NLP 模型能够使用简单的提示高效地合成和分析数据集。这使得世界各地的人们能够大规模使用,显着拓宽了高级语言处理工具的使用范围2。Transformer 技术带来了两个游戏规则改变者的发展:Transformers 双向编码器表示 (BERT) 和生成预训练 Transformer (GPT),它们使用半监督方法并获得了卓越的泛化能力,能够解释和生成类似人类的文本3。ChatGPT 于 2022 年推出,凭借其可访问性和用户友好的界面,几乎在生活的各个领域引起了公众的关注。法学硕士提供人工智能驱动的支持,特别是在文献综述、文章总结、摘要筛选、提取数据和起草手稿方面。由于工作量的减少和所提供的便利性,人们越来越有兴趣将 ChatGPT、Perplexity、Llama by Meta(以前的 Facebook)、Google Bard 和 Claude 等法学硕士纳入学术研究,这一点从ChatGPT 发布后的文章数量3,4。
尽管在研究中利用法学硕士可以提高效率,但它们无法取代人类,特别是在细致的理解和原创思想以及问责制至关重要的情况下5,6。随着对LLM的了解越来越深入,人们发现LLM还能够生成虚假引文,快速生成大量可疑信息,并且还会放大偏见3,7。这导致了负面的道德影响,例如作者诚信和掠夺性行为激增,因此,出现了“人工智能驱动的信息流行病”5。代写的科学文章、假新闻和误导内容还存在对公共健康构成威胁的风险3。在解决这些问题时,第一步是通过评估研究人员对使用法学硕士的认识和实践来了解研究人员对法学硕士在研究中的态度。
我们的研究对参加哈佛医学院 (HMS) 为期一年的认证课程 - 全球临床学者研究培训 (GCSRT) 计划的目标医学和辅助医学研究人员群体进行了独特的分析。我们的目标是深入了解人工智能在研究和出版中的使用趋势,并展望法学硕士的未来范围和影响。我们坚信,我们的研究结果可以帮助期刊制定未来在出版过程中使用人工智能工具的政策,从而确保医学出版物的可信度和完整性。
方法
研究设计和人群
这项全球调查是采用横断面设计进行的。该研究于 2024 年 4 月至 6 月期间进行,参与者包括在哈佛大学 GCSRT 项目接受过培训的多元化医学和辅助医学研究人员。该项目由来自 6 大洲 50 多个国家、跨越不同专业、职业阶段、年龄组和性别的研究人员组成。在该项目中,所有参与者都会接受研究各个阶段的高级培训,包括统计分析、出版和资助写作8。因此,他们是评估研究中人工智能工具使用情况的理想群体。
学习目标
我们的这项研究有三个主要目标。首先,评估全球研究人员对法学硕士的认识水平。其次,确定我们的调查受访者目前如何将法学硕士用于学术研究和出版。第三,分析人工智能工具在医学研究和出版中的潜在未来影响和伦理影响。
资格标准
-
(一个)
入选标准:2020 年至 2024 年间属于任何队列的 HMS GCSRT 项目参与者的医学和辅助医学研究人员,无论其原籍国、研究兴趣、研究活跃年限、年龄或性别。特别包括非官方班级 WhatsApp 群组成员、精通英语阅读和写作的研究人员。
-
(二)
排除标准:来自上述指定年份以外的队列的研究人员、无法通过班级 WhatsApp 群组联系到的人员或不精通英语阅读和写作的人员被排除在研究之外。未接受过该计划培训的医学和辅助医学研究人员以及非医学研究人员未受邀参加本研究。
问卷开发和调查传播策略
该调查是使用 Google 表单以英语起草的。它总共由 4 个部分组成,涵盖了我们的主要目标 - (1) 背景、(2) 对法学硕士的认识、(3) 法学硕士的影响和 (4) 未来政策。每个问题都经过仔细审查,确保其相关性、有效性和公正性。该研究的数据收集者是从 GCSRT 计划的参与者中自愿选择的。每个目标群体的数据收集者主要负责通过 WhatsApp 和 LinkedIn 上的个人消息来接触他们群体中的目标人群。调查受访者的联系信息是从非官方类WhatsApp群组和数据收集者的个人网络获得的。总共向每位潜在参与者发送了 3 条个人消息,其中包括 2 条提醒,每条间隔 7 天。来自超过 59 个国家的总共 226 名研究人员获得了知情同意,并填写了 Google 调查表格。
样本量和统计方法
Google 调查表的链接已分发给 GCSRT 计划的 5 个队列,其中总共有 550 名医学和辅助医学研究人员。考虑 5% 的误差幅度、95% 的置信水平和 0.8 的功效,计算出总样本量为 220。调查受访者的描述性统计数据以正态分布连续数据的平均值±标准差、非正态分布连续数据的中位数(四分位距)以及分类数据的频率和百分比的形式呈现。使用夏皮罗威尔克检验对连续数据进行正态性检验。使用单向方差分析分析正态分布数据,使用 Kruskal-Wallis 检验分析非正态分布数据。分类数据采用卡方检验或费舍尔精确检验进行分析。通过主题分析研究来自开放式问题的定性数据。所有统计分析均在 Stata MP 17.0 版(StataCorp,College Station,TX,USA)中进行。所有测试都是双尾的并且被认为是显着的磷≤<≤0.05。道德考虑
根据赫尔辛基声明
8,这项研究得到了巴基斯坦拉合尔阿拉马伊克巴尔医学院/真纳医院伦理审查委员会的批准(参考编号:ERB 163/9/30-04-2024/S1 ERB)。它不受 HMS 支持或认可。然而,有关该研究的通知已及时通知给 GCSRT 计划的管理部门。作为对调查问卷的第一次强制性答复,我们收集了每位受访者的参与同意书。所有个人信息(例如电子邮件 ID、国籍和年龄)均经过仔细去识别化处理并进行保密处理。向受访者提供了有关研究自愿性的必要信息以及主要研究者的联系信息。
结果
我们分析了来自超过 59 个国家、在 65 个不同医疗和辅助医疗专业领域执业的 226 名全球研究人员的回答。各个原产国(补充表S1),两个最常见的原产地是美洲地区(23.5%)和东南亚地区(23.5%)。
桌子1代表了我们的调查受访者的学术和人口特征,并将了解法学硕士的受访者与不了解法学硕士的受访者进行了比较。调查受访者中 PubMed 索引出版物的中位数为 7(四分位距:2-18)。198 名 (87.6%) 的调查受访者之前了解法学硕士。除了 PubMed 索引出版物的数量外,所有特征均与法学硕士的认知度没有显着相关。与那些不知道的人相比,那些知道使用法学硕士的人发表的出版物数量更多(p–< –0.001)。表 1 调查受访者的学术和人口特征
2代表有意识的受访者 – (n–= –198) 有关法学硕士的知识、态度和实践。大多数人对法学硕士有一定程度的了解(分别为 33.3% 和 30.8%)。在这些有意识的受访者中,曾经亲自使用过LLM的人(18.7%),主要用于语法错误和格式排版(64.9%),其次是写作(45.9%),最后是修改和编辑(45.9%)。当根据医学研究的活跃年数进行分层时,这些变量都没有显着相关。
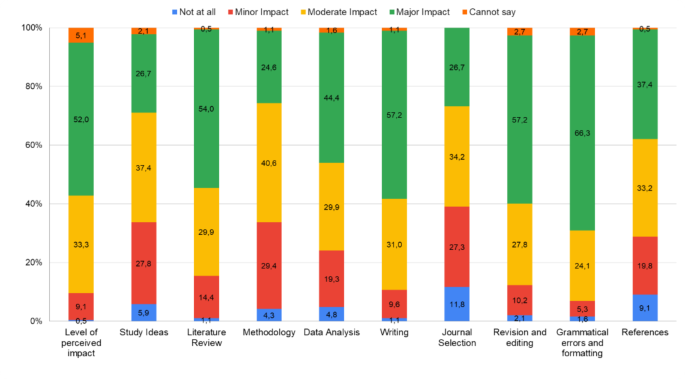
图 1显示了有意识的受访者对法学硕士在不同出版阶段的未来影响的感知水平。大多数人认为法学硕士将产生重大的总体影响(52.0%)。受影响最大的领域是语法错误和格式(66.3%)、修订和编辑(57.2%)以及写作(57.2%)。不会受到影响到中等影响的领域是方法论(74.3%)、期刊选择(73.3%)和研究思路(71.1%)。

法学硕士在出版过程各个阶段的未来。
表 3代表了受访者对法学硕士未来范围的认知。大多数人认为这会带来积极影响(50.8%),但也有很大一部分人不确定(32.6%)。虽然大多数受访者认为期刊应该允许在出版中使用人工智能工具(58.1%),但大多数受访者(78.3%)也认为应该制定一些法规(即修改期刊政策、人工智能审查委员会、检测 LLM 使用情况的工具)。使人工智能工具在出版业中符合道德规范。当根据医学研究的活跃年数进行分层时,这些变量都没有显着相关。
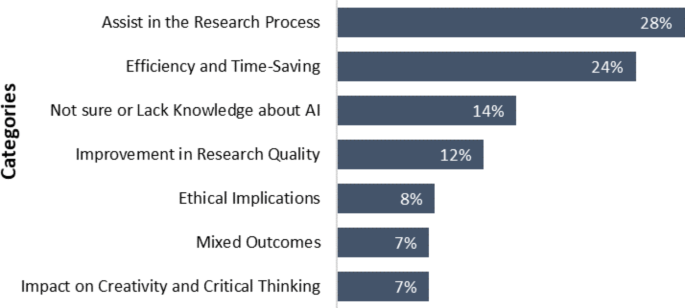
关于未来范围和挑战的总体意见(主题类别)。
在我们的调查中,79%(n–= –179) 的受访者愿意分享他们对法学硕士未来范围和挑战的总体看法。他们的观点属于图 1 中的一个或多个类别。 2。28%(n�=�64) 受访者表示,法学硕士是出版过程中的有用工具,特别是在系统地组织和撰写大型主题方面。此外,大约四分之一的受访者(n�=�55) 表示,通过使用法学硕士,研究人员能够花更少的时间在研究项目的不同部分,如文献综述、数据分析和手稿准备。然而,调查受访者还透露了与在学术研究中使用法学硕士相关的一些担忧和挑战。14%(n–= –33) 的受访者表示不确定或缺乏法学硕士的经验。8% 的参与者指出了对在学术研究和出版中使用法学硕士的道德担忧,包括潜在的偏见、隐私问题和剽窃(n�=�18)。讨论
人工智能在世界各地产生了地震波;
研究领域也不例外。我们的研究评估了法学硕士的认知度、使用趋势和未来范围,以更好地分析这种在学术界的影响。它反映了来自 59 个国家、涵盖 65 个专业的各行各业的医学和辅助医学研究研究人员的看法。我们的受访者主要属于医学亚专业 (64.6%),而不是外科或辅助医疗亚专业,这与 Abdelhafiz 等人的研究中看到的受访者特征相似 (68%)。9我们的受访者大多在学术机构工作(57.1%),其次是公共和私人医疗机构,这与 Abdelhafiz 等人的研究类似。其中 75% 的参与者来自大学或研究中心9。具有10年以上、6-10年和0-5年研究经验的受访者分别占21.7%、31.4%和46.9%,这表明我们的目标人群很好地代表了不同职业阶段的院士。
我们的绝大多数受访者 (87.6%) 都了解法学硕士,这与在约旦医学生中进行的一项调查类似 (85%)10,与在巴基斯坦进行的一项研究相比更高,其中只有 21.3% 的受访者熟悉人工智能11。GCSRT 参与者的高意识水平的一个合理解释可能是他们已经完成了高级研究培训,并且可能在培训期间遇到了法学硕士在当代研究和出版中的应用。此外,他们对研究的浓厚兴趣可能促使他们探索该领域的最新进展,其中法学硕士和人工智能工具的使用可能位居榜首。12,13。有趣的是,了解 LLM 的参与者比不了解 LLM 的参与者发表的论文数量更多(p 值≤<≤0.001)。这一发现与之前的研究相吻合,之前的研究报告称,对 LLM 的熟悉度和访问度更高法学硕士与学术作者的预印本和发表率较高有关,这可能是由于法学硕士研究的快节奏性质以及法学硕士用于写作辅助的原因14。年龄、受访者所在国家或执业领域等其他变量均与法学硕士使用意识显着相关。绝大多数了解法学硕士的受访者表示,他们在 2022 年之前并不了解人工智能工具(86.4%)。这与 2021 年 5 月至 2023 年 7 月期间与医学研究法学硕士相关的出版物的引人注目的轨迹相对应15。
81.3% 的受访者此前从未在他们的研究项目或出版物中使用过法学硕士。这与 Eppler 等人的早期研究形成鲜明对比16,近一半的受访者表示曾在学术实践中使用过法学硕士。在那些以前在出版物中使用过法学硕士的人中,大多数人认为其在语法错误纠正、编辑和手稿写作等任务中的使用强度为中等至频繁。这些结果与 Eppler 等人的研究一致。16,这表明法学硕士在科学出版中最常见的用途是写作(36.6%),其次是检查语法(30.6%)。借助基于NLP的法学硕士,可以使用分类模型和基于算法的句子构造方便地纠正语法错误17 号,18。尽管法学硕士经常用于学术写作的各个部分,但相当一部分受访者(约 40%)并未承认其在其出版物中的使用。研究人员可能不会在其研究论文中透露人工智能工具的包含情况,原因有多种。首先,部分研究人员对他们正在使用的技术缺乏信息或理解,因此他们仍然不知道人工智能融入他们的研究的程度19,20。其次,是与人工智能的使用相关的怀疑或负面看法,例如部署机器来生成建议或对其研究进行科学讨论的观念21。因此,是否承认人工智能在研究中的使用仍然是一个伦理纠纷。出版商可能会要求作者提交或包含一份关于他们是否在写作中使用人工智能系统的声明22,23,24。
数字 1和2;表 3深入了解全球研究人员中法学硕士的未来范围和挑战。图 1揭示了对法学硕士变革潜力的坚定信念,略多于一半的受访者预计会产生重大的总体影响。未来受法学硕士影响最显着的具体领域包括语法错误和格式、修订和编辑、写作以及文献综述。这些结果与当前的文献一致,表明法学硕士可以极大地提高这些任务的效率和准确性,从而促进更快、更高质量的学术成果25,26,27。相反,被认为受影响较小的领域,例如方法论、期刊选择和研究思路,反映了人们对人工智能的担忧,以批判性地评估研究设计和期刊的适用性。
如表所示 3略多于一半的参与者对法学硕士的影响持积极态度,但其中约三分之一的人仍不确定。这种不确定性凸显了人们对人工智能技术的道德影响和潜在滥用的严重担忧。现有研究中充分记录了道德问题,这些研究强调了人工智能生成的内容可能产生的数据隐私、错误信息和意外偏见等问题28,29。此外,我们的研究表明,虽然大多数受访者支持在出版中使用人工智能工具,但对于实施监管措施的必要性存在强烈共识,例如修改期刊政策、人工智能审查委员会和检测法学硕士使用情况的工具。这一发现与文献中提出的更广泛的道德准则一致,该准则主张建立强有力的监督和道德框架,以减轻与医学研究等敏感领域人工智能部署相关的风险27,30。有趣的是,对人工智能道德使用的看法随着经验水平的不同而变化。在我们的研究中,与研究经验较少的参与者相比,具有 10 年以上研究经验的参与者更有可能认为人工智能工具是积极的,并支持在监管条件下使用它们;然而,这一结果在统计上并不显着。
结论
随着法学硕士的出现,学术写作学科发生了明显的转变,越来越多的研究人员在其研究出版物的不同阶段结合了这些工具。然而,随着法学硕士申请的增加,对其有效性、责任性、潜在剥削和道德影响的担忧也相应增加。
虽然人们广泛认识到法学硕士对学术研究和出版的某些方面的有益影响,但解决相关的道德风险和忧虑至关重要。我们的研究强调需要制定全面的指南和道德框架来管理人工智能在医学和辅助医学研究中的使用。法学硕士的实用性不断增长,需要及时实施此类监管政策,以确保其安全、负责任和有效的使用。
局限性
我们的研究存在某些需要解决的方法学局限性。首先,由于这是一项横断面研究,因此无法从研究结果中得出因果推论,而且我们研究结果的时间相关性会随着时间的推移而发生变化。其次,尽管我们广泛尝试保持调查回复的匿名性,但研究结果很容易出现社会期望偏差。第三,由于我们的研究人群仅限于具有广泛学术研究知识的 GCSRT 项目参与者,因此可能会引入选择偏差,从而限制了研究结果的普遍性。第四,我们的研究没有收集可能与法学硕士使用意识相关的几个受访者特征,例如性别、教育水平和收入水平。最后,由于使用 WhatsApp 和 LinkedIn 进行数据收集,我们的研究很容易出现抽样偏差。使用 LinkedIn 的参与者可能同时使用其他平台进行研究,而使用 WhatsApp 的参与者可能更年轻,更精通技术和人工智能。因此,对某些人口统计数据代表性过高的担忧可能会影响研究结果的外部有效性。
数据可用性
本研究的数据将根据通讯作者的合理要求进行共享。
参考
纳维德,H.等人。大语言模型的全面概述。(2023)。https://arxiv.org/abs/2307.06435。Radford, A.、Narasimhan, K.、Salimans, T. 和 Sutskever, I。通过生成预训练提高语言理解 (2018)。
https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper。pdf,.德·安吉利斯,L.等人。
ChatGPT 和大型语言模型的兴起:人工智能驱动的公共卫生信息流行病威胁。正面。民众。健康 11,(2023)。
Bornmann, L.、Haunschild, R. 和 Mutz, R. 现代科学的增长率:一种潜在的分段增长曲线方法,用于模型来自已建立的新文献数据库的出版物数量。人道。苏克。科学。交流。 8,(2021)。
Kendall, G. 和 Teixeira Da Silva, J. A. 在科学出版中滥用大型语言模型(如 ChatGPT)的风险:作者身份、掠夺性出版和造纸厂。学习。酒馆 37,(2024)。
Rane, N.、Choudhary, S. P.、Tawde, A. 和 Rane, J. ChatGPT 无法担任作者:教育中大型语言模型的伦理问题和挑战。IRJMETS5、(2023)。
Hosseini, M. & Horbach, S. P. J. M. 对抗审稿人疲劳或放大偏见?在学术同行评审中使用 ChatGPT 和其他大型语言模型的注意事项和建议。资源。积分。同行牧师。 8,(2023)。
阿卜杜勒哈菲兹,A.S. 等人。研究人员对于在研究中使用 ChatGPT 的知识、看法和态度。J. Med。系统。 48,(2024)。
Al Saad,M.M. 等人。医学生对人工智能的知识和态度:在线调查。打开。民众。健康 J. 15,(2022)。
乌默,M.等人。调查巴基斯坦医学生和专业人员对医疗保健人工智能的认识:一项横断面研究。安.医学。外科医生。 86,(2024)。
Watkins, R. 为研究人员和同行评审员在科学研究工作流程中道德使用大语言模型 (LLM) 提供的指南。人工智能伦理(2023)。
李,H.等人。医学和医学研究中大型语言模型的伦理。柳叶刀数字。健康 5,(2023)。
梁,W.等人。映射法学硕士在科学论文中的使用日益增加。(2024)。https://arxiv.org/abs/2404.01268v1,.
孟X.等人。大语言模型在医学中的应用:范围界定审查。科学27,(2024)。
埃普勒,M.等人。ChatGPT 和大型语言模型的认识和使用:泌尿外科前瞻性横断面全球调查。欧元。乌罗尔。 85,(2024)。
卡诺,P.M.A.等人。学术写作语法检查工具的自然语言处理:系统文献综述。J.电气。系统。 20,(2024)。
Wu, L. & Pan, M. 基于 LSTM-CRF 机器学习模型的英语语法检测。计算机智能神经科学(2021)。(2021)。
Christou, P. A. 关于是否以及如何承认在定性研究中使用人工智能 (AI) 的批判性观点。合格。代表。 28,(2023)。
Bender, E. M. & Koller, A.《攀登 NLU:论数据时代的意义、形式和理解》。计算语言学协会第 58 届年会论文集(2020)。
Barocas, S. 和 Selbst, A.D. 大数据的不同影响。加利福尼亚州 L Rev. 104,(2016)。
工具之类的。由于 ChatGPT 威胁到透明科学;以下是我们使用它们的基本规则。自然 613,(2023)。
Thorp, H. H. ChatGPT 很有趣,但不是作家。科学 第379章,(2023)。
Flanagin, A.、Bibbins-Domingo, K.、Berkwits, M. 和 Christiansen, S. L. 非人类作者及其对科学出版和医学知识完整性的影响。美国医学会杂志第329章,(2023)。
Wagner, G.、Lukyanenko, R. 和 Paré, G. 人工智能和文献综述的进行。J.信息。技术。 37,(2022)。
Patil, S. 和 Tovani-Palone, M. R. 智能研究的兴起:人工智能应如何协助研究人员进行医学文献检索?诊所78,(2023)。
Dave, T.、Athaluri, S. A. 和 Singh, S. ChatGPT 在医学上的应用:概述其应用、优点、局限性、未来前景和伦理考虑。正面。阿蒂夫。英特尔。 6,(2023)。
Biswas,S. ChatGPT 和医学写作的未来。放射科 307,(2023)。
Preiksaitis, C. 和 Rose, C. 医学教育中生成人工智能的机遇、挑战和未来方向:范围界定审查。JMIR 医学。教育。 20,(2023)。
Alkaissi, H. & McFarlane, S.I. ChatGPT 中的人工幻觉:对科学写作的影响。库勒乌斯19,(2023)。
致谢
我们衷心感谢 Le Huu Nhat Minh 博士为这项研究收集 27 份回复做出的宝贵贡献。此外,我们衷心感谢哈佛大学 GCSRT 项目的所有研究学者参与我们的调查并帮助我们完成这项研究。
道德声明
利益竞争
作者声明没有竞争利益。
附加信息
出版商备注
施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
电子补充材料
以下是电子补充材料的链接。
权利和权限
开放获取本文获得 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License 的许可,该许可允许以任何媒介或格式进行任何非商业使用、共享、分发和复制,只要您给予原作者适当的署名即可和来源,提供知识共享许可的链接,并指出您是否修改了许可材料。根据本许可,您无权共享源自本文或其部分内容的改编材料。本文中的图像或其他第三方材料包含在文章的知识共享许可中,除非材料的出处中另有说明。如果文章的知识共享许可中未包含材料,并且您的预期用途不受法律法规允许或超出了允许的用途,则您需要直接获得版权所有者的许可。要查看该许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

米什拉,T.,苏坦托,E.,罗桑蒂,R.
等人。全球临床研究人员在学术研究和出版中使用大型语言模型作为人工智能工具。 科学代表14,31672(2024)。 https://doi.org/10.1038/s41598-024-81370-6下载引文
:2024 年 6 月 25 日
:2024 年 11 月 26 日
:2024 年 12 月 30 日
:https://doi.org/10.1038/s41598-024-81370-6关键词