

浏览 LLM 评估指标 - RTInsights
作者:Chaitanya Pathak
检查语言质量的评估指标、评估某些任务的法学硕士任务特定标准以及人工评估是可以衡量法学硕士绩效和准确性的三大类评估。
评估法学硕士是一个困难且多维的过程,需要定量和定性方法。评估法学硕士时,必须使用解决模型性能和影响多个方面的综合评估技术。缺乏标准化评估是我们面临的最大问题之一,因为它使得我们很难系统地比较各种模型的能力、可能的危险和潜在的损害。这凸显了审查过程的难度和重要性,因为这意味着我们缺乏客观的方法来衡量这些特定模型的智能程度或良好程度。
当我们谈论 GenAI 评估时,大多数对话都集中在准确性和性能评估上,这些评估衡量语言模型理解和生成与人类语言相似的文本的效率。诸如聊天机器人、内容创建和摘要工作之类的应用程序取决于其所生成内容的质量和适用性,应密切关注这一因素。
检查语言质量的传统评估指标、评估某些任务的法学硕士任务特定标准以及人工评估是可以衡量绩效和准确性的三大类评估。
LLM评估支柱:上述应该是构建法学硕士评估框架时的五个关键设计考虑因素,以确保为持续模型改进建立系统且严格的方法和基础设施。
用例特殊性:在创建 LLM 的用例上测试 LLM,即将模型应用于一系列自然语言处理(NLP)活动,包括翻译、问答和总结——对于提供有意义的评估是必要的。标准指标,如 ROUGE(面向回忆的基础评估),应在总结评估过程中使用,以保持可比性和可靠性。
及时工程:提示的制定是LLM评估的重要组成部分。为了对模型的能力提供可靠的评估,提示需要清晰且公平。通过这样做,可以保证评估结果准确地代表模型的性能。
基准测试:基准测试是一项关键技术,可以使用现有标准和替代模型来评估法学硕士的表现。这不仅可以监控进展情况,还可以查明需要发展的领域。通过持续的审查方法与持续的开发程序相结合,可以定期评估和改进法学硕士。
GenAI 道德规范:在法学硕士评估过程的每个阶段,都必须考虑道德因素。检查模型是否存在偏见、公平性和道德问题需要检查训练数据和结果。为了确保模型的输出满足用户的需求和期望,评估还应包括有关用户体验的重要部分。
记录和监控:评估的各个方面都必须公开、透明。保留标准、程序和结果的记录可以增强对法学硕士技能的信心并允许独立验证。模型、训练数据和评估程序都应根据绩效指标和反馈进行改进,评估结果应指导持续开发的循环。
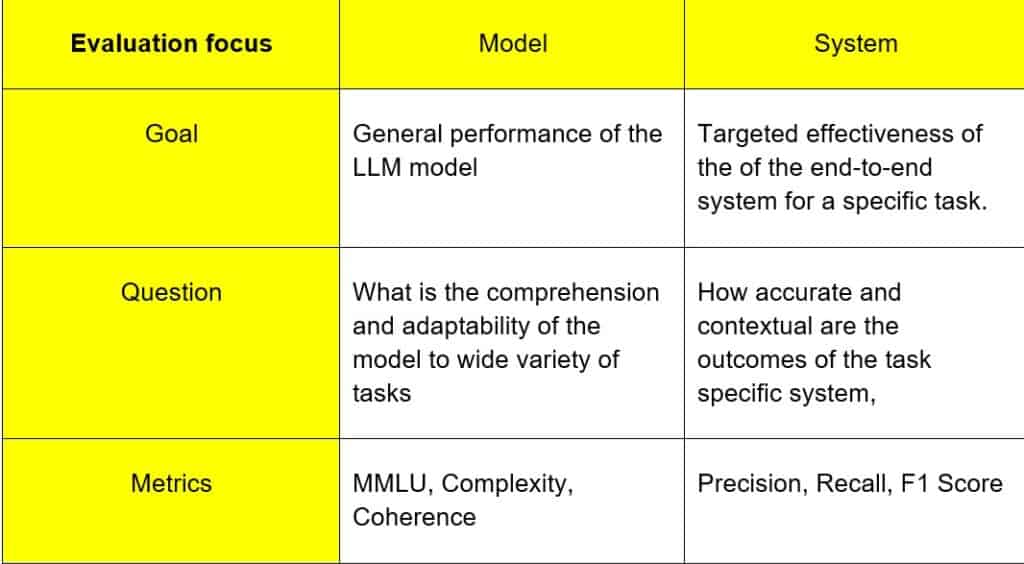
评估范围:模型 vs 系统
LLM 系统是一个完整的设置,不仅包括 LLM 本身,还包括额外的组件,如功能工具调用(用于代理)、检索系统(RAG 中)、响应缓存等,这使得 LLM 对于现实世界的应用程序非常有用,例如文本到 SQL 生成器、自主销售代理和客户支持聊天机器人。相比之下,LLM(大型语言模型)特指经过训练以理解和生成人类语言的模型(例如 GPT-4)。
不过,重要的是要记住,LLM 系统有时只能由 LLM 本身组成,ChatGPT 就是这种情况。
因此,评估LLM系统比直接评估LLM更为复杂。尽管法学硕士和法学硕士系统都接收和生成文本输出,但您应该更精确地使用法学硕士评估指标来评估各种法学硕士系统组件,以便更好地理解。这是因为法学硕士系统可能有多个组件一起工作。
下面是 GQM(目标问题指标)表,说明了焦点上的主要差异。
一个好的评估框架必须确保用例复杂性和评估架构方法趋同。这种融合将提供最相关的指标。
基于参考的指标
使用基于参考的指标将参考(人工注释的真实文本)与生成的文本进行比较。尽管其中许多指标是在法学硕士开发之前为传统 NLP 任务创建的,但它们仍然与法学硕士生成的文本相关。
基于 N 元语法的指标
基于重叠的测量 JS 散度 (JS2)、ROUGE(面向回忆的 Gisting 评估研究)和 BLEU(双语评估研究)使用 n-gram 衡量参考文本和输出文本的相似程度。
文本相似度指标
通过评估文本部分之间单词或单词序列的重叠,评估者专注于计算相似度。它们有助于生成参考真实文本和法学硕士的预计输出之间的相似性分数。此外,这些指标还表明了模型在每项任务上的表现。
编辑相似率
用于比较两个序列相似性的字符串度量是 Levenshtein 相似度比率。编辑距离作为该指标的基础。将一个字符串转换为另一个字符串所需的最小单字符修改(插入、删除或替换)次数称为两个字符串之间的编辑距离。
语义相似度指标
Sentence Mover 相似度 (SMS)、MoverScore 和 BERTScore 指标都使用上下文嵌入来衡量两个文本的相似程度。研究表明,这些指标与人类评估者的相关性较差,缺乏可解释性,存在固有偏见,对更广泛任务的适应性较差,并且无法捕捉语言中的细微差别,尽管计算起来快速、简单且成本较低比基于 LLM 的指标。
两个语句含义相似的程度称为语义相似度。这是通过首先将每个字符串表示为封装其语义和含义的特征向量来实现的。制作字符串的嵌入(例如,使用法学硕士),然后计算两个嵌入向量之间的余弦相似度是一种流行的方法。
无参考指标
无参考(基于上下文)指标不使用基本事实,而是为创建的文本生成分数。上下文或源文档作为评估的基础。生成真实数据的困难导致了其中几个指标的开发。这些方法通常比基于参考的方法更新,这反映出随着 PTM 的发展,对规模文本评估的需求不断增长。这些包括基于质量、蕴涵、事实性、问答 (QA) 和问题生成 (QG) 的测量。
基于质量的指标 –这些指标用于摘要任务,它们是生成的摘要中信息的相关性的有力指标。BLANC 质量量化屏蔽标记的两次重建之间的准确性差异,而 SUPERT 质量评估摘要与 BERT 的匹配程度基于伪引用。ROUGE-C是ROUGE的改编版,它使用源文本作为上下文进行比较,并且不需要参考文献。
基于蕴含:自然语言推理(NLI)任务评估输出文本(假设)是否暗示、矛盾或破坏给定文本(前提),是基于蕴涵的度量的基础[24]。这可以帮助发现事实的不一致。可以使用 SummaC(摘要一致性)基准、FactCC 和 DAE(依赖弧蕴含)指标来发现与源文本的事实不一致。基于蕴涵的指标的分类任务被标记为“一致”或“不一致”。
基于 QG、QA 和事实性的指标。基于事实的指标,例如 QAFactEval 和 SRLScore(语义角色标签),评估生成的文本是否包含偏离原始文本的不准确信息。事实一致性和相关性也可以使用基于 QA 的指标(例如 QuestEval)和基于 QG 的指标来衡量。
法学硕士-法官
一种有效的方法是法学硕士作为法官,它利用法学硕士根据您选择的任何特定标准评估法学硕士的回答来进行法学硕士(系统)审查。给LLM一个评估标准并让它为你评分是一个简单的想法。法学硕士作为评委的三个类别,首先在《使用 MT-Bench 和 Chatbot Arena 评判法学硕士作为评委》一文中提出,作为人工评估的替代品(人工评估通常成本高昂且耗时),包括:
单一输出评分(无参考):LLM 法官会获得一个评分标准作为标准,并被要求根据许多标准对 LLM 回答进行评分,包括 RAG 管道中的检索上下文、LLM 系统的输入等。
单一输出评分(带参考):与之前相同,尽管有时 LLM 评委可能会变得不稳定。当有参考、理想和预期输出时,法学硕士法官更容易提供一致的评级。
成对比较:法学硕士法官将选择法学硕士产生的两个输出中哪一个在输入方面更优。此外,需要一套独特的标准来决定什么是“更好”。
由于替代方案不足,使用法学硕士作为法学硕士评估措施的评分者来评估其他法学硕士正变得越来越流行。尽管人工审核速度很慢,而且 BERT 和 ROUGE 等传统评估技术由于忽略了 LLM 生成文本中的底层语义而存在不足,但 LLM 评估对于衡量和查明领域以增强 LLM 系统性能至关重要。
G-评估
G-Eval 是一种方法/框架,采用 CoT 提示来稳定和提高 LLM 法官在计算指标分数时的准确性和可靠性。
G-Eval首先根据原始评估标准创建一组评估阶段,然后采用填表范例来确定最终分数。这只是一种奇特的说法,G-Eval 需要大量信息才能发挥作用。例如,使用 G-Eval 评估 LLM 输出的一致性需要创建包含评估标准和文本的提示以创建评估阶段,然后使用 LLM 根据这些步骤产生 1 到 5 之间的分数。
用例复杂性
各种应用程序需要与其特定目标和规范相对应的独特性能指标。BLEU 和 METEOR 等评估指标经常用于机器翻译领域,其中生成正确且连贯的翻译是关键目标。这些措施的目的是评估机器生成的翻译和人工参考翻译之间的相似程度。在这种情况下,修改评估标准以强调语言准确性就变得至关重要。在情感分析等应用中,精度、召回率和 F1 分数等指标可能会被优先考虑。为了评估语言模型识别文本数据中积极或消极情绪的准确性,需要一个考虑情感分类微妙之处的度量框架。当制定评估标准来突出某些措施时,可以保证进行更中肯、更有意义的审查。
RAG架构模式
检索增强生成 (RAG) 模式是一种广泛使用的提高 LLM 性能的技术。该过程需要从知识库获取相关数据,然后利用生成模型生成最终结果。法学硕士可用于创建模型和检索模型。检索和生成模型的性能可以使用 RAGAS 实现中的以下指标进行评估(RAGAS 是检索增强生成管道的评估框架;见下文),这需要每个查询检索到的上下文:
世代相关
忠实性:评估生成的答案与所提供上下文的事实一致性。如果答案包含任何无法从上下文推断的陈述,将会受到处罚。这是通过采用两步范例来实现的,该范例涉及从生成的响应生成语句,然后使用推理或上下文确认每个语句。它是根据答案和检索到的上下文计算得出的。响应范围从 0 到 1,其中 1 代表最佳结果。
相关性:答案直接响应并适合特定问题或情况的程度称为答案相关性。这会惩罚多余信息或对查询的部分答复的存在,而不是考虑答案的事实准确性。
检索相关
上下文相关性:指示检索到的上下文与查询的相关程度。理想情况下,上下文应该只提供响应查询所需的详细信息。当上下文中出现冗余信息时,它就会受到惩罚。它是使用检索到的上下文和查询来计算的。
上下文回忆:使用带注释的响应作为基本事实来衡量上下文的记忆程度。基本事实的上下文由带注释的响应表示。它是使用恢复的上下文和地面实况来计算的。
道德与安全
法学硕士最终将被全球各地的各种公司和组织定期使用。为了让这些模型发挥最佳功能,甚至遵守文化规范,它们必须遵守道德和安全评估。
识别偏见
仔细检查法学硕士的结果是否存在不平等待遇或不同群体代表性的情况。该指标确定并评估模型忽略任何年龄、种族、性别、宗教和其他刻板印象的程度。
毒性评估
此衡量标准评估任何冒犯性、不当或有害内容的总体可能性。它甚至利用某些算法根据宣扬仇恨言论、粗俗语言或其他类似类型内容的可能性对输出进行分类和排名。
检查事实正确性
它评估 LLM 聊天机器人生成的数据的总体准确性。为了完全确定所提供的信息是可信的,它将输出与可靠的来源或事实进行比较,特别是在不准确或误导性信息可能产生严重后果的情况下。
安全和隐私评估
该措施评估并保证 LLM 模型不会无意中泄露任何私人信息。此外,它还提供防泄漏安全性,仔细检查模型对私人数据的处理,并遵守该领域最新的隐私法。