
代谢数据和人工智能相结合,重新定义了我们衡量衰老和预测健康跨度的方式。
 学习:代谢组年龄(MileAge)预测健康和寿命:多种机器学习算法的比较。图片来源:Sergey Tarasov / Shutterstock
学习:代谢组年龄(MileAge)预测健康和寿命:多种机器学习算法的比较。图片来源:Sergey Tarasov / Shutterstock
在最近发表在该杂志上的一项研究中科学进步伦敦国王学院的研究人员使用根据英国 (U.K) 生物银行的血浆代谢数据训练的机器学习模型探索了代谢组衰老时钟。该研究旨在通过对代谢组衰老时钟的准确性、稳健性以及与实际年龄之外的生物衰老指标的相关性进行基准测试,评估代谢组衰老时钟在预测健康结果和寿命方面的潜力。
背景
生物衰老与实际年龄不同,反映了影响健康和疾病易感性的分子和细胞损伤。仅实际年龄无法捕捉个体之间与衰老相关的生理状态的变化。然而,组学技术,特别是代谢组学的最新进展,通过分子分析提供了对生物衰老的见解。
代谢物或代谢途径中的小分子可以提供生理健康评估,并与衰老相关的结果(例如慢性疾病和死亡率)相关。早期的研究已将代谢组数据与衰老相关联,但受到样本量和标记物有限的限制。
最近利用机器学习从组学数据中推导出“衰老时钟”的努力已经证明了对健康结果的显着预测能力。然而,优化这些模型的准确性和可解释性仍然存在挑战,特别是使用代谢组学。
目前的研究
本研究利用核磁共振 (NMR) 光谱分析来自英国生物银行的血浆代谢物数据,涉及 225,212 名年龄在 37 岁至 73 岁之间的参与者。排除标准包括怀孕、数据不一致和极端代谢值。该数据集包含代表脂质谱、氨基酸和糖酵解产物的 168 种代谢物。
研究人员将 17 种机器学习算法(包括线性回归、基于树的模型和集成技术)应用于数据集,以开发代谢组衰老时钟。他们还使用严格的嵌套交叉验证方法来确保稳健的模型评估。
一些主要的预处理步骤包括处理异常代谢值和纠正模型固有的年龄预测偏差。预测模型旨在利用代谢物谱来估计实际年龄,预测年龄与实际年龄之间的差异被定义为“MileAge delta”。广泛应用统计校正来消除系统偏差并提高预测准确性,特别是对于较年轻和较年长的年龄范围。
使用平均绝对误差 (MAE)、均方根误差 (RMSE) 和相关系数等指标评估模型的预测准确性。例如,Cubist 回归模型的 MAE 为 5.31 年,优于多元自适应回归样条等其他模型(MAE = 6.36 年)。进一步的分析调整了预测,以消除系统偏差并提高其与实际年龄的一致性。
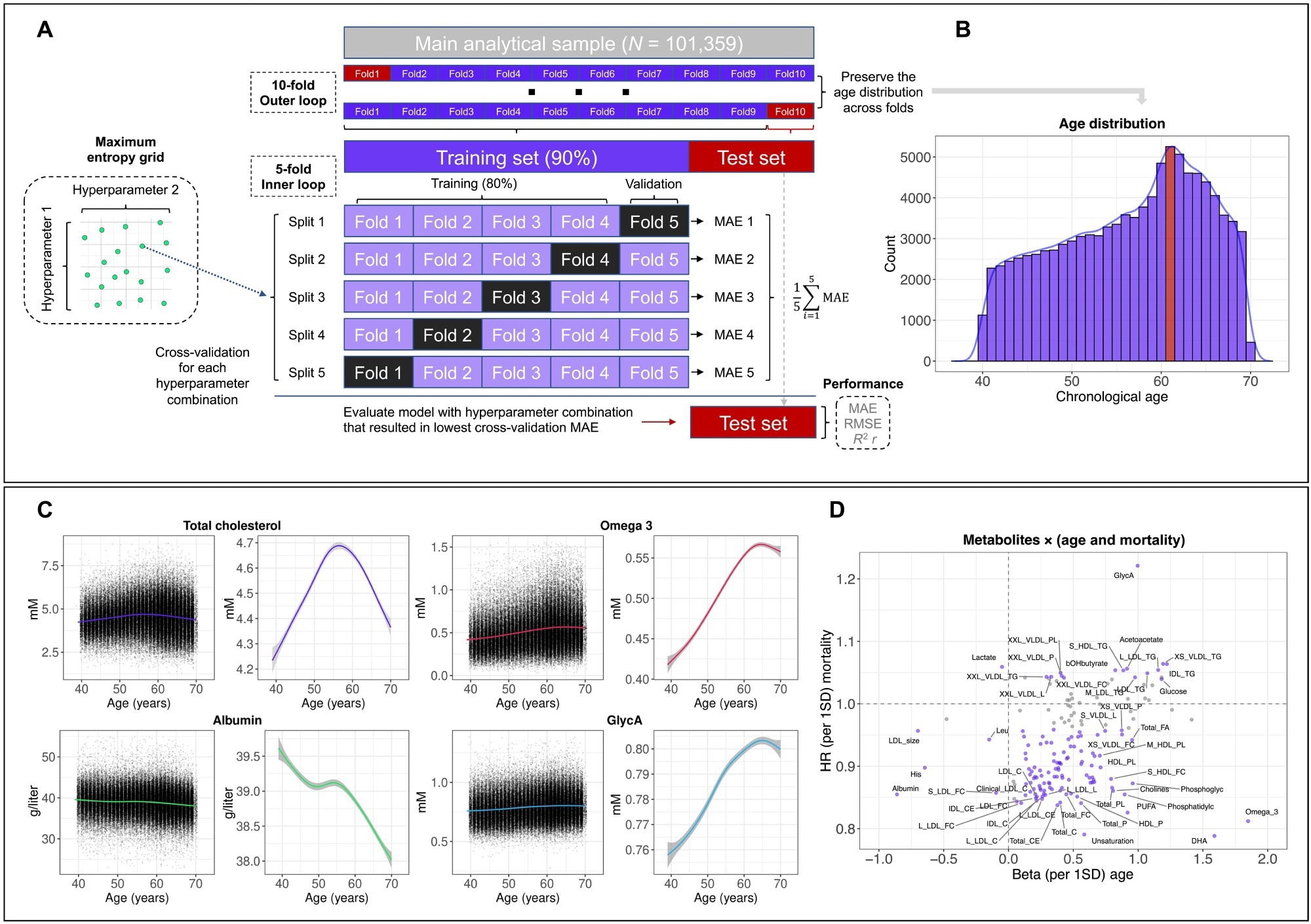
研究设计和概述。(A) 嵌套交叉验证方法概述。MAE,平均绝对误差;RMSE,均方根误差。(B) 分析样本的实际年龄分布的直方图。统计模式(年龄,61岁)以红色显示。(C) 按实际年龄排列的代谢物水平分布,显示所有观察结果的散点图和平滑曲线(注意 y 轴刻度的差异)。使用广义加性模型估计平滑曲线,阴影区域对应于 95% 置信区间 (CI)。糖A,糖蛋白乙酰基。(D) 散点图显示全因死亡率的风险比 (HR) 以及与代谢物水平 1 个 SD 差异相关的实际年龄的 β。与实际年龄和全因死亡率有统计显着相关性的代谢物以紫色显示。
结果
研究结果表明,根据血浆代谢物谱开发的代谢组衰老时钟可以有效区分生物衰老和时间衰老。在该研究中测试的各种模型中,基于 Cubist 规则的回归模型提供了与健康标记和死亡率最强的预测关联,并且在准确性和稳健性方面优于其他算法。
此外,正的 MileAge delta 值表明衰老加速,与虚弱、端粒较短、发病率较高和死亡风险增加有关。具体来说,MileAge 增量每增加 1 年,全因死亡风险就会增加 4%,在极端情况下,风险比 (HR) 会超过 1.5。
此外,研究表明,加速衰老的人更有可能报告自己的健康状况较差并患有慢性疾病。衰弱和端粒磨损之间的关联尤其明显,其中一些差异相当于衰弱指数得分 18 年的差异。有趣的是,在大多数车型中,女性的里程增量略高于男性。
该研究还证实了代谢物与年龄关系的非线性性质,并强调了统计校正在提高预测准确性方面的效用。此外,比较现有的衰老标记表明,代谢组衰老时钟捕获了独特的健康相关信号,并且通常优于更简单的预测因子。然而,结果强调,减缓衰老(负 MileAge 增量)并不能始终转化为更好的健康结果,凸显了生物衰老指标的复杂性。
结论
总体而言,该研究证明了代谢组衰老时钟在预测生物衰老和相关健康结果方面的效用。通过对多种机器学习算法进行基准测试,研究结果还表明,Cubist 基于规则的模型在将代谢物衍生的年龄与健康标记和死亡率联系起来方面具有卓越的性能。
结果表明,代谢组衰老时钟具有主动健康管理和风险分层的潜力,并强调需要在不同人群和纵向数据中进一步验证,以实现更广泛的临床应用。这项研究为算法开发设定了新的基准,说明代谢组学概况如何为衰老和健康提供可行的见解。
期刊参考:
- 穆茨,J.,伊涅斯塔,R.,&刘易斯,C.M.(2024)。代谢组学年龄 (MileAge) 预测健康和寿命:多种机器学习算法的比较。科学进步。https://www.science.org/doi/10.1126/sciadv.adp3743