
基于机器学习的非对比特征跟踪应变分析和 T1/T2 映射的解释,用于评估心肌活力
作者:Mohammadzadeh, Ali
介绍
缺血性心脏病 (IHD) 仍然是全球发病率和死亡率的主要原因,需要准确的诊断和预后工具来实现最佳的患者管理1,2。心血管磁共振 (CMR) 成像,特别是通过晚期钆增强 (LGE) 成像,已成为评估心肌活力和纤维化的金标准。LGE 能够精确区分缺血性和非缺血性病因,为血运重建策略和风险分层的临床决策提供重要信息3,4,5。然而,该技术存在明显的局限性,包括肾病或对比剂过敏患者的禁忌症、由于对比剂保留需要 10-15 分钟的延迟而导致扫描时间延长,以及无法提供全面的功能见解2,5。
对替代诊断方法的日益增长的需求引发了人们对无造影剂技术的兴趣,这些技术可能会减少扫描时间、降低成本并提高 CMR 的可及性。特征跟踪 (FT) 应变分析和 T1/T2 映射等新方法已成为有前景的无钆心脏表型分析方法2,6,7。虽然初步研究显示出令人鼓舞的结果,但 Tantawy 等人的研究表明。显示 FT-CMR 区分可行片段和不可行片段的能力6和达斯蒂达等人。强调原生 T1 映射在可行性评估中的潜力7,大多数研究都受到孤立参数分析或小样本量的限制。
人工智能(AI)在心血管成像领域的快速发展为提高诊断准确性和效率开辟了新途径5。基于人工智能的方法已在各种 CMR 应用中展现出显着的实用性,包括自动图像采集、重建和分析,同时提供有价值的诊断和预后信息8。AI 模型支持的非对比 CMR 检查的最新发展在检测心肌梗塞方面显示出有希望的结果2,9,10,11。然而,这些方法在不同节段和冠状动脉区域的综合心肌活力评估中的应用和验证在很大程度上仍未得到探索。
本研究旨在评估 FT 应变分析和 T1/T2 映射与机器学习 (ML) 模式识别技术相结合的综合功效,以预测心肌活力。通过对这些非对比方法和已建立的 LGE 技术进行系统比较,我们试图确定它们的相对诊断准确性和在临床实践中的潜在优势。这项研究代表了开发更容易、更有效和更全面的心肌活力评估方法的关键一步,有可能改变当前的心脏成像诊断范式。
方法和材料
研究设计
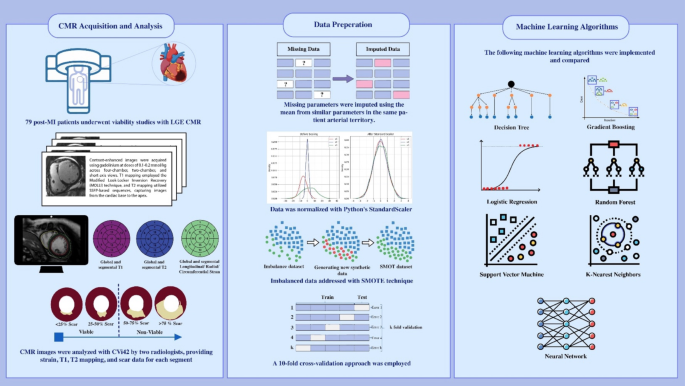
本研究对心肌梗死 (MI) 患者进行回顾性分析,这些患者在 MI 后两到四周内使用 LGE CMR 进行生存力研究。主要目的是评估 FT 应变分析和 T1/T2 映射与 ML 相结合,与 LGE 相比预测心肌活力的功效。研究方法的总结如图所示。 1。图1图形摘要。

研究人群
这项回顾性研究纳入了 ST 段抬高型心肌梗死患者,这些患者在 2020 年 1 月至 2021 年 12 月的两到四周内接受了 LGE CMR 进行生存能力评估。该研究是根据赫尔辛基宣言进行的,并获得了伦理委员会的批准
Rajaie 心血管医学和研究中心委员会。由于这是一项回顾性研究,机构伦理委员会放弃了知情同意的要求。所有方法均按照相关指南和规定进行。研究人群选自心肌梗死患者数据库,确保全面收集临床和影像数据以进行稳健分析。
纳入和排除标准
纳入标准包括年龄 18 岁或以上、经临床、生化和心电图标准确诊为 ST 段抬高型 MI 的患者,这些患者在 MI 后 2 至 4 周完成了 LGE CMR 生存力研究。
排除标准包括有 CMR 禁忌症的患者,例如植入金属装置、不完整或质量差的影像数据、冠状动脉旁路移植术 (CABG) 病史或指数 MI 之前的其他重大心脏手术史以及可能影响生存或生存的严重合并症。成像结果。如果患者接受过其他形式的生存能力评估,例如正电子发射断层扫描(PET),也被排除在外,以避免混淆结果。
CMR 成像采集
使用 Sola MRI(具有 32 通道设置的 1.5 Tesla XA20)进行 CMR 采集涉及详细的协议,以确保高质量成像,特别是对于 LGE。最初,使用基于钆的试剂以 0.1 至 0.2 mmol/kg 的剂量进行对比。成像从多个平面开始,包括四腔、两腔和短轴 (SA) 视图。视场 (FOV) 设置为 300 毫米,六个切片的切片厚度为 6 毫米。造影剂管理后,在 1 至 3 分钟内捕获初始图像,以评估反转时间 (TI) 大于 400 毫秒的早期造影剂分布。随后,在对比后 10 分钟以上获取 LGE 图像,以突出显示心肌纤维化或疤痕区域,确保最佳的组织特征和诊断准确性。
CVi42数据预处理
在 Sola MRI(1.5 Tesla XA20,32 通道)上采集 CMR 后,医学数字成像和通信 (DICOM) 图像将被导出以供进一步分析。将图像导入 CVi42(加拿大卡尔加里循环心血管成像公司),用于评估全局纵向应变 (GLS)、全局周向应变 (GCS) 和全局径向应变 (GRS)。这些参数可以检测心脏力学的细微异常。此外,CVi42 支持 T1 和 T2 映射,这对于组织表征至关重要。T1 映射能够评估心肌纤维化和细胞外容量,而 T2 映射用于检测水肿和炎症。这些先进的分析有助于诊断各种心脏疾病并监测疾病进展或对治疗的反应。如果图像因伪影或信号丢失而影响观察者的准确解释而导致图像不理想或无法诊断,则图像被排除在研究之外。T1 映射
T1 映射是 CMR 成像中心肌组织表征的关键参数。
它是一种无需钆造影剂即可检测心肌异常的有前途的工具。心肌T1弛豫时间反映了心肌细胞内和细胞外成分的变化。各种病理会影响 T1 值,例如胶原沉积(心肌纤维化)、水(水肿和炎症)、脂质(法布里病)和铁(含铁血黄素沉着症)。T1 图是从一系列 T1 加权图像生成的,每个像素代表一个特定的 T1 值,从而可以精确量化组织特征。T1 映射可以使用多种采集方法进行,其中通常使用修改后的锁定器反转恢复 (MOLLI) 序列,如我们的研究中所示。从心脏的基部到心尖至少采集三幅 SA 图像。专用 CMR 软件用于量化 T1 地图图像,可以手动或使用自动功能绘制轮廓。原始 T1 值是通过在特定心肌区域上手动绘制感兴趣区域 (ROI) 或通过以 AHA 分割格式呈现数据来获得的。据报道,使用 MOLLI 方法获得的正常心肌天然 T1 参考范围在 1.5 特斯拉时为 930±±21 毫秒(图 1)。 2)。图2对一名患有 STEMI 中 LAD 区域 MI 的 57 岁男性进行生存能力评估。

一个) 左心室前间壁底部至中部的透壁 LGE。(乙) 用于 T1 和 T2 评估的 LV 壁轮廓。(C) 由于间隔纤维化,左室前间壁基底部到中段的 T1 值较高 (T1 = 1043 ms)。(D) T1 加权左心室壁极坐标图显示间隔壁 T1 值增加。(乙) T2 加权左心室壁极坐标图显示间隔壁的正常 T2 值 (T2 = 48 ms)。
T2 映射
与 T1 值类似,T2 值代表来自细胞内和细胞外区室的全局信号。每种组织类型都有 T2 值的正常范围,T2 值升高通常表明含水量升高。因此,心肌水肿(炎症)是导致T2值升高的主要病理。T2 作图序列有助于检测急性 MI 和心肌炎患者的心肌水肿。据报道,使用基于稳态自由进动 (SSFP) 的序列获得的正常心肌 T2 值在 1.5 特斯拉时为 52.18±±3.4 毫秒(图 1)。 2)。用于应变分析的特征跟踪
心肌应变测量心肌在松弛和收缩状态之间的变形
12。在缺血性心脏病中,应变在预测主要不良心脏事件方面优于左心室 (LV) 射血分数或梗塞面积等已知风险标记13。
有多种 CMR 应变技术可用,包括标记、受激回波位移编码 (DENSE) 和应变编码 (SENC),这些技术需要专用序列。然而,最常用的技术是 FT,它处理常规采集的电影 SSFP MR 图像13,14。FT 后处理涉及在短轴和长轴电影图像上定义心内膜和心外膜边界,并在收缩末期和舒张末期描绘心室长轴13,15这样可以测量周向、纵向和径向应变参数(GLS、GCS、GRS)。这些步骤可以使用后处理软件的人工智能 (AI) 功能快速完成。
可以显示整个心脏(全局)、切片级别(基底、中部、心尖)、AHA 节段或特定 ROI 内的应变值。极坐标图可以显示所有 17 个部分的应变指标,并且颜色编码的应变数据可以叠加在电影 SSFP 图像上以增强可视化(图 1)。 3)。

一名 57 岁男性,患有 LAD 领土 MI。(一个) 描绘 SAX 中部彩色编码应变的成像。(乙) 显示特定 ROI(左心室前间壁中部)周向应变减少的图表。(C) 周向应变值的极坐标图。
统计分析
排除或估算缺失值
在进行机器学习分析之前,我们评估了 T1 和 T2 映射以及应变特征跟踪,以保持最佳的数据质量。如果给定区域内多个区段包含缺失值,则将患者排除在分析之外。对于 T1、T2、纵向、径向或周向应变中存在单个缺失值的情况,通过对同一区域内相邻段的值进行平均来估算缺失值。这种方法用相应组的可用值的平均值替换了缺失的数据,如下所示。
$$\:{\widehat{\text{x}}}_{\text{i}\text{j}}=\:\frac{1}{{\text{n}}_{\text{i}}}\sum\:{\text{x}}_{\text{i}\text{j}}\:\ne\:\text{N}\text{A}$$
\(\:{\widehat{\text{x}}}_{\text{i}\text{j}}\):缺失值的估算值,\(\:{\text{n}}_{\text{i}}\):第 i 组中非缺失值的数量,\(\:{\text{x}}_{\text{i}\text{j}}\):第 i 组变量 j 中的观测值,NA 表示缺失值。
正常化
在 Python 中使用 StandardScaler 进行标准化涉及到转换数据集的特征,使它们的平均值为 0,标准差为 1。这种标准化确保每个特征对分析的贡献相同,这可以提高许多 ML 算法的性能。应用的归一化公式为:
$$\:\text{z}=\frac{x-\mu\:}{\sigma\:}$$
\(\:x\)表示原始特征值,μ 是特征的均值,Ï 是特征的标准差。此过程将数据调整到通用范围,而不会扭曲值范围的差异,从而确保分析的一致性和可靠性。
合成少数过采样技术(SMOTE)
合成少数过采样技术 (SMOTE) 是一种用于解决数据集中类别不平衡的技术,特别是在一个类别占主导地位的情况下,可能会影响分类器的性能。SMOTE 的工作原理是选择一个少数类实例,识别其 k 最近的少数类邻居,并沿着连接该实例及其邻居的线段创建合成实例。生成合成实例的公式为:
$$\:{X}_{新}={X}_{i}+\lambda\:\left({X}_{j}-{X}_{i}\right)$$
在这里,X我代表少数类实例,Xj表示其 k 个最近邻之一 (k−=−5),Δ 是 0 到 1 之间的随机数。
在我们的研究中,应用 SMOTE 来确保训练数据集的平衡,从而提高分类器有效处理不平衡数据的能力。
数据集分割和十倍交叉验证
采用 10 倍交叉验证方法来确保稳健评估并防止过度拟合。该方法涉及将数据集分为十个子集,在每次迭代中使用九个用于训练,一个用于测试,确保每个子集仅用于测试一次。
$$\:{CV}_{错误}=\frac{1}{k}\sum\:_{i=1}^{k}{错误}_{i}$$
机器学习算法
实现并比较了以下 ML 算法:决策树、梯度提升、逻辑回归、朴素贝叶斯、随机森林 (RF)、支持向量机 (SVM)、K 最近邻 (KNN) 和神经网络(全连接)。每个算法都使用网格搜索进行调整,以优化超参数并增强性能。
资源和要求
在机器学习任务中,我们使用了搭载 Apple M2 芯片的 M2 MacBook Pro 设备,配备 8 核 CPU 和 10 核 GPU,配备 16GB 统一内存,可高效处理数据密集型操作,确保性能流畅在模型训练和评估期间。它在所有机器学习任务中表现出稳定、流畅的性能,没有任何下降或中断。
决策树
决策树递归地将特征空间划分为最小化杂质的区域,通常通过分类任务的熵来衡量。
熵公式
$$\:\text{H}\left(\text{T}\right)=-\sum\:_{i=1}^{c}p\left(i|T\right){\text{日志}}_{2}p\left(i|T\right)$$
H(T):节点T的熵,p(i|T):节点T中I类样本的比例,c:类的数量(本研究中c≤=≤2)。
在这个分类器中,我们使用基尼分数和最佳分割器的标准,没有类别权重。
梯度提升
梯度提升按顺序组合弱学习器以最小化损失函数,以 0.001 的学习率调整预测
$$\:{\widehat{y}}_{i}^{(t+1)}={\widehat{y}}_{i}^{\left(t\right)}+\eta\:.{h}^{\左(t\右)}\左({x}_{i}\右)$$
\(\:{\widehat{y}}_{i}^{\left(t\right)}\):迭代 t 时集合的预测。\(\:{h}^{\left(t\right)}\left({x}_{i}\right)\)
:弱学习者(例如,决策树)x 样本的预测我。逻辑回归
逻辑回归使用逻辑函数对二元结果的概率进行建模。
物流功能
$$\:\text{P}\left(y=1|x\right)=\frac{1}{1+{e}^{-\left({w}^{T}x+b\right
)}}$$
w:系数(权重),x:输入特征,b:偏差项。
LogisticRegression 的默认配置使用 lbfgs 求解器,它非常适合中小型数据集。它采用 L2 正则化(惩罚=-l2-),正则化强度为 C-=-1。class_weight 参数设置为 None,表示除非另有说明,否则所有类都受到同等对待。优化过程的上限为最多 100 次迭代 (max_iter–=–100),以确定最佳解决方案。
损失函数(二元交叉熵)
$$\:\mathbf{L}\left(\varvec{w},\varvec{b}\right)=-\frac{1}{\varvec{N}}\sum\:_{\varvec{i}=1}^{\varvec{N}}\left[{\varvec{y}}_{\varvec{i}}\mathbf{log}\left(\varvec{P}\left(\varvec{y}=1|\varvec{x}\right)\right)+1-{\varvec{y}}_{\varvec{i}}\mathbf{log}\左(1-\varvec{P}\left(\varvec{y}=1|\varvec{x}\right)\right)\right]$$
\(\:\mathbf{L}\left(\varvec{w},\varvec{b}\right)\):二元交叉熵损失,y我:样品 i 的实际标签,P(y−=−1|x):样本 I 的类别 1 的预测概率,N:样本数。随机森林RF 构建决策树集合,其中每棵树都构建在特征的随机子集和数据的随机子集上。
在随机森林中,以基尼分数为准则来使分类器的效率最优,如下所示:
$$\:基尼=1-\sum\:_{i=1}^{c}{p}_{i}*\left({1-p}_{i}\right)$$
c:目标变量中的类数。
p:节点中第 i 类的比例(或概率)。
具有线性核和概率的支持向量机 (SVM)
SVM 找到一个在特征空间中分隔类别的超平面,其中线性核表示线性决策边界。
线性 SVM 的决策函数\(\:f\left(x\right)={w}^{T}x+b\)
w:权重向量,b:偏差项。
概率估计
$$\:P\left(y=1|x\right)=\frac{1}{1+{e}^{-f\left(x\right)}}$$
在这个实验中,我们使用了正则化参数(c≤=≤1.0),RBF核,以及决策函数形状�ovr�(一对一)来优化分类过程。
K-最近邻(KNN)
KNN 根据特征空间中 k 个最近邻中的多数类对样本进行分类。在本研究中,我们考虑了 K−=−5。
决策规则
$$\:\widehat{y}=arg\:max\:{y}_{j}\sum\:_{i\in\:{N}_{k}\left(x\right)\:}I\左({y}_{i}={y}_{j}\右)$$
\(\:\widehat{y}\):新样本 x 的预测类别,Nk(x) x 的 k 个最近邻集,I:指示函数。
神经网络
神经网络 (NN) 由互连的神经元层组成,这些神经元学习数据的表示。在本研究中,使用了多层感知器分类器(MLPClassifier),具体细节如下:
隐藏层变换的输入
$$\:{h}_{j}=f\left(\sum\:_{i=1}^{c}{w}_{ij}{x}_{i}+{b}_{j}\右)\:\:$$x我
:第i个输入特征。wijâ:将第 i 个输入连接到第 j 个神经元的权重。乙贾:第 j 个神经元的偏差项。f :ReLU 激活函数。
隐藏层到输出层的转换
$$\:{z}_{k}=g(\sum\:_{j=1}^{m}{w}_{ik}{h}_{j}+{b}_{k})$$小时j
—:隐藏层第j个神经元的输出。wj:连接第 j 个隐藏神经元和第 k 个输出神经元的权重。乙k–:第 k 个输出神经元的偏置项。g:输出激活函数。
预测的类别是概率最高的类别:
$$\:\widehat{y}=argma{x}_{k}\left({\widehat{y}}_{k}\right)$$
我们设置max_iter=-1000来定义优化算法收敛的最大迭代次数。此外,我们将模型的隐藏层大小配置为100(hidden_layer_sizes=(100)),使用“relu”作为激活函数,选择Adam求解器进行优化,并应用恒定的学习率来调节训练过程。
评估指标
使用多种评估指标来评估 ML 的性能,包括曲线下面积 (AUC)、精度、召回率、准确性和 F1 分数。这些指标提供了对模型预测能力的全面评估。
AUC 通过评估受试者工作特征 (ROC) 曲线下的面积来衡量分类模型的整体性能。尽管 AUC 本身没有简单的封闭式公式,但它的计算方式为 ROC 曲线下的面积,该曲线绘制了不同阈值设置下的真阳性率 (TPR) 与假阳性率 (FPR) 的关系。
精度衡量的是预测阳性中真阳性的比例,并使用以下公式计算:
$$\:\text{精度}=\frac{\text{TP}}{\text{TP+FP}}$$
召回率也称为敏感性或真阳性率,表示真阳性占所有实际阳性的比例。召回率的公式为:
$$\:\text{回忆=}\frac{\text{TP}}{\text{TP+FN}}$$
准确度反映了预测的整体正确性,使用以下公式计算:
$$\:\text{准确度=}\frac{\text{TP+TN}}{\text{TP+TN+FP+FN}}$$
F1 分数通过考虑两个指标的调和平均值,在精确度和召回率之间提供平衡。F1分数的计算公式为:
$$\:{\text{F1 = 2}} \times \frac{{{\text{精度}} \times {\text{召回率}}}}{{{\text{精度 + 召回率}}}}$$
这些指标共同给出了模型性能的全面描述,其中 AUC 评估整体性能,精确测量积极预测的准确性,召回率表明模型捕获实际积极因素的能力,准确性反映预测的正确性,而 F1平衡精确度和召回率之间的分数。
特征选择和消融研究
评估特征重要性以确定预测心肌活力最有影响力的参数。使用排列重要性和 SHapley 加法解释 (SHAP) 值等各种技术对特征进行排序。进行消融研究以确定各个特征对模型性能的影响。这涉及一次系统地删除一个特征并观察评估指标的变化,从而突出每个特征对模型预测准确性的贡献。
结果
在这项研究中,一开始就招募了 90 名患者,但由于既往有缺血或 CABG 病史、影像质量缺乏、T1 和 T2 标测以及应变分析不合适,有 11 名患者被排除。其余 79 名患者接受了统计和 ML 分析。在入组患者中,根据 LGE 活力评估,52.8% 的参与者(47 人)的左前降支 (LAD) 区域具有活力。59.5% 的参与者(53 人)的右冠状动脉 (RCA) 区域是可行的。60.6% 的参与者(54 人)的左回旋动脉 (LCX) 区域是可行的。(图. 4;表 1)。
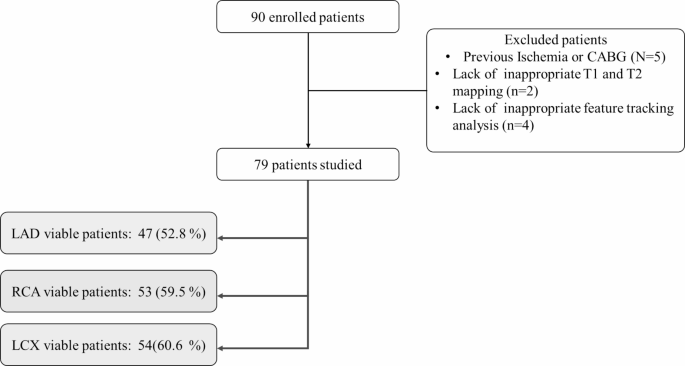
流程图描绘了登记的研究人群和可行区域的分布。
患者的人口统计特征
该研究涉及的参与者平均年龄为 47.97 岁,标准差为 12.48 岁。参与者中,83.5%(66 人)为男性。在健康状况方面,43.0%(34人)患有高血压,32.9%(26人)患有糖尿病,26.5%(21人)患有高脂血症。此外,35.4%(28 人)是吸烟者。
功能指标左心房面积平均值为23.56±±11.97 cm2。右心房平均值为19.99±±18.31 cm2。左心室射血分数(LVEF)平均值为28.13±±10.26。舒张末期容积指数 (EDVI) 平均值为 131.83±±62.43 ml/m2,而收缩末期容积指数(ESVI)的平均值为98.95±±54.55。毫升/立方米2。左心室每搏输出量 (LVSV) 平均值为 58.91 ml±±17.76。
右心室的右心室射血分数(RVEF)平均值为44.64±±12.02。右心室舒张末期容积指数 (RVEDVI) 平均值为 78.67 ml/m2—±—38.27。右心室收缩末期容积指数 (RVESVI) 平均值为 45.52 ml/m2—±—31.30。最后,右心室每搏输出量 (RVSV) 的平均值为 54.73 ml±±16.97。表 2总结了完整的人口统计和功能指标。
数据调整
对 LAD、RCA 和 LCX 中非存活区域与存活区域的个体的分析显示,临床因素(高血压、糖尿病、高脂血症、吸烟)或影像参数(心房面积、心室功能、容量)没有显着差异。只有 RCA 地区的年龄才达到显着水平(磷–= –0.05),有活力的地区显示出略高的平均年龄(表 3)。在 LAD 区域,非存活片段显示径向和周向应变减少,T1 和 T2 值升高。RCA 区域仅在非生存区域表现出较高的 T2 值。LCX 区域在非存活片段中表现出较低的应变值和较高的 T1 和 T2 值(表 4;图。 5)。

每个冠状动脉区域的非存活区域与存活区域的特征改变。(一个)小伙子,(乙)RCA,和(C)LCX。预测每个区域生存能力的各种模型的进化指标
在LAD领域,RF模型展示了最高的AUC(0.87)和强大的整体性能,准确度、平衡准确度和F1分数为0.74。
逻辑回归也表现良好,达到了 0.83 的 AUC、最高准确率(0.78)和平衡准确率(0.77)。虽然 KNN 模型具有相对较高的 AUC(0.82)和准确度(0.75),但其召回率较低(0.65),尽管它具有较高的精确度(0.84)。NN、SVM、梯度提升和决策树模型表现出中等的性能,但强度各异,其中 NN 和 SVM 模型实现了平衡的精度,F1 分数约为 0.70-0.74。梯度提升和决策树的 AUC 最低(分别为 0.73 和 0.72),其他类别的指标相应较低。
对于 RCA 领域,RF 模型表现最好,达到了最高的 AUC 0.90 和强大的整体指标,包括 0.79 的准确度和 0.78 的 F1 分数。NN 模型也表现良好,AUC 为 0.84,最高准确率为 0.81,平衡准确率为 0.81,尽管其召回率较低,为 0.69。KNN 模型的 AUC 较低,为 0.80,准确度为 0.70,召回率特别低,为 0.54。Logistic 回归和 SVM 的性能中等,AUC 分别为 0.76 和 0.74,平衡准确度约为 0.72–0.73。梯度提升和决策树的 AUC 最低,分别为 0.74 和 0.72,相应的准确度和 F1 得分也较低。
对于 LCX 领域,RF 和 NN 模型均达到了最高 AUC 0.92。NN 模型还具有最高的准确率 (0.87)、平衡准确率 (0.87)、召回率 (0.83)、准确率 (0.90) 和 F1 分数 (0.86)。RF 模型紧随其后,准确度为 0.83,平衡准确度为 0.83,F1 得分为 0.81。Logistic回归和SVM模型也表现良好,Logistic回归的AUC为0.91,准确度为0.84,F1得分为0.83,而SVM的AUC为0.89,准确度为0.83,F1得分为0.82。KNN 模型的 AUC 较低,为 0.87,准确率为 0.74,召回率为 0.62。梯度提升和决策树表现出最低的性能,AUC 分别为 0.76 和 0.74,并且在准确度、平衡准确度和 F1 分数方面相应的指标也较低(表 5;图。 6)。

用于预测 LGE 的各种机器学习模型的 AUC 曲线。
选型
在研究的模型中,RF、KNN 和逻辑回归在评估 LAD 区域心肌活力方面表现出优异的性能。对于RCA领土,RF,NN和KNN成为表现最好的人,而RF,NN和Logistic回归在LCX领域都表现出色。
表格中详细介绍的特征重要性分析 6;图 7,在预测参数中揭示了特定于区域的模式。在LAD领土中,最具影响力的特征是由段13和14的T2映射参数以及节段7和1的节段径向应变测量的主导。RCA领域显示出对映射参数的强烈依赖,而T2映射来自片段9和3,以及从段9映射的t1映射,作为关键预测指标。LCX领域表现出不同的特征,其中应变测量起着至关重要的作用,尤其是节段11,段6的T2映射和节段5的节段性纵向应变(表)(表)(表) 7)。表6归一化特征重要性以及基于三种表现最佳模型的前10个最重要功能的选择。

表7与其他细分和特征相比,每个段中T1/ T2映射和特征跟踪分析的重要性。
进行了SHAP评估,以确定影响LGE预测的最重要特征。
获得的结果与上一节中报道的平均特征重要性紧密相吻合(图 8)。

Shap分析显示了在冠状动脉领土上预测LGE的前三个最佳模型中每个功能的重要性。
讨论
在缺血性心脏病中,检测储蓄以外的区域与寻找可挽救的组织一样重要。因此,生存能力研究现在是IHD管理部门不可或缺的一部分16,17 号。当前的生存力研究基于LGE作为纤维化的代表性标记和随后的细胞外体积扩张。T1/T2映射和应变分析等其他成像特性理论上显示了与组织代替的一致的变化,这使它们成为可行性评估的潜在标记18,19 号,20。与LGE相反,为了测量这些标记,不需要对比度注射,这可以使可行性研究更快,更安全,尤其是在IHD患者中患有肾脏疾病风险增加并且更可能无法无法进行的人要长时间成像方式21,22。在当前的研究中,通过采用多个ML模型,我们试图提取最佳特征,以预测由菌株,T1和T2映射值确定的LGE确定的心肌组织生存能力。这可以为建立心肌组织生存能力的复杂预测模型提供基础,而无需LGE序列。
先前的研究表明,使用非对比度CMR图像作为LGE-CMR检测心肌梗死的替代方案的有希望的结果,从而消除了注射gadolinium的需求。几项关键研究表明了这一潜力。Baessler等。使用放射线特征和逻辑回归模型评估了72例患者(52例具有心肌梗塞,20个健康对照),用于大型梗塞的AUC为0.93,而小梗塞的AUC为0.929。Zhang等人对843例使用深度学习虚拟天然增强模型的心肌梗死患者的研究表明,与LGE在疤痕定量中的相关性很强(右检测疤痕的0.89)和84%的精度2。其他研究包括Chen等人使用合并的生理临床ML模型对150名患者的研究,达到88.67%的分类精度23,Xu等人在Cine-CMR图像上与深层时空生成对抗网络一起工作,达到96.98%的像素分类精度24。Abdulkareem等。使用U-NET和RESNET50模型分析了272名患者(108例具有梗塞,164个对照),SVM的精度得分为0.68,决策树达到0.6225。
然而,对不同部分和冠状动脉领土上的心肌生存能力的非对比度评估仅限于孤立的参数分析和小样本量。两项著名的研究探讨了这一领域:Dastidar等。与60名患者的LGE(慢性MI中的AUC为0.88,急性MI中的AUC为0.88)相比,使用天然T1映射具有出色的诊断精度7,而Tantawy等。使用特征跟踪应变分析(圆周菌株的AUC为0.7,径向应变为0.67)显示中等诊断精度6。因此,我们的研究首次旨在评估与ML模式识别技术集成的FT菌株分析和T1/T2映射的综合功效,以预测节段和冠状动脉区域的心肌生存能力。值得注意的是,在先前的研究中尚未解决冠状动脉区域生存能力的评估。
该分析为有关血运重建策略和风险分层的临床决策提供了至关重要的信息。
我们发现,在LAD领土内,RF,Logistic回归和KNN具有最高的可行性歧视能力。提取的十个最有价值的特征包括各种节段径向和圆周峰菌株以及T2映射以及全局T2映射。关于LCX领土,RF,NN和Logistic回归是最富有成果的方法。所有段的周向菌株都在十个最佳特征之内,而在这些特征中只有一个段的径向和纵向应变。还发现基底T1和基础T2是可行性评估最有效的特征。关于RCA,RF,NN和KNN提供的细分,发现较高。十个最有效的功能仅包含T1和T2映射值,除了一个中段的圆周应变。
与先前的文献相似,我们发现可行区域和不可生存区域之间的最高歧视价值是圆周和径向菌株,而不是纵向菌株6。GC和GRS与LVEF显示最高的相关性,而GLS是最小相关的全局应变6,26。此外,圆周全球应变是最可重复的全球菌株6,27。因此,与其他应变值相比,考虑到可行性预测的可行性预测可能更实用,尤其是在LAD领土上。
节段性峰值菌株的另一个优点是它们对其各自细分的心肌生存能力评估的歧视价值6。据我们所知,这项研究是第一个追求应变和T1和T2映射特征,以根据冠状动脉循环领域确定心肌活力。根据理论上评估其各自的冠状区域,评估节段菌株以及T1和T2映射值可以增强心肌组织生存力预测。我们发现每个冠状动脉领域最有价值的特征不同。RCA领域的最佳提取特征主要是T1和T2映射,而LAD和LCX的特征主要是分段峰值菌株。这种差异的可能解释是,主要由右心室组成的RCA领土的应变值不能像LCX和LCA领土一样精确,准确地测量28。
许多研究追求峰值应变值的切点,以区分可行和不可行的心肌6,29。但是,我们试图建立一个基础,以开发由最佳歧视性特征组成的ML模型,并考虑到动脉领土以达到更高的准确性。鉴于心肌组织冬眠/惊人和生存性病理生理学的复杂性,最终模型假设超过了单个特征的歧视力。
这项研究的结果表明,以FT应变分析和T1/T2映射为指导的ML技术的潜力,以高精度预测心肌活力。这种方法提供了基于传统的LGE方法的非对抗性替代方法,可解决与LGE相关的一些局限性,例如对比剂依赖性和无法启发心肌组织功能特征。
我们的结果表明,ML模型,尤其是梯度提升和RF,具有高性能指标,以预测心肌活力,具有AUC,精度,召回,准确性,准确性和F1得分,可与LGE获得的分数相当。30,31。这一发现与以前的研究一致,这些研究强调了ML算法在心脏成像和生存能力评估中的有效性32,33。FT应变分析和T1/T2映射的整合提供了对心肌组织特征的更全面评估,可能会增强诊断能力,超出单独使用LGE的功能34,35。
使用5层完全连接的NN的深度学习模型也表现出强大的预测性能。这支持了越来越多的证据表明,深度学习技术可以有效地处理复杂的,高维数据,并发现传统方法之外的复杂模式。36。先前的研究表明,深度学习模型可以在包括心脏成像在内的各种医学成像任务中胜过常规的ML算法。我们的研究通过在心肌生存能力评估中证明深度学习的适用性增加了这一文献。
使用FT应变分析和T1/T2映射的一个重要优点是能够提供有关心肌的功能和结构信息,而无需对比度给药。这对于患有Gadolinium对比剂的禁忌剂作为患有慢性肾脏疾病的患者特别有益10。此外,这些无对解的技术可以轻松地集成到常规的CMR方案中,从而有可能增加其在临床实践中的采用并减少健康支出37。但是,ML和深度学习技术的应用需要大量的计算资源和专业知识,这可能会限制其在临床环境中的广泛使用而没有适当的支持和基础架构。
这项研究表明,ML和深度学习技术可以根据FT菌株分析和T1/T2映射数据有效地预测心肌活力,从而提供LGE的有希望的替代方案。未来的研究应集中在这些发现的前瞻性验证,将这些技术的整合到临床工作流程中,以及探索它们改善患者预后的潜力。这种方法有可能提供当前方法的全面,无创和患者友好的替代品。机器学习在医学成像诊断中越来越重要,但是它面临需要解决的关键限制。其中包括小样本量问题和标记数据的稀缺性,在复杂诊断方案中管理多个优化目标方面的效率低下,以及在流媒体医学数据实时处理方面的挑战。尽管最近的研究在克服这些问题方面取得了长足的进步,但进一步的研究是必要的38,39,40,41。此外,深度学习体系结构,尤其是卷积神经网络(CNN),在自动从医学图像中提取相关功能方面表现出显着的功能,通常在特定诊断任务中匹配或超过人类水平的表现42,43,44,可以进一步用于心肌生存能力评估。
局限性
我们研究的主要局限性源于与回顾性设计相关的固有偏见以及回顾性收集的数据质量。尽管SMOTE的使用有助于减轻班级失衡,但无法完全解决此问题。因此,使用各种MRI扫描仪和后处理软件的未来前瞻性研究对于验证我们的发现至关重要。值得注意的是,在这项研究中,心肌生存力分为两组:可行且不可行,可行类别中包含远程心肌区域。此外,放射学专家的参与对于应用此模型时准确测量应变和描述ROI仍然至关重要。
结论
总之,研究表明,RF和NN模型在预测不同冠状动脉领土的心肌生存力方面提供了最高的准确性,在RCA和LCX区域具有显着性能。包括T1/T2映射和应变分析在内的非对比度成像技术的整合在增强生存力评估方面有价值。这些成像技术的关键特征显着有助于预测建模,突出了它们提高MI诊断准确性的潜力。这项研究强调了高级成像与ML相结合以优化心脏生存能力评估的希望。进一步的研究应考虑使用多个临床环境中的多样化患者人群,并使用多个MR扫描仪和后处理软件来验证本研究的有希望的发现。此外,执行放射组学分析可能会改善模型的性能。
数据可用性
根据合理的要求,可以从通讯作者(mralimohammadzadeh@yahoo.com)获得支持本研究发现的数据。
参考
Giovanni,A。等。心血管疾病和危险因素的全球负担,1990年2019年:GBD 2019研究的更新。J. Am.科尔。心脏。 76(25),2982 3021(2020)。
张,Q.等人。无对比度MRI的人工智能:使用基于深度学习的虚拟本地增强的心肌梗死中的疤痕评估。循环 146(20),1492 - 1503(2022)。
Roes,S。D.等。通过对比增强的磁共振成像和左心室功能和体积评估的心肌梗死大小的比较,以预测愈合心肌梗塞患者的死亡率。是。J.卡迪奥尔。 100(6),930 936(2007)。
Kelle,S。等。使用磁共振成像的心肌梗死大小和收缩储备的预后价值。J. Am.科尔。心脏。 54(19),1770年1777年(2009年)。
Cau,R。等。心血管磁共振成像中的人工智能应用:我们是否正在避免对比造影介质的给药?诊断 13(12),2061(2023)。
Tantawy,S。W.,Mohammad,S。A.,Osman,A。M.,El Mozy,W。&Ibrahim,A。S.使用特征跟踪心脏磁共振共振(FT-CMR)的菌株分析,以评估慢性缺血患者的心肌生存能力。国际。J.心血管。影像学 37(2),587 A 596(2021)。
Dastidar,A。G。等。天然T1映射以检测急性和慢性心肌梗塞的程度:与晚期增强技术的比较。国际。J.心血管。影像学 35,517 A527(2019)。
Cau,R。等。人工智能在心脏磁共振成像中的潜在作用:它可以帮助临床医生做出诊断吗?J·索拉克。成像。 36(3),142â148(2021)。
Baessler,B。等。亚急性和慢性左心室心肌疤痕:非增强Cine MR图像的纹理分析的准确性。放射科 第286章(1),103â112(2018)。
Avard,E。等。非对比度的Cine心脏磁共振图像放射线学特征和机器学习算法用于心肌梗塞检测。计算。生物。医学。 141,105145(2022)。
Larroza,A。等。急性和慢性心肌梗塞通过质地增强和Cine心脏磁共振成像的质地分析之间的区分。欧元。J.Radiol。 92,78 - 83(2017)。
Amzulescu,M。S。等。心肌应变成像:综述,验证和差异来源的综述。欧元。Heart J. Cardiovasc。影像学 20(6),605â619(2019)。
Schuster,A.,Hor,K。N.,Kowallick,J。T.,Beerbaum,P。&Kutty,S。心血管磁共振心肌功能跟踪:概念和临床应用。循环。心血管。影像学 9(4),E004077(2016)。
Muser,D.,Castro,S。A.,Santangeli,P。&Nucifora,G。特征跟踪心脏磁共振成像的临床应用。世界J. Cardiol。 10(11),210â221(2018)。
Pedrizzetti,G.,Claus,P.,Kilner,P。J.&Nagel,E。心血管磁共振的原理跟踪和超声心动图斑点跟踪,用于知情临床使用。J.心血管。马格。共振。 18(1),51(2016)。
Garcia,M。J.等。艺术状态:心肌生存能力的成像:美国心脏协会的科学陈述。循环。心血管。影像学 13(7),E000053(2020)。
Virani,S。S.等。2023 AHA/ACC/ACCP/ASPC/NLA/PCNA治疗慢性冠状动脉疾病患者的指南:美国心脏协会/美国心脏病学院临床实践指南联合委员会的报告。循环 148(9),E9 e119(2023)。
泰勒·安德鲁(J.JACC:心脏。影像学 9(1),67â81(2016)。
Hamlin,S.A.,Henry,T。S.,Little,B。P.,Lerakis,S。&Stillman,A。E.映射心脏MR成像的未来:基于病例的T1和T2映射技术的评论。射线照相技术 34(6),1594年1611(2014)。
舒斯特(A.循环:心血管成像9(4),E004077(2016)。
Deferrari,G.,Cipriani,A。&La Porta,E。心血管疾病中的肾功能障碍及其后果。J.内弗罗尔。 34(1),137â153(2021)。
Laffin,L。J.&Bakris,G。L.慢性肾脏疾病与心血管疾病之间的交集。电流。心脏。代表。 23(9),117(2021)。
陈,Z.等人。通过机器学习的患者特征预测心肌梗塞的预测。正面。心血管。医学。 9,754609(2022)。
Xu,C。等。通过时空生成对抗性学习对没有对比剂的梗塞进行分割和定量。医学。图像。肛门。 59,101568(2020)。
Abdulkareem,M。等。使用机器学习:挑战和方法从对比度的自由心脏MRI中预测对比后的对比后信息。正面。心血管。医学。 9,894503(2022)。
Kihlberg,J.,Haraldsson,H.,Sigfridsson,A.,Ebbers,T。&Engvall,J。E.使用密集的菌株成像的临床经验,用于检测梗塞的心脏段。J.心血管。马格。共振。 17 号(1),50(2015)。
Morton,G。等。心血管磁共振心肌特征跟踪的研究间可重复性。J.心血管。马格。共振。 14(1),34(2012)。
Lange,T。&Schuster,A。对左心室的CMR-Feature-Tracking的心肌变形的定量?电流。心脏衰竭。代表。 18(4),225â239(2021)。
Becker,M。等。基于超声像素跟踪的心肌变形成像,以识别可逆的心肌功能障碍。J. Am.科尔。心脏。 51(15),1473年1481(2008)。
李,G.等人。使用交织的T1-T2*加权成像映射心肌活力。国际。J.心血管。影像学 20(2),135â143(2004)。
Azzu,A。等。心脏磁共振3D特征跟踪通过心肌菌株分析确定了神经肌肉疾病患者的亚临床异常,没有明显的心脏受累。欧元。Heart J. Cardiovasc。影像学 24(4),503 - 511(2023)。
Rouzrokh,P。等。心血管成像中的机器学习:对已发表文献的范围评论。电流。放射线。代表。 11(2),34â45(2023)。
邢,J.等人。联合深度学习可改善心脏MRI的心肌疤痕检测。过程。IEEE int symp生物成像。2023。(2023)。
Chudgar,P。D.,Burkule,N。J.,Kamat,N。V.,Rege,G。M.&Jantre,M。N.使用心脏MRI的功能跟踪方法:我们对此新颖参数作为附加诊断工具的最初经验。印度J. Radiol。影像学 32(4),479 487(2022)。
泰勒,R。J。等。心肌应变测量具有特征跟踪的心血管磁共振:正常值。欧元。Heart J. Cardiovasc。影像学 16(8),871 - 881(2015)。
Litjens,G。等。医学图像分析中的深度学习综述。医学。图像肛门。 42,60â88(2017)。
Pennell,D。J.心血管磁共振。循环 121(5),692â705(2010)。
Fei,X.,Wang,J.,Ying,S.,Hu,Z。&Shi,J。基于稀疏的多个经验核学习机,用于诊断脑病的稀疏参数转移。神经计算 第413章,271 283(2020)。
石,B.等人。使用联合自适应SIME模具算法的进化机器学习对复发自发流产的预测。计算。生物。医学。 148,105885(2022)。
Chen,M-R。,Zeng,G-Q。&lu,k-d。具有自适应杂化突变操作的多个目标人群极端优化算法。信息。科学。 第498章,62â90(2019)。
Jin,X。EURASIP J. Wirel。交流。网络。 2019年,1 - 7(2019)。
Zeng,N。等。DPMSN:用于图像伪造检测的双通道多尺度网络。IEEE 传输。工业。信息。(2024)。
Xiong,B。等。transemg:一种用于高精确髋关节矩预测的反式杂交模型。IEEE 传输。仪器。测量。(2024)。
文,W.等人。通过通道复发融合的增强多标签心脏病学诊断。计算。生物。医学。 171,108210(2024)。
致谢
作者希望对放射学系Rajaie心血管医学研究中心表示衷心的感谢,以提供本研究中使用的宝贵数据。特别感谢Maedeh Dastmardi博士和Ghazaleh Salehabadi博士在整个研究过程中的宝贵支持和帮助。
道德声明
利益竞争
作者声明没有竞争利益。
科学写作中的生成人工智能宣言
在准备这项工作的过程中,作者使用语法和Chatgpt来纠正文本并使其流利。使用此工具/服务后,作者根据需要审阅和编辑了内容,并对出版物的内容承担全部责任。
附加信息
出版商的注释
施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
权利和权限
开放获取本文获得 Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License 的许可,该许可允许以任何媒介或格式进行任何非商业使用、共享、分发和复制,只要您给予原作者适当的署名即可和来源,提供知识共享许可的链接,并指出您是否修改了许可材料。根据本许可,您无权共享源自本文或其部分内容的改编材料。本文中的图像或其他第三方材料包含在文章的创意共享许可证中,除非在材料的信用额度中另有说明。如果文章的创意共享许可中未包含材料,并且您的预期用途不得由法定法规允许或超过允许的用途,则需要直接从版权所有者那里获得许可。要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

Ghaffarijolfayi,A.,Salmanipour,A.,Heshmat-Ghahdarijani,K。
等人。基于机器学习的非对比度特征跟踪应变分析和T1/T2映射的解释,用于评估心肌活力。科学代表15 ,753(2025)。https://doi.org/10.1038/s41598-024-85029-0
已收到:
公认:
已发表:
DOI:https://doi.org/10.1038/s41598-024-85029-0
关键词
关于《基于机器学习的非对比特征跟踪应变分析和 T1/T2 映射的解释,用于评估心肌活力》的评论
msk553 2025-01-04 22:45:32
詩函本土外送茶 多年老茶坊 有口碑 有保障 兼職正妹各有特色 ◇長腿美女◇大奶空姐◇熱情少婦◇檳榔西施◇柔情學妹 ◇氣質美眉◇高挑女秘◇絲襪OL◇街拍麻豆◇性感人妻 ◇風騷護士◇高校正妹◇火辣舞者◇清涼酒促◇萌系少女 ◇日系台妹◇麻辣教師◇AV女優◇商業秘書◇童顔巨乳 <不話術 不欺騙 見面滿意 現金消費> 賴:https://line.me/ti/p/oiiM8Sw7Gj Telegram:@tt896w 美女頻道:https://t.me/tgdhwd