

REDA:一种新颖的多智能体强化学习人工智能方法,可以解决复杂的序列相关分配问题
作者:Adeeba Alam Ansari
配电系统通常被概念化为优化模型。虽然优化代理执行任务对于检查点有限的系统效果很好,但当启发式处理多个任务和代理时,事情就会开始失控。缩放大大增加了分配问题的复杂性,通常是 NP 困难和非线性问题。优化方法成为房间里的白象,在高资源消耗的情况下提供次优性。这些方法的另一个主要问题是它们的问题设置是动态的,需要迭代的、基于状态的分配策略。当人们想到人工智能中的状态时,首先想到的是强化学习。就作业应用而言,鉴于其时间状态依赖的性质,研究人员意识到顺序决策强化学习的吸引力和巨大潜力。本文讨论了基于状态的分配的最新研究,通过强化学习优化其解决方案。
西雅图华盛顿大学的研究人员引入了一种新颖的多智能体强化学习方法来解决顺序卫星分配问题。多智能体强化学习为大规模、现实的场景提供了解决方案,如果使用其他方法,这些场景将极其复杂。作者提出了一种精心设计并在理论上证明合理的新颖算法来解决卫星分配问题,该算法可确保特定奖励、保证全球目标并避免相互冲突的约束。该方法集成了 MARL 中现有的贪婪算法,只是为了改进其长期规划的解决方案。作者还通过简单的实验和比较,为读者提供了对其工作和全局收敛特性的新颖见解。
其区别在于,代理首先学习预期的分配值;该值用作最佳分布式任务分配机制的输入。这允许代理执行满足分配约束的联合分配,同时在系统级别学习接近最优的联合策略。该论文遵循卫星互联网星座的通用方法,其中卫星充当代理。该卫星分配问题通过支持 RL 的分布式分配算法 (REDA) 来解决。在此,作者从非参数化贪婪策略引导策略,他们在训练开始时以概率 ε 采取行动。此外,为了引发进一步的探索,作者向 Q 添加了随机分布的噪声。REDA 降低复杂性的另一个方面是它的学习目标规范,它确保目标满足约束。
为了进行评估,作者在简单的 SAP 环境上进行了实验,随后将其扩展到具有数百颗卫星和任务的复杂卫星星座任务分配环境。作者引导实验回答一些有趣的问题,例如 REDA 是否鼓励无私行为以及 REDA 是否可以应用于大问题。作者报告说,REDA 立即推动该群体制定最佳联合政策,这与其他鼓励自私的方法不同。对于高度复杂的缩放 SAP,REDA 产生的方差较低,并且始终优于所有其他方法。总的来说,作者报告说比其他最先进的方法提高了 20% 到 50%。
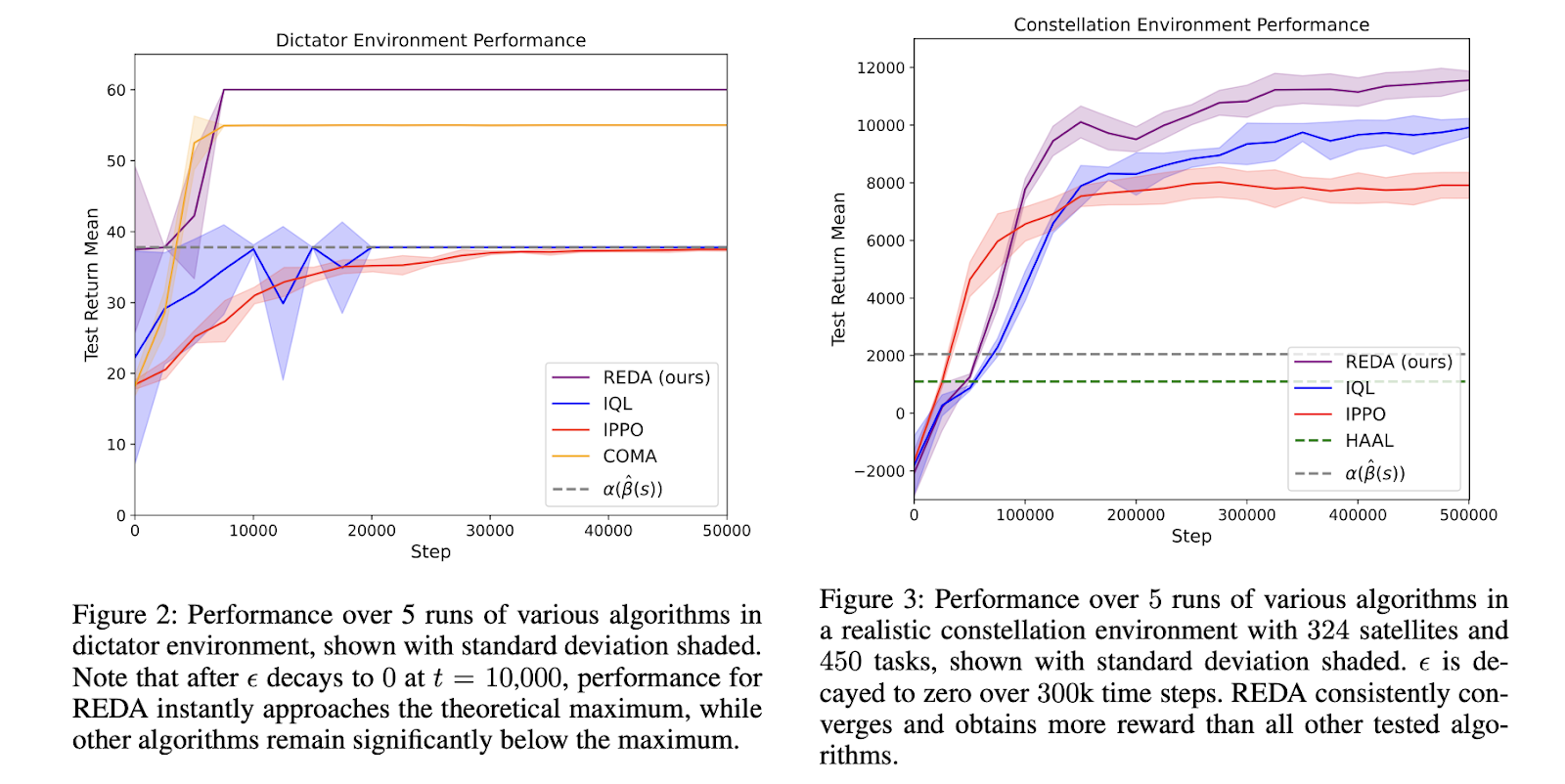
结论:本文讨论了 REDA,一种新颖的多智能体强化学习方法,用于解决复杂的状态相关分配问题。该论文解决了卫星分配问题,并教导智能体在学习有效解决方案的同时无私地行动,即使在大型问题环境中也是如此。
查看这纸和GitHub 页面。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。不要忘记加入我们的 60k+ ML SubReddit。
ðě 即将举行的免费人工智能网络研讨会(2025 年 1 月 15 日):利用综合数据和评估情报提高法学硕士的准确性—参加本次网络研讨会,获得可操作的见解,以提高 LLM 模型的性能和准确性,同时保护数据隐私。

Adeeba Alam Ansari 目前正在印度理工学院 (IIT) Kharagpur 攻读双学位,获得工业工程学士学位和金融工程硕士学位。她对机器学习和人工智能有着浓厚的兴趣,是一位狂热的读者和好奇心强的人。Adeeba 坚信技术的力量可以通过同理心和对现实世界挑战的深刻理解驱动的创新解决方案来增强社会能力并促进福祉。