

事实证明,大型语言模型 (LLM) 是发现零日、绕过检测和编写漏洞代码的宝贵工具,从而降低了渗透测试者和攻击者的进入门槛。
生成式人工智能对各种业务流程产生了重大影响,优化和加速了工作流程,在某些情况下还降低了专业知识的基线。
将漏洞搜寻添加到该列表中,因为大型语言模型 (LLM) 被证明是帮助黑客(无论好坏)更快地发现软件漏洞和编写漏洞利用程序,同时弥合知识差距的宝贵工具。
这种错误搜寻技能的民主化有可能通过降低能够开发和使用零日漏洞攻击的攻击者的进入门槛来重塑威胁格局。针对以前未知和未修补的漏洞。
从历史上看,这些漏洞与资金充足、经验丰富的威胁行为者有关,例如民族国家网络间谍组织,以及少数拥有内部开发技能或有财力在黑市上购买它们的网络犯罪团伙。
“法学硕士和生成式人工智能可能会对零日漏洞利用生态系统产生重大影响,”网络安全作家兼 HypaSec 创始人 Chris Kubecka 表示,HypaSec 是一家提供安全培训并就民族国家事件向政府提供建议的咨询公司响应和管理。
“这些工具可以协助代码分析、模式识别,甚至自动化部分漏洞开发过程,”她在之后通过电子邮件告诉 CSO11 月在布加勒斯特举行的 DefCamp 会议上发表演讲,主题是量子计算和人工智能重新定义网络战。– 通过快速分析大量源代码或二进制文件并识别潜在漏洞,法学硕士可以加速零日漏洞的发现。此外,提供自然语言解释和建议的能力降低了理解漏洞利用创建的障碍,有可能使更广泛的受众能够访问这些过程。
另一方面,道德错误猎人和渗透测试人员正在利用相同的法学硕士来更快地发现漏洞并将其报告给受影响的供应商和使用受影响产品的组织。安全和开发团队还可以将法学硕士与现有的代码分析工具集成,以便在错误投入生产之前识别、分类和修复错误。
法学硕士寻找 bug 的效率和局限性
使用法学硕士来发现漏洞,漏洞搜寻者可能会取得不同程度的成功。因素包括:
- 应用于模型的定制级别以及是否与传统分析工具一起使用
- 模型中存在限制某些类型响应的本机安全协议
- 所分析代码的大小和复杂性,以及代码中存在的漏洞的性质
- 模型在单个提示中可以处理的输入大小的限制
- 可能出现编造和错误的反应,即幻觉
尽管如此,专家认为,即使是开箱即用的法学硕士,只需进行很少的修改,也可以识别不太复杂的输入清理漏洞,例如跨站脚本 (XSS) 和 SQL 注入,甚至内存损坏错误,例如缓冲区溢出。这些模型在网络来源的信息上接受了广泛的培训,包括安全编码实践、开发人员支持论坛、漏洞列表、黑客技术和漏洞利用示例,说明了这种与生俱来的能力。但是,当错误搜寻者使用特定于主题的数据增强模型并精心设计提示时,法学硕士的效率可以显着提高。
例如,Kubecka 构建了 ChatGPT 的自定义版本,她称之为“零日 GPT”。使用这个工具,她能够在几个月内识别出大约 25 个零日漏洞——她说,否则这项任务可能需要花费数年时间才能完成。开源协作平台 Zimbra 发现一个漏洞以前是国家支持的网络间谍组织的目标, 包括通过 2023 年底的零日漏洞利用。
法学硕士寻找 bug 是什么样的
为了发现此漏洞,Kubecka 指示她的自定义 GPT 分析已知 Zimbra 缺陷的补丁,为模型提供易受攻击的版本和修补版本之间的代码更改以及已知的漏洞。然后她询问是否仍然可以使用旧的漏洞来对抗修补后的代码。
– 答案是:您可以重用该漏洞利用程序,但是您需要稍微更改一下代码,顺便说一句,让我重构它,因为现有的漏洞利用程序代码编码得不太好, –她在接受 CSO 采访时表示。“所以,它能够突破它并给我一个全新的利用,天哪,它成功了。”
Kubecka 的 GPT 发现了一个补丁绕过方法,研究人员偶尔也能完成这项任务。许多开发人员通过实施过滤机制来阻止恶意输入来解决输入清理缺陷。然而,历史表明,这种黑名单方法往往是不完整的。凭借创造力和技巧,研究人员可以设计出有效载荷的变体,成功绕过这些过滤器。
– 考虑这样一个场景:通过过滤与此类漏洞相关的特定关键字或模式,对 Web 应用程序进行修补以防止 SQL 注入攻击。”渗透测试公司 Bit Sentinel 的红队技术主管 Lucian NiÈescu 告诉 CSO。攻击者可以使用 LLM 生成绕过这些过滤器的替代有效负载。例如,如果补丁阻止常见的 SQL 关键字(例如“sleep”),LLM 可能会建议使用编码表示形式或非常规语法,以在不触发过滤器的情况下实现相同的恶意结果,例如 SQL 注释或 URL编码。 –
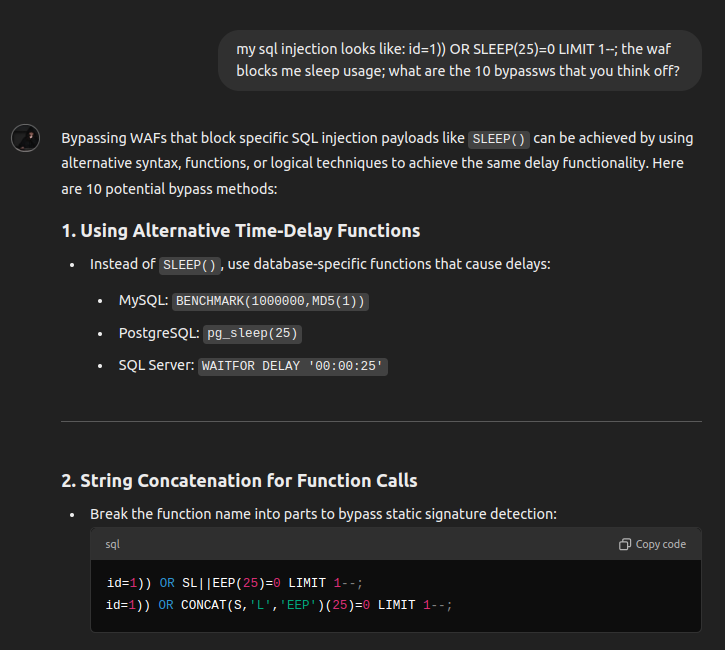
ChatGPT 为 Web 应用程序防火墙的 SQL 注入过滤器编写绕过程序
卢西安·尼埃斯库
NiÈescu 还在他的工作中使用了 LLM,包括 ChatGPT 或 Ollama(本地托管的 GPT)的自定义提示,他用诸如HackTricks 存储库,黑客和漏洞利用技术的集合。他还测试了一个由 LLM 驱动的开源代码分析工具,名为猎杀者由 Protect AI 开发并已用于到目前为止,已发现十多个可远程利用的零日漏洞。
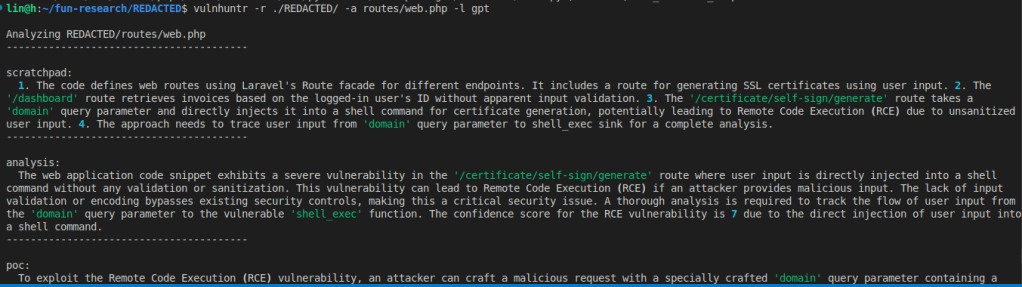
Vulnhuntr 在未命名项目中发现零日 RCE 缺陷
卢西安·尼埃斯库
NiÈescu 告诉 CSO,他启动了 Vulnhuntr,并在 GitHub 上托管的随机选择的项目上进行了测试。法学硕士在 15 分钟内发现了远程代码执行缺陷。他拒绝透露具体细节,因为该漏洞仍处于披露过程中,但他强调了使用该工具在高评价的 GitHub 项目中发现的其他公开披露的漏洞作为示例。
– 如果是CVE-2024-10099,这是使用 Vulnhuntr 识别的,我们可以观察到它提供了完整的利用链或帮助实现了功能齐全的两步利用,”他说。– 考虑到该漏洞影响舒适用户界面– GitHub 上拥有超过 60k star 的项目 – 它已经将技能障碍降低到了相当低的水平,允许早期/入门黑客编写功能齐全的漏洞利用程序。 –
与此同时,Kubecka 向 CSO 演示了她如何通过将代码拆分为 12 个块,实时使用自定义 GPT 来识别网站上的安全弱点和漏洞。LLM 检测到缺失的安全标头和可能被利用的弱输入验证问题以及其他漏洞。
提高复杂性
当然,实现预期影响所需的漏洞或攻击链越复杂,法学硕士就越难以完全自动化发现过程。尽管如此,法学硕士仍然可以识别复杂的错误,只要知识渊博的用户指导他们,提供额外的背景信息,或者将问题分解为更有针对性的组件。
“当您使用大型语言模型对传统分析工具的输出进行优先级排序,以便用更多的上下文来补充每个潜在的发现,然后相应地对它们进行优先级排序时,真正的力量就会显现出来。”Caleb Gross,进攻性安全公司 Bishop Fox 的能力开发告诉 CSO。
Gross 认为,由于单个提示(称为上下文窗口)的输入大小限制,简单地将代码块输入 LLM 并要求其识别缺陷既高效也不实用。例如,模型可能会识别出 C 代码中 strcpy 的大量不安全使用,这在理论上可能导致缓冲区溢出,但它无法确定应用程序中哪些代码路径是可访问的以及如何访问。
格罗斯和他的福克斯主教同事们给了在 RVASec 2024 上的演讲关于 LLM 漏洞搜寻以及他们如何使用 LLM 构建排序算法,对 Semgrep 或补丁比较等传统静态代码分析工具产生的潜在误报进行排名。
LLM 还可用于识别解析复杂数据的代码函数,并且是模糊测试的良好候选者,模糊测试是一种安全测试,涉及向函数提供格式错误的数据以触发意外行为,例如崩溃或信息泄漏。法学硕士甚至可以帮助设置模糊测试用例。
——并不是我们不知道如何模糊测试;而是我们不知道如何模糊测试。“我们的能力有限,无法找到正确的目标,也无法完成围绕其编写工具的初步跑腿工作,”格罗斯说。“我在这方面非常有效地使用了法学硕士。”
使用 LLM 编写漏洞并绕过检测
识别潜在漏洞是一回事,但编写针对这些漏洞的漏洞利用代码需要对目标平台上存在的安全缺陷、编程和防御机制有更深入的了解。
例如,将缓冲区溢出错误转变为远程代码执行漏洞可能涉及绕过进程沙箱机制或规避操作系统级防御(例如 ASLR 和 DEP)。同样,利用 Web 表单中的弱输入验证问题来发起成功的 SQL 注入攻击可能需要绕过 SQL 注入有效负载的通用过滤器或规避部署在应用程序前面的 Web 应用程序防火墙 (WAF)。
这是法学硕士可以产生重大影响的领域:弥合初级错误猎人和经验丰富的漏洞作者之间的知识差距。甚至生成现有漏洞的新变体来绕过防火墙和入侵防御系统中的检测签名也是一项值得注意的发展,因为许多组织不会立即部署可用的安全补丁,而是依赖其安全供应商添加对已知漏洞的检测,直到他们修补为止周期赶上。
德勤罗马尼亚公司网络安全专家主管 Matei Bädänoiu 是一名 bug 猎人,拥有 100 多个负责任地披露的 CVE,他告诉 CSO,他尚未在自己的 bug 搜寻工作中使用 LLM,但他团队中的同事已经成功使用过法学硕士在渗透测试期间编写绕过现有防御的漏洞有效负载。
虽然他并不认为法学硕士对零日生态系统产生了重大影响,但他看到了它们破坏它的潜力。– 它们似乎能够通过充当集中知识库来帮助研究人员发现零日漏洞,以缩短开发漏洞所需的时间 – 例如,对漏洞进行部分编码、提供通用代码模板 –这导致 0day 数量总体增加,”他说。
Bädänoiu 指出的工具包括0dAI,一个基于订阅的聊天机器人和经过网络安全数据训练的模型,以及法学硕士支持的渗透测试框架HackingBuddyGPT。
福克斯主教的格罗斯将他对法学硕士写作功绩的经历描述为“犹豫的乐观主义”,并指出他见过法学硕士掉入兔子洞并失去了更广阔视野的例子。他还认为,关于漏洞利用编写的优质、高技术材料(一个可能非常细致和复杂的领域)并不像安全测试资源那样在网上广泛提供。因此,与其他主题相比,法学硕士接受的漏洞利用编写成功示例培训可能较少。
法学硕士弥合安全知识差距
Bit Sentinel 的 NiÈescu 已经看到了 LLM 在提升威胁猎手游戏中的影响力。作为 DefCamp 夺旗黑客竞赛组织者的领导者,Nièscu 和 D-CTF 组织者不得不重新思考今年的一些挑战,因为他们意识到在法学硕士的帮助下这些挑战太容易解决了与往年相比。
“人工智能工具可以帮助经验不足的个人对其有效负载进行更复杂的利用和混淆,这有助于绕过安全机制,或提供利用特定漏洞的详细指导,”NiÈescu 说。– 这确实降低了网络安全领域的进入壁垒。同时,它还可以通过建议现有代码的改进、识别新的攻击向量,甚至自动化部分漏洞利用链,来帮助经验丰富的漏洞开发人员。这可能会导致更高效、更有效的零日漏洞利用。”

DefCamp CTF 2024 获奖者防御营
今年的 DefCamp 夺旗活动有来自 92 个国家的近 800 支队伍参加预选赛阶段的角逐,其中 16 支决赛选手在大会现场进行角逐。
获胜团队的两名成员 Hackemus Papam 告诉 CSO,他们依靠 ChatGPT 来解决一些挑战,其中包括涉及错误配置的 AWS 云环境的挑战。
为了检索“标志”,他们必须利用服务器端请求伪造 (SSRF) 缺陷从元数据中提取凭据,然后将这些凭据用于与 S3 存储桶交互的其他服务。由于他们没有与这些 AWS 服务及其 API 交互的经验,事实证明,在他们自己发现初始漏洞后,ChatGPT 在后期利用阶段提供了很大的帮助,这相对容易,并且可能是 ChatGPT 可以发现的如果给出代码就好了。
他们的团队还在评估 Vulnhuntr 以发现代码中的脆弱区域,但目前,他们认为填补知识空白是法学硕士可以最好地帮助人类的地方。法学硕士可以提供关于在哪里寻找和尝试什么的想法——类似于故障排除的过程。
HypaSec 的 Kubecka 也强调了这一点,并指出错误搜寻者可以要求法学硕士解释不熟悉的编程语言的代码或他们在尝试利用漏洞时遇到的错误。然后,法学硕士可以帮助他们找出问题所在,并提出修复或重构代码的方法。
“法学硕士可以减少编写武器化漏洞所需的技能,”她说。– 通过提供详细说明、生成代码模板,甚至调试漏洞利用尝试,法学硕士使个人更容易开发功能性漏洞利用。虽然绕过先进的保护机制仍然需要对现代防御有深入的了解,但法学硕士可以帮助生成多态变体、绕过有效载荷和武器化的其他组件,从而极大地帮助这一过程。
在 DefCamp CTF 中获得第二名的 The Few Chosen 成员 Horia NiÈä 证实,他的团队使用多种定制的 AI 工具来帮助扫描新代码库,提供对潜在攻击向量的洞察,并提供解释他们遇到的代码。
“像这样的工具极大地简化了我们的错误赏金工作,我相信这个领域的每个人的工具箱中都应该有类似的资源,”他告诉 CSO。
NiÈä 说,他使用法学硕士来研究特定主题或生成暴力破解的有效负载,但根据他的经验,这些模型在针对特定类型的缺陷时仍然不一致。
“就人工智能的当前状态而言,它有时可以生成功能性且有用的漏洞或有效负载的变体来绕过检测规则,”他说。– 然而,由于幻觉和不准确的可能性很高,它并不像人们希望的那样可靠。虽然随着时间的推移,这种情况可能会有所改善,但目前,许多人仍然发现手动工作更加可靠和有效,特别是对于精度至关重要的复杂任务。
尽管存在明显的局限性,许多漏洞研究人员发现法学硕士很有价值,可以利用其能力来加速漏洞发现、协助编写漏洞利用程序、重新设计恶意负载以规避检测,并提出新的攻击路径和策略,并取得了不同程度的成功。他们甚至可以自动创建漏洞披露报告——研究人员通常不喜欢这种耗时的活动。
当然,恶意行为者也可能利用这些工具。在野外发现漏洞或有效负载时,很难确定是否由 LLM 编写,但研究人员已经注意到攻击者明显让 LLM 发挥作用的实例。
2 月,微软和 OpenAI 发布一份报告强调一些知名的 APT 团体如何使用法学硕士。检测到的一些 TTP 包括 LLM 通知侦察、LLM 增强脚本技术、LLM 增强异常检测规避和 LLM 辅助漏洞研究。可以肯定的是,从那时起,威胁行为者对法学硕士和生成式人工智能的采用只会增加,组织和安全团队也应该努力利用这些工具来跟上。
订阅我们的时事通讯
从我们的编辑直接发送到您的收件箱
请在下面输入您的电子邮件地址开始使用。