

Nvidia 如何在人工智能的十年里创造 1.4T 美元的数据中心市场 - SiliconANGLE
作者:Dave Vellante and David Floyer
Nvidia 如何在人工智能的十年里创造 1.4T 美元的数据中心市场
![]()
万亿美元的转变正在展开
我们正在见证一个全新的计算时代的崛起。在未来十年内,价值超过万亿美元的数据中心业务将在我们所说的“数据中心”的推动下进行转型。 极端并行计算(EPC) – 或者正如一些人更喜欢的说法,加速计算。尽管人工智能是主要的促进剂,但其影响会波及整个技术堆栈。
英伟达公司处于这一转变的先锋,打造了一个集成硬件、软件、系统工程和庞大生态系统的端到端平台。我们的观点是,Nvidia 有 10 到 20 年的时间来推动这一转型,但发挥作用的市场力量远大于单一参与者。这种新范式是从头开始重新构想计算:从芯片级到数据中心设备,再到大规模分布式计算、数据和应用程序堆栈以及边缘的新兴机器人技术。
在这篇重大分析中,我们探讨了极端并行计算如何重塑技术格局、主要半导体厂商的表现、Nvidia 面临的竞争、护城河的深度,以及其软件堆栈如何巩固其领导地位。我们还将利用企业技术研究的数据来讨论 CES 的最新进展,即所谓的“人工智能 PC”的到来。然后,我们将探讨数据中心市场如何在 2035 年达到 1.7 万亿美元。最后,我们将讨论其上行潜力以及威胁这一积极前景的风险。
优化极限并行计算的技术栈
我们的研究表明,技术堆栈的每一层(从计算到存储、网络再到软件层)都将针对人工智能驱动的工作负载和极端并行性进行重新架构。我们相信,从通用 x86 中央处理单元向分布式图形处理单元集群和专用加速器的转变速度比许多人预期的还要快。以下是我们对数据中心技术堆栈的几个层次以及 EPC 的影响的简要评估。
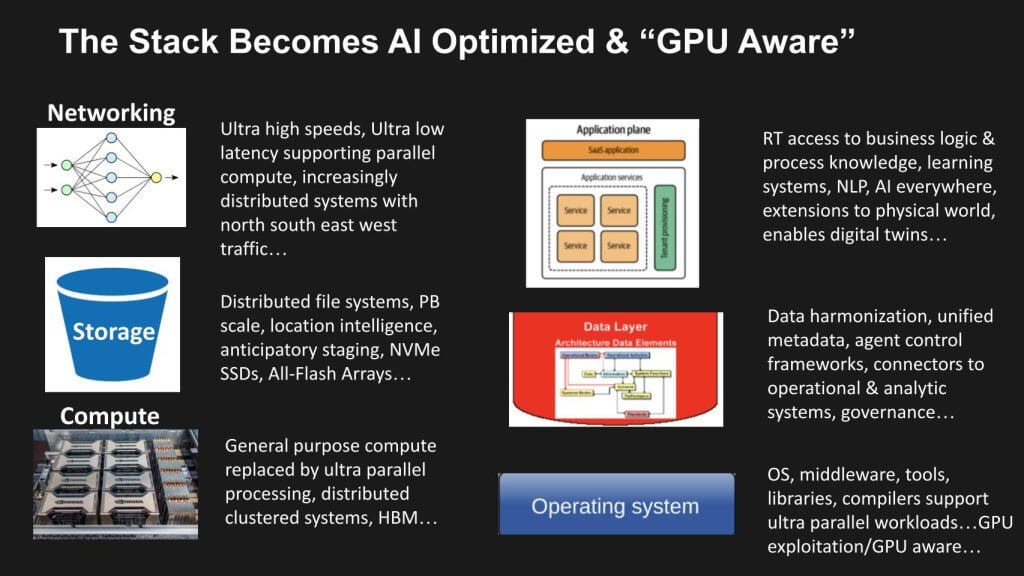
计算
三十多年来,x86 架构主导着计算。如今,通用处理正在让位于专用加速器。GPU 是这一变化的核心。大型语言模型、自然语言处理、高级分析和实时推理等人工智能工作负载需要大量并发。
- 极端并行性:传统的多核扩展已经遭遇收益递减。相比之下,单个 GPU 可以包含数千个核心。即使 GPU 在封装层面上更昂贵,但在 每个计算单元鉴于其大规模并行设计,它的价格可能要便宜得多。
- 大规模人工智能:高度并行的处理器需要先进的系统设计。大型GPU集群共享高带宽内存或HBM,并且需要快速互连(例如InfiniBand或超高速以太网)。GPU、高速网络和专用软件之间的这种协同作用正在实现新类别的工作负载。
贮存
虽然存储有时在人工智能对话中被忽视,但数据是驱动神经网络的燃料。我们相信人工智能需要先进的高性能存储解决方案:
- 预期数据分级:下一代数据系统预测模型将请求哪些数据,确保数据提前驻留在处理器附近,以减少延迟并尽可能解决物理限制。
- 分布式文件和对象存储:PB 级容量将成为常态,元数据驱动的智能可以跨节点协调数据放置。
- 性能层:NVMe SSD、全闪存阵列和高吞吐量数据结构在保持 GPU 和加速器的数据饱和方面发挥着重要作用。
联网
在过去十年中,随着移动和云的发展,我们看到网络流量从南北轨迹(用户到数据中心)转向东西偏向(服务器到服务器)。人工智能驱动的工作负载会在数据中心内和网络中产生大量的东西向和南北向流量。在 HPC 领域,InfiniBand 成为超低延迟互连的首选。现在,我们看到这种趋势渗透到超大规模数据中心,高性能以太网作为主导标准,我们认为这最终将被证明是流行的开放网络选择:
- 超大规模网络:超高带宽和超低延迟结构将促进人工智能集群所需的并行操作。
- 多向交通:先进的人工智能工作负载曾经以南北流量为主,最近以东西流量为主,现在则向各个方向分流流量。
软件堆栈和工具
操作系统和系统级软件
加速计算对操作系统、中间件、库、编译器和应用程序框架提出了巨大的要求。必须对它们进行调整以利用 GPU 资源。随着开发人员创建更高级的应用程序(一些桥接实时分析和历史数据),系统级软件必须以前所未有的水平管理并发性。操作系统、中间件、工具、库和编译器正在迅速发展,以支持超并行工作负载,并能够利用 GPU(即 GPU 感知操作系统)。
数据层
数据是人工智能的燃料,数据堆栈正在迅速注入智能。我们看到数据层从历史分析系统转变为实时引擎,支持创建组织的实时数字表示,包括人员、地点、事物以及流程。为了支持这一愿景,将出现通过知识图、统一元数据存储库、代理控制框架、统一治理以及操作和分析系统连接器进行数据协调。
应用层
统一和协调数据的智能应用程序不断涌现。这些应用程序越来越多地可以实时访问业务逻辑和流程知识。单代理系统正在发展为多代理架构,具有从人类推理痕迹中学习的能力。应用程序越来越能够理解人类语言,注入智能(换句话说,人工智能无处不在)并支持工作流程自动化和创造业务成果的新方法。应用程序日益成为物理世界的延伸,几乎所有行业都有机会创建实时代表业务的数字孪生。
要点:极端并行计算代表了对技术堆栈(计算、存储、网络,尤其是操作系统层)的全面重新思考。它将 GPU 和其他加速器置于架构设计的中心。
半导体股票表现:五年镜头
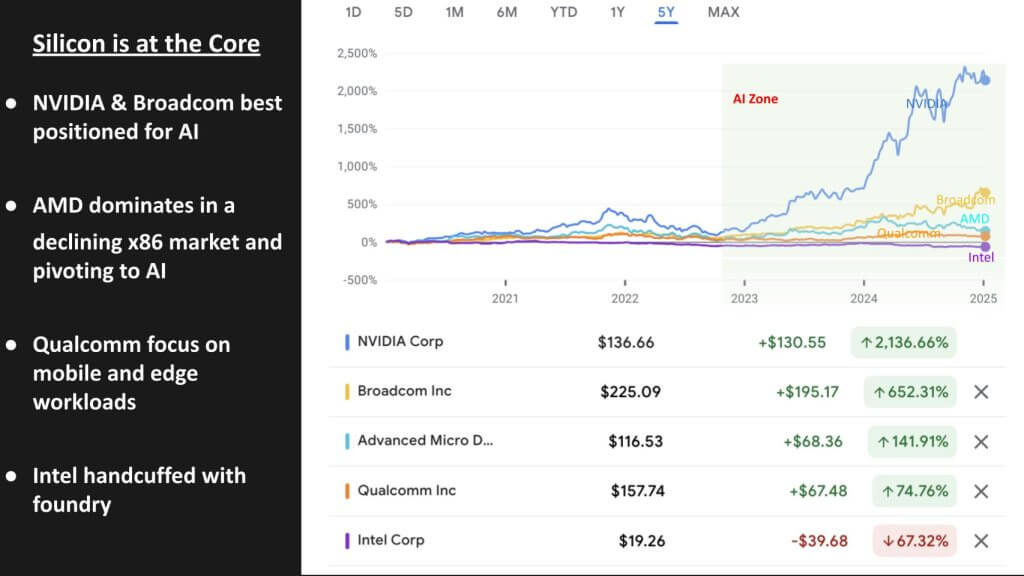
上图显示了主要半导体厂商的五年股票表现,其中“AI 区域”从 2022 年底开始出现阴影,与 ChatGPT 最初的热度大致一致。在此之前,许多人对大规模 GPU 加速的人工智能能否成为如此强大的业务驱动力持怀疑态度。
- 英伟达:在人工智能的热潮中脱颖而出,一跃成为全球最有价值的上市公司。
- 博通:我们的数据继续支持博通公司(Broadcom Inc.)成为芯片领域次强的人工智能公司,特别是在数据中心基础设施方面。它为云巨头提供定制 ASIC 和下一代网络的关键 IP,包括 Google LLC、Meta Platforms Inc. 和 ByteDance Ltd.。
- 超微半导体:一直在 x86 市场击败英特尔,但该领域正在下滑,因此 Advanced Micro Devices Inc. 正在加速进军人工智能领域。我们看到 AMD 试图复制其成功的 x86 策略——这次是针对 Nvidia 的 GPU。如果英伟达没有重大失误,AMD 就更难削弱英伟达的竞争护城河和软件堆栈。
- 英特尔:英特尔的代工战略仍然是一个主要阻力。正如我们所概述的 英特尔公司代工厂计划,随着资本限制的增加,我们认为销量不足以赶上台积电。我们相信英特尔今年将被迫剥离其代工业务,这将使我们对英特尔强大的设计业务更加乐观,使该公司能够再次释放创新能力,成为一个可行的人工智能玩家。
- 高通:仍然主要关注移动、边缘和以设备为中心的人工智能。虽然高通公司在数据中心不会对英伟达构成直接威胁,但未来向机器人和分布式边缘人工智能领域的扩张可能会让这些玩家偶尔陷入竞争。
我们认为,市场已经认识到半导体是未来人工智能能力的基础,为能够满足加速计算需求的公司提供了溢价倍数。今年,“富人”(以英伟达、博通和 AMD 为首)表现出色,而“穷人”(特别是英特尔)则表现落后。
竞争格局:英伟达及其竞争对手
英伟达 65% 的营业利润率吸引了投资者和竞争对手纷纷进入 AI 芯片市场。现有企业和新进入者都做出了积极的回应。然而,市场潜力如此之大,而且英伟达的领先地位如此之大,我们认为,短期竞争不会损害英伟达。尽管如此,我们还是从多个角度看待英伟达的挑战者,每个角度都有自己的市场策略。

博通和谷歌
我们将这两个领导者放在一起是因为:1)Broadcom 为定制芯片提供支持,例如 Google 的张量处理单元或 TPU;2)我们相信TPU v4在人工智能方面极具竞争力。Broadcom 围绕 SerDes、光学和网络的 IP 是同类最佳的,在我们看来,与 Google 一起代表了相对 Nvidia 而言最可行的技术替代方案。
- 潜在的音量播放:一个不太可能发生的情况是,谷歌最终可能会更积极地将 TPU 商业化,从纯粹的内部解决方案转向更广泛的市场产品。但在短期内,谷歌 TPU 周围的生态系统仍然受到限制,目前是一个封闭的市场,限制了谷歌内部用例的采用。
博通和元
重要的是,博通还与 Meta 建立了长期合作关系,并为其人工智能芯片提供支持。谷歌和 Meta 都已经证明,人工智能在消费者广告领域的投资回报是有回报的。尽管许多企业都在为人工智能投资回报率而苦苦挣扎,但这两家公司正在展示令人印象深刻的人工智能投资回报。
谷歌和 Meta 都倾向于将以太网作为网络标准。Broadcom 是以太网的坚定支持者,也是超以太网联盟中的主导声音。此外,博通是除 Nvidia 之外唯一一家在 XPU 内部和跨 XPU 集群的网络方面拥有成熟专业知识的公司,这使得该公司成为人工智能芯片领域极其强大的竞争对手。
AMD
AMD 的数据中心战略取决于提供有竞争力的 AI 加速器——建立在该公司在 x86 方面的记录之上。尽管它在游戏和 HPC 领域拥有重要的 GPU,但人工智能软件生态系统(以 CUDA 为中心)仍然是一个主要障碍。
- 两个角度:一些人认为 AMD 将在人工智能领域占据重要的市场份额,至少足以维持收入增长。其他人预计只会有适度的增长,因为 AMD 不仅必须与 Nvidia 的硬件相匹配,而且还必须与 Nvidia 的软件堆栈、系统专业知识和开发人员忠诚度相匹配。
AMD 在人工智能领域采取了积极的举措。它正在与英特尔合作,努力保持 x86 的活力。它有收购ZT Systems更好地了解端到端人工智能系统要求,并将成为商业芯片的可行替代方案,特别是对于推理工作负载。最终,我们相信 AMD 将在庞大的市场中占据相对较小的份额(个位数)。它将通过对抗英特尔赢得市场份额来应对 x86 市场的下滑,并对抗英伟达进军成本敏感的人工智能芯片市场。英特尔
英特尔曾经是处理器领域无可争议的领导者,但随着向加速计算的转变,英特尔的命运发生了转变。
我们继续看到英特尔因保留自己的代工厂所需的巨额资本而受到阻碍。
- 垂直整合与规模化:垂直集成对于苹果公司、英伟达、甲骨文公司和特斯拉公司等公司来说是有利的,它们将硬件和软件结合在一个系统中。但就英特尔而言,我们认为代工业务正在耗尽关键资源和管理层的注意力。我们认为,如果英特尔今年不剥离其代工业务,它可能会面临进一步受损的风险。
- 可能的结果:我们普遍持有的立场是,英特尔应该剥离其代工业务,专注于设计和合作伙伴关系,类似于 AMD 剥离其代工业务的方式。另一种情况是英特尔继续投资,最终重新夺回工艺领先地位并正面竞争。然而,这种结果的概率极低(我们认为低于 5%)。
AWS 和 Marvell:Trainium 和 Inferentia
亚马逊的定制芯片方法通过 Graviton 在 CPU 实例中取得了成功。它对 Annapurna Labs 的收购是企业技术史上最好的投资之一。当然,这一点经常被忽视。如今,AWS 与 Marvell 合作,通过 Trainium(用于训练)和 Inferentia(用于推理)将类似 Graviton 的策略应用于 GPU。
Dylan Patel 对亚马逊 GPU 的看法总结了我们的观点。以下是他在最近一集 BG2 播客中所说的话:
亚马逊,他们在 re:Invent 上的全部事情,如果你真的在他们宣布 Trainium 2 时与他们交谈,我们关于它的整篇文章以及我们对它的分析都是供应链方面的……你眯起眼睛,这看起来像亚马逊基础知识热塑性聚氨酯,对吗?这很不错,对吧?但它真的很便宜,A;B,它为您提供市场上任何芯片中性价比最高的 HBM 容量和性价比最高的 HBM 内存带宽。因此,对于某些应用程序来说,使用它实际上是有意义的。所以这就像一个真正的转变。就像,嘿,我们的设计可能不如 Nvidia,但我们可以在封装上放置更多内存。
[迪伦·帕特尔 (Dylan Patel) 对 Amazon Trainium 的看法]
我们的观点是,AWS 产品将进行成本优化,并在 AWS 生态系统中提供替代 GPU 方法来训练和推理。尽管开发人员最终可能更喜欢 Nvidia 平台的熟悉度和性能,但 AWS 将为客户提供尽可能多的可行选择,并将在其专属市场中获得公平的份额。相对于商用 x86 芯片,Graviton 的渗透率可能不是很高,但相当大的采用率足以证明投资的合理性。目前我们还没有对 Trainium 的最新预测,但我们正在关注它以获得更好的数据。
要点
- 价值与性能:某些工作负载不需要 Nvidia 的高级功能,这些工作负载可能会迁移到成本较低的 AWS 芯片。与此同时,Nvidia 堆栈仍将是复杂、大规模部署和开发人员便利性的首选。
- AWS后端基础设施– 我们对 re:Invent 的研究表明,AWS 多年来一直致力于构建自己的 AI 基础设施,以减少对 Nvidia 全栈的依赖。与许多需要 Nvidia 端到端系统的公司不同,虽然 AWS 可以为客户提供这样的解决方案,但它还可以提供自己的网络和支持软件基础设施,进一步降低客户的成本,同时提高自己的利润。
微软和高通
微软在定制芯片方面历来落后于 AWS 和谷歌,尽管它确实有正在进行的项目,例如 Maia。微软可以凭借其软件主导地位以及为高端 GPU 支付英伟达利润的意愿来弥补任何芯片差距。高通是微软客户端设备的主要供应商。正如所指出的,高通在移动和边缘领域展开竞争,但随着机器人和分布式人工智能应用的扩展,我们看到与英伟达发生更直接冲突的可能性。
新兴替代方案
Cerebras Systems Inc.、SambaNova Systems Inc.、Tenstorrent Inc. 和 Graphcore Ltd. 等公司已经推出了专门的人工智能架构。中国还在开发国产 GPU 或类似 GPU 的加速器。然而,统一的挑战仍然是软件兼容性、开发人员动力以及推翻事实上标准的陡峭攀登。
要点:尽管竞争很激烈,但这些参与者都无法单独威胁英伟达的长期主导地位——除非英伟达犯了重大失误。市场规模足够大,可以让多个赢家蓬勃发展。
Nvidia 的护城河内部:硬件、软件和生态系统
我们将 Nvidia 的竞争优势视为跨越硬件和软件的多方面护城河。经过近二十年的系统创新,形成了既广泛又深入的综合生态系统。

硬件整合与“全牛”战略
Nvidia 的 GPU 采用先进的处理节点,包括 HBM 内存集成和专用张量核心,可实现 AI 性能的巨大飞跃。值得注意的是,Nvidia 可以每 12 到 18 个月推出一次新的 GPU 迭代。同时,它使用“全牛”方法,确保每个可回收的芯片在其产品组合(数据中心、PC GPU 或汽车)中占有一席之地。这可以保持高产量和健康的利润率。
网络优势
这获得Mellanox Technologies Ltd. 的子公司让 Nvidia 控制了 InfiniBand,使其能够销售用于 AI 集群的全面端到端系统并快速进入市场。ConnectX 和 BlueField DPU 的集成扩展了 Nvidia 在超高速网络(多 GPU 扩展的关键组件)方面的领先地位。随着行业向超以太网标准迈进,许多人认为这对 Nvidia 的护城河构成了威胁。我们没有。尽管网络是 Nvidia 上市时间优势的关键组成部分,但我们将其视为其产品组合的支持成员。我们认为,该公司能够并且将会根据市场需求成功优化其以太网堆栈;它将保持其核心优势,该优势来自整个堆栈的紧密集成。
软件集成和平台方法
Nvidia 的软件生态系统已经远远超出了 CUDA,涵盖了人工智能应用程序开发的几乎每个阶段的框架。最终结果是,开发人员有更多理由留在 Nvidia 的生态系统中,而不是寻求替代方案。
生态系统和合作伙伴关系
Nvidia 首席执行官黄仁勋经常强调该公司对建立合作伙伴网络的重视。几乎每个主要技术供应商和云提供商都提供基于 Nvidia 的实例或解决方案。这种广泛的足迹产生了显着的网络效应,强化了护城河。
要点:Nvidia 的优势不仅仅取决于芯片。它的软硬件一体化,以庞大的生态系统为支撑,形成了难以复制的堡垒般的护城河。
深入了解 Nvidia 的软件堆栈
CUDA 正确地主导了软件讨论,但 Nvidia 的堆栈非常广泛。下面我们重点介绍六个重要层:CUDA、NVMI/NVSM(此处表示为“NIMS”)、Nemo、Omniverse、Cosmos 和 Nvidia 开发人员库/工具包。CUDA

计算统一设备架构或 CUDA
是 Nvidia 的基础并行计算平台。它抽象化了 GPU 硬件的复杂性,并允许开发人员使用 C/C++、Fortran、Python 等语言编写应用程序。CUDA 协调 GPU 核心并优化工作负载调度,以加速 AI、HPC、图形等。
NIMS(Nvidia 管理接口系统)
NIMS 专注于基础设施级管理:大规模 GPU 集群中的监控、诊断、工作负载调度和整体硬件运行状况。严格来说,它并不是一个“开发人员工具”,但对于任何需要在数千个 GPU 上运行高级人工智能工作负载的企业来说仍然至关重要。
尼莫
NeMo 是一个用于开发和微调大型语言模型和自然语言应用程序的端到端框架。它提供预构建模块、预训练模型以及将这些模型导出到其他 Nvidia 产品的工具,帮助想要利用 NLP 和大型语言模型的企业加快获得洞察的时间。
全方位宇宙
Omniverse 是一个用于 3D 设计协作、模拟和实时可视化的平台。虽然 Omniverse 最初是针对设计工程和媒体展示的,但现在已扩展到机器人、数字孪生和基于物理的高级模拟。它利用 CUDA 进行图形渲染,将实时图形与人工智能驱动的模拟功能相结合。
宇宙
Cosmos 是 Nvidia 的分布式计算框架,可简化大规模人工智能模型的构建和训练。通过与公司的网络解决方案和 HPC 框架集成,Cosmos 有助于水平扩展计算资源。它允许研究人员和开发人员以更加无缝的方式统一硬件资源进行大规模训练。
开发人员库和工具包
除了核心框架之外,Nvidia 还开发了数百个用于神经网络运算、线性代数、设备驱动程序、HPC 应用程序、图像处理等的专用库。这些库针对 GPU 加速进行了精心调整,进一步锁定了投入时间掌握它们的开发人员社区。
要点:软件堆栈可以说是 Nvidia 保持领先地位的最重要因素。CUDA 只是故事的一部分。Nvidia 更广泛的人工智能软件套件的深度和成熟度对新挑战者构成了巨大的进入壁垒。
数据中心的简短切线:人工智能电脑的出现
尽管本次重大分析重点关注数据中心转型,但如果我们不简要讨论人工智能 PC,那就太失职了。在今年的 CES 上,多家供应商推出了名为“AI PC”的笔记本电脑和台式机,通常配备 NPU(神经处理单元)或用于设备上推理的专用 GPU。
客户端设备上的 ETR 数据
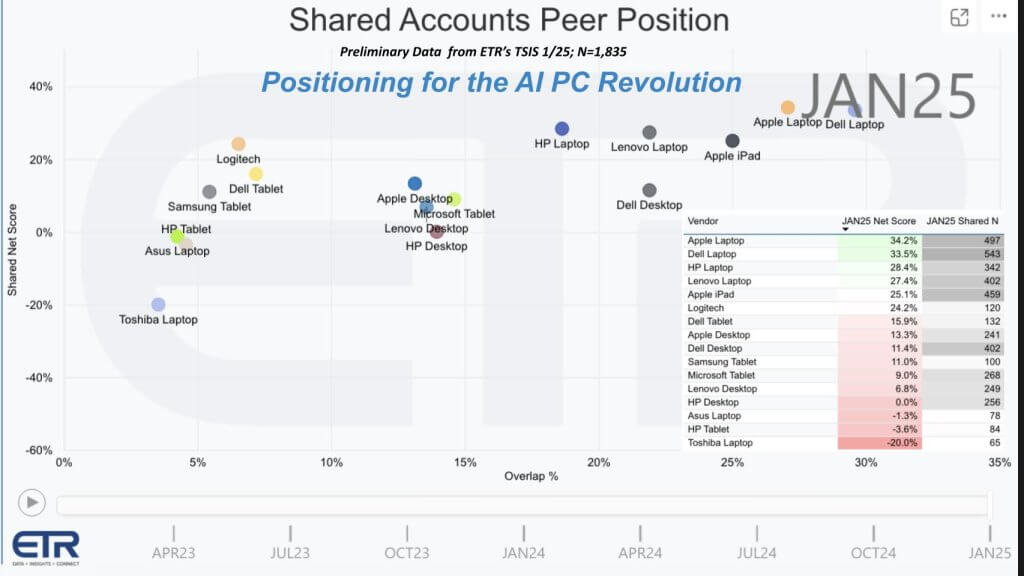
上面显示的调查数据来自 ETR 对大约 1,835 名信息技术决策者的调查。纵轴是净得分或支出动量,横轴是这 1,835 个账户中的重叠或渗透率。表格插入显示了如何绘制点(净得分和 N)。数据显示,戴尔笔记本电脑以 543 N 的数量位居份额曲线的顶端,苹果、惠普和联想的消费势头强劲。该图揭示了领先个人电脑供应商的健康消费势头。
- 戴尔科技公司:一个 推出人工智能笔记本电脑并已表示与 AMD、英特尔和高通等多个芯片合作伙伴进行合作。我们相信它也可以集成 Nvidia 解决方案。
- 苹果:有 NPU 已出货数年在其 M 系列芯片中,有利于电池寿命和本地推理。苹果仍然是垂直整合领域的一股力量。
- 其他(惠普公司、联想集团有限公司等):每个都在测试或发布以人工智能为中心的端点,有时使用专用 NPU 或独立 GPU。
NPU 在 PC 中的作用
目前,由于软件堆栈尚未完全优化,NPU 在许多 AI PC 中经常处于闲置状态。随着时间的推移,我们预计客户端设备上会出现更专业的人工智能应用程序——有可能实现小规模的实时语言翻译、图像/视频处理、高级安全性和本地法学硕士推理。
Nvidia 的立场
我们相信,凭借在 GPU 领域的良好记录,Nvidia 能够提供比移动或笔记本电脑上的典型 NPU 性能更高的 AI PC 技术。然而,功耗、热量和成本限制仍然是重大挑战。我们确实看到 Nvidia 使用回收的“整头牛”模具并将其构建到功耗较低的笔记本电脑 GPU 中。
尽管本节偏离了数据中心的重点,但人工智能 PC 可以推动开发人员采用。设备上的人工智能对于生产力、专业工作负载和特定的垂直用例很有意义。反过来,这可能会加强更广泛的生态系统向并行计算架构的过渡。
市场分析:数据中心支出和 EPC 优势
我们对 2019 年至 2035 年的整个数据中心市场(服务器、存储、网络、电力、冷却和相关基础设施)进行了建模。我们的研究表明,传统通用计算正在快速过渡到极端并行计算。
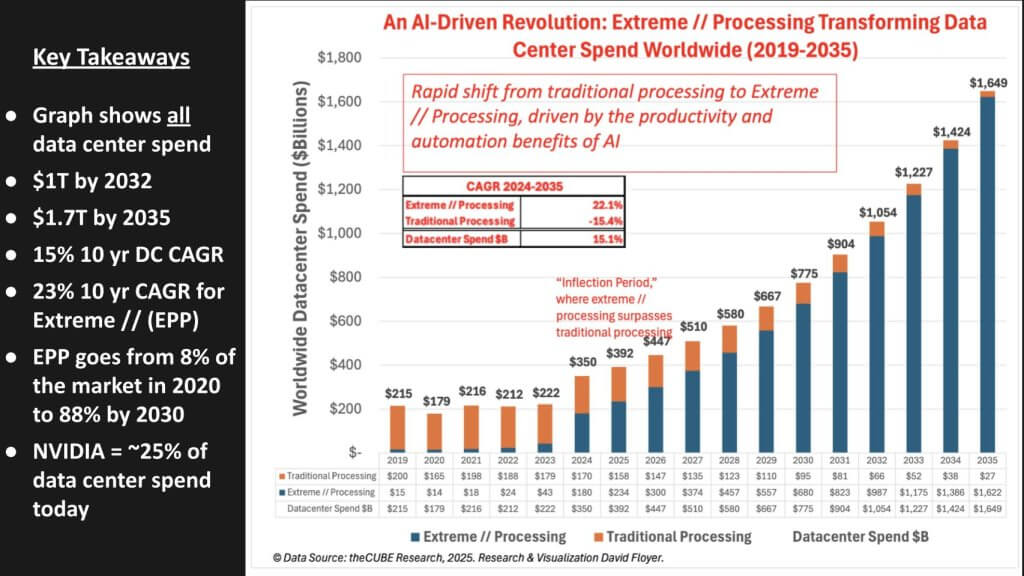
数据中心 TAM 增长
- 数据中心市场总量预计将超过 到 2032 年将达到 1 万亿美元并扩展到 到 2035 年将达到 1.7 万亿美元。从 2024 年开始,我们的基线模型显示
- 整体年复合增长率15% – 远高于企业 IT 历史个位数增长率。并行计算的极端增长
我们将“极端并行计算”归类为用于人工智能训练、推理、HPC 集群和高级分析的专用硬件和软件。
EPC 部分正在以
- 复合年增长率 23%在同一时期,最终使曾经占据主导地位的基于标准 x86 的系统的份额相形见绌。2020 年,EPC 约占数据中心支出的 8%。
- 到2030年,我们预计这一比例将超过50%。到 2030 年代中期,高级加速器可能占数据中心芯片投资的绝大多数(80% 至 90%)。
Nvidia 占据 EPC 支出
目前,我们估计 Nvidia 大约占 25%整个数据中心领域。我们的观点是,尽管来自超大规模厂商、AMD 和其他公司的激烈竞争,英伟达将在整个预测期内保持领先份额(假设它避免了非受迫性错误)。
增长动力
- 生成式人工智能和法学硕士:类似 ChatGPT 的大型语言模型展示了自然语言、编码、搜索等加速计算的强大功能。
- 企业代理模式:世界各地的公司都将人工智能嵌入到业务流程中,这需要更重的数据中心工作负载。
- 机器人和数字孪生:随着时间的推移,工业自动化和复杂的机器人技术将需要大规模模拟和实时推理。
- 自动化投资回报率:当与加速人工智能相结合时,降低成本和劳动力依赖的努力通常会产生立竿见影的回报。
要点:预期向加速计算的转变构成了我们对数据中心增长的乐观立场的基础。我们相信,极端并行计算将为数据中心基础设施投资带来多年(甚至数十年)的超级周期。
结论和我们乐观的 Nvidia 情景的风险
前提总结
我们断言,在人工智能的推动下,一个价值数万亿美元以上的新市场正在出现。正如我们所知,数据中心将转变为分布式并行处理结构,其中 GPU 和专用加速器将成为常态。Nvidia 紧密集成的平台(硬件+软件+生态系统)引领了这一转变,但它并不孤单。超大规模企业、竞争性半导体公司和专业初创公司都可以在快速扩张的市场中发挥作用。

该情景的主要风险
尽管我们做出了积极的评估,但我们承认存在一些风险:
- 对台积电的依赖和供应链脆弱
- 英伟达严重依赖台积电进行制造。地缘政治事件(特别是涉及中国大陆和台湾)的潜在破坏是一个严重的脆弱性。
- 人工智能过度炒作或经济衰退
- 人工智能可能很难像一些人预期的那样快速提供短期回报。宏观经济衰退可能会抑制昂贵的基础设施支出。
- 开源替代品
- 许多社区和供应商正在开发开源框架来绕过 Nvidia 的软件堆栈。如果这些变得足够成熟,它们可能会削弱英伟达对开发者思想份额的控制。
- 反垄断、监管与黄继任计划
- 从道德规范到竞争政策,世界各国政府都将人工智能作为关注的焦点。监管压力可能会限制英伟达捆绑硬件和软件或通过收购扩张的能力。
- 黄先生是行业中提供战略方向、清晰沟通和巨大影响力的最重要力量。如果他不再领导英伟达,情况就会发生变化。继任计划讨论尚未披露,但这仍然是一个不言而喻的风险。
- 替代方法
- 量子计算、光学计算或超低成本人工智能芯片可能最终会颠覆 GPU 的主导地位,特别是如果它们以更低的成本和瓦数提供卓越的性能。最后一句话:我们认为,英伟达的未来看起来一片光明,但它不能自满。该公司的最佳防御仍然是在硬件和软件方面进行不懈的创新,这一战略使其取得了今天的成就,并可能会推动其在这个极端并行计算的新时代继续保持领先地位。
最后一句话: 我们认为,英伟达的未来看起来一片光明,但它不能自满。该公司的最佳防御仍然是在硬件和软件方面进行不懈的创新,这一战略使其取得了今天的成就,并可能会推动其在这个极端并行计算的新时代继续保持领先地位。
照片:英伟达
免责声明:所有有关公司或证券的陈述均仅代表 SiliconANGLE Media、Enterprise Technology Research、theCUBE 上的其他嘉宾和特邀撰稿人所持的信念、观点和意见。此类声明并非这些个人购买、出售或持有任何证券的建议。所呈现的内容不构成投资建议,不应作为任何投资决策的基础。您且只有您对您的投资决策负责。
披露:《重大分析》中引用的许多公司都是 theCUBE 的赞助商和/或 Wikibon 的客户。这些公司或其他公司都无法对《重大分析》中发布的内容进行任何编辑控制或高级查看。
您的支持票对我们很重要,它有助于我们保持内容免费。
一键点击即可支持我们提供免费、深入且相关的内容的使命。一个
加入我们的 YouTube 社区
加入由超过 15,000 名 #CubeAlumni 专家组成的社区,其中包括 Amazon.com 首席执行官安迪·贾西 (Andy Jassy)、戴尔技术公司 (Dell Technologies) 创始人兼首席执行官迈克尔·戴尔 (Michael Dell)、英特尔首席执行官帕特·基辛格 (Pat Gelsinger) 以及更多名人和专家。
谢谢