

RAG-Check:一种用于多模态检索增强生成系统中幻觉检测的新型人工智能框架
作者:Sajjad Ansari
)彻底改变了生成式人工智能,显示出产生类似人类反应的卓越能力。然而,这些模型面临着一个被称为幻觉的严峻挑战,即产生不正确或不相关信息的倾向。这个问题在医疗评估、保险索赔处理和准确性至关重要的自主决策系统等高风险应用中带来了重大风险。幻觉问题从基于文本的模型扩展到处理图像和文本查询的视觉语言模型(VLM)。尽管开发了 LLaVA、InstructBLIP 和 VILA 等强大的 VLM,但这些系统仍难以根据图像输入和用户查询生成准确的响应。
现有的研究已经引入了几种解决语言模型中的幻觉的方法。对于基于文本的系统,FactScore 通过将长语句分解为原子单元以更好地验证来提高准确性。Lookback Lens 开发了一种注意力评分分析方法来检测情境幻觉,而 MARS 则实施了一个专注于关键陈述成分的加权系统。为了抹布具体来说,RAGAS 和 LlamaIndex 作为评估工具出现,其中 RAGAS 侧重于使用人类评估者的响应准确性和相关性,而 LlamaIndex 采用 GPT-4 进行可信度评估。然而,现有的工作还没有专门为多模态 RAG 系统提供幻觉分数,其中上下文包括多个多模态数据。
马里兰大学帕克分校和新泽西州普林斯顿美国 NEC 实验室的研究人员提出了 RAG-check,这是一种评估多模态 RAG 系统的综合方法。它由三个关键组成部分组成,旨在评估相关性和准确性。第一个组件涉及一个神经网络,用于评估每个检索到的数据与用户查询的相关性。第二个组件实现一种算法,将 RAG 输出分段并分类为可评分(客观)和不可评分(主观)范围。第三个组件利用另一个神经网络根据原始上下文评估目标范围的正确性,其中可以包括通过 VLM 转换为基于文本的格式的文本和图像。
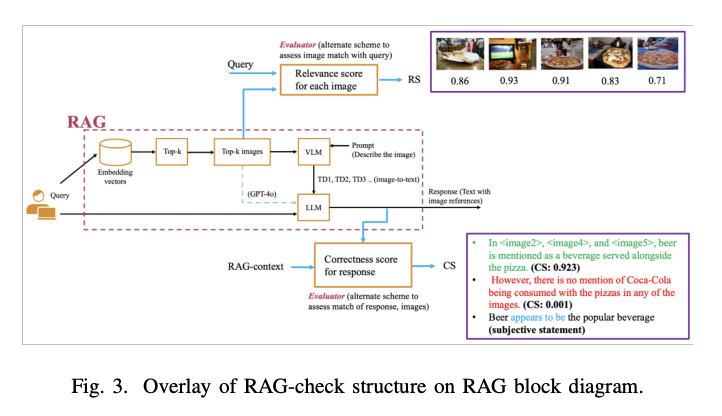
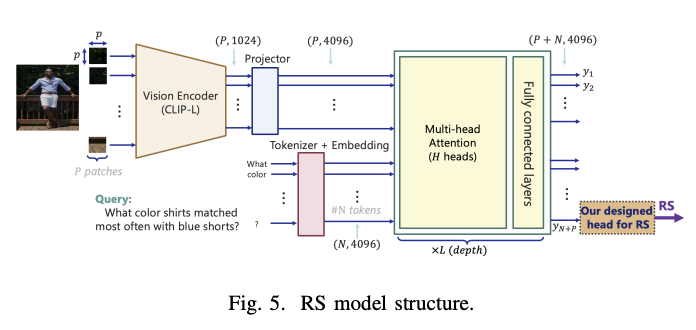
RAG 检查架构使用两个主要评估指标:相关性得分 (RS) 和正确性得分 (CS) 来评估 RAG 系统性能的不同方面。为了评估选择机制,系统分析了 1,000 个问题测试集中检索到的前 5 个图像的相关性分数,从而深入了解不同检索方法的有效性。在上下文生成方面,该架构允许灵活集成各种模型组合,无论是单独的 VLM(如 LLaVA 或 GPT4)和 LLM(如 LLAMA 或 GPT-3.5),还是统一的 MLLM(如 GPT-4)。这种灵活性使得能够全面评估不同的模型架构及其对响应生成质量的影响。
评估结果表明不同 RAG 系统配置之间存在显着的性能差异。当使用 CLIP 模型作为具有余弦相似度的视觉编码器进行图像选择时,平均相关性得分在 30% 到 41% 之间。然而,实施用于查询图像对评估的 RS 模型可将相关性分数显着提高到 71% 至 89.5%,但代价是使用 A100 GPU 时计算要求增加了 35 倍。GPT-4o 成为上下文生成和错误率方面的卓越配置,比其他设置高出 20%。其余 RAG 配置的性能相当,准确率在 60% 到 68% 之间。
总之,研究人员提出了 RAG-check,这是一种用于多模态 RAG 系统的新颖评估框架,旨在解决跨多个图像和文本输入的幻觉检测的关键挑战。该框架的三部分架构(包括相关性评分、跨度分类和正确性评估)显示了性能评估的显着改进。结果表明,虽然 RS 模型将相关性得分从 41% 大幅提高到 89.5%,但计算成本也随之增加。在测试的各种配置中,GPT-4o 成为上下文生成最有效的模型,凸显了统一多模态语言模型在提高 RAG 系统准确性和可靠性方面的潜力。
查看这纸。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。不要忘记加入我们的 65k+ ML SubReddit。
ðě 即将举行的免费人工智能网络研讨会(2025 年 1 月 15 日):利用综合数据和评估情报提高法学硕士的准确性—参加本次网络研讨会,获得可操作的见解,以提高 LLM 模型的性能和准确性,同时保护数据隐私。

Sajjad Ansari 是 IIT Kharagpur 的最后一年本科生。作为一名技术爱好者,他深入研究人工智能的实际应用,重点是了解人工智能技术的影响及其现实世界的影响。他的目标是以清晰易懂的方式阐明复杂的人工智能概念。