

超越变形金刚:新的人工智能架构可以彻底改变大型语言模型 - Decrypt
作者:Decrypt / Jose Antonio Lanz
过去几周,谷歌和 Sakana 的研究人员公布了两种可能颠覆人工智能行业的尖端神经网络设计。
这些技术旨在挑战变形金刚——一种根据上下文连接输入和输出的神经网络——这项技术在过去六年中定义了人工智能。
新方法是谷歌的“Titans”和“Transformers Squared”,它是由 Sakana 设计的,Sakana 是一家东京人工智能初创公司,以使用自然作为技术解决方案的模型而闻名。事实上,谷歌和 Sakana 都通过研究人脑来解决变压器问题。他们的变压器基本上利用不同阶段的内存并独立激活不同的专家模块,而不是针对每个问题立即使用整个模型。
最终结果使人工智能系统比以往任何时候都更智能、更快速、更通用,而无需使它们变得更大或运行成本更高。
对于上下文,变压器架构是 ChatGPT 名称中“T”的技术,专为序列到序列任务而设计,例如语言建模、翻译和图像处理。Transformer 依靠“注意力机制”或工具来了解概念在上下文中的重要性,对输入标记之间的依赖关系进行建模,使它们能够并行处理数据,而不是像所谓的循环神经网络那样顺序处理数据。变形金刚出现之前人工智能的主导技术。这项技术为模型提供了上下文理解,并标志着人工智能开发的前后时刻。
然而,尽管 Transformer 取得了巨大的成功,但它在可扩展性和适应性方面面临着巨大的挑战。为了使模型更加灵活和通用,它们还需要更加强大。因此,一旦它们经过培训,就无法改进,除非开发人员提出新模型或用户依赖第三方工具。这就是为什么今天在人工智能领域,“越大越好”是一条普遍规则。
但由于 Google 和 Sakana,这种情况可能很快就会改变。
泰坦:愚蠢人工智能的新内存架构
谷歌研究的泰坦建筑采用不同的方法来提高人工智能的适应性。泰坦并没有改变模型处理信息的方式,而是专注于改变模型存储和访问信息的方式。该架构引入了一个神经长期记忆模块,可以在测试时学习记忆,类似于人类记忆的工作原理。
目前,模型会读取整个提示和输出,预测一个标记,再次读取所有内容,预测下一个标记,依此类推,直到得出答案。他们拥有令人难以置信的短期记忆,但长期记忆却很糟糕。要求他们记住上下文窗口之外的事情,或者一堆噪音中非常具体的信息,他们可能会失败。
另一方面,Titans 结合了三种类型的记忆系统:短期记忆(类似于传统的 Transformer)、长期记忆(用于存储历史背景)和持久记忆(用于特定任务的知识)。这种多层方法允许模型处理长度超过 200 万个令牌的序列,远远超出电流互感器可以有效处理的范围。
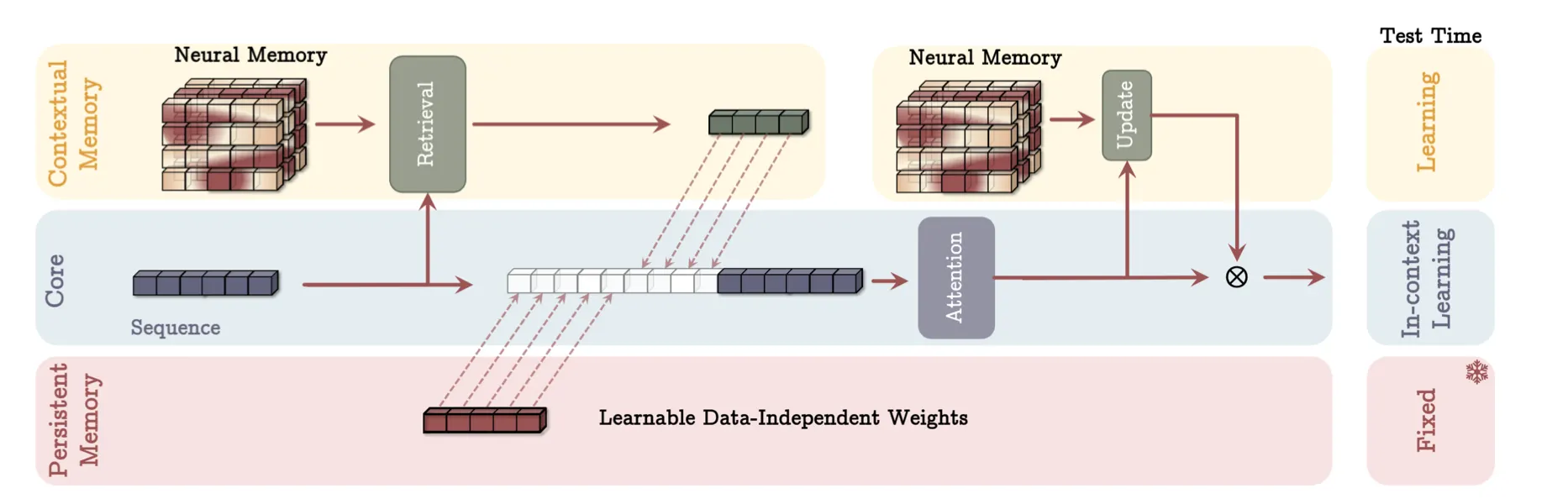
根据研究论文,泰坦在各种任务上都表现出了显着的进步,包括语言建模、常识推理和基因组学。事实证明,该架构在“大海捞针”任务中特别有效,因为它需要在很长的上下文中定位特定信息。
该系统模仿人脑如何激活不同任务的特定区域,并根据不断变化的需求动态地重新配置其网络。
换句话说,类似于大脑中的不同神经元专门负责不同的功能并根据您正在执行的任务被激活,泰坦通过合并互连的记忆系统来模仿这一想法。这些系统(短期、长期和持久记忆)协同工作,根据手头的任务动态存储、检索和处理信息。
Transformer Squared:自适应人工智能就在这里
就在 Google 发表论文两周后,来自 Sakana AI 和东京科学研究所的研究人员团队介绍了变压器平方,一个允许人工智能模型根据手头的任务实时修改其行为的框架。该系统的工作原理是在推理过程中仅选择性地调整权重矩阵的奇异分量,使其比传统的微调方法更有效。
Transformer Squared — 采用两遍机制:首先,调度系统识别任务属性,然后使用强化学习训练的特定于任务的“专家”向量进行动态混合,以获得传入提示的目标行为。”根据研究论文。
它牺牲推理时间(思考更多)来实现专业化(知道应用哪些专业知识)。
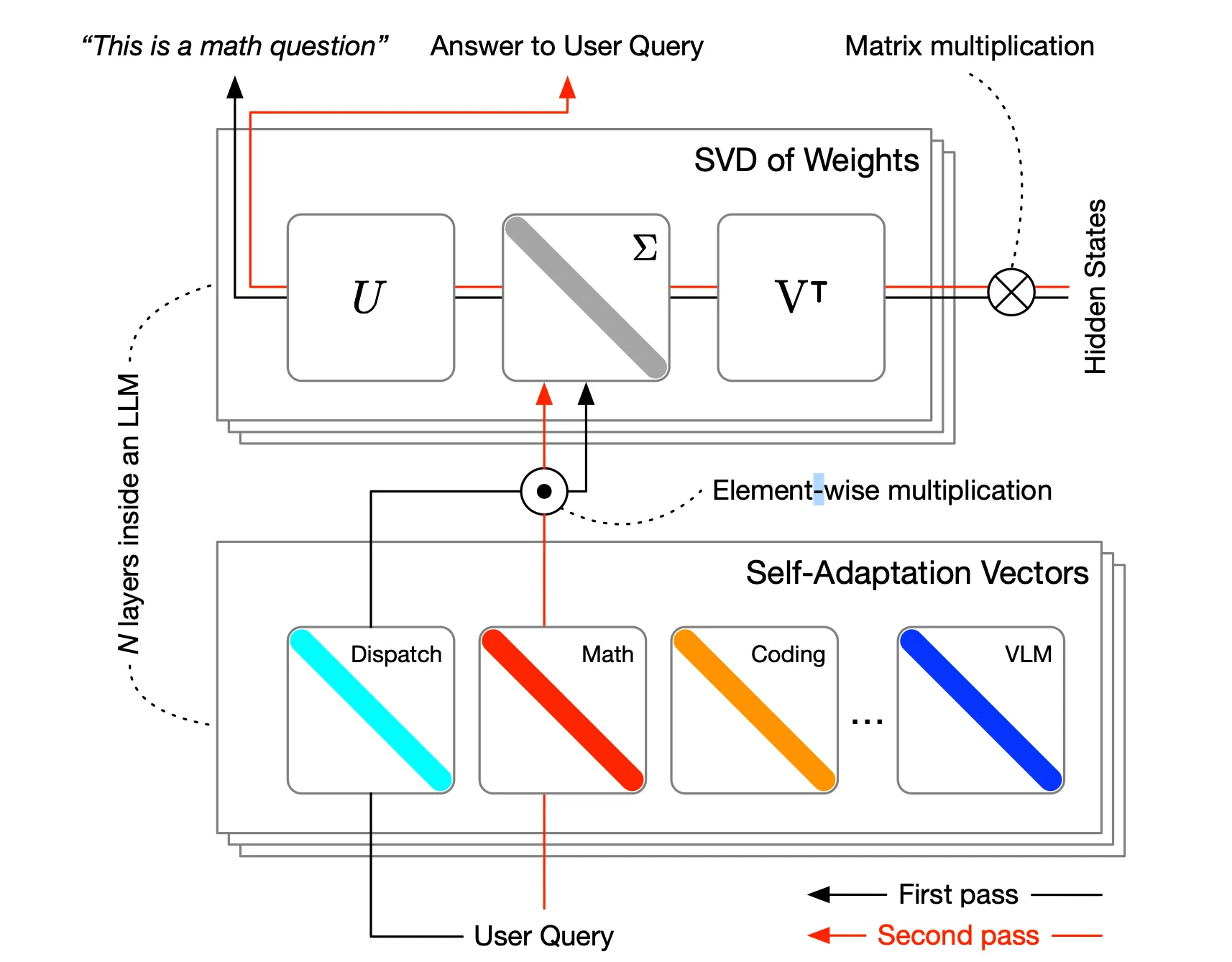
Transformer Squared 的创新之处在于其无需进行大量再培训即可适应的能力。该系统使用研究人员所谓的奇异值微调(SVF),其重点是仅修改特定任务所需的基本组件。与当前方法相比,这种方法显着降低了计算需求,同时保持或提高了性能。
在测试中,Sakana 的 Transformer 在不同任务和模型架构中展示了卓越的多功能性。该框架在处理分布式应用程序方面表现出了特别的前景,这表明它可以帮助人工智能系统变得更加灵活,对新情况的响应更加灵敏。
这是我们尝试进行的类比。当学习新技能时,你的大脑会形成新的神经连接,而无需重新连接一切。例如,当您学习弹钢琴时,您的大脑不需要重写所有知识,它会在保持其他功能的同时适应该任务的特定神经回路。Sakana 的想法是,开发人员不需要重新训练模型的整个网络来适应新任务。
相反,该模型有选择地调整特定组件(通过奇异值微调),以在特定任务上变得更加高效,同时保持其一般功能。
总体而言,人工智能公司吹嘘其模型规模庞大的时代可能很快就会成为过去。如果新一代神经网络获得关注,那么未来的模型将不需要依赖大规模来实现更大的多功能性和性能。
如今,变压器占据主导地位,通常辅以检索增强生成 (RAG) 或 LoRA 等外部工具来增强其功能。但在快速发展的人工智能行业中,只需要一次突破性的实施就可以为一场巨大的转变奠定基础——一旦发生这种情况,该领域的其他领域肯定会效仿。
编辑者安德鲁·海沃德
一般智能通讯
由生成型人工智能模型 Gen 讲述的每周人工智能之旅。