

Salesforce AI Research 推出 CodeXEmbed (SFR-Embedding-Code):在 CoIR 基准测试中排名第一并支持 12 种编程语言的代码检索模型系列
作者:Asif Razzaq
代码检索对于现代软件开发中的开发人员来说至关重要,可以有效地访问相关代码片段和文档。与有效处理自然语言查询的传统文本检索不同,代码检索必须解决独特的挑战,例如编程语言的结构变化、依赖性和上下文相关性。随着 GitHub Copilot 等工具越来越受欢迎,高级代码检索系统对于提高生产力和减少错误变得越来越重要。
现有的检索模型通常难以捕获特定于编程的细微差别,例如语法、控制流和变量依赖性。这些限制阻碍了代码摘要、调试和语言间翻译中问题的解决。虽然文本检索模型取得了显着的进步,但它们无法满足代码检索的特定要求,这凸显了对能够提高各种编程任务的准确性和效率的专用模型的需求。CodeBERT、CodeGPT 和 UniXcoder 等模型已经使用预先训练的架构解决了代码检索的问题。尽管如此,由于其较小的尺寸和特定于任务的重点,它们在可扩展性和多功能性方面受到限制。尽管 Voyage-Code 引入了大规模功能,但其闭源性质限制了更广泛的采用。这突出表明迫切需要一个开源、可扩展的代码检索系统来泛化多个任务。
Salesforce AI Research 的研究人员介绍代码X嵌入,一系列专为代码和文本检索而设计的开源嵌入模型。这些型号推出了三种尺寸,SFR-嵌入代码-400M_R,SFR-嵌入代码-2B_R和 70 亿个参数,可解决各种编程语言和检索任务。CodeXEmbed 的创新培训管道集成了 12 种编程语言,并将五种不同的代码检索类别转换为统一的框架。通过支持文本到代码、代码到文本和混合检索等多种任务,该模型扩展了检索系统可以实现的范围,提供了前所未有的灵活性和性能。
CodeXEmbed 采用创新方法,将代码相关任务转换为统一的查询和回答框架,从而实现跨各种场景的多功能性。文本到代码检索将自然语言查询映射到相关代码片段,从而简化代码生成和调试等任务。代码到文本检索生成代码的解释和摘要,从而增强文档和知识共享。混合检索集成了文本和代码数据,有效解决需要技术和描述性见解的复杂查询。该模型的训练利用对比损失来优化查询-答案对齐,同时减少不相关数据的影响。低等级适应和令牌池等先进技术可以在不牺牲性能的情况下提高效率。
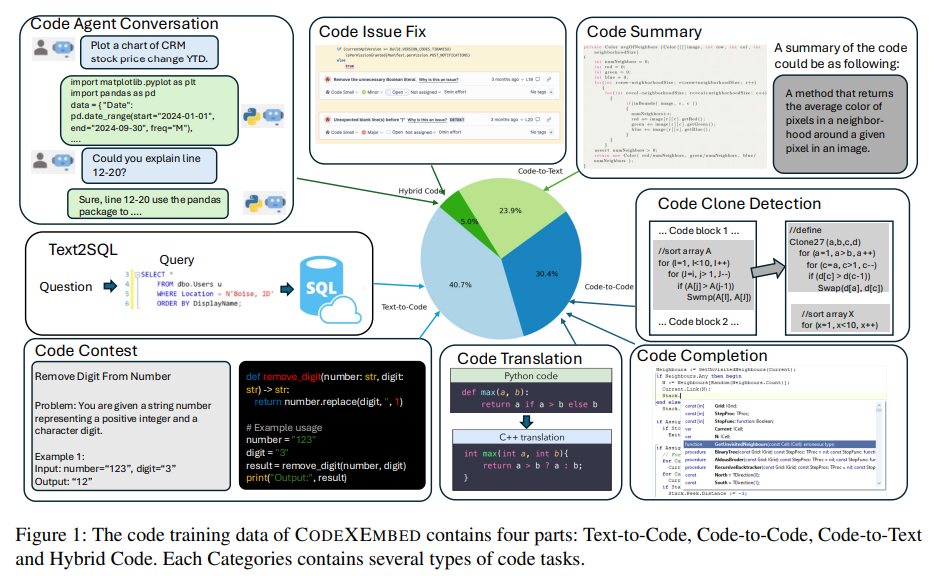
在测试中,它已经通过各种基准进行了评估。在覆盖 10 个子集、超过 200 万条条目的综合代码检索评估数据集 CoIR 基准上,70 亿参数模型与之前最先进的 Voyage-Code 模型相比,性能提升了 20% 以上。值得注意的是,4 亿和 20 亿参数模型的性能也优于 Voyage-Code,证明了该架构在不同规模下的可扩展性。此外,CodeXEmbed 在文本检索任务中表现出色,拥有 70 亿个参数的模型在 BEIR 基准测试中取得了 60 分的平均分,BEIR 基准测试由 15 个数据集组成,涵盖了问答和事实核查等不同的检索任务。
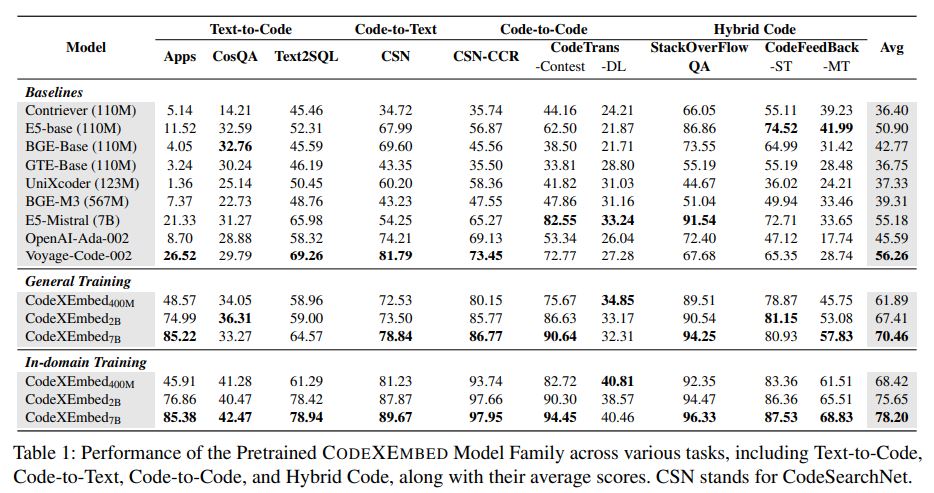
该模型可以检索代码并增强端到端检索增强生成(抹布)系统。例如,当应用于代码完成和问题解决等存储库级任务时,70 亿参数模型在 RepoEval 和 SWE-Bench-Lite 等基准测试中取得了显着的结果。RepoEval 专注于存储库级别的代码补全,当模型检索上下文相关的片段时,其准确性得到了 top-1 的提高。在 SWE-Bench-Lite(用于 GitHub 问题解决的精选数据集)中,CodeXEmbed 的性能优于传统检索系统。
该研究的主要结论强调了 CodeXEmbed 在推进代码检索方面的贡献和影响:
- 70 亿参数模型实现了最先进的性能,比 CoIR 基准提高了 20% 以上,在 BEIR 上取得了有竞争力的结果。它展示了跨代码和文本任务的多功能性。
- 4 亿和 20 亿参数模型为计算资源有限的环境提供了实用的替代方案。
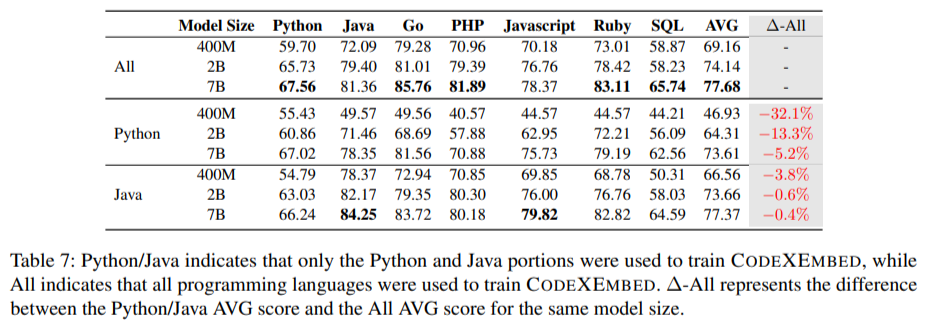
- 这些模型通过统一 12 种编程语言和 5 个检索类别来解决广泛的代码相关应用程序。
- 与 Voyage-Code 等封闭系统不同,CodeXEmbed 促进社区驱动的研究和创新。
- 与检索增强生成系统集成可以改善代码完成和问题解决等任务的结果。
- 使用对比损失和令牌池可以优化检索准确性和模型适应性。
总之,Salesforce 推出的 CodeXEmbed 系列促进了代码检索。这些模型通过在 CoIR 基准上实现最先进的性能并在文本检索任务中表现出色,展示了无与伦比的多功能性和可扩展性。支持 12 种编程语言的多语言和多任务统一框架,使 CodeXEmbed 成为开发人员和研究人员的关键工具。其开源可访问性鼓励社区驱动的创新,同时缩小自然语言和代码检索之间的差距。
查看这纸,400M型号,和 2B模式我。这项研究的所有功劳都归功于该项目的研究人员。另外,不要忘记关注我们 叽叽喳喳并加入我们的 电报频道和 领英 集团奥普。不要忘记加入我们的 65k+ ML SubReddit。
噗噗噗推荐开源平台:Parlant 是一个框架,它改变了人工智能代理在面向客户的场景中做出决策的方式。 (已晋升)

Asif Razzaq 是 Marktechpost Media Inc. 的首席执行官。作为一位富有远见的企业家和工程师,Asif 致力于利用人工智能的潜力造福社会。他最近的努力是推出人工智能媒体平台 Marktechpost,该平台因其对机器学习和深度学习新闻的深入报道而脱颖而出,技术可靠且易于广大受众理解。该平台月浏览量超过200万,可见其深受观众欢迎。