
多任务意见增强了精神健康分析的混合BERT模型
作者:Alfarhood, Sultan
介绍
由于数百万的人患有一系列精神疾病,心理健康在全球越来越普遍1。有效治疗心理健康问题需要尽早认识和持续监测。由于社交媒体和数字平台的普及,每天都会生产大量文本数据2,通常代表用户的思想,感觉和情感状态。通过分析这些数据,可以评估心理健康问题并确定情绪不适的早期指标。但是,准确地辨别人们从文本中的感受和思想的微妙之处仍然是一个重大挑战。
从文本数据中分析心理健康的先前方法主要依赖于独立执行状态检测或情感分类的单任务学习模型3,,,,4。这些模型虽然有帮助,但通常无法捕捉到在现实世界中共存的细微人类情感和主观观点5。例如,单独的情感分析可能会忽略意见中嵌入的批判性心理线索,这是主观的解释和观点6。这种局限性降低了传统模型在理解心理健康分析所需的复杂情绪环境方面的有效性。
情感分析提供了有价值的信息,但通常将情绪视为一般分类,缺乏提取细微的情绪状态所需的粒度或与心理健康相关文本的主观解释6。现有模型还无法整合基于外部意见的见解,这些见解可能会增加基于变压器模型(例如Bert)提供的上下文嵌入7,,,,8。因此,对于一个框架的迫切需要,该框架可以纳入文本数据的事实和主观维度,以提供对心理健康指标的全面理解。
为了解决这些差距,我们介绍了具有意见增强的混合BERT模型(意见-Bert),这是一个专门为心理健康评估设计的新型多任务学习框架。我们研究的关键区别是引入意见嵌入,这些嵌入是由外部情感注释和预训练的意见提取模型动态构建的。与以前的研究不同,我们的方法明确捕获了主观的观点,使该模型能够与Bert嵌入的上下文信息一起分析观点。这种双重表示使我们能够比单独的情感分析更有效地辨别微妙的情感模式和心理状态。
此外,我们还利用了混合体系结构,结合了卷积神经网络(CNNS)和双向封闭式复发单元(BIGRUS),该单元(BIGRUS)量身定制,以捕获局部模式(例如,情感带电的短语)和顺序依赖性(例如,文本中的思想进展)。通过采用多任务学习,我们的模型同时执行情感和状态分类,利用共享表示形式来提高这两个任务的绩效。
我们广泛的评估表明,意见 - 伯特在情感分类中的精度达到96.77%,地位分类的精度为94.22%,表现优于伯特(Bert)的最先进基线模型9,罗伯塔10和Distilbert11。这些结果强调了嵌入在改善模型性能并获得对心理健康指标的更全面了解方面的关键作用。
这项工作的主要贡献如下:
-
我们提出了一种新颖的意见增强的混合BERT模型,该模型将意见嵌入到基于BERT的体系结构中,从而使该模型能够捕获和利用主观观点来增强心理健康预测。
-
我们引入了一种混合体系结构,将BERT与CNN和BIGRU层相结合,从而使模型可以通过卷积层和顺序依赖性通过经常性层有效地提取局部特征。
-
我们的方法利用多任务学习可以同时执行情感和状态分类,从而通过在两个任务之间共享信息来提高整体绩效。
-
我们通过证明了舆论增强的嵌入在实现细微的理解和准确的预测方面的优越性,从而明确解决了先前作品的局限性。
这些贡献突出了我们在进行精神健康评估文本数据分析方面的新颖性和有效性。通过弥合情感和基于意见的见解之间的差距,意见 - 伯特为早期识别和干预心理健康挑战提供了强大的框架。
本文的其余部分如下组织。对文献进行了详尽的评估。文献综述。节数据描述介绍数据集和数据预处理。所提出的方法在“问题陈述,然后在节中进行实验设置实验设置以及对节目中结果的分析结果分析。节讨论提出讨论,节限制和未来工作概述了局限性和未来工作,以及节结论纸总结。
文献综述
近年来,从社交媒体,在线论坛和患者记录中增加了文本数据的可用性引起了人们对使用自然语言处理(NLP)的浓厚兴趣。传统的机器学习技术一直是早期方法的主要手段,但是伯特,罗伯塔和GPT等深度学习模型的发展在该领域取得了长足的进步。但是,这些模型经常无法考虑感受和观点在心理健康文本中发挥的复杂作用。文献的概述着眼于多任务学习模型,情感分析和心理健康检测,强调了我们意见增强的混合BERT模型寻求填补的重大发展和差距。
机器学习和NLP技术通过各种平台上的文本分析越来越多地应用于早期的心理健康诊断。辛格等。12使用决策树,随机森林和逻辑回归等分类器进行了基于SMS的心理健康评估,逻辑回归可实现93%的准确性。Inamdar等。13专注于使用Elmo和Bert嵌入的Reddit柱中的精神压力,并获得了0.76 F1得分,并具有逻辑回归。Alanazi等。14调查了金融新闻对公共心理健康的影响,发现SLCNN是最有效的,在情感分类中的准确性为93.9%。ABD Rahman等人进行的系统审查。15强调SVM是在线社交网络中用于心理健康检测的常用模型,强调了诸如数据质量和道德问题之类的挑战。Abdulsalam等。16引入了带有5719条推文的阿拉伯自杀检测数据集,表明阿拉伯模型的表现优于传统模型,例如SVM和随机森林,达到91%的准确性和F1得分为88%。Almeqren等。17使用BI-GRU模型和自定义的阿拉伯心理词典(ARAPH),应用阿拉伯情感分析(ASA)来预测沙特阿拉伯共同19日大流行期间的焦虑水平,在从推文中分类焦虑方面达到了88%的准确性。Ameer等。18重点是检测16,930个Reddit职位的抑郁症和焦虑,罗伯塔(Roberta)模型达到了83%的最高精度,强调了自动化在支持心理健康提供者中的作用。Su等。19对心理健康中的深度学习应用进行了探索,对跨临床,遗传,人声和社交媒体数据的研究进行了分类,并强调了DL的早期检测潜力,同时指出了模型可解释性和数据多样性的挑战。这些研究共同证明了AI在增强各种平台和语言的早期心理健康诊断方面的变革潜力。
多项研究强调了多任务学习(MTL)在检测心理健康状况并改善各个领域的情感分析方面的有效性。刘和苏20与单任务模型和通用大语模型(LLMS)相比,探索了基于BERT的MTL MTL框架,可在社交媒体上进行心理健康检测,在Reddit自杀和精神病学症状数据集中取得了卓越的表现。佛陀和墨人21专注于使用基于CNN的MTL模型应用于Reddit和Twitter的自杀构想检测,表现优于基层,并强调合并症条件(例如PTSD)在提高预测准确性方面的作用。Sarkar等。22引入了AMMNET,这是一种MTL模型,该模型将单词嵌入和主题建模集成以预测Reddit柱中的抑郁和焦虑,但尽管存在数据限制,但通过积极学习表明了强劲的表现。Li等。23应用MTL来检测对话中的抑郁,结合了情感,对话法和主题分类等任务,并在对话数据集中达到了70.6%的F1分数。同样,Plaza-Del-Arco等。24在西班牙推文中提出了用于仇恨语音检测的MTL模型,结合了情感分析和情感分类,其中MTLSENT+EMO配置的表现优于单任务学习模型。最后,Jin等人。25开发了一种情感分类MTL模型(MTL-MSCNN-LSTM),该模型集成了多尺度的CNN和LSTM,以捕获商品评论中的全球和本地文本功能,在六个数据集中实现了更高的准确性和F1分数。这些研究共同证明了MTL在提高预测准确性,处理多个任务以及解决诸如数据稀疏性和模型效率等挑战方面的潜力。
多项研究集中于加速意见 - 装饰方法,主要是使用情感分析中的注意机制和最先进的体系结构。Malik等。26引入了一种混合模型,该模型将多头关注与BI-LSTM和BI-GRU分类器相结合,实现了95%的精度,97%的召回率和96%的F1在学生反馈情绪分析中使用高级嵌入式(例如FastText和Roberta)。以类似的方式,Chen等人。27提出了一个基于BERT的双通道混合神经网络,该神经网络将CNN和Bilstm与注意力机制集成在一起,从而显着改善了酒店评论数据集的情感分析,达到了92.35%的精度。另一方面,Dimple Tiwari和Nagpal28介绍了富含知识的混合变压器Keaht,用于分析与Covid-19和Farmer抗议活动相关的情感,并结合了LDA主题建模和BERT,展示了其处理复杂的社交媒体情感分析任务的能力。Huang等人引入的AEC-LSTM模型。29使用一种新颖的方法来整合情绪智力和注意力机制,从而在现实世界数据集上进行卓越的表现进行情感分类。相比之下,汉和坎多30专注于使用具有深层上下文化嵌入(例如BERT)的Bilstm-CRF模型来改善意见表达检测,显示出卓越的检测主观表达的结果。耶巴拉和西里亚诺31探索了角色级别的嵌入,以提高意见目标表达(OTE)提取,以解决诸如拼写错误和域特异性术语之类的问题,而Liu等人。32强调了RNN,尤其是LSTM的有效性,比传统的CRF模型在细粒度挖掘中,通过微调单词嵌入来增强性能。这些研究强调了情感分析模型的演变,强调了对高级嵌入,注意机制和混合体系结构的需求,以改善各种应用程序中的情感分类和意见挖掘。
总之,情感分析中的进步,尤其是关于心理健康的进步,突出了深度学习和机器学习方法的革命潜力。使用RNN,CNN和Transformer架构(例如Bert)的复杂模型取代了传统的基于词典的方法,从而提高了从文本输入中提取细微情绪的能力。在各种平台上进行的实验中,多任务学习(MTL)和注意力过程有助于处理复杂的任务并提高预测准确性。情感分析解决了AI模型中数据多样性的问题和对可解释性的要求。随着它继续合并,它为早期心理健康诊断和干预措施提供了潜在的途径。
数据描述
这项研究中采用的数据集是从带有心理健康状况注释的几个平台上进行的广泛而艰苦地组装的一组话语。它结合了来自其他Kaggle数据集的信息,例如用于聊天机器人和凹陷的3K对话数据集。REDDIT清洁,人力压力预测,双极心理健康数据集,Reddit心理健康数据,学生焦虑和抑郁数据集,自杀心理健康数据集和自杀推文检测数据集与心理健康和焦虑预测有关。以下七个心理健康状况之一与该数据集中的陈述有关:正常,抑郁,自杀,焦虑,压力,双相情感障碍或人格障碍。数据中的每个条目都具有特殊的心理健康状况,并且是从Reddit和社交媒体等各种站点收集的。从Kaggle获得的数据集已经标记为标签,不包括任何用户级信息,例如每个用户的帖子数。
该数据集由唯一_ID,声明和心理健康状况等变量组织,是研究心理健康趋势,为精神健康创造复杂的聊天机器人的无价工具,并进行了深入的情感分析。

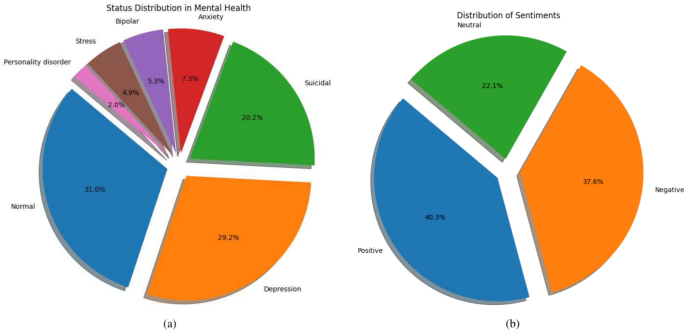
数据集中的心理健康状况和情感分布。
对样本的态度和心理健康状况的重要见解如图2所示。1。心理健康状况的分布如图所示。 1A,正常情况占最大比例(31%),其次是抑郁症(20.2%)和自杀实例(20.2%)。较小的百分比用其他类别(包括焦虑症(7.3%),双相情感障碍(5.3%),压力(4.9%)和人格障碍的其他类别来解释(4.3%2.0%)。该分布证明了精神健康状况(例如抑郁症和自杀思想)等心理健康状况的频率。
情感分布如图所示。 1b,积极情绪最为普遍,为40.3%,其次是否定的情绪为37.6%,中立情绪为22.1%。这种情绪崩溃通过反映与心理健康状况相关的情感调子来研究心理健康趋势中的情绪分析的关键背景。

数据集中的后长度分布。直方图根据其单词计数显示帖子的频率,突出显示了最常见的帖子长度,并提供了对数据集典型内容大小的见解。
数字2表明数据集中的大多数帖子相对较短,其中大多数包含少于500个单词,而显着的浓度低于100个单词。随着单词计数的增加,帖子数量的急剧下降突出了用户生成的内容中较短帖子的主导地位。这种模式表明,用户倾向于以简短的格式传达自己的想法,这对于经常鼓励简洁的社交媒体或数字平台是典型的。超过1,000个字的帖子很少见,进一步加强了人们对简洁交流的偏好。了解此分布对于自然语言处理任务至关重要,因为它可以帮助我们设定适当的令牌化限制,从而确保大多数帖子被充分捕获,同时最大程度地减少截断或过度填充的需求。此外,这种见解使我们能够设计针对用户内容典型长度的优化模型,从而提高了分类,情感分析或主题建模等下游任务的效率和准确性。
数据预处理
数据清洁
数据清洁需要几个重要的程序来确保质量和完整性33。确定并消除了重复的条目,以避免冗余。删除了特殊字符,URL和其他非α数字组件以简化文本数据。此外,文本被转化为小写,以保持均匀性并消除由于病例敏感性而引起的问题。通过根据上下文或消除受影响的行进行合适的值来仔细处理缺失值。最后,为了提高分析对主要思想的重视,消除了对陈述的含义最小的通用单词。所有这些程序共同努力,提供了一个干净且值得信赖的数据集,以进行进一步的处理和检查。
柠檬酸
Lemmatization专注于将单词分解为最基本或根部的形式,是文本制备中必不可少的阶段。与经常截断单词的茎相反,lemmatization试图通过考虑意义和上下文来产生合理的单词。首先,为了保持均匀性,将所有标点符号删除,并将文本转换为小写。将文本的令牌化成单个单词,频繁停止单词被消除。下一34,,,,35,这可以保证像跑步和运行一样的术语被简化为词根。随后将诱人的令牌合并为处理的语句,为随后的特征提取和建模阶段准备。
使用同义替代品的数据增强
作为数据增强过程的一部分,我们使用了同义词替代技术来提高数据集的多样性和弹性36,,,,37。此方法找到单词,并使用WordNet词汇数据库替换它们38。使用WordNet Synset,该过程开始于给定文本中的每个单词提取同义词。同义词是从文本中每个单词的潜在同义词列表中随机选择的。此替换在措辞中引入了修改,同时将文本含义保持在预定的次数(在此示例中,n = 3)。随后,将修改后的文本组合在一起并添加到数据集中,从而增加了数量和多样性。为了提供一个更完整的数据集,创建了每个原始文本项目的几个副本,并使用同义词附加了。使用同义词_replacement函数,此方法可显着提高数据集的多样性,并可以帮助经过培训的机器学习模型表现更好并变得更广泛地适用。为了在进一步的分析或培训中保持一致性,将原始标签保留在使用原始和新鲜生成的文本创建的增强数据集中。
用文本框架分析的情感分析
在情感分析阶段,TextBlob用于评估补充数据集中的每个陈述以确定其情感极性39。基于极性得分\(p \), 在哪里\(p \ in [-1,1] \),TextBlob将态度分为三类:积极,中立,或负面。下一节描述了如何进行情感分类。
-
积极的情绪:\(p> 0 \)
-
中性情绪:\(p = 0 \)
-
负面情绪:\(p <0 \)
功能\(\ text {Analysis} \ _ \ text {情感} \ _ \ text {by} \ _ \ text {status} \)用于执行此分类。它处理每个语句\(S \)以及随之而来的状态\(\ text {status} \),评估情感,并产生元组\((s,\ text {status},\ text {情感})\)\)。组合情感后,我们可以通过检查一个称为的数据框来确定每个状态的情感类型的数量\(\ text {情感} \ _ \ text {df} \)。特别是,通过使用
$$ \ begin {aligned} \ text {text} \ _ \ text {counts} _ {ij} = \ text {count} \ left(\ text {text} \ _ \ _ \ _ \ text {df text {df}= i \ text {and} \ text {textiment} = j] \ right)\ end {aligned} $$
状态的语句数量\(我\)和情感\(J \)由\(\ text {textiment} \ _ \ text {counts} _ {ij} \)。这种分布阐明了各种心理健康状态中感受的分布,并在\(\ text {textiment} \ _ \ text {counts} \)\)。分析与报告的心理健康问题有关的话语的情感语气需要了解此分布。
为了确保我们的发现的鲁棒性,我们还尝试了其他情感分析工具,包括Vader和Afinn。这些工具提供了不同的情感评分方法,并用于重新评估数据集的情感标签。比较分析表明,虽然TextBlob提供了情感类别的平衡分布,但Vader发现了更细微的极性转移,尤其是在中性和负面情绪中。结果部分介绍了这些结果及其对最终模型的影响。
意见
我们使用Spacy的英语NLP模型确定了与意见相关的重要术语,以从文本输入中提取和消毒主观表达40。我们通过删除辅助动词并专注于形容词,副词和动词来完善提取程序,这可能通过通过模型运行每个文本来传达主观感觉。为了方便起见,将检测到的意见合并为字符串格式。总之,我们在提取后使用了清洁机制。该功能消除了过于重复或微不足道的非字母字母和短语,仅留下重要的和原始的表达式。最终产品是通过相关且清洁的短语增强的数据集,为其他研究或模型培训提供了强大的基础。
表中列出了每种情感类型的平均意见数量1。平均而言,有36.31个意见,积极的类别的意见最多,紧随其后的是否定类别,有33.80个意见。另一方面,中立类别的平均平均值要低得多,每种感觉的意见为3.64。这表明用户记录的中性评论较少,并且更喜欢在积极或消极的方面更频繁地表达更强的情感。如中立思想的数量不平衡所见,数据集中可能会有一个普遍的趋势。
数据集中最常使用的意见在表中列出2。有81,114次发生,动词的感觉是最常见的,这表明情感表达对数据集很重要。诸如New和Want之类的动词,分别遵循了52,940和50,827次的动词,表明知识和想要的知识与用户态度密切相关。诸如“ get”之类的其他经常使用的词也确实表示典型的重点或强度宣言。这些经常表达的意见提出了对用户经常用来传达其感受,想法和行为的重要短语的关注,从而为数据集的复发主题提供了见解。
数据令牌化和标签编码
我们使用了令牌化和标签编码的两步步骤来获取用于模型培训的文本输入。首先,使用Berttokenizer,将原始文本数据转换为适合基于BERT的模型的令牌ID和注意性掩码9。在处理数据帧语句列中的短语之后,tokenize_data函数生成input_ids和注意_masks使用给定的填充参数并截断至最大长度为100令牌,除其他方面。由于该令牌化,该文本数据是正确构建的,用于模型输入。
对数据集进行了探索性分析后,我们将输入序列长度设置为100个令牌。最初,我们检查了令牌化句子的分布,并观察到大多数实例包含不到100个令牌。具体而言,我们的初步数据分析表明,数据集中约有90%的句子的代币计数低于此阈值,从而最大程度地减少了大多数样本的不必要填充量。选择稍长的长度将增加计算开销,而较短的长度风险截断相关环境。因此,填充长度为100令牌代表了计算效率和保留重要的文本信息之间的平衡妥协。
下一步涉及标签编码,该标签编码将类别标签转换为模型训练所需的数值值41。为了地位,,,,情感, 和consions_str列,我们初始化了标签编码器。这些编码器使模型能够通过将不同的类标签映射到整数来有效地理解和处理分类数据。观点标签保存为整数编码,而状态和情感标签则通过使用该标签转换为单热编码向量to_categorical功能。彻底的准备可以确保正确准备分类数据和文本数据,并将其整合到培训管道中。这些编码的标签现在包含在新的数据框架中,这使得管理数据并更容易训练模型。
数据拆分
该数据集系统地分为培训,验证和测试集,以简化模型的培训和评估。为了兼容Scikit-learn的train_test_split函数,首先将输入张量(Input_IDS和COATION_MASKS)和编码标签(status_labels,stormiment_labels和opinions_labels和opinions_labels)从TensorFlow Tensors转换为Numpy阵列。
最初,该数据集分为培训和临时组合,预留了30%用于测试和验证,而有70%的人进行培训。然后将临时集均匀地分为测试和验证集,每个集合占初始数据的15%。该方法通过均匀分发数据来确保扎实的模型培训和客观评估。相应的数据集尺寸为1,10,365个样本,用于验证23,650个样本,23,650个样品进行测试。These splits are essential for evaluating model performance, fine-tuning hyperparameters, and guaranteeing the applicability of the model to new data.
问题陈述
Mental health analysis through text requires a deep understanding of both sentiments and subjective opinions expressed in user-generated content. This challenge can be effectively addressed using multi-task learning, in wich a model is trained to handle multiple related tasks simultanously. In this study, we aim to classify both sentiment and status using a BERT-based hybrid model that integrates external opinion embeddings to enhance the model’s interpretative capabilities.
输入: 让\(X_i\)represent the input sequence for the\(我\)-th instance, where
$$\begin{aligned} X_i = \{x_{i1}, x_{i2}, \dots , x_{im}\} \end{aligned}$$
represents a sequence of\(m\)令牌。In addition, let\(O_i\)denote the external opinion information associated with the input sequence, represented as an embedding.
-
文本输入:\(X_i \in \mathbb {R}^{m \times d}\)(BERT embeddings of the input text sequence)
-
Opinion Input:\(O_i \in \mathbb {R}^{d}\)(dense opinion embedding)
输出: The model is designed for multi-task learning, providing predictions for both sentiment and status classification:
-
Sentiment output:\(Y_i^{\text {sentiment}} \in \mathbb {R}^C\), 在哪里\(C\)is the number of sentiment classes.
-
Status output:\(Y_i^{\text {status}} \in \mathbb {R}^S\), 在哪里\(S\)is the number of status classes.
-
最终输出: The model predicts:
$$\begin{aligned} Y_i = (Y_i^{\text {sentiment}}, Y_i^{\text {status}}) \end{aligned}$$
在哪里\(Y_i\)is a pair consisting of the predicted sentiment and status labels for input sequence\(X_i\)。
This formulation encapsulates the multi-task nature of the problem, aiming to accurately classify both sentiment and status from text data enriched with opinion-based insights.
建议的方法
数字3illustrates the architecture of our Opinion-Enhanced Hybrid BERT Model, which is designed to handle two tasks simultaneously: sentiment classification and status classification in mental health-related text data. Our model enhances standard BERT embeddings with custom opinion embeddings, capturing subjective opinions expressed in the text. These opinions are critical for understanding mental health conditions. By combining contextual information from BERT with subjective insights through opinion embeddings, we provide a deeper understanding of emotional states.

Our proposed architecture combines dynamically produced opinion embeddings with BERT embeddings. We integrate these opinion embeddings with BERT’s contextual representations, which are obtained via sentiment annotations. Our design uses a hybrid feature extraction technique to capture sequential relationships as well as local patterns. This mechanism consists of layers of CNN and BiGRU. We apply concatenation, dropout, and normalizing layers to the final representations, yielding outputs for status prediction and sentiment categorization.
We employed BERT as the foundation of our model to generate contextual embeddings. We extended this using a custom OpinionsEmbedding Layer that integrates opinion-based information. A hybrid feature extraction mechanism, utilizing both CNN and BiGRU layers, captures the local patterns and long-range dependencies in the text. Our model is structured within a multi-task learning framework, enabling us to perform sentiment and status classification in parallel, learning shared representations that improve performance on both tasks.
-
1。
BERT encoder: Our model is based on BERT and produces embeddings represented by\(H_{\text {BERT}}\)。These BERT embeddings capture syntactic and semantic relationships between words, offering a comprehensive, context-aware representation of the input text.By leveraging BERT, we ensure the model identifies subtle nuances in meaning, which is essential for correctly understanding information linked to mental health.Each word is represented in relation to its surrounding context, which is particularly helpful when handling complex language patterns often found in mental health-related text, such as metaphorical language and emotive expressions.
To enhance sentiment and status classification accuracy, we complement the contextual understanding provided by\(H_{\text {BERT}}\)with additional components, such as CNN, BiGRU, and attention-based opinion embeddings. This layered approach enables the model to capture nuanced changes in tone, inferred emotions, and subtle viewpoints.
-
2。
Opinion embeddings: We incorporate a specific layer called the OpinionsEmbedding Layer, which extracts subjective information like opinions and emotions. This layer complements the contextual information captured by BERT embeddings. To extract sentiment-related subtleties, we employ an attention mechanism that highlights the most relevant textual elements. Specifically, we calculate queries\(Q_i\),钥匙\(K_i\)和值\(V_i\)for each word in the input sequence:
$$\begin{aligned} Q_i = E_o \cdot W_{Q_i}, \quad K_i = E_o \cdot W_{K_i}, \quad V_i = E_o \cdot W_{V_i} \end{aligned}$$
这里,\(E_o\)is the base opinion embedding derived from external sentiment annotations, while\(W_{Q_i}\),,,,\(W_{K_i}\), 和\(W_{V_i}\)are learned weight matrices that transform\(E_o\)into queries, keys, and values.
Next, we compute the attention score\(S_i\), which determines the significance of each word in expressing opinions or emotions:
$$\begin{aligned} S_i = \tanh (Q_i \cdot W_a + K_i \cdot U_a + V_a) \end{aligned}$$
This score leverages learned weight matrices\(W_a\),,,,\(U_a\), and a vector\(V_a\)to highlight opinion-relevant words. Applying these scores to the values generates the final opinion embeddings\(O_{\text {opinions}}\), which encapsulate the subjective dimensions of the text.
We then concatenate these opinion embeddings with the contextual embeddings from BERT to create a unified representation:
$$\begin{aligned} H_{\text {combined}} = \text {Concat}(H_{\text {BERT}}, O_{\text {opinions}}) \end{aligned}$$
This combined embedding\(H_{\text {combined}}\)enriches the model’s understanding by integrating both factual and emotional insights, which is crucial for mental health studies.
-
3。
Hybrid architecture (CNN and BiGRU): We process the combined embeddings\(H_{\text {combined}}\)using a hybrid architecture that includes convolutional neural networks (CNNs) and bidirectional GRUs (BiGRUs). The CNN branch captures local patterns, such as emotionally charged phrases, using 1D convolution:
$$\begin{aligned} H_{\text {CNN}} = \text {Conv1D}(H_{\text {combined}}, k) \end{aligned}$$
A max-pooling operation reduces the dimensionality while retaining significant features:
$$\begin{aligned} H_{\text {CNN}} = \text {MaxPool1D}(H_{\text {CNN}}) \end{aligned}$$
Simultaneously, the BiGRU captures long-range dependencies and sequential relationships in the text. We generate the BiGRU output\(H_{\text {BiGRU}}\)作为:
$$\begin{aligned} H_{\text {BiGRU}} = \text {BiGRU}(H_{\text {combined}}) \end{aligned}$$
A global max-pooling operation further condenses the BiGRU output:
$$\begin{aligned} H_{\text {BiGRU}} = \text {GlobalMaxPooling1D}(H_{\text {BiGRU}}) \end{aligned}$$
By combining the CNN and BiGRU outputs, our architecture captures both short-term and long-term dependencies, making it well-suited for analyzing nuanced emotional expressions.
-
4。
多任务学习: We adopt a multi-task learning framework to perform sentiment classification and status classification simultaneously. This approach enables the model to generalize better by leveraging shared patterns between the two tasks. We apply dropout and layer normalization to the concatenated outputs from the CNN and BiGRU layers:
$$\begin{aligned} H_{\text {final}} = \text {LayerNormalization} (\text {Dropout} (\text {Concat} (H_{\text {CNN}}, H_{\text {BiGRU}}))) \end{aligned}$$
Finally, two separate softmax layers generate predictions for sentiment and status classifications:
$$\begin{aligned} \hat{y}_{\text {sentiment}}= & \text {softmax}(W_{\text {sentiment}} H_{\text {final}})\\ \hat{y}_{\text {status}}= & \text {softmax}(W_{\text {status}} H_{\text {final}}) \end{aligned}$$
This framework effectively integrates data from both tasks, improving overall accuracy and efficiency.
Our CNN-BiGRU hybrid architecture, combined with opinion embeddings and BERT, captures both subjective viewpoints and factual information in mental health-related texts. Consequently, we achieve a comprehensive understanding of emotional tone (sentiment) and broader emotional contexts (status). This approach makes our model a robust tool for analyzing text in the domain of mental health.
损失功能
For sentiment and status categorization, the described model uses categorical cross-entropy loss functions, that are subsequently applied to the respective outputs. Each task has an output layer, however, the two loss functions are calculated separately and combined to provide the overall loss.
\(\mathcal {L}_{\text {status}}\)represents the categorical cross-entropy loss for the status classification problem, whereas\(\mathcal {L}_{\text {sentiment}}\)represents the sentiment classification task. The overall loss function is the weighted sum of these individual losses and is represented by the model as\(\mathcal {L}\)。
$$\begin{aligned} \mathcal {L} = \alpha \cdot \mathcal {L}_{\text {status}} + \beta \cdot \mathcal {L}_{\text {sentiment}} \end{对齐} $$
(1)
在哪里:
$$\begin{aligned} \mathcal {L}_{\text {status}}= & - \sum _{i=1}^{C_{\text {status}}} y_{\text {status},i} \log (p_{\text {status},i}) \end{aligned}$$
(2)
$$\begin{aligned} \mathcal {L}_{\text {sentiment}}= & - \sum _{j=1}^{C_{\text {sentiment}}} y_{\text {sentiment},j} \log (p_{\text {sentiment},j}) \end{aligned}$$
(3)
这里:
-
\(y_{\text {status},i}\)is the true label for the status classification, where\(C_{\text {status}}\)is the number of status classes.
-
\(p_{\text {status},i}\)is the predicted probability for the status classification.
-
\(y_{\text {sentiment},j}\)is the true label for sentiment classification, where\(C_{\text {sentiment}}\)denotes the number of sentiment classes.
-
\(p_{\text {sentiment},j}\)is the predicted probability for the sentiment classification.
权重\(\阿尔法\)和\(\beta\)balance the contributions of each loss term to the overall loss function, allowing for tailored optimization based on the importance of each task. These weights can be adjusted to consider task-specific needs or performance. For equal weighting, these weights were typically set to one.
The model minimizes the combined loss\(\mathcal {L}\), which guides the optimization process by balancing errors across both classification tasks to guarantee that it learns to perform well in both status and sentiment predictions.
实验设置
The trials in this study were conducted using a machine with 16GB of RAM and an NVIDIA GeForce RTX 2060 GPU, which provided sufficient processing capability for deep learning model training. The implementation was completed using TensorFlow 2.10.1, a popular deep learning framework that facilitates GPU acceleration for effective training and inference. Python 3.9.19 was used to construct the codebase because it provides a stable environment for integrating different libraries and performing machine learning operations. Fast training iterations and efficient use of computing resources were made possible by this configuration, which guaranteed a stable and consistent platform for testing the proposed Opinion-Enhanced Hybrid BERT Model.
Baseline models
The baseline models used in this study were DistilBERT11, RoBERTa10, and BERT9。These sophisticated models are quite effective at comprehending text.Strong language comprehension was provided by the primary model, BERT.To outperform BERT, RoBERTa requires longer training times and more data.DistilBERT is a useful alternative to BERT, as it is a scaled-down version of the algorithm that operates more quickly without sacrificing much of its accuracy.
-
BERT-base-uncased: A transformer-based model that uses a masked language-modeling objective for pre-training, making it effective for various NLP tasks.
-
罗伯塔: An optimized version of BERT that modifies key hyperparameters, removes the next sentence prediction objective, and trains on larger mini-batches.
-
Distilbert: A smaller, faster, and lighter version of BERT trained using knowledge distillation, providing competitive performance with reduced resource consumption.
Because these models have demonstrated efficacy in natural language processing tasks and consistently deliver high performance across a range of benchmarks, we chose them as baselines. We can evaluate efficiency and accuracy by comparing their different sizes and training approaches, which provide information about the trade-offs associated with model selection.
消融研究
The goal of this ablation study was to evaluate the efficacy of several elements incorporated into the suggested model. We performed this by experimenting with different configurations and evaluating how well they performed in comparison to the entire BERT-CNN-BiGRU model with attention-based opinion embeddings. In the original version, sentiment and status predictions were made using only the BERT encoder, thereby eliminating opinion embeddings. Subsequently, we simply used BERT and opinion embeddings to evaluate the model, not the hybrid CNN-BiGRU architecture, to see how opinion information contributed. We also experimented with the more straightforward hybrid models, BERT-BiGRU and BERT-CNN, to separate the effects of each element. To determine how adding or removing CNN, BiGRU, and opinion embeddings impacted the overall performance, each configuration was examined. The effects of adding or removing the CNN, BiGRU, and opinion embeddings on the overall performance were examined for each configuration. The full BERT-CNN-BiGRU model with attention-based opinion embeddings consistently outperformed all other configurations, according to the results, proving that attention-enhanced opinion integration and local and sequential feature extraction are essential for precise and nuanced mental health analysis.
Hyperparameter settings
Certain hyperparameters were used to fine-tune the suggested Opinion-BERT model. The Adam optimizer was employed with a learning rate of 2e−5 and a batch size of 32. With an embedding dimension of 768, the length of the input sequence is restricted to 100 tokens. The CNN component employed 64 filters with a kernel size of 3, and MaxPooling1D came next. The attention mechanism features four heads. The 64 units of the BiGRU layer were used to record sequential data. The model was trained for 15 epochs with categorical cross-entropy as the loss function, and a dropout rate of 0.3 was used to avoid overfitting. Early halting with four-epoch patience was used to maximize training, and when the validation loss plateaued, the learning rate scheduler modified the learning rate. This setup allowed the model to accurately capture complex sentiments and status patterns in mental health texts.
评估指标
Several assessment measures were used to evaluate how well the suggested Opinion-BERT model classified sentiment and status:
-
准确性: This metric measures the proportion of correct predictions to the total predictions. It is a straightforward indicator of how well the model performs in both sentiment and status classification tasks.
$$\begin{aligned} \text {Accuracy} = \frac{\text {Number of Correct Predictions}}{\text {Total Number of Predictions}} \end{aligned}$$
-
精确: Precision evaluates the accuracy of positive predictions. This is the ratio of true positive predictions to the total predicted positives, providing insight into the ability of the model to avoid false positives.
$$\begin{aligned} \text {Precision} = \frac{\text {True Positives}}{\text {True Positives} + \text {False Positives}} \end{aligned}$$
-
Recall (sensitivity): Recall assesses the model’s capability to correctly identify positive instances. This is the ratio of true positive predictions to the total actual positives, indicating the effectiveness of the model in detecting relevant cases.
$$\begin{aligned} \text {Recall} = \frac{\text {True Positives}}{\text {True Positives} + \text {False Negatives}} \end{aligned}$$
-
F1-score: The F1-Score is the harmonic mean of the Precision and Recall, providing a balanced measure that accounts for both false positives and false negatives. This is particularly useful when dealing with unbalanced datasets.
$$\begin{aligned} \text {F1-Score} = 2 \times \frac{\text {Precision} \times \text {Recall}}{\text {Precision} + \text {Recall}} \end{aligned}$$
-
AUC-ROC (area under the receiver operating characteristic curve): This metric evaluates the model’s ability to distinguish between classes. A higher AUC indicates better performance, reflecting the trade-off between the true positive rate (recall) and the false positive rate.
A thorough assessment of the model’s efficacy in sentiment and status categorization is provided by these metrics combined, enabling a thorough examination of its prediction abilities and dependability while processing intricate text data on mental health.
Results analysis
Baseline comparison
The suggested Opinion BERT model and the baseline models (BERT, RoBERTa, and DistilBERT) are thoroughly compared in Table3for the Status and Sentiment Classification tasks. As can be seen, the proposed model achieved the maximum accuracy, macro precision, recall, and F1-score metrics while continuously outperforming the baselines in both tasks. Opinion BERT outperformed the next best BERT, with an accuracy of 93.74% for Status Classification, compared to 90.98% for BERT. Opinion BERT outperformed BERT in Sentiment Classification, with 96.25% accuracy. Incorporation of attention-based opinion embeddings, which improve the model’s comprehension of complex contextual information, is responsible for the model’s higher performance. Furthermore, a higher F1-score in both tests indicates that Opinion BERT is competent at properly identifying both positive and negative examples, as seen by its more balanced accuracy and recall values. This demonstrates the effect of combining the BERT-CNN-GRU architecture with opinion-aware embeddings.
The confusion matrices for status and sentiment classification tasks across different models are shown in Figs. 4和5, 分别。The effectiveness of BERT, RoBERTa, DistilBERT, and the suggested model in categorizing mental health status into groups including stress, anxiety, depression, and personality disorder are contrasted in Fig.4。Improved prediction accuracy across several categories is demonstrated by the suggested model’s decreased misclassification rates, particularly in more complicated categories like bipolar and suicidal.With a greater count in the diagonal element for the true class, for instance, it more accurately identifies bipolar instances.

Confusion matrices for status classification using different models.

Confusion matrices for sentiment classification using different models.
The confusion matrices for sentiment classification show how well various models distinguish between positive, neutral, and negative attitudes, as shown in Fig.5。Compared with the conventional BERT and RoBERTa models, the suggested model shows improved accuracy in predicting Positive and Neutral classes, lowering the number of cases that are incorrectly categorized.The proposed model exhibits fewer mistakes in differentiating between Positive and Neutral sentiments, which results in improved overall performance metrics.This is especially evident in the accurate classification of positive sentiment.The outcomes demonstrate the effectiveness of the proposed model design, which combines CNN, BiGRU, and sophisticated attention mechanisms to capture subtle linguistic signals essential for mood and status predictions.
The performance of several models across status and sentiment classification tasks are depicted by the ROC curves in Figs.6和7, 分别。These graphs, which plot the True Positive Rate (sensitivity) versus the False Positive Rate at different threshold values, demonstrate the capacity of the models to discriminate between the classes.

AUC-ROC (Area under the receiver operating characteristic curve) for status classification using different models.

AUC-ROC (Area under the receiver operating characteristic curve) for sentiment classification using different models.
A strong discriminative capacity is indicated by the proposed model’s high AUC values across all mental health status categories, as shown in Fig.6。With an AUC of 1.00, the model attained perfect or almost perfect AUC values for categories, such as stress, anxiety, and suicidal thoughts.Interestingly, the suggested model achieves AUC values of 0.98, exceeding RoBERTa and DistilBERT, especially in more complicated categories such as depression and bipolar disorder, which sometimes offer difficulties because of overlapping symptoms.This demonstrates how well the proposed approach can identify minute patterns connected to various mental health issues.
A strong performance in the emotion categorization challenge is also shown in Fig.7。The suggested model regularly outperformed the conventional BERT and RoBERTa models, producing AUC values of 0.99 or higher, across Positive, Neutral, and Negative attitudes.According to this, the architecture that combines CNN and BiGRU layers with sophisticated attention mechanisms is very good at capturing the subtleties of sentiments, which reduces misclassifications and improves overall precision, particularly when separating positive and neutral sentiments.These ROC curves highlight the accuracy and dependability of the proposed model in sentiment and status classification tasks.
Comparison of sentiment lexicons
桌子4highlights the performance comparison of sentiment lexicons-Afinn, VADER, and TextBlob-across status and sentiment classification tasks. TextBlob consistently outperforms the others, achieving the highest test accuracy of 93.74% for status classification and 96.25% for sentiment classification. It also demonstrates superior macro precision, recall, and F1-scores, reaching 94.17%, 94.48%, and 94.32% for status classification, and 96.50%, 96.68%, and 96.58% for sentiment classification. VADER shows strong performance, particularly in sentiment classification, with a test accuracy of 94.12% and an F1-score of 93.68%. Afinn performs reliably, achieving a sentiment classification F1-score of 91.97%. As shown in Table4, TextBlob proves to be the most effective lexicon for sentiment analysis, with VADER and Afinn providing solid alternatives for specific use cases.Table 4 Comparison of different sentiment lexicons.
5
displays the findings of the ablation research, which was conducted to assess how well different models performed on tasks involving the categorization of emotion and status. BERT with opinion embedding, BERT-CNN-BiGRU with attention-based opinion embedding, BERT-BiGRU with opinion embedding, BERT-CNN with opinion embedding, BERT-CNN-BiGRU without opinion embedding, and suggested Opinion BERT with attention-based opinion embedding are among the models that were evaluated. For both classification tasks, each model’s test accuracy, F1-score, recall, and macro precision are displayed.Table 5 Ablation study results for status and sentiment classification.Notably, the suggested Opinion BERT demonstrated its efficacy in capturing subtle semantic links through attention-based opinion embedding, with the highest test accuracy of 93.74% for status classification and 96.25% for sentiment classification. By concentrating on the important elements of the input text, this novel embedding technique improves the model’s comprehension and contextualization of the attitudes conveyed. More accurate predictions are produced by the model’s ability to evaluate the importance of various words or phrases according to their applicability to the attitude under study, owing to the inclusion of attention processes.
Furthermore, the findings show that opinion embedding is important for enhancing performance. Illustration of the significance of integrating domain-specific information, BERT-BiGRU with opinion embedding fared better than versions utilizing conventional embeddings alone, although it had lower accuracy than the suggested model. The BERT-CNN-BiGRU model without opinion embedding, on the other hand, performed the worst, highlighting the need for embedding techniques to increase model efficacy.
Overall, the findings demonstrate how various model architectures and embedding tactics affect performance, highlighting the significance of customized methods in opinion analysis, especially with the inclusion of attention mechanisms in the suggested Opinion BERT.
Prediction analysis
The anticipated and actual sentiment and mental health conditions for many models, including BERT, RoBERTa, DistilBERT, and the suggested Opinion-BERT, are compared in Table
6
。The sentiment and actual mental health state of the input text were compared with each model’s predictions.When the actual state was “Depression,†as in the first example, all models expected the status to be “Suicidal,†but the predicted attitude stayed consistently “Positive.†This shows that certain algorithms have a propensity to correctly detect emotions but misclassify mental health conditions.However, in the same scenario, Opinion-BERT demonstrated an improved capacity to comprehend subtle manifestations of mental health by effectively matching the projected condition with the actual status.
Opinion-BERT continuously performed well in a variety of scenarios according to additional examinations of other entrants. While other models showed differences, particularly in sentiment predictions, the second entry accurately classified the status and sentiment as “Bipolar†and “Positive,†respectively. Opinion-BERT further proved its resilience by maintaining accurate predictions under both neutral and negative circumstances. These findings imply that, in comparison to its competitors, Opinion-BERT’s attention-based opinion embedding may provide a deeper understanding of mental health manifestations and improve classification performance. This table demonstrates how well the suggested model interprets complicated sentiments and mental health states in a variety of textual inputs.
Comparison among and existing work
A comparison of several methods for sentiment analysis and mental health identification across the datasets is presented in Table7。When Kokane et al.42applied NLP transformers such as DistilBERT to social media data, they were able to obtain noteworthy accuracy for Reddit (84%) and Twitter (91%).Chen等。43achieved a 92.35% accuracy rate for hotel reviews by combining BERT with CNN, BiLSTM, and Attention processes to overcome the conventional drawbacks of CNN and RNN. By using a Bi-LSTM architecture for social media data from sites such as Facebook, Instagram, and Twitter, Selva Mary et al.44were able diagnosed with depression, with an astounding 98.5% accuracy rate. Sowbarnigaa et al.45classified depression with a 93% accuracy rate using a CNN-LSTM combination. By using the EmoMent corpus and RoBERTa, Atapattu et al.46concentrated on South Asian settings and obtained F1 values of 0.76 and 0.77 for post-categorization and mental health prediction, respectively. The intricacy of the MAMS dataset was addressed by Wu et al.47work on multi-aspect sentiment analysis using a RoBERTa-TMM ensemble, which demonstrated good F1 scores in both ATSA (85.24%) and ACSA (79.41%). In contrast, our study uses a multi-input neural network called Opinion-BERT, which integrates CNN, BiGRU, Transformer blocks, token embeddings, and attention mechanisms. It achieved an accuracy of 93.74% for classifying mental health status and 96.25% for sentiment analysis. This demonstrates how well our method handles the complex and multidimensional characteristics of mental health literature.
讨论
The proposed Opinion-BERT model has shown great promise for improving mental health analysis through multi-task learning by integrating attention-based opinion embeddings. Understanding both explicit and subtle material in texts pertaining to mental health has been demonstrated to be greatly aided by the combination of opinion-specific data with contextual embeddings of BERT. This integrated method reflects the intricacies of human language, which frequently consists of a combination of ideas, feelings, and factual information that is difficult for standard models to comprehend.
The effect of opinion embeddings on overall model performance is one noteworthy finding. Incorporating subjective signals is crucial because the ablation study makes it evident that adding opinion embeddings improves emotion and status classification tasks. According to these results, opinions are important in mental health analysis since they frequently give emotional states and behavioral inclinations context. To extract sentiment-related information from the text, the Opinions Embedding Layer’s attention mechanism effectively finds the most pertinent passages, which enhances the accuracy and dependability of the model.
Additionally, the hybrid design that included CNN and BiGRU layers worked well. Local patterns and relationships, including phrases and word n-grams, are well captured by the CNN component, but the BiGRU component represents the long-term context and sequential dependencies. In texts on mental health, which may contain subtle tone changes, sarcasm, or complicated emotional states that call for an awareness of both local and global text elements, this combination is particularly helpful.
Furthermore, by utilizing shared information between various tasks, the multi-task learning architecture enabled the model to predict sentiment and status at the same time. This shared learning was beneficial because of its improved generalization and decreased the possibility of overfitting to a single task. The findings support the idea that multi-task learning works well in complicated fields like mental health, where overlapping variables affect different emotional states.
All things considered, the Opinion-BERT model shows promise for enhancing mental health analysis through the use of cutting-edge NLP approaches. A step toward developing more precise and thorough language models for this delicate and important topic has been made with the effective integration of context and subjective perspectives.
Limitation and future work
Despite the encouraging outcomes of the Opinion-BERT model, it is important to recognize several limitations. First, both the quality and representativeness of the training data are critical to the success of the model. Real-world applications may perform less well if the dataset is undiversified or skewed toward particular emotions or mental health issues. While the model’s dependence on attention-based embeddings is advantageous for capturing context, it can also present problems such as overfitting, especially in situations where there is a lack of data. Moreover, there is still uncertainty over the interpretability of the model’s choices. Although the attention mechanism emphasizes significant terms, it might be challenging to comprehend the underlying logic of certain forecasts.
To strengthen the generalizability of the Opinion-BERT model across a range of demographics and circumstances, future research should concentrate on expanding and diversifying its datasets. Further improvements classification accuracy and resilience may include investigating different embedding structures and methodologies, such as adding knowledge graphs or strengthening multi-task learning techniques. Future research could also focus on including explainability tools to provide more precise information on how the model makes decisions. Finally, expanding the Opinion-BERT framework’s scope and fostering a more thorough comprehension of mental health feelings across various settings may be achieved by applying it to other fields, including social media and healthcare.
结论
We introduced the Opinion-BERT model in this study, which effectively integrates attention-based opinion embeddings to classify emotional states and mental health conditions. Through extensive experimentation, including an ablation study, we demonstrated that incorporating opinion-related features significantly enhances the model’s performance. Our results show that Opinion-BERT outperforms baseline models across key evaluation metrics, such as accuracy, precision, recall, and F1-score.
Our findings emphasize the critical role of both emotional and contextual cues in improving the accuracy of machine learning models for mental health analysis. By combining sentiment-specific embeddings with advanced contextual representations from BERT, we lay a strong foundation for future advancements in sentiment analysis and multi-task learning frameworks.
This research opens new avenues for more effective and nuanced mental health evaluations, offering the potential for better understanding and intervention in this important field. Integrating sentiment analysis with mental health assessments not only improves classification accuracy but also contributes to more insightful and adaptable mental health monitoring tools.
In conclusion, the Opinion-BERT model takes a significant step forward in leveraging machine learning for mental health applications, offering a robust framework for future research and practical implementation in the field.
参考
Vigo, D., Thornicroft, G. & Atun, R. Estimating the true global burden of mental illness.Lancet Psychiatr. 3, 171–178 (2016).
文章一个 Google Scholar一个
Ghani, N. A., Hamid, S., Hashem, I. A. T. & Ahmed, E. Social media big data analytics: A survey.计算。哼。行为。 101, 417–428 (2019).
文章一个 数学一个 Google Scholar一个
Kusal, S. et al. A systematic review of applications of natural language processing and future challenges with special emphasis in text-based emotion detection.艺术品。Intell。修订版 56, 15129–15215 (2023).
文章一个 数学一个 Google Scholar一个
Fudholi, D. H. Mental health prediction model on social media data using CNN-BILSTM.在Kinetik: Game technology, information system, computer network, computing, electronics, and control29–44 (2024).
Gratch, J. & Marsella, S. A domain-independent framework for modeling emotion.Cogn。系统。res。 5, 269–306 (2004).
文章一个 数学一个 Google Scholar一个
Suleiman, S. R. & Crosman, I. (eds.)The reader in the text: Essays on audience and interpretation,卷。617 (Princeton University Press, 2014).
Dogra, V. et al. A complete process of text classification system using state-of-the-art NLP models.计算。Intell。Neurosci。 2022, 1883698 (2022).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Acheampong, F. A., Nunoo-Mensah, H. & Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches.艺术品。Intell。修订版 54, 5789–5829 (2021).
文章一个 数学一个 Google Scholar一个
Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding.corrabs/1810.04805(2018)。arXiv:1810.04805。Liu,Y。等。
Roberta: A robustly optimized BERT pretraining approach.corrabs/1907.11692(2019)。arXiv:1907.11692。Sanh, V., Debut, L., Chaumond, J. & Wolf, T. Distilbert, a distilled version of BERT: Smaller, faster, cheaper and lighter (2020).
arXiv:1910.01108。Singh, A. The early detection and diagnosis of mental health status employing NLP-based methods with ml classifiers.J. Mental Health Technol.
12, 45–60 (2024). 数学一个
Google Scholar一个 Inamdar, S., Chapekar, R., Gite, S. & Pradhan, B. Machine learning driven mental stress detection on reddit posts using natural language processing.Hum.-Centric Intell.
系统。3 , 80–91 (2023).文章
一个 Google Scholar一个 Alanazi, S. A. et al. Public’s mental health monitoring via sentimental analysis of financial text using machine learning techniques.int。
J. Environ。res。公共卫生 19, 9695 (2022).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Abd Rahman, R., Omar, K., Noah, S. A. M., Danuri, M. S. N. M. & Al-Garadi, M. A. Application of machine learning methods in mental health detection: A systematic review.IEEE访问 8, 183952–183964 (2020).
文章一个 数学一个 Google Scholar一个
Abdulsalam, A., Alhothali, A. & Al-Ghamdi, S. Detecting suicidality in Arabic tweets using machine learning and deep learning techniques.Arabian J. Sci.工程。1–14 (2024).
Almeqren, M. A., Almuqren, L., Alhayan, F., Cristea, A. I. & Pennington, D. Using deep learning to analyze the psychological effects of COVID-19.正面。Psychol。 14, 962854 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Ameer, I., Arif, M., Sidorov, G., Gómez-Adorno, H. & Gelbukh, A. Mental illness classification on social media texts using deep learning and transfer learning.ARXIV预印本arXiv:2207.01012(2022)。
Su, C., Xu, Z., Pathak, J. & Wang, F. Deep learning in mental health outcome research: A scoping review.翻译。Psychiatr 10, 116 (2020).
文章一个 数学一个 Google Scholar一个
Liu, J. & Su, M. Enhancing mental health condition detection on social media through multi-task learning.medrxiv2024–02 (2024).
Buddhitha, P. & Inkpen, D. Multi-task learning to detect suicide ideation and mental disorders among social media users.正面。res。Metrics Anal. 8, 1152535 (2023).
文章一个 数学一个 Google Scholar一个
Sarkar, S., Alhamadani, A., Alkulaib, L. & Lu, C. T. Predicting depression and anxiety on reddit: a multi-task learning approach.在2022 IEEE/ACM international conference on advances in social networks analysis and mining (ASONAM), 427–435 (IEEE, 2022).
Li, C., Braud, C. & Amblard, M. Multi-task learning for depression detection in dialogs.ARXIV预印本arXiv:2208.10250(2022)。
Plaza-Del-Arco, F. M., Molina-González, M. D., Ureña-López, L. A. & MartÃn-Valdivia, M. T. A multi-task learning approach to hate speech detection leveraging sentiment analysis.IEEE访问 9, 112478–112489 (2021).
文章一个 Google Scholar一个
Jin, N., Wu, J., Ma, X., Yan, K. & Mo, Y. Multi-task learning model based on multi-scale CNN and LSTM for sentiment classification.IEEE访问 8, 77060–77072 (2020).
文章一个 Google Scholar一个
Malik, S. et al. Attention-aware with stacked embedding for sentiment analysis of student feedback through deep learning techniques.PeerJ Comput.科学。 10, e2283 (2024).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Chen, N., Sun, Y. & Yan, Y. Sentiment analysis and research based on two-channel parallel hybrid neural network model with attention mechanism.IET Control Theory Appl. 17, 2259–2267 (2023).
文章一个 数学一个 Google Scholar一个
Tiwari, D. & Nagpal, B. Keaht: A knowledge-enriched attention-based hybrid transformer model for social sentiment analysis.N. Gener.计算。 40, 1165–1202 (2022).
文章一个 数学一个 Google Scholar一个
Huang, F. et al. Attention-emotion-enhanced convolutional lstm for sentiment analysis.IEEE Trans。Neural Netw.学习。系统。 33, 4332–4345 (2021).
文章一个 数学一个 Google Scholar一个
Han, W. & Kando, N. Opinion mining with deep contextualized embeddings.在Proceedings of the 2019 conference of the north american chapter of the association for computational linguistics: student research workshop, 35–42 (2019).
Jebbara, S. & Cimiano, P. Improving opinion-target extraction with character-level word embeddings.ARXIV预印本arXiv:1709.06317(2017)。
Liu, P., Joty, S. & Meng, H. Fine-grained opinion mining with recurrent neural networks and word embeddings.在Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 1433–1443 (2015).
Gudivada, V., Apon, A. & Ding, J. Data quality considerations for big data and machine learning: Going beyond data cleaning and transformations.int。J. Adv。软件。 10, 1–20 (2017).
Vatri, A. & McGillivray, B. Lemmatization for ancient greek: An experimental assessment of the state of the art.J. Greek Linguistics 20, 179–196 (2020).
文章一个 数学一个 Google Scholar一个
Bondugula, R., Udgata, S., Rahman, N. & Sivangi, K. Intelligent analysis of multimedia healthcare data using natural language processing and deep-learning techniques.在Edge-of-things in personalized healthcare support systems, 335–358 (Academic Press, 2022).
Xiang, L., Li, Y., Hao, W., Yang, P. & Shen, X. Reversible natural language watermarking using synonym substitution and arithmetic coding.计算。母校。Continua 55, 541–559.https://doi.org/10.3970/cmc.2018.03510(2018)。
文章一个 数学一个 Google Scholar一个
Michalopoulos, G., McKillop, I., Wong, A. & Chen, H. Lexsubcon: Integrating knowledge from lexical resources into contextual embeddings for lexical substitution.ARXIV预印本arXiv:2107.05132(2021)。
Huang, K., Geller, J., Halper, M., Perl, Y. & Xu, J. Using wordnet synonym substitution to enhance UMLS source integration.艺术品。Intell。医学 46, 97–109 (2009).
文章一个 PubMed一个 Google Scholar一个
Hermansyah, R. & Sarno, R. Sentiment analysis about product and service evaluation of pt telekomunikasi indonesia tbk from tweets using textblob, naive bayes & k-nn method.在2020 international seminar on application for technology of information and communication (iSemantic), 511–516 (IEEE, 2020).
Hilal, A. & Chachoo, M. A. Aspect based opinion mining of online reviews.Gedrag Organisatie Rev. 33, 1185–1199 (2020).
文章一个 数学一个 Google Scholar一个
Meng, Y.等。Text classification using label names only: A language model self-training approach.ARXIV预印本arXiv:2010.07245(2020)。arXiv:2010.07245。Kokane, V., Abhyankar, A., Shrirao, N. & Khadkikar, P. Predicting mental illness (depression) with the help of nlp transformers.
在2024 second international conference on data science and information system (ICDSIS), 1–5 (IEEE, 2024).
Chen, N., Sun, Y. & Yan, Y. Sentiment analysis and research based on two-channel parallel hybrid neural network model with attention mechanism.IET Control Theory Appl. 17, 2259–2267 (2023).
文章一个 数学一个 Google Scholar一个
Selva Mary, G. et al. Enhancing conversational sentimental analysis for psychological depression prediction with BI-LSTM.J. Autonomous Intell.,,,,7(2023)。
Sowbarnigaa, K. S. et al. Leveraging multi-class sentiment analysis on social media text for detecting signs of depression.应用。计算。工程。 2, 1020–1029.https://doi.org/10.54254/2755-2721/2/20220660(2023)。
文章一个 数学一个 Google Scholar一个
Atapattu, T.等。Emoment: An emotion annotated mental health corpus from two south asian countries.ARXIV预印本arXiv:2208.08486(2022)。
Wu, Z., Ying, C., Dai, X., Huang, S. & Chen, J. Transformer-based multi-aspect modeling for multi-aspect multi-sentiment analysis.在Natural Language Processing and Chinese Computing: 9th CCF International Conference, NLPCC 2020, Zhengzhou, China, October 14–18, 2020, Proceedings, Part II, 546–557 (Springer International Publishing, 2020).
致谢
The authors extend their appreciation to the Research Chair of Online Dialogue and Cultural Communication, King Saud University, Riyadh, Saudi Arabia for funding this study.
资金
This research is funded by the Research Chair of Online Dialogue and Cultural Communication, King Saud University, Riyadh, Saudi Arabia.
道德声明
竞争利益
The authors assert that there are no conflicts of interest to disclose.
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Hossain, M.M., Hossain, M.S., Mridha, M.F.
等。Multi task opinion enhanced hybrid BERT model for mental health analysis.Sci代表15 , 3332 (2025). https://doi.org/10.1038/s41598-025-86124-6下载引用
:2024年10月25日
:2025年1月8日
:2025年1月27日
:https://doi.org/10.1038/s41598-025-86124-6关键字