
旨在评估和构建用于医学的多功能大语模型
作者:Xie, Weidi
介绍
大型语言模型(LLMS)最近在各种自然语言处理任务上取得了重大进步,证明了语言翻译,文本生成,对话等方面的显着能力。如Singhal等人所指出的那样,这些发展也扩展到了医疗领域,LLM在医疗保健中获得了高分问题(MCQA)基准,并成功地通过了UMLS检查,在该医学领域中取得了很高的分数。1,,,,2。此外,LLM在采用适当提示策略时显示了临床文本摘要的专家级表现3。
然而,除了这些进步之外,人们对LLM在临床环境中的应用越来越多,这主要是由于它们在基本医学知识中的缺陷。例如,LLM证明对ICD代码的理解不佳4,产生与临床程序相关的预测不正确5,并误解了电子健康记录(EHR)数据6。我们认为,这些两极分化的观点对LLM的功效是源自临床环境中AI部署所需的严格标准。当前的基准测试基准主要关注多项选择问题2,,,,7,,,,8,无法充分反映现实世界中LLM的实际实用性。
为了解决这个差距,我们介绍药物板凳(s for Super),这是一个综合基准,超出了多项选择的问题答案(MCQA),包括11个高级临床任务, 例如临床报告摘要,,,,治疗建议,,,,诊断, 和命名实体识别,,,,等等。该基准为临床医生和研究人员提供了详细的了解LLMS Excel及其在医疗任务中缺乏的位置。具体而言,我们评估了九种医学主流模型:Meditron8,米斯特拉尔9,Internlm 210,骆驼311,Qwen 212,Baichuan 213,Med42-V214,GPT-415和Claude-3.516。我们的发现表明,即使使用少量弹药提示,即使是最先进的LLM,即使在MCQA基准上的高性能与临床实践的实际需求之间的差距也是如此。
为了促进能够解决各种临床任务的开源医疗LLM的开发17,并构建第一个全面的指导调谐数据集,用于医学,药物。它汇总58来自五个文本来源的开源生物医学自然语言处理数据集,包括考试,临床文本,学术论文,医学知识基础和日常对话,导致5M实例,带有19k说明穿过122个临床任务,每个都伴随着手写的任务定义。我们对开源医学语言模型进行了广泛的指导调整,并探索了零射击和少量促进策略。结果是新的医学法学学士学位Mmedins-lalama 3,首次通过指导调整来展示对各种医疗任务的培训的有效性,这使开源医疗LLMS能够超越包括GPT-4和Claude-3.5在内的领先的封闭源模型,并在广泛的临床任务中超越了封闭式LLM。
虽然我们的最终模型主要是学术概念证明,但我们认为药物是朝着改进现实世界中临床应用的医学LLM的第一步,超越了在线聊天或多项选择问题的回答。
结果
在本节中,我们首先介绍药物板凳,我们的研究中采用的基准旨在在对临床应用至关重要的一系列任务中进行全面评估。然后,我们在我们的指令调整数据集上介绍详细统计信息,药物,经过精心策划,以涵盖各种医学语言处理任务。最后,我们提供了对评估结果的深入分析,将领先的主流模型的性能与我们自己的模型进行了比较,Mmedins-lalama 3根据开源语言模型的改编,并根据全面的医学说明进行了微调。
为了确保在随后的讨论和分析中清晰,我们定义了整个研究中使用的关键术语。有关其他示例,请参考Meds-Ins中的详细任务–补充。
-
文本域:指数据的性质或类型,例如临床文本,考试材料,学术论文等。
-
数据源:与描述数据属性的文本域相反,数据源是指数据的特定起源,例如Mimic-IV或PubMed论文。不同的数据源可能属于同一文本域。
-
任务类别:这些表示语言处理任务的广泛类型,例如多项选择的问题回答或指定的实体识别,ETC。同一类别中的任务共享一个共同的目标。
-
任务:这些表示我们的数据收集管道中的基本单元(叶节点),包括诸如提取结果,药物剂量提取,病理摘要等特定任务,ETC。每个任务可以通过数据源,任务类别或文本域的唯一组合来定义。
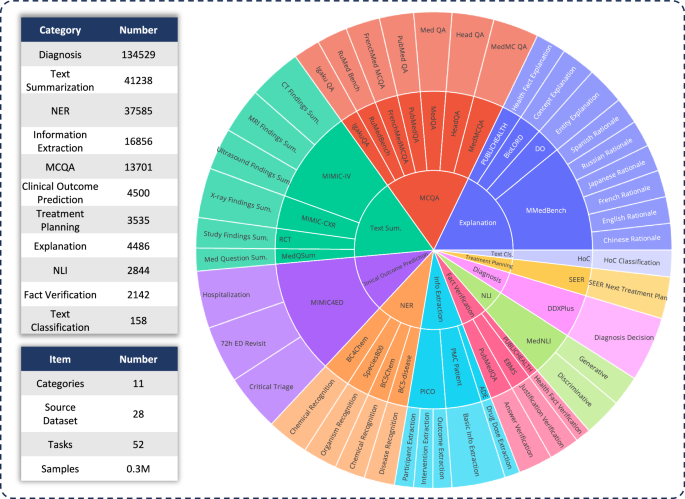
首先,要评估各种LLM在临床应用中的功能,我们开发了药物板凳,这是一个综合的医疗基准,超出了传统的多项选择问题。药物板凳包含11个高级临床任务类别,源自28个现有数据集,如图图所示。1。每个数据集都被重新格式化为指令提出的提问结构,并配有手工制作的任务定义(指令),如图2所示。2一个。我们考虑的任务类别包括:多选择问题答案,文本摘要,信息提取,说明,理由,命名实体识别,诊断,治疗计划,临床结果预测,文本分类,事实验证和自然语言推断。每个类别都提供了更详细的描述。任务类别详细信息–补充。

分层环图在评估基准中精心显示数据分布。第一层将任务类型分类,基准包括11个主要任务类别。第二层概述了所涉及的数据集,其中包括28个数据集。第三层详细介绍了特定任务,基准共同解决了52个不同的任务。总体而言,该基准可以对多个维度的模型性能进行彻底而全面的评估。

一个任务收集管道。对于每个任务,我们为其添加一个任务类别以及手写的定义,从而总共有19个任务类别。b我们收集现有的58个公共数据集。c我们将不同数据集的格式转换为一个统一的医疗指导数据集,药物。d我们收集的最终数据分布药物。SANKEY图显示了不同的文本域(左),任务类别(中间)和数据源(右)如何有助于最终数据集。在底部的左侧,两个饼图分别显示了文本域和任务类别的数据分布。
除了定义这些任务类别外,我们还提供有关令牌数量的详细统计信息,并区分LLMS以解决每个任务的必要能力,如该任务所示。Meds-Ins中的详细任务–补充。以前的工作18,我们根据所需的技能将任务手动分为两类:(i)回顾模型中的事实,以及(ii)从提供的上下文中检索事实。从广义上讲,前者涉及的任务需要访问大规模预训练中模型权重中编码的知识,而后者涉及必须从提供的上下文中提取信息的任务,例如摘要或信息提取。如图所示Meds-Ins中的详细任务–补充,八个任务类别要求该模型从模型中回忆知识,而其余三个则需要从给定上下文中进行事实检索。
然后,我们介绍了建议的指令数据集,药物,从5个不同的文本来源和19个任务类别收集了数据,122个不同的临床任务。统计数据药物总结在图中。2。我们提出的指令调谐数据集由从五个不同的样本组成文本域:考试,临床文本,学术论文,医学知识基础和日常对话,如下:
-
考试:此类别包括来自各个国家的医学检查问题的数据。它涵盖了广泛的医学知识,从基本的医学事实到复杂的临床程序。尽管考试领域是理解和评估医学教育的重要资源,但重要的是要注意,与现实世界中的临床任务相比,考试的高度标准化性质通常会导致过度简化的病例。我们数据集中7%的令牌来自考试。
-
临床文本:这些文本在常规临床实践中产生,支持医院和临床中心内的诊断,治疗和预防过程。此类别包括电子健康记录(EHR),放射学报告,实验结果,后续说明和药物建议等。这些文本对于疾病诊断和患者管理是必不可少的,这对于有效的LLM临床应用至关重要。我们数据集中35%的令牌来自临床文本。值得注意的是,临床文本的显着比例可确保调整数据与临床需求紧密保持一致。
-
学术论文:这些数据来自医学研究论文,涵盖了医学研究领域的最新发现和进步。鉴于他们的可及性和结构化组织,从学术论文中提取数据相对简单。这些案例有助于掌握尖端的医学研究信息,从而指导他们更好地了解当代医学方面的发展。我们数据集中的13%的令牌来自学术论文。
-
医学知识库:该领域包括组织良好且全面的医学知识,包括医学百科全书,知识图和医学术语词汇表。这种数据构成了医学知识基础的骨干,支持医学教育和LLM在临床实践中的应用。我们数据集中有43%的令牌来自医学知识。
-
每日对话:该来源是指医生和患者之间产生的每日咨询,主要来自在线平台和其他互动场景。这些相互作用反映了医疗专业人员与患者之间的现实互动,在了解患者需求并增强医疗服务的整体体验方面发挥了关键作用。我们数据集中有2%的令牌来自日常对话。
除了对原始数据采购的文本域进行分类之外,样本中的样本药物进一步组织为独特的任务类别。我们已经确定了19个任务类别,每个任务类别都代表了我们认为医疗LLM应该拥有的关键能力。通过相应地构建此指令调整数据集和微调模型,我们旨在为LLMS配备解决广泛医疗应用所需的多功能性。
这19个任务类别包括但不限于MEDS基准基准中的11个类别。其他类别包括一系列对于全面的医学语言处理至关重要的语言和分析任务,包括意图识别,翻译,单词关系分类,文本检索,句子组成分析,错误候选人生成,对话, 和文本完成MCQA类别扩展到一般问题回答,其中还包括自由文本回答案例。任务类别的多样性从共同的问题回答和对话到各种下游临床任务,可确保对潜在的医疗应用有全面的了解。每个类别的详细说明在任务类别详细信息–补充。
在介绍了所有提出的数据集后,我们将相应地分析各种任务的不同LLM。对于每种任务类型,我们首先讨论各种现有LLM的性能,然后与我们的最终模型进行比较,Mmedins-lalama 3。此处介绍的所有结果均使用3次提示策略获得(更多的详细信息评估设置 - 部分补充),除了MCQA任务外,我们使用了零拍的提示设置来与以前的研究保持一致7,,,,8,,,,19。由于我们的比较包括GPT-4和Claude 3.5的专有模型,这些模型会产生使用成本,因此我们每个基准测试案例随机采样约1500个测试用例,以管理成本限制。任务描述和特定的采样编号在本节中详细介绍任务类别详细信息在补充。为简单起见,以下所有表和结果分析中省略了百分比(%)。
多语言多项选择提问
在这里,我们介绍了广泛使用的多项选择问题(MCQA)基准的评估结果,如表所示1。我们以前的研究直接合并了一些数字8,,,,13,,,,14,,,,19,,,,20。在这些多项选择提问的数据集上,现有的专有LLM表现出非常高的精度,例如,在MEDQA上,GPT-4可以实现85.8,这几乎可以与人类专家相提并论,而Llama 3也可以通过60.9通过考试。分数。同样,在英语以外的其他语言中,LLMS在Mmedbench上的多项选择准确性也表现出卓越的结果19。结果表明,由于在现有研究中已广泛考虑了多项选择问题,因此可能已针对此类任务进行了专门优化不同的LLM,从而导致高性能。因此,必须建立一个更全面的基准,以进一步将LLM的开发推向临床应用。我们提出的模型Mmedins-lalama 3虽然没有主要针对多项选择问题进行培训,但仍显示出显着的改进,在不同基准的平均准确度中达到了63.9的平均精度,显着超过了GPT-3.5。
文本摘要
如表所示2,据报道,文本摘要的性能为“ bleu/rouge分数,在各种方式上的多种报告类型上,包括X射线,CT,MRI,超声和其他医学问题。在这些型号中,封闭源LLM(例如GPT-4和Claude-3.5)的性能优于所有开源元素,平均达到24.46/25.66和26.29/27.36。在开源模型中,Mistral取得了最佳效果,BLEU/Rouge得分为24.48/24.90。Llama 3紧随其后,得分为22.20/23.08。我们的模型(Mmedins-llama 3),接受了针对医学特定指令数据集的培训(药物),明显胜过其他人,达到46.82/48.38的平均得分。
信息提取
信息提取的性能总结在表中3。Interlm 2在此任务中表现出异常良好的表现,平均得分为79.11。例如,在PICO任务中,Interlm 2在干预和结果提取方面都引导,得分分别为74.42和69.77。诸如GPT-4和Claude-3.5之类的封闭源模型的表现分别均优于所有其他开源对应物,平均得分分别为76.92和79.41。对单个基准组件的分析表明,与更专业的医学数据(如结果和干预措施)相比,大多数LLM在提取较少的医学复杂信息(例如基本患者详细信息)方面的表现更好。例如,在从PMC患者中提取基本信息时,大多数LLMS得分高于90,Claude-3.5的得分最高99.07。相反,PICO内的临床结果提取任务的性能相对较差。我们提出的模型Mmedins-lalama 3展示了最佳的总体表现,平均得分为83.77,超过了Interlm 2,得到4.66分。值得注意的是,在PICO任务中,Mmedins-lalama 3在参与者提取中出色,得分为83.72,超过第二好的模型,得出11.63分。
概念解释
我们对医学概念解释进行评估,并在所有相关数据集和模型中报告了BLEU-1和Rouge-1分数。在表中4,我们评估了有关医学概念解释的模型,GPT-4在这项任务上表现良好,平均得分为19.37/21.58。相比之下,Meditron和Qwen 2的得分相对较低,平均值为8.51/18.90和9.20/12.67。我们假设Meditron的表现较低可能是由于其培训语料库的主要侧重于学术论文和准则,从而使其在解释基本医学概念方面的有效性降低。同样,Qwen 2的表现似乎受到对医学术语的熟悉程度的限制。尽管QWEN 2在健康事实解释任务上的表现更好,而该任务的特定于领域,但其性能在更专业的任务上大大降低,例如实体解释和Biolord概念解释,其中需要模型来解释医学术语。我们的最终模型MMedins-Lalama 3极大地胜过所有概念解释任务中的其他模型,尤其是在健康事实解释(30.50/28.53)和Biolord概念解释(38.12/43.90)中,并实现34.43/37.47的最高平均分数。在Mmedins-lalama 3之后,GPT-4也表现出强劲的表现,GPT-4得分为19.37/21.58。
答案解释(理由)
在表中5,我们评估了复杂的理由,IE。解释答案并使用Mmedbench19跨六种语言的数据集。在测试的模型中,封闭源模型Claude-3.5表现出最强的性能,平均得分为46.26/36.97,在所有语言中,尤其是法语和西班牙语的分数始终如一。这种卓越的性能可能归因于该任务与经过思考链推理的相似性,这在许多通用LLM中都得到了专门增强的能力。在开源模型中,Mistral和Interlm 2表现出可比的性能,平均得分分别为38.14/32.28和35.65/32.04。重要的是要注意,GPT-4被排除在此评估之外,因为MMEDBENCH数据集的理由组成部分主要是使用GPT-4输出构建的,这可能引入偏见并带来不公平的比较。与我们在概念解释中的观察结果一致的是,我们的最终模型Mmedins-llama 3,在所有语言中,平均BLEU-1/Rouge-1得分为46.90/34.54,在所有语言中,尤其是在日本的推理任务中达到51.74/35.19,英文49.08/38.19和46.93/38.73的法语。这种卓越的表现可能是由于我们的基本语言模型(Mmed-llama 3)最初是由多语言发展的19。因此,即使我们的指令调整并未明确针对多语言数据,但最终模型在多种语言上都优于其他模型。表5基本原理的结果,如“ Bleu/Rouge分数”报道
如表所示
6,在这些模型中,GPT-4是唯一一个始终在命名实体识别(NER)任务中表现出稳健性能的人,其平均F1分数为59.52。它特别在BC5CHEM化学识别任务中表现出色,得分为67.62。Interlm 2显示了所有开源车型中最佳性能,平均F1得分为45.69。QWEN 2和MED42-V2也显示出坚实的性能,平均值分别为35.55和24.73。Llama 3和Mistral,平均F1得分分别为23.62和16.53,表现出适度的性能。未针对NER任务进行优化的Meditron在该领域显示有限的有效性。我们的模型,Mmedins-lalama 3,明显优于所有其他模型,达到79.29的平均F1得分。它在BC4CHEM和BC5CHEM化学识别任务中表现出色,F1得分分别为90.78和91.25。此外,Mmedins-llama 3在BC5Disease疾病识别任务中领先,F1分数为54.26,在80.87的物种800有机体识别任务中,表明在处理各种生物医学领域的复杂NER任务方面具有出色的能力。
诊断,治疗计划和临床结果预测
我们使用DDXPLUS基准进行诊断,治疗计划的SEER基准以及模拟于临床结果预测的模拟基准,评估涉及诊断,治疗计划和临床结果预测的任务的绩效。结果显示在表中7,以准确性来衡量。在这里,在此生成预测问题中使用准确性作为度量是适当的,因为这些数据集将原始问题简化为封闭式选择。具体而言,DDXPLU使用了预定义的疾病列表,该疾病必须根据提供的患者上下文选择一种疾病。在SEER中,治疗建议分为八个高级类别,而在MIMIC4ED中,最终的临床结果决策是二进制的,具有对还是错误。总体而言,这些任务中的开源LLM表现不佳。在SEER治疗计划任务中,Interlm 2和Meditron在开源模型中的准确度分别为62.33和68.27,但这仍然远离GPT-4的84.73和Claude-3.5â€S 92.93。对于DDXPLUS诊断任务,开源表现出相似的,相对较低的分数,左右35.00左右,甚至医学特异性模型(如Meditron和Med42-V2)的性能差。这可能是由于任务的复杂性,这与多项选择质量质量质量检查明显不同,并且模型缺乏专业培训。值得注意的是,在临床结果预测中,Baichuan 2和Llama 3都在努力预测关键分类和72小时ED重新审视二进制指标,未能提供有意义的预测。这可能是因为任务在于他们的训练分配,并且模型通常无法遵循提供的三弹性格式,从而导致得分极低。诸如GPT-4和Claude-3.5之类的封闭式模型表现出明显更好的性能。例如,Claude-3.5在治疗计划中取得了92.93的精度得分,而GPT-4达到84.73。它们还表现出更好的诊断性能,突出了开源和封闭源LLM之间的巨大差距。尽管有这些结果,但得分仍然不足以用于可靠的临床使用。相比之下,Mmedins-lalama 3在临床决策支持任务中表现出卓越的准确性,治疗计划的精度为97.47,诊断97.53,平均准确性为63.35(平均住院评分,72h ED Revisit和关键的分类)在临床结果预测中。
文本分类
在表中7,我们介绍了有关癌症(HOC)多标签分类任务的评估,并报告宏观精确,宏观回报和宏F1分数。对于此任务,所有候选标签都作为列表输入到语言模型中,并要求该模型选择其首选答案,以进行多个选择。然后根据这些模型选择来计算指标。GPT-4和Claude-3.5在这项任务上表现良好,GPT-4的宏F1分数为68.06,Claude-3.5在66.74时稍差。这两种模型均显示出强大的召回功能,尤其是GPT-4,该功能达到了80.23的宏观回调,强调了其在识别相关标签方面的熟练程度。在开源型号Med42-V2中,经过全面监督的微调和偏好优化的最新医学LLM在开源模型中表现良好,达到了47.87的宏F1分数。Llama 3和Qwen 2显示中等性能,宏F1分别为38.37和40.29。这些模型,尤其是Interlm 2,表现出很高的回忆,但精确地挣扎,导致F1得分较低。Baichuan和Meditron在这项任务中排名最低,宏F1分别为23.76和23.70。我们的Mmedins-lalama 3显然,所有其他型号都超过了所有其他模型,在所有指标中取得了最高的分数,宏观精神为89.59,宏观回报为85.58,宏F1分数为86.66。这些结果突出了Mmedins-llama 3的卓越能力,可以准确地对多个标签进行分类和回忆,从而使其成为这一复杂任务的最有效模型。
事实验证
在表中8,我们在事实验证任务上评估模型。对于PubMedQA答案验证和HealthFact验证,LLM需要从提供的候选人列表中选择一个答案,而精确度则是评估度量。相反,对于EBMS的理由验证,任务涉及生成自由形式文本,使用BLEU和Rouge分数评估性能。Interlm 2以99.23的得分达到了PubMedQA答案验证的最高精度。在Publichealth上,Med42-V2达到79.54,这是所有开源车型中最好的,仅次于GPT-4的78.60。在EBMS基准测试中,Llama 3和GPT-4显示出可比的性能,平均BLEU/Rouge得分为16.52/16.49和16.28/16.27。Mmedins-lalama 3继续超过现有模型,达到Interlm 2的最高精度得分,在EMBS中,在PubMedQA答案验证和HealthFact验证方面表现出色,Mmedins-llama 3略微落后于GPT-4和Llama 3,在Bleu和Rouge中,在Bleu和Rouge,When When When Wurn and Llama 3落后于12.71/14.65我们将其视为未来的工作,以进一步改进。
自然推论(NLI)
桌子8使用MEDNLI文本Intailment数据集对医学自然语言推断(NLI)的评估进行了评估。结果的准确性(从候选人列表中选择正确的答案)和生成任务(生成自由形式的文本答案)的准确度(从候选人列表中选择正确的答案)。Interlm 2在开源LLM中取得了最高的分数,得分为84.67。对于闭合源LLM,GPT-4和Claude-3.5的得分均分别为86.63和82.14精度得分。QWEN 2和MED42-V2在生成任务中,在开源LLM中还显示了第二好的表现,在生成任务中,Llama 3表明了与参考地面真相的最高一致性,在BLEU中获得了21.31的得分和22.75的ROUGE,对于22.75开源型号。同样,GPT-4在生成任务格式中也表现良好,导致27.09/23.71分数,而Claude-3.5在此任务中并不理想。Mmedins-lalama 3在判别任务中达到了最高的精度,得分为86.71,与GPT-4相当。Mmedins-llama 3在生成任务中也表现出色,BLEU/Rouge得分为23.52/25.17,除了GPT-4以外的其他模型。
运行时间分析
除了任务性能外,我们还比较了不同模型的推理成本。结果显示在运行时间分析 - 部分补充。通常,各种LLM系列(例如Mistral vs. Llama 3)之间的运行时间差异并不显着。因此,在实际的临床应用中,我们认为临床医生需要考虑的主要事实。
讨论
总体而言,本文做出了一些关键贡献:
首先,我们构建了一个全面的评估基准-Meds Bench。The development of medical LLMs has largely relied on benchmarks focused on multiple-choice question answering (MCQA).However, this narrow evaluation framework risks overlooking the broader capabilities required for LLMs in various clinical scenarios.In this work, we introduceMedS-Bench, a comprehensive benchmark designed to assess the performance of both closed-source and open-source LLMs across diverse clinical tasks, including those that require fact recall from the model or reasoning from given context. Our results reveal that while existing LLMs perform exceptionally well on MCQA benchmarks, they struggle to align with the actual clinical practice, particularly in tasks such as treatment planning and explanation. This finding underscores the need for further efforts to develop medical LLMs that are better suited to a wider range of clinical and medical scenarios beyond MCQA.Secondly, we introduce a new comprehensive instruction tuning dataset - MedS-Ins. We have developed
MedS-Ins, a novel medical instruction tuning dataset, by extensively sourcing data from existing BioNLP datasets and converting these samples into a unified format, with semi-automated prompting strategies. Previous efforts have focused primarily on constructing question-answer pairs from daily conversations, exams, or academic papers, often neglecting the texts generated from real clinical practice. In contrast, MedS-Ins integrates a broader range of medical text sources, encompassing five primary text domains and 19 task categories, as illustrated in Fig.2d。This systematic analysis on data composition is crucial for aligning LLMs with the diverse queries encountered in clinical practice.
Thirdly, we present a strong large language model for medicine - MMedIns-Llama 3. On the model front, we demonstrate that by conducting instruction tuning onMedS-Ins, we can significantly enhance the alignment of open-source medical LLMs with clinical demands. Our final model,MMedIns-Llama 3, serves as a proof-of-concept, featuring a medium-scale architecture with 8 billion parameters, has exhibited a deep understanding of various clinical tasks and adapts flexibly to multiple medical scenarios through zero-shot or few-shot instruction prompts, without the need for further task-specific training. As evidenced by the results, our model outperforms existing LLMs, including GPT-4, Claude-3.5, across a range of medical benchmarks, covering different text sources.
Lastly, we need highlight the limitations of our paper and the potential improvements in future work.
第一的,,,,MedS-Benchcurrently covers only 11 clinical tasks, which does not fully encompass the complexity of all clinical scenarios. Additionally, while we evaluated nine mainstream LLMs, some models remain absent from our analysis. To address these limitations, we plan to release an open leaderboard for medical LLMs alongside this paper. This initiative aims to encourage contributions from the community to continually expand and refine comprehensive benchmarks for medical LLMs. Specifically, this will involve updating the test set to better reflect real clinical demands and include a broader range of medical LLMs. By incorporating more task categories from diverse text sources into the evaluation process, we hope to gain a deeper understanding of the ongoing advancements in LLMs within the medical field.
第二, 虽然MedS-Insnow encompasses the widest range of medical tasks available, it remains incomplete, and certain practical medical scenarios may be missing. To address this, we have made all our collected data and resources available as open-source on GitHub. We encourage contributions from the broader AI4medicine community to help maintain and dynamically expand this instruction tuning dataset, similar to efforts for Super-NaturalInstructions in the general domain21。Detailed guidelines are provided on our GitHub page, and we will acknowledge every contributor involved in updating the dataset.The current limited number of tasks may explain why we have not yet observed the models exhibiting emergent abilities to generalize to unseen clinical tasks, a capability seen in LLMs trained on thousands of diverse tasks in the general domain17,,,,22。
第三, we plan to incorporate more languages intoMedS-Bench和MedS-Insto support the development of more robust multilingual LLMs for medicine. Multilingual language models have seen substantial development in general domains, evidenced by advancements in models23,,,,24,,,,25, training datasets26,,,,27, and evaluation benchmarks28,,,,29,,,,30。Despite this, the multilingual capabilities of biomedical language models, particularly those dealing with diverse healthcare data from various regions, remain underexplored.Recent efforts, such as BioMistral31, Apollo32, and MMedLM19, have begun to address this gap by developing multilingual medical large language models (LLMs). However, their evaluation or instruction tuning progress still mainly focuses on multiple-choice question-answering formats. This may be attributed to the lack of well-established, comprehensive benchmarks or a task-wise taxonomy in the medical field, even in English, which complicates the creation of multilingual evaluation benchmarks via translate-and-filter strategies31。Thus, our MedS-Bench and MedS-Ins, although currently primarily in English, can offer an exemplary taxonomy-wise framework for expansion into multilingual contexts.Expanding to include a broader range of languages would be a promising future direction, ensuring that the latest advancements in healthcare AI can benefit a wider and more diverse range of regions equitably.We leave this as a crucial potential future direction.For now, we just combine a few existing multilingual benchmarks, for example, multiple-choice question-answering, and translation.
提, our model has not yet undergone extensive clinical validation. We aim to collaborate with the community to develop higher-quality instruction-tuning datasets that can better reflect real clinical needs. Furthermore, we are considering to further align the model safety with human preference. With these refinements, we plan to conduct clinical validation in real-world deployments to assess its practical effectiveness in future work. Beyond the model performance, more importantly, we have to emphasize that while our benchmark is more comprehensive and clinically relevant than previous MCQA benchmarks, it cannot replace the final stage of evaluating LLMs in actual clinical settings to ensure their safety. Instead, our benchmark is expected to serve as an experimental arena for assessing the performance of different LLMs, offering a more accurate reflection of their clinical capabilities, and serving as a crucial preliminary step before costly real-world evaluations, thus significantly reducing the expenses associated with assessing a model’s true clinical effectiveness.
最后, all our code, data, and evaluation pipelines are open-sourced. We hope this work will inspire the medical LLM community to focus more on aligning these models with real-world clinical applications.
方法
In this section, we will first describe thedata constructing procedure为了MedS-Ins, as shown in Fig.3一个。In order to organize the different tasks, we assign a domain tag and category tag to each task, the former denotes the domain covered by the instructions, while the category tag denotes the applicable task.We start by filtering the medical-related sentence in natural instruction datasets, followed by prompting specific BioNLP into free-text response formats.

一个The data collection pipeline. We mainly collect data by filtering natural instructions and prompting well-organized BioNLP datasets.bThe training and evaluation pipeline for our model leveraging the collected MedS-Ins. We leverage the instruction tuning training method to combine different datasets and evaluate the final model on multiple benchmarks comprehensively. The icons in the figure are from Microsoft free icon basis.Filtering Natural Instructions
We start by filtering medical-related tasks from the 1616 tasks collected in Super-NaturalInstructions
21。As this work focuses more on different natural language processing tasks in general-purpose domains, the granularity of classification is relatively coarse for the medical domain.We first extract all the instructions in “Healthcare†and “Medicine†categories, subsequently, we manually added more detailed granularity to the domain labels for them, while the task category remains unchanged.
In addition, we found that many of the organized instruction fine-tuning datasets in the generic domain also cover some healthcare-related data, such as LIMA33and ShareGPT34。To filter out the medical part of these data, we used InsTag35to classify the domain of each instruction at a coarse granularity. Specifically, InsTag is an LLM, specialized for tagging different instruction samples. Given an instruction query, it will analyze which domain and task it belongs to. Finally, by filtering instruction datasets in the general domain, we collect 37 tasks, for a total of 75373 samples.
Prompting Existing BioNLP Datasets
In the literature, there exist many excellent datasets on text analysis in clinical scenarios. However, as most datasets are collected for different purposes, like classification or text completion, they can not be directly used for training large language models. Here, we convert these existing former medical NLP tasks into a format that can be used for training generative models, naturally adding them into instruction tuning.
Specifically, we use MIMIC-IV-Note as an example, which provides high-quality structured reports with both findings and impressions, they are used as a proxy task for text summarization, where impressions act as an abstract summary of the findings. We first manually write prompts to define the task, for example,“Given the detailed finding of Ultrasound imaging diagnostics, summarize the note’s conclusion in a few words.â€。Considering the diversity for instruction tuning, we ask 5 individuals to independently describe a certain task with 3 different prompts.This results in 15 free-text prompts for each task, with similar semantic meanings but as varied as possible in wording and format.Then, inspired by the Self-Instruct36, we use these manually written instructions as seed prompts and asked GPT-415to rewrite more task instructions based on the following prompt:
Rewrite the following instruction definition directly. You can change the wording, but keep the meaning the same. Output the rewritten definition directly without any additional information.
Finally, for each task, we will describe it with 7 key elements as shown at the bottom of Fig.3一个,IE。,,{“Categoriesâ€, “Domains†“Definitionsâ€, “Input Languageâ€, “Output Languageâ€, “Instruction Language†and “Instancesâ€}, where “Definition†consists of the manually written or GPT-4 enhanced instruction to describe the tasks, “Input Languageâ€, “Output Languageâ€, and “Instruction Language†respectively describe the languages, such as English or Chinese, used in the corresponding components of a specific instance of this task. “Categories†and “Domains†describe what text domains and categories the task belongs to. Finally, in “Instancesâ€, different training or evaluation instances with Input and Output contents are stored.
Through the above procedure, we prompt an extra 85 tasks into a unified free-form question-answering format, combined with the filtered data, resulting in a totaling 5M instances with 19K instructions, covering 122 tasks, termed asMedS-Ins(the detailed 122 task information can be found in the “Detailed Tasks in MedS-Ins†section of the补充, which has shown to significantly improve the LLMs on clinical tasks.
After preparing the related data, we will further detail thetraining procedure, as shown in Fig.3b。We take the same approach as our previous work7,,,,19, which have shown that further auto-regressive training on medical-elated corpus can inject medical knowledge into the models, thus allowing them to perform better in different downstream tasks. We start from a multilingual LLMs base model (MMed-Llama 319), and further train it with comprehensive instructions fromMedS-Ins。
指令调整
Given the base model, trained on a large-scale medical corpus with auto-regressive prediction, we further fine-tune it to better follow human instructions or prompts. Considering an input sequence with an instruction我and a contextc, and an output sequenceo, the model is trained to maximize the probability:
$$P(O| C,I)=\mathop{\prod }\limits_{t=1}^{|O |}P({o}_{t}| {o}_{1},{o}_{2},\ldots ,{o}_{t-1},C,I;\theta )$$
(1)
Similarly, the loss function used in instruction tuning is cross-entropy loss and can be calculated as follows:
$${\rm{Loss}}=-\mathop{\sum }\limits_{t=1}^{|O |}\log P({o}_{t}| {o}_{1},{o}_{2},\ldots ,{o}_{t-1},C,I;\theta )$$
(2)
The key insight here is to construct diverse instructions, that enables the model to robustly output the preferred answers. Here, we mainly consider two types of instructions, namely, zero-shot and few-shot prompting:
-
Zero-shot Prompting。在这里,我contains some semantic task descriptions as hints, and the model is therefore asked to directly answer the questions based on its internal model knowledge. In our collectedMedS-Ins, the “Definition†contents for each task can be naturally used as the zero-shot instruction input. Due to the coverage of a wide range of different medical task definitions, the model is expected to learn the semantic understanding of various task descriptions. The input template is as follows:
-
{操作说明}
-
Input: {INPUT}
-
-
Few-shot Prompting。在这里,我contains the few-shot examples, that allow the model to learn the input-output mapping on the fly. We simply obtain such instructions by randomly sampling other cases from the training set of the same task, and organizing them using a straightforward template as follows:
-
Case1: Input: {CASE1_INPUT}, Output: {CASE1_OUTPUT}
-
…
-
CaseN: Input: {CASEN_INPUT}, Output: {CASEN_OUTPUT}
-
{操作说明}
-
Please learn from the few-shot cases to see what content you have to output.
-
Input: {INPUT}
Notably, considering some extremely long context clinical tasks the few-shot examples may exceed the max length of the context window. In this case, we adopt basic left-truncation to prioritize the last part of the case-related content or output format part in the few-shot examples.
-
实施详细信息
We conduct all our experiments usingPytorchframework and变压器python package. Specifically, we set the maximum length to 2048, and pad the sequence to the longest case with padding tokens in a batch. We employ the Fully Sharded Data Parallel (FSDP) implemented withTransformers.trainerfunction to save the memory cost per GPU. We also adopt BF16 as default training precision and gradient checkpointing37techniques to optimize memory usage. We use a global batch size of 128 and a learning rate of 1e-5. We choose the medical-knowledge-enhanced model MMed-Llama 3 in our previous work as the foundation model. We further train the model by supervised fine-tuning on Meds-Ins for 5 Epoch with 32 Ascend910B for 383.5 hours.
At last, we will talk about our评估细节。First, we provide details for the baseline large language models (LLMs).Note that, we evaluate all models in few-shot settings, as we observe that open-source models struggle to complete zero-shot evaluation.具体来说,三example cases are given to the model, the detailed prompting strategy and model versions can be found in the “评估设置†section in补充。
The first category includes the powerful closed-source LLMs, known for their robust performance in the general domain. We evaluate these models on various medical-specific tasks:
-
GPT-415, developed by OpenAI, stands for one of the most sophisticated LLMs to date. It is renowned for its strong capabilities in language processing in general domains, including medical applications.
-
Claude-3.516, developed by Anthropic, is a frontier AI language model designed to be secure, trustworthy, and reliable. It exhibits advanced reasoning capabilities that enable it to perform complex cognitive tasks effectively. We adopt the Claude-3.5-Sonnet for comparison, which is claimed as the best model among the Claude family.
The second category comprises the mainstream open-source LLMs:
-
骆驼311, developed by Meta AI, is one of the most notable open-source LLMs globally. As part of the LLaMA series, it is designed for high performance in natural language processing tasks, with enhancements over its predecessors in accuracy and contextual understanding. In this study, considering our model is an 8B scale LLM, for fair comparison, we adopt its 8B version as well.
-
Mistral9, developed by Mistral AI, is an innovative open-source LLM that claims superiority over Llama 2 13B across all evaluated benchmarks. For a fair comparison against other LLMs, we consider its 7B version.
-
Internlm 210, developed by Shanghai AI Laboratory, stands out as a leading open-source multilingual LLM, showcasing exceptional performance, particularly in English and Chinese. In this paper We adopt the 7B version of Internlm 2.
-
QWEN 212, developed by Alibaba, is a series of advanced large language and multi-modal models, ranging from 0.5 to 72 billion parameters, designed for high performance in a variety of tasks. In this paper we adopt the 7B version.
-
Baichuan 213is a series of large-scale multilingual language models with 7 billion and 13 billion parameters, trained from scratch on 2.6 trillion tokens. Baichuan 2 excels particularly in specialized domains such as medicine and law. Here, we adopt the 7B version.
The third category of models we choose is the open-sourced medical LLMs, which have been further trained on medical data.
-
MEDITRON8is a large-scale medical LLM, further pre-trained on Llama 2. It leverages 21.1M medical papers, guidelines for further pre-training, and supervised finetuning on different MCQA datasets with context and chain-of-thought prompt styles. Similarly, we consider its 7B version.
-
Med42-v214is a suite of clinical LLMs built on the Llama 3 architecture and fine-tuned with specialized clinical data. These models are designed to address the limitations of generic LLMs in healthcare settings by effectively responding to clinical queries, which typical models avoid due to safety concerns. Similarly, we consider its 8B version.
Then, we delineate the metrics employed across various tasks and categories within our evaluation benchmark.
准确性
For tasks requiring the model to select a single correct answer from multiple choices, we employ ‘accuracy’ as a direct metric. This metric is applied to tasksMedQA, MedMCQA, and MMedBenchin Multilingual Multiple-choice Question-answering;participant, intervention, and outcome extraction in PICO, drug dose extraction in ADE, and patient information extraction in PMC-patientfor Information Extraction. It is also used inSEERfor Treatment Planning,DDXPlusfor Diagnosis,MIMIC4EDfor Clinical Outcome Prediction,PubMedQA and PUBLICHEALTH Verificationfor Fact Verification, as well asMedNLI textual entailment discriminative tasksfor NLI.
Precision, Recall, F1 Score
For tasks where the model is required to select multiple correct answers, we utilize Precision, Recall, and the F1 Score. These metrics are relevant forBC4Chem and BC5Chem for chemical recognition, BC5Disease for disease recognition, Species800 for organism recognitionin Named Entity Recognition (NER), andHoCin Classification.
BLEU, ROUGE
For tasks necessitating the generation of free-form text, which are inherently more challenging to evaluate, we utilize BLEU and ROUGE metrics to assess the similarity between the generated text and the ground truth. Specifically, we use BLEU-1 and ROUGE-1 by default if no other statements in this paper. These tasks includeMedQSum, RCT-Text, MIMIC-CXR, MIMIC-IVfor Text Summarization;EBMSfor Fact Verification;PUBLICHEALTH Explanation, Do, BioLORD and MMedBenchfor Concept Explanation / Rationale;以及generative tasks in textual entailment in MedNLIfor NLI.