
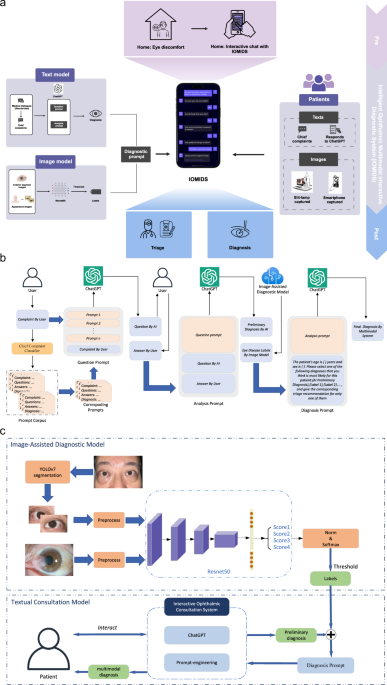
多模式的机器学习使AI聊天机器人诊断眼科疾病并提供高质量的医疗反应
作者:Zhao, Chen
在医疗领域,健康数据本质上是多模式的,包括物理测量和自然语言叙事1。眼科是一项严重依赖多模式信息的学科,需要详细的患者历史和视觉检查2。因此,多模式的机器学习对于眼科医学诊断越来越重要。先前关于眼科诊断模型的研究突显了图像识别AI在自动化任务中的巨大潜力,该任务需要临床专家3。最近,基于聊天机器人的多模式生成AI已成为促进精确健康的有前途的途径,从成像和文本角度整合了健康数据。但是,通常使用GPT-4V和Google的VLM等公共模型,同时证明了某些诊断能力,目前被认为是在眼科中的临床决策不足4,,,,5。此外,这些当前模型尚未实现通过自然语言人类计算机相互作用积极收集患者历史的能力,也可以准确解释使用非专家眼科设备(例如智能手机)获得的图像。克服多模式AI中的这些挑战至关重要,可以为家庭环境中的眼科条件的自我诊断铺平道路,从而产生了可观的社会经济益处6。因此,既需要进一步开发多模式AI模型来诊断和分类眼科疾病。
在通过人类互动来收集医学历史的领域中,引入迅速工程的一种简化,数据和参数有效的技术,用于使大型语言模型与复杂的病史询问的复杂需求相结合,这是一个重大的进步7。在扩大这项创新方面,我们提出了一个交互式眼科咨询系统,该系统利用AI聊天机器人强大的文本分析功能自主根据其主要投诉进行了对患者病史的询问。虽然先前的研究并未直接利用聊天机器人来收集眼科医学历史,但证据表明,当前的AI聊天机器人可以对眼科查询提供精确而详细的答复,例如与视网膜相关的多项选择问题,与近视相关的开放式问题,以及有关近视相关的开放式问题以及有关的问题紧急分类8,,,,9,,,,10。此外,这些聊天机器人在提供高质量的自然语言对医学询问的反应方面表现出色,通常比人类医生表现出更大的同理心11。因此,我们建议该系统应能够根据患者的反应来制定全面的诊断和量身定制的建议。先前关于语言模型的研究的重大缺点是它们依赖于研究人员创建的模拟患者历史或观点,这些历史或研究人员在现实世界中缺乏验证大型临床环境。这种限制使这些模型的实际应用和自动部署功能提出了不确定性。因此,必须在真实的临床环境中开发和验证一种体现的对话剂,患者本身会贡献数据。
关于眼科成像,先前的研究主要集中在缝隙灯泡照片上,从而产生了令人鼓舞的结果。例如,已经开发了一种新型的端到端完全卷积网络,用于使用角膜照片诊断感染性角膜炎12。最近,对智能手机视频的探索显示了它们在诊断儿科眼病的有效性,有可能帮助识别儿童视觉障碍的护理人员13。使用智能手机获得照片的算法也已证明在测量前部的深度方面很有价值,这对于筛选初级角度闭合青光眼特别有用14。这些研究共同强调了狭缝照片和智能手机获得图像的实用性,以应对眼科诊断的各种挑战。但是,以前的AI成像和多模式研究的显着局限性是它们对单疾病的关注狭窄。这些管道通常在其域内独立运行,缺乏在不同领域的集成以增强整体功能15。例如,应用专为疱疹带状疱疹眼镜的模型分类,使白内障患者产生无关的输出16。此外,依赖单一疾病类型增加了由于频谱偏向疾病危害差异而导致模型普遍性差的风险17。对于基于家庭的自我诊断和自我评价,这种局限性尤其有问题。为了应对这些挑战,最近开发和评估了一种针对眼科分类的新型机器学习系统,使用955名患者的数据在95个条件下使用18。因此,能够诊断和分三叶多种眼科疾病的多模式AI对于改善各种人群的护理至关重要。
基于上述环境,我们的研究旨在开发智能的眼科多模式诊断系统(IOMIDS),这是一种与AI Chatbot Chatgpt集成的体现的对话代理。该系统设计用于使用狭缝或智能手机捕获的眼睛图像的多模式诊断和分类,以及病史。临床评估将在三个中心进行,重点是对50种普遍的眼科条件进行全面研究。主要目的是评估诊断有效性,第二个侧重于10个眼科的分类性能。我们的研究旨在探讨AI在复杂的临床环境中的应用,不仅将研究人员的数据贡献纳入了患者的直接,从而模拟了现实世界中的情况,以确保AI技术在眼科护理中的实用性。
结果
研究和数据集的概述
我们在三个中心进行了这项研究,收集了9825名受试者(4554名男性,5271名女性)的15640个数据条目,以开发和评估IOMIDS系统(图。1a)。其中,有6551个条目属于模型开发数据集,912个条目属于无声评估数据集,而8177个条目属于临床试验数据集(补充图。1)。详细介绍,我们首先收集了450个条目的医生通信对话框数据集,以通过及时的工程来训练文本模型。接下来,为了评估文本模型的诊断和分类效率,我们收集了数据集A(表1),由从门诊记录得出的模拟患者数据组成。然后,我们收集了两个图像数据集(表1,数据集B和数据集c)用于培训和验证图像诊断模型,仅包含图像和相应的基于图像的诊断数据。数据集D,数据集E和数据集F(表1然后收集)以评估图像诊断模型性能并开发文本图像多模型。这些数据集包括患者病史和前部段图像。遵循IOMIDS计划的计算机开发,我们收集了一个无声评估数据集,以比较不同模型之间的诊断和分类功效(表1,数据集G)。早期的临床评估包括内部评估(上海中心)和外部评估(Nanjing和Suqian),上海有3519名患者的3519个条目,Nanjing的1748名患者的2791个参赛作品,以及Suqian患者的1192例患者的1867年参赛作品。这些中心之间的比较揭示了亚专科,疾病分类,性别,年龄和横向性的显着差异(补充表1),表明这些因素可能会影响模型性能,应在进一步分析中考虑。图1:IOMIDS的工作流和功能概述。一个

它包括文本模型和图像模型。文本模型采用分类器进行主要投诉,以及从真实医生对话框开发的问题和分析提示。图像模型利用用缝隙灯和/或智能手机拍摄的眼睛照片进行基于图像的诊断。这些模块通过诊断提示组合,创建一个多模式模型。眼睛不适的患者可以使用自然语言与Iomids相互作用。这种相互作用使Iomids能够收集患者病史,指导他们使用智能手机捕获眼病变照片或上传缝隙灯光图像,并最终提供疾病诊断和眼科次专科分类信息。b文本模型和多模式模型都遵循基于文本的模块的类似工作流程。在患者输入其主要投诉之后,使用关键字的主要投诉分类器将其分类,从而触发相关的问题和分析提示。该问题促使指导Chatgpt提出特定问题以收集患者的病史。该分析促使人们认为患者的性别,年龄,主要投诉和病史以产生初步诊断。如果没有提供图像信息,IOMIDS将提供初步诊断,以及专科分类和预防,治疗和护理指导作为最终反应。如果图像信息可用,诊断及其将图像分析与初步诊断相结合,以提供最终的诊断和相应的指导。c文本+图像多模型模型分为文本+slit-lamp,text+智能手机和text+slit-lamp-+'基于图像采集方法的智能手机模型。对于智能手机捕获的图像,Yolov7将图像段隔离以隔离受影响的眼睛,删除其他面部信息,然后使用RESNET50训练的诊断模型进行分析。缝隙灯捕获的图像跳过分割,并通过另一个经过重新NET50训练的模型直接分析。两种诊断输出都经过阈值处理,以排除非相关诊断。然后,将图像信息与通过诊断提示从文本信息得出的初步诊断集成在一起,以形成多模式模型。
Iomids系统的开发
为了开发文本模型,我们根据主要投诉主题对医生患者对话进行了分类(补充表2)。三名研究人员独立审查了数据集,每个研究人员都选择了一组90个对话框进行培训。基于这些对话框,我们使用了及时的工程(图。1B)与chatgpt开发一个体现的对话代理。比较后,最有效的90个对话框集(补充数据1确定),最终确定文本模型以进行进一步研究。其中包括在干眼上进行的11个对话,10对话,痒眼,红眼10,眼睛肿胀7,眼睛疼痛10,在眼睛排放的8上,眼睛质量为5个,13在模糊视觉上,6在双视力上,6对眼睛受伤或外国身体,四个。该文本模型可以可靠地产生与主要投诉有关的问题,并根据患者的答案提供最终回应,其中包括诊断,分类和其他预防,治疗和护理指导。
开发文本模型后,我们使用数据集A进行了评估(表1)。结果表明,各种疾病的诊断精度有所不同(图。2a)。具体而言,该模型针对原发性前部疾病(白内障,角膜炎和翼状g)的表现最少,仅达到48.7%的精度(补充图。2a)。为了确定不符合发展目标的疾病,我们分析了每个亚科中的前1种疾病。结果表明,以下内容未达到90%和特异性的敏感性目标(95%)(图。2a):角膜炎,翼状,白内障,青光眼和甲状腺眼病。临床经验表明,狭缝灯和智能手机捕获的图像对于诊断白内障,角膜炎和翼状gi症很有价值。因此,基于图像的诊断模型的开发工作将集中在这三个条件下。

诊断(顶部)和分类(底部)性能指标的热图在对文本模型(数据集A)评估后的热图。指标是从-2(蓝色)到2(红色)的列标准化。疾病类型分为六种主要分类。最左边的棒棒糖图显示了每个诊断和分类的患病率。b数据集A.彩虹环中疾病特异性诊断(红色)和分类(绿色)精度的雷达图表代表六种疾病分类。星号表明基于Fisher的精确测试,诊断和分类精度之间存在显着差异。c跨不同模型(数据集G)无声评估后的诊断(红色)和分类(绿色)的总体准确性和特异性精度的条形图。下面的线路图表示所使用的模型:文本模型,文本+缝隙模型,文本+智能手机模型和text+slit-lamp-+slit-lampâ+智能手机型号。d数据集G的Sankey图说明了每种情况下不同模型中诊断的流动。每行代表一个情况。PPV,正预测价值;NPV,负预测价值;*p<<0.05,**p<0.01,***p<<0.001,****p<<0.0001。除诊断外,聊天机器人还有效地提供了分诊信息。统计分析表明,总体分类准确性很高(88.3%),明显优于诊断精度(84.0%;图。
2b;费舍尔的确切测试,p= 0.0337)。所有亚专业都达到了负预测价值95%,除了验光(79.7%)和视网膜(77.6%)以外,所有的预测价值都达到了阳性的预测价值85%(85%(补充数据中的数据集A2)。因此,十分之八的亚专业符合预定义的发展靶标。未来的多模式模型开发将集中于增强诊断功能,同时使用文本模型的提示而没有额外的细化。
为了开发结合文本和图像的多模式模型,我们首先基于数据集B和数据集C创建了两个基于图像的诊断模型(表1),有80%用于培训的图像和20%的验证。狭缝模型的疾病特异性准确性为79.2%,角膜炎为87.6%,翼状a和98.4%的疾病精度为98.4%(补充图。2b)。智能手机模型可为白内障达到96.2%的疾病特异性精度,角性炎的疾病精度为98.4%,翼状a的精度为91.9%(补充图。2C)。开发了图像诊断模型后,我们收集了数据集D,数据集E和数据集F(表1),其中包括成像结果和患者病史。临床诊断需要整合病史和眼部成像特征,因此临床和图像诊断可能并不总是对齐(补充图。3a)。为了解决这个问题,我们仅使用图像信息来排除诊断。使用图像诊断作为黄金标准,我们绘制了数据集D中的白内障,角膜炎和pterygium的接收器操作特征(ROC)曲线(补充图。3b)和数据集E(补充图。3C)。阈值> 0.363在数据集D中提供了所有三种条件(白内障83.5%,角膜炎99.2%,pterygium 96.6%)的高特异性,并用于开发文本+slit-lit-lamp多模型。同样,在数据集E中,阈值> 0.315为所有三种条件提供了高特异性(白内障96.8%,角膜炎98.5%,pterygium 95.0%),并用于开发文本+智能手机多模型。在Text+slit-lampâ+智能手机多模型模型中,我们测试了两种方法,以结合缝隙灯和智能手机图像的结果。第一种方法使用了每个模型排除的诊断的联合,而第二种则使用了相交。对数据集F的测试表明,第一种方法的精度明显更高(52.2%,补充图。3D)比第二种方法(31.9%,补充图。3e;费舍尔的确切测试,p<<0.0001)。因此,我们在文本+slit-lampâ+智能手机模型的所有后续评估中应用了第一种方法。
与文本模型相比,使用临床诊断作为黄金标准,所有多模型模型的诊断准确性都显着提高。具体而言,文本+狭缝模型从32.0%增加到65.5%(Fisher的确切文本,p<0.0001),文本+智能手机模型从41.6%增加到64.2%(Fisher的确切测试,p<<0.0001),文本+slit-lampâ+智能手机模型从37.4%增加到52.2%(费舍尔的精确测试,p= 0.012)。因此,我们成功地为IOMIDS系统开发了四个模型:单峰文本模型,文本+slit-lamp多模型模型,文本+智能手机多模型模型和文本+'SLIT-LAMP+智能手机多模型。
对诊断和分类性能的无声评估
在无声评估阶段,收集数据集G,以验证IOMIDS系统的诊断和分类性能。虽然白内障,角膜炎和翼状a(补充数据中的数据集G)的诊断性能3)不符合已建立的临床目标,与文本模型相比,所有多模型模型均观察到诊断准确性的显着提高(图。2C)。Sankey图显示,在文本模型中,有70.8%的白内障病例和78.3%的翼状士病例被错误地分类为其他人(图。2d)。在其他类别中,文本+缝隙 - 灯 - 多模型正确识别了88.2%的白内障病例和63.0%的翼状士病例。文本+智能手机多模型的表现更好,可以正确诊断93.3%的白内障病例和80.0%的翼状案例。同时,文本+缝隙 - 灯泡+智能手机多模型准确地识别了90.5%的白内障病例和同一类别中68.2%的pterygium病例。
关于分类精度,多模型模型的总体性能提高了。但是,白内障分类的准确性显着降低,在文本+缝隙模型中从91.7%下降到62.5%(图。2C,费舍尔的确切测试,p= 0.0012),在文本+智能手机模型中为58.3%(图。2C,费舍尔的确切测试,p= 0.0003),在文本+slit-lamp+智能手机模型中更远,至53.4%(图。2C,费舍尔的确切测试,p= 0.0001)。此外,文本模型和三个多模型模型均未符合任何亚科(补充数据)中已建立的临床目标2)。
我们还研究了仅门诊电子系统中的病史是否足以使文本模型获得准确的诊断和分类结果。我们从数据集G中随机抽样了104名患者,并将其医疗对话重新输入到文本模型中(补充图。1)。对于未记录在门诊历史记录中的信息,给出了响应为“无信息”。结果表明,诊断准确性显着降低,从63.5%的20.2%下降(Fisher的精确测试,p<0.0001),虽然分类精度保持相对不变,但仅从72.1%的70.2%略微降低(费舍尔的精确测试,p= 0.8785)。这项研究表明,虽然文本模型的分类精度不取决于对话的完整性,但诊断准确性会受到所提供答案的完整性的影响。因此,对AI聊天机器人查询的彻底响应在临床应用中至关重要。
与训练有素的研究人员在真实临床环境中进行评估
临床试验涉及两个部分:研究人员收集的数据和患者输入的数据(表2)。研究人员和患者之间的输入单词输入和投入持续时间存在显着差异。对于研究人员收集的数据,平均为38.5±8.2个单词和58.2±13.5 s,而对于患者输入的数据,平均值为55.5英寸。±10.3个单词(t-测试,p= 0.002)和128.8±27.1(t-测试,p<<0.0001)。我们首先评估了研究人员收集的数据阶段的诊断性能。对于六个数据集的文本模型(补充数据中的数据集1â3,6â83),以下疾病数量符合诊断眼科疾病的临床目标:数据集1中的46种疾病中有16个(占所有病例的46.4%),在数据集中的32种疾病中,有16个(所有病例的16.4%)中有16种,第2个疾病(占所有病例的16.4%)数据集3中的28种疾病(占所有病例的61.4%)中有48种疾病(所有病例的43.9%)在数据集6中,其中28种疾病中有14个(所有病例的35.3%)在数据集中7,而数据集则有11个,其中11个疾病(占所有病例的35.3%)数据集8中的42种疾病(所有病例的33.3%)。因此,在研究人员收集的数据阶段,只有不到一半的病例达到了诊断的临床目标。
接下来,我们研究了各种数据集的文本模型的亚专科分类精度2)。我们的发现表明,在内部验证期间,角膜亚科实现了分类眼科疾病的临床目标。在外部验证中,一般门诊诊所,角膜亚科,验光子专业和青光眼亚科也符合这些临床标准。我们进一步比较了六个数据集的文本模型的诊断和分类结果。数据分析表明,在大多数数据集中,分类精度超过诊断精度(补充图。4aâc,eâg)。具体而言,与数据集1中的诊断精度为69.3%相比,分类精度为88.7%(图。3a;费舍尔的确切测试,p<<0.0001),为84.1%,而数据集2为62.4%(Fisher的确切测试,p<<0.0001),82.5%,而数据集3为75.4%(Fisher的精确测试,p= 0.3508),为85.7%,而数据集6为68.6%(图。3a;费舍尔的确切测试,p<<0.0001),80.5%,而数据集7中为66.5%(Fisher的精确测试,p<<0.0001),为84.5%,而数据集8(Fisher的精确测试,则为65.1%)p<<0.0001)。这表明,尽管文本模型可能无法满足临床诊断需求,但它可能会满足临床分类要求。

临床评估文本模型(左,数据集1)和外部(右,数据集6)中心的临床评估后,疾病特异性诊断(红色)和分类(绿色)精度的雷达图表。星号表明基于Fisher的精确测试,诊断和分类精度之间存在显着差异。b内部(左,数据集2â4)和外部(右,数据集7 9)评估的不同模型的疾病特异性诊断准确性的圆形堆叠条形图。实心条代表文本模型,而空心条则代表多模式模型。星号表明,基于Fisher的精确测试,两个模型之间的诊断准确性显着差异。c在数据集2 -5和数据集7的不同模型中,原发性前部疾病(较低)的总体准确性(上)和准确性(较低)的条形图图表(较低)(绿色)(绿色)。下面的线路图表示研究中心(内部,外部),使用的模型(文本,文本+缝隙,文本+智能手机,text+slit-lamp-+智能手机)和数据提供商(研究人员,患者)。*p<<0.05,**p<0.01,***p<<0.001,****p<<0.0001。
然后,我们研究了数据集2、3、7和8中多模型模型的诊断性能(补充数据3)。与内部和外部验证中的文本模型相比数据集8中的智能手机型号(图。3C)。诊断眼科疾病的临床目标是通过数据集2的32种疾病中的11种(占所有病例的13.8%)实现,其中21种疾病中有21种(所有病例的70.2%)在数据集中3,其中11个疾病中有11种(28例28.5%)(28.5%)在所有情况下)在数据集7中,在数据集8中的42种疾病中有15个(占所有病例的50.6%)。文本+智能手机模型通过满足更多病例诊断的临床目标,超过了文本模型疾病类型。对于一些其他不符合诊断临床目标的疾病,在多模式模型中也发现了诊断准确性的显着提高(图。3b)。因此,与文本模型相比,多模式模型表现出更好的诊断性能。
关于分类,与文本模型相比,多模型模型的一些数据集显示出准确性的较小降低,但是,这些差异在统计学上并不显着(图。3C)。与临床应用中的无声评估阶段不同,两个多模型模型都没有表现出不同疾病(包括白内障)的分类准确性显着下降(补充图。5)。总而言之,研究人员收集的数据表明,多模式模型在诊断准确性方面的表现优于文本模型,但分类效率略低。
在未经训练的患者的实际临床环境中评估
在患者输入的数据阶段,考虑到智能手机的便利性,我们专注于文本模型,文本+智能手机模型和文本+slit-lampâ+slit-lampâ+'智能手机型号。首先,我们比较了分类精度。与研究人员收集的数据阶段一致,多模型模型的总体分类准确性略低于文本模型的整体精度,但是这种差异在统计上并不显着(图。3C)。对于子专业,在内部和外部验证中,一般门诊诊所和青光眼的文本和多模型模型符合分列眼科疾病的临床目标。此外,内部验证表明,多模型模型符合这些标准,用于角膜,验光和视网膜亚专科。在外部验证中,文本模型符合角膜和视网膜的标准,而多模型模型符合白内障和视网膜的标准。这些结果表明,当患者输入自己的数据时,文本模型和多模式模型都符合分类要求。
接下来,我们比较了文本模型和多模式模型的诊断准确性。结果表明,在内部和外部验证中,所有疾病均符合95%的特异性标准。在数据集4中,文本模型符合敏感性的临床标准 - 在42种疾病中,有15个(占病例的40.5%)中有75%,而文本+智能手机多模型符合这一点。42种疾病中有24个(占病例的78.6%)的标准。在数据集5中,文本模型达到了40个疾病中14个(占48.3%)的14元的灵敏度阈值,而文本+slit-slit-lamp”+智能手机多模型在40种疾病中只有10个(35.0%的病例)符合此标准。在数据集9中,文本模型在43种疾病中有24个(57.1%)达到了临床标准,而文本+智能手机模型符合43种疾病中的28个标准(81.9%)。In Dataset 10, the text model achieved the criterion in 25 out of 42 diseases (62.5%), whereas the text + slit-lamp + smartphone model met the criterion in 22 out of 42 diseases (50.8%).This suggests that the text + smartphone model outperforms the text model, while the text + slit-lamp + smartphone model does not.Further statistical analysis confirmed the superiority of text + smartphone model when comparing its diagnostic accuracy with the text model in both Dataset 4 and Dataset 9 (Fig.3C)。We also conducted an analysis of diagnostic accuracy for individual diseases, identifying significant improvements for certain diseases (Fig.3b)。These findings collectively show that during the patient-entered data phase, the text + smartphone model not only meets triage requirements but also delivers better diagnostic performance than both the text model and the text + slit-lamp + smartphone model.
We further compared the diagnostic and triage accuracy of the text model in Dataset 4 and Dataset 9. Consistent with previous findings, both internal validation (triage: 80.4%, diagnosis: 69.6%; Fisher’s exact test,p < 0.0001) and external validation (triage: 84.7%, diagnosis: 72.5%; Fisher’s exact test,p < 0.0001) demonstrated significantly higher triage accuracy compared to diagnostic accuracy for the text model (Supplementary Fig.4d, h)。Examining individual diseases, cataract exhibited notably higher triage accuracy than diagnostic accuracy in internal validation (Dataset 4: triage 76.8%, diagnosis 51.2%; Fisher’s exact test,p = 0.0011) and external validation (Dataset 9: triage 87.3%, diagnosis 58.2%; Fisher’s exact test,p = 0.0011). Interestingly, in Dataset 4, the diagnostic accuracy for myopia (94.0%) was significantly higher (Fisher’s exact test,p = 0.0354) than the triage accuracy (80.6%), indicating that the triage accuracy of the text model may not be influenced by diagnostic accuracy. Subsequent regression analysis is necessary to investigate the factors determining triage accuracy.
Due to varying proportions of the disease classifications across the three centers (Supplementary Table1), we further explored changes in diagnostic and triage accuracy within each classification.Results revealed that, regardless of whether data was researcher-collected or patient-reported, diagnostic accuracy for primary anterior segment diseases (cataract, keratitis, pterygium) was significantly higher in the multimodal model compared to the text model in both internal and external validation (如图。3C)。Further analysis of cataract, keratitis, and pterygium across Datasets 2, 3, 4, 7, 8, and 9 (Fig.3b) also showed that, similar to the silent evaluation phase, multimodal model diagnostic accuracy for cataract significantly improved compared to the text model in most datasets. Pterygium and keratitis exhibited some improvement but showed no significant change across most datasets due to sample size limitations. For the other five major disease categories, multimodal model diagnostic accuracy did not consistently improve and even significantly declined in some categories (Supplementary Fig.6)。These findings indicate that the six major disease categories may play crucial roles in influencing the diagnostic performance of the models, underscoring the need for further detailed investigation.
Comparison of diagnostic performance in different models
To further compare the diagnostic accuracy of different models across various datasets, we conducted comparisons within six major disease categories. The results revealed significant differences in diagnostic accuracy among the models across these categories (Fig.4a)。For example, when comparing the text + smartphone model (Datasets 4, 9) to the text model (Datasets 1, 6), both internal and external validations showed higher diagnostic accuracy for the former in primary anterior segment diseases, other anterior segment diseases, and intraorbital diseases and emergency categories compared to the latter (Fig.4a, b)。Interestingly, contrary to previous findings within datasets, comparisons across datasets demonstrated a notable decrease in diagnostic accuracy for the text + slit-lamp model (Dataset 1 vs 2, Dataset 6 vs 7) and the text + slit-lamp + smartphone model (Dataset 4 vs 5, Dataset 9 vs 10) in the categories of other anterior segment diseases and vision disorders in both internal and external validations (Fig.4a)。This suggests that, in addition to the model used and the disease categories, other potential factors may influence the model’s diagnostic accuracy.

Bar charts of diagnostic accuracy calculated for each disease classification across different models from internal (upper, Dataset 1–5) and external (lower, Dataset 6–10) evaluations. The bar colors represent disease classifications. The line graphs below denote study centers, models used, and data providers.bHeatmaps of diagnostic performance metrics after internal (left) and external (right) evaluations of different models. For each heatmap, metrics in the text model and text + smartphone model are normalized together by column, ranging from -2 (blue) to 2 (red). Disease types are classified into six categories and displayed by different colors.cMultivariate logistic regression analysis of diagnostic accuracy for all cases (left) and subgroup analysis for follow-up cases (right) during clinical evaluation.The first category in each factor is used as a reference, and OR values and 95% CIs for other categories are calculated against these references.或优势比;CI,置信区间;*p < 0.05, **p < 0.01, ***p < 0.001, ****p < 0.0001.
We then conducted univariate and multivariate regression analyses to explore factors influencing diagnostic accuracy. Univariate analysis revealed that seven factors (age, laterality, number of visits, disease classification, model, data provider, and words input) significantly influence diagnostic accuracy (Supplementary Table3)。In multivariate analysis, six factors (age, laterality, number of visits, disease classification, model, and words input) remained significant, while the data provider was no longer a critical factor (Fig.4C)。Subgroup analysis of follow-up cases showed that only the model type significantly influenced diagnostic accuracy (Fig.4C)。For first-visit patients, three factors (age, disease classification, and model) were still influential.Further analysis across different age groups within each disease classification revealed that the multimodal models generally outperformed or performed comparably to the text model in most disease categories (Table3)。However, all multimodal models, including the text + slit-lamp model (OR: 0.21 [0.04–0.97]), the text + smartphone model (OR: 0.17 [0.09–0.32]), and the text + slit-lamp + smartphone model (OR: 0.16 [0.03–0.38]), showed limitations in diagnosing visual disorders in patients over 45 years old compared to the text model (Table3)。Additionally, both the text + slit-lamp model (OR: 0.34 [0.20–0.59]) and the text + slit-lamp + smartphone model (OR: 0.67 [0.43–0.89]) were also less effective for diagnosing other anterior segment diseases in this age group.In conclusion, for follow-up cases, both text + slit-lamp and text + smartphone models are suitable, with a preference for the text + smartphone model.For first-visit patients, the text + smartphone model is recommended, but its diagnostic efficacy for visual disorders in patients over 45 years old (such as presbyopia) may be inferior to that of the text model.
We also performed a regression analysis on triage accuracy. In the univariate logistic regression, the center and data provider significantly influenced triage accuracy. Multivariate regression analysis showed that only the data provider significantly impacted triage accuracy, with patient-entered data significantly improving accuracy (OR: 1.40 [1.25–1.56]). Interestingly, neither model type nor diagnostic accuracy affects triage outcomes. Considering the previous data analysis results from the patient-entered data phase, both the text model and the text + smartphone model are recommended as self-service triage tools for patients in clinical applications. Collectively, among the four models developed in our IOMIDS system, the text + smartphone model is more suitable for patient self-diagnosis and self-triage compared to the other models.
模型解释性
In subgroup analysis, we identified limitations in the diagnostic accuracy for all multimodal models for patients over 45 years old. The misdiagnosed cases in this age group were further analyzed to interpret the limitations. Both the text + slit-lamp model (Datasets 2, 7) and the text + slit-lamp + smartphone model (Datasets 5, 10) frequently misdiagnosed other anterior segment and visual disorders as cataracts or keratitis. For instance, with the text + slit-lamp + smartphone model, glaucoma (18 cases, 69.2%) and conjunctivitis (22 cases, 38.6%) were often misdiagnosed as keratitis, while presbyopia (6 cases, 54.5%) and visual fatigue (11 cases, 28.9%) were commonly misdiagnosed as cataracts. In contrast, both the text model (Datasets 1–10) and the text + smartphone model (Datasets 3, 4, 8, 9) had relatively low misdiagnosis rates for cataracts (text: 23 cases, 3.5%; text + smartphone: 91 cases, 33.7%) and keratitis (text: 16 cases, 2.4%; text + smartphone: 25 cases, 9.3%). These results suggest that in our IOMIDS system, the inclusion of slit-lamp images, whether in the text + slit-lamp model or the text + slit-lamp + smartphone model, may actually hinder diagnostic accuracy due to the high false positive rate for cataracts and keratitis.
We then examined whether these misdiagnoses could be justified through image analysis. First, we reviewed the misdiagnosed cataract cases. In the text + slit-lamp model, 30 images (91.0%) were consistent with a cataract diagnosis. However, clinically, they were mainly diagnosed with glaucoma (6 cases, 20.0%) and dry eye syndrome (5 cases, 16.7%). Similarly, in the text + smartphone model, photographs of 80 cases (88.0%) were consistent with a cataract diagnosis. Clinically, these cases were primarily diagnosed with refractive errors (20 cases), retinal diseases (15 cases), and dry eye syndrome (8 cases). We then analyzed the class activation maps of the two multimodal models. Both models showed regions of interest for cataracts near the lens (Supplementary Fig.7), in accordance with clinical diagnostic principles. Thus, these multimodal models can provide some value for cataract diagnosis based on images but may lead to discrepancies with the final clinical diagnosis.Next, we analyzed cases misdiagnosed as keratitis by the text + slit-lamp model. The results showed that only one out of 25 cases had an anterior segment photograph consistent with keratitis, indicating a high false-positive rate for keratitis with the text + slit-lamp model. We then conducted a detailed analysis of the class activation maps generated by this model during clinical application. The areas of interest for keratitis were centered around the conjunctiva rather than the corneal lesions (Supplementary Fig.
7a)。Thus, the model appears to interpret conjunctival congestion as indicative of keratitis, contributing to the occurrence of false-positive results.In contrast, the text + smartphone model displayed areas of interest for keratitis near the corneal lesions (Supplementary Fig.7b), which aligns with clinical diagnostic principles. Taken together, future research should focus on refining the text + slit-lamp model for keratitis diagnosis and prioritize optimizing the balance between text-based and image-based information to enhance diagnostic accuracy across both multimodal models.
Inter-model variability and inter-expert variability
We further evaluated the diagnostic accuracy of GPT4.0 and the domestic large language model (LLM) Qwen using Datasets 4, 5, 9, and 10. Additionally, we invited three trainees and three junior doctors to independently diagnose these diseases. Since the text + smartphone model performed the best in the IOMIDS system, we compared its diagnostic accuracy with that of the other two LLMs and ophthalmologists with varying levels of experience (Fig.5a-b)。The text + smartphone model (80.0%) outperformed GPT4.0 (71.7%, χ² test,p = 0.033) and showed similar accuracy to the mean performance of trainees (80.6%). Among the three LLMs, Qwen performed the poorest, comparable to the level of a junior doctor. However, all three LLMs fell short of expert-level performance, suggesting there is still potential for improvement.Fig. 5: Assessment of model-expert agreement and the quality of chatbot responses.一个

Heatmap of Kappa statistics quantifying agreement between diagnoses provided by AI models and ophthalmologists.cKernel density plots of user satisfaction rated by researchers (red) and patients (blue) during clinical evaluation.dExample of an interactive chat with IOMIDS (left) and quality evaluation of the chatbot response (right). On the left, the central box displays the patient interaction process with IOMIDS: entering chief complaint, answering system questions step-by-step, uploading a standard smartphone-captured eye photo, and receiving diagnosis and triage information. The chatbot response includes explanations of the condition and guidance for further medical consultation. The surrounding boxes show a researcher’s evaluation of six aspects of the chatbot response. The radar charts on the right illustrate the quality evaluation across six aspects for chatbot responses generated by the text model (red) and the text + image model (blue). The axes for each aspect correspond to different coordinate ranges due to varying rating scales. Asterisks indicate significant differences between two models based on two-sidedt-测试。**p < 0.01, ***p < 0.001, ****p < 0.0001.We then analyzed the agreement between the answers provided by the LLMs and ophthalmologists (Fig.5b
)。Agreement among expert ophthalmologists, who served as the gold standard in our study, was generally strong (κ: 0.85–0.95).Agreement among trainee doctors was moderate (κ: 0.69–0.83), as was the agreement among junior doctors (κ: 0.69–0.73).However, the agreement among the three LLMs was weaker (κ: 0.48–0.63).Notably, the text + smartphone model in IOMIDS showed better agreement with experts (κ: 0.72–0.80) compared to the other two LLMs (GPT4.0: 0.55–0.78; Qwen: 0.52–0.75).These results suggest that the text + smartphone model in IOMIDS demonstrates the best alignment with experts among the three LLMs.
Evaluation of user satisfaction and response quality
The IOMIDS responses not only contained diagnostic and triage results but also provided guidance on prevention, treatment, care, and follow-up (Fig.5c)。We first analyzed both researcher and patient satisfaction with these responses.Satisfaction was evaluated by researchers during the model development phase and the clinical trial phase;satisfaction was evaluated by patients during the clinical trial phase, regardless of the data collection method.Researchers rated satisfaction score significantly higher (4.63 ± 0.92) than patients (3.99 ± 1.46;t-test, P < 0.0001;如图。5c)。Patient ratings did not differ between researcher-collected (3.98 ± 1.45) and self-entered data (4.02 ± 1.49;t-测试,p = 0.3996). Researchers frequently rated chatbot responses as very satisfied (82.5%), whereas patient ratings varied, with 20.2% finding responses not satisfied (11.7%) or slightly satisfied (8.5%), and 61.9% rating them very satisfied. Further demographic analysis between these patient groups revealed that the former (45.7 ± 23.8 years) were significantly older than the latter (37.8 ± 24.4 years;t-测试,p < 0.0001), indicating greater acceptance and positive evaluation of AI chatbots among younger individuals.Next, we evaluated the response quality between multimodal models and the text model (Fig.
5d)。The multimodal models exhibited significantly higher overall information quality (4.06 ± 0.12 vs. 3.82 ± 0.14;t-测试,p = 0.0031) and better understandability (78.2% ± 1.3% vs. 71.1% ± 0.7%;t-测试,p < 0.0001) than the text model. Additionally, the multimodal models showed significantly lower misinformation scores (1.02 ± 0.05 vs. 1.23 ± 0.11;t-测试,p = 0.0003) compared to the text model. Notably, the empathy score statistically decreased in multimodal models compared to the text model (3.51 ± 0.63 vs. 4.01 ± 0.56;t-文本,p < 0.0001), indicating lower empathy in chatbot responses from multimodal models. There were no significant differences in terms of grade level (readability), with both the text model and multimodal models being suitable for users at a grade 3 literacy level. These findings suggest that multimodal models generate high-quality chatbot responses with good readability. Future studies may focus on enhancing the empathy of these multimodal models to better suit clinical applications.讨论
The Intelligent Ophthalmic Multimodal Interactive Diagnostic System (IOMIDS) is designed to diagnose ophthalmic diseases using multimodal information and provides comprehensive medical advice, including subspecialty triage, prevention, treatment, follow-up, and care. During development, we created four models: a text-based unimodal model, which is an embodied conversational agent integrated with ChatGPT, and three multimodal models that combine medical history information from interactive conversations with eye images for a more thorough analysis. In clinical evaluations, the multimodal models significantly improved diagnostic performance over the text model for anterior segment diseases such as cataract, keratitis, and pterygium in patients aged 45 and older. Previous studies also demonstrated the strength of multimodal models over unimodal models, showing that multimodal model outperformed image-only model in identifying pulmonary diseases and predicting adverse clinical outcomes in COVID-19 patients
19。Thus, multimodal models are more suitable for analyzing medical information than unimodal models.Notably, the text + smartphone model in the IOMIDS system demonstrated the highest diagnostic accuracy, outperforming current multimodal LLMs like GPT4.0 and Qwen. However, while this model approaches trainee-level performance, it still falls short of matching the accuracy of expert ophthalmologists. GPT4.0 itself achieved accuracy only slightly higher than junior doctors. Previous studies have similarly indicated that while LLMs show promise in supporting ophthalmic diagnosis and education, they lack the nuanced precision of trained specialists, particularly in complex cases
20。For instance, Shemer et al.tested ChatGPT’s diagnostic accuracy in a clinical setting and found it lower than that of ophthalmology residents and attending physicians21。Nonetheless, it completed diagnostic tasks significantly faster than human evaluators, highlighting its potential as an efficient adjunct tool.Future research should focus on refining intelligent diagnostic models for challenging and complex cases, with iterative improvements aimed at enhancing diagnostic accuracy and clinical relevance.
Interestingly, the text + smartphone model outperformed the text + slit-lamp model in diagnosing cataract, keratitis, and pterygium in patients under 45 years old. Even though previous studies have shown significant progress in detecting these conditions using smartphone photographs22,,,,23,,,,24, there is insufficient evidence to support the finding that the text + slit-lamp model is less efficient than the text + smartphone model. To address this issue, we first thoroughly reviewed the class activation maps of both models. We found that the slit-lamp model often focused on the conjunctival hyperemia region rather than the corneal lesion area in keratitis cases, leading to more false-positive diagnoses. This mismatch between model-identified areas of interest and clinical lesions suggests a flaw in our slit-lamp image analysis12。Additionally, we analyzed the imaging characteristics of the training datasets (Dataset B and Dataset C) for image-based diagnostic models.Dataset B exhibited a large proportion of the conjunctival region in images, particularly in keratitis cases, which often displayed extensive conjunctival redness.Conversely, Dataset C, comprising smartphone images, showed a smaller proportion of the conjunctival region and facilitated reducing bias towards conjunctival hyperemia in keratitis cases.Overall, refining the anterior segment image dataset may enhance the diagnostic accuracy of the text + slit-lamp model.
Notably, the text + smartphone model has demonstrated advantages in diagnosing orbital diseases, even though it was not specifically trained for these conditions. These findings highlight the need and potential for further enhancement of the text + smartphone model in diagnosing both orbital and eyelid diseases. Additionally, there was no significant difference in diagnostic capabilities for retinal diseases between the text + slit-lamp model, the text + smartphone model, or the text + slit-lamp + smartphone model compared to the text-only model, which aligns with our expectations. This suggests that appearance images may not significantly contribute to diagnosing retinal diseases, consistent with clinical practice. Several studies have successfully developed deep learning models for accurately detecting retinal diseases using fundus photos25, optical coherence tomography (OCT) images26, and other eye-related images. Therefore, IOMIDS could benefit from functionalities to upload retinal examination images and enable comprehensive diagnosis, thereby improving the efficiency of diagnosing retinal diseases. Furthermore, we found that relying solely on medical histories from the outpatient electronic system was insufficient for the text model to achieve accurate diagnoses. This suggests that IOMIDS may gather clinically relevant information that doctors often overlook or fail to record in electronic systems. Thus, future system upgrades could involve aiding doctors in conducting preliminary interviews and compiling initial medical histories to reduce their workload.
Regarding subspecialty triage, consistent with prior research, the text model demonstrates markedly superior accuracy in triage compared to diagnosis27。Additionally, we observed an intriguing phenomenon: triage accuracy is influenced not by diagnostic accuracy but by the data collector.Specifically, patients’ self-input data resulted in significantly improved triage accuracy compared to data input by researchers.Upon careful analysis of the differences, we found that patient-entered data tends to be more conversational, whereas researcher-entered data tends to use medical terminology and concise expressions.A prior randomized controlled trial (RCT) investigated how different social roles of chatbots influence the chatbot-user relationship, and results suggested that adjusting chatbot roles can enhance users’ intentions toward the chatbot28。However, no RCT study is available to investigate how users’ language styles influence chatbot results.Based on our study, we propose that if IOMIDS is implemented in home or community settings without researcher involvement, everyday conversational language in self-reports does not necessarily impair its performance.Therefore, IOMIDS may serve as a decision support system for self-triage to enhance healthcare efficiency and provide cost-effectiveness benefits.
Several areas for improvement were identified for our study. Firstly, due to sample size limitations during the model development phase, we were unable to develop a combined image model for slit-lamp and smartphone images. Instead, we integrated the results of the slit-lamp and smartphone models using logical operations, which led to suboptimal performance of the text + slit-lamp + smartphone model. In fact, previous studies involving multiple image modalities have achieved better results29。Therefore, it will be necessary to develop a dedicated multimodal model for slit-lamp and smartphone images in future work.Moreover, the multimodal model showed lower empathy compared to the text model, possibly due to its more objective diagnosis prompts contrasting with conversational styles.Future upgrades will adjust the multimodal model’s analysis prompts to enhance empathy in chatbot responses.Thirdly, older users reported lower satisfaction with IOMIDS, highlighting the need for improved human-computer interaction for this demographic.In addition, leveraging ChatGPT’s robust language capabilities and medical knowledge, we used prompt engineering to optimize for parameter efficiency, cost-effectiveness, and speed in clinical experiments.However, due to limitations in OpenAI’s medical capabilities, particularly its inability to pass the Chinese medical licensing exam30, we aim to develop our own large language model based on real Chinese clinical dialogs. This model is expected to enhance diagnostic accuracy and adapt to evolving medical consensus. During our study, we used GPT3.5 instead of GPT4.0 due to token usage constraints. Since GPT4.0 has shown superior responses to ophthalmology-related queries in recent studies31, integrating GPT4.0 into IOMIDS may enhance its clinical performance. It is worth mentioning that the results of our study may not be applicable to other language environments. Previous studies have shown that GPT responds differently to prompts in various languages, with English appearing to yield better results32。There were also biases in linguistic evaluation, as expert assessments can vary based on language habits, semantic comprehension, and cultural values.Moreover, our study represents an early clinical evaluation, and comparative prospective evaluations are necessary before implementing IOMIDS in clinical practice.
材料和方法
道德批准
The study was approved by the Institutional Review Board of Fudan Eye & ENT Hospital, the Institutional Review Board of the Affiliated Eye Hospital of Nanjing Medical University, and the Institutional Review Board of Suqian First Hospital. The study was registered on ClinicalTrials.gov (NCT05930444) on June 26, 2023. It was conducted in accordance with the Declaration of Helsinki, with all participants providing written informed consent before their participation.
研究设计
This study aims to develop an Intelligent Ophthalmic Multimodal Interactive Diagnostic System (IOMIDS) for diagnosing and triaging ophthalmic diseases (Supplementary Fig.1)。The IOMIDS includes four models: an unimodal text model, which is an embodied conversational agent with ChatGPT;a text + slit-lamp multimodal model, which incorporates both text and eye images captured by a slit-lamp equipment;a text + smartphone multimodal model, utilizing text along with eye images captured by a smartphone for diagnosis and triage;and a text + slit-lamp + smartphone multimodal model, which combines both image modalities with text to achieve a final diagnosis.Clinical validation of the three models’ performance is conducted through a two-stage cross-sectional study, an initial silent evaluation stage followed by an early clinical evaluation stage, as detailed in the protocol article33。Triage covers 10 ophthalmic subspecialties: general outpatient clinic, optometry, strabismus, cornea, cataract, glaucoma, retina, neuro-ophthalmology, orbit, and emergency.Diagnosis involves 50 common ophthalmic diseases (Supplementary Data4), categorized by lesion location into anterior segment diseases, fundus and optic nerve diseases, intraorbital diseases and emergencies, eyelid diseases, and visual disorders.Notably, because of the image diagnostic training conducted for cataract, keratitis, and pterygium during the development of multimodal models, anterior segment diseases are further classified into two categories: primary anterior segment diseases (including cataract, keratitis, and pterygium) and other anterior segment疾病。
Collecting and formatting doctor-patient communication dialogs
Doctor-patient communication dialogs were collected from the outpatient clinics of Fudan Eye & ENT Hospital, covering the predetermined 50 disease types across 10 subspecialties. After collection, each dialog underwent curation and formatting. Curation requires removing filler words and irrelevant redundant content (e.g., payment methods). Formatting refers to structuring each dialog into four standardized parts: (1) chief complaint; (2) series of questions from the doctor; (3) patient’s responses to each question; (4) doctor’s diagnosis, triage judgment, and information on prevention, treatment, care, and follow-up. Subsequently, researchers (with at least 3 years of clinical experience as attending physicians) carefully reviewed the dialogs for each disease, selecting those where the doctor’s questions were focused on the chief complaint, demonstrated medical reasoning, and contributed to diagnosis and triage. After this careful review, 90 out of 450 dialogs were selected for prompt engineering to train the text model for IOMIDS. Three researchers independently evaluated the dialogs, resulting in three sets of 90 dialogs. To assess the performance of the models trained with these different sets of dialogs, we created two virtual cases for each of the five most prevalent diseases across 10 subspecialties at our research institution, totaling 100 cases. The diagnostic accuracy for each set of prompts was 73%, 68%, and 52%, respectively. Ultimately, the first set of 90 dialogs (Supplementary Data1) was chosen as the final set of prompts.Developing a dynamic prompt system for IOMIDS
To build the IOMIDS system, we designed a dynamic prompt system that enhances ChatGPT’s role in patient consultations by integrating both textual and image data. This system supports diagnosis and triage based on either single-modal (text) or multi-modal (text and image) information. The overall process is illustrated in Fig.
1B, with a detailed explanation provided below:The system is grounded in a medical inquiry prompt corpus, developed by organizing 90 real-world clinical dialogs into a structured format. Each interview consists of four segments: “Patient’s Chief Complaint,†“Inquiry Questions,†“Patient’s Responses,†and “Diagnosis and Consultation Recommendations.†These clinical interviews are transformed into structured inquiry units, known as “prompts†within the system. When a patient inputs their primary complaint, the system’s Chief Complaint Classifier identifies relevant keywords and matches them with corresponding prompts from the corpus. These selected prompts, along with the patient’s initial complaint, form a question prompt that guides ChatGPT in asking about the relevant medical history related to the chief complaint.
After gathering the responses to these inquiries, an analysis prompt is generated. This prompt directs ChatGPT to perform a preliminary diagnosis and triage based on the conversation history. The analysis prompt includes the question prompts from the previous stage, along with all questions and answers exchanged during the consultation. If no appearance-related or anterior segment images are provided by the patient, the system uses only this analysis prompt to generate diagnosis and triage recommendations, which are then communicated back to the patient as the final output of the text model.
For cases that involve multi-modal information, we developed an additional diagnosis prompt. This prompt expands on the previous analysis prompt by incorporating key patient information—such as gender, age, and preliminary diagnosis/triage decisions—alongside diagnostic data obtained from slit-lamp or smartphone images. By combining image data with textual information, ChatGPT is able to provide more comprehensive medical recommendations, including diagnosis, triage, and additional advice based on both modalities.
It is important to note that in a single consultation, the question prompt, analysis prompt, and diagnosis prompt are not independent; rather, they are interconnected and progressive. The question prompt is part of the analysis prompt, and the analysis prompt is integrated into the diagnosis prompt.
Collecting and ground-truth labeling of images
Image diagnostic data is crucial for diagnosis prompts, and to obtain this data, we need to develop an image-based diagnostic model. Considering there are two common methods for capturing eye photos in clinical settings, both slit-lamp captured and smartphone captured eye images were collected for the development of the image-based diagnostic model. These images encompass diseases identified as requiring image diagnosis (specifically cataract, keratitis, pterygium) through in silico evaluation of the text model (as detailed below). For patients with different diagnoses in each eye (e.g., keratitis in one eye and dry eye in the other), each eye was included as an independent data entry. Additionally, slit-lamp and smartphone captured images for diseases with top 1–5 prevalence rates in each subspecialty were collected and categorized as “others†for training, validation, and testing of the image diagnostic model.
For slit-lamp images, the following criteria apply: 1. Images must be taken using the slit-lamp’s diffuse light with no overexposure; 2. Both inner and outer canthi must be visible; 3. Image size must be at least 1MB, with a resolution of no less than 72 pixels/inch. For smartphone images, the following conditions must be met: 1. The eye of interest must be naturally open; 2. Images must be captured under indoor lighting, with no overexposure; 3. The shooting distance must be within 1 meter, with focus on the eye region; 4. Image size must be at least 1MB, with a resolution of no less than 72 pixels/inch. Images not meeting these requirements will be excluded from the study. Four specialists independently labeled images into four categories (cataract, keratitis, pterygium, and others) based solely on the image. Consensus was reached when three or more specialists agreed on the same diagnosis; images where agreement could not be reached by at least two specialists were excluded.
Developing image-based ophthalmic classification models for multimodal models
We developed two distinct deep learning algorithms using ResNet-50 to process images captured by slit-lamp and smartphone cameras. The first algorithm was designed to detect cataracts, keratitis, and pterygium in an anterior segment image dataset (Dataset B) obtained under a slit lamp. The second algorithm targeted the detection of these conditions in a dataset (Dataset C) consisting of single-eye regions extracted from smartphone images. To address the challenge of non-eye facial regions in smartphone images, we collected an additional 200 images to train and validate an eye-target detection model using YOLOv7. This model was specifically trained to detect eye regions by annotating the eye areas within these images. Of the total images, 80% were randomly assigned to the training set, and the model was trained for 300 epochs using the default learning rate and preprocessing settings specified in the YOLOv7 website (
https://github.com/WongKinYiu/yolov7)。The remaining 20% of the images were used as a validation set, achieving a Precision of 1.0, Recall of 0.98, and mAP@.5 of 0.991.These images were not reused in any other experiments.
For the disease classification network, we created a four-class dataset consisting of cataracts, keratitis, pterygium, and “Other†categories. This dataset includes both anterior segment images and smartphone-captured eye images across all categories. The “Other†class includes normal eye images and images of various other eye conditions. Using a ResNet-50 model pretrained on ImageNet, we fine-tuned it on this four-class dataset for 200 epochs to optimize classification accuracy across both modalities.
During training, each image was resized to 224 × 224 pixels and underwent data augmentation techniques to enhance generalization. These included a 0.2 probability of random horizontal flipping, random rotations between -5 to 5 degrees, and a 0.2 probability of automatic contrast adjustments. White balance adjustments were also applied to standardize the images. For validation and testing, images were resized to 224 × 224 pixels, underwent white balance adjustments, and were then input into the model for disease prediction. To improve model robustness and minimize overfitting, we employed five-fold cross-validation. The dataset was divided into five parts (each 20%), with four parts used for training and one part for validation in each fold. The final model was selected based on the highest validation accuracy, without specific constraints on sensitivity and specificity for individual models.
Generating image diagnostic data for multimodal models
Before being input into the diagnosis prompt, image diagnostic data underwent preprocessing. Preliminary experiments revealed that when the data indicated a single diagnosis, the multimodal model might overlook patient demographics and medical history, leading to a direct image-based diagnosis. To address this, we adjusted the image diagnostic results by excluding specific diagnoses.
Specifically, we modified the classification model by removing the final Softmax layer and using the scores from the fully connected (fc) layer as outputs for each category. These scores were then rescaled to fall within the range of [-1, 1], providing continuous diagnostic output for each image category. The rescaled scores served as the image model’s diagnostic output. We also collected additional datasets, Dataset D (slit-lamp captured images) and Dataset E (smartphone captured images), to ensure the independence of training, validation, and testing sets. The model was then run on Datasets D and E, generating scores for all four categories across all images, with the image diagnosis serving as the gold standard. Receiver operating characteristic (ROC) curves were plotted for cataracts, keratitis, and pterygium to determine optimal thresholds for maximizing specificity across these diseases. These thresholds were then established as the output standard. For example, if only cataracts exceeded the threshold among the three diseases, the output label from the image diagnostic module would be “cataractâ€.
To further develop a text + slit-lamp + smartphone model, we collected Dataset F, which includes both slit-lamp and smartphone images for each individual. We tested two methods to combine the results from the slit-lamp and smartphone images. The first method used the union of diagnoses excluded by each model, while the second method used the intersection. For example, if the slit-lamp image excluded cataracts and the smartphone image excluded both cataracts and keratitis, the first method would exclude cataracts and keratitis, while the second method would exclude only cataracts. These “excluded diagnoses†were then combined with the user’s analysis prompt, key patient information, and preliminary diagnosis to construct the diagnosis prompt, as shown in Fig.1C。This diagnosis prompt was then sent to ChatGPT, allowing it to generate the final multimodal diagnostic result by integrating both image-based and contextual data.
In silico evaluation of text model
After developing chief complaint classifiers, question prompt templates, and analysis prompt templates, we integrated these functionalities into a text model and conducted an in silico evaluation using virtual cases (Dataset A). These cases consist of simulated patient data derived from outpatient records. To ensure the cohort’s characteristics are representative of real-world clinical settings, we determined the total number of cases per subspecialty based on outpatient volumes over the past 3 years. We randomly selected cases across subspecialties to cover the predefined set of 50 disease types (Supplementary Data4)。These 50 disease types were chosen based on their prevalence rates in each subspecialty and their diagnostic feasibility without sole dependence on physical examinations.Our goal was to gather about 100 cases for general outpatient clinics and the cornea subspecialty, and ~50 cases for other subspecialties.
During the evaluation process, researchers conducted data entry for each case as a new session, ensuring that chatbot responses were generated solely based on that specific case, without any prior input from other cases. Our primary objective was to achieve a sensitivity of ≥ 90% and a specificity of ≥ 95% for diagnosing common disease types that ranked in the top 1–3 based on outpatient volumes over the past three years within each subspecialty. The disease types include dry eye syndrome, allergic conjunctivitis, conjunctivitis, myopia, refractive error, visual fatigue, strabismus, keratitis, pterygium, cataract, glaucoma, vitreous opacity, retinal detachment, ptosis, thyroid eye disease, eyelid mass, chemical ocular trauma, and other eye injuries. For disease types that had failed to meet these performance thresholds and had the potential to be diagnosed through imaging, we would develop an image-based diagnostic system. Additionally, regarding triage outcomes, our secondary goal was to achieve a positive predictive value of ≥ 90% and a negative predictive value of ≥ 95%. Since predictive values are significantly influenced by prevalence, diseases with prevalence below the 5th percentile threshold are excluded from the secondary outcome analysis.
Silent evaluation and early clinical evaluation of IOMIDS
After developing the text model and two multimodal models, all three were integrated into IOMIDS and installed on two iPhone 13 Pro devices to conduct a two-stage cross-sectional study, comprising silent evaluation and early clinical evaluation. During the silent evaluation, researchers collected patient gender, age, chief complaint, medical history inquiries, slit-lamp captured images, and smartphone captured images without disrupting clinical activities (Dataset G). If researchers encountered a specific chatbot query for which the answer could not be found in electronic medical histories, patients would be followed up with telephone interviews on the same day as their clinical visit. Based on sample size calculations33, we aimed to collect 25 cases each for cataract, keratitis, and pterygium, along with another 25 cases randomly selected for other diseases.Following data collection, we conducted data analysis.If the data did not meet predefined standards, further sample expansion was considered.These standards were set as follows: the primary outcome aimed to achieve a sensitivity of ≥ 85% and a specificity of ≥ 95% for diagnosing cataract, keratitis, and pterygium;the secondary outcome aimed to achieve a positive predictive value of ≥ 85% and a negative predictive value of ≥ 95% for subspecialty triage after excluding diseases with a prevalence below the 5th percentile临界点。To further investigate whether the completeness of medical histories would influence the diagnostic and triage performance of the text model, we randomly selected about half of the cases from Dataset G and re-entered the doctor-patient dialogs.For the chatbot queries that should be answered via telephone interviews, the researcher uniformly marked them as “no information availableâ€.The changes in diagnostic and triage accuracy were subsequently analyzed.
The early clinical evaluation was conducted at Fudan Eye & ENT Hospital for internal validation and at the Affiliated Eye Hospital of Nanjing Medical University and Suqian First Hospital for external validation. Both validations included two settings: data collection by researchers and self-completion by patients. Data collection by researchers was conducted at the internal center from July 21 to August 20, 2023, and at the external centers from August 21 to October 31, 2023. Self-completion by patients took place at the internal center from November 10, 2023, to January 10, 2024, and at the external centers from January 20 to March 10, 2024. During the patient-entered data stage, researchers guided users (patients, parents, and caregivers) through the entire process, which included selecting an appropriate testing environment, accurately entering demographic information and chief complaints, providing detailed responses to chatbot queries, and obtaining high-quality eye photos. It is important to note that when collecting smartphone images using the IOMIDS system, we provide guidance throughout the image capture process. Notifications are issued for problems such as excessive distance, overexposure, improper focus, misalignment, or if the eye is not open (Supplementary Fig.8)。In both the researcher-collected data phase and the patient-entered data phase, the primary goal was to achieve a sensitivity of ≥ 75% and a specificity of ≥95% for diagnosing ophthalmic diseases, excluding those with a prevalence below the 5th percentile threshold.The secondary goal was to achieve a positive predictive value of ≥ 80% and a negative predictive value of ≥95% for subspecialty triage.
Comparison of inter-model and model-expert agreement
Five expert ophthalmologists with professor titles, three ophthalmology trainees (residents), and two junior doctors without specialized training participated in the study. The expert ophthalmologists were responsible for reviewing all cases, and when at least three experts reached a consensus, their diagnostic results were considered the gold standard. The trainees and junior doctors were involved solely in the clinical evaluation phase for Datasets 4-5 and 9-10, independently providing diagnostic results for each case. Additionally, GPT-4.0 and the domestic large language model Qwen, both with image-text diagnostic capabilities, were included to generate diagnostic results for the same cases. The diagnostic accuracy and consistency of these large language models were then compared with those of ophthalmologists at different experience levels.
Rating for user satisfaction and response quality
User satisfaction with the entire human-computer interaction experience was evaluated by both patients and researchers using a 1–5 scale (not satisfied, slightly satisfied, moderately satisfied, satisfied, and very satisfied) during early clinical evaluation study. Neither the patients nor the researchers were aware of the correctness of the output when assessing satisfaction. Furthermore, 50 chatbot final responses were randomly selected from all datasets generated during both silent evaluation and early clinical evaluation. Three independent researchers, who were blinded to the model types and reference standards, assessed the quality of these chatbot final responses across six aspects. Overall information quality was assessed using DISCERN (rated from 1 = low to 5 = high). Understandability and actionability were evaluated with the Patient Education Materials Assessment Tool for Printable Materials (PEMAT-P), scored from 0–100%. Misinformation was rated on a five-point Likert scale (from 1 = none to 5 = high). Empathy was also rated using a 5-point scale (not empathetic, slightly empathetic, moderately empathetic, empathetic, and very empathetic). Readability was analyzed using the Chinese Readability Index Explorer (CRIE;http://www.chinesereadability.net/CRIE/?LANG=CHT), which assigns scores corresponding to grade levels: 1–6 points for elementary school (grades 1–6), 7 points for middle school, and 8 points for high school.
统计分析
All data analyses were conducted using Stata/BE (version 17.0). Continuous and ordinal variables were expressed as mean ± standard deviation. Categorical variables were presented as frequency (percentage). For baseline characteristics comparison, a two-sidedt-test was used for continuous and ordinal variables, and the Chi-square test or Fisher’s exact test was employed for categorical variables, as appropriate. Diagnosis and triage performance metrics, including sensitivity, specificity, accuracy, positive predictive values, negative predictive values, Youden index, and prevalence, were calculated for each dataset using the one-vs.-rest strategy. Diseases with a prevalence below the 5th percentile threshold were excluded from subspecialty parameter calculations. Reference standards and the correctness of the IOMIDS diagnosis and triage were established according to the protocol article33。Specifically, overall diagnostic accuracy was defined as the proportion of correctly diagnosed cases out of the total cases in each dataset, while overall triage accuracy was the proportion of correctly triaged cases out of the total cases. Similarly, disease-specific diagnostic and triage accuracies were calculated as the proportion of correctly diagnosed or triaged cases per disease. Diseases were categorized into six classifications based on lesion location: primary anterior segment diseases (cataract, keratitis, pterygium), other anterior segment diseases, fundus and optic nerve diseases, intraorbital diseases and emergencies, eyelid diseases, and visual disorders. Diagnostic and triage accuracies were calculated for each category. Fisher’s exact test was used to compare accuracies of different models within each category.Univariate logistic regression was performed to identify potential factors influencing diagnostic and triage accuracy. Factors with
p
 < 0.05 were further analyzed using multivariate logistic regression, with odds ratios (OR) and 95% confidence intervals (CI) calculated. Subgroup analyses were conducted for significant factors (e.g., disease classification) identified in the multivariate analysis. Notably, age was dichotomized using the mean age of all patients during the early clinical evaluation stage for inclusion in the logistic regression. Additionally, ROC curves for cataract, keratitis, and pterygium were generated in Dataset D and Dataset E using image-based diagnosis as the gold standard. The area under the ROC curve (AUC) was calculated for each curve. Agreement between answers provided by doctors and LLMs was quantified through calculation of Kappa statistics, interpreted in accordance with McHugh’s recommendations20。During the evaluation of user satisfaction and response quality, a two-sided t-test was used to compare different datasets across various metrics.Quality scores from three independent evaluators were averaged before statistical analysis.在这项研究中,pvalues of <0.05 were considered statistically significant.
数据可用性
The data that support the findings of this study are divided into two groups: published data and restricted data. The authors declare that the published data supporting the main results of this study can be obtained within the paper and its Supplementary Information. For research purposes, a representative image deidentified using masks on patient’s face in this study is available. In the case of noncommercial use, researchers can contact the corresponding authors for access to the raw data. Due to portrait rights and patient privacy restrictions, restricted data, including raw videos, are not provided to the public.
代码可用性
The code for the prompt engineering aspect of our work is embedded within a Java backend development system, making it tightly integrated with our proprietary infrastructure. Due to this integration, we are unable to publicly release this specific portion of the code. However, the image processing component of our system utilizes open-source models, specifically ResNet-50 and YOLOv7, which are readily available on GitHub and other repositories. Readers interested in the image processing methodologies we employed can easily access and utilize these models from the following sources: ResNet-50:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/resnet.py。YOLOv7:https://github.com/WongKinYiu/yolov7。We encourage readers to explore these repositories for implementation details and further insights into the image processing techniques used in our study.
参考
Poon H. Multimodal generative AI for precision health.nejm ai https://ai.nejm.org/doi/full/10.1056/AI-S2300233(2023)。
Tan, T. F. et al. Artificial intelligence and digital health in global eye health: opportunities and challenges.柳叶刀球。健康 11, 1432–1443 (2023).
文章一个 Google Scholar一个
Wagner, S. K. et al. Development and international validation of custom- engineered and code-free deep-learning models for detection of plus disease in retinopathy of prematurity: a retrospective study.柳叶刀数字。健康 5, E340–E349 (2023).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Xu, P. S., Chen, X. L., Zhao, Z. W. & Shi, D. L. Unveiling the clinical incapabilities: a benchmarking study of GPT-4V(ision) for ophthalmic multimodal image analysis.br。J. Ophthalmol。 108, 1384–1389 (2024).
Antaki, F., Chopra, R. & Keane, P. A. Vision-language models for feature detection of macular diseases on optical coherence tomography.JAMA OPHTHALMOL。 142, 573–576 (2024).
文章一个 PubMed一个 Google Scholar一个
Wu, X. H. et al. Cost-effectiveness and cost-utility of a digital technology-driven hierarchical healthcare screening pattern in China.纳特。社区。 15, 3650 (2024).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Singhal,K。等。Large language models encode clinical knowledge.自然 620, 172–180 (2023).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Mihalache, A. et al. Accuracy of an artificial intelligence chatbot’s interpretation of clinical ophthalmic images.JAMA OPHTHALMOL。 142, 321–326 (2024).
文章一个 PubMed一个 Google Scholar一个
Lim, Z. W. et al. Benchmarking large language models’ performances for myopia care: a comparative analysis of ChatGPT-3.5, ChatGPT-4.0, and Google Bard.Ebiomedicine 95, 104770 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Lyons R. J., Arepalli S. R., Fromal O., Choi J. & D. Jain N. Artificial intelligence chatbot performance in triage of ophthalmic conditions.能。J. Ophthalmol。 59, e301–e308 (2023).
Ayers, J. W. et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum.JAMA Int.医学 183, 589–596 (2023).
文章一个 Google Scholar一个
Li, J. H. et al. Class-aware attention network for infectious keratitis diagnosis using corneal photographs.comp。生物。医学 151, 106301 (2022).
文章一个 Google Scholar一个
Chen, W. B. et al. Early detection of visual impairment in young children using a smartphone-based deep learning system.纳特。医学 29, 493–503 (2023).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Qian, C. X. et al. Smartphone-acquired anterior segment images for deep learning prediction of anterior chamber depth: a proof-of-concept study.正面。医学 9, 912214 (2022).
文章一个 Google Scholar一个
Khan, S. M. et al. A global review of publicly available datasets for ophthalmological imaging: barriers to access, usability, and generalisability.柳叶刀数字。健康 3, E51–E66 (2021).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Nath, S., Marie, A., Ellershaw, S., Korot, E. & Keane, P. A. New meaning for NLP: the trials and tribulations of natural language processing with GPT-3 in ophthalmology.br。J. Ophthalmol。 106, 889–892 (2022).
文章一个 PubMed一个 Google Scholar一个
Dow, E. R. et al. The collaborative community on ophthalmic imaging roadmap for artificial intelligence in age-related Macular degeneration.眼科 129, E43–E59 (2022).
文章一个 PubMed一个 Google Scholar一个
Brandao-de-Resende, C. et al. A machine learning system to optimise triage in an adult ophthalmic emergency department: a model development and validation study.Eclinicalmedicine 66, 102331 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Zhou, H. Y. et al. A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics.纳特。生物。工程。 7, 743–755 (2023).
文章一个 PubMed一个 Google Scholar一个
Thirunavukarasu,A。J.等。Large language models approach expert-level clinical knowledge and reasoning in ophthalmology: A head-to-head cross-sectional study.PLOS Digit.健康 3, e0000341 (2024).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Shemer, A. et al. Diagnostic capabilities of ChatGPT in ophthalmology.Graefes Arch.临床经验。眼科。 262, 2345–2352 (2024).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Wang,L。等。Feasibility assessment of infectious keratitis depicted on slit-lamp and smartphone photographs using deep learning.int。J. Med。通知。 155, 104583 (2021).
文章一个 PubMed一个 Google Scholar一个
Askarian, B., Ho, P. & Chong, J. W. Detecting cataract using smartphones.IEEE J. Transl.工程。Health Med. 9, 3800110 (2021).
文章一个 PubMed一个 Google Scholar一个
Liu,Y。等。Accurate detection and grading of pterygium through smartphone by a fusion training model.br。J. Ophthalmol。 108, 336–342 (2024).
文章一个 PubMed一个 Google Scholar一个
Dong,L。等。Artificial intelligence for screening of multiple retinal and optic nerve diseases.JAMA NetW。打开 5, e229960 (2022).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kang, E. Y.-C.等。A multimodal imaging–based deep learning model for detecting treatment-requiring retinal vascular diseases: model development and validation study.JMIR Med.通知。 9, e28868 (2021).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Zandi, R. et al. Exploring diagnostic precision and triage proficiency: a comparative study of GPT-4 and bard in addressing common ophthalmic complaints.Bioeng。巴塞尔 11, 120 (2024).
Nissen, M. et al. The effects of health care chatbot personas with different social roles on the client-chatbot bond and usage intentions: development of a design codebook and web-based study.J. Med。int。res。 24, e32630 (2022).
Xiong,J。等。Multimodal machine learning using visual fields and peripapillary circular OCT scans in detection of glaucomatous optic neuropathy.眼科 129, 171–180 (2022).
文章一个 PubMed一个 Google Scholar一个
Zong,H。等。Performance of ChatGPT on Chinese national medical licensing examinations: a five-year examination evaluation study for physicians, pharmacists and nurses.Bmc Med.edu。 24, 143 (2024).
文章一个 Google Scholar一个
Pushpanathan K. et al. Popular large language model chatbots’ accuracy, comprehensiveness, and self-awareness in answering ocular symptom queries.Iscience 26, 108163 (2023).
Liu, X. C. et al. Uncovering language disparity of ChatGPT on retinal vascular disease classification: cross-sectional study.J. Med。int。res。 26, e51926 (2024).
Peng, Z. et al. Development and evaluation of multimodal AI for diagnosis and triage of ophthalmic diseases using ChatGPT and anterior segment images: protocol for a two-stage cross-sectional study.正面。艺术品。Intell。 6, 1323924 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
致谢
We sincerely appreciated the support from Yuhang Jiang (Jiangsu Health Vocational College) for assisting with data collection, Xiang Zeng (Fudan University) for assisting with image formatting, and Shi Yin and Xingxing Wu for assisting with auditing the clinical data.作者声明了本文的研究,作者身份和/或出版的财政支持。This work was supported by Shanghai Hospital Development Center (Grant Number SHDC2023CRD013), National Key R&D Program of China (Grant Number 2018YFA0701700), National Natural Science Foundation of China (Grant Numbers 82371101, U20A20170, 62271337, 62371328, 62371326), Zhejiang Key Research and Development Project (Grant Number 2021C03032), Natural Science Foundation of Jiangsu Province of China (Grant Numbers BK20211308, BK20231310).
道德声明
竞争利益
作者没有宣称没有竞争利益。
附加信息
Publisher’s note关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
补充信息
权利和权限
开放访问This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Ma, R., Cheng, Q., Yao, J.
等。Multimodal machine learning enables AI chatbot to diagnose ophthalmic diseases and provide high-quality medical responses.NPJ数字。医学 8, 64 (2025). https://doi.org/10.1038/s41746-025-01461-0
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41746-025-01461-0