
AI数据集和学术研究和出版市场报告2030
市场规模和趋势
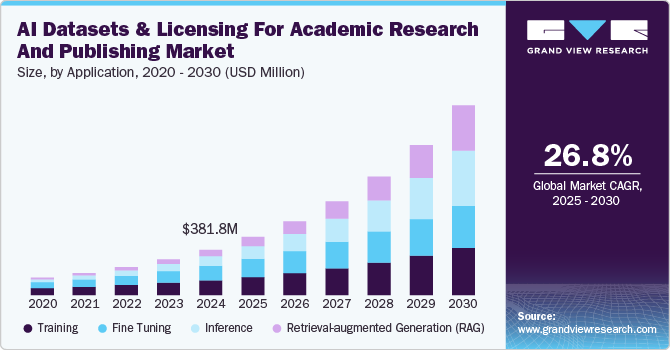
全球AI数据集和学术研究和出版市场规模的许可在2024年估计为3.818亿美元,预计从2025年到2030年将以26.8%的复合年增长率。,验证和测试人工智能模型。这些数据集可能包括文本,图像,音频,视频和数值信息,这些信息来自公共记录,专有研究或用户生成的内容。
许可是指管理这些数据集访问,使用和重新分布的法律框架,以确保知识产权和道德合规性。在学术研究和出版中,AI数据集和许可促进了机器学习的突破,自然语言处理,图像识别和预测分析。应用程序涵盖了各种领域,例如用于自动化内容审查,引用分析和元数据丰富的学术出版;研究驱动的模拟;和用于预测建模的医疗保健。随着开放科学计划的兴起,道德许可是促进可及性的一部分,同时维护隐私和知识产权。
AI数据集和许可的市场是由于对准确的AI模型培训所需的高质量,不同数据集的需求激增。的增殖机器学习整个学术界的AI应用程序提高了针对利基研究领域的专业数据集的需求。此外,政府和教育机构的开放数据计划具有增强的可访问性,从而促进了创新。
但是,存在重大限制因素。道德问题,特别是与数据隐私和同意有关的问题,加强了监管审查,使组织对自由共享和许可数据的挑战。获取或许可高级数据集的成本也为小型机构带来了障碍。此外,数据失衡,偏见和缺乏标准化许可框架在公平访问方面造成了挑战。这些因素共同塑造了在学术背景下AI数据集的采用和开发,需要采取平衡的方法来解决隐私,公平和负担能力问题。
AI数据集和许可行业的特征是快速创新和多元化。越来越多地针对特定学科的数据集,例如基因组学正在开发气候建模和社会科学。市场还以大学,人工智能公司和数据提供商之间的合作为特征,以创建符合道德和法律标准的存储库。地理扩展是值得注意的,由于既定的研究基础设施和监管框架,北美和欧洲在创新和采用方面领先。亚太地区正在成为主要贡献者,这是由AI研究和教育改革的投资驱动的。此外,开放访问存储库的趋势是重新定义传统的许可规范,从而促进了竞争性但协作的市场环境。
亚洲,非洲和拉丁美洲等地区的新兴市场为AI数据集和许可提供了显着的增长机会。这些市场正在大量投资于AI驱动的教育和研究,以弥合技术差距并增强全球竞争力。公共记录的广泛数字化和政府对AI创新的支持正在为市场扩张创造沃土。通过国际合作伙伴关系和资金来减轻诸如对不同数据集,新生法律框架和基础设施障碍的访问权限之类的挑战。诸如开放数据平台和跨境研究合作之类的举措正在加速采用许可数据集。随着这些地区继续发展其学术和技术能力,预计未来几年它们对全球市场的贡献将显着增长。
申请见解
该培训部门在2024年占32.4%的主要收入份额。AI培训需要多样化的高质量数据集,以建立能够解决复杂学术问题的强大模型。这些数据集对于开发AI解决方案(例如预测分析,自然语言处理和图像识别,广泛用于研究和发布工作流程。在基因组学,社会科学和语言研究等学科中,对培训数据集的需求特别强,大规模数据推动了创新。专有数据集来自专业研究或特定于行业的数据库,由于其相关性和可靠性而主导了该细分市场。此外,受监督和无监督的学习技术的进步继续推动对注释和标记的数据集的需求。随着AI的采用在学术机构中的增长,培训数据集的作用仍然是核心,确保该细分市场在市场上保持领导地位。
在AI数据集和许可行业中,检索功能增强的一代(RAG)领域正在成为增长最快的应用程序。这种创新的方法将生成的AI模型与信息检索技术相结合,以增强生成的产出的准确性和相关性。在学术研究和出版中,越来越多地用于诸如自动文献综述,实时内容生成和动态引用分析之类的任务。
该细分市场的快速增长是由自然语言处理的进步以及大型语言模型与域特异性数据库的整合所驱动的。RAG应用程序依赖于许可的数据集,这些数据集可提供对知识的庞大,结构化存储库的访问,从而确保其输出可信并且上下文准确。它提高生产率并降低学术环境中的手动努力的潜力使其具有很高的吸引力。随着复杂的研究疑问的兴起和实时知识的需求,RAG预计将在未来几年见证持续的增长。
客户类型的见解
大型语言模型(LLM)建筑商细分市场占2024年学术研究和出版行业的AI数据集和许可中的主要收入份额,占整个市场的37.5%的市场份额。这些组织,包括科技公司和研究实验室,都需要广泛的高质量数据集来开发最先进的语言模型。LLM构建者利用这些数据集培训基础模型,这些模型为许多学术应用,例如自动化内容摘要,语义搜索和智能辅导系统。
这一领域的主导地位是由研究和开发的大量投资以及与学术机构的合作进行的,以访问专有和开源数据集。LLM构建者优先考虑确保法律合规性和数据完整性的许可框架,从而使专有和定制许可的数据集备受追捧。随着LLMS继续发展和扩展其能力,该细分市场可能仍然是对学术领域许可数据集需求的关键驱动力。
应用程序开发人员细分市场是AI数据集和许可行业中增长最快的客户细分市场。这些开发人员为学术研究和发布创建了专门的AI驱动工具,例如窃检测软件,知识管理系统和内容建议引擎。该细分市场的增长是由于满足特定学术需求(包括利基研究领域和跨学科研究)的定制应用的需求不断增长的推动。应用程序开发人员通常依靠开放访问和特定领域的数据集来确保其工具准确且相关。
此外,模块化API和预培训模型的可用性使较小的开发团队授权进入市场,进一步推动增长。随着学术机构越来越多地采用AI驱动的解决方案来提高效率和创新,应用开发商在塑造市场中的作用将大大扩展。
许可类型的见解
专有的许可部门在2024年主导了AI数据集和许可行业,因为它能够提供针对特定的学术和研究需求量身定制的独家高质量数据集。机构和组织更喜欢专有许可证,可以确保访问通常为专业应用程序策划,注释和设计的高级数据。这种许可类型可确保数据隐私并遵守法律和道德标准,使其成为医疗保健,气候科学和工程等领域高风险研究的首选选择。
专有许可还允许许可方提供增值服务,例如定期更新和技术支持,进一步增强其吸引力。随着学术研究人员之间的竞争加剧,对保持竞争优势的专有数据集的依赖确保了这一细分市场在市场上仍然占主导地位。
开放访问和公共许可部门是AI数据集和许可行业中增长最快的细分市场,这是对可访问和具有成本效益的数据的不断增长的驱动。这些许可通过允许研究人员和开发人员自由访问和共享数据集来促进合作,从而促进学术研究和出版中的创新。
开放的许可模型,例如创意共享和开放数据存储库,在优先考虑透明度和包容性的机构中特别受欢迎。政府和学术组织正在积极支持开放数据计划,以民主化获得研究资源的访问。跨学科研究的兴起也推动了这种增长,在该研究中,共享的数据集可以在多个领域进行协作。随着开放科学倡议的增长,预计开放访问和公共许可的采用将增长,使其成为市场上的变革力量。
垂直见解
生命科学和制药细分市场主导了AI数据集和学术研究和出版市场的许可,因为它们依赖于数据驱动的创新研究。这些部门使用AI数据集用于药物发现,基因组分析和临床试验优化。许可的数据集对于确保遵守严格的监管标准的同时保持数据质量和安全性至关重要。
拥有患者记录,分子数据和试验结果的专有数据集被广泛用于开发预测模型并加速研发过程。学术机构,生物技术公司和数据提供商之间的合作进一步加强了该垂直行业的主导地位。随着生命科学和药品继续对解决全球健康挑战的AI驱动研究优先考虑,他们对许可数据集的需求有望保持强大。
")
健康科学领域代表了AI数据集和许可市场中增长最快的垂直领域,这是由于人工智能对医学研究,公共卫生和个性化医学的采用越来越多。该垂直效力利用数据集用于疾病建模,医疗保健资源计划和患者结果分析等应用程序。医疗记录的快速数字化和AI在公共卫生计划中的整合是增长的主要驱动力。
开放式访问和道德采购的数据集在此细分市场中特别有价值,因为它们促进了协作研究并公平地访问数据。随着政府和机构投资于应对医疗挑战的AI技术,新兴市场也有助于增长。随着对预防医学和人口健康的越来越重视,许可数据集在推进健康科学方面的作用将大大扩展。
区域见解
北美人工智能AI数据集和学术研究和出版市场的许可占据了全球市场的主导地位,在2024年占39.4%的领先份额。归因于该市场增长的因素包括先进的技术基础设施,建立的研究机构以及强大的政府资金资金用于AI创新。该地区的统治地位是由学术界,私营企业和政府机构之间广泛合作的驱动,从而能够开发高质量的专业数据集。

北美从强大的监管框架中受益,该框架可确保遵守数据隐私和知识产权法,从而促进信任和创新。此外,领先的人工智能公司和研究实验室的存在为数据集许可和开发创造了一个蓬勃发展的生态系统。凭借对AI驱动的教育和学术出版的大量投资,预计北美将保持其在全球市场中的领导地位。
美国AI数据集和学术研究和出版市场趋势的许可
美国的学术研究和出版市场的AI数据集和许可是AI数据集和许可市场中北美优势的主要驱动力。它拥有建立和许可高质量数据集的主要大学,研究组织和专注于AI的公司的丰富生态系统。联邦倡议,例如国家科学基金会等机构的《国家AI倡议法》和资金,加速了AI研究,进一步增强了对数据集的需求。美国还从建立的知识产权框架中受益,确保法律合规和促进创新。此外,学术界和私人实体之间的合作伙伴关系导致创建了针对特定研究应用程序量身定制的专有数据集。凭借其在开发尖端AI技术方面的领导地位,美国仍然是全球AI市场中学术研究和出版的中心枢纽。
加拿大AI数据集和学术研究和出版市场许可在强大的AI研究生态系统和政府对创新的支持的推动下,市场正在经历大幅增长。该国是几个领先的AI研究中心和计划的所在地,例如Vector Institute和Cifar,它们积极地有助于数据集的开发和许可。加拿大对道德AI实践及其强大的数据隐私法的关注使其成为学术研究的有吸引力的目的地。此外,政府资金和公私伙伴关系促进了开放式数据集的创建,从而促进了学术出版的包容性。随着对AI驱动的教育和研究的投资不断增加,加拿大正迅速成为全球市场的关键参与者,并补充了北美的统治地位。
亚太AI数据集和学术研究和出版市场趋势的许可
亚太地区的学术研究和出版市场的AI数据集和许可正在见证AI数据集和许可市场中最快的增长,这是由于在学术和研究机构中迅速采用AI技术的推动力。该地区的政府正在积极投资AI创新和基础设施,促进了数据集开发和许可的有利环境。大学与人工智能公司之间的合作越来越多,导致创建了迎合各种学科的专业数据集。像中国和印度这样的国家处于最前沿,通过大规模数字化计划以及将AI整合到教育系统中,推动了区域增长。侧重于弥合技术差距并促进国际伙伴关系,亚太地区有望在市场上持续增长。中国
AI数据集和学术研究和出版市场许可 是亚太地区AI数据集和许可市场增长的主要贡献者。在新一代人工智能开发计划等政府倡议的支持下,该国对AI研发的大量投资加剧了对许可数据集的需求。中国学术机构和科技公司越来越多地合作,以创建针对AI应用程序量身定制的专有和开放式数据集。此外,公共记录的快速数字化以及该国对成为全球人工智能领导者的强调进一步加速了增长。随着中国继续扩大其学术和研究能力,预计其对全球AI数据集市场的影响将有所加强。
AI数据集和学术研究和出版市场许可 在印度在AI数据集和许可市场中成为关键参与者,这是由于其扩大的AI生态系统和强调教育和研究中数字化转型的驱动。诸如国家AI战略和促进数字素养的计划之类的政府倡议促进了AI驱动的学术研究的发展。印度的种群和多语言环境使其成为自然语言处理和其他AI应用程序的独特数据集。该国还受益于越来越多的公私合作伙伴关系,这些伙伴关系支持开放式数据集的创建和许可。随着对AI教育和研究的投资不断提高,印度在全球市场上有了显着增长的位置。
欧洲AI数据集和学术研究和出版市场趋势的许可
欧洲AI数据集和学术研究和出版市场的许可正经历AI数据集和许可市场的显着增长,其基础是其强大的学术和研究基础设施,并强调道德AI实践。欧洲联盟的倡议,例如Horizon Europe和AI法案,在确保数据隐私和安全性的同时促进了高质量数据集的开发和共享。
大学,研究组织和人工智能公司之间的合作导致创建了针对各种学科的专业数据集。法国,德国和英国等国家在AI研究和教育方面的强大投资驱动着该地区的增长。欧洲专注于促进创新和遵守道德标准,可确保其在全球市场的持续扩展。
这AI数据集和学术研究和出版市场许可 在法国是欧洲的AI数据集和许可市场的杰出参与者,这是政府对AI研究和教育的强烈支持和投资的驱动。诸如国家人工智能战略之类的举措促进了AI数据集的开发,并促进了学术机构和私人组织之间的合作。法国研究中心和大学正在积极促进开放访问数据集的创建,从而促进了学术出版的创新。此外,该国强调道德AI实践,并遵守欧盟一般数据保护法规(GDPR)增强了对许可数据集的信任。随着其在AI研究中的作用越来越大,法国有望显着影响区域和全球市场。
中东与非洲(MEA)AI数据集和学术研究和出版市场趋势的许可
中东和非洲(MEA)AI数据集以及用于学术研究和出版市场的许可,在AI技术和教育的投资增加的推动下,AI数据集和许可市场的显着增长。该地区的政府正在积极促进AI驱动的计划,例如智慧城市和教育中的数字化转型,这些计划需要高质量的数据集。学术机构越来越多地与全球AI公司合作,以开发并许可根据区域需求量身定制的数据集。此外,采用开放式数据集正在获得势头,从而可以公平地访问研究资源。随着对AI研究和教育的持续投资,MEA地区将扩大其在全球市场的影响力。这
阿联酋AI数据集和学术研究和出版市场许可 是中东和非洲地区AI创新的最前沿,在AI数据集和许可市场中取得了长足的进步。阿联酋人工智能战略2031和对AI驱动教育和研究的投资等政府倡议加剧了对许可数据集的需求。
该国强调成为全球AI枢纽,导致学术机构,研究中心和技术公司之间的合作,以创建高质量的专业数据集。此外,阿联酋强大的数字基础设施和监管框架可确保遵守数据隐私和知识产权标准。随着阿联酋继续优先考虑AI研究和教育,其在区域和全球市场中的作用有望大大增长。
关键AI数据集和学术研究和出版公司Insights的许可
AI数据集中的一些关键公司和学术研究和出版市场的许可包括Elsevier,Springer Nature,电气和电子工程师研究所(EEE),EEE),Wolters Kluwer N.V.,Proquest(Clarivate的一部分),数字科学,Sage Publishing,Zenodo(CERN数据中心),Datacite和Figshare(数字科学与研究培训有限公司)。组织致力于增加客户群以在行业中获得竞争优势。因此,主要参与者正在采取几项战略计划,例如合并和收购,以及与其他主要公司的合作伙伴关系。
-
Elsevier是一家全球信息分析公司,成立于1880年,总部位于荷兰阿姆斯特丹,专门为包括科学,健康和技术在内的各个行业的专业人员提供数据,内容和工具。该公司主要通过其广泛的学术和科学期刊,书籍和数据库提供广泛的数据集和分析解决方案。Elsevier的产品包括针对研究人员,临床医生和其他专业人员的数据驱动工具,重点是允许灵活访问高质量的,同行评审的内容的许可模型。该公司专注于医疗保健,生命科学,工程学和社会科学等应用领域,提供推动创新,改善患者结果并提高科学发现的见解。
-
Springer Nature成立于2015年,总部位于德国柏林。该公司致力于通过提供广泛的数据集,许可选项和专注的应用领域来推进研究和教育。他们的产品包括访问支持各种研究领域的广泛数据库和期刊,使研究人员和教育工作者能够利用高质量的资源。该公司强调创新的产品和服务,以促进发现和学习,以满足各种学术和专业需求。
关键的AI数据集和学术研究和出版公司的许可:
以下是领先的公司AI数据集和学术研究和出版市场许可。这些公司共同拥有最大的市场份额并决定了行业趋势。
- Elsevier
- 施普林格
- 电气和电子工程师研究所(EEE)
- 沃尔特·克鲁维尔(Wolters Kluwer N.V.)
- 泰勒和弗朗西斯(Informa plc部)
- 美国化学学会
- 清晰
- ProQuest(Clarivate的一部分)
- 数字科学
- 鼠尾草出版
- Zenodo
- 数据属
- 小花
最近的发展
-
2024年5月Elsevier宣布与南加州电子图书馆财团(SCELC)建立合作伙伴关系,以扩大开放式出版机会。这项合作旨在通过支持机构过渡到开放访问模型来增强对研究的访问。通过这种合作伙伴关系,Scelc成员将受益于精简的工作流程,并降低与Elsevier期刊上发布相关的成本。该倡议反映了Elsevier致力于促进开放科学并提高学术研究的可见性。
-
2024年7月31日,施普林格与卡塔尔国家图书馆签署了中东第一次开放访问书协议。该协议允许与卡塔里机构有隶属关系的作者获得出版书籍开放访问的资金,从而促进更广泛的研究传播
-
2024年7月,Rightdirect,一个子公司版权清除中心(CCC),引入了针对学术研究人员和机构需求量身定制的AI驱动许可合规性工具。通过自动化许可协议的解释和执行,该工具代表了数据许可管理方面的重要一步。它旨在最大程度地减少法律复杂性,可为研究人员提供有关各种数据集允许用途的见解,从而确保遵守许可条款并保护知识产权。这项创新不仅降低了意外滥用的风险,而且还促进了研究人员,内容创建者和数据提供商之间的信任,为更多开放和协作的研究生态系统铺平了道路。
AI数据集和学术研究和出版市场报告范围的许可
|
报告属性 |
细节 |
|
2025年的市场规模价值 |
USD 48680万 |
|
2030年收入预测 |
15.9亿美元 |
|
增长率 |
从2025年到2030年的复合年增长率为26.8% |
|
实际数据 |
2018-2024 |
|
预测期 |
2025-2030 |
|
定量单位 |
从2025年到2030年的收入为100万美元/亿美元和复合年增长率 |
|
报告覆盖范围 |
收入预测,公司排名,竞争格局,增长因素和趋势 |
|
段范围 |
应用程序,客户类型,许可类型,垂直,区域 |
|
区域范围 |
北美;欧洲;亚太地区;拉美;中东和非洲 |
|
国家范围 |
我们。;加拿大;墨西哥;英国;德国;法国;中国;日本;印度;韩国;澳大利亚;巴西;阿联酋KSA;南非 |
|
关键公司介绍了 |
Elsevier;施普利特的自然;电气和电子工程师研究所(EEE);沃尔特·克鲁威(Wolters Kluwer)n.v。;Taylor&Francis(Informa plc部);美国化学学会;清晰ProQuest(Clarivate的一部分);数字科学;鼠尾草出版;Zenodo;数据属;和figshare |
|
自定义范围 |
免费报告自定义(最多等同于8位分析师工作日)。对国家,地区和细分市场范围的增加或更改 |
|
定价和购买选项 |
可用定制的购买选项来满足您的确切研究需求。 探索购买选项 |
用于学术研究和出版市场报告细分的全球AI数据集和许可
该报告提供了全球,区域和国家级别的收入增长预测,并对2018年至2030年的每个子发现的最新行业趋势进行了分析。对于这项研究,Grand View Research已将全球AI数据集和分布基于应用,客户类型,许可类型,垂直和地区的学术研究和出版市场报告:
-
应用 前景(收入,2018年至2030年)
-
训练
-
微调
-
检索授权一代(RAG)
-
推理
-
-
客户类型Outlook(收入,百万美元,2018年至2030年)
-
大型语言模型(LLM)建筑商
-
应用程序开发人员
-
企业
-
研究机构和学术界
-
-
许可类型Outlook(收入,百万美元,2018年至2030年)
-
专有许可
-
基于订阅
-
开放访问和公共许可
-
基于用法的许可
-
定制/企业许可
-
-
垂直(收入,百万美元,2018年至2030年)
-
生命科学和药品
-
健康科学
-
食品科学
-
化学
-
工程
-
材料科学
-
-
Regional Outlook (Revenue, USD Million, 2018 - 2030)
-
北美
-
我们。
-
加拿大
-
墨西哥
-
-
欧洲
-
英国
-
德国
-
法国
-
-
亚太地区
-
中国
-
日本
-
印度
-
澳大利亚
-
韩国
-
-
拉美
-
巴西
-
-
中东和非洲(MEA)
-
KSA
-
阿联酋
-
南非
-
-
关于这份报告的常见问题
b。The global AI datasets and licensing for academic research and publishing market size was estimated at USD 381.8 million in 2024 and is expected to reach USD 381.8 million in 2025.
b。The global AI datasets and licensing for academic research and publishing market is expected to grow at a compound annual growth rate of 26.8% from 2025 to 2030 to reach USD 1.59 billion by 2030.
b。North America dominated the AI datasets and licensing for academic research and publishing market with a share of 39.4% in 2024. The factors attributing to the growth of this market includes advanced technological infrastructure, established research institutions, and strong government funding for AI innovation. The region’s dominance is driven by extensive collaborations between academia, private enterprises, and government agencies, enabling the development of high-quality, specialized datasets.
b。Some key players operating in the AI datasets and licensing for academic research and publishing market include Key companies like Elsevier;施普利特的自然;Institute of Electrical and Electronics Engineers (EEE);Wolters Kluwer N.V.;Taylor & Francis (division of Informa plc);American Chemical Society;Clarivate;ProQuest (part of Clarivate);Digital Science;Sage Publishing;Zenodo;DataCite;and Figshare
b。Key factors that are driving the market growth include a surge in demand for high-quality, diverse datasets required for accurate AI model training. The proliferation of machine learning and AI applications across academia has heightened the need for specialized datasets tailored to niche research fields