
诊断口服和口咽癌和白细胞癌的图像识别的人工智能
作者:Wirth, Markus
介绍
头颈部鳞状细胞癌(HNSCC)是一种异质疾病,它来自口腔中的粘膜上皮,咽和喉1。尽管可以轻松地访问和可视化口腔和口腔咽,但大多数HNSCC在高级阶段被诊断出来。由于与人类乳头瘤病毒病毒(HPV)的关联,口咽鳞状细胞癌(OPSCC)的发生率上升,并且据估计,HPV感染与HPV+HNSCC的发展之间的长期潜伏期很长,据估计直到2060年,HNSCC的患病率才能反映出HPV疫苗接种的作用2。尽管与HPV阴性病例相比,HPV相关OPSCC患者的存活率更好,但迫切需要策略以实现早期诊断和预防。目前,尽管有液体活检技术,例如无细胞的人乳头瘤病毒DNA3,血小板4,还有许多其他5被调查。
早期癌症通常是无症状的,可以模仿良性疾病,从而降低了受影响个体的可能性。因此,筛选计划为早期发现提供了关键的机会6。此外,还可以通过视觉检查可访问前病变(OPL),包括白细胞,促红细胞洛基亚和发育不良的白血病以及肿瘤复发7,,,,8。在印度喀拉拉邦进行了最早针对人口口腔癌筛查的随机对照研究之一,在15年内筛查了87,655例口腔癌风险的患者。这导致口腔癌发病率降低,口腔癌死亡率显着降低了34%,强调了基于人群的筛查的潜在益处9。但是,资源,成本,时间和可用性的局限性需要创新的策略来克服这些挑战。
这些策略之一是人工智能的实施。人工智能(AI)以深度学习(DL)和自然语言处理(NLP)的形式(NLP)的形式,使大型语言模型(LLM)(如生成的预训练的变压器(GPT))能够开发10,,,,11。这些模型在很短的时间内访问大型数据集,并能够收集最近的研究信息,也可以将历史数据总结为现代方法的基础,以讨论肿瘤学案例12,,,,13,,,,14,包括头和颈癌15,,,,16。AI组织和结构数据的能力为这些工具提供了帮助甚至指导临床决策的机会17,,,,18。ChatGpt 4.0的最新功能之一是语音和图像识别功能,有望扩大当前医疗保健景观中这些工具的使用,其中包括鉴定医疗图像或皮肤病变中异常的应用19,,,,20。由于口腔和大多数口咽病变源自粘膜上皮,并且在大多数情况下很容易获得图像,因此Chatgpt的图像识别也可能检测到鳞状细胞癌或预防性病变。然后可以将此能力用作筛查工具,也可以在头颈部初始恶性肿瘤后进行肿瘤随访21。
这项探索性研究的主要目的是评估LLMS区分SCC,预立防性病变,良性或无病变状况的能力,以及提出下一个诊断步骤。在第二步中,添加了患者的临床病史,以模拟现实的临床环境。两名独立审阅者评估了结果,并分析了整体绩效,以洞悉Chatgpt 4.0在临床实践中的图像解释的潜在作用。
材料和方法
患者队列
这项研究包括口服和口咽鳞状细胞癌患者的临床图像,白细胞的图像以及没有口腔病理学的图像。这些图像始终以完全匿名的方式使用,任何可能允许识别患者的细节被删除。电子患者文件和MDT文件在诊断时提供了临床和组织学肿瘤特征以及患者年龄。这项研究由慕尼黑技术大学的Klinikum Rechts der Isar klinikum Rechts der Isar组成45例Otorhinolaryngology/Head and Neck Surgery系的患者。患者年龄从49岁到88岁。这项研究中的25张图像显示了鳞状细胞癌,而其中两个图像描绘了口咽病变。另外15张图像显示了口服白细胞,另外15张图像在口腔或口咽(两例)中没有病变。这些被用作控制机制。所有图像均由单个研究者拍摄,并来自受控图像数据库,其中成像协议是一致的。这些图像还需要清楚地显示无病变或无病变的区域而没有障碍物,并且没有预处理。在分析之前,另一个独立的头颈外科医生对数据集进行了审查,以确认所有图像符合研究的质量标准。为了确保患者的机密性,在与研究人员共享之前将数据匿名化,从而使患者识别不可能。这项研究得到了慕尼黑技术大学伦理委员会的批准。在补充表中描述了患者队列的特征1。从所有受试者和/或其法定监护人那里获得知情同意。人工智能/图像识别通过chatgpt提示格式和数据评估
Chatgpt 4.0是一个由AI驱动的聊天机器人,可供公众访问。
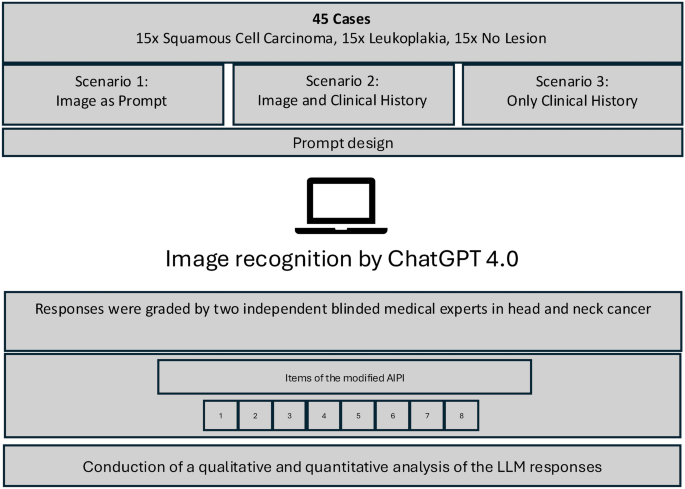
聊天机器人使用基于变压器的语言模型来生成类似人类的文本响应。互动是大多数时间基于用户通过网站界面提交问题(提示)的。然后,LLM可以分析用户查询中单词之间的上下文关系以提出响应。图像分析是Chatgpt最近添加的功能,并在本研究中进行了测试。研究设计,并在图中的流程图中显示。 1。

整体研究设计的流程图。研究工作流程的描述,包括通过Chatgpt 4.0识别图像识别的响应评分。两位独立审阅者对回答的评估。
评估LLM使用的研究的先决条件是严格的及时测试。因此,在选择最合适的提示之前对八个不同版本的提示进行了测试。除临床图像外,还采用了这种标准化的及时格式将患者的临床病史输入CATGPT。提示如下:一名患者出现了这种口腔内病变。什么是最可能的诊断和差异诊断?下一个诊断步骤是什么?当使用临床病史时,提示为患者(xx)。患者是(xx)饮酒和(xx)吸烟。患者还具有(xx)。患者发送了这张照片,并想知道最可能的诊断。下一个诊断步骤是什么?可以提出以下情况:“患者出现吞咽困难4个月,夜间汗水。患者很少喝酒和活跃,25py吸烟。此外,患者还没有合并症。患者发送了这张照片,并想知道最有可能的情况。诊断是什么?为了防止以前的响应产生任何影响,为每个提示开始了一个新的会话,以确保最一致的结果,在本研究的附加部分中,在三个不同的网络浏览器中也使用了一部分提示一天和三天不同的日子,以确保最一致的结果(补充图。 2)。收集了响应,并以双盲方法进行了评估。两位独立的审阅者得到了图像和响应,并且对AI模型表示响应的信息没有信息。所有审稿人都独立评分了缓解主观偏见的答案。Chatgpt 4.0提供的答案是使用Lechien等人提出的人工智能绩效指数(AIPI)的分级量表进行评估的。22。此外,图像描述的类别是通过0级=缺少图像描述/转介的四个等级实现一般描述,3 =图像识别和位置。将Chatgpt产生的每种可疑诊断,无论是仅基于图像识别还是补充临床病史,都将其与已确认的组织学诊断进行了比较。这种方法确保了对Chatgpt鉴定鳞状细胞癌,白细胞和无良性或无病变的能力的客观评估。Cohen的Kappa系数用于衡量评估者间的可靠性。对于LLM的响应,Mann -Whitney U检验用于确定重大差异。当进行多个假设检验时,使用Bonferroni校正方法调整了P值。p值小于0.05被认为具有统计学意义。数据集在补充材料中描绘。
结果
Chatgpt 4.0以异常快速的方式对本研究中的所有提示做出了回应,无论是否仅使用图像还是图像的组合和患者的临床病史。它始终认识到提示中使用的图像正在显示口腔或口腔咽部,并且在大多数情况下能够分析图像并更详细地指定病变,包括位置和外观。图中描述了一个例子。 2。在这项探索性研究的第二种情况下,当将患者的临床病史添加到图像中,并且提示在大多数病例中没有描述图像,而是更喜欢分析和剖析患者的临床病史。因此,将图像描述的类别添加到AIPI中,以定性地评估图像识别的能力。AIPI的修改版本还对列表差异诊断(问题4),主要诊断(问题5),其他检查(问题6)的性能进行了评分(问题6),以及是否有必要/有用(问题7)以及是否有优先级排序诊断步骤(问题8)。CHATGPT为图像病变产生的最常见的差异诊断是口腔癌,口腔溃疡,感染:真菌,病毒或细菌感染,创伤,创伤和其他病变,包括良性生长,囊肿,以及临床史包括疼痛,疼痛,何时神经痛。对于问题4,ChatGpt使用SCC,Leukoplakia和无病变的图像时列出了描绘病变的这些差异诊断。在这种情况下,Chatgpt的表现最好与Liukoplakia的图像一起表现最好。对于问题5(主要诊断)和7(其他考试)的图像,可以观察到相同的情况,达到最高性能得分。当将患者的临床病史添加到提示中时,获得了不同的结果。这在问题5和7中使用SCC的图像提高了提示的性能,同时降低了类别描述的性能。添加临床病史时,降低了图像描述类别中所有病变的性能评分。值得注意的是,在包括临床病史的情况下,Chatgpt经常省略对图像的参考。在没有图像的提示结果分析提示的结果时,结果在提供图像和临床病史时类似于方案2。由于没有提供图像,因此评论者没有回答图像类别。在大多数情况下,Chatgpt将患者转介术(ENT专家)或口腔外科医生或专家,强调了医疗专业人员评估的需求。在几乎所有粘膜病变的病例中,Chatgpt建议对确定性组织学进行诊断活检,而在大多数情况下,成像被认为是可选的。示范提示和Chatgpt 4.0产生的相应答案如图所示。 2。图2示例性口腔癌病例和图像的描述。

答案是从响应页面复制的。
在第一种情况下,仅提供病变的图像提示,只有26%的鳞状细胞癌图像通过Chatgpt 4.0鉴定出来,而86.7%的白血病图像被鉴定出来。没有病变的图像被归类为良性/无病变或错误分类为白细胞。在第二种情况下,当图像伴随着患者的临床病史时,诊断准确性提高了。精确检测到73.3%的恶性病变,而良性的93.3%和93.3%的口腔白细胞图像被Chatgpt 4.0识别。
此外,与口腔病变相比,在分析口咽病变的结果时,可以正确诊断为26.7%的口腔病变图像(15例中有4例),而没有任何诊断的口腔病变图像,而没有。检测到两个口咽病变。当添加临床病史时,检测到口咽病的一个病变和73.3%(15例)口腔癌病变的病变。此外,对肿瘤大小(T阶段)的分析表明了趋势:早期SCC不太可能被识别。但是,临床病史的增加始终提高了整个阶段的识别率。当将没有病变的图像提交给Chatgpt时,有时说没有病变,或者有良性的病变,例如裂开的舌头。在5例(33.3%)的场景中,1 Chatgpt将图像错误分类为描绘白血病。在添加临床病史时,该速率降低到6.7%(15例中的1例)。在第三种情况(仅临床历史)中,Chatgpt在检测SCC(73.3%)的表现与方案2(图像和临床历史记录)的表现相似,而Leukoplakia的表现降低(80%)。Chatgpt只有临床病史作为临床病史,怀疑白细胞或80%的良性/阴性病例的恶性肿瘤。值得注意的是,与早期病变(T1/T2)相比,当通过肿瘤阶段分层时,该模型对晚期SCC(T3/T4)的表现更好。
这些发现和子分析的全面概述如图所示。 3。
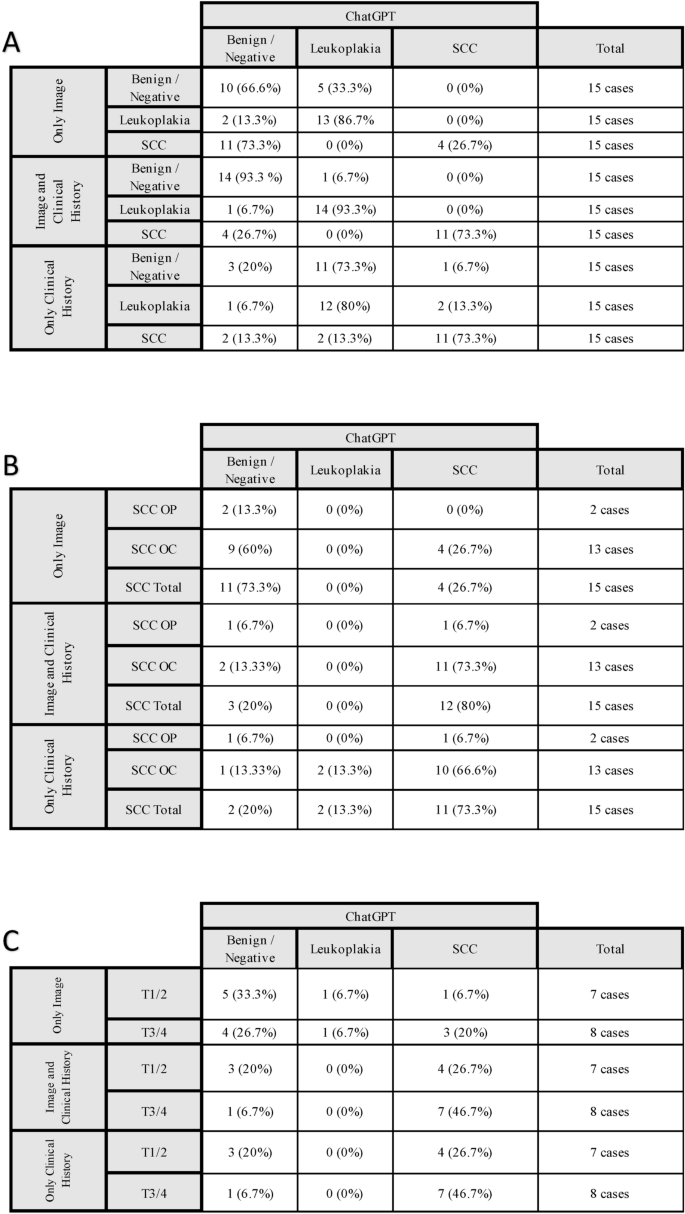
ChatGpt 4.0在识别良性/阴性,白细胞和鳞状细胞癌(SCC)病例中的性能,基于不同的情况:仅图像,图像和临床病史以及仅临床病史;((一个)ChatGpt 4.0的总体表现;((b)结果通过病变位置(口腔[OC]与口咽[OP])和(c)肿瘤阶段(早期[T1/T2]与高级阶段[T3/T4])。每个表概述了诊断结果,并突出了临床病史和病变特征对Chatgpt 4.0预测准确性的影响。
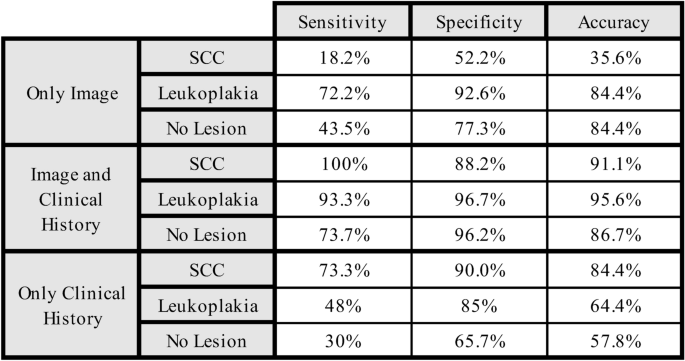
计算了通过病变的Chatgpt识别图像识别的敏感性,特异性和准确性,并在图中描绘了。 4。结合临床病史的敏感性使检测到鳞状细胞癌的敏感性从18.2%增加到100%,而特异性从52.2%增加到88.2%。对于白细胞,最初的敏感性为72.2%,特异性为92.6%,增加到93.3%和96.7%。相比之下,即使包括临床病史,与白细胞和SCC相比,没有病变的图像显着降低了灵敏度和特异性。当仅出现临床病史时,该模型对SCC的敏感性为73.3%,而检测白细胞的灵敏度降低到48%。对于没有病变的图像,灵敏度是所有三种情况中最坏的(30%)(图。 4)。图4
CHATGPT产生的所有绩效评级均由两名独立的审阅者评估,并使用Cohen s-®评估评估者一致性。
在比较结果时,审稿人达成了Cohen s -之间的0.498的协议,用于图像识别为0.529,问题4、0.773的问题5,1.0的问题6,0.287 for Question 7和0.287,对于问题8。第二种情况是,两名独立审稿人达成了Cohen s -º的协议0.686,用于图像识别,问题4,问题5,0.468的问题5,1.0的问题6,0.493 for Questions 7和1.0,对于问题8。每个病变的修饰AIPI的结果如图所示。 5。图5ChatGpt 4.0对图像识别性能的总体评分。

一个)对(a)方案1的两个独立审稿人的改性AIPI和图像描述/识别的评分与仅作为提示的比较;(b)每个患者的图像和临床病史的场景2;(c)仅具有临床病史的情况3((b)表演的总体比较。每个条是两个独立审阅者评分的平均值。*等于p> 0.05,**等于p> 0.01,***等于p> 0.001。对45例病例进行了详细分析,以探索在某些临床情况下图像识别方面具有重要专业知识的领域(补充图。 1
)。但是,在大多数情况下,没有明确的专业领域模式可以观察到比方案2的总体得分更高。例外包括案例6、12、13和14,SCC图像,leukoplakia案例5图像,以及没有病变的图像的第7和15个图像。
ChatGpt 4.0在其反应中一直强调的是,应与医生讨论最终诊断和临床决策。单个患者场景的独特性。Chatgpt 4.0通常列出了类似于提示图像的源材料,甚至链接的图像。
讨论
这是评估Chatgpt 4.0基于人工智能的图像识别特征的第一项研究,用于诊断口腔和口腔咽部鳞状细胞癌,头颈部鳞状细胞癌的子集。在这项探索性研究中,在两个不同的临床方案中使用了45个口腔内图像,一次仅带有图像的信息,第二次与患者的临床病史一起使用。由两位不同的审阅者评估了正确诊断的能力以及ChatGpt对诊断步骤的建议。这项研究的目的是研究高级LLM识别图像识别的潜在和局限性,并评估在临床环境中的潜在用途。
在这项研究时20。在这项研究中研究了口腔和口咽癌,因为这种恶性肿瘤的发生率正在上升,并且很容易进入病变以拍摄图像。这些图像可以由远程医疗专业人员观察到,但也可以通过人工智能工具进行评估。Chatgpt 4.0是一种自然语言处理(NLP),这是一个专门用于分析人类语言的人工智能(AI)。LLM的使用已经在不同的应用中进行了研究,包括医学教育,风湿病学,乳腺癌研究和不同的体检18,,,,23,,,,24,,,,25,,,,26,,,,27。
在这项研究中,ChatGpt 4.0的敏感性为18.2%,对于检测口腔癌的特异性为52.2%,当提示仅由图像组成,而LLM只能分析图像的信息,以找到最可能的口腔诊断癌症。该结果类似于研究使用Chatgpt 4.0用于分析黑色素瘤图像的研究,其中敏感性为32.0%,特异性达到40%20。由于在临床环境中,大多数患者没有显示病变的图像,但抱怨症状,因此在这项研究中研究了第二种情况,其中迅速使用了图像,并提供有关临床病史的其他信息。在第二种情况下,Chatgpt的敏感性和特异性增加到100%和88.2%。尤其是疼痛的症状通常是这项研究中患者临床病史的一部分,可能导致口腔/口咽癌的诊断。在场景3中也观察到了这一点,当时仅提出临床病史,并且更一致地诊断出更高级的病例。在场景3中,仅提供临床病史,SCC的平庸灵敏度为70%,而白细胞和没有病变的病例大部分被错误地分类,这再次表明LLMS的文本依赖性性质。
ChatGpt 4.0在仅获得图像时已经很高的灵敏度为72.2%,特异性的敏感性为72.2%,特异性为93.3%,而当临床历史包括96.7%的敏感性时,Chatgpt 4.0取得了显着的结果。迅速的。当显示没有病变或具有良性病变的图像时,即使图像中没有可见病变,也将场景2中的五个病变识别为Leukoplakia中的一个病变。当仅将临床病史和不使用图像用作提示和白细胞,或者在大多数情况下怀疑有恶性肿瘤时,这种情况就更加强调了。在另一项研究中20LLM在用CHETGPT诊断黑色素瘤的情况下,甚至将一些良性病变的图像归为黑色素瘤。通常,在我们的研究中,比口咽癌更频繁地识别出更多的晚期病变,并且口腔病变的频率更高。这可能是由于难以获得口咽的足够图像,或者在数据库中缺乏口咽病变图像的图像。不幸的是,即使已经显示了响应的某些图像和源材料,但导致chatgpt特定答案的机制和数据库大多数时候都不清楚,通常被称为黑匣子现象28。在其他研究中也观察到了这一点18,,,,23,,,,24,,,,25,,,,26,,,,27。
LLM能够根据以前研究中患者的书面症状评估和诊断头颈癌,人造肿瘤板在乳腺癌和头颈癌中达到了很高的一致性。一项研究调查了各种晚期癌症患者的虚构病例,其中4位不同的LLM和一名医生提供了遗传改变。LLM能够提供大量不同的治疗选择,但没有提供任何令人信服的临床推理来支持其建议,也没有达到专家的水平29。这类似于问题4中我们研究中的表现的高评分,在该研究中,Chatgpt以非常有效的方式列出了差异诊断。这种基于数据库生成书面信息的能力是LLM的核心优势之一18,,,,30。人工智能绩效指数(AIPI)的修改版本22在这项研究中被用来评估CHATGPT的诊断性能。有趣的是,当仅将图像用作提示时,两位独立审阅者将新添加的图像描述类别的评分明显得多。这种情况还获得了更好的评级,以说明口腔腔病变的差异诊断。在比较鳞状细胞癌,白细胞和没有病变的图像的修饰的AIPI评级时,Leukoplakia在两种情况下都达到了很高的评分,而SCC在方案1中均不在。作为专业诊断的备份,以帮助最大程度地减少缺失黑色素瘤的风险31,只有少数研究调查了使用人工智能工具来诊断口腔/口腔咽部鳞状细胞癌32。这些方法中的大多数都是技术高度技术,包括Nayak等人。他们使用机器学习以使用激光诱导的自动荧光光谱记录来区分正常,预先和组织之间的口服病变,并达到98.3%的精度,特异性为100%,灵敏度为96.5%33。关于组织病理学图像的研究发现,在最近的综述中,敏感性从97.76%到99.26%的精度为97.76%至99.26%,特异性范围为92%至99.42%。34。由于目前Chatgpt无法分析组织病理学幻灯片,因此很难比较这项研究的结果。在印度有一些基于人群的优雅研究,其中手机与口腔内探针相连,以制造口腔癌的护理点筛查工具,包括神经网络8,,,,35。这种方法的精度为81%,灵敏度为85%,特异性为84%,当仅将图像用作提示时,显然超过了我们研究的结果。在我们的研究中,临床病史的其他信息可以达到更高的灵敏度和特异性。这可能是由于LLM本质上是依赖文本的事实,并且可能更喜欢基于文本的信息。文献中的数据还不能支持该观察结果,但可能可以解释为什么在临床病史也可用时,在本研究的许多情况下,Chatgpt没有提及该图像。
尽管这些研究的结果以及基于人工智能的图像识别的最新发展需要在这个有希望的领域的未来研究,但在将人工智能实施到临床实践中之前,仍然存在许多局限性。首先,缺乏用于生成答案的资源的透明度28。虽然指南和临床研究是临床决策的骨干,但获取LLMS源信息的访问仍然非常有限。因此,验证和繁殖受到许多研究报告的高度限制10,,,,36,,,,37。尽管这项探索性研究分析了目前最多的口腔/口腔咽部病变图像,这是为此目的评估Chatgpt 4.0的图像识别功能的第一次,但患者图像的异质性可能有一定程度影响了这项研究的结果。使用LLM的另一个局限性是提示设计的重要性15,,,,25,,,,29。迅速的变化会导致LLM的不同反应,并影响任何研究的结果。在本研究的准备中,测试了8个不同的提示,并有两个不同的提示,导致了两种不同的临床方案,一个仅作为提示,另一个具有图像和图像的图像,使用了患者的临床病史。这项单中心研究调查了仅一个欧洲机构的患者的图像,这是由于仅分析高加索患者的图像而受到的限制。在许多研究中,已经证明在分析不同种族的皮肤癌时存在差异38,LLM可以适应不同地区的实践和变化以及培训数据的来源和多样性39。Future studies might benefit from a multicentric/multiethnic approach, with the accessibility of LLMs as one of the major benefits of LLMs.Simultaneously, the use of LLMs for image interpretation in clinical settings raises significant ethical concerns.A major limitation is the potential for misdiagnosis, as LLMs can provide incorrect or inconsistent interpretations, as seen in the sensitivity and specificity in this study, which might endanger patient safety.Privacy and data security are also critical, as using clinical images might contain sensitive patient information.In addition, LLMs might be biased if the training data lacks diversity or contains systemic inaccuracies.Unfortunately, the source data is not publicly available at the moment40,,,,41。Addressing these ethical concerns requires careful validation and improvements in terms of data transparency before integration of LLMs into clinical workflows.
Currently LLMs are not programmed to think independently but generate a text-based output based on public documents and databases10。While in the clinical setting the otolaryngologist/maxillofacial surgeon/dentist can palpate the lesion, or ask additional questions about the clinical history, or make another image from a slightly different angle, an LLM is not able to “think outside the boxâ€.Additionally, while the treatment of HNSCC remains a complex field due to the heterogenous nature of the disease, even the appearance of oral lesions is highly heterogeneous.A study investigating a larger number of images of oral lesions might lead to better results when only an image is used as a prompt, but the combination of the clinical history and an image led to a significantly better sensitivity and specificity with the current version of ChatGPT 4.0 and therefore is more suitable for implementation into the clinical setting.At the moment the diagnosis of lesions of the oral cavity and oropharynx by ChatGPT needs to be evaluated carefully by medical professionals based on their clinical knowledge and cannot be used as a clinical guidance.This is also addressed by the LLMs themselves at the end of most of the responses in this study.
结论
The study is the first highlighting the potential of artificial intelligence-based image recognition using ChatGPT 4.0 for assessing clinical images of oral and oropharyngeal squamous cell carcinoma and leukoplakia.The findings highlight that, at present, combining image analysis with clinical history is important to achieve convincing diagnostic accuracy, as image recognition alone remains limited in sensitivity and specificity.Notably, leukoplakia images demonstrated high sensitivity and specificity without requiring additional clinical history. These results suggest that artificial intelligence could play a significant role in the future clinical evaluation of early stages of cancer and oral lesions, paving the way for more accessible and efficient diagnostic工具。
数据可用性
Data is provided within the manuscript or supplementary information files. The datasets generated and/or analysed during the current study are available in the Supplementary Material.
参考
Johnson, D. E. et al. Head and neck squamous cell carcinoma.纳特。修订版。底漆。 6(1), 92–92 (2020).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Yarbrough, W. G. et al. De-escalated therapy and early treatment of recurrences in HPV-associated head and neck cancer: The potential for biomarkers to revolutionize personalized therapy.病毒 16(4), 536 (2024).
文章一个 CAS一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
O’Boyle, C. J. et al. Cell-free human papillomavirus DNA kinetics after surgery for human papillomavirus-associated oropharyngeal cancer.癌症 128(11), 2193–2204 (2022).
文章一个 PubMed一个 数学一个 Google Scholar一个
Rolfes, V. et al. PD-L1 is expressed on human platelets and is affected by immune checkpoint therapy.Oncotarget 9(44), 27460–27470 (2018).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Ferrandino, R. M. et al. Performance of liquid biopsy for diagnosis and surveillance of human papillomavirus-associated oropharyngeal cancer.JAMA耳鼻喉科。头颈外侧。 149(11), 971–977 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Warnakulasuriya, S. & Kerr, A. R. Oral cancer screening: Past, present, and future.J. Dent.res。 100(12), 1313–1320 (2021).
文章一个 CAS一个 PubMed一个 数学一个 Google Scholar一个
Sarode, G. S., Kumari, N. & Sarode, S. C. Oral cancer histopathology images and artificial intelligence: A pathologist’s perspective.口服Oncol。 132, 105999 (2022).
文章一个 PubMed一个 数学一个 Google Scholar一个
Song, B. et al. Mobile-based oral cancer classification for point-of-care screening.J. Biomed。选择。 26(6), 065003 (2021).
文章一个 广告一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Sankaranarayanan, R. et al. Long term effect of visual screening on oral cancer incidence and mortality in a randomized trial in Kerala, India.口服Oncol。 49(4), 314–321 (2013).
文章一个 PubMed一个 数学一个 Google Scholar一个
Cascella, M. et al. Evaluating the feasibility of ChatGPT in healthcare: An analysis of multiple clinical and research scenarios.J. Med。系统。 47(1), 33 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Sufi, F. Generative pre-trained transformer (GPT) in research: A systematic review on data augmentation.信息 15(2), 99 (2024).
文章一个 数学一个 Google Scholar一个
Thenappan, A. et al. Review at a multidisciplinary tumor board impacts critical management decisions of pediatric patients with cancer.小儿科Blood Cancer 64(2), 254–258 (2017).
文章一个 PubMed一个 Google Scholar一个
Berardi, R. et al. Benefits and limitations of a multidisciplinary approach in cancer patient management.癌症管理。res。 12, 9363–9374 (2020).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Luchini, C. et al. Molecular tumor boards in clinical practice.趋势癌 6(9), 738–744 (2020).
文章一个 PubMed一个 数学一个 Google Scholar一个
Schmidl, B. et al. Assessing the role of advanced artificial intelligence as a tool in multidisciplinary tumor board decision-making for primary head and neck cancer cases.正面。Oncol。 14, 1353031 (2024).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Lechien, J. R. et al. Accuracy of ChatGPT in head and neck oncological board decisions: Preliminary findings.欧元。拱。otorhinolaryngol。 281(4), 2105–2114 (2024).
文章一个 PubMed一个 数学一个 Google Scholar一个
Dave, T., Athaluri, S. A. & Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations.正面。艺术品。Intell。 6, 1169595 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Lukac, S. et al. Evaluating ChatGPT as an adjunct for the multidisciplinary tumor board decision-making in primary breast cancer cases.拱。妇科。产科。 308(6), 1831–1844 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Temsah, R. et al. Healthcare’s new horizon with ChatGPT’s voice and vision capabilities: A leap beyond text.肉质 15(10), e47469 (2023).
Shifai, N. et al. Can ChatGPT vision diagnose melanoma? An exploratory diagnostic accuracy study.J. Am。学院。皮肤病。 90(5), 1057–1059 (2024).
文章一个 PubMed一个 数学一个 Google Scholar一个
Kar, A. et al. Improvement of oral cancer screening quality and reach: The promise of artificial intelligence.J. Oral.Pathol。医学 49(8), 727–730 (2020).
文章一个 PubMed一个 数学一个 Google Scholar一个
Lechien, J. R. et al. Validity and reliability of an instrument evaluating the performance of intelligent chatbot: The artificial intelligence performance instrument (AIPI).欧元。拱。otorhinolaryngol。 281(4), 2063–2079 (2024).
文章一个 PubMed一个 数学一个 Google Scholar一个
Huang,Y。等。Benchmarking ChatGPT-4 on a radiation oncology in-training exam and Red Journal Gray Zone cases: Potentials and challenges for ai-assisted medical education and decision making in radiation oncology.正面。Oncol。 13, 1265024 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Hughes, K. S. et al. Natural language processing to facilitate breast cancer research and management.乳房J。 26(1), 92–99 (2020).
文章一个 PubMed一个 数学一个 Google Scholar一个
Hügle, T. The wide range of opportunities for large language models such as ChatGPT in rheumatology.RMD开放 9(2), e003105 (2023).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kanjee, Z., Crowe, B. & Rodman, A. Accuracy of a generative artificial intelligence model in a complex diagnostic challenge.贾马 330(1), 78–80 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Chakraborty, C. et al. Overview of Chatbots with special emphasis on artificial intelligence-enabled ChatGPT in medical science.正面。艺术品。Intell。 6, 1237704 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Gallistl, V. et al. Addressing the black box of AI - A model and research agenda on the co-constitution of aging and artificial intelligence.Gerontologist 64, gnae039 (2024).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Benary, M. et al. Leveraging large language models for decision support in personalized oncology.JAMA NetW。打开 6(11), e2343689 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Lechner, M. et al. HPV-associated oropharyngeal cancer: Epidemiology, molecular biology and clinical management.纳特。临床。Oncol。 19(5), 306–327 (2022).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
di Ferrante Ruffano, L. et al. Computer-assisted diagnosis techniques (dermoscopy and spectroscopy-based) for diagnosing skin cancer in adults.Cochrane数据库系统。修订版 12(12), 013186 (2018).
Patil, S. et al. Artificial intelligence in the diagnosis of oral diseases: Applications and pitfalls.诊断(巴塞尔) 12(5), 1029 (2022).
文章一个 CAS一个 PubMed一个 数学一个 Google Scholar一个
Nayak, G. S. et al. Principal component analysis and artificial neural network analysis of oral tissue fluorescence spectra: Classification of normal premalignant and malignant pathological conditions.生物聚合物 82(2), 152–166 (2006).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Khanagar, S. B. et al. Application and performance of artificial intelligence (AI) in oral cancer diagnosis and prediction using histopathological images: A systematic review.生物医学 11(6), 1612 (2023).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Uthoff, R. D. et al. Small form factor, flexible, dual-modality handheld probe for smartphone-based, point-of-care oral and oropharyngeal cancer screening.J. Biomed。选择。 24(10), 1–8 (2019).
文章一个 PubMed一个 数学一个 Google Scholar一个
Lechien, J. R. et al. ChatGPT performance in laryngology and head and neck surgery: a clinical case-series.欧元。拱。otorhinolaryngol。 281, 319 (2023).
文章一个 PubMed一个 数学一个 Google Scholar一个
Uprety, D., Zhu, D. & West, H. J. ChatGPT-A promising generative AI tool and its implications for cancer care.癌症 129(15), 2284–2289 (2023).
文章一个 PubMed一个 数学一个 Google Scholar一个
Asadi, L. K., Khalili, A. & Wang, S. Q. The sociological basis of the skin cancer epidemic.int。J. Dermatol。 62(2), 169–176 (2023).
文章一个 PubMed一个 数学一个 Google Scholar一个
Deng,L。等。Evaluation of large language models in breast cancer clinical scenarios: A comparative analysis based on ChatGPT-3.5, ChatGPT-4.0, and Claude2.int。J. Surg。 110(4), 1941–1950 (2024).
文章一个 PubMed一个 PubMed Central一个 数学一个 Google Scholar一个
Haltaufderheide, J. & Ranisch, R. The ethics of ChatGPT in medicine and healthcare: A systematic review on Large Language Models (LLMs).NPJ.数字。医学 7(1), 183 (2024).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Bogdanovich, B. et al. Keeping up with AI evolution: ChatGPT-4o in surgery.是。外科。 91, 31348241272423 (2024).
数学一个 Google Scholar一个
资金
由Projekt Deal启用和组织开放访问资金。这项研究没有获得外部资金。
道德声明
竞争利益
作者没有宣称没有竞争利益。
机构审查委员会声明
The study was conducted according to the guidelines of the Declaration of Helsinki and the ethics committee of the Technical University of Munich.
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
补充信息
权利和权限
开放访问This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/4.0/。重印和权限
引用本文

Schmidl, B., Hütten, T., Pigorsch, S.
等。Artificial intelligence for image recognition in diagnosing oral and oropharyngeal cancer and leukoplakia.Sci代表15 , 3625 (2025). https://doi.org/10.1038/s41598-025-85920-4下载引用
:2024年6月25日
:2025年1月7日
:2025年1月29日
:https://doi.org/10.1038/s41598-025-85920-4关键字