可以立即解释任何电子表格的AI工具



合成数据用于培训可以分析列表数据的AI模型,例如财务信息。图片来源:Kazuhiro Nogi/AFP/Getty
它甚至不是去年一月,而2025年已经被证明是人工智能(AI)的决定性一年。1月21日,在担任总统职位仅一天,美国总统唐纳德·特朗普(Donald Trump)宣布了《星际之门》项目,这是美国,日本和阿拉伯联合酋长国的领先技术公司与金融家之间的合资企业。他们承诺在美国开发AI基础设施的5000亿美元。
只有第二天,位于中国杭州的AI-Research公司DeepSeek才表明,可能不需要如此巨大的款项。它发布了DeepSeek-R1,这是一种大型语言模型(LLM),能够逐步完成类似于人类推理的任务,据报道,现有LLM的成本和计算能力的一小部分。在早期测试中,其在化学和数学任务上的表现与去年9月Openai发行的O1 LLM相匹配,Openai是一家位于加利福尼亚州旧金山的公司。一个消息便宜但先进的AI已将某些技术股票的价格发送到了尾矿中。
可以立即解释任何电子表格的AI工具
在可能定义未来几年的AI的各种愿景中,重要的研究将继续发表,但并非所有人都将成为头条新闻。他们也需要听到,讨论和辩论。一项这样的作品发表在自然本月初。它被称为使用表粉底模型的小数据上的准确预测(N. Hollman等。 自然 637,319 326;2025),这对于数据科学领域来说可能是革命性的。D. C. McElfresh自然637,274 275;2025)。
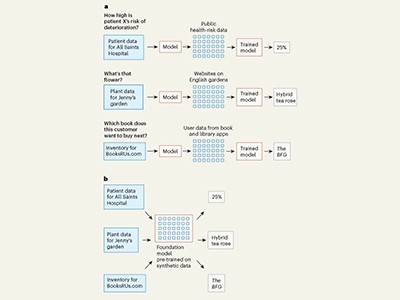
最著名的LLM经过数百万种实际数据示例(例如文本和图像)的预先培训。这使他们能够以一定程度的可靠性回答用户查询。但是,如果所需数量中不存在相关的现实世界数据怎么办?在较少的数据集接受培训时,AI仍然可以提供可靠的答案吗?对于使用AI来从列表的数据集中进行预测的研究人员来说,这是一个关键问题,培训AI模型的所需数量远不远。这自然研究表明,如果对AI模型进行了合成数据的培训,可以实现可靠的结果,以模仿现实世界数据的统计特性的随机生成的数据。
这是计算机科学家诺亚·霍尔曼(Noah Hollman),塞缪尔·穆勒(SamuelMã¼ller)和弗兰克·哈特(Frank Hutter)的计算机科学家及其同事的作品。他们的模型称为TABPFN,旨在分析表格中的表格数据。通常,用户通过使用数据填充行和列来创建电子表格,并使用数学模型从这些数据中进行推断或投影。TABPFN可以对任何小型数据集做出预测,从会计和资金到基因组学和神经科学的数据集。此外,即使在没有现实世界数据的情况下对其进行了完全训练,但模型预测是准确的,而是对1亿个随机生成的数据集进行的。

AI公司在培训中使用学术数据时必须公平地发挥作用
综合数据没有没有风险,例如产生不准确的结果或幻觉的危险。这就是为什么要复制此类研究很重要的原因。复制是科学的基石,还向用户保证,他们可以信任其查询结果。
增强对AI的信任以及最小化危害的信任必须仍然是全球优先事项,即使它似乎已被特朗普降级。总统已取消了他的前任的行政命令,该命令呼吁国立标准技术研究所(NIST)和AI公司合作以提高对AI的信任和安全性,包括使用合成数据。特朗普的新行政命令被称为“消除美国在人工智能领导的障碍”,忽略了使用“安全”一词。去年11月,NIST发布了一份关于身份验证AI内容和跟踪其出处的方法的报告(请参阅go.nature.com/42c21tn)。研究人员应该以这些努力为基础,不要让他们浪费。
霍尔曼(Hollman)及其同事的工作是必要创新的一个例子:研究人员意识到没有足够的可访问现实世界数据集来训练他们的模型,因此他们找到了另一种方法。
仍然是所有AI模型,无论是在合成还是现实世界中培训的,仍然都是黑匣子:用户和监管机构都不知道如何达到结果。因此,随着2025年带来更多令人兴奋的发展,让我们不要忘记试图了解AI的方式以及为什么以及方法论文的研究。它们与宣布突破的出版物一样重要。