
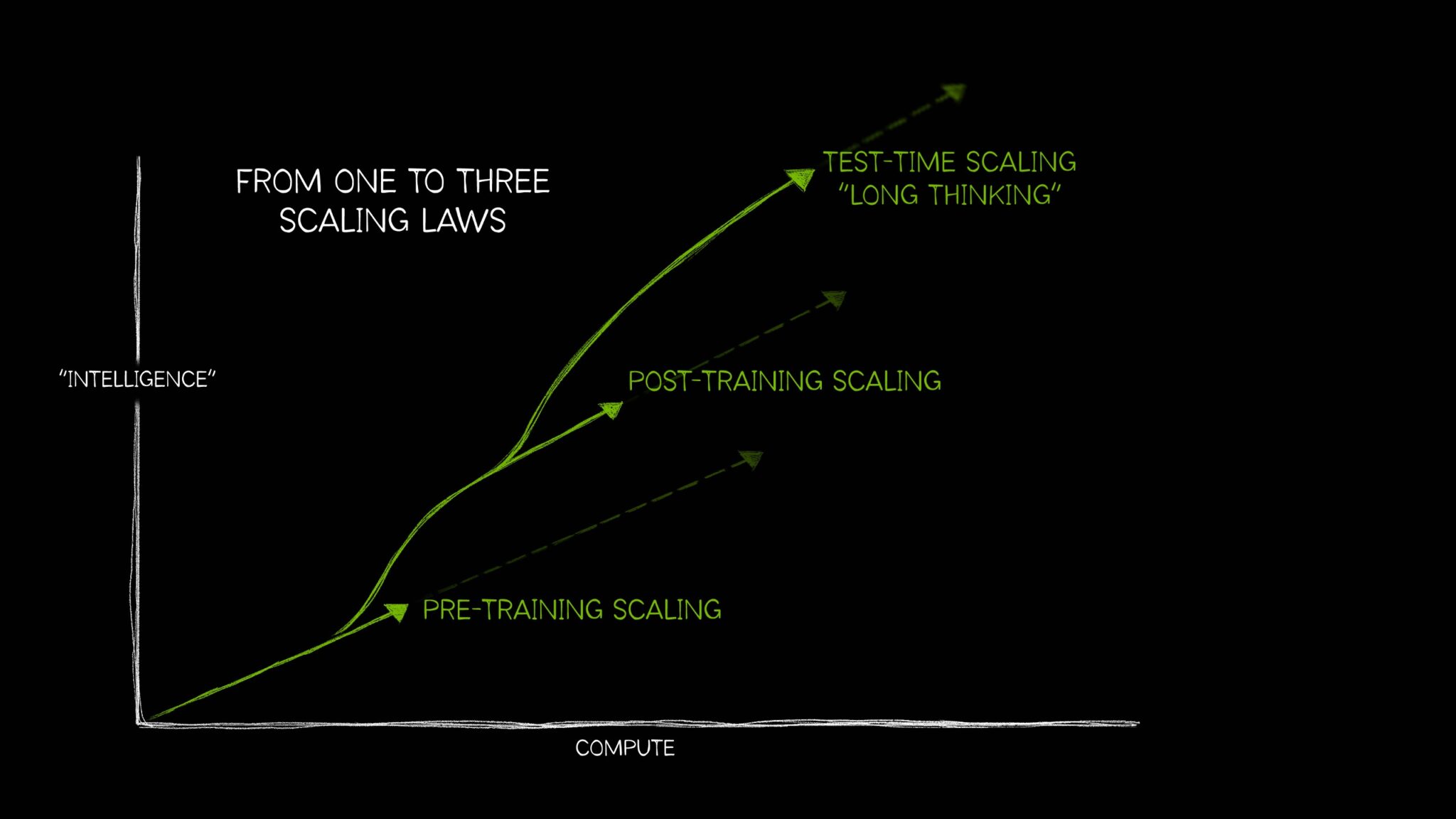
就像有广泛理解的自然经验定律一样,上升必须下降, 或者每个动作都有平等和相反的反应长期以来,AI的领域由一个想法来定义:更多的计算,更多的训练数据和更多的参数使AI模型更好。
但是,自那时以来,AI已成长为需要三个不同的法律,这些定律描述了如何以不同方式应用计算资源会影响模型性能。这些AI缩放定律在一起 - 训练缩放,训练后缩放和测试时间缩放,也称为长思维 - 反映了该领域如何随着技术的发展而发展,以在各种越来越复杂的AI中使用其他计算案例。
测试时间缩放的最新增长 - 在推理时间应用更多的计算以提高准确性 - 已使AI推理模型,这是一种新的大型语言模型(LLMS)执行多个推理通过以解决复杂问题,同时描述解决任务所需的步骤。测试时间缩放需要大量的计算资源来支持AI推理,这将推动对加速计算的进一步需求。
什么是预缩放缩放?
预刻缩放是AI开发的原始定律。它表明,通过增加培训数据集大小,模型参数计数和计算资源,开发人员可以期望模型智能和准确性可预测的改善。
这三个元素中的每一个数据,模型大小,计算都相互关联。根据训练缩放法,在本研究论文中概述了,当较大的模型获得更多数据时,模型的总体性能会有所改善。为了使这一可行,开发人员必须扩展其计算 - 创造了对强大的加速计算资源的需求,以运行那些更大的培训工作量。
预处理缩放的原则导致了实现开创性功能的大型模型。它还刺激了模型架构的重大创新,包括数十亿美元和万亿参数的兴起变压器模型,,,,专家的混合物模型和新的分布式培训技术都要求大量计算。
并且预刻板定律定律的相关性仍在继续 - 随着人类继续产生越来越多的多模式数据,这种文本,图像,音频,视频和传感器信息将用于培训强大的未来AI模型。
什么是训练后缩放?
预处理一个基础模型对于每个人来说,都需要大量投资,熟练的专家和数据集。但是,一旦一个组织预测并发布了模型,他们就通过使他人能够使用验证的模型作为适应自己的应用的基础来降低采用AI的障碍。
这种训练后的过程推动了跨企业和更广泛的开发人员社区加速计算的额外累积需求。流行的开源型号可以具有数百或数千种衍生模型,这些模型跨越了许多域。
为各种用例开发这个衍生模型的生态系统可能要比预处理原始基础模型要花费大约30倍的计算。为各种用例开发这个衍生模型的生态系统可能要比预处理原始基础模型要花费大约30倍的计算。
培训后技术可以进一步提高模型的特殊性和对组织所需用例的相关性。
虽然预训练就像将AI模型派往学校学习基础技能,但培训后培训以适用于预定工作的技能增强了模型。例如,LLM可能会进行培训,以解决情感分析或翻译之类的任务 - 或了解特定领域的行话,例如医疗保健或法律。
训练后的缩放定律认为,使用微调,修剪,量化,蒸馏,加强学习和合成数据在内的技术,验证的模型的性能可以进一步提高计算效率,准确性或域特异性。增强
- 微调使用其他培训数据来为特定域和应用定制AI模型。这可以使用组织的内部数据集或对示例模型输入和输出对完成。
- 蒸馏需要一对AI模型:一个大型,复杂的教师模型和轻量级的学生模型。在最常见的蒸馏技术(称为离线蒸馏)中,学生模型学会了模仿预验证的教师模型的输出。
- 强化学习或RL是一种机器学习技术,它使用奖励模型来训练代理商以与特定用例保持一致的决策。该代理商旨在做出决策,以随着时间的流逝而与环境进行交互,例如,聊天机器人llm会受到用户的反应的积极加强。该技术被称为从人类反馈(RLHF)学习的强化学习。另一种较新的技术是从AI反馈(RLAIF)学习的强化,而是使用来自AI模型的反馈来指导学习过程,简化了培训后的工作。
- 最佳N采样从语言模型中生成多个输出,并根据奖励模型选择具有最高奖励分数的输出。它通常用于改善AI的输出而无需修改模型参数,从而提供了通过增强学习进行微调的替代方案。
- 搜索方法在选择最终输出之前,请探索一系列潜在的决策路径。这种训练后技术可以迭代地改善模型的反应。
为了支持培训后,开发人员可以使用合成数据增加或补充其微调数据集。使用AI生成的数据补充现实世界数据集可以帮助建模可以提高其处理原始培训数据中代表性不足或缺少的边缘案例的能力。

什么是测试时间缩放?
LLMS生成对输入提示的快速响应。尽管此过程非常适合获取简单问题的正确答案,但是当用户提出复杂的查询时,它可能无法正常工作。回答复杂的问题 -代理AI工作负载要求LLM在提出答案之前通过问题进行推理。
这类似于大多数人类的思考方式 - 当被要求添加两个加两个时,它们提供了一个即时的答案,而无需通过添加或整数的基本面进行交谈。但是,如果当场被要求制定可以将公司利润增长10%的业务计划,那么一个人可能会通过各种选择来推理并提供多步骤的答案。
测试时间缩放(也称为长时间思考)发生在推理期间。使用此技术在推断期间分配额外的计算工作,而不是传统的AI模型,而不是迅速为用户提示产生单次答案的模型,从而使他们能够通过在达到最佳答案之前通过多个潜在响应进行推理。
在为开发人员生成复杂的,定制的代码等任务上,与传统LLM上的单个推断通过相比,该AI推理过程可能需要数分钟甚至数小时,并且很容易需要超过100倍的计算来进行具有挑战性的查询,这将是在第一次尝试时,极不可能响应复杂问题而产生正确的答案。
与传统LLM上的单个推理通过相比,这个AI推理过程可能需要数分钟甚至数小时,并且很容易需要超过100倍的计算来进行具有挑战性的查询。
此测试时间计算功能使AI模型能够探索有关问题的不同解决方案,并将复杂请求分解为多个步骤 - 在许多情况下,以此为由向用户展示其工作。研究发现,当AI模型获得需要多个推理和计划步骤的开放式提示时,测试时间缩放会导致更高质量的响应。
测试时间计算方法论有许多方法,包括:
- 经过思考链的提示:将复杂的问题分解为一系列简单的步骤。
- 以多数投票抽样:生成对同一提示的多个响应,然后选择最常见的回答作为最终输出。
- 搜索:探索和评估在响应的类似树状结构中存在的多个路径。
在推断期间,也可以将训练后的方法(如最佳N采样)进行长时间思考,以优化与人类偏好或其他目标保持一致的响应。

测试时间缩放如何启用AI推理
测试时间的兴起计算,可以解锁AI对复杂,开放式用户查询的良好,有益,更准确的响应的能力。这些功能对于自主期望的详细的多步推理任务至关重要代理AI和物理AI申请。在整个行业中,它们可以通过为用户提供高能力的助手来加速其工作,从而提高效率和生产率。
在医疗保健中,模型可以使用测试时间缩放来分析大量数据并推断疾病将如何进展,并预测可能源于基于药物分子的化学结构的新处理的潜在并发症。或者,它可以通过临床试验数据库进行梳理,以提出与个体疾病概况相匹配的选择,并分享其有关不同研究的利弊的推理过程。
在零售和供应链物流中,长期的思维可以帮助解决近期运营挑战和长期战略目标所需的复杂决策。推理技术可以通过同时预测和评估多种情况来帮助企业降低风险并解决可扩展性挑战,这可以使更准确的预测预测,简化的供应链旅行路线以及与组织可持续性计划相吻合的采购决策。
对于全球企业而言,该技术可以应用于起草详细的业务计划,生成复杂的代码进行调试软件,或优化送货卡车,仓库机器人和机器人的旅行路线。
AI推理模型正在迅速发展。Openai O1-Mini和O3-Mini,DeepSeek R1,以及Google DeepMind的Gemini 2.0 Flash Thinky在过去几周中都引入了,预计将很快遵循其他新型号。
这样的模型需要更大的计算才能在推理过程中进行推理,并为复杂问题产生正确的答案 - 这意味着企业需要扩展其加速计算资源,以提供下一代的AI推理工具,这些工具可以支持复杂的问题解决,编码复杂和多步计划。