

如何微调Distilbert进行情感分类|迈向数据科学
作者:Claudia Ng
客户支持团队在我工作的每个公司的客户询问中都淹没了大量的客户查询。您有类似的经历吗?
如果我告诉您您可以使用AI自动确认,,,,分类,甚至解决最常见的问题?
通过微调诸如BERT之类的变压器模型,您可以构建一个自动化系统,该系统通过问题类型标记票证并将其路由到合适的团队。
在本教程中,我将向您展示如何以五个步骤微调变压器模型:
- 设置您的环境:准备数据集并安装必要的库。
- 负载和预处理数据:解析文本文件并组织您的数据。
- 微调Distilbert:火车模型使用数据集对情绪进行分类。
- 评估性能:使用准确性,F1得分和混淆矩阵等指标来衡量模型性能。
- 解释预测:使用Shap(Shapley添加说明)可视化和理解预测。
到最后,您将拥有一个微调的模型,该模型以很高的精度从文本输入中分类,您还可以学习如何使用Shap来解释这些预测。
除了情感分类之外,可以将相同的方法应用于现实世界中的用例,例如客户支持自动化,情感分析,内容审核等。
让我潜水!
选择正确的变压器模型
在选择变压器模型时文本分类,这是最常见模型的快速分解:
- 伯特:非常适合一般的NLP任务,但计算对于培训和推理来说都昂贵。
- Distilbert:保留97%的功能,比BERT快60%,使其非常适合实时应用。
- 罗伯塔:BERT的更强大版本,但需要更多的资源。
- XLM-Roberta:罗伯塔(Roberta)的多语言变体接受了100种语言的培训。它非常适合多种语言任务,但相当大的资源密集型。
在本教程中,我选择微调Distilbert,因为它在性能和效率之间提供了最佳的平衡。
步骤1:设置和安装依赖项
确保您安装了所需的库:
!步骤2:加载和预处理数据
我用了NLP的情绪数据集由Praveen Govi撰写,可在Kaggle和获得商业用途的许可。它包含标有情感的文字。数据有三个。TXT文件:火车,验证,和测试。
每行包含一个句子及其相应的情感标签,被半隆分开:
文本;情感“我没有感到羞辱”;“悲伤”“我感到脾气暴躁”;“愤怒”“我更新我的博客是因为我感到卑鄙”;“悲伤”将数据集解析到PANDAS数据室中
让我们加载数据集:
def parse_emotion_file(file_path):”“”``以每行的格式解析文本文件:{text;情感}``并用“文本”和“情感”列返回熊猫的数据框架。Args: - file_path(str):要解析.txt文件的路径回报: - df(pd.dataframe):包含“文本”和“情感”列的数据框架 -文字= []情绪= [] - ``带有open(file_path,'r',encoding ='utf-8')作为文件:for file中的行:尝试:–分离器将每一行分开ââââ– text,comention = line.strip()。split(';') - •将文本和情感附加到单独的列表``文本(文本)``情感''(情感)除了ValueRror:继续 - •返回pd.dataframe({'text':texts,'情感':情感})#解析文本文件,并将其存储为Pandas DataFramestrain_df = parse_emotion_file(“ train.txt”)val_df = parse_emotion_file(“ val.txt”)test_df = parse_emotion_file(“ test.txt”)了解标签分布
此数据集包含16K培训示例和2K示例用于验证和测试。这是标签分布分解:
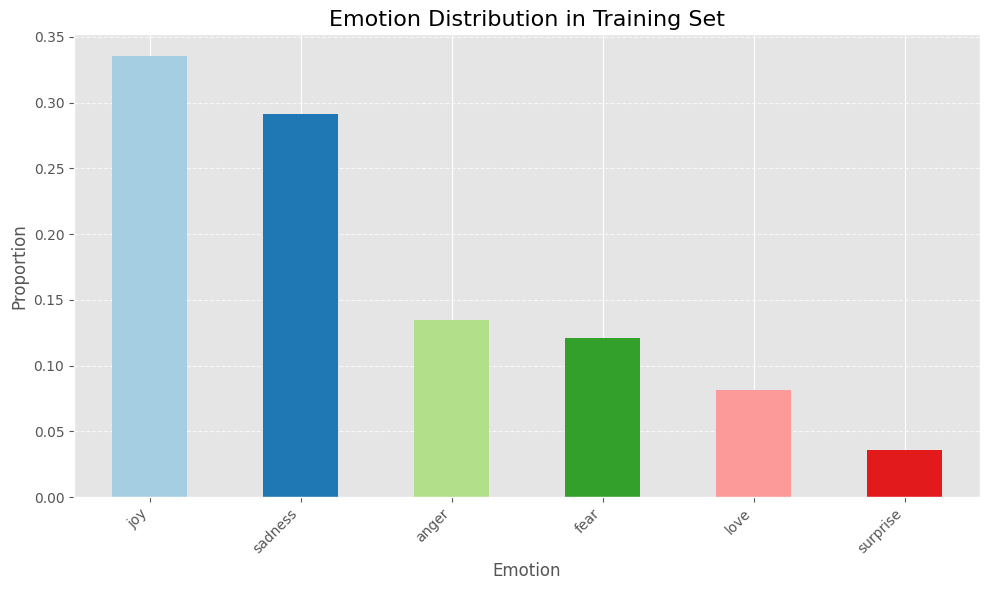
上面的条形图显示数据集为不平衡,大多数样本标签是喜悦和悲伤。
对于生产模型,我将考虑尝试不同的抽样技术来克服此类不平衡问题并改善模型的性能。
步骤3:令牌化和数据预处理
接下来,我加入了Distilbert的令牌:
从变形金刚导入自动源#定义Distilbert的模型路径model_name =“ Distilbert-base-uncund”#加载令牌机tokenizer = autotokenizer.from_pretaining(model_name)然后,我用它来代币化文本数据并将标签转换为数值ID:
#图形数据def preprocess_function(df,label2ID): -将文本数据引起化并将标签转换为数值ID。Args:df(dict或pandas.Series):包含“文本”和“情感”字段的字典对象。– bail2ID(dict):从情感标签到数字ID的映射。回报:dict:包含字典:–“ input_ids”:编码令牌序列âââ–“ fivation_mask”:掩盖以指示填充令牌“标签”:分类的数字标签示例用法:–train_dataset = train_dataset.map(lambda x:preprocess_function(x,tokenizer,label2id),batched = true) -tokenized_inputs = tokenizer(df [“ text”],``填充=“最长”,truncation = true,max_length = 512,– return_tensors =“ pt”)tokenized_inputs [“ label”] = [label2id.get(情感,-1),用于df [“情感”]返回tokenized_inputs - #将数据框转换为拥抱面数据集格式train_dataset = dataset.from_pandas(train_df)#将“ Preprocess_function”应用于标记文本数据并转换标签train_dataset = train_dataset.map(lambda x:preprocess_function(x,label2ID),batched = true)步骤4:微调模型
接下来,我为我们的文本分类文本加了一个预先培训的Distilbert模型。我还指定了此数据集的标签是什么样的:
#从培训数据框架中的“情感”列中获取独特的情感标签labels = train_df [“情感”]。unique()#创建标签到ID和ID到标签映射label2ID = {label:IDX的IDX,枚举(labels)}中的标签}ID2LABEL = {IDX:IDX标签,枚举(labels)}中的标签}#初始化模型model = automodelfor sequencececrification.from_pretrated(model_name,num_labels = len(标签),ID2LABEL = ID2LABEL,–label2ID = label2ID)用于分类的预先训练的大杂货模型包括五层和分类头。
为了防止过度拟合,我冻结前四层,保留在预训练期间学到的知识。这使模型可以保留一般语言理解,同时仅微调第五层和分类标题以适应我的数据集。这是我如何做到的:
#冻结基本型号参数对于姓名,param in Model.base_model.named_parameters():âparam.requires_grad = false#保持分类器可训练对于姓名,param in Model.base_model.named_parameters():如果名称为“ transformer.layer.5”,则名称为:– param.requires_grad = true定义指标
鉴于标签不平衡,我认为准确性可能不是最合适的指标,因此我选择包括适合于精度,召回,F1分数和AUC分数的其他指标。
我还使用了F1分数,精确度和召回的加权平均值来解决类不平衡问题。该参数可确保所有类别对度量标准成比例贡献,并防止任何单个类别主导结果:
DEF COMPUTE_METRICS(P): -用于计算多类分类的计算精度,F1分数,精度和召回指标。Args:P(元组):包含预测和标签的元组。回报:使用加权平均在多类分类任务中说明阶级失衡。 -LOGITS,标签= P - #使用SoftMax(Pytorch)将逻辑转换为概率SOFTMAX = TORCH.NN.SOFTMAX(DIM = 1)pribs = softmax(torch.tensor(logitts)) - ##将逻辑转换为预测的类标签•preds = probs.argmax(axis = 1)返回{“准确性”:准确性_score(标签,preds),#准确度指标“ f1_score”:f1_score(标签,preds,平均='加权'),#f1得分为不平衡数据的加权平均值“精确”:precision_score(标签,preds,平均='加权'),#具有加权平均值的精度得分“回忆”:recce _score(标签,preds,平均='加权'),#召回得分以加权平均值â'auc_score':roc_auc_score(标签,概率,平均=“ macro”,multi_class =“ ovr”)}让我们设置培训过程:
#定义超参数LR = 2E-5batch_size = 16num_epochs = 3weight_decay = 0.01#为微调模型设置培训论点triending_args = triencharguments(âofutp_dir =“ ./结果”,devaluation_strategy =“ step”,deval_steps = 500,学习_rate = lr,per_device_train_batch_size = batch_size,per_device_eval_batch_size = batch_size,num_train_epochs = num_epochs,'wigath_decay = wigath_decay,•logging_dir =“ ./ logs”,logging_steps = 500,–load_best_model_at_end = true,âtric_for_best_model=“ eval_f1_score”,大_is_better = true,)#使用模型,参数和数据集初始化培训师培训师=教练(模型=模型,阿格斯=训练_args,–train_dataset = train_dataset,âeval_dataset = val_dataset,â€tokenizer =令牌,compute_metrics = compute_metrics,)#训练模型打印(f“训练{model_name} ...”)Trainer.Train()步骤5:评估模型性能
训练后,我评估了测试集的模型性能:
#使用微调模型在测试数据集上生成预测precadionions_finetuned_model = trainer.predict(test_dataset)preds_finetuned = prepartions_finetuned_model.predictions.argmax(axis = 1)#计算评估指标(准确性,精度,召回和F1得分)eval_results_finetuned_model = compute_metrics(((preciventions_finetuned_model.predictions,test_dataset [“ label''])))与预训练的基本模型相比,微调的Distilbert模型在测试集上进行的如何:

从本质上讲,这是随机猜测的,正如AUC分数为0.5所反映的那样,这表明没有比机会更好。
微调后,模型显着所有指标都有改进,在正确识别情绪时达到83%的精度。这表明该模型即使只有16K培训样本,该模型即使仅使用16K培训样本,都可以成功地学习了有意义的模式。
太神奇了!
步骤6:用塑造解释预测
我在三个句子上测试了微调模型,这是它预测的情绪:
- 在大批人群面前说话的想法使我的心脏竞争,我开始感到不知所措。
- 我可以相信他们有多无礼!我在这个项目上非常努力,他们只是在没有聆听的情况下就将其驳回。它令人发指!愤怒ð
- 我绝对喜欢这部新手机!相机质量很棒,电池持续一整天,而且如此之快。我无法对自己的购买感到满意,我强烈推荐给任何寻找新手机的人。欢乐ð
令人印象深刻,对吧?
我想了解模型如何做出预测,我使用了塑造(Shapley添加说明)可视化特征重要性。
我首先创建一个解释器:
#建立一个预测的管道对象preds =管道(“文本分类”,模型= model_fineTuned,â€tokenizer =令牌,rother_all_scores = true,)#创建解释器解释器= shap.explainer(preds)然后,我使用解释器计算了形状值:
#使用解释器计算形状值shap_values = duminder(example_texts)#制作形状文本图shap.plots.text(shap_values)下面的图可视化输入文本中的每个单词如何使用塑形值对模型的输出贡献:

在这种情况下,该情节表明焦虑是预测恐惧为情感的最重要因素。
Shap Text图是一种很好,直观和交互式的方式,可以通过分解每个单词影响最终预测的程度来理解预测。
概括
您成功地学会了从文本数据中微调Distilbert进行情感分类!(您可以在拥抱脸上查看模型这里)。
可以针对许多现实世界应用进行微调变压器模型,包括:
- 标记客户服务票(如引言中所述),
- 在基于文本的对话中标记心理健康风险,
- 在产品评论中检测情绪。
微调是一种使用相对较小的数据集将强大的预训练模型适应特定任务的有效方法。
接下来你会微调什么?
想建立您的AI技能吗?
ðð»我运行AI周末和编写有关数据科学,AI周末项目的每周博客文章,有关数据专业人士的职业建议。
资源