


可以肯定地说,在2025年,世界上最好的工作是NVIDIA的首席执行官,并且该公司的联合创始人詹森·黄(Jensen Huang)将公司引导到了高度的高度,就像联合创始人托马斯·沃森(Thomas Watson)与国际商业机器所做的那样,Larry Ellison与Oracle和Steve乔布斯(Steve Elcare)一起使用了Apple Apple Computer。
但是,肯定是NVIDIA的第二好的工作是Bill Dally拥有的工作。或更确切地说,这两个工作同时也在做。正如Nvidia的首席科学家一样,他是斯坦福大学计算机科学系主席多年以来担任的角色,在MIT和CALTECH的筹码和互连和系统中担任了杰出的职业,达利(Dally)在此之前已有数十年的历史,他说,他在公司周围的一切都在努力宣传了所有的工作,并能够与他一起进行,并能够与他一起进行。”在圣何塞(San Jose)中,达利(Dally)补充说,他还有另一项正在进行NVIDIA研究的工作,这意味着他可以与许多真正聪明的人一起解决许多困难的知识问题。”
达利的演讲总是很有趣,而最近的GTC的演讲也不例外。像往常一样,达利(Dally)在硬件和软件中选择了一些整洁的技术,并钻入了它们,要么展示了他们在销售GPU加速系统时如何给Nvidia具有当前优势或将来可能。
这使我们思考了NVIDIA的研发支出,这很繁重,但由于过去一年半的NVIDIA收入和利润的爆炸,现在看起来很小。但是毫无疑问:NVIDIA投入了大量投资,以创造未来的未来,即它现在比地球上的任何其他供应商都从中受益更多。
早在2008年11月,当NVIDIA首次在Austin举行的超级计算会议上首次阐明了HPC模拟和建模领域中的GPU计算愿望。这是在Fairmont Hotel举行的第一次GPU技术会议近一年之前PowerXcell数学加速器刚刚闯入了前5月的高性能Linpack基准上的Petaflops屏障。只是向您展示我们离AI革命和当前现实的距离,太平洋西北国家实验室主持了一个小组讨论,称为â电力公司会通过购买电力合同而赠送超级计算机吗?(我参加了本次会议,并且仍然有演讲的照片和丹·里德(Dan Reed),他们刚刚从一年提前一年从伊利诺伊大学的国家超级计算申请中心加入微软,手里拿着一些现在晦涩难懂的计算设备。)
事实证明现实截然不同:您会为超级计算机和电力合同支付比您想象中能获得的预算更多的费用吗?也许我们将向SC25人提出小组讨论。这种现实完全由NVIDIA数据中心GPU的性能,功耗和成本占据主导地位。
而且,我们认为,未来有所不同的部分原因是,NVIDIA GPU成为HPC,Analytics和AI工作负载的主力平行计算引擎,即使具有矢量的CPU,有时甚至有张力引擎的CPU仍然可以做很多并行的工作。
如果Nvidia没有看到价值,这都不会发生Brook流处理编程语言,将数学计算卸载到ATI(现在AMD)和NVIDIA GPU上的浮点着色器单元和雇用其创作者伊恩·巴克(Ian Buck)创建现在所谓的库达。数据中心中GPU计算的需求迫使GPU设计不断发展及其编程堆栈。当世界创建了足够的数据时,AI算法从时间的黎明(1980年代初)实际上起作用时,GPU是完成这项工作的最佳计算引擎,并成为AI Revolution的平台,特别是我们的意思是,我们的意思是古典机器学习。Genai及其基础模型只是很可能是AI创新波浪的第二波。正是NVIDIA的研究,在达利(Dally)的关注下,确保GPU芯片的发展,并且可能与大量平行计算的工作负载可以与未来的GPU结婚,并保持技术飞轮,并保持金钱飞行。
把它放在我的账单上
这已经进行了投资。我们直到2010年4月才开始跟踪NVIDIA的财务状况,这是其2011财年的第一季度,因为其数据中心业务甚至还没有材料。NVIDIA甚至没有举报数据中心部门的收入,直到2015财年的第一季度收入,而且销售额为5700万美元,总销售额为137亿美元。并非一无所有。
这是NVIDIA奠定了基础,以利用AI的第一波并进入第二波。放心,它已经预测了第三波(它称为物理AI),毫无疑问,为第四波浪潮做准备。
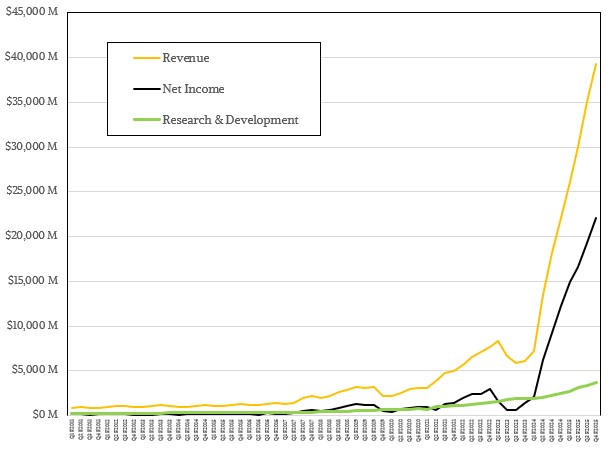
现在,对于经验丰富的眼睛来说,似乎NVIDIA正在削减研发支出,我们应该担心其未来的投资。不正确。The fact is, Nvidia has been able to corner the market on GPU compute because of its two decades in creating the CUDA platform, a collection of over 900 libraries, frameworks, and models that underpin every accelerated HPC and AI application in the world, and the fact that it can pay the absolute top dollar for the scare HBM memory that modern datacenter GPUs require to run AI training workloads, and increasingly AI inference由于思想链或推理模型的强烈计算需求。
如果HBM并不那么稀缺和昂贵,AMD将对它的MI250和MI300 GPU堆放到天堂,并且卖出的GPU比目前的GPU要多得多。但是HBM是恐慌,AMD不能像Nvidia那样付出很多。但是,对于某些用户而言,HPC人群的CUDA X堆栈(如NVIDIA软件所谓的称呼)对AI人群的重要性并不重要,AI人群站在HPC人群的肩膀上,无论他们否则抗议多少抗议。(例如,NCCL是MPI的笨拙。)这就是为什么您会看到AMD使用其GPU追求传统的HPC中心,并在那里获得吸引力,因为HPC中心在计算时非常敏感。AI客户进行计算以制造有望赚钱的模型,他们可以将许多投资者排成一列以实现这一目标。HPC中心依靠州和国家政府。
如果您看过去十年半,NVIDIA的R&D支出一直占收入的20%至25%,这是Meta平台在同一时间内设计自己的服务器,存储,网络和数据中心以来所做的一切。Google和Oracle一样,往往在研发上花费15%至20%的收入。微软约为15%,给予或接受Smidgen,而亚马逊则降低了几分。AMD过去的花费在15%至20%之间,但现在与Nvidia相同。但是,在十二个月后,NVIDIA的销售额为1305亿美元,比AMD带来的258亿美元高5.1倍。
也就是说,尽管Nvidia在Genai Boom期间一直在增长其研发预算,但它并没有花费20%至25%的研发收入。实际上,自2023年夏天以来,当Genai Boom寄给Nvidia收入并赚钱飙升以来,它一直是销售的趋势。在十二个月的时间里,它平均占收入的10%。但这仍然占2025财年与2024财年的增长相比,增长率为48.9%,研发总计为129.1亿美元。
该日志图表显示了NVIDIA的研发支出增加的稳定程度:
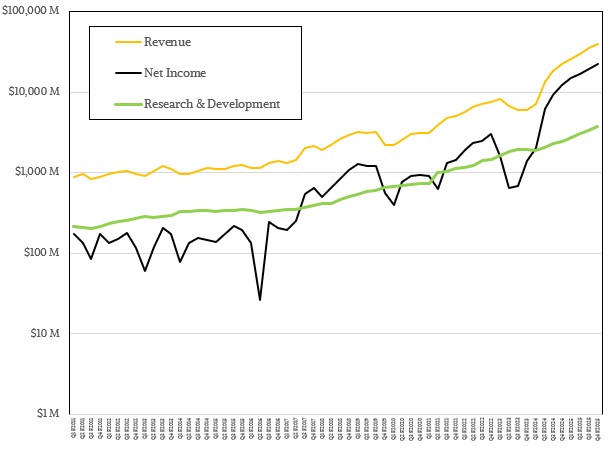
我们不知道该数字有多少是r,d是多少,但是我们认为,随着NVIDIA接管越来越多的数据中心硬件和软件堆栈,R Investments量不断增长,D成本爆炸。很难用任何精确性地说。
Dally将其提出来,NVIDIA研究大致分为两部分,他称之为供应方和需求方面。
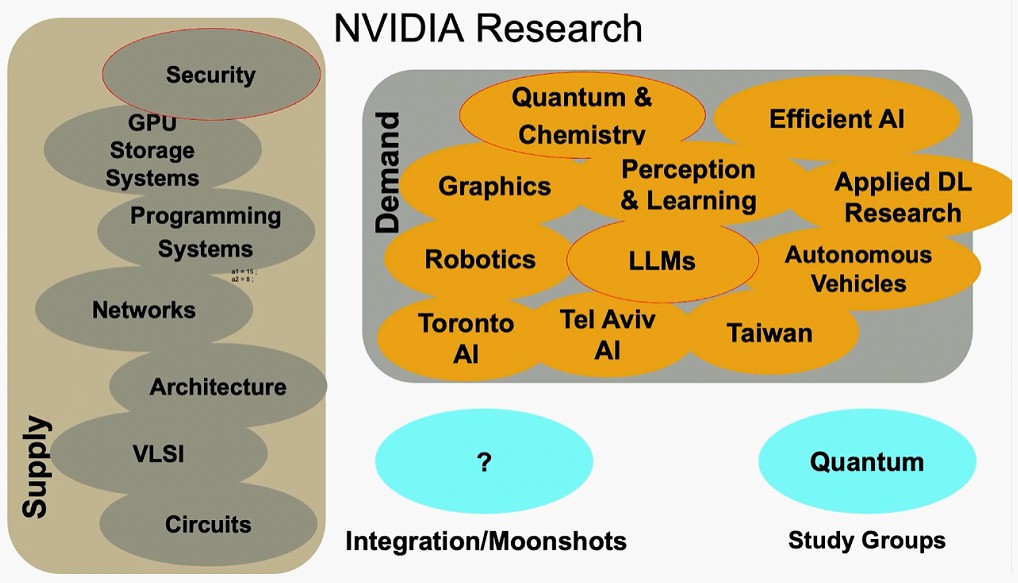
供应方面涉及从整个电路一直到系统体系结构的所有事物的研究,正如他所说的那样,提供了使GPU伟大的技术的明确工作。现在,此供应方研究包括GPU存储系统和安全性,这些存储系统和安全性是任何商业AI系统不可或缺的。
需求方是要研究各种应用领域的研究,以使加速计算的宇宙不断扩大,从而提高了对NVIDIA GPU的需求。有两个不同的AI组,一个在多伦多,另一个在特拉维夫,另一个在圣克拉拉进行了深入学习研究。台湾的实验室是生成AI工作以及多模式学习和3D视觉的地方。有专门的AI实验室,专注于机器人技术和自动驾驶汽车,而其他集中在大型语言模型或有效的AI算法上的团体。显然,有三个小组专注于图形,其中一组从事量子物理和化学。
Nvidia Research刚刚组成了一个量子计算研究小组,该小组正在试图评估该技术的当前状态,并查看NVIDIA在机会中的何处,何时何时何地。
而且每个人偶尔都有达利所说的月光,来自NVIDIA研究组织以及整个产品部门的研究人员都可以将新技术栩栩如生。是图形卡一部分的RT核心(因此,出售到数据中心的一些推理卡)是用来加快射线跟踪处理的速度的一个示例。该项目始于2013年,RT核心于2017年进入Turing GPU。
NVIDIA可能有大约500名研究人员正式是NVIDIA研究的一部分,但是来自产品组的成千上万的工程师也是某些项目的一部分。Nvidia目前拥有约36,000名员工,我们估计其中75%的人在软件上工作,这是至少在过去十年中NVIDIA劳动力的传统份额。
NVLink和NVSwitch是NVIDIA研究中最成功的技术之一,这是我们之前讨论过的。但是在他在GTC 2025的主题演讲中,达利进一步阐述了:
达利解释说,我实际上是在2012年左右从能源部获得了一份合同,当时我们正在为橡树岭建造超级计算机,”达利解释说,指的是IBM是Prime承包商的峰会超级计算机的合同。作为这些计划的一部分,有研发资金。因此,我申请了一些开发GPU网络。而且我记得当时,能源部想花钱分享该项目。他们想让NVIDIA支付40%,并支付60%的能源付款。我去了詹森,他说:“绝对不是。是的,我们不进行网络。我们是一家GPU公司。所以我回到了能源部,幸运的是,他们100%资助了该项目,以开发第一个NVSWWITCH和第一个NVLINK。实际上,从那里开始,这些项目在我们完成该项目之前就被我们抓住了,他们意识到他们需要使几个GPU看起来像一个大GPU。从那以后,Nvidia就参与了网络。
但是达利说,NVIDIA研究最重要的技术转移可能是机器学习。
达利回忆说,在与我的斯坦福大学同事安德鲁·恩格(Andrew Ng)共进早餐后,我在2011年获得了NVIDIA研究。”当时他在Google Brain使用16,000 CPU在互联网上发现猫。我想,哎呀,我们可以用GPU来做到这一点,然后少得多。因此,我分配了Brian Catanzaro(当时是编程系统研究人员)与Andrew合作,他将该软件放置在48 GPU上运行,实际上在48 GPU上运行的速度比16,000 CPU的速度更快。该软件变成了CUDDN,并向我们启动了我们今天经过深入学习的道路。
这些年来,已经有很多技术转移的成功,这是一个很小的样本:
![]()
One of the technologies that Dally talked about at this GTC was ground-referenced signaling, which he talked to us way back at Hot Chips in the summer of 2019. GRS is a single-ended signaling technique and, to simplify it a whole lot, allows Nvidia to drive twice the bandwidth per pin through the wire traces on an organic substrate at twice the bandwidth per pin as other differential signaling techniques and at twice the芯片边缘每毫米的带宽。而且,我们六年后我们在这里使用了GRS信号传导将NVIDIA的CG100 CPU连接到DGX GB300系统中即将来临的Blackwell b300 GPU。

早在2013年,当GRS研究才刚刚开始时,NVIDIA可以以每位一半的picojoule进行25 GB/sec的信号传导,但是为了使信号更强大,它将其提高到每位约1 picojoule,而生产GRS则将其提高。达利说,典型的PC-Express链接是按5 picojoules到6 picojoules的信号传导的需求。
达利(Dally)只是抛弃我们可以期望最终进入产品的新想法。这里是基于逆变器的信号,例如,您可能会在一个软件包上链接多个gpu chiplets:

这是用于3D芯片堆叠的互连的NVIDIA方法:
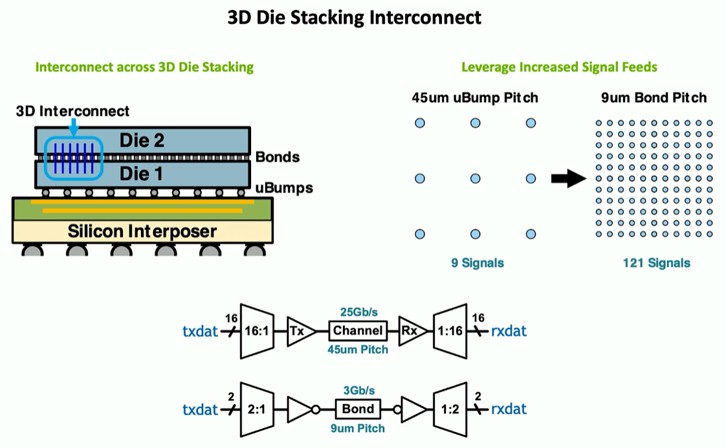
这是这种3D堆叠的方式与插座者的每销带宽和femtojoules每位消耗以推动信号的方式相比:

从观看Dally的Nvidia研究演讲中,它不断地进行,这是他多年来他所做的和各种事件所做的。
过去,当IBM如此富有时,它可能会沉迷于它想要的任何研究,这样就这样做了。然后,当业务在1990年代初在岩石上上升时,大蓝色是距离破产的三头发,这是IBM唯一从外部带来的路易斯·格斯特纳(Louis Gerstner)的第一件事之一就是让IBM研究专注于解决针对影响实际客户的实际问题。
NVIDIA从来不必重新调整其研究人员和工程师来做到这一点。这就是他们所做的一切。希望Nvidia现在在收入流和净收入池方面非常丰富,因此该公司不会过度沉迷于研究,担心它会错过任何下一波浪潮。它需要做的一切都坚持其GPU编织,它的路线图显示了计划。
还有一件事要考虑:Nvidia并没有发明所有内容,但它确实发明了它认为与竞争或建立新市场所需的东西。因此,例如,NVIDIA购买了第三方的PCI-Express开关和录音机。它从多个供应商那里购买了DRAM,GDDR,HBM和闪存。它对从外部带来的技术和有必要的中立性具有特定用例的偏好。它将购买公司 - Mellanox Technologies就是一个很好的例子,库卢斯网络也是如此。

注册我们的新闻通讯
直接从我们到您的收件箱中,介绍了一周的亮点,分析和故事,两者之间一无所有。
立即订阅