
在人工智能下的音乐美学教育中优化的分析
作者:Peng, Yixuan
介绍
研究背景和动机
在人工智能快速发展(AI)的背景下,音乐教育领域也正在发生前所未有的变化。AI技术的突破,尤其是深度学习(DL)技术,为音乐审美教育带来了新的机会和挑战1,,,,2。音乐审美教育是一种审美教育的一种形式,它使用音乐作为媒介。它旨在通过学习,欣赏和创作音乐来培养学生的审美能力,人文素质和情感体验。它不仅专注于掌握音乐知识和技能,而且还强调音乐对个人情感,思想和人格发展的影响。它可以通过音乐来帮助学生感受,理解和创造美丽。与传统的音乐教育不同,主要侧重于音乐理论,表演技巧以及音乐作品的繁殖,音乐审美教育更加重视音乐的美学价值和文化意义。它优先考虑学生的情感经历和艺术感知。相比之下,传统的音乐教育更面向发展专业技能。然而,音乐审美教育努力通过音乐来促进整体个人发展,使其成为个人精神世界的重要组成部分3。
深度学习是机器学习的一个分支,它使用多层神经网络来模拟人脑学习的方式,从而自动从大量数据中提取特征以进行模式识别和预测。将人工智能和深度学习整合到教育中面临许多挑战。一个是AI驱动平台的可访问性和负担能力。由于高科技成本和大量硬件要求,许多学校和教育机构都难以提供普遍的访问。为了解决这个问题,可以开发更具成本效益的基于云的解决方案或开源平台来降低使用障碍。另一个挑战是数据隐私和道德考虑。教育领域涉及大量个人数据。使用AI时,必须确保保护学生隐私并遵守相关法律法规,例如GDPR或美国FERPA。数据加密和去识别技术可用于增强安全性。同时,深度学习模型中可能存在偏见,这可能导致不公平的评估结果,尤其是在不同的学生人群中。为了解决此问题,需要在培训数据集中进行公平调整,以确保它们包括各个组的代表并不断优化模型以减少偏见。因此,本文致力于探索基于深度学习的音乐美学教育方法的可能性和途径,希望在AI时代带来新的方向和实用途径。
本文的目的是探索如何充分利用DL技术的优势,以优化和创新音乐审美教育方法,以增强学生对音乐的欣赏,理解和创造力,培养更全面的音乐素养,同时为音乐教育者和促进现代化音乐教育提供更有效的音乐教学工具和科学教学工具和策略。通过本文,预计它将弥补现有音乐教育体系的可能缺点,并为中国音乐美学教育的未来发展提供强有力的理论支持和实际参考。
研究目标
本文的动机源于AI技术,尤其是DL技术在教育领域越来越重要的影响,以及其在音乐美学教育中的潜在巨大应用价值。研究目标是使用DL技术来解决传统音乐审美教育中个性不足,单个教学方法和不完美的反馈机制的瓶颈问题4。
首先,本文介绍了DL技术,以准确分析和确定音乐作品中的情感特征。这一技术突破使得对音乐情感的分析不再限于传统的主观评估,而是依靠数据驱动的方法来获得更客观和准确的情感识别。其次,实验方法采用了智能数据反馈机制,这将音乐审美教育中的学生情感反应转化为视觉数据,并根据这些数据实时调整教学策略,以为学生提供个性化的美学教育指导。这种聪明的反馈机制增强了教师与学生之间的互动,并使教学更具针对性5。最后,实验方法将注意定量和定性方法的组合。此外,通过对学生情感反应的定量分析,它可以补充传统教育中的定性评估方法,从而使音乐审美教育更加科学。这种方法不仅丰富了教育评估的手段,还提供了以优化教学内容和方法的数据支持,并促进了智能和个性化方向的音乐审美教育的发展6。
文献综述
近年来,随着AI技术的快速发展,尤其是DL领域的主要突破,其在各种教育领域的应用变得越来越广泛。音乐审美教育是一个充满艺术性和创造力的重要分支,也迎来了前所未有的发展机会7,,,,8,,,,9。许多研究人员已经开始积极探索AI和DL技术与音乐审美教育方法和实践的集成。这种整合旨在优化教学过程,提高教学效率,并满足现代时代的个性化和聪明的教育需求10。
Bharadiya研究了如何使用DL技术自动分析和标记音乐材料,以实现对音乐元素的智能分析和个性化教学。开发了基于DL的音乐审美教学平台。它可以根据学生的音乐偏好和学习进度智能地推荐学习内容,并通过实时反馈机制优化教学路径。实验表明,该平台在提高学生的音乐美学能力和学习热情方面具有重要优势11。Moysis着重于AI技术如何改变传统音乐美学教育模式。这包括利用DL算法来识别和传达音乐情绪,以及整合虚拟现实(VR)技术来建立沉浸式音乐学习环境。研究结果表明,AI优化的音乐美学教育方法不仅改善了学生对音乐的认知理解和情感共鸣,而且还大大增强了他们的创新思维和实践能力12。Shukla提出了一种基于DL技术的音乐审美能力的新教学方式,并在实际的教学环境中进行了实验。通过构建深层神经网络模型,对学生的音乐美学能力进行了定量评估,并根据评估结果对教学内容和策略进行了动态调整。研究表明,该模型可以更准确地满足学生的差异化学习需求,从而有效地提高音乐审美教育的效果和效率13。
在情感识别研究领域,国际研究一直在探索基于深度学习的方法。Oksanen等。提出了基本的情感理论,该理论奠定了基于面部表情的情感识别的理论基础14。Shukla强调了多模式情感识别的重要性,提倡声音,文本和面部表达数据的组合以提高识别精度13。Borkowski使用生成的对抗网络(GAN)来优化面部表达数据,增强识别系统的概括能力15。在中国,研究人员基于国际成就,以优化中文和地方文化的情感识别方法。例如,CUI(2015)引入了一种基于深信念网络(DBN)的普通话语音情感识别方法,该方法改善了特征提取16。Huang等。开发了一种多模式情感识别模型,该模型结合了注意力机制,以增强音乐教育中的情绪感知。研究指出,情感识别技术在音乐美学教育中的应用可以优化智能教学反馈,提高个性化音乐建议的精度并增强学习者的情感体验17。
总而言之,研究人员开发了几个基于深度学习的教学平台和模型。这些工具可以通过自动分析音乐材料,识别情绪和使用VR来显着增强学生的音乐美学能力和学习热情。但是,现有研究具有一些潜在的局限性和偏见。例如,尽管深度学习在提取音乐特征方面表现出色,但在培养音乐审美教育中情感表达和美学意识的主观性方面,它却差不多。许多研究着重于量化学生的学习进步和个性化需求,但全面考虑了复杂因素,例如情感反应和文化背景,这可能会导致个性化教学中的偏见。此外,现有的深度学习模型通常依赖大量数据和高计算能力,这可能会构成可伸缩性问题,尤其是在资源有限的教育环境中。未来的研究需要进一步增强模型的情感感知能力,并增强其在非结构化数据和主观经验中的应用,以克服当前方法的局限性并促进音乐美学教育的全面发展。
研究方法
AI和音乐审美教育的结合
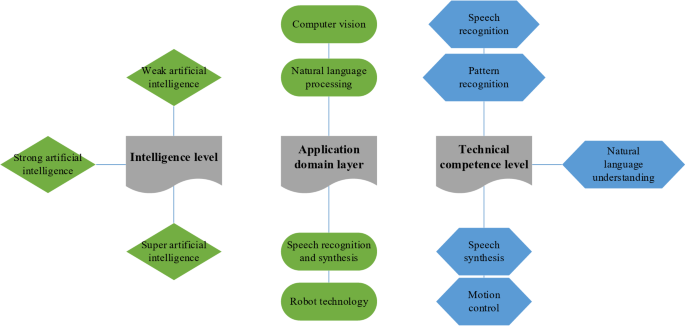
AI是一个专门用于理解和创造智能行为的科学技术领域。人工智能整合了计算机科学,统计学,认知科学和其他学科的知识,旨在研究,设计和发展智能代理。这些代理可以感知环境,学习,理性,解决问题并独立做出决定。AI的应用形式是多样的,涵盖但不限于机器人技术,语音识别,图像识别,自然语言处理(NLP),专家系统和机器学习。根据其功能和复杂性,AI可以进一步分为三个级别:弱AI,强AI和Super AI18。它的分层划分如图所示。 1以下:

AI层次结构。
弱AI专注于特定任务的执行。尽管强大的AI具有跨学科和全面的人类智能,并且可以执行人类可以完成的任何认知任务。至于强大的人工智能,假定它存在于人类智力的范围之外12,,,,15,,,,19。随着技术的发展,AI越来越渗透到社会生活的各个方面,并继续促进科学和技术进步以及工业升级20。
随着AI技术的持续发展,重塑音乐为培养学生的学术成就,美学感知,艺术表达和文化理解提供了更多的支持和创造力。在此基础上,讨论了使用AI技术促进音乐美学教学的改革和发展的可能性21,,,,22。通过应用先进的AI技术,音乐审美教育可以实现更精致和个性化的教学策略。它们之间的关系显示在表中 1:
一方面,人工智能通过大数据分析和算法模型准确地识别和评估学生的音乐审美倾向,学习方式和能力水平。这样可以提供个性化的教学内容和学习路径,从而增强了教学的相关性和有效性。另一方面,AI也可以用于情感分析,风格识别,创造力和音乐创作的其他方面。这有助于学生对音乐的内部结构和外部表达有了更深入的了解,从而扩大了他们的美学视野并增强了对音乐的欣赏。此外,聪明的音乐教学系统可以通过实时反馈和互动来促进学生的积极参与和沉浸式学习体验。从传统的灌输转变为新的教学模式,重点是探究和体验式学习,促进了音乐美学教育的质量和效率,从而导致教育成果的双重改善23。
DL算法
DL是一种机器学习方法,它受到人脑神经网络的工作原理的启发,并通过构建一系列相互联系的人工神经网络(ANN)级别来进行高级抽象和学习数据24。在DL模型中,原始输入(例如图像像素,文本字符或声音波形)首先通过多级非线性转换。每一层将从输入数据中提取越来越复杂的特征表示。这种逐层处理机制使模型能够自动学习和探索原始数据的有用功能,而无需人工设计功能25,,,,26,,,,27。DL的核心技术包括深神经网络(例如卷积神经网络,经常性神经网络,长期和短期记忆网络等)。它们在解决许多复杂问题方面非常出色,例如图像识别,语音识别,NLP,机器翻译,推荐系统,游戏策略和自动驾驶。通过通过优化算法(例如Back Expagation算法)更新模型参数,DL模型可以自我训练和改进大型数据集,从而实现高精度预测和决策能力28。随着计算能力的增强和大数据的普及,DL已成为现代AI领域的关键技术之一,并在许多行业中取得了革命性的突破29。
DL的无监督学习算法可用于学习音乐信号的内在功能表示。通过降低维度并重建音乐数据,自我编码器能够从原始音频信号中提取有意义的音乐功能。这些特征可能包括节奏,音色和谐波结构等。这种提取的功能可以帮助教师设计和实施目标教学活动30。一种典型的无监督学习方法是找到数据的最佳表示。最好的表达方式可以不同,但通常意味着与固有传达的信息相比,某些限制或局限性。从本质上讲,它表示具有更少的优势或约束。因此,保留尽可能多的有关X的信息至关重要。
矩阵x被设计为结合\(M \ times n \)。数据的平均值为0,即\(e \ left [x \ right] = 0 \)。如果不是0,则从预处理步骤中的所有样本中减去平均值,并且数据很容易集中31。公正的样品协方差矩阵,对应于x给出如下:
$ \:\ text {v} \ text {a} \ text {r} \ left [\ text {x} \ right] = \ frac {1} {1} {m-1} {x}^}^{t} x $$
(1)
var [z]是一个对角矩阵,转化为z =\(\:{w}^{t} x \)通过线性变换。设计矩阵的主要组成部分x由\({x^t} x \)32,如下:
$$ \:{x}^{t} x = w \ wedge \:{w}^{t} $$
(2)
假设w是奇异值分解的正确的单数矢量\(x = u \ sum {{w^t}}} \),并服用w作为特征向量的基础,可以获得原始特征值方程如下:
$ \:{x}^{t} x = {\ left(u \ sum \ \:{w}^{t} \ right)}^{t}^{t} u \ sum \:{w}^{w}^{t} = w {
(3)
这可以完全解释算法中的var [z]是对角线矩阵。使用主要成分分解x,差异x可以表示为:
$ \:\ text {v} \ text {a} \ text {r} \ left [\ text {x} \ right] = \ frac {1} {1} {\ text {m} -1} -1} {\ text {x}}}}}}}}
(4)
$$ \:= \ frac {1} {m-1} {(u \ sum \:{w}^{t})}^{t}^{t} u \ sum \:{w}^}^{t} $$
(5)
$$ \:= \ frac {1} {m-1} w {\ sum \:}^{t} {t} {u}^{t} u \ sum \ \:{w}^{t} $$
(6)
$$ \:= \ frac {1} {m-1} w {\ sum \:}^{2} {2} {w}^{t} $$
(7)
\({u^t} u = i \)被使用,因为矩阵你根据单数值的定义是正交的,这表明Z的协方差满足对角线要求,如下所示:
$ \:\ text {v} \ text {a} \ text {r} \ left [\ text {z} \ right] = \ frac {1} {1} {m-1} {z}^{t}^{t} z $$
(8)
$$ \:= \ frac {1} {m-1} {w}^{t} {x}^{t} {t} {x}^{t} w $$
(9)
$$ \:= \ frac {1} {m-1} {w}^{t} w {\ sum \:}^{2} {2} {w} {w}^{t} w $$
(10)
$$ \:= \ frac {1} {m-1} {\ sum \:}^{2} $$
(11)
上面的分析表明,当数据x通过线性转换投影到z时w。由获得的数据表示的协方差矩阵是对角线\(\ left({\ sum {^{2}}}}} \ right)\)\),这意味着Z中的元素彼此独立1。
通过这些无监督的学习技术,音乐审美教育可以变得更加聪明和个性化。同时,它可以帮助教师和研究人员从新的角度检查和优化教学方法,从而提高音乐教育的质量和效果。
音乐审美教育方法基于AI环境中的DL
在此基础上,本文提出了基于DL的新音乐审美教学模式。基于AI,该系统为学生学习提供了各种支持服务33,,,,34。系统的功能设计如图所示。 2:

系统功能设计。
机器学习在音乐行业中的作用是从音乐中提取数据,将其输入特定的模式,从中学习功能,然后进行分析和整理。特定的伪代码的安排如下:
使用多模式深度学习框架初始化AI模型。
输入音乐功能(MFCC,PLP,旋律)和情感数据(唤醒,价)。
训练并优化个性化音乐审美教育反馈的模型。
借助DL技术,通过分析大量用户数据,AI可以深入了解每个学生的学习方式,兴趣倾向和技能水平。然后,AI提供自定义的音乐欣赏和学习内容。目的是确保音乐审美教育能够更准确地满足个人需求,并真正根据自己的才能来教会学生35。同时,人工智能可以实时监视和响应学生的学习行为和反馈。它可以动态调整教学计划,以确保教育过程有效且有针对性,从而增强了学习经验的有效性。其次,DL增强了音乐教育中的互动体验。通过集成VR/AR技术和DL算法,建立了高度沉浸式的音乐教学环境,以便学生可以直接感受到音乐中音乐中的节奏,旋律,和谐和其他美学元素。
音乐功能和音乐情感模型基于AI环境中的DL
这里研究的音乐功能主要分为Mel频率Cepstral系数(MFCC)功能和感知线性预测(PLP)功能。两种:MFCC是在语音信号处理中广泛使用的功能参数,尤其是在语音识别和扬声器识别中。MFCC的核心思想是模拟人类听觉系统的合理感知机制。PLP功能也是语音识别中常用的特征参数,但是与MFCC不同,PLP功能更直接基于人类听觉感知模型。PLP通过一系列的语音信号频谱模拟来增强语音识别。
本文中的音乐情感模型是长期记忆(LSTM)模型。LSTM是RNN的变体,也是本文设计和构建的神经网络模型的重要组成部分之一。LSTM不仅继承了传统RNN的优势,而且还克服了RNN梯度爆炸或消失的问题。它可以有效地处理任意长度串联数据并捕获数据的长期依赖性,并且与传统的机器学习模型相比,处理速度和训练速度的总量已大大提高。LSTM由许多重复单元组成,这些单元称为内存块。每个内存块都包含三个门和一个内存单元,三个门分别是忘记门,输入门和输出门。记忆块的特定计算流如图所示。 3:
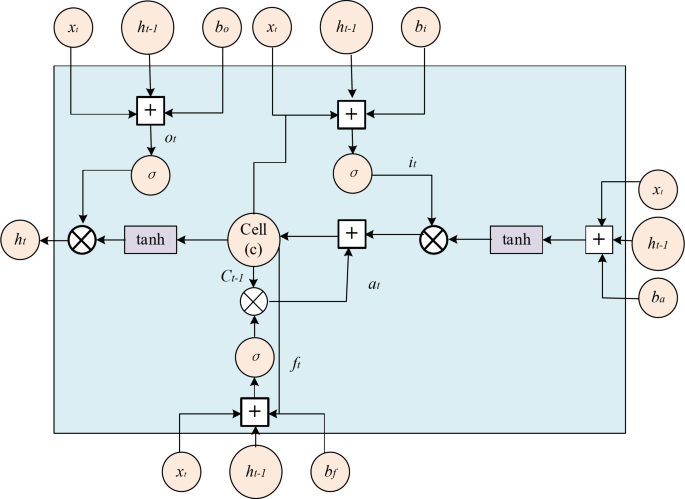
LSTM的网络结构图。
用于计算输入层信息的方程式获取上部输入单元数据的方程如下:
$$ {a_t} = \ tanh \ left({{{w_ {xa}}} {x_t}+{w_t}+{w_ {ha}} {
(12)
\({v_t} \):候选记忆单元的值。
\(\ tanh \):双曲线切线激活函数,用于将输入压缩到[-1,1]间隔中。
\({W_ {Xa}} \)\):候选内存单元的重量输入。
\({世界卫生大会}}\):隐藏状态的重量到上一刻的候选记忆单元。
\({x_t} \):在当前时刻输入。
\({H_ {T -1}} \)\):上一刻的隐藏状态。
\({b_a} \):候选记忆单元的偏见。
输入门,忘记门和输出门由Sigmoid函数控制,并且特定的计算方程如下:
$$ {i_t} = \ sigma \ left({{w_ {xi}}} {x_t}+{w_t}+{w_ {hi}} {
(13)
\({它}\):输入门的激活值,以控制当前输入信息进入内存单元的程度。
:Sigmoid激活该函数,该功能将输入压缩到[0,1]的间隔中,并用于控制信息流。
\({w_ {xi}} \)\):输入到输入门的重量输入。
\({w_ {hi}} \):隐藏状态在上一刻的输入门的重量。
\({双}\):输入门的抵消。
$$ {f_t} = \ sigma \ left({{w_ {xf}}} {x_t}+{w_f} {
(14)
\({f_t} \):遗忘门的激活值在上一刻控制记忆单元的信息保留程度。
\({w_ {xf}} \)\):重量进入了忘记的大门。
\({w_ {hf}} \)\):从隐藏状态到上一刻的重量。
\({b_f} \):忘记门。
$$ {o_t} = \ sigma \ left({{w_ {w_ {x0}} {x_t}+{w_ {h0}} {
(15)
\({o_t} \):输出门的激活值在当前时刻控制内存单元的信息输出度。
\({w_ {x0}} \):输入输出门的重量输入。
\({w_ {h0}} \)\):隐藏状态在上一刻的输出门的重量。
\({b_0} \):偏移输出门。
ï代表sigmoid函数,计算方程为:
$$ \ sigma(z)= \ frac {1} {{1+ {e^{ - z}}}} $$
(16)
记忆单元和输出门的状态值如下:
$$ {c_t} = {f_t} \ odot {c_ {t - 1}}}+{i_t} \ odot {a_t} $$
(17)
\({C_T} \):当前时刻内存单元格状态。
\(\ odot \):在元素级别(Hadamard产品)的乘法。
\({C_ {T -1}} \)\):上一刻的记忆单元状态。
\({在}\):当前时刻候选记忆单元格。
$$ {h_t} = {o_t} \ odot \ tanh({c_t})$$
(18)
\({h_t} \):当前时刻的隐藏状态。
\(\ tanh({c_t})\)\:在当前时刻将双曲线切线激活函数应用于内存单元状态。
实验设计和性能评估
数据集集合
韩国Yeungnam University的音乐学院的大学生(其年龄超过18岁)被视为研究样本,并随机选择了100名学生。
实验的具体步骤如下:首先,参与者将收听一系列精心选择的音乐摘录,每个音乐摘录持续约3分钟。音乐随着风格和情感语调而变化,涵盖了喜悦,忧郁和兴奋等情感。在实验过程中,将使用可穿戴设备实时记录参与者的生理反应(例如心率和皮肤电导)。同时,他们的面部表情将被摄像机捕获,以进一步分析情绪状态。实验后,将将模型的预测情绪状态与参与者的实际情感反应进行比较,以评估模型的准确性和有效性。
(1)数据集构造。
该数据集应包括多模式数据源,主要包括生理响应,面部表情,眼睛跟踪数据以及参与者在实验过程中产生的音乐音频功能。对于生理响应数据,可以将心率监测器和皮肤电导传感器等设备用于收集。面部表达数据可以通过高精度摄像机捕获,并使用面部表达识别算法提取。可以使用眼动物跟踪器记录眼睛跟踪数据,以衡量参与者的注意水平。音乐音频数据应根据已知的情感音调进行分类。
(2)注释方法。
为了确保数据的准确性和一致性,应使用双盲方法通过多个注释来完成情绪反应和注意状态的注释,以减少偏见。情绪反应注释可以基于参与者的生理反应和面部表情,并针对每个情绪类别(例如欢乐,悲伤,焦虑,兴奋等)设定了明确的标准,以确保一致的标签。考虑到眼动频率和固定持续时间之类的指标,通过分析眼睛跟踪数据来评估注意状态,重点是捕获参与者的集中和注意音乐的波动。
(3)情绪反应的定义。
情绪反应可以在多个维度上定义,包括但不限于:情感价(例如欢乐,悲伤,愤怒),情绪强度(低,中或高强度)和情感波动(情感变化的振幅和速度)。情绪的预测不仅应依赖生理信号,而且还应考虑音乐和参与者的个人情感倾向的情感特征。
(4)注意状态的定义。
注意状态定义为参与者听音乐时的注意力程度,可以分为几种类型:高度集中,略微分散注意力和严重分心。This state should be determined by combining eye-tracking data, reaction times, and behavioral performance (such as signs of attention drifting).Changes in attention status may interact with changes in emotional responses, especially when music evokes emotional fluctuations, causing corresponding variations in the participants’ attention.
实验环境
This paper designs an unsupervised DL network model, which needs a large number of labeled samples for training.Consequently, it needs to use high-performance GPU for training to improve the training speed and testing speed.The built platform development environment36is shown in Table 2:
参数设置
This paper takes the collected dataset as the sample, the batch_size is 4, and the initial learning rate is 0.005, including 24 epochs cycles.Based on the initial learning rate, the learning rate is adjusted to 0.0005 in the 17th epoch and 0.00005 in the 22nd epoch, and the construction parameters37are shown in Table 3:
绩效评估
In music aesthetic education, music emotion is the core of aesthetic experience.Through emotion recognition technology, students can be provided with richer emotional experience, which can help them deeply understand the emotional expression in music and enhance their aesthetic sensibility.This technical means can assist teachers to implement personalized teaching according to students’ reaction to music emotion, optimize the effect of music aesthetic education, and enhance students’ emotional resonance and music understanding.Music emotion analysis based on DL can accurately identify the emotional features in music, such as joy, sadness and calmness, through AI technology, thus helping educators to better understand and convey the emotional connotation of music works.Therefore, this paper analyzes the music emotion based on DL in the AI environment to show the effectiveness of the music aesthetic education method.
The experiments are conducted under three conditions: single-input continuous emotional features, single-input discrete emotional features, and a 1:1 ratio of continuous to discrete emotional features.Under these conditions, this paper measures the MFCC and PLP features extracted from the continuous emotional space and the main melody features extracted from the discrete emotional space.The experimental results are shown in Figs. 4和5, 和6。

Model recognition accuracy comparison with all continuous emotional features as input.
As Table 4;Fig. 4show, the proposed model achieves the highest accuracy compared to other mainstream emotion recognition models when the number of MFCC and PLP features extracted from the continuous emotional space is equal to the number of main melody features extracted from the discrete emotional space (1:1).This demonstrates that multimodal feature input has a positive effect on music emotion recognition.

Model recognition accuracy comparison with all discrete emotional features as input.
桌子 5;Fig. 5show that the proposed model performs better in the continuous emotional space on the premise that only a single feature is input, which shows that the model is more suitable for content recognition in the continuous emotional space.

Model recognition accuracy comparison with input features of continuous and discrete emotional features in a 1:1 ratio.
桌子 6;Fig. 6show that when the same feature is input, the recognition accuracy is not as accurate as other mainstream models on the premise of only a single feature, which shows that this model is not the optimal solution when only a single feature is input.
In practice, interviews with teachers and students reveal that teachers can obtain real-time analysis reports on students’ emotional responses and learning progress through the model, thereby optimizing teaching methods and content.Students, on the other hand, can adjust their performance based on model feedback, enhancing their understanding and expression of musical emotions.The practical experience assessment of the model includes feedback from teachers on its teaching assistance capabilities and evaluations from students on their personalized learning experiences.The model continuously refines its feedback accuracy and practicality through data analysis.Additionally, the model is integrated with a music interaction application, embedding functions such as emotion analysis, audio feature extraction, and mood regulation into the app.This allows teachers and students to interact in real-time in a virtual learning environment.The feedback provided by the model dynamically adjusts according to student performance, thereby increasing students’ interest in music learning and their aesthetic abilities.
讨论
The research shows that the design of music interactive application with DL function can capture and analyze students’ playing actions and performances in real time, provide immediate feedback and guidance, and promote the development of their music practical skills and aesthetic perception.Furthermore, DL has greatly improved the accuracy of evaluation and feedback in music aesthetic education.It can deeply analyze students’ unstructured data (such as emotional reaction and attention state) in music activities through complex pattern recognition and signal processing technology, and form an objective and detailed evaluation report.For specific singing or performance exercises, AI can accurately judge the nuances of pitch, rhythm and musical expression, and give specific suggestions for improvement in time.
DL is also applied to the generation and mining of innovative music education resources.Zhuang research uses AI music generation model to create new music materials, which not only enriches the teaching content, but also stimulates students’ creative thinking.At the same time, through the intelligent screening and classification of massive music materials by DL technology, teachers can obtain and use the teaching materials that are most suitable for the curriculum objectives more conveniently.The construction of intelligent auxiliary teaching system and big data-driven teaching decision-making are also important ways for DL to optimize music aesthetic education38。Zhang researched and built an online education platform integrating DL module, which realized the automatic tutoring of students’ music reading ability, auditory training and music theory knowledge, and significantly improved the teaching efficiency.Meanwhile, by analyzing the big data of music aesthetic education through DL, educators can obtain a macro view of teaching effectiveness, clarify the progress of student groups, and scientifically verify and optimize teaching strategies and methods39。In this paper, the combination of the two is applied to music aesthetic teaching, which not only greatly enriches the teaching methods and contents, but also effectively promotes the development of individualization, intelligence and effectiveness of music aesthetic education, making it closer to students’ needs and more conducive to cultivating a new generation with high-level music aesthetic literacy.
结论
Research contribution
The main contribution of this paper is to extract multimodal music features from music data, build its neural network model, and carry out emotion recognition and related application research.On this basis, this paper aims to extract various types of musical emotions from multiple perspectives.This paper seeks to integrate them with existing musical features and model musical emotions through preprocessing, feature extraction, model optimization, and other steps.The ultimate goal is to enhance the accuracy of musical emotion recognition.This paper also tests the speech recognition system based on AI and DL, which integrates the functions of emotion recognition and music production into the teaching of music aesthetics.Experiments show that this method can better realize the recognition of musical emotions and has broad application prospects in future music teaching.In real-world educational settings, the method proposed in this paper can ensure scalability and accessibility for schools or educators with limited technical resources through various strategies.First, the method can rely on cloud computing and edge computing technologies to deploy deep learning models in the cloud, allowing educational institutions to use intelligent music aesthetic teaching tools without the need for high-performance local computing devices.Second, by using lightweight deep learning models (such as knowledge distillation and pruning techniques) to optimize computational efficiency, core functions can be run on low-power devices like regular PCs, tablets, and even smartphones.Third, standardized music datasets and pre-trained models can be provided through open-source platforms and shared databases, reducing the technical barriers for schools to build their own data and train AI models.Fourth, the method involves combining modular teaching tools with tiered AI functions.This allows for the provision of different levels of AI-assisted functions based on the infrastructure conditions of individual schools.The range of functions includes simple music recommendations as well as more advanced capabilities such as emotion recognition and personalized teaching adjustments.This ensures that educators of all types can flexibly apply this method.
In addition, the implementation strategies for personalized teaching in a deep learning-based music aesthetic education model in an AI environment are as follows: First, the system can analyze students’ emotional recognition results based on the deep learning model.For example, when it detects that a student shows positive emotions towards a certain music style, it can enhance the teaching content related to that style.Conversely, for music types that students find difficult to understand or have less interest in, the teaching method can be adjusted, such as by increasing interactive experiences or using different explanation methods.Second, intelligent data feedback can be used for personalized teaching path planning.For example, by predicting students’ suitable learning pace based on their learning performance, the system can adjust music work recommendations, practice difficulty, or evaluation criteria to ensure that teaching meets students’ ability levels and promotes the improvement of their aesthetic literacy.Third, the system can also use group data analysis to identify learning patterns of different types of students and provide teachers with suggestions for teaching optimization, achieving precise teaching that combines intelligence and human effort.Through the implementation of these strategies, students can obtain music aesthetic education that better meets their personal needs, thereby increasing their interest in learning, enhancing their music perception abilities, and promoting the cultivation of personalized aesthetic literacy.
Future works and research limitations
The emotion recognition method of DL music aesthetic teaching under the background of AI constructed in this paper has achieved good results, but there are still some shortcomings.The constructed model is complex in structure, too dependent on the original data scale and the accuracy of music emotion labeling, and has some problems such as weak adaptive ability.Therefore, how to realize the lightweight promotion of the model and make it have better adaptive ability in a low sample environment should be studied.The proportion used in this paper needs to be further improved and optimized.
数据可用性
The datasets used and/or analyzed during the current study are available from the corresponding author Yixuan Peng on reasonable request via e-mail pengyixuan0426@163.com.
参考
Li, F. Chord-based music generation using long short-term memory neural networks in the context of artificial intelligence[J].J. Supercomputing。80(5), 6068–6092 (2024).数学
一个 Google Scholar一个 Li, P. & Wang, B. Artificial intelligence in music education.int。
J. Human–Computer Interact.40 (16), 4183–4192 (2023).数学
一个 Google Scholar一个 Zhang, L. Z. L. Fusion artificial intelligence technology in music education Teaching[J].J. Electr.
系统。19 (4), 178–195 (2023).广告
一个 CAS一个 数学一个 Google Scholar一个 Paroiu, R. & Trausan-Matu, S. Measurement of music aesthetics using deep neural networks and Dissonances[J].信息
14(7), 358 (2023). 数学一个
Google Scholar一个 Iffath, F. & Gavrilova, M. RAIF: A deep learning-based architecture for multi-modal aesthetic biometric system.计算。
Animat.虚拟世界 34(3–4), e2163 (2023).
数学一个 Google Scholar一个
Ji, S., Yang, X. & Luo, J. A survey on deep learning for symbolic music generation: representations, algorithms, evaluations, and challenges[J].ACM计算。调查。56(1), 1–39 (2023).数学
一个 Google Scholar一个 Oruganti, R. K. et al.Artificial intelligence and machine learning tools for high-performance microalgal wastewater treatment and algal biorefinery: A critical review[J].
科学。总环境。 876, 162797 (2023).
PubMed一个 CAS一个 数学一个 Google Scholar一个
Yin, Z. et al.Deep learning’s shallow gains: A comparative evaluation of algorithms for automatic music generation[J].马赫。学习。 112(5), 1785–1822 (2023).
MathScinet一个 数学一个 Google Scholar一个
Gomes, B. & Ashley, E. A. Artificial intelligence in molecular medicine[J].N. Engl。J. Med。 388(26), 2456–2465 (2023).
PubMed一个 CAS一个 数学一个 Google Scholar一个
Soori, M., Arezoo, B. & Dastres, R. Machine learning and artificial intelligence in CNC machine tools, a review[J].Sustainable Manuf.Service Econ. 2, 100009 (2023).
Bharadiya, J. P. A comparative study of business intelligence and artificial intelligence with big data analytics[J].是。J. Artif。Intell。 7(1), 24 (2023).
数学一个 Google Scholar一个
Moysis, L. et al.Music deep learning: deep learning methods for music signal processing-a review of the state-of-the-art.IEEE访问 11, 17031–17052 (2023).
数学一个 Google Scholar一个
Shukla, S. Creative computing and Harnessing the power of generative artificial Intelligence[J].J. Environ。科学。技术。 2(1), 556–579 (2023).
数学一个 Google Scholar一个
Oksanen, A. et al.Artificial intelligence in fine arts: A systematic review of empirical research.计算。哼。行为。艺术品。哼。 20, 100004 (2023).
数学一个 Google Scholar一个
Borkowski, A., Vocal Aesthetics, A. I. & ImaginariesReconfiguring Smart Interfaces[J] Afterimage,,,,50(2): 129–149.(2023)。
Cui, K. Artificial intelligence and creativity: piano teaching with augmented reality applications[J].相互影响。学习。环境。 31(10), 7017–7028 (2023).
数学一个 Google Scholar一个
Huang, X. et al.Trends, Research Issues and Applications of Artificial Intelligence in Language education[J]26112–131 (Educational Technology & Society, 2023).1。
Rathore, B. Digital transformation 4.0: integration of artificial intelligence & metaverse in marketing[J].Eduzone: Int.Peer Reviewed/Refereed Multidisciplinary J. 12(1), 42–48 (2023).
数学一个 Google Scholar一个
Liu, B. Arguments for the rise of artificial intelligence art: does AI Art have creativity, motivation, Self-awareness and Emotion?[J].Arte Individuo Y Sociedad。35(3), 811 (2023).
CAS一个 数学一个 Google Scholar一个
Kim, T. W. Application of artificial intelligence chatbot, including ChatGPT in education, scholarly work, programming, and content generation and its prospects: a narrative review[J].J. Educational Evaluation Health Professions。20, 38 (2023).数学
一个 Google Scholar一个 Wang,H。等。Scientific discovery in the age of artificial intelligence[J].
自然620 (7972), 47–60 (2023).广告
一个 PubMed一个 CAS一个 数学一个 Google Scholar一个 Liu, W. Literature survey of multi-track music generation model based on generative confrontation network in intelligent composition[J].J. Supercomputing
。79(6), 6560–6582 (2023).数学一个
Google Scholar一个 Mosqueira-Rey, E. et al.Human-in-the-loop machine learning: a state of the art[J].
艺术品。Intell。修订版 56(4), 3005–3054 (2023).
数学一个 Google Scholar一个
Alkayyali, Z. K., Idris, S. A. B. & Abu-Naser, S. S. A systematic literature review of deep and machine learning algorithms in cardiovascular diseases Diagnosis[J].J. Theoretical Appl.通知。技术。 101(4), 1353–1365 (2023).
Tufail, S. et al.Advancements and challenges in machine learning: A comprehensive review of models, libraries, applications, and algorithms[J].电子产品 12(8), 1789 (2023).
数学一个 Google Scholar一个
Ahmadi, S. Optimizing data warehousing performance through machine learning algorithms in the Cloud[J].int。J. Sci。res。(IJSR)。12(12), 1859–1867 (2023).数学
一个 Google Scholar一个 Sonkavde, G. et al.Forecasting stock market prices using machine learning and deep learning models: A systematic review, performance analysis and discussion of implications[J].
int。J. Financial Stud. 11(3), 94 (2023).
Paturi, U. M. R., Palakurthy, S. T. & Reddy, N. S. The role of machine learning in tribology: a systematic review[J].拱。计算。Methods Eng. 30(2), 1345–1397 (2023).
数学一个 Google Scholar一个
张,J。等。Public cloud networks oriented deep neural networks for effective intrusion detection in online music education[J].计算。电子工程。 115, 109095 (2024).
数学一个 Google Scholar一个
Zhang, W., Shankar, A. & Antonidoss, A. Modern Art education and teaching based on Artificial intelligence[J].J. InterConnect。网络。22(Supp01), 2141005 (2022).Google Scholar
一个 Dai, D. D. Artificial intelligence technology assisted music teaching design[J].
Scientific programming, 2021: 1–10.(2021)。
Ferreira, P., Limongi, R. & Fávero, L. P. Generating music with data: application of deep learning models for symbolic music Composition[J].应用。科学。 13(7), 4543 (2023).
CAS一个 数学一个 Google Scholar一个
Saberi-Movahed, F. et al.Deep metric learning with soft orthogonal Proxies[J].arXiv preprintarXiv:2306.13055,2023年。
Dan, X. Social robot assisted music course based on speech sensing and deep learning algorithms[J].Entertainment Comput. 52, 100814 (2025).
Fang, J. Artificial intelligence robots based on machine learning and visual algorithms for interactive experience assistance in music classrooms.Entertainment Comput.,,,,52, 100779 (2025).
Li,X。等。Learning a convolutional neural network for propagation-based stereo image segmentation[J].视觉计算。 36, 39–52 (2020).
CAS一个 数学一个 Google Scholar一个
Zhang,X。等。Multi-level fusion and attention-guided CNN for image dehazing[J].IEEE Trans。电路系统。视频技术。 31(11), 4162–4173 (2020).
数学一个 Google Scholar一个
Zhuang, X. et al.Artificial multi-verse optimisation for predicting the effect of ideological and political theory course.Heliyon 10(9), 1–14 (2024).
CAS一个 数学一个 Google Scholar一个
张,L。等。Bioinspired scene classification by deep active learning with remote sensing applications[J].IEEE Trans。控制论。52(7), 5682–5694 (2021).数学
The studies involving human participants were reviewed and approved by College of Music, The Yeungnam University of Korea Ethics Committee (Approval Number: 2021.02039345).
参与者提供了书面知情同意,以参加这项研究。
所有方法均根据相关的指南和法规进行。
附加信息
出版商的注释
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问
本文在Creative Commons Attribution-Noncormercial-Noderivatives 4.0国际许可下获得许可,该许可允许任何非商业用途,共享,分发和复制以任何媒介或格式的形式,只要您提供适当的原始作者和来源的信用,请符合原始作者和来源,并提供了与Creative Commons的链接,并指示您是否修改了许可的材料。
您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Peng, Y. The analysis of optimization in music aesthetic education under artificial intelligence.
Sci代表15 , 11545 (2025).https://doi.org/10.1038/s41598-025-96436-2
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41598-025-96436-2