
使用机器学习改进了印度洋的长期高分辨率表面PCO2数据产品
作者:Chakraborty, Kunal
背景和摘要
自从工业革命以来2)1。大约50%的CO2人类活动释放被土地和水吸收2。根据2023年全球碳预算3,海洋吸收了总CO的26%2在2013 - 2022年期间。印度洋海岸(IO)拥有近30%的世界人口
4,,,,5。结果,这些区域受到较高的人为压力。北印度洋河流的高淡水涌入,由于季风风的季节性逆转而导致季节性逆流,高气溶胶沉积严重影响了北印度地区的碳循环6,,,,7,,,,8,,,,9,,,,10,,,,11,,,,12,,,,13。此外,观察到诸如Elniâ±o-o-southern振荡(ENSO)和印度洋偶极子(IOD)之类的气候事件会影响CO的部分压2((p公司2)和IO区域的pH变异性14,,,,15,,,,16,,,,17。
作为区域碳循环评估和过程-2(RECCAP2)项目的一部分,多种方法,例如插值观测气候,后播模型,基于观察的表面p公司2(经验模型)和大气反转模型用于估算净空气CO21985年至2018年之间的通量。根据RECCAP2海洋建模方案,配置了一个高分辨率(1/12°)区域后标模型,称为Incois-Bio-Roms(IBR_ORIGINAL)。IBR_original模型模拟了1980 - 2019年的输出是RECCAP2评估过程的一部分5并用于研究IO区域上的海洋酸化16。区域海洋模型为海洋提供了宝贵的见解
p公司2可变性和趋势,但由于它们在表示模型参数化中的小规模过程和相关的不确定性方面的局限性,因此通常会出现明显的偏见。尽管观察对于了解表面至关重要p公司2可变性,空间和时间变化的观察值的可用性有限,尤其是在IO中。这些数据稀缺为验证和改善基于观察的模型预测带来了挑战。模型输出和观察之间的错误可能会阻碍我们准确估计表面的能力p公司2和相关的航空公司2通量,强调了对高级校正技术的需求,这些技术可以弥合建模和观察到的表面之间的间隙p公司2值。机器学习(ML)算法提供了一种有希望的方法来提高模型模拟的表面质量p
公司2通过纠正其偏见18,,,,19关于观察。ML算法也广泛应用于预测表面p公司2使用观察13,,,,20,,,,21,,,,22,,,,23,,,,24。ML算法可以捕获目标变量和预测变量之间的复杂的非线性关系13,,,,2024。将基于ML的校正与现有模型输出集成使得可以产生更可靠和高分辨率的表面p公司2估计更好地反映观察到的条件19。这项研究旨在产生基于ML的改进表面
p公司2数据产品通过结合可用观测值和1980年至2019年IO区域的高分辨率IBR_original模型模拟输出。该数据产品对于估算更准确的Air-SEA CO将是有用的2通量并识别IO中充当来源的区域(释放CO2进入大气)和下沉(吸收CO2来自CO的大气)2。建模的精度提高了p公司2,我们可以更好地理解IO酸化,以应对不断变化的气候。方法用于改善模型模拟的表面p公司
2
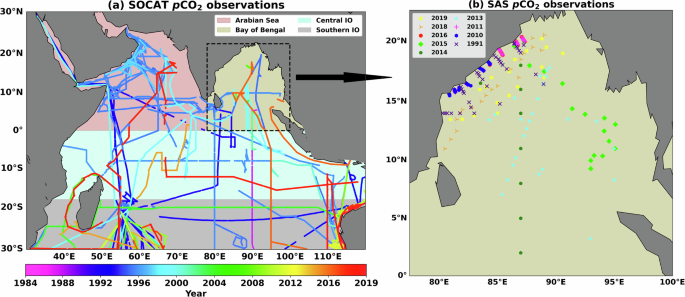
使用IO跨IO的异质原位观测,我们将IO区域分为四个子区域(图。 1)如(a)阿拉伯海(0°N 30°N; 30°e 78°e),(b)孟加拉湾(0â°N 30°N; 78°e 110°e),(c)中央Io(0到18°Nâ°Nâ°s; 30°s; 30°e; e Southern e Southtlan; e Essoutn; d;(18°S 30°S; 30°e -120°E)。该划分基于IO区域区域物理过程的复杂性5。图1代表研究区(印度洋(IO))和子区域(阿拉伯海,孟加拉湾,中部IO和南部IO)。

一个)显示年度变化p公司2从SOCAT获得的观察结果(Surface Ocean Co2Atlas)数据,((b)是SAS(SRIDEVI和SARMA)数据观察结果年度变化的表示。我们假设表面p公司
2变形(观察到p公司2((p公司2obs) - 建模p公司2((p公司2模型)是表面温度(SST),表面盐度(SSS),混合层深度(MLD),表面溶解的无机碳(DIC),表面硝酸盐的函数(无3)和表面叶绿素-A(CHL)。上述海洋变量的变化显着控制了表面的变异性p公司2。变量SST,SSS,MLD,DIC,no3和CHL被认为是海洋热力学,溶解度,分层和生物泵等主要海洋过程的代理。在这项研究中,我们预测时空变化的表面p公司2使用ML模型的异常。这些预测p公司2然后将异常添加到p公司2模型获得校正的表面p公司2。图 2是一个示意图,显示了本研究采用的完整方法。本研究所需的数据的详细信息,ML模型的描述以及映射方法的描述如下。

本研究中采用的完整方法的示意图p公司2模型。数据获取
我们获得了
p公司2obs来自两个不同的来源。第一个来源是地表海co2Atlas(Socat)(Socat)(https://socat.info/index.php/version-2022/)25可用于1984年至2019年的IO。时空变化的表面的可用性p公司2SOCAT的观察如图所示。 1一个。除了SOCAT数据库,表面p公司2也从表示为SAS(Sridevi和Sarma)数据的不同印度科学巡游中收集观察结果11。SAS数据可从1991年到2019年获得。SAS数据的更多详细信息可在我们最近的研究中获得13。图 1B显示表面的时空可用性p公司2来自SAS数据集。数据收集和质量控制方法在与这些数据集相对应的文献中明确可用11,,,,25。
可用表面的每月数据频率p公司2观察(p公司2obs(SOCAT和SAS)来自各种来源。 3对于印度洋(IO)的四个子区域,即阿拉伯海(AS),孟加拉湾(鲍勃),中部IO和南部IO。在AS区域,与其他月相比,从5月到9月,观测值的记录明显更高。同样,从2月至5月的鲍勃(Bob)提供大量观察结果。在西南季风季节(6月9月)的AS和中部IO峰观察,而季风前季节(3月)看到了鲍勃和南部IO地区的最大观察次数(图。 3)。该分析强调了由于某些时期无法获得数据而导致的预测不确定性的潜在来源。随着观察次数的增加,预测的准确性有望提高。尽管存在这些时间差距,但这些数据在整个IO区域都提供了出色的空间覆盖范围(图。 1)。

每月观察p公司2(SOCAT+SAS)分为四个子区域(一个)((d印度洋(IO)的)。蓝色酒吧表示东北季风季节(12月至5月),而绿色,黄色和红色的酒吧则代表季风前(三月 - 五月),夏季季风(6月至9月)和季风后(10月至11月)的季节。
海洋状态变量的输入数据(SST,SSS,MLD,DIC,否3,和chl)是从ibr_original模型中提取的p公司2obs可从不同的来源(SOCAT和SAS)获得。我们还提取了表面p公司2来自ibr_original,即p公司2模型在这些相同的位置。IBR_original模型输出为1/12°空间分辨率,从1980年到2019年以每月量表提供。本研究中使用的IBR_original模型输出已经在我们以前的研究中得到验证和使用5,,,,16。因此,我们鼓励读者参考我们以前的研究5,,,,16有关IBR_original模型配置的更多详细信息。
在使用数据进行培训和预测之前,我们检查了IO的每个子区域的数据分布。MLD,CHL,没有3通过进行日志转换,将数据转换为正态分布。由于ML模型对离群值敏感(> 3 -),从IO的每个子区域的可用数据中删除异常值。
孟加拉湾海洋酸化(Boboa)系泊是表面的唯一点源观察p公司22014 - 2018年在IO地区上市。因此,它被用作评估表面改进的独立数据集p公司2在Boboa系泊地点。Boboa系泊设备位于15°N,90°E。该位置的观察数据被转换为每月频率,然后与模拟p公司2。表面p公司2来自Boboa的数据已下载https://www.pmel.noaa.gov/co2/story/boboa。我们承认,在海洋碳酸盐可变研究中,无间隙时空观察的稀缺是一个普遍的挑战。
独立验证的一种方法是从数据集中删除特定的巡航线。但是,这将减少开发ML模型的可用观察次数,并可能影响其整体性能。更重要的是,巡航线是特定于区域的,通常缺乏广泛的时间覆盖范围,因此仅根据单个巡航系列验证而无法理解整个IO的改进。鉴于该纠正了p公司2数据集具有1/12°的高空间分辨率,并且从1980年到2019年跨度,必须评估其在整个IO地区的改进至关重要。栅格SOCAT是根据SOCAT巡航观察准备的每月1°Binned数据产品
25。表面p公司2从IBR_original中的空间分辨率为0.083°。这p公司2从该数据集提取了与每个巡航位置相对应的值,差异用作我们的目标变量(p公司2异常)。使用最近的邻居插值方法进行此提取。然而,SOCAT1â°数据产品箱值不插值而无需插值,从而与训练值的值略有差异。因此,我们使用SOCAT1â°数据集评估最终产品是否表现出表面的改善或下降p公司2值。这p公司2模型并纠正p公司2数据集具有每月频率,使月度网格的SOCAT数据对于评估校正后的改进特别有用p公司2与观测值相比,数据集。在IO地区,可以从1984年到2019年获得网格的SOCAT数据。该数据可以从中下载https://socat.info/index.php/data-access/。基于ML的产品很重要,因为它们提供了无空间间隙的估计值。
在这项研究中,我们使用两种高分辨率(0.25°– 0.25°)基于ML的数据产品(CMEMS-LSCE-FFNN(哥白尼海洋环境监测服务Service service laboratoire laboratoire des Sciences des Sciences de Climat et de climat et de liniment vel delânovormnemp23和Oceansoda(Oceansoda-Ethzv2)24)。在这项研究中,CMEMS-LSCE-FFNN(OceanSoda)数据从1985年(1982年)到2019年。https://data.ipsl.fr/catalog/srv/srv/catalog.search#/metadata/a2f0891b-763a-49e9-af1b-78ed78b16982。在下载海洋索达数据时https://zenodo.org/records/11206366。尽管这些数据产品是使用SOCAT观测来开发的,但它们采用不同的方法来构建表面p公司2,导致它们之间的内在差异。此外,具有不同空间分辨率的数据产品(例如CMEMS-LSCE-FFNN和OceanSoda)的可用性,可以对我们的产品进行更严格的比较。这种全面的评估增强了对最终产品可靠性的信心。桌子 1总结本研究中使用的所有数据。
分裂和缩放数据
在这项研究中,SST,SSS,MLD,无3浓度和来自ibr_original的Chl用作预测因子。偏差p公司2obs值(来自SOCAT和SAS数据集)和p公司2模型值[PCO2obsPCO2模型]作为目标。使用Scikit-Learn模块,将四个子区域中每个区域的数据随机分为训练(80%)和测试(20%)数据集26。这些测试数据集用于每个子区域,并专门用于验证模型的性能,以确保无偏评估。为了训练模型并防止过度拟合问题,采用了10倍的交叉验证技术。在这种方法中,训练数据集分为10个子集(折叠)。该模型在其中9个折叠上进行了训练,并在其余的折叠上进行了验证,并重复所有折叠的过程。
机器学习算法
该研究利用高级ML算法(极端梯度提升(XGB))生成了改进的版本p公司2模型1980 - 2019年期间的IO地区。XGBoost算法的详细信息如下。
-
极端梯度提升(XGB)XGB算法27是一种属于基于决策树的增强算法系列的监督学习算法。XGB算法是通过提高梯度增强算法的计算速度和性能而创建的。先前的研究强调了算法的卓越计算速度,准确性和整体性能与其他机器学习算法相比13,,,,19,,,,22,,,,28。该高级ML算法在先前的研究中具有可靠的能力,促使我们采用此XGB算法来纠正该算法p公司2模型对于IO的四个子区域中的每个区域。该算法从初始猜测开始,然后再依次添加树。每棵树试图通过最大程度地减少损失函数来改善合奏的性能。在这项研究中,使用XGB算法开发的模型称为XGB模型。
调谐XGB模型的性能
XGB模型具有可调的超参数。遵循以前的文献13,,,,22,我们决定使用Optuna优化29调整超参数。每个子区域的超参数范围以及最终优化值 2。为了确定调整后的XGB模型是否既不适合也不适合,必须使用20%的测试数据集在80:20数据拆分的情况下对IO的每个子区域进行80:20数据拆分,以评估XGB模型的性能。表格总结了为这些子区域开发的四个单独的XGB模型的性能 3。跨各个子区域的培训和测试数据集的类似RMSE值表明在所有子区域中都一致且可靠的XGB模型性能。
最佳估计和不确定性
量化与预测相关的不确定性p公司2Deviants,我们采用了一种类似于统计中的引导技术的方法21,,,,23。这种方法需要生成大量模型,其中平均预测提供了目标的最佳估计(p公司2deviants)和标准偏差(SD,1- -)量化预测不确定性。为了实现这一目标,我们通过随机从高参数调整期间使用的训练集中提取80%的数据来生成150个训练数据集。
此过程导致150个独立训练的XGB模型。随后,我们创建不同尺寸的合奏,从最少2到最多150 xgb模型。然后为每个子区域确定最佳的合奏大小,定义为RMSE(针对测试数据集评估)稳定的大小(对测试数据集进行评估)。如图所示 4,最佳合奏尺寸为AS和中央IO的140,而Bob和Southern IO为130。

在四个子区域中评估RMSE作为集成大小的函数(((((一个)阿拉伯海((b)孟加拉湾((c)中央IO和((d)南部IO)确定最佳的合奏尺寸。映射方法
生成时空变化p
公司2每个子区域,时空输入的异常(SST,SSS,MLD,DIC,否)3来自IBR_original(覆盖1980年的2019年)的浓度和Chl)被送入140 XGB模型中的每一个(对于AS和Central IO)或130 XGB模型(对于Bob和Southern IO)。如上一节所述,这些算法的平均输出提供了时空的最佳估计值p公司2异常,而标准偏差则量化了1980年期间的相关不确定性。图 5显示域平均值p公司2每个子区域的异常及其相应的不确定性。这些时空p公司2然后将变形者添加回p公司2模型(在每个网格单元格)得出校正p公司2。图5

p公司2四个子区域的偏差。实线显示了IO域的每个子区域的最佳估计,误差线表示相关的不确定性。
在这里,我们研究了将空间偏差纳入纳入的两种不同的方法p公司2校正过程。在第一种方法中,添加了年际变形者p公司2模型,导致经过固定的校正p公司2数据集(PCIBR_INT)。在第二种方法中,只添加了偏差的气候平均值p公司2模型,产生经过气候纠正的p公司2数据集(PCIBR_CLIM)。由于气候偏差的可变性大于年际变化的变化,因此我们旨在确定哪种方法会产生更好的结果。使用两种方法生成的数据产品都针对基于Boboa系泊浮标的观测值进行了广泛的验证,1°1°1°SOCAT数据集以及两个其他网格数据产品(CMEMS-LSCE-FFFNN和OCEANSOD),以确定最有效的表面表面的方法p公司2数据。数据记录
长期高分辨率校正表面
p公司2可以从https://zenodo.org/records/1461473930。该产品的每月时间分辨率和1/12°的空间分辨率。数据可从1980 - 2019年获得。从同一链接中,用户可以访问用于纠正的输入数据p公司2模型和p公司2Deviants,以及从XGB模型得出的相关不确定性。所有数据都在一个NetCDF文件中提供。
技术验证
比较p公司2模型和校正的表面p公司2数据产品(PCIBR_INT和PCIBR_CLIM)已针对表面的时间序列观察进行p公司2从Boboa停泊的浮标位置(图) 6)。本研究采用三个统计指标(均方根误差(RMSE),平均绝对误差(MAE)和Taylor技能得分(TSS))来评估校正后的性能p公司2针对的数据p公司2模型使用基于Boboa系泊的观测值。如表中总结 4,PCIBR_CLIM(PCIBR_INT)和BOBOA之间的RMSEp公司2观测值降低了约37.84%±2.35%(40.63%±0.38%),与RMSE相比p公司2模型和Boboa。同样,PCIBR_INT的MAE降低了约50.43%的±1.85%,PCIBR_CLIM的MAE下降了44.46%。TSS衡量模型输出和参考数据之间的一致性,尤其是在可变性方面,其中一个接近1的值表示完美匹配。这p公司2模型证明良好的TSS为0.87。但是,本研究中应用的校正进一步提高了PCIBR_INT的TSS约1.11%±0.77%,PCIBR_CLIM的TSS和2.23%的TSS和2.23%的TSS提高了TSS。基于与Boboa观察的比较,我们得出结论,校正方法(PCIBR_CLIM和PCIBR_INT)为该方法提供了重大改进p公司2模型。该比较进一步表明,这两种方法的性能彼此非常接近。

PCIBR_INT,PCIBR_CLIM和p公司2模型在位于15°N和90°E的Boboa浮标的观察中,灰色阴影区域代表了Boboa浮标的观察数据中的标准偏差。表4 PCIBR_INT,PCIBR_CLIM和p
公司2(图 7,,,,8, 和9)。校正p公司2数据集(PCIBR_INT和PCIBR_CLIM)的分辨率为1/12°,比所有参考数据集更细。因此,我们重新网格纠正p公司2数据以使用最近的相互作用方法匹配参考数据集的网格。图7

p公司2模型在将它们每个人与网格的Socat产品进行比较时。RMSE和MAE中的负值(蓝色)表示改善p公司2模型。而TSS中的正值(红色)代表了对p公司2模型。图
7显示了PCIBR_INT之间RMSE的差异(图 7a)或pcibr_clim(图 7b) 和p公司2模型与网格的SOCAT数据相比。两个面板(图 7a和b)在IO域中证明RMSE的大幅度减少。具体而言,PCIBR_INT的RMSE降低了约40.43%的±4.39%,PCIBR_CLIM的RMSE降低了38.87%。图的第二和第三行 7显示校正后的MAE和TSS的差异p公司2输出(来自两种方法)和p公司2模型与Socat相比。与PCIBR_INT相比,PCIBR_CLIM的MAE降低更为明显(40%±5%)(35%±4%)。图的第三行 7,显示TSS差异,包含的网格单元少于第一行和第二行。这是因为TSS考虑了数据可用性,而网格的SOCAT数据集bins巡航线数据则为1°网格,从而导致较少的具有重复数据值的单元格。第三行中显示的网格单元每个单元格至少三个观察数据点。对于PCIBR_INT,观察到TSS的增加约为7.13%,而PCIBR_CLIM的TSS增加了约5.15%的±0.76%。然而,有限数量的时空变化表面的可用性p公司2观察结果使得最终确定哪种方法(PCIBR_INT或PCIBR_CLIM)更好地改善p公司2模型。但是,分析清楚地表明,这两种方法都对SSTHE都有显着改善p公司2模型。CMEMS-LSCE-FFNN和OCEANSODA是基于观察的重建数据产品,可提供高分辨率,无间隙,时空变化的网格表面
p公司2。这两个数据集均使用不同的ML方法来预测表面的长期变化p公司2。国际科学界广泛认可这些数据产品,因为它们在推进海洋碳循环研究方面做出了重大贡献,并提高了我们对环境变化如何影响航空公司的理解。2通量动态。因此,我们利用这些数据集执行可靠的时空验证,如图1和图2所示。((8和9)。

该图代表RMSE(RMSE,第一行),MAE(MAE,第二行)和TSS(TSS,第三行)的更改PCIBR_INT(第一列)或PCIBR_CLIM(第二列)和p公司2模型在将它们的每个产品与CMEMS-LSCE-FFNN产品进行比较时。RMSE和MAE中的负值(蓝色)表示改善p公司2模型。而TSS中的正值(红色)代表了对p公司2模型。图9

p公司2模型在将它们的每个产品与Oceansoda产品进行比较时。RMSE和MAE中的负值(蓝色)表示改善p公司2模型。而TSS中的正值(红色)代表了对p公司2模型。数字 (
8a和b)与PCIBR_CLIM和PCIBR_INT相比,PCIBR_CLIM和PCIBR_INT的RMSE显着降低p公司2模型。与CMEMS-LSCE-FFNN进行比较时,PCIBR_INT的域平均RMSE降低了约29.48%的±4.25%,相对于PCIBR_CLIM,相对于PCIBR_CLIM的降低约为37.06%。p公司2模型。数字 (8C和d)突出显示校正后的MAE的差异p公司2数据集和p公司2模型,与CMEMS-LSCE-FFNN相比。对于PCIBR_INT,尤其是在AS中的小区域显示MAE的增加。这表明添加的额外添加p公司2偏差p公司2模型可以导致某些领域的质量下降。这种下降可能是由于时间频率有限p公司2巡航观察。相反,对于PCIBR_CLIM,质量下降的区域几乎可以忽略不计(图 8d)。在整个IO域中,PCIBR_INT的MAE降低了约32.19%的±4.28%,PCIBR_CLIM的MAE降低了约38.91%的±4.93%。同样,图(图)(8e和f)显示TSS的变化。对于PCIBR_INT(图 8e),某些区域表现出TSS的减少。但是,对于PCIBR_CLIM(图 8f),TSS在整个域中始终增加。PCIBR_INT的TSS的域平均改善约为1.35%,在PCIBR_CLIM的大约5.01%±0.21%的情况下,在大约5.01%±0.21%。总而言之,结果表明PCIBR_CLIM明显胜过PCIBR_INT。它的RMSE减少(37.06%±4.46%vs. 29.48%)和MAE(38.91%±4.93%±4.93%vs. 32.19%vs. 32.19%),TSS(5.38%),TSS(5.0%)(5.0%)(5.0%)(5.0%)(5.0%)。±0.09%),较少的区域显示出质量降解。总体而言,与CMEMS-LSCE-FFNN相比,PCIBR_CLIM表现出卓越的性能和一致性。
数字9a和b)说明校正表面之间的RMSE差异p公司2数据产品(PCIBR_INT和PCIBR_CLIM)和p公司2模型与OceanSoda数据相比。对于两种方法,在整个域上都观察到RMSE的减少。平均而言,PCIBR_INT的整个域RMSE降低了约30.82%的±4.43%,PCIBR_CLIM的RMSE降低了约37.73%的±4.75%。MAE的差异也在图2中。9C和d)。与与cmems-lsce-ffnn的比较相似,pcibr_int案例(图 9C)显示MAE的局部增加,特别是在AS中。相比之下,MAE在PCIBR_CLIM案例的IO域上始终减少(图 9d)。在域积的基础上,PCIBR_INT的MAE降低了约34.71%的±4.91%,PCIBR_CLIM的MAE降低了约40.94%。数字9e和f)显示TSS的改进。对于PCIBR_CLIM案例,TSS在IO域上显示出一致的改进。但是,对于PCIBR_INT,某些区域表现出恶化的斑块。平均而言,PCIBR_CLIM的域TSS平均提高了约3.81%的±0.15%,PCIBR_INT的TSS提高了约1.00%的±0.08%。总之,在比较两个校正表面时p公司2数据产品(PCIBR_INT和PCIBR_CLIM)参考CMEMS-LSCE-FFNN和OCEANSODA等产品,PCIBR_CLIM表现出卓越的性能。它可以增加RMSE和MAE的更大减少,并在TSS方面进行更一致的改进,从而使其成为更有效的校正方法。
因此,基于此技术分析,很明显,本研究中采用的两种方法(PCIBR_CLIM和PCIBR_INT)都可以改善p公司2模型。此外,与其他基于ML的产品相比,PCIBR_CLIM表现出优于PCIBR_INT的性能。但是,我们已经制造了这两种产品,即一种产品,一种源自PCIBR_INT,另一种是从PCIBR_CLIM中衍生的,可用于用户。用户可以选择最适合其研究目的的方法。校正的表面p公司2可以用来得出更准确的空气CO2flux estimations for the period 1980–2019 in the IO region.This long-term, high-resolution air-sea CO2flux data can also help identify regions with significant source and sink characteristics within the IO, thereby contributing to a better understanding of the IO’s role in the global carbon budget.代码可用性The code used to create the final product is available at
https://github.com/prasannakanti/XGBoost_pCO2_IO
Friedlingstein, P.
等。Global carbon budget 2022.Earth System Science Data Discussions2022, 1–159 (2022). Google Scholar一个
。Global carbon and other biogeochemical cycles and feedbacks (2021).Friedlingstein, P.
等。Global carbon budget 2023.地球系统科学数据15 , 5301–5369,https://doi.org/10.5194/essd-15-5301-2023(2023)。数学
一个 Google Scholar一个 Wafar, M., Venkataraman, K., Ingole, B., Ajmal Khan, S. & LokaBharathi, P. State of knowledge of coastal and marine biodiversity of Indian ocean countries.PLoS one
6, e14613 (2011). 广告一个
CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个 Sarma, V. V. S. S.等
。Air-sea fluxes of CO2in the Indian Ocean between 1985 and 2018: A synthesis based on observation-based surface CO2, hindcast, and atmospheric inversion models.全球生物地球化学周期37, e2023GB007694 (2023). 广告一个
CAS一个 数学一个 Google Scholar一个 Sarma, V. V. S. S.等
。East India coastal current controls the dissolved inorganic carbon in the coastal Bay of Bengal.海洋化学205 , 37–47 (2018).广告
一个 CAS一个 数学一个 Google Scholar一个 Chakraborty, K., Valsala, V., Gupta, G. V. M. & Sarma, V. V. S. S. Dominant biological control over upwelling onp
公司2in sea east of Sri Lanka.Journal of Geophysical Research: Biogeosciences123, 3250–3261 (2018). 广告一个
CAS一个 数学一个 Google Scholar一个 Sarma, V. V. S. S., Krishna, M. S. & Srinivas, T. N. R. Sources of organic matter and tracing of nutrient pollution in the coastal Bay of Bengal.海洋污染公告
159, 111477 (2020). CAS一个
PubMed一个 数学一个 Google Scholar一个 Chakraborty, K., Valsala, V., Bhattacharya, T. & Ghosh, J. Seasonal cycle of surface oceanp
公司2and pH in the northern Indian ocean and their controlling factors.Progress in Oceanography198, 102683 (2021). 数学一个
Google Scholar一个 Joshi, A. P., Chowdhury, R. R., Warrior, H. V. & Kumar, V. Influence of the freshwater plume dynamics and the barrier layer thickness on the CO2
source and sink characteristics of the Bay of Bengal.海洋化学236, 104030 (2021). CAS一个
Google Scholar一个 Sridevi, B. & Sarma, V. Role of river discharge and warming on ocean acidification andp
公司2levels in the Bay of Bengal.Tellus B: Chemical and Physical Meteorology73, 1–20 (2021). CAS一个
数学一个 Google Scholar一个 Joshi, A. P. & Warrior, H. V. Comprehending the role of different mechanisms and drivers affecting the sea-surfacep
公司2and the air-sea CO2fluxes in the Bay of Bengal: A modeling study.海洋化学243, 104120 (2022). CAS一个
Google Scholar一个 Joshi, A. P., Ghoshal, P. K., Chakraborty, K. & Sarma, V. V. S. S. Sea-surfacep
公司2maps for the Bay of Bengal based on advanced machine learning algorithms.科学数据11, 384 (2024). CAS一个
PubMed一个 PubMed Central一个 数学一个 Google Scholar一个 Valsala, V. & Maksyutov, S. Interannual variability of the air–sea CO2
flux in the north Indian Ocean.海洋动力学63, 165–178 (2013). 广告一个
Google Scholar一个 Valsala, V., Sreeush, M. & Chakraborty, K. The IOD impacts on the Indian Ocean carbon cycle.Journal of Geophysical Research: Oceans
125, e2020JC016485 (2020). 广告一个
。Indian Ocean acidification and its driving mechanisms over the last four decades (1980-2019).全球生物地球化学周期38 , e2024GB008139 (2024).CAS
一个 数学一个 Google Scholar一个 Chakraborty, K.等
。Mechanisms and drivers controlling spatio-temporal evolution ofp公司2and air-sea CO2fluxes in the southern Java coastal upwelling system.河口,沿海和货架科学293, 108509 (2023). CAS一个
Google Scholar一个 Gloege, L., Yan, M., Zheng, T. & McKinley, G. A. Improved quantification of ocean carbon uptake by using machine learning to merge global models andp
公司2数据。Journal of Advances in Modeling Earth Systems14, e2021MS002620 (2022). Google Scholar一个
49, e2022GL098632 (2022). 广告一个
CAS一个 Google Scholar一个 Gregor, L. & Gruber, N. OceanSODA-ETHZ: A global gridded data set of the surface ocean carbonate system for seasonal to decadal studies of ocean acidification.地球系统科学数据
13, 777–808 (2021). 广告一个
Google Scholar一个 Chau, T. T. T., Gehlen, M. & Chevallier, F. A seamless ensemble-based reconstruction of surface oceanp
公司2and air–sea CO2fluxes over the global coastal and open oceans.生物镜19, 1087–1109 (2022). 广告一个
CAS一个 Google Scholar一个 Joshi, A. P., Kumar, V. & Warrior, H. V. Modeling the sea-surfacep
公司2of the central Bay of Bengal region using machine learning algorithms.海洋建模178, 102094 (2022). 数学一个
Google Scholar一个 Chau, T. T. T., Gehlen, M., Metzl, N. & Chevallier, F. CMEMS-LSCE: A global, 0.25°, monthly reconstruction of the surface ocean carbonate system.地球系统科学数据
16, 121–160 (2024). 广告一个
Google Scholar一个 Gregor, L., Shutler, J. & Gruber, N. High-resolution variability of the ocean carbon sink.全球生物地球化学周期
38, e2024GB008127 (2024). CAS一个
。Surface ocean CO2atlas database version 2022 (SOCATv2022)(ncei accession 0253659).地球系统科学数据(2022)。Pedregosa, F.
等。Scikit-learn: Machine learning in Python.the Journal of machine Learning research12 , 2825–2830 (2011).MathScinet
一个 数学一个 Google Scholar一个 Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system.在
Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, 785–794 (2016).Bennington, V., Galjanic, T. & McKinley, G. A. Explicit physical knowledge in machine learning for ocean carbon flux reconstruction: The
p公司2-residual method.Journal of Advances in Modeling Earth Systems14 , e2021MS002960 (2022).广告
一个 Google Scholar一个 Akiba, T., Sano, S., Yanase, T., Ohta, T. & Koyama, M. Optuna: A next-generation hyperparameter optimization framework.在
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2623–2631 (2019).Ghoshal, P. K., Joshi, A. P. & Chakraborty, K. An improved long-term high-resolution surface
p公司2data product for the Indian ocean using machine learning,https://doi.org/10.5281/zenodo.14614739(2025)。Sutton, A. J.
等。A high-frequency atmospheric and seawaterp公司2data set from 14 open-ocean sites using a moored autonomous system.地球系统科学数据6 , 353–366 (2014).广告
一个 数学一个 Google Scholar一个 下载参考致谢
The improved version of INCOIS-BIO-ROMS surface
p公司2data products (pCIBR_Clim and pCIBR_Int) has been developed as a part of the ‘Development of Climate Change Advisory Services’ project of the Indian National Centre for Ocean Information Services, Hyderabad, India, under the ‘Deep Ocean Mission’ programme of the Ministry of Earth Sciences (MoES), Govt.印度。The Surface Ocean CO2Atlas (SOCAT) is an international effort endorsed by the International Ocean Carbon Coordination Project (IOCCP), the Surface Ocean Lower Atmosphere Study (SOLAS), and the Integrated Marine Biosphere Research (IMBeR) program to deliver a uniformly quality-controlled surface ocean CO2数据库。The many researchers and funding agencies responsible for collecting data and quality control are thanked for their contributions to SOCAT.Sincere gratitude is extended to the scientists, funding organizations, and SOCAT data collection and quality-control process organizers.The field programs for making ship-based observations (presented in this paper as SAS data) were funded by several Indian funding agencies (Ministry of Earth Sciences, Ministry of Science and Technology, Department of Space) of the Govt.印度。This is INCOIS contribution number 559.
道德声明
竞争利益
作者没有宣称没有竞争利益。
附加信息
Publisher’s note关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问本文在Creative Commons Attribution-Noncormercial-Noderivatives 4.0国际许可下获得许可,该许可允许任何非商业用途,共享,分发和复制以任何媒介或格式的形式,只要您提供适当的原始作者和来源的信用,请符合原始作者和来源,并提供了与Creative Commons的链接,并指示您是否修改了许可的材料。您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Ghoshal, P.K., Joshi, A. & Chakraborty, K. An improved long-term high-resolution surface
p公司2data product for the Indian Ocean using machine learning.SCI数据12 , 577 (2025).https://doi.org/10.1038/s41597-025-04914-z
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41597-025-04914-z