
自然语言处理模型揭示了人类对话的神经动态
作者:Cash, Sydney S.
介绍
自然对话是人类交流的一种基本方式,不仅可以传达,还可以从语言传达复杂的信息。这个核心过程涉及两个不同但互补的语言计算之间的频繁过渡:理解和生产。语音理解涉及一系列结构化的过程,这些过程从声学信号中提取信息,使我们能够理解句子的含义并理解所传达的主题和上下文信息1,,,,2,,,,3,,,,4,,,,5,,,,6。相比之下,语音生产计划涉及一个反向过程,在该过程中,高阶概念信息转换为运动计划以进行发音7,,,,8,,,,9。这些过程对于在对话中传达信息是必要的10,,,,11,包括提取意义以及计划和生产我们自己的口头输出的过程。
对话的动态性质,交换信息的多样性及其上下文性质使人的神经机制是人类对话的基础12。为了应对这些挑战,以前的研究在很大程度上采用了简化主义方法,将对话分解为较小,更易于管理的组成部分。特别是,大多数研究都使用了块设计任务,这些任务涉及预定的语言材料和对话中的脚本转折,并专注于语言或过渡过程的有限方面13,,,,14,,,,15。鉴于自由流动的演讲的动态性质16,很少的工作直接研究了自然对话的神经表示作为一个连续的过程17,以及在自然对话中如何在大脑中代表语言仍然是一个挑战。
具体而言,尽管某些大脑区域已被证明可以区分有意义的有意义的句子与降解或非敏感的刺激,这表明它们参与了语言处理18,,,,19,,,,20,,,,21,详细的神经过程,在大脑中可能表示单词序列仍然很大程度上是未知的。此外,虽然在语言生产和理解中涉及的领域之间通常存在广泛的重叠22,,,,23,,,,24,,,,25,,,,26,在谈话中代表说话和聆听是否涉及的常见神经过程仍然很少理解。最后,尽管大脑的某些区域已与对话或转弯有关13,,,,27,,,,28,,,,29,关于大脑活动是否与对话过程中传达的信息有关,尤其是在考虑分析自然语音时间动态的方法时,知之甚少。
基于人工深度学习神经网络的自然语言处理(NLP)模型的最新进步提供了一个前瞻性平台,可以通过该平台研究持续的自然语言互动。这些模型已显示出在对话中与人类受试者的高级表演互动30并可以在基于理解的任务和提问方面实现最先进的基准31,,,,32,,,,33。这些模型能够使用向量捕获特定的单词序列及其在短语和句子中的组成34,,,,35,,,,36。通过提供语言的结构化表示,这些模型可以在语言内容和记录的神经活动之间提供至关重要的联系。实际上,NLP模型在解释被动聆听期间的大脑活动方面也表现出了高性能37,,,,38,,,,39,表明它们在表示神经生物学活性和机制方面的能力。例如,最近的研究表明了共享的上下文空间和与人脑的类似几何模式,从而有助于交流40,模型的中层和较高层为神经活动提供了最佳的解释能力41。通过这种方式,无论参与者使用什么特定的单词和句子,这种方法都提出了一种可量化的方法来研究语言的产生和理解。
在这里,我们将这些模型用作自然对话过程中语言的人工,层次结构化的矢量化表示。这种方法使我们可以研究大脑在对话中将整个单词序列作为一个过程中的整个单词序列进行处理,而不是将其分解为小部分。此外,通过检查神经通道活动与NLP嵌入之间的相关性,我们旨在确定专门参与与语言相关信息的大脑区域。这种方法使我们能够探索在口语和聆听过程中,在大脑和聆听过程中,尽管语言内容有所不同,但特定的单词序列以及它们的组成语义和上下文特征如何。最后,这种方法使我们能够比较在说话者过渡期间选择性响应的神经模式与处理单词序列的神经模式。我们的方法一起通过直接研究说话,听力和说话者过渡的综合过程,对自然对话的神经机制进行了全面的研究。这种方法对语言交流的这些相互联系的方面涉及的神经基板提供了整体观点。
结果
自然对话中的神经记录
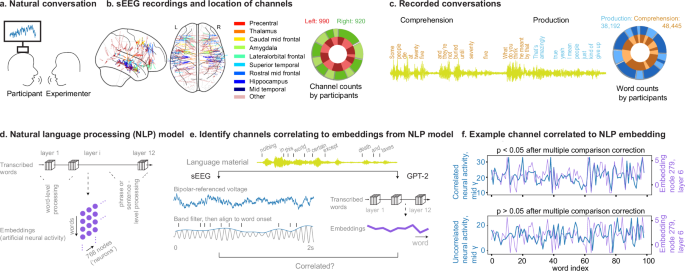
在14名接受癫痫监测的参与者中,使用半静脉植入深度电极作为其临床护理的一部分(6名女性和8名男性,平均年龄为34岁,16至59岁,图16至59)获得了局部田间电位(LFP)记录。 1a,桌子 S1)。一起,我们从1910年双极引用的通道记录了(图 1B)。这些通道跨越了两个半球的总共39个大脑区域(桌子 S2)。排除表现出低信噪或频繁癫痫样放电的电极(方法)。对于所有记录,将LFP过滤并转化为Alpha(8â13Hz),Beta(13 30),低γ(30-55),中伽马(70 110)和高伽马(130-170)频带(图)(图。 S1)。

指示参与者与实验者进行自然对话,并记录其神经活动。b将深度电极植入14名参与者中,以记录局部现场电位(LFP)。共有1910个双极引用的通道表明癫痫样放电率较低,主要分布在两个半球的额叶,颞和近中区域。频道的位置显示在左边,每个参与者的渠道数量显示在正确的通过亮度。使用NiLearn包装(Nilearn Contrutors,Chamma,A。等(2025)。Nilearn(TestRelease)。Zenodo。https://doi.org/10.5281/Zenodo.14697221)。c对话材料被抄录到单词,以及参与者感知或产生的单词都被标记了(左边)。这导致所有参与者总共有86,637个单词,每个参与者的单词计数显示在正确的通过亮度。d参与者感知和产生的转录单词是对GPT-2模型的输入,并且获得了所有节点和所有层的嵌入。e这些嵌入与每个频带的LFP相关。通过这种方式,我们确定了与人工模型中特定节点的人工活动显着相关的通道。f与人工嵌入显着相关的示例通道(顶部),并且与人工嵌入无关(底部)。用Bonferroni校正对768个节点(方法)进行线性回归分析。源数据作为一个源数据文件。
在录音过程中,参与者与实验者进行了大约一个小时的无约束,自由流动的对话(范围16分钟;方法)。这些对话在主题和主题方面范围广泛,允许个人听和说话(表格 S3)。所有转录单词均以毫秒分辨率同步到神经活动。其中包括2728±1804(平均±s.t.d)在生产过程中和3460±2581个单词(在理解过程中)(图。 1C)。听力和口语之间平均有168个过渡,这反映了所相关人员之间的动态互换。
与基于NLP模型的活动相比,脑网络活动模式
为了量化对话过程中神经活动反映所传达的信息的程度(例如,在说话或聆听时简单的任何活动中的任何变化),我们采用了预先训练的GPT-2(小)模型42,,,,43,,,,44。重要的是,该模型以矢量化格式提供了对隐藏嵌入的访问。考虑到记录单词的数量,GPT-2小型模型用于我们的分析。
在这里,对模型嵌入(一组层次有组织的向量作为人工神经活动)进行了培训,以代表从广泛语言语言中提取的语言特征。当应用于自然对话时,该模型可以以定量的方式将单词和句子组成矢量化,可以直接将其与同时获得的神经数据进行比较37(图 1d,e)。因此,如果特定大脑区域的神经活动模式始终与这些语言模型中人工神经活动得出的活动相匹配,则这意味着它们的模式具有有意义的对话中传达的方面(请参阅方法)。具体而言,我们使用了参与者说话或听取的相同单词作为人工模型的输入,并检查了跨单词的大脑和模型活动之间的相关性,以阐明参与语言处理的神经活动。
通过跟踪自然对话中的LFP信号,我们发现大脑广泛的部分活动的变化与NLP模型的活动一致一致(图。 1d f)。当考虑所有记录触点和频带时,大多数大脑区域和频段的相关通道的总体分布均匀分布,这些通道的比例显着高于机会(Chi-Square Test,统计,7785,7785,p<10100)。平均和标准偏差r所有显示出显着相关性的通道的值均为0.12±0.04,听力的0.04±0.03(平均值±s.t.d.)为0.10±0.03,这意味着神经活动的变化反映了模型的嵌入所捕获的信息。
总体而言,与右侧相比,有更多的渠道来自左半球区域的活动相关活动(左)n= 990,对n= 920,卡方检验,统计= 1214,p= 3.6 - 10266,图 S2A)。此外,在17个大脑区域中,植入了大量通道(n€€25,方法),有九个地区显示出明显很高的渠道(p<0.01)与NLP嵌入相关,包括颞叶和额叶皮质,丘脑和边缘系统结构(图。 2a,b)。因此,在随后的数字中,我们将这九个区域用于可视化目的,以避免重叠的颜色。我们还检查了使用GPT-2模型对17个大脑区域进行多次比较的Bonferroni校正区域的比例(图。 S3),在其他NLP模型中显示出一致的响应(图 S4)。具体而言,并且可以预期的是,在理解过程中,在语音生产计划(21%)和左和右上颞皮层(分别为23%和25%)期间,在左侧前后皮层中发现了具有相关活性的最高比率(图2(图2.) 2a和 S2A)。此外,所有额叶,时间和介体大脑区域似乎都在多个频段中吸引神经活动,以在口语和聆听过程中进行语言编码(图。 2d)。这些结果以及从所有区域的这些相关通道的一般分布都在很大程度上保留了,无论惯用性如何 S2B)并且在参与者之间保持一致(图 S5),不论他们的智能商(IQ)如何(图 S6)或对话的长度(图 S7)。如果分配给最近的灰质的白色物质位置,它们也很健壮(图 S8),或者如果这些白色物质通道被完全排除(卡方比例测试:统计= 37.7,p= 8.2 - 1010讲话;统计= 127.4,p= 1.5â1029聆听,图 S9)。总之,这些发现表明,不同大脑区域(尤其是额颞网络)的神经活动与NLP模型的相似,具有相似的单词和句子组成的神经表示,由模型在语音生产和理解过程中捕获。

在所有参与者的两个半球中,频道总数较高的地区(n25),使用图2中描述的方法绘制了与人工网络嵌入显着相关的通道的百分比(平均值)。 1e,f。条形和点颜色表示该百分比是在语音产生还是理解过程中计算出的,而边缘颜色标签左或右半球。情节标签中的点百分比来自每个参与者,而条图中显示的总百分比是通过组合所有参与者的通道来计算的。误差线是根据二项式分布来计算的,每个区域中的通道数(数字的顶部)和右(底行)半球标记。BOLD中突出显示的大脑区域表示相关通道百分比显着超过卡方检验所检查的偶然性的百分比(没有多重比较校正,p<0.05,方法)。该区域的数量在很大程度上与更严格的控制结果一致,包括17个区域的Bonferroni校正(图) S3,方法)。b在语音生产过程中,通道的位置与NLP嵌入显着相关(顶部)和理解(底部)。为了避免拥挤并确保清晰度,仅说明了示例区域。使用NiLearn包装(Nilearn Contrutors,Chamma,A。等(2025)。Nilearn(TestRelease)。Zenodo。https://doi.org/10.5281/Zenodo.14697221)。c绝对的平均值r通道/频带和NLP嵌入的相关对的值(n当参与者的自然对话和控制任务中,1722年的讲话和748n= 4)指示聆听并重复设计的句子。灰色酒吧标记r从所有神经-NLP对中的值。d绘制相关渠道的百分比(n= 1910频道)基于语言产生和理解的频带。每个点都标记每个参与者的百分比(n= 14名参与者)。e根据自然对话中所有领域的NLP层绘制相关渠道的百分比(左边),以及具有被动聆听和重复句子的控制任务(正确的)。对于子图(d,,,,e),误差线和阴影区域是基于二项式分布计算的标准误差(n= 1910频道)。确切的p值(一个):中间时间,左,说话,p= 310;对,说话,p= 0.001;左,听着,p= 913;对,听着,p= 28;海马,左,说话,p= 0.01;对,说话,p= 0.009;左,听着,p= 26;中间额叶,左,说话,p= 0.01;左,听着,p= 0.003;对,听着,p= 0.0004;上等时间,左,说话,p=8。105;对,说话,p= 28;左,听着,p= 1e6;对,听着,p= 48;杏仁核,左,听,p= 0.0005;外侧眶额,左,听,p= 0.0004;尾部中部额叶,左,说话,p= 0.006;左,听着,p= 0.03;putamen,左,说话,p= 0.02;Thalamus-proper,左,说话,p= 0.009;前沿,左,说话,p= 0.008;左,听着,p= 0.02;pars-triangularis,左,说话,p= 0.01;对,说话,p= 0.04;对,听着,p= 0.03;岛上的,对,听,p= 0.03;下顶,左,听,p= 0.04;对,听着,p= 0.03;上级,左,说话,p= 0.05;对,听着,p= 0.02;上额,左,说话,p= 0.02;左,听着,p= 0.02。源数据作为一个源数据文件。自然对话中神经NLP关系的概括和鲁棒性
为了进一步确保神经活动与NLP模型的嵌入之间的关系与语言相关,我们将神经活动随机定位于单词上,以消除偶然获得的任何与语言相关的特征。
当随机分配和使用来自所有大脑区域的所有通道时,我们发现显示出选择性的触点比例明显较低(卡方检验,统计,5002,5002,p<10100,图 S10A)以及与r= 0.02。此外,我们表明,无论转变之间的语音持续时间或使用非参数秩相关性,神经-NLP相关性都是牢固的(材料和方法,图。 S11)。这些共同证明了在自然对话的语言过程中神经NLP关系的鲁棒性。
其次,我们表明,这些来自所有大脑区域的NLP相关活动无法通过与低级声音特征的相关性来解释。我们认为,如果观察到的神经NLP相关性起源于对低级声音特征的响应的神经活动,我们希望与NLP相关的通道对声音功能表现出更高的响应,例如与所有通道的声音响应相比(包括与NLP不相关的响应)。但是,与所有记录的通道相比,NLP相关的通道对语音振幅和音高的响应相似(两侧置换测试结合了幅度:p=说话0.41,p=聆听0.21;沥青:p=说话0.79,p=聆听0.60;n= 10,000)。第三,为了确认上述发现是可推广的,我们比较了从所有领域的神经活动模式与在其他数据集中训练的另一个NLP模型的神经活动模式。在这里,我们使用了双向网络架构的BERT(基本)模型,并接受了不同语言材料的培训45。
同样,我们发现相关通道的比例明显高于机会(卡方检验,统计= 15,278,,,p<10100),并且大于GPT-2模型观察到的(图) S10B)。此外,在具有不同层和体系结构的一系列NLP模型中观察到了类似的发现(图 S12,卡方比例测试,p<123),随着相关通道百分比增加到NLP模型的大小(r> 0.80和p23)。这些表明,大脑中神经活动模式与语言模型的关系之间的关系是神经元反应的可推广性能。第四,我们调查了与自然对话唯一相关的信息与通过指示参与者聆听句子并重复他们听到的句子的被动聆听两个句子的独特相关的信息不同。该任务旨在模拟说话和聆听的格式,但用约束材料(方法)代替自然对话的自发性。
总的来说,我们对4位参与者(465个渠道)执行了这项任务,每个参与者听到237±6(平均值±s.d),平均为233±6个单词。接下来,我们计算了r来自神经-NLP对的值(范围0)在自然对话中显着相关。我们发现,当参与者被动地参与伪对话时,平均相关系数显着下降(语音产生为0.13至0.09,理解为0.11。t-测试,p256对于这两个图,图 2C)。因此,这些神经签名与对话特别相关,而不是更简单地说话和倾听。
最后,我们对同一四个参与者进行了jabberwocky的控制,这是由听起来像单词但没有传达实际含义的伪单字符串组成的(例如,pikap的dorty dorty dorty cikap a flup a flup a of mool flup。)。因此,即使参与者正在产生和感知类似的声音签名,但他们并没有进行有意义的对话,从而使我们能够与参与对话有意义的对话的人一起,简单地将演讲的言语和声音表达成分与演讲的互动。我们发现,与Jabberwocky的理解和生产相比,对真实句子做出响应的渠道的百分比明显更高(ANOVA重复测量,自由度数= 12,12,12f= 34.1,p=说话的0.0043;f= 18.5,p=聆听的0.012,图。 S13)。这些表明,通过对话传达的语言含义对神经加工产生了重大贡献,表明语言理解和生产的复杂性。
跨频段和NLP层的神经NLP关系
神经-NLP的相关性不仅跨越了额叶,时间和介体区域,而且占据了多个频带。具体而言,从所有大脑区域的每个频段的相关通道的百分比始终高于理解和生产的机会(每个频率的卡方检验,统计> 13,13,p<3â104;FDR校正了多个频率),对于语言理解和生产,中伽马频率(70â级Hz)中观察到的百分比最高(11%和14%,图。 2d)。此外,这些频率模式在生产和理解中都显示出对大脑面积的依赖性弱(重复测量方差分析,自由度= 4,4,4f(32)= 2.49,p=说话0.063,f(32)= 3.3,p= 0.02聆听,图。 S14)。例如,在语音生产计划期间,中间皮层中的13%的通道与高γ频段中的NLP嵌入相关,而在Rostral中部额叶皮层中只有5%的通道表现出相似的关系。此外,尽管许多领域在理解过程中表现出较高的频道(例如,中间和上级皮层中的24%和35%),但包括海马和杏仁核在内的其他领域,含有较高的Alpha频率(分别为12%和10%和10%)的频道比例更高。总之,这些发现表明,与语言处理相关的神经活动的频率不仅是广泛的,而且表明与非侵入性FMRI方法相比,颅内EEG具有独特的表征。
对话期间的神经对模型相关性取决于语言模型中的隐藏层。在NLP中,语言的处理发生在层次层中,从大量文本数据中提取统计模式。尽管图层并不直接与已知的语言类别相对应,但较低(输入)网络层优先反映有关单个单词独立于其上下文的信息,而中间层捕获了更复杂的语言结构,较高(输出)层反映了综合的构图句子层信息46,,,,47,,,,48,,,,49,,,,50。因此,为了进一步研究神经活动模式与NLP模型之间的关系,我们计算了与每个网络相关的所有领域的渠道百分比,发现神经活动优先与语音计划和理解较高的网络层相符(在讲话期间的第一层和最后6层中,12%和14%t-test统计= 3.2,p= 13;14%和18%的理解,统计= 4.3,p= 1.8 - 105,图 2e)。对于语音产生和理解,已经观察到类似的层依赖性模式,其输入层中重要的通道百分比较低(语音产生为8%,语音理解的9%)随后逐渐增加,达到了第8层的峰值(口语为11%,聆听13%)。在朝向输出的较高层时,我们观察到随着层的增加,显着通道的减少。跨层的这种神经分布与参与者被动聆听与表达句子的试验有显着不同(重复测量ANOVA,f(12)= 23.3,p= 44倾听,f(12) = 5.6,p = 0.036 for speaking).Further, the specific layer distribution was dependent on the brain area (repeated measurement ANOVA,f(96) = 4.2,p < 1 × 10−5for speak;f(96) = 6.7,p < 1 × 10−5for listen, Fig. S15), with those from temporal lobe exhibiting higher layer-dependence compared to those in frontal cortex (temporal: 11.8% for first six layers, 15.0% for last six layers during production planning; frontal: 9.1%, 9.9%).In short, the majority of neural activity patterns likely reflect higher-order contextual information rather than low-level early processing or pre-speech motor planning.
Neural activity patterns during speech production versus comprehension
While the above findings suggested a broad representation of word sequences during production and comprehension, it remained unclear whether or how these representations overlapped spatially across the frontotemporal network.Therefore, to examine this in more detail, we tested the correlation between neural activity and the NLP models from all areas that were specific to either production or comprehension.Overall, we found a similar number of channels whose neural activities were correlated with those of the NLP models during speech production planning compared to comprehension (210 and 286 contacts, respectively; Fig. 3a) as well as a similar strength of correlation with the models (r = 0.12 vs.r = 0.11, Fig. 3a)。This percentage of significant channels could not be attributed to word count disparities between production and comprehension for each participant (Fig. S16, “Methodsâ€).Across all patients, there were 76 channels (18%) that showed shared responses for both speech production and comprehension, displaying some overlapping processing between the two activities.These overlapping representations were significantly higher than chance (Chi-square proportion test, statistic = 19,p = 1.3 × 10−5), although 82% of selective channels only responded during production or comprehension alone.Fig. 3: Comparing neural activities during language production and comprehension.一个

左边)。Individual data points are not applicable because bar plots represent the total number of channels from all participants.Absolute correlation coefficients (mean ± s.e.m.) are plotted by channels significantly correlated to artificial embeddings during comprehension or production (n = 134, 210, and 76 channels respectively,中间)。Percentage of correlated channels selective to language production and comprehension were plotted by their locations (正确的)。Individual data points are not applicable because bar plots represent the percentage of responding channels relative to all recorded channels from all participants in both hemispheres.The number of samples is the same as illustrated in Fig. 2a。bThe locations of the channels that responded to both production and comprehension were shown in large dots, and the smaller dots showed the channels that only responded to one of comprehension or production.Only example areas are illustrated.Glass brain plots were generated using the Nilearn package (Nilearn contributors, Chamma, A., et al. (2025). nilearn (TestRelease). Zenodo. 10.5281/zenodo.14697221).Source data are provided as a源数据文件。
Furthermore, different brain areas exhibited different extents of overlapping processes (Fig. 3a, b)。For example, most channels selective to production were also selective to comprehension in the superior and middle temporal cortex (14% and 11% selective to both vs. production alone in the superior temporal cortex; 8% and 7% in the middle temporal cortex).Similarly, most channels selective to comprehension were selective to production in the precentral cortex (9% and 3% selective both and perception alone).In contrast, other areas, including the rostral middle frontal cortex and lateral orbitofrontal cortex and amygdala, displayed minimal overlapping between speak and listen (≤1%).This inhomogeneous distribution of channels responding during either speech production, comprehension, or both cannot be attributed to randomness (Chi-square test considering the ratio of channels selective to both to the total number of channels,p = 2 × 10−6)。Collectively, although the channels selective for speech production and comprehension exhibited certain degree of overlap across all examined brain areas, there was a significant inhomogeneity in their distribution, particularly within the specific areas we scrutinized.
Neural activity during speaker–listener transitions correlated with those in response to the NLP model
A core aspect of conversation is the alternating transition between listening and speaking.Given the distinct neural processes underlying speech production and comprehension, we also examined neural activity during transitions between speaker and listener to investigate whether these neural activity patterns aligned with specific transitions rather than established correlations for production or comprehension.To start, we tracked specific transition points at which the participants changed from listener to speaker or from speaker to listener during dialog.These were the times when they specifically shifted between assimilating and communicating information (Fig. 4a)13。Across all brain areas, we found that 13% of channels displayed a significant change in activity during transitions from comprehension to production, whereas 12% displayed significant changes at the transitions to comprehension (Fig. 4b)。Both proportions were significantly higher than random chance (Chi-square proportion test,p = 7 × 10−88和p = 1 × 10−64), and most of these channels were only selective during natural conversation, compared to a control in which the participant was “forced†to take turns (66% channels only selective to turn-taking to speak during natural conversations but not during designed turn-taking, whereas the percentage was 55% channels selective to natural turns to listen, Fig. 4b)。In addition, the number of contacts at the transitions from production to comprehension was significantly smaller than the transition from comprehension to production at low-frequency bands (alpha, beta bands, two-side permutation test,n = 105,,,,p = 0.048, 0.035 respectively), whereas there were little differences at the mid- and high-gamma bands (p = 0.39 andp = 1.0) between the two directions.These patterns were consistently found throughout the brain (Fig. S17)。Further, the patterns also differed in polarity in terms of increases to decreases in activity.For example, there was a decrease in beta frequency activity in the superior temporal cortex during the transition to comprehension, whereas channels from superior and middle temporal cortices demonstrated an increase in middle and high-gamma bands (Fig. S18)。Together, neural activities reflected transitions during turn-taking, showing diverse changes among brain areas and frequency bands.

Audio waveform illustrates the transitions between production and comprehension (顶部) and the counts for turn number for each participant (底部)。bThere are an average of 13% and 12% channels that showed significant changes of activities across all areas and all five bands during transitions, but transition to comprehension adopts a lower number of channels at low-frequency bands (alpha, beta) compared to transition to production, whereas the mid- and high-gamma bands are similar.Each gray dot labels the percentage of significant channels for each participant (n = 14 participants), whereas the bar plot is calculated from combination of all channels from all participants (n = 1910 channels).The subplot on the正确的shows the channels that responded to turns during natural conversation compared to designed transitions.cComparing transition-responding channels to the ones that are significantly correlated to NLP during production, there is significant overlapping between NLP-response channels and the transition-response channels.Source data are provided as a源数据文件。
Finally, we asked whether neural responses to these speaker–listener transitions overlapped with those reflecting correlations with the NLP models.It is possible, for instance, that neural responses to these transitions used entirely separate subsets of neural patterns compared to those encoding the specific information being conveyed during conversation.We found from all areas, however, that 39% (112 out of 286) of the contacts whose activities correlated with that of the NLP models overlapped with those that displayed speaker-to-listener transitions (Fig. 4C), while 40% (84 out of 210) of the production-planning contacts displayed changes during listener-to-speaker transitions.This degree of overlap was markedly higher than that expected by chance (Chi-square contingency;p = 4.9 × 10−14and 1.7 × 10−22for each transition direction respectively).These neural activity patterns therefore appeared to reflect not only information about the conversations being held but also tracked the specific transitions between speakers at which times the “directionality†of communication changed—elements that together would be necessary for our ability to converse.
讨论
Major challenges in understanding how our brain supports natural conversation include limitations in precisely recording the relevant neural activity, the difficulty of richly and accurately representing word sequences, and the ability to place both of these problems in the context of natural human interactions51,,,,52。By comparing intracranially recorded neural patterns during natural dialog between individuals to those of NLP models, we have taken a unique route toward overcoming these significant hurdles.This approach importantly allowed us to examine directly the interconnected neural processes of speech production, comprehension, and transition, providing a comprehensive analysis of the crucial components of natural conversation as an integrated system.We found that compositional information about the word and contextual features as captured by the models could similarly explain neural activity patterns found in the brain when the participants were not only engaged in language comprehension but also during language production.These neural patterns were carried across multiple frequency bands and showed heterogeneity over brain areas, and were largely absent when randomizing the neural data, suggesting that these neural patterns reflected the specific word sequence being conveyed in natural conversation.Similarly, channels that responded to speaker transitions were not localized in certain brain areas or frequency bands.These together, indicate a well-coordinated and integrated neural pattern underlying the process of natural conversation.
To support smooth speech production and comprehension in natural conversation, neural activity is characterized by a distributed and widespread patterns of activation17。We found that responding channels spanned across various cortical and subcortical areas (e.g., frontal and temporal cortices, hippocampus, and amygdala), and were significantly reduced during pseudo-conversation controls.These findings collectively suggest that natural conversations involve an integration of neural signals across various processing pathways.In contrast, previous studies showed localized neural engagement (e.g., STG for comprehension, precentral for production) for language-specific activities9,,,,37,,,,53,,,,54。By examining neural activity in these regions during natural conversation, we found a higher percentage of responding channels from the established language areas, with more than 20% of responding channels located in superior temporal cortices during comprehension and the left precentral area during production.This heterogeneity suggests that, while conversation engages widespread areas of the brain, language areas still maintain a central role in the natural verbal communication54。Together, the broad and heterogeneous distribution of neural response suggests the complex and interconnected nature of language processing during real-world communication.
In addition, when comparing neural encodings during speech production and comprehension, we found that information being conveyed in speech production, though, did not simply mirror that of comprehension.Here, we found a higher ratio of channels involved in language processing in the temporal cortex during comprehension than production, whereas the precentral cortex was biased towards production planning, suggesting distributed processing with varying functional tendencies for different brain regions.In addition, most neural activities throughout frontal and temporal lobes reflected either production or comprehension, with less than 20% of single channels involved in both.Together, these findings suggest the presence of a core set of locations that respond selectively to both language modalities, in addition to areas reflecting exclusively one of the processes.In addition, speech production and comprehension involve similar oscillatory dynamics in natural conversation.While most frequency bands showed activation, we observed a higher percentage of responding channels in the gamma frequency55。Together, although previous fMRI work has suggested partially shared brain areas underlying language comprehension and production56,,,,57,,,,58,,,,59, sEEG recordings offer direct measurement of neural activities that have high temporal resolution and can be applied, leveraging deep learning approaches, to natural conversation.This provides a richer and more complete view of the neural basis of normal human conversation than has been achieved previously.
Further, neural patterns partially overlapped between those that encode word sequences conveyed between speakers with those that respond to speaker-role transitions.When tracking neural responses during comprehension-production transitions, we observed that many brain areas significantly changed their activity during turn-taking, a process surprisingly similar to that observed in prior animal and human models of communication13,,,,60。More notably, these neural changes closely overlapped with brain areas that respond to word sequences as identified by neural-to-model correlations.These findings further expanded upon previous studies that identified frontal cortices involved in speech production planning during speaker transitions13。These findings suggest that the response patterns reflected the process of communication rather than simply the act of listening or speaking.
A final striking finding was the relationship between neural activities and the activities of specific nodes in the NLP models37,,,,53。Overall, we found that neural patterns of activity in the brain reflected the artificial activities of nodes across all NLP layers.This indicates a complex and distributed mapping of the neural processes which may involve multiple levels, from low-level lexical features to high-level semantic and abstraction representations46,,,,48,,,,49,,,,50,,,,50。Further, the neural dynamics of most areas preferably correlated with representations in the middle and higher layers of the NLP model, suggesting that neural activity patterns reflected contextual or sentence-level information integration over the course of conversation rather than showing a specific focus on individual words which would be represented by lower layers.Notably, these layer distributions were significantly altered when the participants passively listened to and repeated sentences, indicating differences in processing mechanics during language tasks compared to more natural language.
Taken together, using a combination of intracranial recordings, NLP models, and naturalistic conversation, our findings reveal a set of collective neural processes that support conversation in humans and a detailed organization of neural patterns that allow word and sentence composition to be shared across speakers.However, there are limitations of this study: Our primary focus is to demonstrate the differences between natural conversation compared to passive listening and repeating rather than delving into their underlying mechanisms.Due to the inherent complexity of natural conversation, future studies will be needed to pinpoint the precise linguistic or cognitive factors responsible for differentiating it from passive listening and repeating.Further, variations in electrode placement across participants hinder direct comparisons of neural activity, making it challenging to precisely quantify individual differences in brain responses.Lastly, the reliance on text-based NLP models limits its ability to capture the full richness of spoken language, as it excludes acoustic information.Here, our results provide an initial prospective neural framework by which to begin understanding the detailed neuronal computation underlying verbal communication in humans.
方法
In this study, all data acquisition and analyses were approved by the Partners Human Research Committee Institutional Review Board (currently Massachusetts General Brigham Institutional Review Board).Before their enrollment in the study, participants were informed that their participation would not impact their clinical treatment and that they could withdraw their participation at any time without impacting their clinical care.Electrodes were targeted and implanted independent of any study consideration.Consent was obtained from all study participants.
Stereo EEG recording
We recorded neurophysiological data from fourteen intractable epilepsy participants during invasive monitoring for localization of the brain areas that onset of their seizures (Table S1)。A team of clinicians who were independent of this study determined the decision to implant electrodes, the type of electrodes and the areas for implantation solely based on clinical grounds (Table S2)。We recorded neuronal activities using one or two neural signal processor systems (128–256 channels, NSP, Cerebus, Blackrock Microsystems).These raw voltages were digitized at a 2 kHz resolution and then filtered online to capture LFPs (low-pass filter, 1 kHz cutoff).When two systems were used for recording, we aligned them within a temporal error of 10 ms.
Natural conversation
We recorded the speech comprehension and production of the participants from conversations between the participant and the experimenter (>15 min).These conversations varied broadly in topic and theme to allow the participants to actively engage in dialog whereby they both listened and spoke (Table S3)。For example, conversations would involve real-world topics such as a movie that was recently watched or interpersonal thoughts and events shared between the experimenter and the subject.
Control task with passive listening and speaking sentence
To investigate to what extent information is uniquely associated with natural conversation compared to passively listening and speaking sentences in block design tasks, we performed the following control experiment: Participants were instructed to listen to sentences and passively repeat the words they heard.This task was designed to simulate the format of a natural conversation but replaced the content of the dialog with designed materials.In total, this trial contains 240 words with eight words per sentence.
Control task with passive listening and speaking Jabberwocky
To further dissociate the processes related to motoric and perceptual aspects of speeches in a conversation from those that reflected meaningful communication relayed through dialog, we performed a Jabberwocky control when the participants were instructed to listen and repeat lists of pseudowords that sounded like English sentences.These lists of pseudowords, while structurally similar to real sentences, lacked actual meaning (e.g., “Dorty of the pikap incaged a flup of mool.â€).In this way, we isolate the contribution of the sensory perception and motor articulation from the meaningful speech processing.
Speech recordings
We used an audio recorder (DR-40X by TASCAM) to record the conversation.The audio was synchronized with the intracranial activity at a millisecond resolution by adding an analog input channel to the NSP (Blackrock Microsystems).Audio recordings for each participant were firstly automatically transcribed using whisperX61, then manually adjusted to align the time stamp for each word and manually assigned the speaker identity (participant or experimenter) using either Audacity (The Audacity Team, version 3) or SpeechScribe, a Python application developed in house for manual speech annotation.Any words or sentences containing participants’ personal information were removed and replaced by a set of other names and digits.
Estimation of the number of channels and words
To estimate sample size (number of channels) to achieve 80% statistical power, we used the test for one proportion62。Specifically, we followed the equation below to estimate the sample size\(n\)based on the probability that a channel is significant\({p}_{1}\), the chance level\({p}_{0}=0.05\), 这zvalue for the threshold\(\alpha=0.05\)and the power\(\beta=0.8\):
$$n=\left(\frac{{z}_{\alpha /2}\sqrt{{p}_{0}(1-{p}_{0})}+{z}_{\beta }\sqrt{{p}_{1}(1-{p}_{1})}}{{p}_{1}-{p}_{0}}\right)$$
(1)
We estimated\({p}_{1}\)with a range between 10% to 40%.The estimated sample size increased from 6 for\({p}_{1}=0.4\)to 185 for\({p}_{1}=0.1\)。Therefore, the recorded number of channels after bipolar referencing, 1910, is much higher than the sample size required for 80% power.
Further, we conducted a power analysis of correlation to estimate the minimum number of words required per participant to detect a significant correlation between neural activity and language embeddings.We used Fisher’sz-transformation for the correlation coefficient test63:
$$N={\left(\frac{{z}_{\alpha }+{z}_{\beta }}{C(r)}\right)}^{2}+3$$
(2)
在哪里
$$C\left(r\right)=\frac{1}{2}\log \left(\frac{1+r}{1-r}\right)$$
(3)
Assuming a moderate sample correlation (r = 0.1), an alpha level of 0.05, and a power of 0.8, our calculations indicate that ~783 words spoken or perceived per participant would be sufficient.As our dataset contains a larger number of words per participant (2728 ± 1804 (mean ± s.t.d) words during production and 3460 ± 2581 words during comprehension), our sample size was adequately powered to detect meaningful effects.
Electrode localization
We adopted a combined surface registration and volumetric process to identify each electrode’s anatomical location within the brain64,,,,65。We first used FreeSurfer66to align preoperative MRI data with a postoperative CT scan, then we manually transformed electrode locations identified from the CT scan into the MRI space67。We mapped each electrode to a set of brain regions defined in the DKT atlas using an electrode labeling algorithm68,,,,69,,,,70,,,,71。The electrodes were assigned with an additional probability of being situated in white matter (Table S2)。Electrode contacts were then mapped to MNI space using Fieldtrip volumetric morphing tools72。To illustrate the locations of these electrodes, we used the Nilearn python package (version 0.10.1,https://doi.org/10.5281/zenodo.8397156)。
Bipolar referencing
Neural data was re-referenced into a “bipolar†configuration by taking the voltage differences between adjacent channels from the same electrode array in MATLAB (MathWorks).The importing of neural data was assisted by the NPMK toolbox (Blackrock Microsystems), and then processed in MATLAB (six participants) or in Python (eight participants).Channels that showed no variance or regular 60 Hz oscillation across the whole recording period were excluded from further analysis.The voltages were further decimated to 1 kHz.In total, we obtained 2234 electrode pairs from 14 participants.
Interictal epileptiform discharge detection
Though no seizure occurred during the language tasks, interictal discharges may be common.In order to remove these possible large-amplitude confounds from further data analysis, we detected epileptiform discharges automatically73and removed channels in which there was a high rate of epileptiform events (>6.5 discharges/min).This resulted in a total of 1910 bipolar channels remaining from fourteen participants.
Frequency bands computation and alignment to words
LFPs were further processed for amplitudes at alpha (8–13 Hz), beta (13–30), low gamma (30–55), mid-gamma (70–110), high-gamma (130–170) frequencies using the scipy package for signal processing in Python with the following steps (Fig. S1): To construct the envelope of each frequency band, the voltages were filtered by a Chebyshev type II filter with 4th order and 40 dB attenuation for each frequency band, and a Hilbert transformation was further applied.Next, outliers of the envelopes were capped to\(q3+c\bullet (q3-q1)\)and floored to\(q1-c\bullet (q3-q1)\), 在哪里Q1和Q3are the first and third quartiles, andc = 5 determines the threshold of outliers.
To compute the neuronal activities for each word, envelopes were initially aligned to the auditory signals.For each word, the neuronal activities at each frequency band were computed as the average of the envelope over a 0.5 s window before word onset for speech production planning and afterword onset for comprehension.After this step, for each frequency band of a channel, we obtained an array of neural activities at the same dimension as the word number.
De-autocorrelation
EEG signal is known to possess high long-range temporal correlations and 1/f-like power distribution74,,,,75。In our study, neural activities by words indeed showed strong autocorrelations at all frequency bands we examined.After we aligned the envelope for each frequency to the onset of words and treated the progress of words as a time series, we found that the first-order autocorrelation (AR1) dominated, with an average across all channels for each frequency band higher than 0.4 during speak and listen.These autocorrelations might result in a spurious high correlation to NLP embedding if we had directly calculated the correlation.Therefore, we used a standard autocorrelation estimation called the Cochrane-Orcutt method to process AR(1) in the neural activity76。To avoid heavy computation, we estimatedÏas the AR(1) term from the neural activities and the NLP embeddings respectively.Specifically, the first-order autocorrelation of neural activities as the sequence of words was calculated for each frequency band:
$$\rho={\mbox{corr}}\left({X}_{i},{X}_{i-1}\right)$$
(4)
在哪里\({X}_{i}\)is the neuronal activity for the我th word.Then we removed the AR(1) by transforming the envelopes by
$${\widetilde{X}}_{i}={X}_{i}-\rho {X}_{i-1}$$
(5)
Next, we further treated the outliers withc = 1.5 using the same method as described in the previous paragraph to ensure that our findings were not driven by just a few points.In this way, we only used one variableÏ, and it only counted the degree of freedom of 1. This autocorrelation does not directly reflect any information specific to language (for example, part of speech, lexical semantics, etc).
Natural language processing (NLP) network and embeddings
NLP models process language hierarchically, but without explicit, human-readable rules for each linguistic level.Instead, they learn patterns from large text datasets, approximating linguistic processes statistically.Their embeddings do not necessarily represent single-language elements or correspond directly to linguistic categories.Rather, they encode complex, multidimensional linguistic information distributed across many dimensions, providing a comprehensive representation of language.
We selected a Generative Pre-trained Transformer (GPT-2, small) model to encode language information and compare it to brain activities42,,,,43: The OpenAI GPT-2 model has been applied in previous work to multiple brain imaging studies and has been shown capable of capturing variance of brain activities from multiple areas during language comprehension37。This model was trained on a combination of text datasets that were built on a wide range of natural language demonstrations including diverse domains and contexts, hence, the GPT-2 model was able to process natural dialog with informal colloquial terms (e.g., “gonna†rather than “going toâ€) often encountered during real-world conversations31,,,,32,,,,33,,,,77。We directly loaded the tokenizer (mapping of a word to a vector) and the model from the pre-trained GPT-2 small model in PyTorch via huggingface without fine-tuning44。The model was built on 12 structurally identical modules in sequence and input sentences were represented between layers by hidden embeddings, which were 768-dimension vectors for each word per layer (i.e., 768 nodes or artificial neurons).The model outputs 13 sets of hidden embeddings with 768 dimensions for each word of a sentence.These 13 embeddings include the embeddings “output†of the 12th hidden layers and the “input†embedding to the first module.To capture the contextual information of the discourse for each word, we input words with a moving window of 600 words (concatenation of current and previous words) with stride of 10 words to NLP model to get the embeddings.For words corresponding to more than one token (part of words), the embeddings were obtained from the last token of the word.After this step, we got the embeddings with the dimension of number of words × 768 nodes × 13 layers for each participant.
Correlating neural activities to NLP model embeddings
To examine how brain activity is involved in language processing, we correlated neural activities to artificial embeddings by checking all neural-artificial pairs.Specifically, after de-auto-correlating the artificial embeddings following the same procedures described in Eq.((2) and treated outliers using the method described above withc = l.5, we fit the neural activities (as a function of words) per frequency band of a channel using the artificial embeddings (on the same words) of a node to a linear regression, and obtained the Pearson correlation and thepvalue of whether they were significantly correlated (h: slope = 0).0This resulted in apvalue matrix with the dimension of number of channels × NLP nodes × NLP layers × frequency bands (i.e., 1910 × 768 × 13 × 5).Next, we identified the significant neural-NLP pairs and examined how these correlations are impacted by frequency band, layer, and brain region.
First, to analyze the distribution of channels showing significant neural-NLP correlationsacross different frequency bands, NLP layers, and brain areas, we applied apvalue threshold of 0.05 and performed Bonferroni correction to account for multiple comparisons across NLP nodes (p < 0.05/768 = 6.5 × 10−5)。Second, to examine whether neural-NLP correlation varied based on frequency band, we calculated the percentage of significant neural-NLP pairs by averaging over the dimension of channels and layers to focus on the dimension of frequency bands (Fig. 2d)。This allows us to test whether neural activity varies with frequency band (i.e., rather than whether neural activity varied with layer).Similarly, to examine whether neural-NLP correlation varied based on NLP layers, we calculated the percentage of significant neural-NLP pairs by averaging over the dimension of channels and frequency bands to focus on the dimension of NLP layers (Fig. 2e)。Finally, to examine neural-NLP correlations across brain regions, we averaged over the dimension across NLP layers and frequency bands, and grouped channels by their location.For visualization purposes, we focused on brain areas with high number of channels (n ≥ 25), and within each of these areas, we tested the hypothesis that a higher percentage of channels correlated with the NLP model using a Chi-square proportion test (Fig. 2a)。Further, when examining whether
a channelresponded to NLP embeddings, we used apvalue threshold of 0.05 and performed Bonferroni correction for multiple comparisons over the NLP nodes, layers, and channel frequency bands (p < 0.05/768/13/5 = 1 × 10−6)。At last, we performed a control analysis with conservative Bonferroni correction to examine whether there were任何brain areas that showed a significantly higher percentage of neural-NLP-correlated channels.Based on single channels that responded to NLP embeddings (identified with Bonferroni correction for NLP nodes, layers, and frequency bands), we grouped them by brain areas and calculated the percentage of significant channels for each area.In this step, the dimensions of the variable transformed from areas × NLP nodes × NLP layers × frequency bands (17 × 768 × 13 × 5) to areas × 1 × 1 × 1 (17 × 1 × 1 × 1).Then we used a Chi-square proportion test with Bonferroni correction on the number of examined brain areas (p < 0.01/17 = 6 × 10−4, Figs. S3和S4)。Together, these conservative measures and corrections were made to ensure that the results obtained from recordings were robust.
Grouping brain areas based on hemispheres and participants’ handedness
Given that some participants in this study were left-handed, we further examined the neural responses to language based on the hemispheres from participants of different handedness.Interestingly, among the left-handed subjects, correlated channels from the left hemisphere were still significantly higher than those from the right hemisphere (Fig. S2b, two-side permutation test with combining frequency bands and layers,n = 104,,,,p < 10−4)。Hence, instead of grouping hemispheres based on the handedness, we combined all participants and separated channels by left and right hemispheres regardless of their handedness.
Control with the BERT (base) model and other NLP models
To ensure the observed neural-artificial correlation was generalizable across embeddings from different NLP models, we calculated the neural correlation to a pre-trained BERT (base) model45。The BERT (base) model was composed of 12 layers with similar architecture (transformer modules) to the GPT-2 model and was independently trained on different language corpus.The modules in the BERT model examined pairs of words including both previous and upcoming words.Due to this bidirectional pairing design, we separated language materials by sentences and obtained the embeddings of the words by inputting one sentence at a time.All the other procedures were exactly the same as that of the GPT-2 model.Note that the percentage of BERT-correlated channels after words were articulated was higher than using the GPT-2 model (Fig. S10b)。This was possible because the BERT model contained future word information from the same sentence, so the high percentage may come from articulation planning of future words in the sentence.
To confirm the generalizability of our results, in addition to these two NLP models, we examined other models that contain various numbers of parameters and are trained independently.They majorly composed four families of pre-trained models, including Bloom (with 560 million and 1 billion parameters), Falcon (1b and 40b), dolly (3b and 12b), and llama (3b, 7b, 13b, wizard-13b, 30b, chronos-33b).These models contain different numbers of layers and number of hidden embeddings per layer.To account for this variation, we took the first 100 principal components and then correlated them with the neural activity.We found that there was a significantly higher percentage of channels that correlated to all models examined (Fig. S12, Chi-square proportion test,p < 1 × 10−23) during both speaking and listening.Further, the percentage of correlated channels showed an increased trend with the size of NLP models (r > 0.80 andp < 2 × 10−3)。By extending NLP models with much diverse sizes and model families, we showed that all of them had significant higher percentage of correlated channels than chance, indicating the generalizability across various models.In other words, these findings appear to be robust and generalizable properties of neural activity.
Other controls of the robustness of the neural-NLP correlation
To further ensure that the observed neural-NLP correlations were robust and not driven by one participant or the length of the conversation, and they were not dependent on the intelligence of participants, we performed the following analyses.First, to ensure that the observed neural responses were not driven by one participant, we performed the same analysis but removed one participant from each iteration of the analysis, and examined if there was any significant change of the percentage of responding channels.The result is shown in Fig. S5。A one-way ANOVA was applied to examine whether removing a patient caused a significant change in the ratio.No removal of a participant resulted in a significant change in the correlated channel ratio.Second, we showed that the number of words that a participant spoke and listened to was not correlated with the percentage of responding channels.Specifically, we sorted participants based on the total number of words they spoke and listened to, and plotted the percentage of responding channels in Fig. S7。There was no correlation between the percentage of channels to the rank of words by participants (p = 0.95).This suggests that the sample size is not a factor contributing to our results, hence having a longer conversation is not expected to have an impact on the percentage of the responding channels.Finally, we performed full-scale IQ tests on 9 out of 14 participants.Based on this, we examined the percentage of channels that were significantly correlated to NLP embeddings for each of these participants and performed a linear regression to test whether there was any significant correlation between the neural activities and the IQs of the participants.In Fig. S6, each pair of bars represents a participant, and the location of these bars is plotted based on their IQ values.There is no significant correlation between the percentage of channels and participants’ IQ (p = 0.10 for speak, andp = 0.24 for listen).Similarly, we found that the percentage of channels was not dependent on the age and sex of the participants.Therefore, based on the number of participants we have, the percentage of responding channels seemed not impacted by their cognitive ability, their age or their sex.
In addition, to examine whether the neural-NLP correlation is modulated by only short or long durations of speech before transitions, we categorized word sequences into short or long durations using a 50-percentile threshold.Even after this separation, we found a significantly higher percentage of responding channels for both groups than chance (t-测试,p < 2 × 10−14for both speaking and listening), suggesting that the correlation is not caused by either short or long durations.
To address potential biases due to unequal word counts between speech production and comprehension, we matched the number of words in each condition for each participant by setting a cutoff equal to the minimum word count for speaking and listening.We found that there was a slight numerical difference in the percentage of significant channels between speech production (10%) and comprehension (13%) when word counts were matched, with conditions a substantially higher percentage of significant channels compared to chance (Chi-square proportion test, statistic > 100,p < 2 × 10−23for both conditions, Fig. S16)。These findings are largely consistent with our main analysis without word number matching (compared to 11% for production and 15% comprehension), indicating that the variation in word number does not drive the apparent difference between channels responding to speaking and listening.
Finally, to ensure the observed percentage of correlated channels was not limited only to Pearson correlations, we conducted additional control analysis by performing non-parametric hypothesis tests for rank correlations.Specifically, we used the Kendall Tau test and Spearmanrto examine the correlations between channels and NLP embeddings78,,,,79。Using the Kendall Tau test, we found there were 11.3% channels responding to NLP during language production, whereas there were 12.6% to comprehension (Chi-square proportion test, statistic = 150.0,p = 1.1 × 10−36for speaking;statistic = 230.1,p = 5.5 × 10−52for listen).A similar percentage of channels were selected using the Spearmanrtest (speaking: 11.8%, statistic = 187.7,p = 1.0 × 10−42;listening: 12.9%, statistic = 253.0,p = 5.8 × 10−57)。These together, indicate that the channel-NLP correlations were not limited to specific statistical methods, and were generalizable to various methods for correlation tests.
Neural activities correlate to turn-taking
We investigated the turn-taking properties of a conversation by examining whether any channels show significant changes in each frequency envelope during speaker–listener transitions.For transitions from comprehension to articulation, we averaged neural activities at each frequency band using a 0.5 s time window before the onset of the first word articulation;For transitions to comprehension, we averaged neural activities from a 0.5 s window after the onset of the first word perception.The average activities at each frequency band were compared to the activities during established comprehension using at-test from a Scipy package (ttest_ind) and the threshold ofpvalue to determine whether the activities changed significantly was set to be 0.05.Because speaker–listener transitions had much longer intervals compared to a word being articulated or perceived, we did not perform de-autocorrelation for this analysis.Similar to the method in the previous section, we selected the band that showed the lowestpvalues and attributed each channel responding to transitions with the selected frequency band.To examine whether the number of channels was significantly different from the speaker–listener transition to the listener–speaker transition, we used two neural populations with each including all channels and we labeled each channel by whether it was significantly responding to one direction of the transitions or the other.
Next, we used these populations to perform a two-side permutation test: We concatenated the two populations and randomly sampled from the mixture for a given number of times, with each sampling containing the same number of observations as the original two populations.Then for each sampling, the absolute difference between the average values of the two sets of random sampling was calculated, and this value was compared to the absolute difference from the actual populations.After repeating these steps of sampling, thepvalue was then defined as the number of times when the difference of random sampling from the mixed population was greater than that from the actual population, divided by the number of drawings.报告摘要
Further information on research design is available in theÂ
Nature Portfolio Reporting Summary链接到本文。数据可用性
Deidentified recording data is on the Data Archive BRAIN Initiative (DABI,
https://dabi.loni.usc.edu/) in the iEEG BIDS format.The raw neural recording data and processed data have been deposited to the DABI database under accession code M6RES1N4MVA3 (https://doi.org/10.18120/5jg5-j555)。Source data for all figures in the main manuscript and Supplementary Fig. S2–S18are provided with this paper. 源数据are provided with this paper.
Code availability
The Python code of the analysis of this work can be found in GitHub:https://github.com/jill620/sEEG_conversation。参考
Brodbeck, C. & Pylkkanen, L. Language in context: characterizing the comprehension of referential expressions with MEG.
神经图像147 , 447–460 (2017).文章
一个 PubMed一个 Google Scholar一个 Xu, J., Kemeny, S., Park, G., Frattali, C. & Braun, A. Language in context: emergent features of word, sentence, and narrative comprehension.神经图像
25, 1002–1015 (2005). 文章一个
PubMed一个 Google Scholar一个 Hagoort, P., Hald, L., Bastiaansen, M. & Petersson, K. M. Integration of word meaning and world knowledge in language comprehension.科学
304, 438–441 (2004). 文章一个
广告一个 CAS一个 PubMed一个 Google Scholar一个 Heim, S. & Alter, K. Prosodic pitch accents in language comprehension and production: ERP data and acoustic analyses.Acta Neurobiol.
经验。66 , 55–68 (2006).文章
一个 Google Scholar一个 Droge, A., Fleischer, J., Schlesewsky, M. & Bornkessel-Schlesewsky, I. Neural mechanisms of sentence comprehension based on predictive processes and decision certainty: electrophysiological evidence from non-canonical linearizations in a flexible word order language.脑部
1633年, 149–166 (2016). 文章一个
PubMed一个 Google Scholar一个 Boulenger, V., Hoen, M., Jacquier, C. & Meunier, F. Interplay between acoustic/phonetic and semantic processes during spoken sentence comprehension: an ERP study.Brain Lang.
116, 51–63 (2011). 文章一个
PubMed一个 Google Scholar一个 Bai, F., Meyer, A. S. & Martin, A. E. Neural dynamics differentially encode phrases and sentences during spoken language comprehension.Plos Biol。
20, e3001713 (2022). 文章一个
CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个 Lee, D. K. et al.Neural encoding and production of functional morphemes in the posterior temporal lobe.
纳特。社区。 9, 1877 (2018).
文章一个 广告一个 PubMed一个 PubMed Central一个 Google Scholar一个
Bohland, J. W. & Guenther, F. H. An fMRI investigation of syllable sequence production.神经图像 32, 821–841 (2006).
文章一个 PubMed一个 Google Scholar一个
Levinson, S. C. & Torreira, F. Timing in turn-taking and its implications for processing models of language.正面。Psychol。 6, 731 (2015).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Stivers, T. et al.Universals and cultural variation in turn-taking in conversation.Proc。纳特。学院。科学。美国 106, 10587–10592 (2009).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Maguire, E. A. Studying the freely-behaving brain with fMRI.神经图像 62, 1170–1176 (2012).
文章一个 PubMed一个 Google Scholar一个
Castellucci, G. A. et al.A speech planning network for interactive language use.自然 602, 117–122 (2022).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Bögels, S., Magyari, L. & Levinson, S. C. Neural signatures of response planning occur midway through an incoming question in conversation.科学。代表。 5, 1–11 (2015).
文章一个 Google Scholar一个
Ferreira, F. & Swets, B. How incremental is language production?Evidence from the production of utterances requiring the computation of arithmetic sums.J. Mem.朗。 46, 57–84 (2002).
文章一个 Google Scholar一个
Schilbach, L. et al.Toward a second-person neuroscience1.行为。脑科学。 36, 393–414 (2013).
文章一个 PubMed一个 Google Scholar一个
Zada, Z. et al.A shared model-based linguistic space for transmitting our thoughts from brain to brain in natural conversations.神经元 112, 3211–3222.e5 (2024).
Fedorenko, E. et al.Neural correlate of the construction of sentence meaning.Proc。纳特。学院。科学。美国 113, E6256–E6262 (2016).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Nelson, M. J. et al.Neurophysiological dynamics of phrase-structure building during sentence processing.Proc。纳特。学院。科学。美国 114, E3669–E3678 (2017).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Fedorenko, E., Nieto-Castanon, A. & Kanwisher, N. Lexical and syntactic representations in the brain: an fMRI investigation with multi-voxel pattern analyses.神经心理学 50, 499–513 (2012).
文章一个 PubMed一个 Google Scholar一个
Humphries, C., Binder, J. R., Medler, D. A. & Liebenthal, E. Syntactic and semantic modulation of neural activity during auditory sentence comprehension.J. Cogn。Neurosci。 18, 665–679 (2006).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Silbert, L. J., Honey, C. J., Simony, E., Poeppel, D. & Hasson, U. Coupled neural systems underlie the production and comprehension of naturalistic narrative speech.Proc。纳特。学院。科学。美国 111, E4687–E4696 (2014).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Heim, S. & Friederici, A. D. Phonological processing in language production: time course of brain activity.NeuroReport 14, 2031–2033 (2003).
文章一个 PubMed一个 Google Scholar一个
Jang, G. et al.Everyday conversation requires cognitive inference: neural bases of comprehending implicated meanings in conversations.神经图像 81, 61–72 (2013).
文章一个 PubMed一个 Google Scholar一个
Feng, W. et al.Effects of contextual relevance on pragmatic inference during conversation: an fMRI study.Brain Lang. 171, 52–61 (2017).
文章一个 PubMed一个 Google Scholar一个
Schrimpf, M. et al.The neural architecture of language: Integrative modeling converges on predictive processing.Proc。纳特。学院。科学。美国 118, e2105646118 (2021).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kuhlen, A. K., Allefeld, C., Anders, S. & Haynes, J.-D.Towards a multi-brain perspective on communication in dialogue.在Cognitive Neuroscience of Natural Language Use182–200 (Cambridge University Press, 2015).
Bögels, S. & Levinson, S. C. The brain behind the response: Insights into turn-taking in conversation from neuroimaging.res。朗。Soc。相互影响。 50, 71–89 (2017).
文章一个 Google Scholar一个
Ghilzai, S. A. & Baloch, M. Conversational analysis of turn taking behavior and gender differences in multimodal conversation.欧元。学院。res。 3, 10100–10116 (2015).
Openai。Introducing ChatGPT.https://openai.com/blog/chatgpt(2022)。
Zhang,Y。等。DIALOGPT: Large-Scale Generative Pre-training for Conversational Response Generation.Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System DemonstrationsOnline 270–278 (2020).
Wolf, T., Sanh, V., Chaumond, J. & Delangue, C. Transfertransfo: a transfer learning approach for neural network based conversational agents.arxiv preprint arXiv:1901.08149(2019)。
Budzianowski, P. & Vulić, I. Hello, It‘s GPT-2 - How Can I Help You?Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems.Proceedings of the 3rd Workshop on Neural Generation and Translation香港。15-22 (2019).
Vig, J. & Belinkov, Y. Analyzing the structure of attention in a transformer language model.Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLPFlorence, Italy.(2019)。
Belinkov, Y. & Glass, J. Analysis methods in neural language processing: a survey.反式。联合。计算。语言学家。 7, 49–72 (2019).
文章一个 Google Scholar一个
Manning, C. D., Clark, K., Hewitt, J., Khandelwal, U. & Levy, O. Emergent linguistic structure in artificial neural networks trained by self-supervision.Proc。纳特。学院。科学。美国 117, 30046–30054 (2020).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Goldstein, A. et al.Shared computational principles for language processing in humans and deep language models.纳特。Neurosci。 25, 369–380 (2022).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kell, A. J. E., Yamins, D. L. K., Shook, E. N., Norman-Haignere, S. V. & McDermott, J. H. A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy.神经元 98, 630–644.e16 (2018).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Caucheteux, C. & King, J.-R.Brains and algorithms partially converge in natural language processing.社区。生物。5.1, 134 (2022).
Goldstein, A. et al.Alignment of brain embeddings and artificial contextual embeddings in natural language points to common geometric patterns.纳特。社区。 15, 2768 (2024).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Kumar,S。等。Shared functional specialization in transformer-based language models and the human brain.纳特。社区。 15, 5523 (2024).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Radford, A. et al.语言模型是无监督的多任务学习者。OpenAI Blog 1, 9 (2019).
Vaswani, A. et al.注意就是您所需要的。在神经信息处理系统的进步,卷。30 (Curran Associates, Inc., 2017).
Wolf, T. et al.Huggingface’s transformers: state-of-the-art natural language processing.arxiv preprint arXiv:1910.03771(2019)。
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding.在Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171-4186 (Association for Computational Linguistics, Minneapolis, Minnesota, 2019).https://aclanthology.org/N19-1423。Futrell, R., Gibson, E. & Levy, R. P. Lossy-context surprisal: an information-theoretic model of memory effects in sentence processing.
Cogn。科学。 44, e12814 (2020).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Ho, Q. T., Nguyen, T. T., Khanh Le, N. Q. & Ou, Y. Y. FAD-BERT: improved prediction of FAD binding sites using pre-training of deep bidirectional transformers.计算。生物。医学 131, 104258 (2021).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Huang, K., Hussain, A., Wang, Q.-F.& Zhang, R. Deep learning: fundamentals, theory and applications.在Cognitive Computation Trends(Springer International Publishing, 2019).
Chowdhary, K. R.人工智能的基础pp. 603-649.New Delhi: Springer India.(2020)。
Koehn, P.神经机器翻译(Cambridge University Press, 2020).
Hmamouche, Y., Prevot, L., Magalie, O. & Thierry, C. Identifying causal relationships between behavior and local brain activity during natural conversation.在Proc。 Interspeech 2020101–105 (ISCA, 2020).
van Berkum, J. J. A. The electrophysiology of discourse and conversation.在The Cambridge handbook of psycholinguistics(eds. Spivey, M., McRae, K. & Joanisse, M.) 589–612,https://doi.org/10.1017/CBO9781139029377.031(2012年)。
Heilbron, M., Armeni, K., Schoffelen, J.-M., Hagoort, P. & De Lange, F. P. A hierarchy of linguistic predictions during natural language comprehension.Proc。纳特。学院。科学。美国 119, e2201968119 (2022).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Fedorenko, E., Behr, M. K. & Kanwisher, N. Functional specificity for high-level linguistic processing in the human brain.Proc。纳特。学院。科学。美国 108, 16428–16433 (2011).
文章一个 广告一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Palva, S. et al.Distinct gamma-band evoked responses to speech and non-speech sounds in humans.J. Neurosci。 22, RC211 (2002).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Grande, M. et al.From a concept to a word in a syntactically complete sentence: an fMRI study on spontaneous language production in an overt picture description task.神经图像 61, 702–714 (2012).
文章一个 PubMed一个 Google Scholar一个
Malik-Moraleda, S. et al.An investigation across 45 languages and 12 language families reveals a universal language network.纳特。Neurosci。 25, 1014–1019 (2022).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
AbdulSabur, N. Y. et al.Neural correlates and network connectivity underlying narrative production and comprehension: a combined fMRI and PET study.皮质 57, 107–127 (2014).
文章一个 PubMed一个 Google Scholar一个
Fedorenko, E., Hsieh, P.-J., Nieto-Castañón, A., Whitfield-Gabrieli, S. & Kanwisher, N. New method for fMRI investigations of language: defining ROIs functionally in individual subjects.J. Neurophysiol. 104, 1177–1194 (2010).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Okobi, D. E. Jr, Banerjee, A., Matheson, A. M., Phelps, S. M. & Long, M. A. Motor cortical control of vocal interaction in neotropical singing mice.科学 363, 983–988 (2019).
文章一个 广告一个 CAS一个 PubMed一个 Google Scholar一个
Bain, M., Huh, J., Han, T. & Zisserman, A. Whisperx: time-accurate speech transcription of long-form audio.(INTERSPEECH 2023, 2023).
Mathews, P.Sample Size Calculations: Practical Methods for Engineers and Scientists(Mathews Malnar and Bailey, 2010).
Lachin, J. M. Introduction to sample size determination and power analysis for clinical trials.控制。临床试验 2, 93–113 (1981).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Postelnicu, G., Zollei, L. & Fischl, B. Combined volumetric and surface registration.IEEE Trans。医学成像 28, 508–522 (2009).
文章一个 PubMed一个 Google Scholar一个
Zollei, L., Stevens, A., Huber, K., Kakunoori, S. & Fischl, B. Improved tractography alignment using combined volumetric and surface registration.神经图像 51, 206–213 (2010).
文章一个 PubMed一个 Google Scholar一个
Fischl,B。Freesurfer。神经图像 62, 774–781 (2012).
文章一个 PubMed一个 Google Scholar一个
Dykstra, A. R. et al.Individualized localization and cortical surface-based registration of intracranial electrodes.神经图像 59, 3563–3570 (2012).
文章一个 PubMed一个 Google Scholar一个
Fischl,B。等。Automatically parcellating the human cerebral cortex.Cereb。皮质 14, 11–22 (2004).
文章一个 PubMed一个 Google Scholar一个
Felsenstein, O. & Peled, N.MMVT—Multi-modality Visualization Tool(GitHub Repository)https://github.com/pelednoam/mmvt(2017)。
Reuter, M., Rosas, H. D. & Fischl, B. Highly accurate inverse consistent registration: a robust approach.神经图像 53, 1181–1196 (2010).
文章一个 PubMed一个 Google Scholar一个
Soper, D. J. et al.Modular pipeline for reconstruction and localization of implanted intracranial ECoG and sEEG electrodes.PLOS一个 18, e0287921 (2023).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Oostenveld, R., Fries, P., Maris, E. & Schoffelen, J.-M.FieldTrip: open source software for advanced analysis of MEG, EEG, and invasive electrophysiological data.计算。Intell。Neurosci。 2011, 1–9 (2011).
文章一个 Google Scholar一个
Janca, R. et al.Detection of interictal epileptiform discharges using signal envelope distribution modelling: application to epileptic and non-epileptic intracranial recordings.脑托格格。 28, 172–183 (2015).
文章一个 PubMed一个 Google Scholar一个
Linkenkaer-Hansen, K., Nikouline, V. V., Palva, J. M. & Ilmoniemi, R. J. Long-range temporal correlations and scaling behavior in human brain oscillations.J. Neurosci。 21, 1370–1377 (2001).
文章一个 CAS一个 PubMed一个 PubMed Central一个 Google Scholar一个
Pritchard, W. S. The brain in fractal time: 1/f-like power spectrum scaling of the human electroencephalogram.int。J. Neurosci。 66, 119–129 (1992).
文章一个 CAS一个 PubMed一个 Google Scholar一个
Cochrane, D. & Orcutt, G. H. Application of least squares regression to relationships containing auto-correlated error terms.J. Am。统计联合。 44, 32–61 (1949).
Sun, Z., Zemel, R. & Xu, Y. A computational framework for slang generation.反式。联合。计算。语言学家。 9, 462–478 (2021).
文章一个 Google Scholar一个
Kendall, M. G. A new measure of rank correlation.Biometrika 30, 81–93 (1938).
文章一个 Google Scholar一个
Zwillinger, D. & Kokoska, S.CRC Standard Probability and Statistics Tables and Formulae(CRC Press, 1999).
致谢
J.C. is supported by the Mussallem Transformative Award and the American Association of University Women, Z.M.W.is supported by NIH R01DC019653 and NIH U01NS123130, and S.S.C., A.E.H., A.C.P., D.J.S.are supported by NIH U01NS098968.
竞争利益
S.S.C.
is a founder and advisor to Beacon Biosignals.其余的作者宣布没有竞争利益。
同行评审
同行评审信息
自然通讯thanks the anonymous reviewer(s) for their contribution to the peer review of this work.提供同行评审文件。
附加信息
Publisher’s note关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
补充信息
权利和权限
开放访问本文在Creative Commons Attribution-Noncormercial-Noderivatives 4.0国际许可下获得许可,该许可允许任何非商业用途,共享,分发和复制以任何媒介或格式的形式,只要您提供适当的原始作者和来源的信用,请符合原始作者和来源,并提供了与Creative Commons的链接,并指示您是否修改了许可的材料。您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Cai, J., Hadjinicolaou, A.E., Paulk, A.C.
等。Natural language processing models reveal neural dynamics of human conversation.纳特社区16 , 3376 (2025).https://doi.org/10.1038/s41467-025-58620-w
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41467-025-58620-w