
- 文章
- 开放访问
- 发布:
- Mike Schaekermann一个 orcid:orcid.org/0000-0002-1735-96801一个 NA1,,,,Anil Palepu
- 1一个 NA1,,,,哈立德·萨博(Khaled Saab)
- 1,,,,扬·弗雷伯格(Jan Freyberg)
- 1,,,,ryutaro tanno
- 一个 orcid:orcid.org/0000-0002-8107-67302,,,,艾米·王
- 1,,,,布伦纳·李
- 1,,,,穆罕默德·阿敏
- 1,,,,阳
- 2,,,,Elahe Vedadi
- 1,,,,Nenad Tomasev
- 一个 orcid:orcid.org/0000-0003-1624-02202,,,,Shekoofeh Azizi
- 一个 orcid:orcid.org/0000-0002-7447-60312,,,,卡兰·辛哈尔(Karan Singhal)
- 一个 orcid:orcid.org/0009-0001-0286-609x1,,,,Le Hou
- 1,,,,阿尔伯特·韦伯森
- 2,,,,卡维塔·库尔卡尼(Kavita Kulkarni)
- 1,,,,S. Sara Mahdavi
- 2,,,,克里斯托弗·森林
- 1,,,,Juraj Gottweis
- 1,,,,乔尔·巴拉尔(Joelle Barral)
- 2,,,,凯瑟琳·周
- 1,,,,Greg S. Corrado
- 1,,,,Yossi Matias
- 一个 orcid:orcid.org/0000-0003-3960-60021,,,,Alan Karthikesalingam
- 一个 orcid:orcid.org/0009-0000-4958-59761一个 NA2和…
- Vivek Natarajan
- 一个 orcid:orcid.org/0000-0001-7849-20741一个 NA2一个 自然((
1
,,,,2。能够进行诊断对话的人工智能(AI)系统可以提高可访问性和护理质量。但是,近似临床医生的专业知识是一个重大的挑战。在这里,我们介绍了艾米(Amie)(Articulate Medical Intelligence Explorer),这是一种基于诊断对话的大型语言模型(LLM)的AI系统。AMIE使用基于自我播放的3模拟环境具有自动反馈,以跨越疾病,专业和环境进行扩展学习。我们设计了一个框架,用于评估临床上有意义的性能轴,包括历史记录,诊断准确性,管理,沟通技巧和同理心。我们将AMIE的表现与初级保健医生的表现进行了比较,在与经过验证的患者动作器的随机双盲跨界研究中,类似于客观结构化临床检查4,,,,5。该研究包括加拿大,英国和印度提供者的15个病例场景,与AMIE相比,20位初级保健医生以及专业医生和患者手机的评估。根据专业医生,艾米(Amie)在32个轴中显示出更高的诊断准确性和出色的性能,根据患者角色,在26个轴上有25个轴。我们的研究有几个局限性,应谨慎解释。临床医生使用同步文本聊天,这允许大规模的LLM患者互动,但这在临床实践中并不熟悉。尽管需要在将AMIE转换为现实世界中需要进一步的研究,但结果代表了对话诊断AI的里程碑。
别人观看的类似内容
主要的
医生与患者之间的对话是有效和富有同情心的护理的基础。医学访谈被称为医生可用的最强大,最敏感,最通用的仪器2。在某些情况下,据信仅通过临床历史记录来进行60%的诊断6。医师的患者对话超出了历史和诊断的范围,这是一种建立融洽关系和信任的复杂互动,是满足健康需求的工具,可以使患者能够做出明智的决定,以解决他们的偏好,期望和疑虑7。虽然临床医生之间的沟通技巧差异很大,但训练有素的专业人员可以在临床历史记录和更广泛的诊断对话方面发挥相当大的技能。但是,获得此专业知识仍然是情节性和全球稀缺8。
通用大语模型(LLM)的最新进展9,,,,10,,,,11已经表明,人工智能(AI)系统具有计划,推理并结合相关背景以进行自然主义对话的能力。这一进展为重新考虑AI在医学上的可能性的机会提供了完全互动对话AI的发展。这种医学AI系统将了解临床语言,智能地获取不确定性的信息,并与患者及其照顾患者进行自然,诊断有用的医学对话。能够进行临床和诊断对话的AI系统的潜在现实世界实用程序广泛,这种能力的发展可能会改善获得诊断和预后的专业知识,从而提高了护理的质量,一致性,可用性,可用性和可负担性。以卫生公平为中心的方法将这种技术集成到现有工作流程中,这意味着在发展,实施和政策阶段工作,可能有可能帮助实现更好的健康成果(尤其是对于面临医疗保健差异的人群)。
但是,虽然LLM已被证明可以编码临床知识,并已证明能够高度准确12,,,,13,,,,14,他们的对话能力是针对临床医学以外的领域量身定制的15,,,,16。LLMS的早期工作12,,,,13,,,,14,,,,17,,,,18尚未严格检查AI系统的临床历史记录记录和诊断对话能力,也没有通过与执业通才医生的广泛能力相比,将其进行了背景。
临床历史记录和诊断对话(临床医生得出诊断和管理计划)代表了一项复杂的技能1其最佳行为高度取决于上下文。因此,需要进行多个评估轴以评估诊断对话的质量,包括引起的历史的结构和完整性,诊断准确性,管理计划的适当性及其理由以及以患者为中心的考虑因素,例如建立关系,对个人和沟通效率的尊重19。如果在医学中实现LLM的对话潜力,那么对于诸如此类特征的医学AI系统的开发和评估是有重要的,这是临床医生和患者之间的历史和诊断对话所独有的,这是一个重要的未满足的需求。
在这里,我们详细介绍了临床记录,诊断推理和沟通功效的对话医学AI系统的进度。我们还概述了未来研究的一些关键局限性和方向。
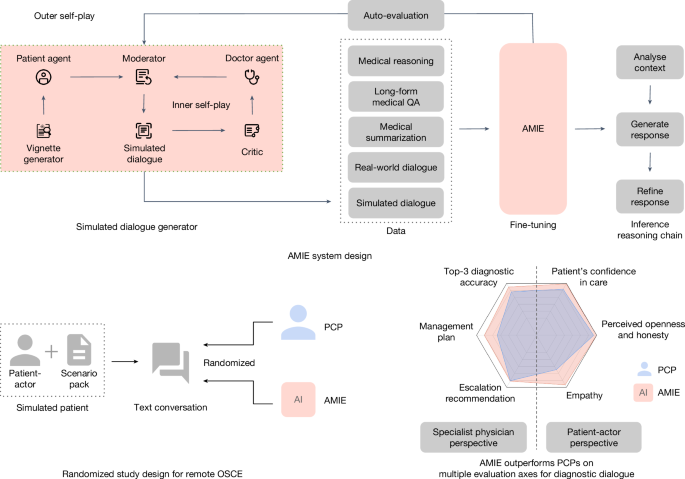
我们的主要贡献(图。1)在这里总结。我们首先介绍了AMIE(Articulate Medical Intelligence Explorer),这是一种基于LLM的AI系统,可针对临床历史记录和诊断对话进行优化。为了扩展AMIE在多种专业和场景中,我们开发了一种基于自我播放的诊断对话环境,具有自动反馈机制,以丰富和加速其学习过程。我们还引入了推理时间链策略,以提高AMIE的诊断准确性和对话质量。然后,我们开发了一个试点评估标题,以评估诊断性对话医学AI的历史记录,诊断推理,沟通技巧和同理心,包括以临床医生为中心和以患者为中心的指标。接下来,我们设计并进行了一项盲目的,远程客观的结构化临床检查(OSCE)研究(图。2)使用加拿大,英国和印度的临床提供者的15个病例场景,使AMIE与初级保健医生(PCP)进行随机和平衡的比较时,在与经过验证的患者活动器进行咨询时。与PCP相比,AMIE表现出较高的诊断精度,如通过各种措施评估(例如,鉴别诊断的TOP-1和TOP-3精度(DDX)列表)。从专家医师的角度来看,在32个评估轴中,有30个,从患者演员的角度来看,在26个评估轴中,AMIE的额定值优于PCP,而其余的则是不属于PCP的。最后,我们进行了一系列消融,以进一步理解和表征AMIE的能力,突出了重要的局限性,并提出了AMIE现实世界中临床翻译的关键下一步。

艾米(Amie)是一种对对话的对话医学AI,用于诊断对话。它是通过现实世界和模拟的医学对话的结合以及各种医疗推理,提问(QA)和摘要数据集的组合进行了微调的。值得注意的是,我们设计了一个基于自我播放的对话环境,具有自动反馈机制,以扩展各种医学环境和专业的AMIE能力。具体而言,这种迭代的自我完善过程由两个自我播放循环组成:(1)内部自我播放循环,艾米(Amie)利用艾米(Amie)在上下文中利用了信誉批评家的反馈来完善其与AI患者剂的模拟对话的行为;(2)外部自我播放循环,其中将一组精制的模拟对话集成到了随后的微调迭代中。在在线推论期间,艾米(Amie)采用了反合策略来逐步完善其反应,以当前的对话为条件,以在每个对话转弯中对患者进行准确而扎根的答复。我们通过文本聊天界面设计并进行了一个盲目的远程OSCE,并通过经过验证的患者演员与AMIE或PCP进行交互。在多个轴上,对应于专业医师(32个中的30个)和患者演员(26个)观点,AMIE被评为优于PCP,而其余的则不属于PCP。

PCP和AMIE(按随机顺序)通过在线多转变同步文本聊天和QuestionNaire提供答案,该虚拟远程OSCE具有模拟患者的虚拟远程OSCE。然后,PCP和AMIE均由患者和专业医生评估。
我们的研究具有重要的局限性,最值得注意的是,我们利用了文本聊天界面,尽管该界面使患者与专门用于诊断对话的患者和LLMS之间有潜在的大规模相互作用,但对PCP却不熟悉远程咨询。因此,我们的研究不应被视为(Tele)医学中常规实践的代表。
鉴别诊断精度
AMIE比PCP具有更高的鉴别诊断精度
AMIE的诊断准确性评估为高于PCP的诊断精度。数字3显示顶部kAMIE和PCP的准确性,考虑到与地面诊断的匹配(图。3a)并与所接受差异上的任何项目匹配(图。3b)。艾米显示出明显更高的顶部k与所有值的PCP相比,精度k((p<0.05)。请注意,与AMIE不同,PCP并不总是在其DDXS中提供十个诊断(Min = 3,平均值= 5.36)。此外,我们通过改变确定匹配项的标准(即需要精确匹配而不是高度相关的诊断),对AMIE和PCP之间的DDX准确性进行了比较。补充图中描述的结果。2在各种匹配标准中,进一步证实了Amie的出色DDX性能。

,,,,b,AMIE和PCP TOP-kDDX精度是由三名专家的多数投票确定的,在159个方案中进行了对基地诊断的比较(一个)以及公认差异中的所有诊断(b)。中心线对应于平均顶部k精度,阴影区域指示从双面引导测试计算出95%的置信区间(n= 10,000)。全部 -kAMIE和PCP DDX精度之间的差异很大,并且pFDR校正后<0.05。FDR调整后p地面比较的值为:0.0017(k= 1),0.0002(k= 2),0.0002(k= 3),0.0002(k= 4),0.0002(k= 5),0.0003(k= 6),0.0003(k= 7),0.0003(k= 8),0.0002(k= 9)和0.0002(k= 10)(10)(一个)。FDR调整后p接受的差异比较值为:0.0001(k= 1),0.0001(k= 2),0.0002(k= 3),0.0002(k= 4),0.0001(k= 5),0.0001(k= 6),0.0001(k= 7),0.0001(k= 8),0.0001(k= 9)和0.0001(k= 10)(10)(b)。
非疾病状态和疾病状态的准确性
AMIE和PCPS进行的十种场景旨在主要描述没有有关诊断的新的患者(例如,对解决方案的解决方案诊断,或者对先前已知的胃食管反联络 - 疾病 - 疾病 - 疾病诱发的胸部疼痛的复发)。这是从心血管,胃肠病学,内科,神经病学和呼吸系统的两种情况。在这里,我们绘制了顶部kDDX的准确性,由这些非疾病状态案件的三位专家的多数投票评价。尽管我们的结果在统计学上并不重要,因为它们仅包括十个场景,但AMIE似乎在这些主要的负面情况下保持了相同的表现趋势(扩展数据图。2)。AMIE在149个主要呈阳性疾病状态的情况下具有较高的DDX准确性(其中只有三种场景具有非疾病状态的基础真相)。
专业的精度
扩展数据图。3说明了AMIE和PCP在我们研究中涵盖的六个医学专业中所达到的DDX准确性。我们观察到,除妇产科和妇科/泌尿外科外,AMIE的表现符合或超过所有专业的PCP性能,其呼吸道和内科专业的最明显改善。
按位置准确
我们观察到,与印度OSCE实验室颁布的咨询相比,在加拿大OSCE实验室进行的咨询中,AMIE和PCP都具有更高的诊断准确性。但是,差异在统计学上并不显着,在加拿大和印度OSCE实验室制定的40个场景的子集中,AMIE和PCP的性能都是等效的(扩展数据图。4)。获取信息的效率
自动评估精度
我们使用与图2中相同的步骤使用基于模型的DDX自动化器来重现DDX精度分析。
3。尽管计算的准确性值差异很小,但通过自动评估器与专家评估相结合的总体性能趋势与专家评估很好地对齐,如扩展数据图所示。5a,b。此外,我们提出了一个完全模拟的消融测试,对不同的患者行为进行了测试(补充图。3),这表明艾米(Amie)对许多不同的患者人物来说是强大的,尽管在采访英语识字率低的患者时,DDX的表现降低了。隔离性能的来源
为了研究AMIE在图2中观察到的优越的DDX性能。
3源于改进的信息获取或从更好的诊断推理能力中,我们根据使用DDX Auto-Evaluator从相应的PCP咨询中产生的AMIE诊断对AMIE的诊断进行了比较。扩展数据图中描述的结果。5C,d揭示了明显相似的DDX性能,表明诊断性能是一致的,无论AMIE是从其自己的对话中处理的信息还是PCP对话中的信息。两种方法都显着优于PCP产生的DDX。这些结果表明,AMIE大约等同于信息获取时的PCP,但在解释该信息以产生准确或完整的DDX时要比PCP更好。
信息获取效率
尽管与PCP相比,AMIE显示出更大的详细性,但就咨询过程中其响应中产生的单词总数而言,对话转弯的数量和来自患者演员的单词数量在两个OSCE代理中相似,如扩展数据图中所示。6aâc。这表明AMIE和PCP都在遭遇期间从患者那里获得了类似的信息。为了调查AMIE或PCP在收集足够信息以制定正确诊断时的有效效率,我们在各种回合计数中截断了对话,并使用AMIE根据这些部分对话来生成DDXS。扩展数据的结果图。6d,e说明AMIE和PCP都能够获取在对话的早期阶段(前十回合)中制定准确差异所需的信息。在所有对话长度上的表现可比,AMIE和PCP似乎都没有在信息获取的速度,效率或诊断效用方面具有显着优势。
对话质量
AMIE超过对话质量的PCP
使用自动评估的患者演员评级,专家评级和输出评估对话质量。补充表5显示了与来自AMIE和PCP的同一模拟患者进行的两个示例咨询。
患者演员评分
数字4呈现患者演员在与OSCE代理商进行磋商后评估的各种对话素质。总体而言,AMIE的咨询得到了明显更好的评分(p患者动作器比在26个轴中有25个轴的PCP的患者使用的<0.05)。以患者为中心的交流最佳实践(PCCBP)轴之一,未检测到评分的显着差异19,承认错误(n= 46)。对于此标准,排除的数量大大较高,因为仅当OSCE代理商犯错并在对话中指出时,该问题才适用。

专业医师评级
专业医师评估了对话质量以及对Questionnaire在其领域专业知识中的场景的反应(图。5)。同样,在32个评估轴中的30个PCP的专家中,AMIE的回答得到了明显的评价,而专家则更喜欢对PCP的AMIE咨询,诊断和管理计划。对于这组评估,AMIE和PCP之间的专家评级差异具有统计学意义(p<0.05)。请参阅补充信息部分 7对于每个情况,三个专家评估者之间的评价者间可靠性。在诊断和管理标题中,没有检测到两个轴的评分显着差异,即适当的升级建议,尽管没有排除在外(没有排除)(n= 159)。图5:专业医师评级。

模拟对话对话质量
我们利用基于模型的自我评估策略(补充表2)从临床检查技能(PACES)的实际评估中对四个评估轴的对话进行评分20,并验证了这些自动评估评级是准确的,并且与专家评分良好(补充图。1B)。比较自我播放过程之前和之后产生的模拟对话,我们发现内部自我播放循环改善了这些轴上的模拟对话质量,如补充图中所示。1C。
讨论
在这项研究中,我们介绍了AMIE,这是一种基于LLM的AI系统,针对具有诊断推理功能的临床对话进行了优化。我们将AMIE的咨询与PCP进行的使用随机的双盲跨界研究与OSCE风格的人类模拟患者进行了比较。值得注意的是,我们的研究并非旨在代表传统OSCE评估,远程或远程医疗咨询实践的临床公约,也不是临床医生通常使用文本和聊天消息与患者进行交流的方式。相反,我们的评估反映了人们当今与LLM互动的最常见方式,利用了AI系统进行远程诊断对话的潜在可扩展和熟悉的机制。在这种情况下,我们观察到,专门针对该任务优化的AI系统AMIE在沿多个临床上有意义的咨询质量轴上进行评估时,在模拟诊断对话上的PCP优于PCP。
诊断性能
与董事会认证的PCP相比,AMIE提供的DDX更准确,更完整,当时两者均由专业医生评估。先前的研究表明,在特定的狭窄任务中,AI系统可能匹配或超过人类的诊断性能21,,,,22在回顾性评估中。但是,这些情况通常涉及AI和医生解释相同的固定输入(例如,确定医疗图像中特定发现的存在)。我们的研究更具挑战性,因为它要求AI系统通过对话积极获取相关信息,而不是依靠人类努力整理的临床信息23。因此,该系统的下游DDXS不仅取决于其诊断推理能力,还取决于通过自然对话和建立融洽关系在不确定性下收集的信息质量。
我们的结果表明,在模拟咨询过程中,AMIE在启发相关信息方面与PCP一样熟练,并且如果给出相同数量的获取信息,则比PCP更准确。这一发现证实了LLM可能能够在具有挑战性的情况下与医生相同的临床信息产生更完整的DDX的其他工作22。尽管在这项研究中没有探讨,但AMIE的辅助表现代表了未来研究的有趣且重要的途径,尤其是考虑到专家监督对AI系统在安全至关重要环境(例如医学)中的现实重要性。
我们的研究利用了各种模拟患者,包括在加拿大和印度接受培训的演员,以及各种专业的情景。这使我们能够探索性能如何通过专业沿多轴变化,以及派生和制定场景的位置。虽然我们观察到PCP和AMIE在胃肠病学和内部医学方案中的表现都比其他专业差(扩展数据图。3),该研究不是为了比较不同专业主题和位置之间的性能,我们不能排除某些专业中的场景可能比其他专业更难。
会话性能
患者演员和专家评估者都评估了AMIE的性能高于与同理心和沟通技巧相关的指标的PCP。这些轴包括评估的大多数维度。这一总体发现与先前的研究一致,在该研究中,LLM的回应比临床医生到Reddit上的健康问题的回答更加移人24。但是,由于研究设计的差异,该研究的发现不能直接推广到我们的环境。具体而言,先前的工作并未涉及与同一患者进行多转弯对话的前瞻性模拟,对医师和AI系统的直接,随机比较。在这两种情况下,缺乏基于语音的和非语言的视觉交流可能对临床医生来说是不公平的劣势。
本研究中使用的基于文本的聊天界面引入了优势和缺点。当今的人们最常通过同步文本聊天界面与LLMS互动25,并且患者经常使用患者门户向其提供者发送消息。因此,我们选择了这种交互模式作为LLM的代表接口来执行多转交谈,从而相应地调整了虚拟OSCE框架。尽管这两者都仅限于同步文本聊天时,虽然这可以公平地比较LLMS和临床医生之间的诊断对话,但重要的是要承认我们的实验并未模仿实际临床实践中的诊断对话的预期质量(包括远程医疗氨基氨酸)。医师可能更习惯于通过电话或视频咨询而不是同步的文本聊天沟通来进行历史记录和诊断对话26。取而代之的是,临床医生更常用文本与患者沟通以寻求情节或异步需求,例如处方补充或有关特定测试结果的沟通27。因此,医师可能更熟悉文本/SMS或电子邮件,而不是我们在本研究中使用的同步文本聊天媒体。在文本/短信和电子邮件中,自然沟通和善解人意的惯例和期望可能不同28。我们研究中的PCP可能尚未习惯于该环境,并且如果接受特定的培训计划(与AMIE的培训过程相似),则可能表现不同。参加该研究的临床医生在评估开始之前与我们的同步文本界面进行了两次预备试点会议,但这不是正式的培训计划,也不是为了优化临床医生的表现。未来的研究可以更彻底地探索这个问题,包括监视学习曲线的影响或探索表现是否根据参与临床医生或模拟患者熟悉远程医疗的程度而变化。请注意,我们研究中的对话是时间限制的,以遵循典型的OSCE公约。尽管现实世界中的患者医师咨询也经常在时间限制下进行,但我们研究中施加的特定时间限制可能不会反映实际情况。
此外,我们关于移情交流的发现也可能部分归因于以下事实:AMIE的反应明显长于临床医生的反应(扩展数据图。6),并具有更大的结构。这可能会向观察者表明,花费了更多的时间来准备反应,类似于已知的发现,患者满意度随着医生而花费的时间增加29。
总的来说,我们的发现提出了许多进一步研究的途径,这些途径可能利用人类的互补性30,将临床医生在分析口头和非语言线索的分析中结合了LLM的潜在优势,以提出更丰富的对话反应,包括移情陈述,结构,口才或更完整的DDXS。
模拟对话
模拟数据的使用使我们能够将培训迅速扩展到广泛的条件和患者环境,而搜索知识的注入则鼓励这些对话保持扎根和现实。尽管模拟的患者涵盖了广泛的疾病,但他们未能捕捉到各种潜在的患者背景,个性和动机。确实,补充图中显示的模拟实验。3提出,尽管AMIE在患者特征和行为方面的某些变化似乎很强,但与某些类型的患者(例如英语识字率低的患者)遇到了很大的困难。通过内部的自我播放程序,我们能够迭代地改善我们在微调中生成和使用的模拟对话。但是,这些改进受到我们表达批评家指示中良好对话的能力的限制,批评者能够产生有效的反馈和适应此类反馈的能力。例如,在模拟环境中,我们强加了AMIE为患者提供了拟议的差异和测试/治疗计划,但是对于某些情况,这种终点可能是不现实的,尤其是在基于虚拟聊天的环境中。此限制也适用于实际环境。
此外,与评估成功定义明确的基于规则的约束环境中评估结果相比,为医学诊断对话的质量产生奖励信号的任务更具挑战性(例如,赢得或失去GO的游戏31)。我们的生成合成小插图的过程考虑到了这一考虑。因为我们知道每个小插图的基础状况和相应的模拟对话推出,所以我们能够自动评估AMIE的DDX预测的正确性作为代理奖励信号。该奖励信号用于滤除失败的模拟对话,例如AMIE在此自我播放过程中未能产生准确的DDX预测的对话。除了DDX精度之外,自我播放的评论家还评估了其他素质,包括医生代理商在每种模拟对话中传达的同理心,专业和连贯性的水平。尽管与诊断准确性相比,这些后一种结构更为主观,但它们是我们研究团队的临床专家施加的领域特定启发式方法,以帮助将Amie的发展转向与既定的临床价值保持一致。我们还注意到,在这项工作中描述的初步分析中,我们的自动评估框架用于评估沿着这种标题的对话,与人类评分相吻合,并且与这些标准的特殊教育一致性相媲美。
请注意,我们评估集中的大多数场景都假定了潜在的疾病状态,而只有一个小子集则假设没有疾病。这是对这项工作的重要局限性,因为它不能反映主要的初级保健流行病学现实,在这些工作中,评估患者的大多数工作涉及排除疾病,而不是排除疾病。我们鼓励未来的工作探索各种疾病分布与非疾病状态的评估。
因此,即使在我们解决的疾病和专业的分布中,我们的发现也应受到谦卑和谨慎的解释。需要进一步的研究来检查相同疾病的各种表现,以及探索在不同患者需求,偏好,行为和情况下评估历史记录和临床对话的替代方法。
公平和偏见
本文提出的评估协议在捕获与公平和偏见有关的潜在问题的能力方面受到限制,这仍然是我们将在随后的系统评估中解决的重要开放问题。LLMS中综合框架的综合框架开发的最新进展32提出了建立这种方法的有希望的起点。应当指出的是,由于医疗领域的复杂性,对话的互动信息收集性质和结果驱动的环境,医疗诊断对话是一种特别具有挑战性的用例,并且在不正确的诊断或不正确的医疗建议的情况下可能会造成相关危害。然而,如果要克服域中的LLM而不是传播医疗保健中的不平等现象,那么解决这些问题是一个重要的进一步研究领域。例如,先前的研究发现,医生平均与患者的沟通方式不同,具体取决于患者的种族,导致黑人患者接受的沟通不那么以患者为中心,阳性影响较低33。其他研究发现,基于性别的医师沟通方式和对话长度的差异34以及患者的健康素养水平35。有效的跨文化沟通技巧是必不可少的36。因此,存在不可忽视的风险,即在AI对话系统中可以复制或放大这种历史对话偏见,但与此同时,也有机会努力设计更具包容性并更具个性化的对话性系统的机会。
为了帮助开发必要的公平,偏见和公平框架,使用参与式方法在广泛的患者人口统计以及临床和健康公平领域专家中征求代表性观点很重要。这种评估框架应通过广泛的模型红色团队和对抗性方法进行补充,以识别剩余的差距和故障模式。在这种情况下,红色团队LLM的最新进展可能很有用37,其中人类评估者或其他AI系统(即红色团队)模拟了对手在这些LLM中识别漏洞和安全差距的作用。这些实践不仅应告知对最终模型的评估,而且还应为其开发和迭代性改进提供信息。模型开发应遵循既定的数据和模型报告实践,并为培训数据和相关决策过程提供透明度38,,,,39,,,,40。在我们的研究中为AMIE培训数据做出贡献的对话研究数据集被取消识别,从而降低了社会经济因素,患者人口统计以及有关临床环境和位置的信息。为了减轻我们的合成小插曲会偏向某些人口组的风险,我们利用网络搜索来检索一系列人口统计学和与每种情况相关的相关症状。我们将这些用作Vignette生成的提示模板的输入,指示该模型在此范围内产生多个不同的小插图。尽管该机制的设计是为了减轻偏见放大风险的目的,但对艾米(Amie)等对话诊断模型的全面评估是公平,公平和偏见,这是未来工作的重要范围。
还需要进一步的工作来确保在多语言环境中医疗LLM的鲁棒性41,尤其是他们在少数族裔语言中的表现42。各种各样的文化43, languages, localities, identities and localized medical needs makes the task of generating a priori static yet comprehensive fairness benchmarks practically infeasible.The measurement and mitigation of bias must move beyond the traditional narrow focus on specific axes that fails to scale globally44。With LLM-based evaluators, a potential solution is presented for preliminary assessments in languages where there are no systematic benchmarks, although prior studies have found these auto-evaluation frameworks to be biased, underscoring the need for calibrating them on native speaker evaluations, and using them with caution45。
部署
这项研究证明了LLM在诊断对话的背景下在医疗保健中使用的潜力。从本研究中评估过的LLM研究原型过渡到可以由医疗保健提供者,管理人员和人员使用的安全和强大的工具,将需要大量额外的研究,以确保该技术的安全性,可靠性,功效和隐私。Careful consideration will need to be given to the ethical deployment of this technology, including rigorous quality assessment across different clinical settings and research into reliable uncertainty estimation methods46that would allow for deferral to human clinical experts when needed.需要这些和其他护栏来减轻对LLM技术的过度依赖,并采取其他具体措施,以关注对未来用例的道德和监管要求,以及在循环中存在合格的医生以维护任何模型输出。Additional research will also be needed to assess the extent to which biases and security vulnerabilities might arise, either from base models or the circumstances of use in deployment, as we have highlighted in our prior work12。Given the continuous evolution of clinical knowledge, it will also be important to develop ways for LLMs to utilize up-to-date clinical information47。
结论
如果医疗AI系统能够更好地进行对话,以大规模的医学知识为基础,同时以适当水平的同理心和信任进行交流,则可以极大地改善他们的效用。这项工作展示了基于LLM的AI系统具有涉及临床历史记录和诊断对话的设置的巨大潜在功能。艾米在模拟咨询中的表现代表了该领域的里程碑,鉴于它是在评估框架上进行了评估的,该评估框架考虑了多个临床相关的轴向对话诊断医学AI。但是,结果应谨慎解释。从这种有限的实验模拟记录记录和诊断对话范围转换为为人们和为他们提供照顾的人的现实世界工具,需要大量额外的研究和开发,以确保该技术的安全性,可靠性,公平性,公平性,功效和隐私。如果成功,我们认为AI系统(例如AMIE)可以是下一代学习卫生系统的核心,这些卫生系统有助于向所有人扩展世界一流的医疗保健。
方法
AMIE的真实数据集
AMIE是使用多种现实世界数据集开发的,包括多项选择的医疗问题,专家策划的长期医疗推理,电子健康记录(EHR)注意摘要和大规模转录的医学对话交互。如下所述,除了对话生成任务外,AMIE的培训任务混合物包括医疗问题,推理和摘要任务。
Medical reasoning
We used the MedQA (multiple-choice) dataset, consisting of US Medical Licensing Examination multiple-choice-style open-domain questions with four or five possible answers48。The training set consisted of 11,450 questions and the test set had 1,273 questions.We also curated 191 MedQA questions from the training set where clinical experts had crafted step-by-step reasoning leading to the correct answer13。
长格式医疗询问
The dataset used here consisted of expert-crafted long-form responses to 64 questions from HealthSearchQA, LiveQA and Medication QA in MultiMedQA12。
医学摘要
A dataset consisting of 65 clinician-written summaries of medical notes from MIMIC-III, a large, publicly available database containing the medical records of intensive care unit patients49, was used as additional training data for AMIE.模拟III包含大约200万笔涉及13种类型的笔记,包括心脏病学,呼吸系统,放射学,医师,一般,出院,病例管理,案例管理,咨询,护理,药房,营养,康复和社会工作。选择了每个类别的五个注释,最低总长度为400个令牌,每位患者至少一张护理笔记。指示临床医生写下单个医学笔记的抽象性摘要,捕获关键信息,同时还允许包含原始票据中不存在的新信息和澄清短语和句子。
现实世界对话
Here we used a de-identified dataset licensed from a dialogue research organization, comprising 98,919 audio transcripts of medical conversations during in-person clinical visits from over 1,000 clinicians over a ten-year period in the United States50。It covered 51 medical specialties (primary care, rheumatology, haematology, oncology, internal medicine and psychiatry, among others) and 168 medical conditions and visit reasons (type 2 diabetes, rheumatoid arthritis, asthma and depression being among the common conditions).音频成绩单包含来自不同演讲者角色的话语,例如医生,患者和护士。On average, a conversation had 149.8 turns (p0.25 = 75.0,p0.75 = 196.0).对于每次对话,元数据都包含有关患者人口统计的信息,访问的理由(随访疾病,急需需求,年度考试等)以及诊断类型(新,现有或其他无关)。参考参考。50有关更多详细信息。
For this study, we selected dialogues involving only doctors and patients, but not other roles, such as nurses.During preprocessing, we removed paraverbal annotations, such as ‘[LAUGHING]’ and ‘[INAUDIBLE]’, from the transcripts.We then divided the dataset into training (90%) and validation (10%) sets using stratified sampling based on condition categories and reasons for visits, resulting in 89,027 conversations for training and 9,892 for validation.
Simulated learning through self-play
While passively collecting and transcribing real-world dialogues from in-person clinical visits is feasible, two substantial challenges limit its effectiveness in training LLMs for medical conversations: (1) existing real-world data often fail to capture the vast range of medical conditions and scenarios, hindering its scalability and comprehensiveness;and (2) the data derived from real-world dialogue transcripts tend to be noisy, containing ambiguous language (including slang, jargon and sarcasm), interruptions, ungrammatical utterances and implicit references.This, in turn, may have limited AMIE’s knowledge, capabilities and applicability.
To address these limitations, we designed a self-play-based simulated learning environment for diagnostic medical dialogues in a virtual care setting, enabling us to scale AMIE’s knowledge and capabilities across a multitude of medical conditions and contexts.除了上面描述的静态,我们使用了这种环境进行迭代微调Amie,除了静态的避开问题,推理,摘要和现实世界中的对话数据外,还使用了一组模拟对话。
这个过程由两个自我播放循环组成:
-
一个内部的自我播放循环,艾米(Amie)利用文章的评论家反馈来完善其与AI患者代理商的模拟对话中的行为。
-
外部自我播放循环,其中将一组精制的模拟对话集成到了随后的微调迭代中。然后,由此产生的新版本AMIE可以再次参与内部循环,从而创建一个连续的学习周期。
在微调的每次迭代中,我们进行了11,686个对话,源于5,230种不同的医疗状况。从三个数据集中选择条件:
-
The Health QA dataset12, which contained 613 common medical conditions.
-
The MalaCards Human Disease Database (https://github.com/Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/malacards-diseases.json), which contained 18,455 less-common disease conditions.
-
The MedicineNet Diseases & Conditions Index (https://github.com/Shivanshu-Gupta/web-scrapers/blob/master/medical_ner/medicinenet-diseases.json), which contained 4,617 less-common conditions.
在每次自我播放迭代中,从613个常见条件中的每一个中产生了四次对话,而从Medicinenet和Malacards随机选择的4,617个较不常见条件中的每一个中都会产生两次对话。The average simulated dialogue conversation length was 21.28 turns (p0.25 = 19.0,p0.75 = 25.0).
通过自我播放模拟对话
为了大规模产生高质量的模拟对话,我们开发了一个新的多代理框架,其中包括三个关键组成部分:
-
小插图生成器:AMIE利用网络搜索来制作特定的医疗状况。
-
模拟对话生成器:三个LLM代理商扮演患者代理,医生和主持人的角色,进行逐个转向的对话,以模拟现实的诊断相互作用。
-
自我播放的评论家:第四位LLM代理人是批评家,向医生经纪人提供自我完善的反馈。值得注意的是,艾米(Amie)在此框架中充当所有代理商。
The prompts for each of these steps are listed in Supplementary Table3。The vignette generator aimed to create varied and realistic patient scenarios at scale, which could be subsequently used as context for generating simulated doctor–patient dialogues, thereby allowing AMIE to undergo a training process emulating exposure to a greater number of conditions and patient backgrounds.患者小插图(场景)包括基本背景信息,例如患者人口统计,症状,过去的病史,过去的手术病史,过去的社会历史和患者问题,以及相关的诊断和管理计划。
For a given condition, patient vignettes were constructed using the following process.First, we retrieved 60 passages (20 each) on the range of demographics, symptoms and management plans associated with the condition from using an internet search engine.To ensure these passages were relevant to the given condition, we used the general-purpose LLM, PaLM 2 (ref.10), to filter these retrieved passages, removing any passages deemed unrelated to the given condition.We then prompted AMIE to generate plausible patient vignettes aligned with the demographics, symptoms and management plans retrieved from the filtered passages, by providing a one-shot exemplar to enforce a particular vignette format.
鉴于患者插图详细详细介绍了特定的医疗状况,模拟的对话发生器旨在模拟患者和医生之间在线聊天设置中进行现实的对话,在线聊天设置可能是不可行的。
AMIE扮演的三个特定的LLM代理(患者代理,医生和主持人)的任务是相互交流以生成模拟对话。每个代理都有不同的说明。患者代理体现了体验小插图中概述的医疗状况的人。Their role involved truthfully responding to the doctor agent’s inquiries, as well as raising any additional questions or concerns they may have had.The doctor agent played the role of an empathetic clinician seeking to comprehend the patient’s medical history within the online chat environment51。Their objective was to formulate questions that could effectively reveal the patient’s symptoms and background, leading to an accurate diagnosis and an effective treatment plan.主持人不断评估患者代理人和医生代理人之间的持续对话,确定对话何时得出自然结论。
The turn-by-turn dialogue simulation started with the doctor agent initiating the conversation: “Doctor: So, how can I help you today?â€.此后,患者代理人做出了回应,他们的答案被纳入了正在进行的对话历史中。随后,医生经纪人根据更新的对话历史制定了回应。然后将此响应附加到对话历史上。对话一直进行,直到主持人检测到对话得出的结论为止,当医生经纪人提供了DDX,治疗计划并充分解决剩余的患者代理问题,或者当任何一个代理商发起了告别时。
To ensure high-quality dialogues, we implemented a tailored self-play3,,,,52framework specifically for the self-improvement of diagnostic conversations.This framework introduced a fourth LLM agent to act as a ‘critic’, which was also played by AMIE, and that was aware of the ground-truth diagnosis to provide in-context feedback to the doctor agent and enhance its performance in subsequent conversations.
Following the critic’s feedback, the doctor agent incorporated the suggestions to improve its responses in subsequent rounds of dialogue with the same patient agent from scratch.值得注意的是,医生经纪人在每个新回合中保留了以前的对话历史的访问权限。重复了两次自我改进过程,以生成用于每次微调迭代的对话。See Supplementary Table4as an example of this self-critique process.
We noted that the simulated dialogues from self-play had significantly fewer conversational turns than those from the real-world data described in the previous section.This difference was expected, given that our self-play mechanism was designed—through instructions to the doctor and moderator agents—to simulate text-based conversations.By contrast, real-world dialogue data was transcribed from in-person encounters.There are fundamental differences in communication styles between text-based and face-to-face conversations.For example, in-person encounters may afford a higher communication bandwidth, including a higher total word count and more ‘back and forth’ (that is, a greater number of conversational turns) between the physician and the patient.AMIE, by contrast, was designed for focused information gathering by means of a text-chat interface.
指令微调
AMIE, built upon the base LLM PaLM 2 (ref.10), was instruction fine-tuned to enhance its capabilities for medical dialogue and reasoning.我们将读者推荐给Palm 2技术报告,以获取有关LLM架构的更多详细信息。微调示例是根据我们的四个代理程序以及静态数据集生成的不断发展的模拟对话数据集制成的。对于每个任务,我们都设计了特定于任务的说明,以指示AMIE执行什么任务。对于对话,这是假设患者在对话中的角色或医生角色,而对于提问和摘要数据集,则指示AMIE回答医疗问题或总结EHR注释。基本LLM的第一轮微调仅使用静态数据集,而随后的微型调整则利用了通过自我播放内部循环产生的模拟对话。
对于对话生成任务,艾米被指示担任医生或患者的角色,并鉴于对话到某个转弯,以预测下一次对话转弯。When playing the patient agent, AMIE’s instruction was to reply to the doctor agent’s questions about their symptoms, drawing upon information provided in patient scenarios.这些场景包括用于模拟对话或元数据的患者小插曲,例如人口统计信息,请访问理性和诊断类型,以获取现实世界对话数据集。For each fine-tuning example in the patient role, the corresponding patient scenario was added to AMIE’s context.在医生代理人的角色中,AMIE被指示担任善解人意的临床医生,面试患者的病史和症状,最终得出准确的诊断。从每次对话中,我们平均对每位医生进行三回合,并根据导致该目标转向的对话进行预测,因为目标转弯预测。目标转弯是从最小长度为30个字符的对话中随机采样的。
Similarly, for the EHR note summarization task, AMIE was provided with a clinical note and prompted to generate a summary of the note.Medical reasoning/QA and long-form response generation tasks followed the same set-up as in ref.13。Notably, all tasks except dialogue generation and long-form response generation incorporated few-shot (1–5) exemplars in addition to task-specific instructions for additional context.
在线推理的链条链
To address the core challenge in diagnostic dialogue—effectively, acquiring information under uncertainty to enhance diagnostic accuracy and confidence, while maintaining positive rapport with the patient—AMIE employed a chain-of-reasoning strategy before generating a response in each dialogue turn.Here ‘chain-of-reasoning’ refers to a series of sequential model calls, each dependent on the outputs of prior steps.具体而言,我们使用了一个三步推理过程,如下所示:
-
分析患者信息。鉴于当前的对话历史,AMIE被指示:(1)总结患者的积极和负面症状以及任何相关的医学/家庭/社会历史和人口统计信息;(2)产生电流DDX;(3)注意更准确诊断所需的缺失信息;(4)评估对当前差异的信心,并突出其紧迫性。
-
制定响应和行动。Building upon the conversation history and the output of step 1, AMIE: (1) generated a response to the patient’s last message and formulated further questions to acquire missing information and refine the DDx;(2)必要时建议立即采取行动,例如急诊室访问。如果对诊断充满信心,则根据可用信息,AMIE提出了差异。
-
完善响应。艾米(Amie)根据对话历史记录和早期步骤的输出来修改其先前的输出,以满足特定条件。该标准主要与响应的事实和格式有关(例如,避免对患者事实和不必要的重复的事实不准确,表现出同理心,并以清晰的格式显示)。
这种发行链的策略使艾米能够逐步完善其在当前对话的条件下的回应,从而得出知情和扎根的答复。
评估
Prior works developing models for clinical dialogue have focused on metrics, such as the accuracy of note-to-dialogue or dialogue-to-note generations53,,,,54, or natural language generation metrics, such as BLEU or ROUGE scores that fail to capture the clinical quality of a consultation55,,,,56。
In contrast to these prior works, we sought to anchor our human evaluation in criteria more commonly used for evaluating the quality of physicians’ expertise in history-taking, including their communication skills in consultation.此外,我们旨在从非专业参与者(参与患者演员)和非参与专业观察者(不直接参与咨询的医师)的角度评估对话质量。We surveyed the literature and interviewed clinicians working as OSCE examiners in Canada and India to identify a minimum set of peer-reviewed published criteria that they considered comprehensively reflected the criteria that are commonly used in evaluating both patient-centred and professional-centred aspects of clinical diagnostic dialogue—that is, identifying the consensus for PCCBP in medical interviews19, the criteria examined for history-taking skills by the Royal College of Physicians in the United Kingdom as part of their PACES (https://www.mrcpuk.org/mrcpuk-examinations/paces/marksheets)20and the criteria proposed by the UK GMCPQ (https://edwebcontent.ed.ac.uk/sites/default/files/imports/fileManager/patient_questionnaire%20pdf_48210488.pdf) for doctors seeking patient feedback as part of professional revalidation (https://www.gmc-uk.org/registration-and-licensing/managing-your-registration/revalidation/revalidation-resources)。
The resulting evaluation framework enabled assessment from two perspectives—the clinician, and lay participants in the dialogues (that is, the patient-actors).The framework included the consideration of consultation quality, structure and completeness, and the roles, responsibilities and skills of the interviewer (Extended Data Tables1–3)。
Remote OSCE study design
To compare AMIE’s performance to that of real clinicians, we conducted a randomized crossover study of blinded consultations in the style of a remote OSCE.Our OSCE study involved 20 board-certified PCPs and 20 validated patient-actors, ten each from India and Canada, respectively, to partake in online text-based consultations (Extended Data Fig.1)。The PCPs had between 3 and 25 years of post-residency experience (median 7 years).The patient-actors comprised of a mix of medical students, residents and nurse practitioners with experience in OSCE participation.We sourced 159 scenario packs from India (75), Canada (70) and the United Kingdom (14).
我们研究中的情景包和模拟患者由两个OSCE实验室(一个在加拿大和印度分别)制备,每个实验室都隶属于医学院,并且在准备情况包和模拟患者进行OSCE检查方面具有丰富的经验。英国场景包来自英国皇家医师学院成员的样本。每个场景包都与基础诊断和一组可接受的诊断有关。The scenario packs covered conditions from the cardiovascular (31), respiratory (32), gastroenterology (33), neurology (32), urology, obstetric and gynaecology (15) domains and internal medicine (16).The scenarios are listed in Supplementary Information section 8。The paediatric and psychiatry domains were excluded from this study, as were intensive care and inpatient case management scenarios.
印度的患者演员在所有印度场景包中扮演着角色,而英国14个场景中有7个。加拿大患者演员参加了加拿大和基于英国的方案包的方案包。该分配过程导致159名不同的模拟患者(即场景)。Below, we use the term ‘OSCE agent’ to refer to the conversational counterpart interviewing the patient-actor—that is, either the PCP or AMIE.补充表1summarizes the OSCE assignment information across the three geographical locations.Each of the 159 simulated patients completed the three-step study flow depicted in Fig.2。
基于文本的在线咨询
在研究开始熟悉界面和实验要求之前,将PCP和患者演员带有样本场景和说明,并参加了试点咨询。
For the experiment, each simulated patient completed two online text-based consultations by means of a synchronous text-chat interface (Extended Data Fig.1), one with a PCP (control) and one with AMIE (intervention).PCP和AMIE的订购是随机的,并且没有告知他们在每次咨询中与之交谈(以控制任何潜在订单效果的平衡设计)。PCP与患者演员位于同一国家 /地区,并根据指定咨询的时间插槽的可用性随机绘制。The patient-actors role-played the scenario and were instructed to conclude the conversation after no more than 20 minutes.在任何情况下,都要求两位OSCE代理(通过研究特定说明,作为及时模板的PCP作为及时模板的一部分)都不透露其身份,或者它们是否是人类。
QuestionNaires
Upon conclusion of the consultation, the patient-actor and OSCE agent each filled in a post-questionnaire in light of the resulting consultation transcript (Extended Data Fig.1)。The post-questionnaire for patient-actors consisted of the complete GMCPQ, the PACES components for ‘Managing patient concerns’ and ‘Maintaining patient welfare’ (Extended Data Table1) and a checklist representation of the PCCBP category for ‘Fostering the relationship’ (Extended Data Table2)。The responses the patient-actors provided to the post-questionnaire are referred to as ‘patient-actor ratings’.OSCE代理商的Questernaire要求提供一个排名的DDX列表,其中至少三个,不超过十个条件,以及提出升级到面对面或基于视频的咨询,调查,治疗,管理计划和随访的需求的建议。
Specialist physician evaluation
Finally, a pool of 33 specialist physicians from India (18), North America (12) and the United Kingdom (3) evaluated the PCPs and AMIE with respect to the quality of their consultation and their responses to the post-questionnaire.During evaluation, the specialist physicians also had access to the full scenario pack, along with its associated ground-truth differential and additional accepted differentials.All of the data the specialist physicians had access to during evaluation are collectively referred to as ‘OSCE data’.Specialist physicians were sourced to match the specialties and geographical regions corresponding to the scenario packs included in our study, and had between 1 and 32 years of post-residency experience (median 5 years).Each set of OSCE data was evaluated by three specialist physicians randomly assigned to match the specialty and geographical region of the underlying scenario (for example, Canadian pulmonologists evaluated OSCE data from the Canada-sourced respiratory medicine scenario).Each specialist evaluated the OSCE data from both the PCP and AMIE for each given scenario.Evaluations for the PCP and AMIE were conducted by the same set of specialists in a randomized and blinded sequence.
Evaluation criteria included the accuracy, appropriateness and comprehensiveness of the provided DDx list, the appropriateness of recommendations regarding escalation, investigation, treatment, management plan and follow-up (Extended Data Table3) and all PACES (Extended Data Table1) and PCCBP (Extended Data Table2) rating items.We also asked specialist physicians to highlight confabulations in the consultations and questionnaire responses—that is, text passages that were non-factual or that referred to information not provided in the conversation.每个OSCE场景包还为专家提供了特定方案的临床信息,以协助评估咨询的临床质量,例如理想的调查或管理计划,或临床病史的重要方面,理想地阐明了最高质量的咨询。这是遵循OSCE考试的指令的共同实践,其中提供了特定的临床方案信息以确保检查人员之间的一致性,并遵循皇家医师学院成员样本包的成员所证明的范式。For example, this scenario (https://www.thefederation.uk/sites/default/files/Station%202%20Scenario%20Pack%20%2816%29.pdf) informs an examiner that, for a scenario in which the patient-actor has haemoptysis, the appropriate investigations would include a chest X-ray, a high-resolution computed tomography scan of the chest, a bronchoscopy and spirometry, whereas bronchiectasis treatment options a candidate should be aware of should include chest physiotherapy, mucolytics, bronchodilators and antibiotics.
Statistical analysis and reproducibility
We evaluated the top-kaccuracy of the DDx lists generated by AMIE and the PCPs across all 159 simulated patients.顶部-kaccuracy was defined as the percentage of cases where the correct ground-truth diagnosis appeared within the top-kpositions of the DDx list.For example, top-3 accuracy is the percentage of cases for which the correct ground-truth diagnosis appeared in the top three diagnosis predictions from AMIE or the PCP.Specifically, a candidate diagnosis was considered a match if the specialist rater marked it as either an exact match with the ground-truth diagnosis, or very close to or closely related to the ground-truth diagnosis (or accepted differential).Each conversation and DDx was evaluated by three specialists, and their majority vote or median rating was used to determine the accuracy and quality ratings, respectively.
The statistical significance of the DDx accuracy was determined using two-sided bootstrap tests57with 10,000 samples and false discovery rate (FDR) correction58across allk。The statistical significance of the patient-actor and specialist ratings was determined using two-sided Wilcoxon signed-rank tests59, also with FDR correction.Cases where either agent received ‘Cannot rate/Does not apply’ were excluded from the test.All significance results are based onpvalues after FDR correction.
此外,我们重申,OSCE场景本身来自三个不同的国家,患者行动者来自加拿大和印度的两个独立的机构,在这项研究中,专家评估是三次评估。
相关工作
临床历史记录和诊断对话
History-taking and the clinical interview are widely taught in both medical schools and postgraduate curricula60,,,,61,,,,62,,,,63,,,,64,,,,65。Consensus on physician–patient communication has evolved to embrace patient-centred communication practices, with recommendations that communication in clinical encounters should address six core functions—fostering the relationship, gathering information, providing information, making decisions, responding to emotions and enabling disease- and treatment-related behaviour19,,,,66,,,,67。The specific skills and behaviours for meeting these goals have also been described, taught and assessed19,,,,68using validated tools68。Medical conventions consistently cite that certain categories of information should be gathered during a clinical interview, comprising topics such as the presenting complaint, past medical history and medication history, social and family history, and systems review69,,,,70。Clinicians’ ability to meet these goals is commonly assessed using the framework of an OSCE4,,,,5,,,,71。Such assessments vary in their reproducibility or implementation, and have even been adapted for remote practice as virtual OSCEs with telemedical scenarios, an issue of particular relevance during the COVID-19 pandemic72。
Conversational AI and goal-oriented dialogue
Conversational AI systems for goal-oriented dialogue and task completion have a rich history73,,,,74,,,,75。The emergence of transformers76and large language models15have led to renewed interest in this direction.The development of strategies for alignment77, self-improvement78,,,,79,,,,80,,,,81and scalable oversight mechanisms82has enabled the large-scale deployment of such conversational systems in the real world16,,,,83。However, the rigorous evaluation and exploration of conversational and task-completion capabilities of such AI systems remains limited for clinical applications, where studies have largely focused on single-turn interaction use cases, such as question-answering or summarization.
AI进行医学咨询和诊断对话
The majority of explorations of AI as tools for conducting medical consultations have focused on ‘symptom-checker’ applications rather than a full natural dialogue, or on topics such as the transcription of medical audio or the generation of plausible dialogue, given clinical notes or summaries84,,,,85,,,,86,,,,87。Language models have been trained using clinical dialogue datasets, but these have not been comprehensively evaluated88,,,,89。Studies have been grounded in messages between doctors and patients in commercial chat platforms (which may have altered doctor–patient engagement compared to 1:1 medical consultations)55,,,,90,,,,91。许多人主要集中于预测记录的交流中的下一个转弯,而不是临床意义的指标。此外,迄今为止,还没有使用与对话和沟通技巧检查和培训人类医生相同的标准,研究了AI模型的诊断对话质量,也没有研究评估OSCE等通用框架中的AI系统的研究。
评估诊断对话
Prior frameworks for the human evaluation of AI systems’ performance in diagnostic dialogue have been limited in detail.他们尚未以既定的标准来评估沟通技巧和历史悠久的质量。例如,参考。56reported a five-point scale describing overall ‘human evaluation’, ref . 90 reported ‘relevance, informativeness and human likeness’, and ref . 91reported ‘fluency, expertise and relevance’, whereas other studies have reported ‘fluency and adequacy’92and ‘fluency and specialty’93。这些标准比医学专业人员教授和实践的标准远不那么全面和具体。参考文献中引入了评估LLMS的对话能力的多代理框架。88, the study, however, was performed in the restricted setting of dermatology, used AI models to emulate both the doctor and patient sides of simulated interactions, and it performed limited expert evaluation of the history-taking as being complete or not.
报告摘要
Further information on research design is available in the Nature Portfolio Reporting Summary链接到本文。
数据可用性
Many of the real-world datasets used in the development of AMIE are open-source, including MedQA (https://github.com/jind11/MedQA), MultiMedQA (https://www.nature.com/articles/s41586-023-06291-2#data-availability) and MIMIC-III (https://physionet.org/content/mimiciii/1.4/)。The scenario packs from the United Kingdom used in the OSCE study are also available for download fromhttps://www.thefederation.uk/sites/default/files/documents/Station%202%20Scenario%20Pack%20%2816%29.pdf。该研究中使用的其他方案包将根据要求提供。
代码可用性
AMIE是一种基于LLM的研究AI系统,用于诊断对话。通过测试程序为系统提供了访问审核者的访问,以与系统进行交互并评估性能。由于在医疗环境中使用这种系统的使用的安全性,我们不是开源的型号代码和权重。为了负责任的创新,我们将与研究合作伙伴,监管机构和提供者合作,以验证和探索AMIE的安全使用。为了获得可重复性,我们已经记录了技术深度学习方法,同时使纸张可用于临床和一般科学受众。Our work builds upon PaLM 2, for which technical details have been described extensively in the technical report10。All analyses were conducted using Python v.2.7.18 (https://www.python.org/)。
参考
Levine, D. History taking is a complex skill.br。医学j。358, j3513 (2017).Engel, G. L. & Morgan, W. L.
Interviewing the Patient(W. B. Saunders, 1973).Fu, Y., Peng, H., Khot, T. & Lapata, M. Improving language model negotiation with self-play and in-context learning from AI feedback.
Preprint athttps://arxiv.org/abs/2305.10142(2023)。
Sloan, D. A., Donnelly, M. B., Schwartz, R. W. & Strodel, W. E. The objective structured clinical examination.The new gold standard for evaluating postgraduate clinical performance.安。外科。 222, 735 (1995).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Carraccio, C. & Englander, R. The objective structured clinical examination: a step in the direction of competency-based evaluation.拱。小儿科Adolesc。医学 154, 736–741 (2000).
文章一个 PubMed一个 Google Scholar一个
Peterson, M. C., Holbrook, J. H., Von Hales, D., Smith, N. & Staker, L. Contributions of the history, physical examination, and laboratory investigation in making medical diagnoses.西方。J. Med。 156, 163 (1992).
Silverman, J., Kurtz, S. & Draper, J.Skills for Communicating with Patients3rd edn (CRC, 2016).
Rennie, T., Marriott, J. & Brock, T. P. Global supply of health professionals.N. Engl。J. Med。 370, 2246–2247 (2014).
文章一个 PubMed一个 Google Scholar一个
OpenAI et al.GPT-4技术报告。Preprint athttps://arxiv.org/abs/2303.08774(2023)。
Anil, R. et al.Palm 2技术报告。Preprint athttps://arxiv.org/abs/2305.10403(2023)。
Gemini Team Google et al.Gemini: a family of highly capable multimodal models.Preprint athttps://arxiv.org/abs/2312.11805(2023)。
Singhal,K。等。大型语言模型编码临床知识。自然 620, 172–180 (2023).
文章一个 广告一个 PubMed一个 PubMed Central一个 Google Scholar一个
Singhal,K。等。使用大语言模型回答专家级的医学问题。纳特。医学 31, 943–950 (2025).
Nori, H. et al.通才基础模型可以胜过特殊实用的调整吗?医学案例研究。Preprint athttps://arxiv.org/abs/2311.16452(2023)。
Thoppilan,R。等。LAMDA:对话应用程序的语言模型。Preprint athttps://arxiv.org/abs/2201.08239(2022)。
Introducing ChatGPT.Openai https://openai.com/blog/chatgpt(2022)。
Toma, A. et al.Clinical Camel: an open-source expert-level medical language model with dialogue-based knowledge encoding.Preprint athttps://arxiv.org/abs/2305.12031(2023)。
Chen,Z。等。MEDITRON-70B: scaling medical pretraining for large language models.Preprint athttps://arxiv.org/abs/2311.16079(2023)。
King, A. & Hoppe, R. B. “Best practice†for patient-centered communication: a narrative review.J. Grad.医学教育。 5, 385–393 (2013).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Dacre, J., Besser, M. & White, P. MRCP(UK) part 2 clinical examination (PACES): a review of the first four examination sessions (June 2001 – July 2002).临床医学 3, 452–459 (2003).
文章一个 Google Scholar一个
Kelly, C. J., Karthikesalingam, A., Suleyman, M., Corrado, G. & King, D. Key challenges for delivering clinical impact with artificial intelligence.BMC Med。 17, 195 (2019).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
McDuff, D. et al.Towards accurate differential diagnosis with large language models.自然 https://doi.org/10.1038/s41586-025-08869-4(2025)。
Semigran, H. L., Linder, J. A., Gidengil, C. & Mehrotra, A. Evaluation of symptom checkers for self diagnosis and triage: audit study.br。医学J. 351, h3480 (2015).
Ayers, J. W. et al.将医师和人工智能的聊天机器人与发布到公共社交媒体论坛的患者问题进行比较。JAMA实习生。医学 183, 589–596 (2023).
Chatgpt.Openai https://chat.openai.com/chat(2023)。
Carrillo de Albornoz, S., Sia, K.-L.&Harris,A。电信在初级保健中的有效性:系统评价。家族。实践。 39, 168–182 (2022).
文章一个 PubMed一个 Google Scholar一个
Fuster-Casanovas, A. & Vidal-Alaball, J. Asynchronous remote communication as a tool for care management in primary care: a rapid review of the literature.int。J. Intern。关心 22, 7 (2022).
Hammersley, V. et al.Comparing the content and quality of video, telephone, and face-to-face consultations: a non-randomised, quasi-experimental, exploratory study in UK primary care.br。J. Gen. Pract. 69, e595–e604 (2019).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Gross, D. A., Zyzanski, S. J., Borawski, E. A., Cebul, R. D. & Stange, K. C. Patient satisfaction with time spent with their physician.J. Fam.实践。 47, 133–138 (1998).
PubMed一个 Google Scholar一个
Dvijotham,K。等。Enhancing the reliability and accuracy of AI-enabled diagnosis via complementarity-driven deferral to clinicians.纳特。医学 29, 1814–1820 (2023).
文章一个 PubMed一个 Google Scholar一个
Silver, D. et al.Mastering the game of Go with deep neural networks and tree search.自然 529, 484–489 (2016).
文章一个 广告一个 PubMed一个 Google Scholar一个
Gallegos, I. O. et al.Bias and fairness in large language models: a survey.计算。语言学家。 50, 1–79 (2024).
Johnson, R. L., Roter, D., Powe, N. R. & Cooper, L. A. Patient race/ethnicity and quality of patient–physician communication during medical visits.是。J.公共卫生 94, 2084–2090 (2004).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Roter, D. L., Hall, J. A. & Aoki, Y. Physician gender effects in medical communication: a meta-analytic review.贾马 288, 756–764 (2002).
文章一个 PubMed一个 Google Scholar一个
Schillinger, D. et al.Precision communication: physicians’ linguistic adaptation to patients’ health literacy.科学。ADV。 7, eabj2836 (2021).
文章一个 广告一个 PubMed一个 PubMed Central一个 Google Scholar一个
Rahman, U. & Cooling, N. Inter-cultural communication skills training in medical schools: a systematic review.医学res。拱。 11,,mra.v11i4.3757 (2023).
Ganguli, D. et al.Red teaming language models to reduce harms: methods, scaling behaviors, and lessons learned.Preprint athttps://arxiv.org/abs/2209.07858(2022)。
Mitchell, M. et al.用于型号报告的型号卡。在Proc。Conference on Fairness, Accountability, and Transparency220–229 (Association for Computing Machinery, 2019).
Crisan, A., Drouhard, M., Vig, J. & Rajani, N. Interactive model cards: a human-centered approach to model documentation.在Proc。2022 ACM Conference on Fairness, Accountability, and Transparency427–439 (Association for Computing Machinery, 2022).
Pushkarna, M., Zaldivar, A. & Kjartansson, O. Data cards: purposeful and transparent dataset documentation for responsible AI.在Proc。2022 ACM Conference on Fairness, Accountability, and Transparency1776–1826 (Association for Computing Machinery, 2022).
Choudhury, M. & Deshpande, A. How linguistically fair are multilingual pre-trained language models?在Proc。AAAI Conference on Artificial Intelligence卷。35 12710–12718 (Association for the Advancement of Artificial Intelligence, 2021).
Nguyen, X.-P., Aljunied, S. M., Joty, S. & Bing, L. Democratizing LLMs for low-resource languages by leveraging their English dominant abilities with linguistically-diverse prompts.在Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics卷。1 (eds Ku, L.-W. et al.) 3501–3516 (Association for Computational Linguistics, 2024).
Naous, T., Ryan, M. J., Ritter, A. & Xu, W. Having beer after prayer?测量大语模型中的文化偏见。在Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics卷。1 (eds Ku, L.-W. et al.) 16366–16393 (Association for Computational Linguistics, 2024).
Ramesh, K., Sitaram, S. & Choudhury, M. Fairness in language models beyond English: gaps and challenges.在Findings of the Association for Computational Linguistics: EACL 2023(eds Vlachos, A. & Augenstein, I.) 2106–2119 (Association for Computational Linguistics, 2023).
Hada, R. et al.基于大型语言模型的大型评估者是否可以扩展多语言评估?在Findings of the Association for Computational Linguistics: EACL 2024(eds Graham, Y. & Purver, M.) 1051–1070 (Association for Computational Linguistics, 2024).
Quach, V. et al.Conformal language modeling.Preprint athttps://arxiv.org/abs/2306.10193(2023)。
Lazaridou, A. et al.Mind the gap: assessing temporal generalization in neural language models.ADV。神经信息。过程。系统。 34, 29348–29363 (2021).
Jin,D。等。这个患者有什么疾病?一个大规模的开放域问,从体检中回答数据集。应用。科学。 11, 6421 (2021).
文章一个 Google Scholar一个
Johnson, A. E. et al.MIMIC-III, a freely accessible critical care database.科学。数据 3, 160035 (2016).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Chiu, C.-C.等。Speech recognition for medical conversations.在Proc。Interspeech(ed. Yegnanarayana, B.) 2972–2976 (International Speech Communication Association, 2018).
Sharma, A., Miner, A., Atkins, D. & Althoff, T. A computational approach to understanding empathy expressed in text-based mental health support.在Proc。2020 Conference on Empirical Methods in Natural Language Processing(eds Webber, B. et al.) 5263–5276 (Association for Computational Linguistics, 2020).
Aksitov, R. et al.Rest meets ReAct: self-improvement for multi-step reasoning LLM agent.Preprint athttps://doi.org/10.48550/arXiv.2312.10003(2023)。
Abacha, A. B., Yim, W.-W., Adams, G., Snider, N. & Yetisgen-Yildiz, M. Overview of the MEDIQA-chat 2023 shared tasks on the summarization & generation of doctor-patient conversations.在Proc。5th Clinical Natural Language Processing Workshop(eds Naumann, T. et al.) 503–513 (Association for Computational Linguistics, 2023).
Ionescu, B. et al.在Experimental IR Meets Multilinguality, Multimodality, and Interaction.CLEF 2023 Lecture Notes in Computer Science卷。14163 (eds Arampatzis, A. et al.) 370–396 (Springer, 2023).
He, Z. et al.DIALMED: a dataset for dialogue-based medication recommendation.在Proc。29th International Conference on Computational Linguistics(eds Calzolari, N. et al.) 721–733 (International Committee on Computational Linguistics, 2022).
Naseem, U., Bandi, A., Raza, S., Rashid, J. & Chakravarthi, B. R. Incorporating medical knowledge to transformer-based language models for medical dialogue generation.在Proc。21st Workshop on Biomedical Language Processing(eds Demner-Fushman, D. et al.) 110–115 (Association for Computational Linguistics, 2022).
Horowitz, J. L. inHandbook of Econometrics,卷。5 (eds Heckman, J. J. & Leamer, E.) 3159–3228 (Elsevier, 2001).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing.J. R. Stat。Soc。ser。B Methodol. 57, 289–300 (1995).
文章一个 MathScinet一个 Google Scholar一个
Woolson, R. F. inWiley Encyclopedia of Clinical Trials(eds D’Agostino, R. B. et al.) 1–3 (Wiley, 2007).
Keifenheim, K. E. et al.Teaching history taking to medical students: a systematic review.BMC Med。教育。 15, 159 (2015).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Yedidia, M. J. et al.Effect of communications training on medical student performance.贾马 290, 1157–1165 (2003).
文章一个 PubMed一个 Google Scholar一个
Makoul, G. Communication skills education in medical school and beyond.贾马 289, 93–93 (2003).
文章一个 PubMed一个 Google Scholar一个
Tan, X. H. et al.Teaching and assessing communication skills in the postgraduate medical setting: a systematic scoping review.BMC Med。教育。 21, 483 (2021).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Raper, S. E., Gupta, M., Okusanya, O. & Morris, J. B. Improving communication skills: a course for academic medical center surgery residents and faculty.J. Surg。教育。 72, e202–e211 (2015).
文章一个 PubMed一个 Google Scholar一个
Von Fragstein, M. et al.UK consensus statement on the content of communication curricula in undergraduate medical education.医学教育。 42, 1100–1107 (2008).
文章一个 Google Scholar一个
De Haes, H. & Bensing, J. Endpoints in medical communication research, proposing a framework of functions and outcomes.Patient Educ.Couns. 74, 287–294 (2009).
文章一个 PubMed一个 Google Scholar一个
Epstein, R. M. & Street Jr, R. L.Patient-Centered Communication in Cancer Care: Promoting Healing and Reducing Suffering(National Cancer Institute, 2007).
Schirmer, J. M. et al.Assessing communication competence: a review of current tools.家族。医学 37, 184–92 (2005).
PubMed一个 Google Scholar一个
Nichol, J. R., Sundjaja, J. H. & Nelson, G.病史(StatPearls, 2018).
Denness, C. What are consultation models for?InnovAiT 6, 592–599 (2013).
文章一个 Google Scholar一个
Epstein, R. M. & Hundert, E. M. Defining and assessing professional competence.贾马 287, 226–235 (2002).
文章一个 PubMed一个 Google Scholar一个
Chan, S. C. C., Choa, G., Kelly, J., Maru, D. & Rashid, M. A. Implementation of virtual OSCE in health professions education: a systematic review.医学教育。 57, 833–843 (2023).
Budzianowski, P. et al.MultiWOZ–a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling.在Proc。2018 Conference on Empirical Methods in Natural Language Processing(eds Riloff, E. et al.) 5016–5026 (Association for Computational Linguistics, 2018).
Wei, W., Le, Q., Dai, A. & Li, J. AirDialogue: an environment for goal-oriented dialogue research.在Proc。2018 Conference on Empirical Methods in Natural Language Processing(eds Riloff, E. et al.) 3844–3854 (Association for Computational Linguistics, 2018).
Lin, J., Tomlin, N., Andreas, J. & Eisner, J. Decision-oriented dialogue for human-AI collaboration.反式。联合。计算。语言学家。 12, 892–911 (2023).
Vaswani, A. et al.注意就是您所需要的。在Proc。31st Conference on Neural Information Processing Systems(eds Guyon, I. et al.) 6000–6010 (Curran Associates, 2017).
Ouyang, L. et al.培训语言模型遵循人类反馈的说明。ADV。神经信息。过程。系统。 35, 27730–27744 (2022).
Zhao, J., Khashabi, D., Khot, T., Sabharwal, A. & Chang, K.-W.Ethical-advice taker: do language models understand natural language interventions?在Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021(eds Zong, C. et al.) 4158–4164 (Association for Computational Linguistics, 2021).
Saunders, W. et al.Self-critiquing models for assisting human evaluators.Preprint athttps://arxiv.org/abs/2206.05802(2022)。
Scheurer, J. et al.Training language models with language feedback at scale.Preprint athttps://arxiv.org/abs/2303.16755(2023)。
Glaese, A. et al.Improving alignment of dialogue agents via targeted human judgements.Preprint athttps://arxiv.org/abs/2209.14375(2022)。
Bai, Y. et al.Constitutional AI: harmlessness from AI feedback.Preprint athttps://arxiv.org/abs/2212.08073(2022)。
Askell, A. et al.A general language assistant as a laboratory for alignment.Preprint athttps://arxiv.org/abs/2112.00861(2021)。
Shor, J. et al.Clinical BERTScore: an improved measure of automatic speech recognition performance in clinical settings.在Proc。5th Clinical Natural Language Processing Workshop(eds Naumann, T. et al.) 1–7 (Association for Computational Linguistics, 2023).
Abacha, A. B., Agichtein, E., Pinter, Y. & Demner-Fushman, D. Overview of the medical question answering task at TREC 2017 LiveQA.在Proc。26th Text Retrieval Conference, TREC 2017(eds Voorhees, E. M. & Ellis, A.) 1–12 (National Institute of Standards and Technology and the Defense Advanced Research Projects Agency, 2017).
Wallace, W. et al.The diagnostic and triage accuracy of digital and online symptom checker tools: a systematic review.NPJ Digit.医学 5, 118 (2022).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Zeltzer, D. et al.Diagnostic accuracy of artificial intelligence in virtual primary care.梅奥临床。Proc。数字健康 1, 480–489 (2023).
文章一个 PubMed一个 Google Scholar一个
Johri, S. et al.Testing the limits of language models: a conversational framework for medical AI assessment.Preprint atmedrxiv https://doi.org/10.1101/2023.09.12.23295399(2023)。
Wu, C.-K., Chen, W.-L.& Chen, H.-H.Large language models perform diagnostic reasoning.Preprint athttps://arxiv.org/abs/2307.08922(2023)。
Zeng, G. et al.MedDialog: large-scale medical dialogue datasets.在Proc。2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)(eds Webber, B. et al.) 9241–9250 (Association for Computational Linguistics, 2020).
Liu,W。等。MedDG: an entity-centric medical consultation dataset for entity-aware medical dialogue generation.在Proc。11th CCF International Conference on Natural Language Processing and Chinese Computing(eds Lu, W. et al.) 447–459 (Springer, 2022).
Varshney, D., Zafar, A., Behera, N. & Ekbal, A. CDialog: a multi-turn COVID-19 conversation dataset for entity-aware dialog generation.在Proc。2022 Conference on Empirical Methods in Natural Language Processing(eds Goldberg, Y. et al.) 11373–11385 (Association for Computational Linguistics, 2022).
Yan, G. et al.ReMeDi: resources for multi-domain, multi-service, medical dialogues.在Proc。45th International ACM SIGIR Conference on Research and Development in Information Retrieval3013–3024 (Association for Computing Machinery, 2022).
致谢
This project represents an extensive collaboration between several teams at Google Research and Google DeepMind.We thank Y. Liu, D. McDuff, J. Sunshine, A. Connell, P. McGovern and Z. Ghahramani for their comprehensive reviews and detailed feedback on early versions of the manuscript.We also thank S. Lachgar, L. Winer, J. Guilyard and M. Shiels for contributions to the narratives and visuals.We are grateful to J. A. Seguin, S. Goldman, Y. Vasilevski, X. Song, A. Goel, C.-l.Ko, A. Das, H. Yu, C. Liu, Y. Liu, S. Man, B. Hatfield, S. Li, A. Joshi, G. Turner, A. Um’rani, D. Pandya and P. Singh for their valuable insights, technical support and feedback during our research.We also thank GoodLabs Studio Inc., Intel Medical Inc. and C. Smith for their partnership in conducting the OSCE study in North America, and the JSS Academy of Higher Education and Research and V. Patil for their partnership in conducting the OSCE study in India.Finally, we are grateful to D. Webster, E. Dominowska, D. Fleet, P. Mansfield, S. Prakash, R. Wong, S. Thomas, M. Howell, K. DeSalvo, J. Dean, J. Manyika, Z. Ghahramani and D. Hassabis for their support during the course of this project.
道德声明
竞争利益
This study was funded by Alphabet Inc. and/or a subsidiary thereof (‘Alphabet’).All authors are employees of Alphabet and may own stock as part of the standard compensation package.
同行评审
同行评审信息
自然thanks Dean Schillinger and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.Peer reviewer reports可用。
附加信息
Publisher’s note关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
扩展数据图和表
Extended Data Fig. 1 User interfaces for the online consultation and evaluation processes.
Online consultations between patient actors and either AMIE or the primary care physicians (PCPs) were conducted by means of a synchronous text-based chat interface.The evaluation process was facilitated through a rating interface in which specialist physicians were provided the scenario information including differential diagnosis answer key, as well as a consultation transcript along with post-questionnaire responses from AMIE or the PCPs.Rating prompts were provided alongside these pieces of information.
Extended Data Fig. 2 DDx top-kaccuracy for non-disease-states and positive disease-states.
a,b:Specialist rated DDx top-kaccuracy for the 149 “positive†scenarios with respect to (一个) the ground-truth diagnosis and (b) the accepted differentials.光盘:Specialist rated DDx top-kaccuracy for the 10 “negative†scenarios with respect to (c) the ground-truth diagnosis and (d) the accepted differentials.Using two-sided bootstrap tests (n = 10,000) with FDR correction, differences in the “positive†scenarios were significant (p <0.05) for all k, but differences in “negative†scenarios were not significant due to the small sample size.Centrelines correspond to the average top-kaccuracy, with 95% confidence intervals shaded.The FDR-adjustedp values for positive disease states, ground-truth comparison: 0.0041 (k = 1), 0.0002 (k = 2), 0.0001 (k = 3), 0.0002 (k = 4), 0.0001 (k = 5), 0.0002 (k = 6), 0.0002 (k = 7), 0.0003 (k = 8), 0.0001 (k = 9) and 0.0001 (k = 10) (一个)。The FDR-adjustedp values for positive disease states, accepted differential comparison: 0.0002 (k = 1), 0.0001 (k = 2), 0.0002 (k = 3), 0.0003 (k = 4), 0.0001 (k = 5), 0.0001 (k = 6), 0.0001 (k = 7), 0.0001 (k = 8), 0.0001 (k = 9) and 0.0001 (k = 10) (b)。The FDR-adjustedp values for non-disease states, ground-truth comparison: 0.1907 (k = 1), 0.1035 (k = 2), 0.1035 (k = 3), 0.1035 (k = 4), 0.1035 (k = 5), 0.1035 (k = 6), 0.1035 (k = 7), 0.1035 (k = 8), 0.1035 (k = 9) and 0.1035 (k = 10) (c)。The FDR-adjustedp values for non-disease states, accepted differential comparison: 0.1035 (k = 1), 0.1035 (k = 2), 0.1829 (k = 3), 0.1035 (k = 4), 0.1035 (k = 5), 0.1035 (k = 6), 0.1035 (k = 7), 0.1035 (k = 8), 0.1035 (k = 9) and 0.1035 (k = 10) (d)。
Extended Data Fig. 3 Specialist rated DDx accuracy by scenario specialty.
顶部-kDDx accuracy for scenarios with respect to the ground-truth in (一个) Cardiology (n = 31, not significant), (b) Gastroenterology (n = 33, not significant), (c) Internal Medicine (n = 16, significant for allk),((d) Neurology (n = 32, significant for k > 5), (e) Obstetrics and Gynaecology (OBGYN)/Urology (n = 15, not significant), (f) Respiratory (n = 32, significant for allk)。Two-sided bootstrap tests (n = 10,000) with FDR correction were used to assess significance (p< 0.05) on these cases.Centrelines correspond to the average top-kaccuracy, with 95% confidence intervals shaded.The FDR-adjustedp values for Cardiology: 0.0911 (k = 1), 0.0637 (k = 2), 0.0637 (k = 3), 0.0911 (k = 4), 0.0911 (k = 5), 0.0929 (k = 6), 0.0929 (k = 7), 0.0929 (k = 8), 0.0929 (k = 9) and 0.0929 (k = 10) (一个)。The FDR-adjustedp values for Gastroenterology: 0.4533 (k = 1), 0.1735 (k = 2), 0.1735 (k = 3), 0.1735 (k = 4), 0.1735 (k = 5), 0.1735 (k = 6), 0.1735 (k = 7), 0.1735 (k = 8), 0.1735 (k = 9) and 0.1735 (k = 10) (b)。The FDR-adjustedp values for Internal Medicine: 0.0016 (k = 1), 0.0102 (k = 2), 0.0216 (k = 3), 0.0216 (k = 4), 0.0013 (k = 5), 0.0013 (k = 6), 0.0013 (k = 7), 0.0013 (k = 8), 0.0013 (k = 9) and 0.0013 (k = 10) (c)。The FDR-adjustedp values for Neurology: 0.2822 (k = 1), 0.1655 (k = 2), 0.1655 (k = 3), 0.069 (k = 4), 0.069 (k = 5), 0.0492 (k = 6), 0.0492 (k = 7), 0.0492 (k = 8), 0.0492 (k = 9) and 0.0492 (k = 10) (d)。The FDR-adjustedp values for OBGYN/Urology: 0.285 (k = 1), 0.1432 (k = 2), 0.1432 (k = 3), 0.1432 (k = 4), 0.1432 (k = 5), 0.1432 (k = 6), 0.1432 (k = 7), 0.1432 (k = 8), 0.1432 (k = 9) and 0.1432 (k = 10) (e)。The FDR-adjustedp values for Respiratory: 0.0004 (k = 1), 0.0004 (k = 2), 0.0004 (k = 3), 0.0004 (k = 4), 0.0004 (k = 5), 0.0006 (k = 6), 0.0006 (k = 7), 0.0006 (k = 8), 0.0006 (k = 9) and 0.0006 (k = 10) (f)。
Extended Data Fig. 4 DDx accuracy by location.
a, b:Specialist DDx rating of AMIE and the PCPs with respect to the ground-truth for the 77 cases conducted in Canada (一个) and 82 cases in India (b)。The differences between AMIE and the PCPs performance are significant for all values ofk。光盘:Auto-evaluation rated DDx for 40 scenarios which were duplicated in both Canada and India for AMIE (c) and the PCPs (d)。The differences between Canada and India performance are not significant on these shared scenarios, for both AMIE and the PCPs.Significance was determined using two-sided bootstrap tests (n = 10,000) with FDR correction.Centrelines correspond to the average top-kaccuracy, with 95% confidence intervals shaded.The FDR-adjustedp values for Canada comparison: 0.0438 (k = 1), 0.0289 (k = 2), 0.0438 (k = 3), 0.0305 (k = 4), 0.0267 (k = 5), 0.0267 (k = 6), 0.0267 (k = 7), 0.0305 (k = 8), 0.0305 (k = 9) and 0.0276 (k = 10) (一个)。The FDR-adjustedp values for India comparison: 0.0037 (k = 1), 0.0005 (k = 2), 0.0005 (k = 3), 0.0013 (k = 4), 0.0013 (k = 5), 0.0009 (k = 6), 0.0009 (k = 7), 0.0005 (k = 8), 0.0005 (k = 9) and 0.0005 (k = 10) (b)。The FDR-adjustedp values for shared AMIE scenarios: 0.3465 (k = 1), 0.3465 (k = 2), 0.4109 (k = 3), 0.4109 (k = 4), 0.3465 (k = 5), 0.3465 (k = 6), 0.3465 (k = 7), 0.3465 (k = 8), 0.3465 (k = 9) and 0.3465 (k = 10) (c)。The FDR-adjustedp values for shared PCP scenarios: 0.3905 (k = 1), 0.4356 (k = 2), 0.3905 (k = 3), 0.3905 (k = 4), 0.3905 (k = 5), 0.3905 (k = 6), 0.3905 (k = 7), 0.3905 (k = 8), 0.3905 (k = 9) and 0.3905 (k = 10) (d)。
Extended Data Fig. 5 Auto-evaluation of DDx performance.
a, b:顶部-kDDx auto-evaluation of AMIE’s and the PCP’s differential diagnoses from their own consultations with respect to the ground-truth (一个, significant fork> 3) and the list of accepted differentials (b, significant fork> 4).光盘:顶部-kDDx auto-evaluation of AMIE’s differential diagnoses when provided its own vs. the PCP’s consultation transcript with respect to the ground-truth (c, not significant) and the list of accepted differentials (d, not significant).Two-sided bootstrap tests (n = 10,000) with FDR correction were used to assess significance (p< 0.05) on these 159 cases.Centrelines correspond to the average top-kaccuracy, with 95% confidence intervals shaded.The FDR-adjustedp values for AMIE vs. the PCP ground-truth comparison: 0.1399 (k = 1), 0.0737 (k = 2), 0.0596 (k = 3), 0.0315 (k = 4), 0.0221 (k = 5), 0.0315 (k = 6), 0.0182 (k = 7), 0.0221 (k = 8), 0.0182 (k = 9) and 0.0182 (k = 10) (一个)。The FDR-adjustedp values for AMIE vs. the PCP accepted differential comparison: 0.2297 (k = 1), 0.1713 (k = 2), 0.0779 (k = 3), 0.0546 (k = 4), 0.018 (k = 5), 0.0174 (k = 6), 0.006 (k = 7), 0.0033 (k = 8), 0.0033 (k = 9) and 0.0033 (k = 10) (b)。The FDR-adjustedp values for AMIE vs. the PCP consultation ground-truth comparison: 0.4929 (k = 1), 0.4929 (k = 2), 0.4929 (k = 3), 0.4929 (k = 4), 0.4929 (k = 5), 0.4929 (k = 6), 0.4929 (k = 7), 0.4929 (k = 8), 0.4929 (k = 9) and 0.4929 (k = 10) (c)。The FDR-adjustedp values for AMIE vs. the PCP consultation accepted differential comparison: 0.4461 (k = 1), 0.4461 (k = 2), 0.4461 (k = 3), 0.4461 (k = 4), 0.4461 (k = 5), 0.4461 (k = 6), 0.4461 (k = 7), 0.4461 (k = 8), 0.4461 (k = 9) and 0.4461 (k = 10) (d)。
Extended Data Fig. 6 Consultation verbosity and efficiency of information acquisition.一个
, Total patient actor words elicited by AMIE and the PCPs.b, Total words sent to patient actor from AMIE and the PCPs.c, Total number of turns in AMIE vs. the PCP consultations.为了 (a-c), Centrelines correspond to the median, with the box indicating 25th and 75th percentiles.The minimum and maximum are presented as the bottom and top whiskers, respectively, excluding the outliers which are defined as data points further than 1.5 times the inter-quartile range from the box.d, e:The top-3 auto-evaluation rated DDx accuracy of AMIE using the firsttturns of each consultation, with respect to the ground-truth diagnosis (d) and the accepted differentials (e)。Differences on these 159 cases are not significant (p> 0.05) when compared through two-sided bootstrap tests (n = 10,000) with FDR correction.Centrelines correspond to the average top-3 accuracy, with 95% confidence intervals shaded.
补充信息
权利和权限
开放访问This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/4.0/。重印和权限
引用本文

Tu, T., Schaekermann, M., Palepu, A.
等。Towards conversational diagnostic artificial intelligence.自然(2025)。https://doi.org/10.1038/s41586-025-08866-7
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41586-025-08866-7