
通过运输激活来控制语言和扩散模型
大型生成模型正变得越来越有能力,并且更广泛地部署到电力生产应用程序中,但是让这些模型确切地生成所需的东西仍然具有挑战性。对这些模型的输出的细粒度控制对于满足用户的期望和减轻潜在的滥用非常重要,从而确保了模型的可靠性和安全性。为了解决这些问题,Apple机器学习研究人员开发了一种新技术,该技术具有模态性不足的态度,并通过微不足道的计算开销对模型的行为进行了精细的控制,同时对模型的能力产生了最小的影响。激活运输(ACT)是一个以最佳运输理论为指导的引导激活的一般框架,该理论概括了许多先前的激活驱动作品。这项工作将作为聚光灯列出ICLR 2025和代码可用这里。
为了帮助生成模型产生与用户期望保持一致的输出,研究人员通常会依靠人为反馈(RLHF)或指导进行微调的强化学习,但是这些方法是资源密集的,并且随着模型的复杂性的增长而变得越来越不切实际。此外,更改模型的参数可能会产生意想不到的后果,从而影响其在其他任务上的整体绩效。
为了控制这些生成模型的输出,用户经常尝试制作精确的提示,但是尽管更易于使用,但它提供了有限的控件。即使有经过精心构造的提示,模型的输出也可能是无法预测的,并且缺乏用户可能需要的细微差别。例如,在提示说明不包含某些内容的指示时,模型不常见的常见(见图1):

在许多应用程序中,例如内容生成,创意写作甚至AI辅助设计,对模型的输出具有精细的控制至关重要。例如,用户可能希望在不更改其内容的情况下调整文本的音调,在维护其上下文的同时更改生成的图像的样式,或者确保谨慎处理敏感的主题,而不会损害整体一致性。激活传输(ACT)提供了这一点,而没有计算开销,复杂性和RLHF或微调所需的数据量,并且比及时工程更可靠的结果。
激活转向:一种简单的解决方案
微调大型模型的计算和经济成本以及对细粒度控制的需求激发了对模型激活的有针对性干预措施的研究,以以细粒度的方式修改特定行为。这些“激活转向”方法的主要优点是它们不需要后传播,通常可以将其合并到模型权重中。
与RLHF或微调不同,激活转向不会影响模型的参数,而是利用对模型操作的理解,将其输出动态转向推理时的期望方向。
先前的激活转向方法使用了基于矢量的干预措施,该干预措施将专家神经元的源激活进行,并将其转移到学习的目标(见图2)。但是,激活转移的程度由无界模型级参数(â»\ lambda)控制,从而使可解释的干预措施具有挑战性。此外,这些干预措施可以将激活转移到分布中,这意味着转移的激活可能与模型在训练过程中所学到的期望相去甚远,从而导致模型的自然动力学破坏,从而导致意外的行为和降低性能。
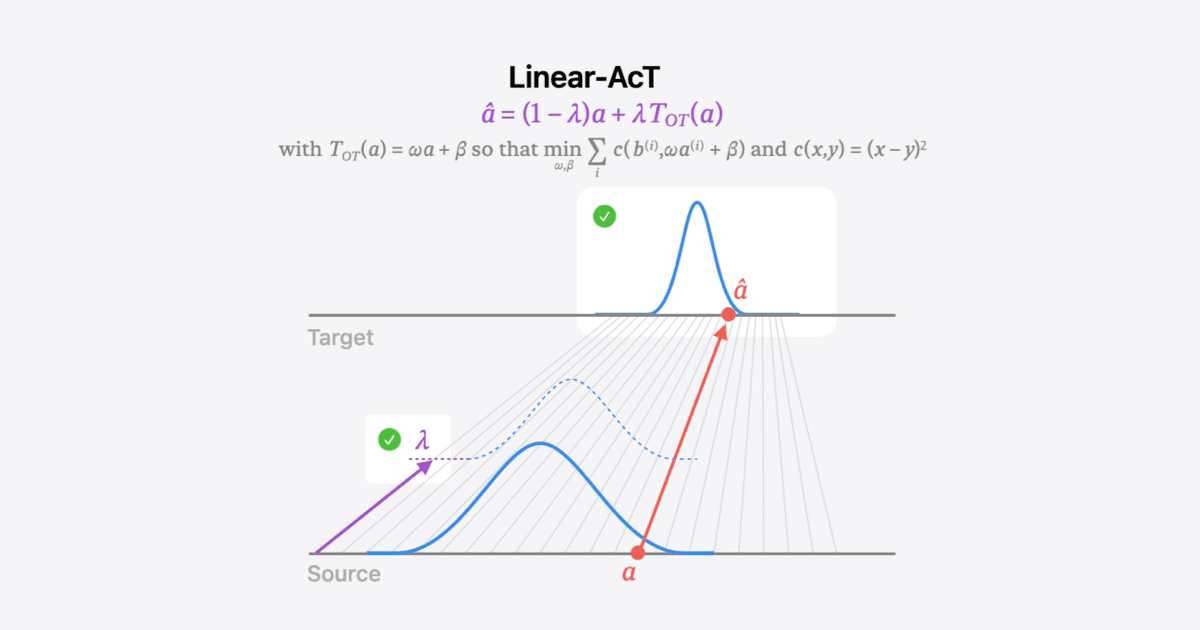
激活转运(ACT)和线性动作
激活传输(ACT)是一个新颖的干预框架,它通过考虑源和目标激活的分布以及使用可解释且可操作的强度参数来超越激活转向的先前局限性。
ACT了解源和目标激活分布之间的最佳传输(OT)图。这样可以确保从源传输的激活将符合目标分布,从而最大程度地减少对模型本身动力学的复合影响。为了估计ot映射,少数示例句子(例如数百个)通过模型运行,揭示了源(例如,不礼貌的语言)和目标(例如,礼貌语言)的激活集。
估计多维和可能的非线性OT图需要大量的数据,其推断将减慢整体LLM文本生成。因此,我们进行了两个简化:(1)我们考虑独立的激活,该激活允许每个神经元估算1D地图,(2)我们考虑线性图,限制内存足迹并确保快速推断。线性和独立运输的转向是线性的(见图3)。
线性动作在LLM的开箱即用以及文本对图像(T2I)扩散模型,在这两种情况下都取得了强大的结果。这是提出条件算法的第一项工作,该算法无需任何修改语言和图像生成。
用线性操作控制LLM输出
为了证明线性动作在控制LLMS的产出方面的有效性,我们将其在两个重要任务上的性能进行了基准测试:降低毒性和真实性诱导,同时监视其他性能指标如何通过困惑(PPL)和MMLU指标影响。
我们在Gemma-2-2b和Llama-3-8B上测试了降低毒性的线性动作(使用RealtoxicityPrompts数据集进行了评估),分别降低了7.5倍和4.3倍。
| 最好的â» | 毒性降低 | ppl | mmlu | |
| 原来的 | 13.98 | 53.1 | ||
| actadd | 0.5 | 1.1倍 | 14.69 | 53.0 |
| 光环 | - | 2.0x | 14.18 | 53.0 |
| iti-c | 8.0 | 5.6倍 | 14.90 | 52.6 |
| 线性动作 | 1.0 | 7.5倍 | 14.79 | 51.3 |
| 最好的â» | 毒性降低 | ppl | mmlu | |
| 原来的 | 9.06 | 65.3 | ||
| actadd | 0.3 | 1.0x | 9.71 | 65.5 |
| 光环 | - | 3.1倍 | 9.52 | 65.5 |
| iti-c | 3.0 | 3.6倍 | 9.48 | 64.7 |
| 线性动作 | 1.0 | 4.3倍 | 9.56 | 64.5 |
我们测试了真实性诱导(使用真实性数据集),显示了每个模型的4.9倍和7.5倍。
| 最好的â» | 真实(MC1 ACC) | mmlu | |
| 原来的 | 21.05 | 53.10 | |
| actadd | 3.0 | 23.01 | 52.83 |
| 光环 | - | 21.20 | 52.73 |
| iti-c | 2.0 | 24.53 | 51.39 |
| 线性动作 | 1.0 | 26.00 | 51.47 |
| 最好的â» | 真实(MC1 ACC) | mmlu | |
| 原来的 | 25.46 | 65.35 | |
| actadd | 0.7 | 26.19 | 65.42 |
| 光环 | - | 25.34 | 65.37 |
| iti-c | 2.0 | 30.11 | 64.71 |
| 线性动作 | 1.0 | 33.22 | 64.78 |
通过线性操作控制文本对图像扩散模型
文本到图像扩散模型(T2IS)是强大的工具,可让用户从简单的文本描述中生成令人惊叹的图像。但是,细粒度的控制是具有挑战性的。例如,不可能执行增量更改,例如添加更多树木或使风格稍微稍微更漫画,或者可靠地预测诸如“许多树”之类的术语将如何影响生成的图像。
由于ACT可以将激活从一个分布传输到另一个分布,无论模型架构或模式如何(见图4)。为此,ACT只需要描述来源(例如,没有人)和目标(例如,人)激活分布的提示列表。
为绘画风格的精细控制
ACT还可以控制生成图像的艺术风格。为了证明这一点,我们将风格标签(例如动漫,Cyberpunk,Watercolor)附加到可可字幕数据集中的一部分(每个概念提示)中。
在此设置中,原始提示可以用作源分布,而样式修饰的提示则表示目标分布。通过学习这些分布之间的ot图,并通过可解释的强度参数应用这些地图,ACT获得了诱导适当数量的所需样式的能力(见图5)。
不要考虑粉红色的大象
上面的标题可能会导致读者考虑一头粉红色的大象 - 有趣的是,发现同样的现象发生在T2IS中(见图6)。如果T2IS的文本编码嵌入句子作为一袋单词,并且不足以解释否定,但通常是这样的情况是,在提示中包括负面指令(例如,“不要显示粉红色的大象”)实际上会导致T2I模型以在图像中包含不希望的元素。

线性动作是一种干预措施,可以应对这一挑战并从生成的图像中删除不希望的概念。为此,需要一组包含要删除的概念的源提示(例如,“旁边的一栋房屋和一棵树和一棵树”),以及一组目标提示,其中不存在该概念的地方(例如,“一座房子和树”)。主要思想是“隔离”要删除的概念作为提示集之间的主要区别。线性操作从源到目标集的运输地图学习,导致可控的干预措施可以消除否定的概念(例如“粉红色大象”),否则该概念将包含在生成的模型中,如图所示图7。

结论
随着生成语言和文本对图像模型的能力和生产部署不断增长,提供对其产出的细粒度控制越来越重要。虽然诸如RLHF和指导微调之类的常见方法在改善LLM输出与用户期望的一致性方面有效,但这些方法是资源密集的,并且随着模型在复杂性上的增长而变得不切实际。激活转运(ACT)可对LLM和T2I扩散模型的输出进行细粒度的控制,而无需RLHF和微调的局限性。根据最佳运输理论进行转向激活的这种通用框架是模态性不足的,需要可忽略的计算开销,研究人员和从业者现在可以使用可用的代码来使用和建立ACT这里。
相关的读数和更新。
大型生成模型及其越来越广泛的部署的能力不断提高,这引起了人们对它们的可靠性,安全性和潜在滥用的担忧。为了解决这些问题,最近的工作提议通过转向模型激活来控制模型生成,以有效地诱导或防止生成的输出中概念或行为的出现。在本文中,我们引入了激活运输(ACT)