

AI编码工具的持续扩散不仅提高了开发人员的效率,而且还标志着AI将在所有新代码中占有越来越大的份额。Github首席执行官Thomas Dohmke(在新标签中打开)在2023年,他说的是,当他更早地说,副代码将由Copilot撰写80%的代码。
大型和小型软件公司都已经大量使用AI来生成代码。Y组合者的Garry Tan(在新标签中打开)指出,大型语言模型编写了Y Combinator最新一批初创企业的四分之一代码的95%。
实际上,大多数开发人员将大部分时间都花在调试代码上,不写它。作为流行的开源存储库的维护者,这引起了我们的共鸣。但是,如果AI工具可以解决数百个开放问题的修复,而我们要做的就是在合并之前批准它们呢?这就是促使我们通过教会调试代码来最大程度地节省AI编码工具的时间。
通过调试,我们是指修复代码的交互式,迭代过程。开发人员通常假设其代码崩溃了,然后通过逐步浏览程序并检查变量值来收集证据。他们经常使用PDB(Python调试器)等调试工具来协助收集信息。重复此过程,直到固定代码为止。
如今,S AI编码工具提高了生产力,并在基于可用代码和错误消息的错误建议方面提高了解决方案。但是,与人类开发人员不同,这些工具在解决方案失败时不会寻求其他信息,而某些错误则没有解决,您可以在此简单中看到当今的标记柱子模块如何编码工具的演示如何(在新标签中打开)。这可能会使用户感觉像AI编码工具一样,不了解他们要解决的问题的完整背景。
介绍DEBUG-GYM
出现了一个自然的研究问题:LLM可以在什么程度上使用交互式调试工具,例如PDB?为了探索这个问题,我们发布了Debug-Gym(在新标签中打开)``一个环境,允许代码修复代理访问用于主动信息寻求信息行为的工具。Debug-Gym通过工具使用情况的反馈,启用设置断点,导航代码,打印变量值并创建测试功能,扩展了代理的动作和观察空间。如果有信心,代理可以与工具进行研究以调查代码或重写它。我们认为,使用适当的工具进行交互式调试可以增强编码代理以应对现实世界软件工程任务,并且是基于LLM的代理研究的核心。具有调试功能的编码代理提出的修复程序,然后由人类程序员批准,将基于相关代码库,程序执行和文档的背景,而不是仅仅基于先前看到的培训数据而依靠猜测。
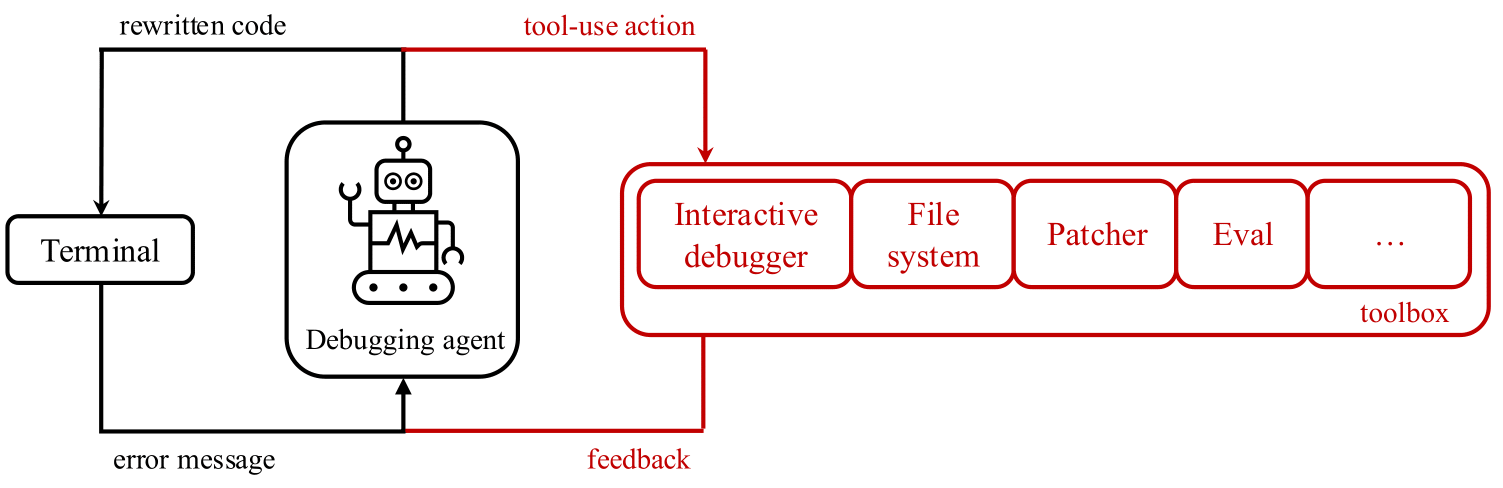
DEBUG-GYM的设计和开发到:
- 处理存储库级信息:完整的存储库可用于调试gym的代理商,使其可以导航和编辑文件。
- 坚强而安全:为了保护系统和开发过程,Debug-Gym在沙盒Docker容器中运行代码。这可以隔离运行时环境,防止有害行动,同时仍允许进行彻底的测试和调试。
- 容易扩展:debug-gym构想了可扩展性,并为从业者提供了轻松添加新工具的可能性。”
- 基于文本:debug-gym代表结构化文本(例如JSON格式)中的观察信息,并为文本动作定义了简单的语法,使环境与现代基于LLM的代理完全兼容。
借助Debug-Gym,研究人员和开发人员可以指定与任何自定义存储库一起评估其调试代理商的性能的文件夹路径。此外,Debug-Gym还包括三个编码基准测试,以测量互动调试中的基于LLM的代理商的性能:简单功能级代码生成的辅助,用于短,手工制作的小型货物代码示例的迷你夜间示例,以及用于现实编码问题的SWE-BENCH,需要全面了解大型Codebase和Gitib os a github of Github of github os github of Github的解决方案。
要了解有关Debug-Gym并开始使用它来培训您自己的调试代理商的更多信息,请参考技术报告(在新标签中打开)和github(在新标签中打开)。一个
早期实验:有希望的信号
为了初步尝试验证LLMS在可以访问调试工具时在编码测试方面的表现更好,我们构建了一个简单的基于提示的代理,并为其提供了对以下调试工具的访问:eval,View,PDB,重写和ListDir。我们使用九种不同的LLM作为代理的骨干。可以在技术报告(在新标签中打开)。(在新标签中打开)
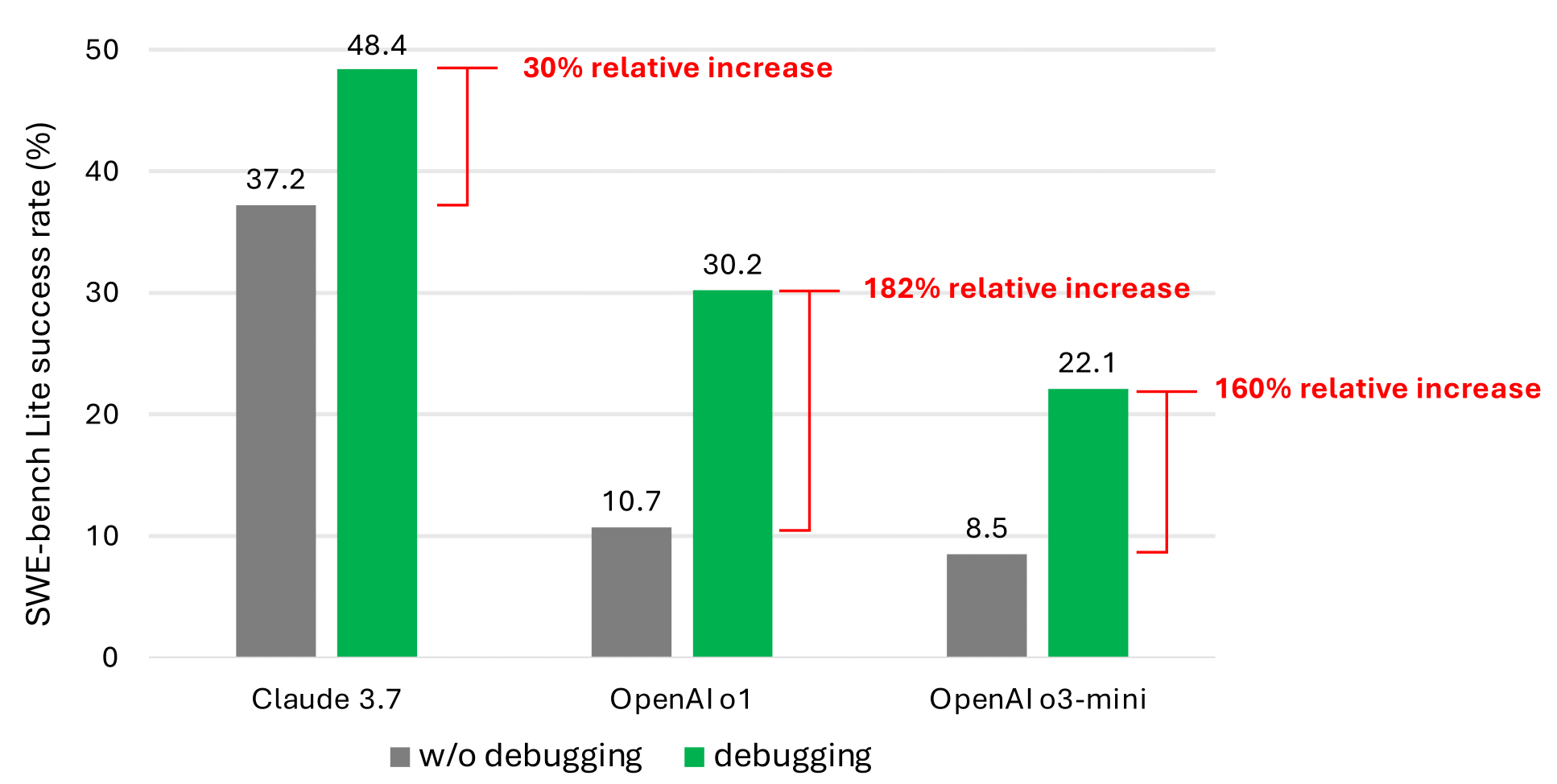
即使使用调试工具,我们简单的基于及时的代理也很少解决一半以上SWE板凳(在新标签中打开)精简版问题。我们认为,这是由于当前LLM培训语料库中代表顺序决策行为的数据稀缺(例如,调试痕迹)。但是,绩效的显着改善(如下图中最有希望的结果所示)证实了这是一个有希望的研究方向。
微软研究播客

你的故事是什么:lex故事
模型制造商和制造商Lex的故事有助于通过原型制作使研究栩栩如生。他讨论了自己的失败的看法。支持他追求艺术和科学的鼓励和建议;放假可能会激发他的下一个职业生涯。
未来的工作
我们认为,培训或微调LLM可以增强其互动调试能力。这需要专门的数据,例如记录与调试器相互作用的代理人在建议修复之前收集信息的轨迹数据。与传统的推理问题不同,交互式调试涉及在触发环境反馈的每个步骤中生成动作。此反馈有助于代理做出新的决策,需要密集的数据,例如问题描述和导致解决方案的动作顺序。
我们的计划是微调寻求信息的模型,专门收集必要的信息以解决错误。目的是使用此模型积极地为代码生成模型构建相关上下文。如果代码生成模型很大,则有机会构建一个较小的信息寻求模型,该模型可以向较大的信息提供相关信息,例如,检索增强发电(RAG)的概括,从而节省了AI推理成本。在加固学习循环期间收集的数据训练信息寻求模型也可以用于微调更大的模型以进行交互式调试。
我们正在开源调试,以促进这一研究。我们鼓励社区帮助我们推进这项研究,以建立交互式调试代理,更普遍地,可以通过需求与世界互动来寻求信息。
致谢
我们感谢Ruoyao Wang关于建立互动调试代理商,Chris Templeman和Elaina Maffeo的团队教练,Jessica Mastronardi和Rich Ciapala在项目管理和资源分配中提供的友好支持,以及Peter Jansen为技术报告提供了宝贵的反馈,他们提供了良好的支持。