


赞助功能:早在AI工厂之前,就有两代人的AI桥接云基础设施超级计算机,该基金会由日本国家高级工业科学技术研究所(AIST)建造。AIST创建了可以说是第一个AI工厂,将加速计算平台与云基础架构软件合并,以构建一个共享的实用程序,供日本研究人员进行AI实验。
早在2017年3月,当AIST AIS AI云(AAIC)为ABCI超级计算机的原型是由NEC构建的,GPU加速了可及时且可租金的计算,在日本尚不常见,即使在北美,欧洲和中国建造的较大云中,也没有广泛使用。
AAIC机器具有50个两杆的Broadwell - Xeon E5 V4节点,每个节点均为八个NVIDIApascalâP100p100 SXM GPU加速器。AAIC机器从运行IBM的GPFS文件系统的Datadirect网络中具有4 pb的群集存储,并使用了100 GB/sec EDR Infiniband Director切换将它们粘合在一起。
在各种AI和数据分析工作负载上证明了AI云概念,并组装了更多的资金来构建具有足够的规模来进行更重的AI研究的东西。
竞争性竞标后,AIST于2017年10月攻击系统制造商Fujitsu以创建ABCI 1.0这是世界上第一个AI工厂本质上的超级计算机 - NVIDIA创造了一个术语来谈论生产级别的云式AI群集。ABCI 1.0也是人们现在所说的“主权AI”的一个例子,这意味着AI旨在加强不想仅仅依赖于高分和云建设者的AI计算能力的民族国家能力。
ABCI 1.0机器的成本为50亿日元。建造了一个新的数据中心,以容纳东京大学Kashiwa II校园的ABCI 1.0机器。
ABCI 1.0机器是基于高分标和云制造商首先创建的服务器雪橇设计,这是合适的,以提高基础架构的密度。ABCI 1.0具有1,088个Fujitsu的Primergy CX2570服务器节点,它们是半宽的服务器雪橇,滑入Primergy CX400 2U机箱。每个雪橇都有两个Intel skylake -Xeon SP处理器,其中四个Nvidiavoltaâv100SXM2 GPU加速器。2,176个CPU插座和4,352个GPU插座。与AAIC原型中使用的P100 GPU相比,GPU上的Volta GPU是第一个在GPU上提供16位半精确张量核心单元的人,从而从根本上提高了AI训练和推理性能。
ABCI 1.0系统有两个EDR Infiniband端口以200 GB/sec运行,所有端口都链接在三层脂肪树中,并具有3:1的超额认可。
ABCI 1.0系统于2018年8月投入运行,其中包括来自HPC社区的软件,以及您可能希望的。该系统支持奇异性和Docker容器,以包装应用程序,并同时管理它们,以及许多同时运行的用户。随着AI研究本身的发展,ABCI堆栈一直在不断发展和变化,其中包括:
- 光泽和GPFS并行文件系统
- Beegfs,Beeond文件系统
- Scality环对象存储
- Altair Gridengine工作调度程序
- Apache Hadoop
- MPI,OpenMP,OpenACC,CUDA和OPENCL并行编程环境,特别是包括NVIDIA NCCL和Intel MPI
- 各种编程语言和其他工具,以及Python,Ruby,R,Java,Scala,Go,Julia。Perl和Jupyter笔记本一起很重要
- SPACK软件包管理器
- 超级计算机的开放式网络接口
- 大量的机器学习库和AI框架
2021年5月,AIST在ABCI 1.0群集上添加了扩展名,当然称为ABCI 2.0,它基于Fujitsu的Primergy GX2570-M6服务器增加了120个节点。ABCI节点使用了一对Intel的Icelake Xeon SP处理器和Nvidia Quantum 200 Gb/sec Infiniband Infonnects(每个节点四个)绑有节点(每个节点都有八个NVIDIA nvidiaampereâmpereâampereâampere - a100 sxm4 gpus)。Infiniband InterConnect是一个两层网络,在脂肪树拓扑结构中具有完整的双截面带宽。
这是ABCI 1.0和ABCI 2.0机器的框图:

ABCI 2.0扩展名成本€20亿日元。通过升级,以FP64精度将所得的簇提高到56.2 PETAFLOPS,FP32精度为224.4 PETAFLOPS和FP16精确度的850 PETAFLOPS。这代表了超过50%的绩效,预算增加了约40%。有趣的是,使用2.0扩展程序添加了为HPC人群创建的奇点容器平台。奇异性支持以NIM格式部署的NVIDIA推理工具,这对于易用性很重要。
新的ABCI 3.0系统是一个全新的集群,而不是ABCI 1.0/ABCI 2.0混合动力的扩展于2024年7月宣布自今年1月以来一直在运营。这次,惠利特·帕卡德企业(Hewlett Packard Enterprise)赢得了合同。
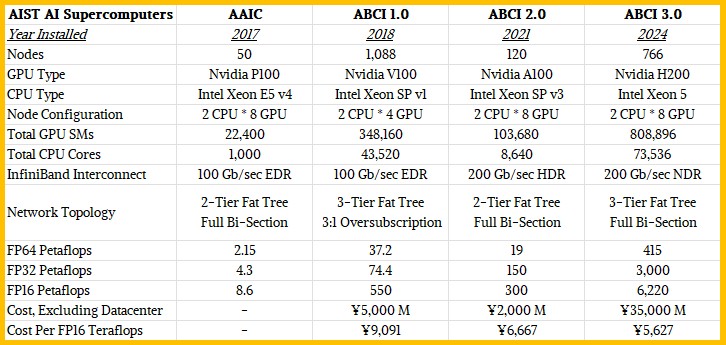
AI超级计算机系统基于HPE的Cray XD670服务器平台,在这种情况下,有一对翡翠急流Xeon 5处理器,每个处理器具有48个内核,并耦合到来自NVIDIA。H200 GPU具有141 GB的HBM3E,可提供4.8 TB/秒的内存带宽。内存容量和内存带宽对于AI工作负载都很重要。事实也是,料斗GPU的额外记忆和带宽可以比以前的H100更接近其在实际工作负载上的峰值理论表现,后者具有80 GB或96 GB的HBM3内存,并且3.35 TB/sec或3.9 TB/sec/sec/sec/sec/sec/sec/sec/sec/sec/sec/sec的记忆带宽。
ABCI 3.0系统中有766个Cray XD670节点,而ABCI 3.0系统中的6,128 GPU通过200 GB/sec NDR Quantum Infiniband互连连接。每个GPU都有一个200 GB/sec的端口,并且由三层,完整的双截面带宽脂肪树Infiniband网络交叉连接。每个节点中有其他100 GB/sec hdr infiniband端口用于主机通信和管理。
ABCI 3.0群集的成本为350亿日元,这是如今高端HPC或AI系统的成本。ABCI机器在FP64精度下为415 PETAFLOPS,FP32精度为3.0 Exaflops,在FP16精度下为6.22 Exaflops。

ABCI 3.0机器提供的价格/性能优于联合ABCI 1.0和ABCI 2.0机器,其FP64 Oomph多7.4倍,FP32 OOMPH的效率高13.4倍,而FP16 OOMPH多7.3倍。ABCI 3.0机器的成本为5倍,以构建为ABCI 1.0和ABCI 2.0机器,但在FP16工作中,对AI工作负载至关重要的FP16工作的速度增长了31.7%。
也许最有趣的是,随着时间的推动,AIST与ABCI机器的任务发生了变化,就像它的硬件配置已经前进一样。
AIST副领导人Ryousei Takano告诉2017年,尽管该行业对该行业产生了浓厚的兴趣,但AI的采用并没有取得预期的进展。下一个平台。``没有地方可以有效地进行大规模的AI实验。为每个人提供AI基础设施是我们创建ABCI 1.0的强大动力。多年来,景观发生了变化,国内商业云提供商(例如Sakura Internet,Softbank,KDDI和GMO Internet)现在提供AI数据中心。我们认为,我们的角色也需要重新考虑。借助ABCI 3.0,资源主要分配给公共和战略研发目的,尤其是国家机构,大学和初创公司。通过与国内云提供商共享和转移我们的经验,我们旨在帮助他们在AI数据中心市场中变得更有竞争力。”
ABCI系统为大约3,000个用户提供了多样化的用户群,从AI初创公司到大型电子制造商。主要用例是培训AI模型,当然是大型语言模型。LLM建筑支持计划由AIST于2023年8月启动,并促进了最先进的日本LLM,例如PLAMO和燕子。
作为下一步,我们希望使用ABCI支持网络物理系统或物理AI的实现,在该系统中感知现实世界,使用AI技术对数据进行分析和模拟,并将结果馈回机器人,” Takano解释说。”
您可能想象的,AIST期待看到它如何将其模型的精度降低到hopper GPU固有的FP8四分之一精确的浮点格式。
展望未来,没有确切的计划可以升级到ABCI 4.0。Takano说,目的是在未来几年内逐步更新ABCI 3.0,与用户需求和技术进步保持一致。关于采用未来GPU或网络互连的任何决定,都将根据新兴趋势做出,并预测ABCI系统用户的要求。
由Nvidia赞助。

注册我们的新闻通讯
直接从我们到您的收件箱中,介绍了一周的亮点,分析和故事,两者之间一无所有。
立即订阅