

A Field Guide to Rapidly Improving AI Products
作者:Hamel Husain
Most AI teams focus on the wrong things. Hereâs a common scene from my consulting work:
AI TEAM
Hereâs our agent architectureâweâve got RAG here, a router there, and weâre using this new framework forâ¦ME
[Holding up my hand to pause the enthusiastic tech lead]
Can you show me how youâre measuring if any of this actually works?⦠Room goes quiet

Learn faster. Dig deeper. See farther.
This scene has played out dozens of times over the last two years. Teams invest weeks building complex AI systems but canât tell me if their changes are helping or hurting.
This isnât surprising. With new tools and frameworks emerging weekly, itâs natural to focus on tangible things we can controlâwhich vector database to use, which LLM provider to choose, which agent framework to adopt. But after helping 30+ companies build AI products, Iâve discovered that the teams who succeed barely talk about tools at all. Instead, they obsess over measurement and iteration.
In this post, Iâll show you exactly how these successful teams operate. While every situation is unique, youâll see patterns that apply regardless of your domain or team size. Letâs start by examining the most common mistake I see teams makeâone that derails AI projects before they even begin.
The Most Common Mistake: Skipping Error Analysis
The âtools firstâ mindset is the most common mistake in AI development. Teams get caught up in architecture diagrams, frameworks, and dashboards while neglecting the process of actually understanding whatâs working and what isnât.
One client proudly showed me this evaluation dashboard:
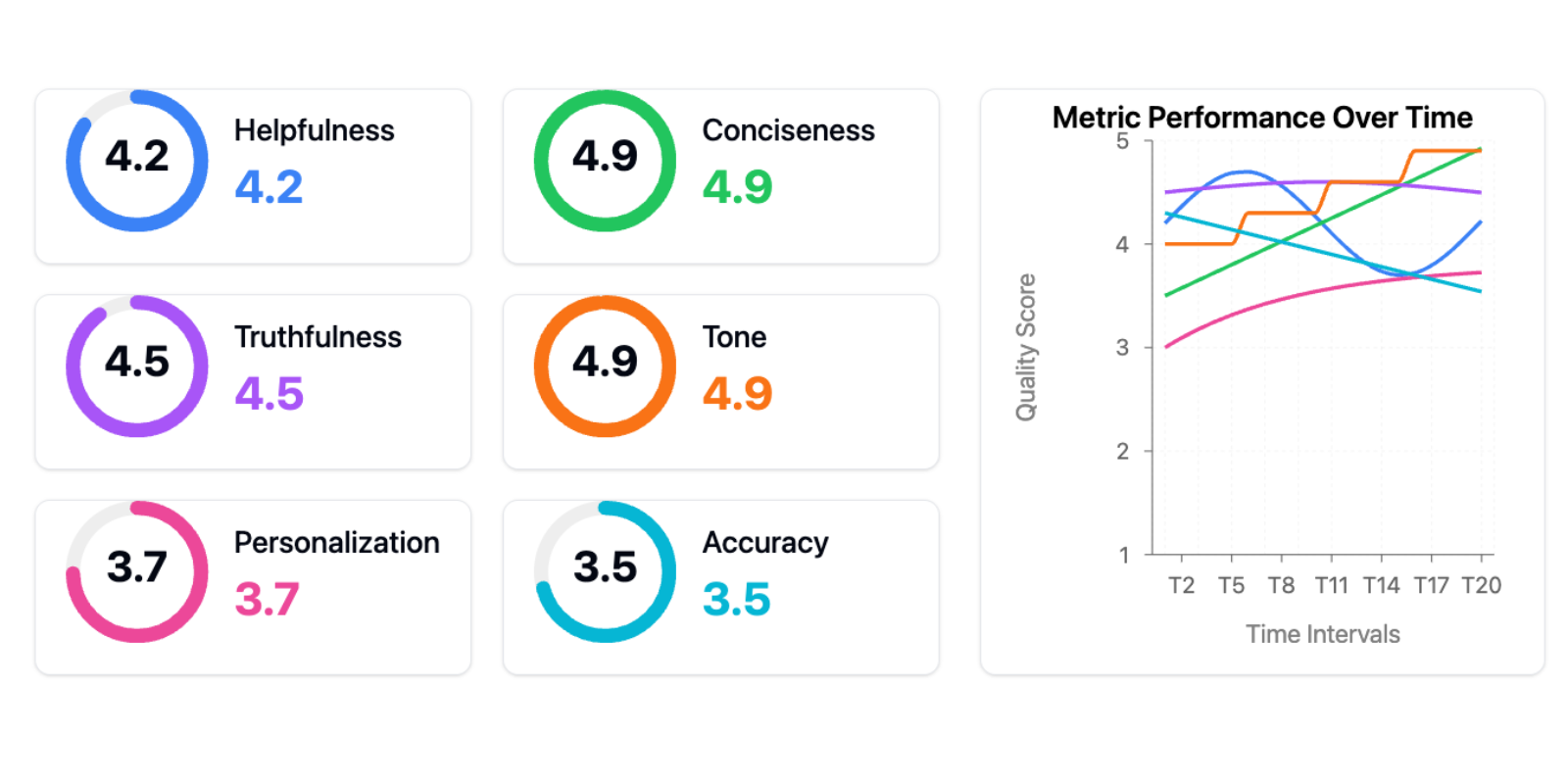
This is the âtools trapââthe belief that adopting the right tools or frameworks (in this case, generic metrics) will solve your AI problems. Generic metrics are worse than uselessâthey actively impede progress in two ways:
First, they create a false sense of measurement and progress. Teams think theyâre data-driven because they have dashboards, but theyâre tracking vanity metrics that donât correlate with real user problems. Iâve seen teams celebrate improving their âhelpfulness scoreâ by 10% while their actual users were still struggling with basic tasks. Itâs like optimizing your websiteâs load time while your checkout process is brokenâyouâre getting better at the wrong thing.
Second, too many metrics fragment your attention. Instead of focusing on the few metrics that matter for your specific use case, youâre trying to optimize multiple dimensions simultaneously. When everything is important, nothing is.
The alternative? Error analysis: the single most valuable activity in AI development and consistently the highest-ROI activity. Let me show you what effective error analysis looks like in practice.
The Error Analysis Process
When Jacob, the founder of Nurture Boss, needed to improve the company’s apartment-industry AI assistant, his team built a simple viewer to examine conversations between their AI and users. Next to each conversation was a space for open-ended notes about failure modes.
After annotating dozens of conversations, clear patterns emerged. Their AI was struggling with date handlingâfailing 66% of the time when users said things like âLetâs schedule a tour two weeks from now.â
Instead of reaching for new tools, they:
- Looked at actual conversation logs
- Categorized the types of date-handling failures
- Built specific tests to catch these issues
- Measured improvement on these metrics
The result? Their date handling success rate improved from 33% to 95%.
Hereâs Jacob explaining this process himself:
Bottom-Up Versus Top-Down Analysis
When identifying error types, you can take either a âtop-downâ or âbottom-upâ approach.
The top-down approach starts with common metrics like âhallucinationâ or âtoxicityâ plus metrics unique to your task. While convenient, it often misses domain-specific issues.
The more effective bottom-up approach forces you to look at actual data and let metrics naturally emerge. At Nurture Boss, we started with a spreadsheet where each row represented a conversation. We wrote open-ended notes on any undesired behavior. Then we used an LLM to build a taxonomy of common failure modes. Finally, we mapped each row to specific failure mode labels and counted the frequency of each issue.
The results were strikingâjust three issues accounted for over 60% of all problems:
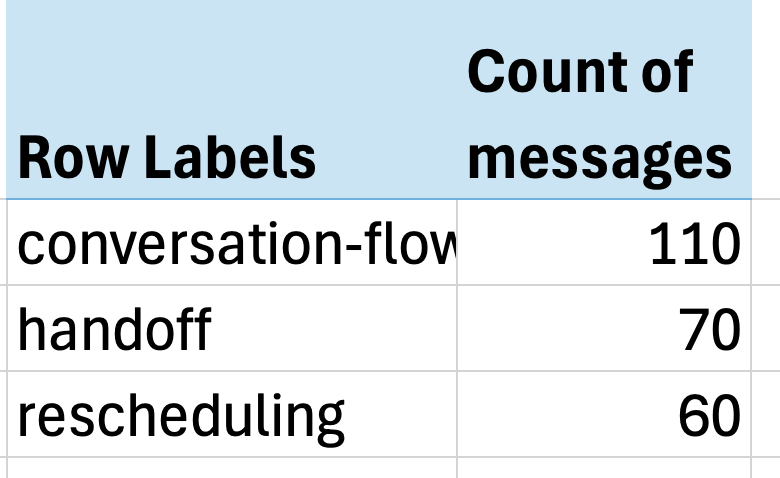
- Conversation flow issues (missing context, awkward responses)
- Handoff failures (not recognizing when to transfer to humans)
- Rescheduling problems (struggling with date handling)
The impact was immediate. Jacobâs team had uncovered so many actionable insights that they needed several weeks just to implement fixes for the problems weâd already found.
If youâd like to see error analysis in action, we recorded a live walkthrough here.
This brings us to a crucial question: How do you make it easy for teams to look at their data? The answer leads us to what I consider the most important investment any AI team can makeâ¦
The Most Important AI Investment: A Simple Data Viewer
The single most impactful investment Iâve seen AI teams make isnât a fancy evaluation dashboardâitâs building a customized interface that lets anyone examine what their AI is actually doing. I emphasize customized because every domain has unique needs that off-the-shelf tools rarely address. When reviewing apartment leasing conversations, you need to see the full chat history and scheduling context. For real-estate queries, you need the property details and source documents right there. Even small UX decisionsâlike where to place metadata or which filters to exposeâcan make the difference between a tool people actually use and one they avoid.
Iâve watched teams struggle with generic labeling interfaces, hunting through multiple systems just to understand a single interaction. The friction adds up: clicking through to different systems to see context, copying error descriptions into separate tracking sheets, switching between tools to verify information. This friction doesnât just slow teams downâit actively discourages the kind of systematic analysis that catches subtle issues.
Teams with thoughtfully designed data viewers iterate 10x faster than those without them. And hereâs the thing: These tools can be built in hours using AI-assisted development (like Cursor or Loveable). The investment is minimal compared to the returns.
Let me show you what I mean. Hereâs the data viewer built for Nurture Boss (which I discussed earlier):
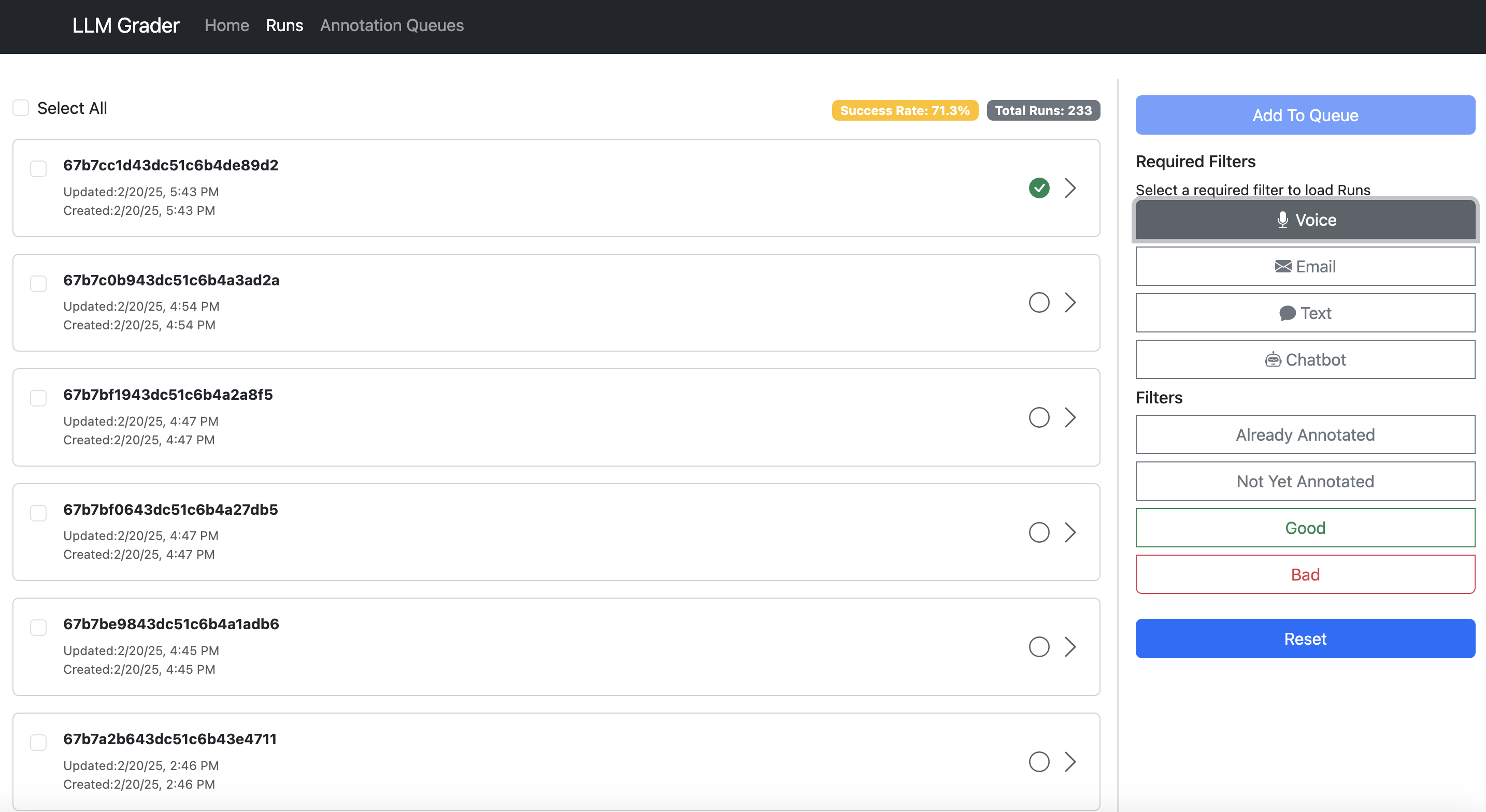
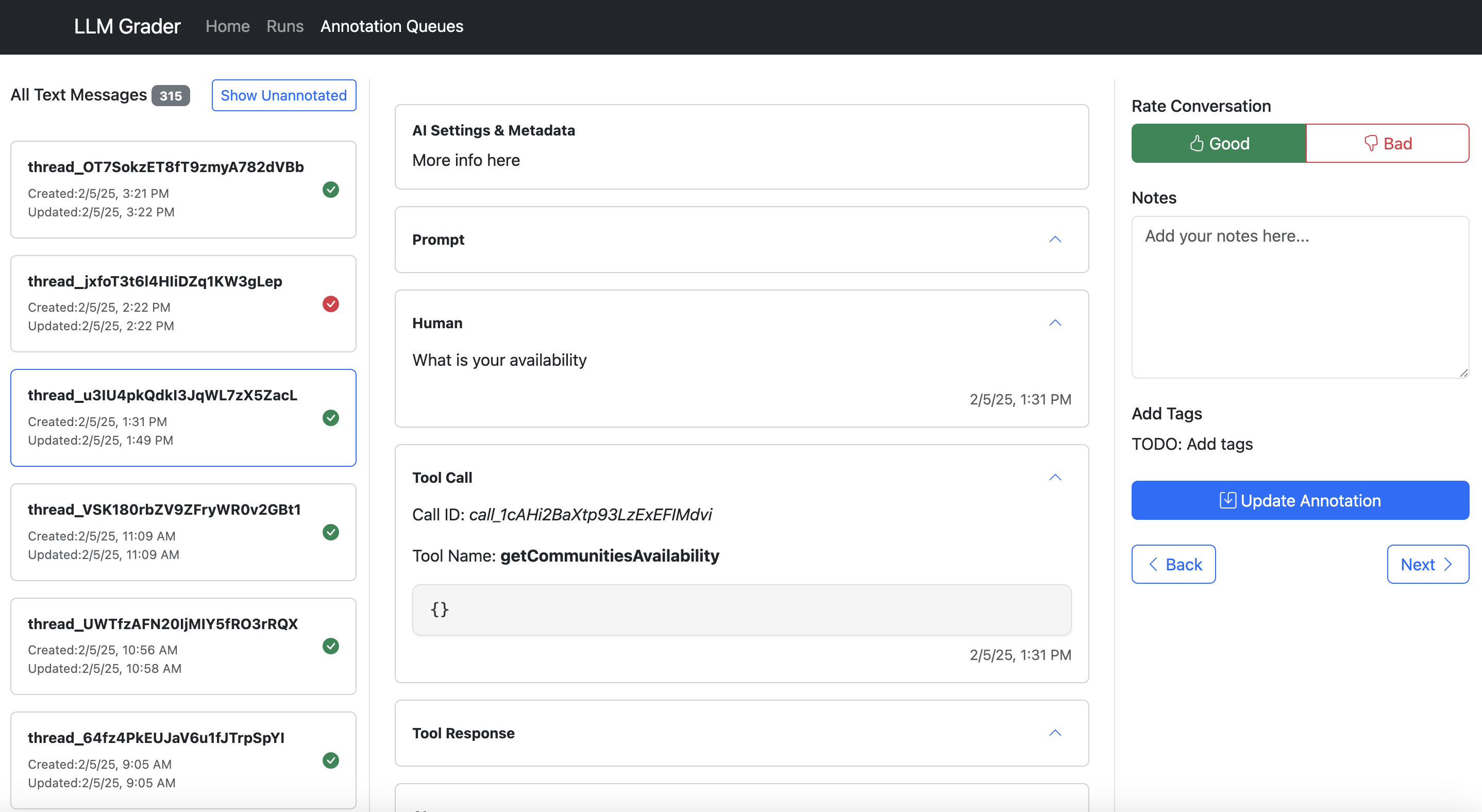
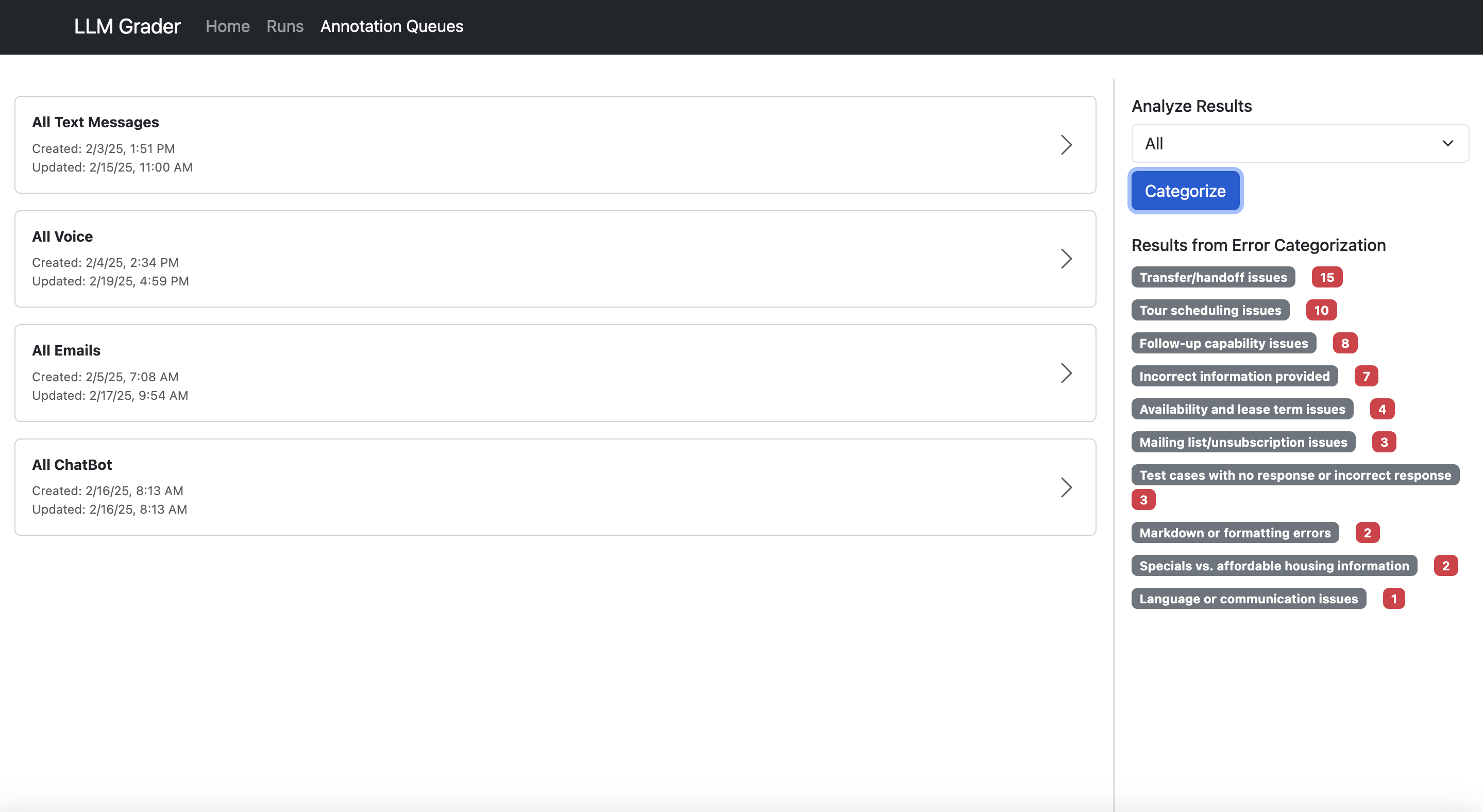
Hereâs what makes a good data annotation tool:
- Show all context in one place. Donât make users hunt through different systems to understand what happened.
- Make feedback trivial to capture. One-click correct/incorrect buttons beat lengthy forms.
- Capture open-ended feedback. This lets you capture nuanced issues that donât fit into a predefined taxonomy.
- Enable quick filtering and sorting. Teams need to easily dive into specific error types. In the example above, Nurture Boss can quickly filter by the channel (voice, text, chat) or the specific property they want to look at quickly.
- Have hotkeys that allow users to navigate between data examples and annotate without clicking.
It doesnât matter what web frameworks you useâuse whatever youâre familiar with. Because Iâm a Python developer, my current favorite web framework is FastHTML coupled with MonsterUI because it allows me to define the backend and frontend code in one small Python file.
The key is starting somewhere, even if itâs simple. Iâve found custom web apps provide the best experience, but if youâre just beginning, a spreadsheet is better than nothing. As your needs grow, you can evolve your tools accordingly.
This brings us to another counterintuitive lesson: The people best positioned to improve your AI system are often the ones who know the least about AI.
Empower Domain Experts to Write Prompts
I recently worked with an education startup building an interactive learning platform with LLMs. Their product manager, a learning design expert, would create detailed PowerPoint decks explaining pedagogical principles and example dialogues. Sheâd present these to the engineering team, who would then translate her expertise into prompts.
But hereâs the thing: Prompts are just English. Having a learning expert communicate teaching principles through PowerPoint only for engineers to translate that back into English prompts created unnecessary friction. The most successful teams flip this model by giving domain experts tools to write and iterate on prompts directly.
Build Bridges, Not Gatekeepers
Prompt playgrounds are a great starting point for this. Tools like Arize, LangSmith, and Braintrust let teams quickly test different prompts, feed in example datasets, and compare results. Here are some screenshots of these tools:
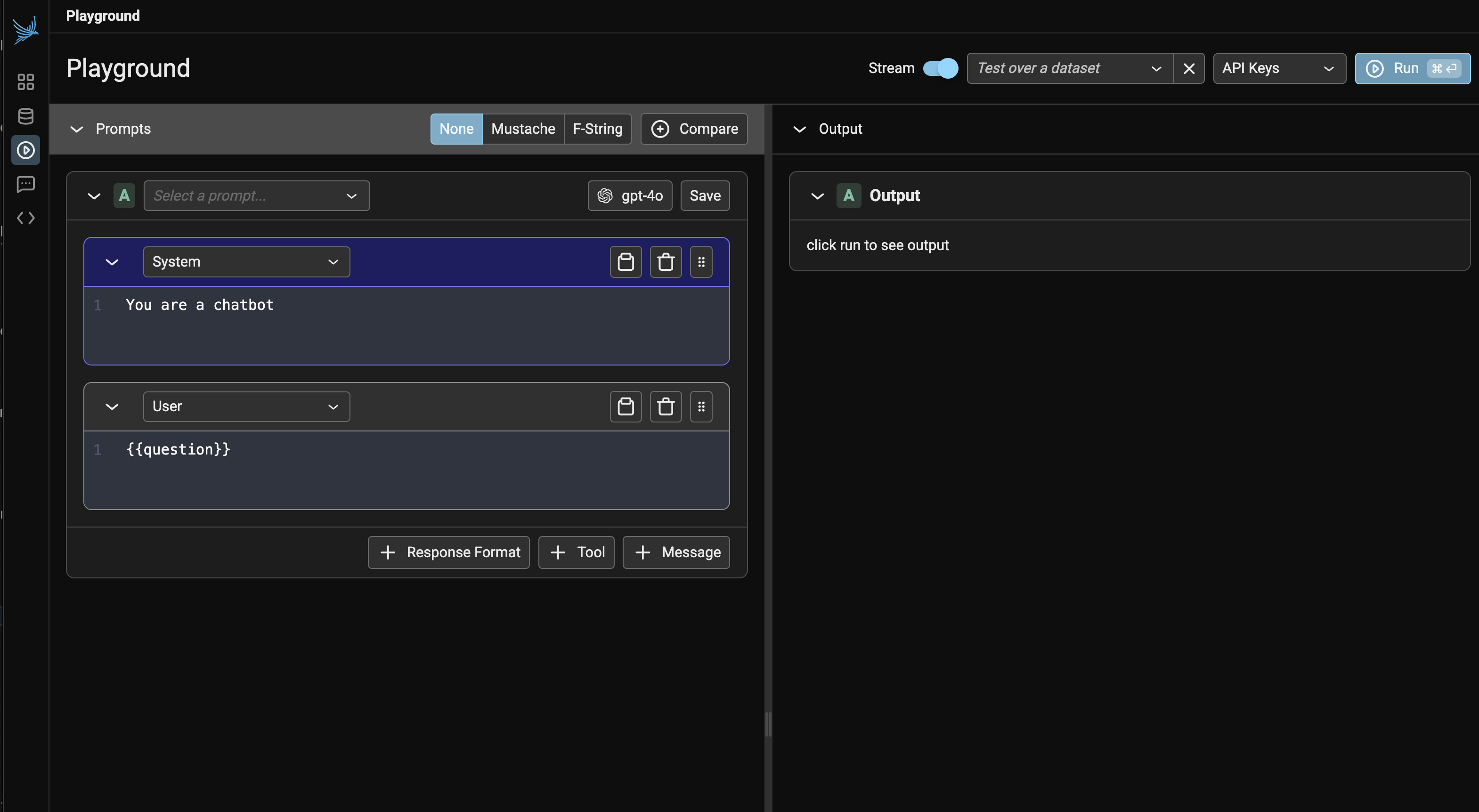
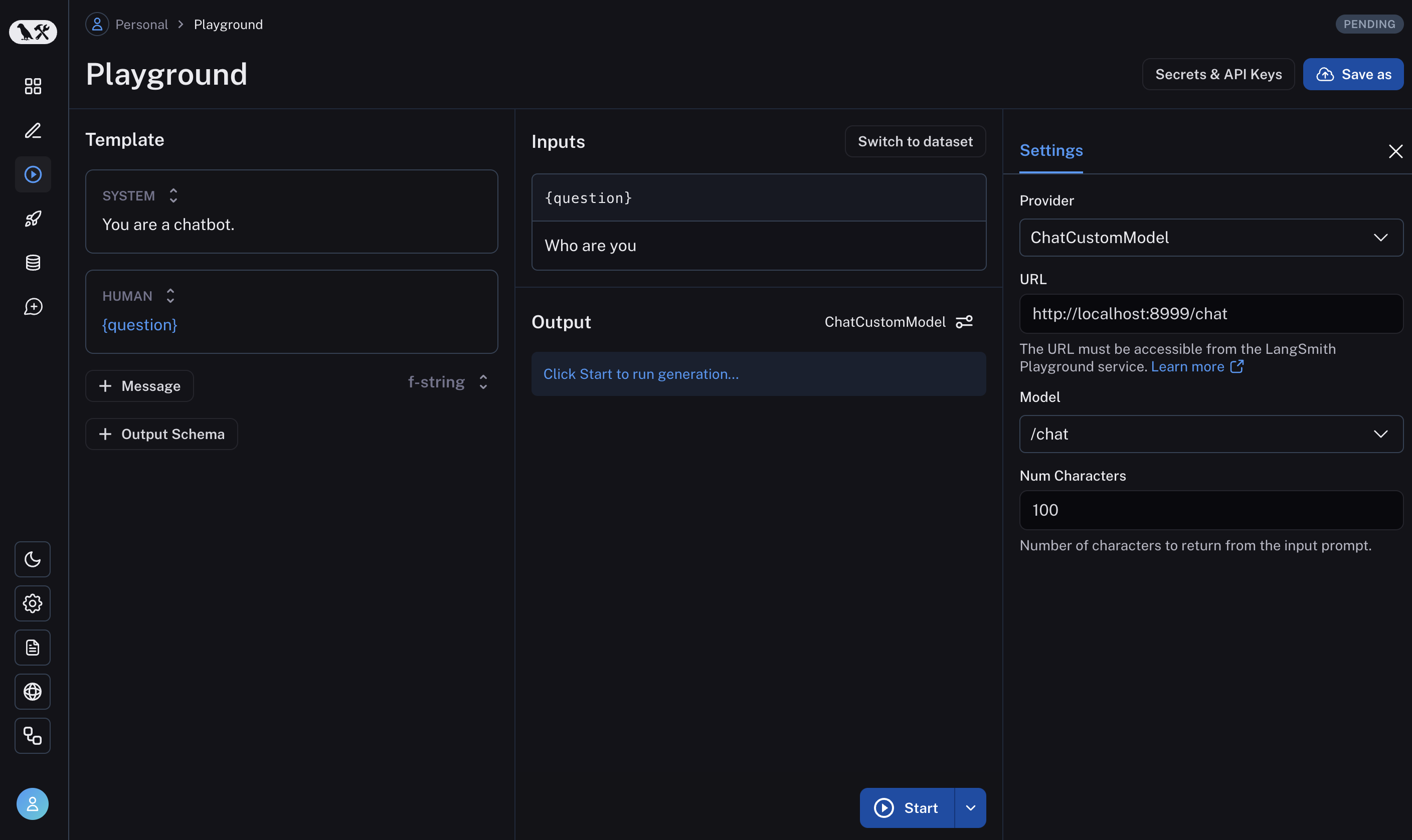
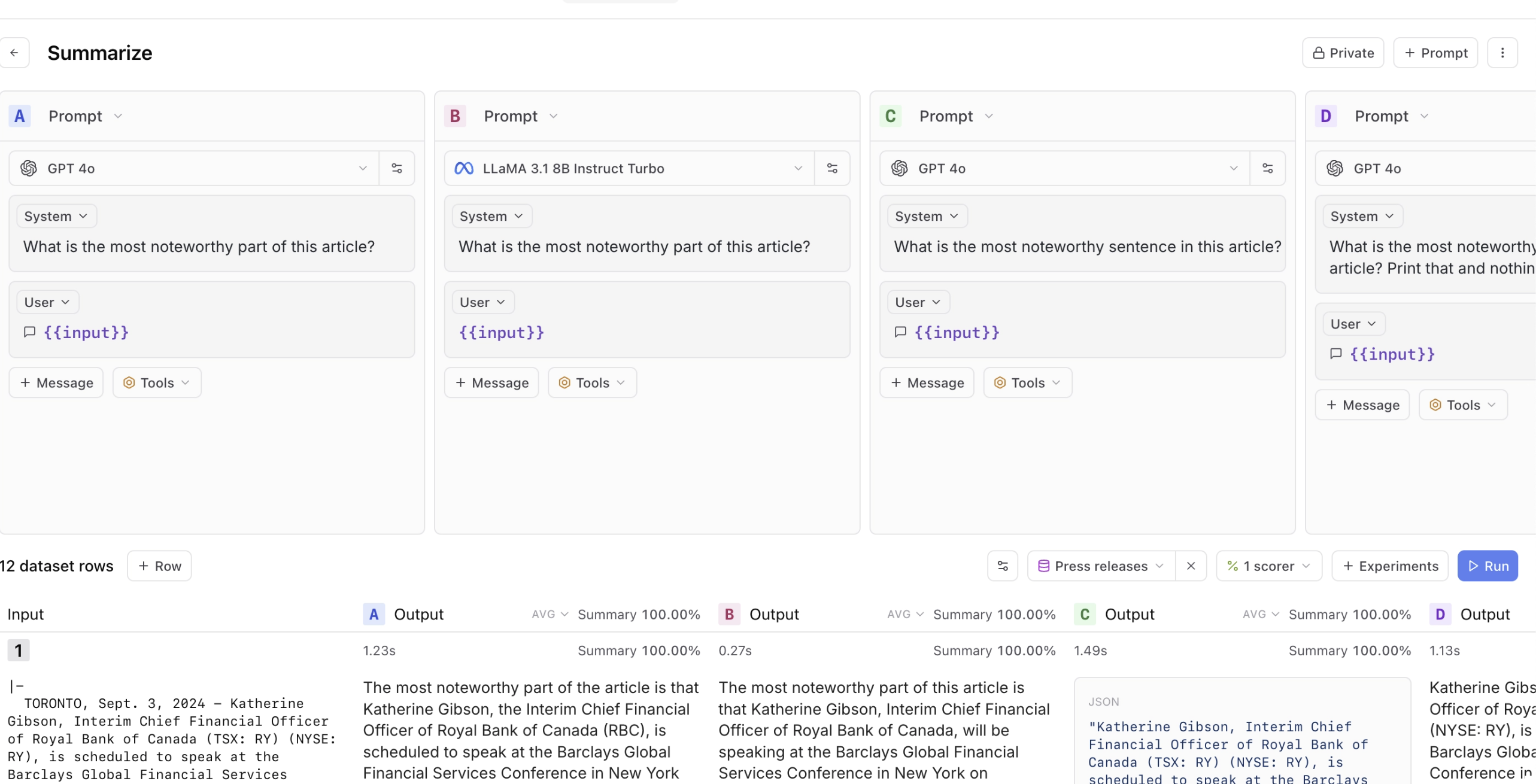
But thereâs a crucial next step that many teams miss: integrating prompt development into their application context. Most AI applications arenât just prompts; they commonly involve RAG systems pulling from your knowledge base, agent orchestration coordinating multiple steps, and application-specific business logic. The most effective teams Iâve worked with go beyond stand-alone playgrounds. They build what I call integrated prompt environmentsâessentially admin versions of their actual user interface that expose prompt editing.
Hereâs an illustration of what an integrated prompt environment might look like for a real-estate AI assistant:
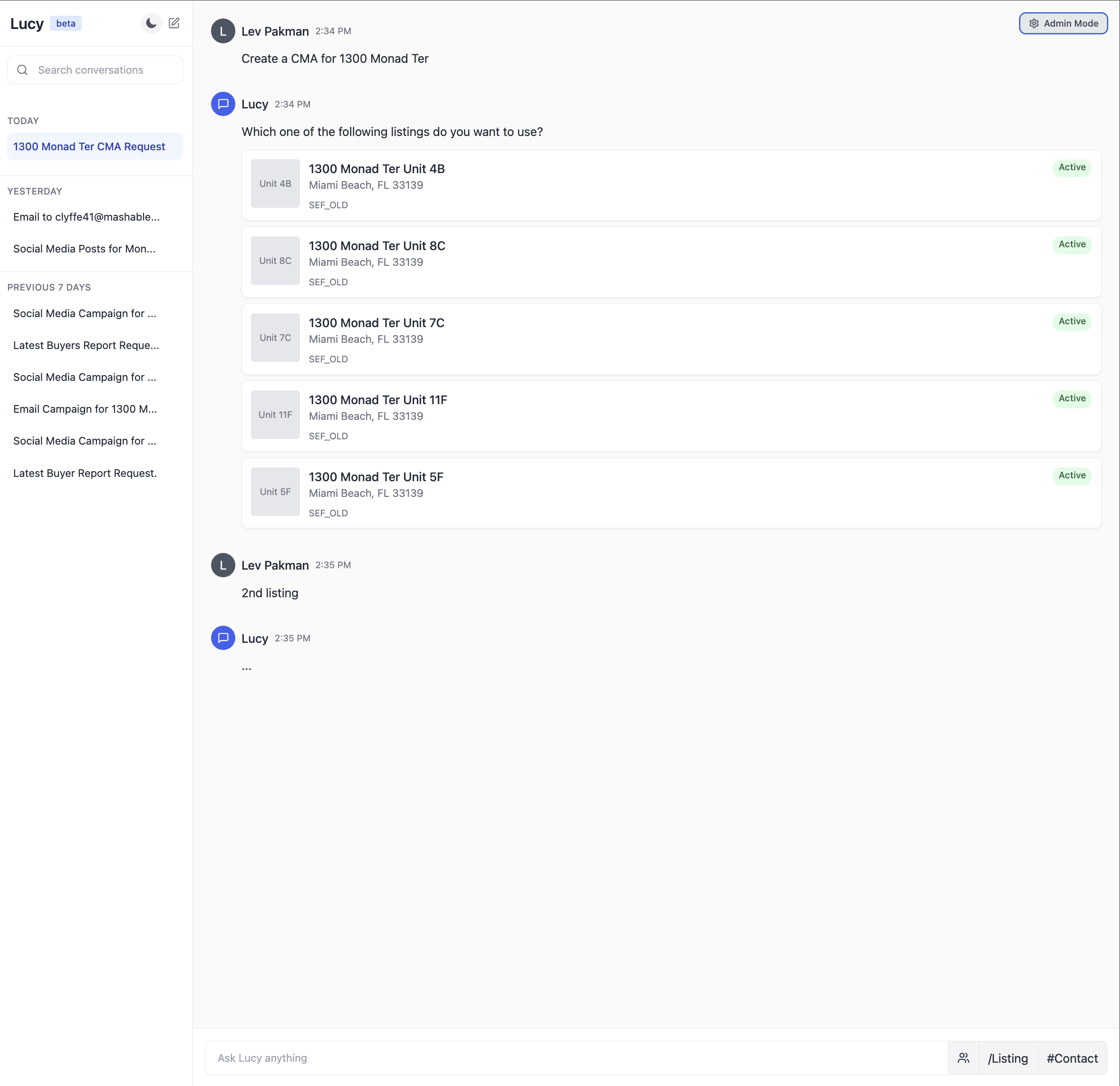
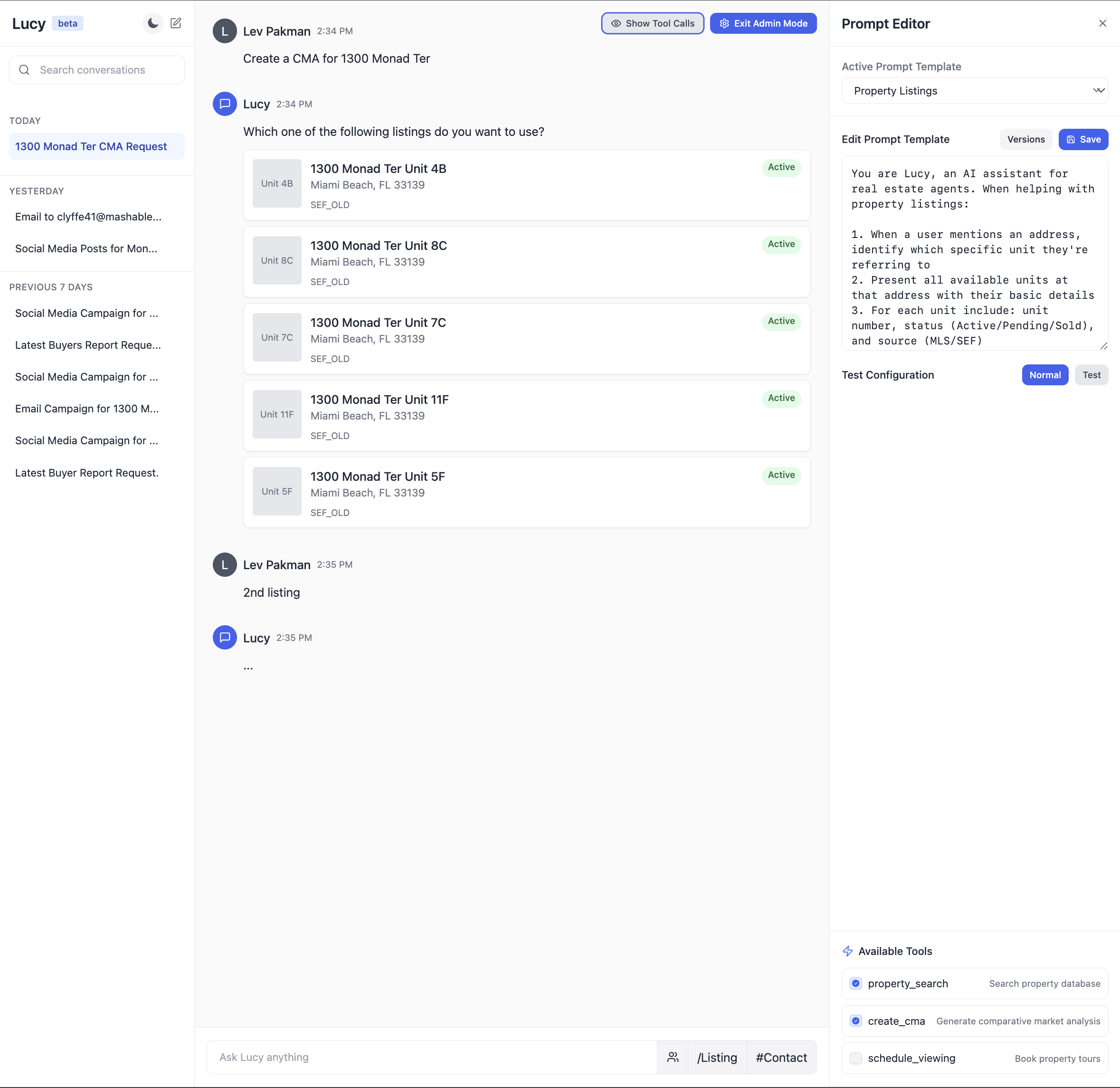
Tips for Communicating With Domain Experts
Thereâs another barrier that often prevents domain experts from contributing effectively: unnecessary jargon. I was working with an education startup where engineers, product managers, and learning specialists were talking past each other in meetings. The engineers kept saying, âWeâre going to build an agent that does XYZ,â when really the job to be done was writing a prompt. This created an artificial barrierâthe learning specialists, who were the actual domain experts, felt like they couldnât contribute because they didnât understand âagents.â
This happens everywhere. Iâve seen it with lawyers at legal tech companies, psychologists at mental health startups, and doctors at healthcare firms. The magic of LLMs is that they make AI accessible through natural language, but we often destroy that advantage by wrapping everything in technical terminology.
Hereâs a simple example of how to translate common AI jargon:
| Instead of saying⦠| Say⦠|
| âWeâre implementing a RAG approach.â | âWeâre making sure the model has the right context to answer questions.â |
| âWe need to prevent prompt injection.â | âWe need to make sure users canât trick the AI into ignoring our rules.â |
| âOur model suffers from hallucination issues.â | âSometimes the AI makes things up, so we need to check its answers.â |
This doesnât mean dumbing things downâit means being precise about what youâre actually doing. When you say, âWeâre building an agent,â what specific capability are you adding? Is it function calling? Tool use? Or just a better prompt? Being specific helps everyone understand whatâs actually happening.
Thereâs nuance here. Technical terminology exists for a reason: it provides precision when talking with other technical stakeholders. The key is adapting your language to your audience.
The challenge many teams raise at this point is âThis all sounds great, but what if we donât have any data yet? How can we look at examples or iterate on prompts when weâre just starting out?â Thatâs what weâll talk about next.
Bootstrapping Your AI With Synthetic Data Is Effective (Even With Zero Users)
One of the most common roadblocks I hear from teams is âWe canât do proper evaluation because we donât have enough real user data yet.â This creates a chicken-and-egg problemâyou need data to improve your AI, but you need a decent AI to get users who generate that data.
Fortunately, thereâs a solution that works surprisingly well: synthetic data. LLMs can generate realistic test cases that cover the range of scenarios your AI will encounter.
As I wrote in my LLM-as-a-Judge blog post, synthetic data can be remarkably effective for evaluation. Bryan Bischof, the former head of AI at Hex, put it perfectly:
LLMs are surprisingly good at generating excellent – and diverse – examples of user prompts. This can be relevant for powering application features, and sneakily, for building Evals. If this sounds a bit like the Large Language Snake is eating its tail, I was just as surprised as you! All I can say is: it works, ship it.
A Framework for Generating Realistic Test Data
The key to effective synthetic data is choosing the right dimensions to test. While these dimensions will vary based on your specific needs, I find it helpful to think about three broad categories:
- Features: What capabilities does your AI need to support?
- Scenarios: What situations will it encounter?
- User personas: Who will be using it and how?
These arenât the only dimensions you might care aboutâyou might also want to test different tones of voice, levels of technical sophistication, or even different locales and languages. The important thing is identifying dimensions that matter for your specific use case.
For a real-estate CRM AI assistant I worked on with Rechat, we defined these dimensions like this:

But having these dimensions defined is only half the battle. The real challenge is ensuring your synthetic data actually triggers the scenarios you want to test. This requires two things:
- A test database with enough variety to support your scenarios
- A way to verify that generated queries actually trigger intended scenarios
For Rechat, we maintained a test database of listings that we knew would trigger different edge cases. Some teams prefer to use an anonymized copy of production data, but either way, you need to ensure your test data has enough variety to exercise the scenarios you care about.
Hereâs an example of how we might use these dimensions with real data to generate test cases for the property search feature (this is just pseudo code, and very illustrative):
def generate_search_query(scenario, persona, listing_db):
"""Generate a realistic user query about listings"""
# Pull real listing data to ground the generation
sample_listings = listing_db.get_sample_listings(
price_range=persona.price_range,
location=persona.preferred_areas
)
# Verify we have listings that will trigger our scenario
if scenario == "multiple_matches" and len(sample_listings) 0:
raise ValueError("Found matches when testing no-match scenario")
prompt = f"""
You are an expert real estate agent who is searching for listings. You are given a customer type and a scenario.
Your job is to generate a natural language query you would use to search these listings.
Context:
- Customer type: {persona.description}
- Scenario: {scenario}
Use these actual listings as reference:
{format_listings(sample_listings)}
The query should reflect the customer type and the scenario.
Example query: Find homes in the 75019 zip code, 3 bedrooms, 2 bathrooms, price range $750k - $1M for an investor.
"""
return generate_with_llm(prompt)
This produced realistic queries like:
| Feature | Scenario | Persona | Generated Query |
|---|---|---|---|
| property search | multiple matches | first_time_buyer | âLooking for 3-bedroom homes under $500k in the Riverside area. Would love something close to parks since we have young kids.â |
| market analysis | no matches | investor | âNeed comps for 123 Oak St. Specifically interested in rental yield comparison with similar properties in a 2-mile radius.â |
The key to useful synthetic data is grounding it in real system constraints. For the real-estate AI assistant, this means:
- Using real listing IDs and addresses from their database
- Incorporating actual agent schedules and availability windows
- Respecting business rules like showing restrictions and notice periods
- Including market-specific details like HOA requirements or local regulations
We then feed these test cases through Lucy (now part of Capacity) and log the interactions. This gives us a rich dataset to analyze, showing exactly how the AI handles different situations with real system constraints. This approach helped us fix issues before they affected real users.
Sometimes you donât have access to a production database, especially for new products. In these cases, use LLMs to generate both test queries and the underlying test data. For a real-estate AI assistant, this might mean creating synthetic property listings with realistic attributesâprices that match market ranges, valid addresses with real street names, and amenities appropriate for each property type. The key is grounding synthetic data in real-world constraints to make it useful for testing. The specifics of generating robust synthetic databases are beyond the scope of this post.
Guidelines for Using Synthetic Data
When generating synthetic data, follow these key principles to ensure itâs effective:
- Diversify your dataset: Create examples that cover a wide range of features, scenarios, and personas. As I wrote in my LLM-as-a-Judge post, this diversity helps you identify edge cases and failure modes you might not anticipate otherwise.
- Generate user inputs, not outputs: Use LLMs to generate realistic user queries or inputs, not the expected AI responses. This prevents your synthetic data from inheriting the biases or limitations of the generating model.
- Incorporate real system constraints: Ground your synthetic data in actual system limitations and data. For example, when testing a scheduling feature, use real availability windows and booking rules.
- Verify scenario coverage: Ensure your generated data actually triggers the scenarios you want to test. A query intended to test âno matches foundâ should actually return zero results when run against your system.
- Start simple, then add complexity: Begin with straightforward test cases before adding nuance. This helps isolate issues and establish a baseline before tackling edge cases.
This approach isnât just theoreticalâitâs been proven in production across dozens of companies. What often starts as a stopgap measure becomes a permanent part of the evaluation infrastructure, even after real user data becomes available.
Letâs look at how to maintain trust in your evaluation system as you scale.
Maintaining Trust In Evals Is Critical
This is a pattern Iâve seen repeatedly: Teams build evaluation systems, then gradually lose faith in them. Sometimes itâs because the metrics donât align with what they observe in production. Other times, itâs because the evaluations become too complex to interpret. Either way, the result is the same: The team reverts to making decisions based on gut feeling and anecdotal feedback, undermining the entire purpose of having evaluations.
Maintaining trust in your evaluation system is just as important as building it in the first place. Hereâs how the most successful teams approach this challenge.
Understanding Criteria Drift
One of the most insidious problems in AI evaluation is âcriteria driftââa phenomenon where evaluation criteria evolve as you observe more model outputs. In their paper âWho Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences,â Shankar et al. describe this phenomenon:
To grade outputs, people need to externalize and define their evaluation criteria; however, the process of grading outputs helps them to define that very criteria.
This creates a paradox: You canât fully define your evaluation criteria until youâve seen a wide range of outputs, but you need criteria to evaluate those outputs in the first place. In other words, it is impossible to completely determine evaluation criteria prior to human judging of LLM outputs.
Iâve observed this firsthand when working with Phillip Carter at Honeycomb on the companyâs Query Assistant feature. As we evaluated the AIâs ability to generate database queries, Phillip noticed something interesting:
Seeing how the LLM breaks down its reasoning made me realize I wasnât being consistent about how I judged certain edge cases.
The process of reviewing AI outputs helped him articulate his own evaluation standards more clearly. This isnât a sign of poor planningâitâs an inherent characteristic of working with AI systems that produce diverse and sometimes unexpected outputs.
The teams that maintain trust in their evaluation systems embrace this reality rather than fighting it. They treat evaluation criteria as living documents that evolve alongside their understanding of the problem space. They also recognize that different stakeholders might have different (sometimes contradictory) criteria, and they work to reconcile these perspectives rather than imposing a single standard.
Creating Trustworthy Evaluation Systems
So how do you build evaluation systems that remain trustworthy despite criteria drift? Here are the approaches Iâve found most effective:
1. Favor Binary Decisions Over Arbitrary Scales
As I wrote in my LLM-as-a-Judge post, binary decisions provide clarity that more complex scales often obscure. When faced with a 1â5 scale, evaluators frequently struggle with the difference between a 3 and a 4, introducing inconsistency and subjectivity. What exactly distinguishes âsomewhat helpfulâ from âhelpfulâ? These boundary cases consume disproportionate mental energy and create noise in your evaluation data. And even when businesses use a 1â5 scale, they inevitably ask where to draw the line for âgood enoughâ or to trigger intervention, forcing a binary decision anyway.
In contrast, a binary pass/fail forces evaluators to make a clear judgment: Did this output achieve its purpose or not? This clarity extends to measuring progressâa 10% increase in passing outputs is immediately meaningful, while a 0.5-point improvement on a 5-point scale requires interpretation.
Iâve found that teams who resist binary evaluation often do so because they want to capture nuance. But nuance isnât lostâitâs just moved to the qualitative critique that accompanies the judgment. The critique provides rich context about why something passed or failed and what specific aspects could be improved, while the binary decision creates actionable clarity about whether improvement is needed at all.
2. Enhance Binary Judgments With Detailed Critiques
While binary decisions provide clarity, they work best when paired with detailed critiques that capture the nuance of why something passed or failed. This combination gives you the best of both worlds: clear, actionable metrics and rich contextual understanding.
For example, when evaluating a response that correctly answers a userâs question but contains unnecessary information, a good critique might read:
The AI successfully provided the market analysis requested (PASS), but included excessive detail about neighborhood demographics that wasnât relevant to the investment question. This makes the response longer than necessary and potentially distracting.
These critiques serve multiple functions beyond just explanation. They force domain experts to externalize implicit knowledgeâIâve seen legal experts move from vague feelings that something âdoesnât sound rightâ to articulating specific issues with citation formats or reasoning patterns that can be systematically addressed.
When included as few-shot examples in judge prompts, these critiques improve the LLMâs ability to reason about complex edge cases. Iâve found this approach often yields 15%â20% higher agreement rates between human and LLM evaluations compared to prompts without example critiques. The critiques also provide excellent raw material for generating high-quality synthetic data, creating a flywheel for improvement.
3. Measure Alignment Between Automated Evals and Human Judgment
If youâre using LLMs to evaluate outputs (which is often necessary at scale), itâs crucial to regularly check how well these automated evaluations align with human judgment.
This is particularly important given our natural tendency to over-trust AI systems. As Shankar et al. note in âWho Validates the Validators?,â the lack of tools to validate evaluator quality is concerning.
Research shows people tend to over-rely and over-trust AI systems. For instance, in one high profile incident, researchers from MIT posted a pre-print on arXiv claiming that GPT-4 could ace the MIT EECS exam. Within hours, [the] work [was] debunked. . .citing problems arising from over-reliance on GPT-4 to grade itself.
This overtrust problem extends beyond self-evaluation. Research has shown that LLMs can be biased by simple factors like the ordering of options in a set or even seemingly innocuous formatting changes in prompts. Without rigorous human validation, these biases can silently undermine your evaluation system.
When working with Honeycomb, we tracked agreement rates between our LLM-as-a-judge and Phillipâs evaluations:
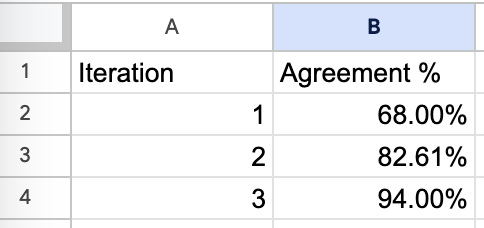
It took three iterations to achieve >90% agreement, but this investment paid off in a system the team could trust. Without this validation step, automated evaluations often drift from human expectations over time, especially as the distribution of inputs changes. You can read more about this here.
Tools like Eugene Yanâs AlignEval demonstrate this alignment process beautifully. AlignEval provides a simple interface where you upload data, label examples with a binary âgoodâ or âbad,â and then evaluate LLM-based judges against those human judgments. What makes it effective is how it streamlines the workflowâyou can quickly see where automated evaluations diverge from your preferences, refine your criteria based on these insights, and measure improvement over time. This approach reinforces that alignment isnât a one-time setup but an ongoing conversation between human judgment and automated evaluation.
Scaling Without Losing Trust
As your AI system grows, youâll inevitably face pressure to reduce the human effort involved in evaluation. This is where many teams go wrongâthey automate too much, too quickly, and lose the human connection that keeps their evaluations grounded.
The most successful teams take a more measured approach:
- Start with high human involvement: In the early stages, have domain experts evaluate a significant percentage of outputs.
- Study alignment patterns: Rather than automating evaluation, focus on understanding where automated evaluations align with human judgment and where they diverge. This helps you identify which types of cases need more careful human attention.
- Use strategic sampling: Rather than evaluating every output, use statistical techniques to sample outputs that provide the most information, particularly focusing on areas where alignment is weakest.
- Maintain regular calibration: Even as you scale, continue to compare automated evaluations against human judgment regularly, using these comparisons to refine your understanding of when to trust automated evaluations.
Scaling evaluation isnât just about reducing human effortâitâs about directing that effort where it adds the most value. By focusing human attention on the most challenging or informative cases, you can maintain quality even as your system grows.
Now that weâve covered how to maintain trust in your evaluations, letâs talk about a fundamental shift in how you should approach AI development roadmaps.
Your AI Roadmap Should Count Experiments, Not Features
If youâve worked in software development, youâre familiar with traditional roadmaps: a list of features with target delivery dates. Teams commit to shipping specific functionality by specific deadlines, and success is measured by how closely they hit those targets.
This approach fails spectacularly with AI.
Iâve watched teams commit to roadmap objectives like âLaunch sentiment analysis by Q2â or âDeploy agent-based customer support by end of year,â only to discover that the technology simply isnât ready to meet their quality bar. They either ship something subpar to hit the deadline or miss the deadline entirely. Either way, trust erodes.
The fundamental problem is that traditional roadmaps assume we know whatâs possible. With conventional software, thatâs often trueâgiven enough time and resources, you can build most features reliably. With AI, especially at the cutting edge, youâre constantly testing the boundaries of whatâs feasible.
Experiments Versus Features
Bryan Bischof, former head of AI at Hex, introduced me to what he calls a âcapability funnelâ approach to AI roadmaps. This strategy reframes how we think about AI development progress. Instead of defining success as shipping a feature, the capability funnel breaks down AI performance into progressive levels of utility. At the top of the funnel is the most basic functionality: Can the system respond at all? At the bottom is fully solving the userâs job to be done. Between these points are various stages of increasing usefulness.
For example, in a query assistant, the capability funnel might look like:
- Can generate syntactically valid queries (basic functionality)
- Can generate queries that execute without errors
- Can generate queries that return relevant results
- Can generate queries that match user intent
- Can generate optimal queries that solve the userâs problem (complete solution)
This approach acknowledges that AI progress isnât binaryâitâs about gradually improving capabilities across multiple dimensions. It also provides a framework for measuring progress even when you havenât reached the final goal.
The most successful teams Iâve worked with structure their roadmaps around experiments rather than features. Instead of committing to specific outcomes, they commit to a cadence of experimentation, learning, and iteration.
Eugene Yan, an applied scientist at Amazon, shared how he approaches ML project planning with leadershipâa process that, while originally developed for traditional machine learning, applies equally well to modern LLM development:
Hereâs a common timeline. First, I take two weeks to do a data feasibility analysis, i.e., âDo I have the right data?â…Then I take an additional month to do a technical feasibility analysis, i.e., âCan AI solve this?â After that, if it still works Iâll spend six weeks building a prototype we can A/B test.
While LLMs might not require the same kind of feature engineering or model training as traditional ML, the underlying principle remains the same: time-box your exploration, establish clear decision points, and focus on proving feasibility before committing to full implementation. This approach gives leadership confidence that resources wonât be wasted on open-ended exploration, while giving the team the freedom to learn and adapt as they go.
The Foundation: Evaluation Infrastructure
The key to making an experiment-based roadmap work is having robust evaluation infrastructure. Without it, youâre just guessing whether your experiments are working. With it, you can rapidly iterate, test hypotheses, and build on successes.
I saw this firsthand during the early development of GitHub Copilot. What most people donât realize is that the team invested heavily in building sophisticated offline evaluation infrastructure. They created systems that could test code completions against a very large corpus of repositories on GitHub, leveraging unit tests that already existed in high-quality codebases as an automated way to verify completion correctness. This was a massive engineering undertakingâthey had to build systems that could clone repositories at scale, set up their environments, run their test suites, and analyze the results, all while handling the incredible diversity of programming languages, frameworks, and testing approaches.
This wasnât wasted timeâit was the foundation that accelerated everything. With solid evaluation in place, the team ran thousands of experiments, quickly identified what worked, and could say with confidence âThis change improved quality by X%â instead of relying on gut feelings. While the upfront investment in evaluation feels slow, it prevents endless debates about whether changes help or hurt and dramatically speeds up innovation later.
Communicating This to Stakeholders
The challenge, of course, is that executives often want certainty. They want to know when features will ship and what theyâll do. How do you bridge this gap?
The key is to shift the conversation from outputs to outcomes. Instead of promising specific features by specific dates, commit to a process that will maximize the chances of achieving the desired business outcomes.
Eugene shared how he handles these conversations:
I try to reassure leadership with timeboxes. At the end of three months, if it works out, then we move it to production. At any step of the way, if it doesnât work out, we pivot.
This approach gives stakeholders clear decision points while acknowledging the inherent uncertainty in AI development. It also helps manage expectations about timelinesâinstead of promising a feature in six months, youâre promising a clear understanding of whether that feature is feasible in three months.
Bryanâs capability funnel approach provides another powerful communication tool. It allows teams to show concrete progress through the funnel stages, even when the final solution isnât ready. It also helps executives understand where problems are occurring and make informed decisions about where to invest resources.
Build a Culture of Experimentation Through Failure Sharing
Perhaps the most counterintuitive aspect of this approach is the emphasis on learning from failures. In traditional software development, failures are often hidden or downplayed. In AI development, theyâre the primary source of learning.
Eugene operationalizes this at his organization through what he calls a âfifteen-fiveââa weekly update that takes fifteen minutes to write and five minutes to read:
In my fifteen-fives, I document my failures and my successes. Within our team, we also have weekly âno-prep sharing sessionsâ where we discuss what weâve been working on and what weâve learned. When I do this, I go out of my way to share failures.
This practice normalizes failure as part of the learning process. It shows that even experienced practitioners encounter dead-ends, and it accelerates team learning by sharing those experiences openly. And by celebrating the process of experimentation rather than just the outcomes, teams create an environment where people feel safe taking risks and learning from failures.
A Better Way Forward
So what does an experiment-based roadmap look like in practice? Hereâs a simplified example from a content moderation project Eugene worked on:
I was asked to do content moderation. I said, âItâs uncertain whether weâll meet that goal. Itâs uncertain even if that goal is feasible with our data, or what machine learning techniques would work. But hereâs my experimentation roadmap. Here are the techniques Iâm gonna try, and Iâm gonna update you at a two-week cadence.â
The roadmap didnât promise specific features or capabilities. Instead, it committed to a systematic exploration of possible approaches, with regular check-ins to assess progress and pivot if necessary.
The results were telling:
For the first two to three months, nothing worked. . . .And then [a breakthrough] came out. . . .Within a month, that problem was solved. So you can see that in the first quarter or even four months, it was going nowhere. . . .But then you can also see that all of a sudden, some new technology…, some new paradigm, some new reframing comes along that just [solves] 80% of [the problem].
This patternâlong periods of apparent failure followed by breakthroughsâis common in AI development. Traditional feature-based roadmaps would have killed the project after months of âfailure,â missing the eventual breakthrough.
By focusing on experiments rather than features, teams create space for these breakthroughs to emerge. They also build the infrastructure and processes that make breakthroughs more likely: data pipelines, evaluation frameworks, and rapid iteration cycles.
The most successful teams Iâve worked with start by building evaluation infrastructure before committing to specific features. They create tools that make iteration faster and focus on processes that support rapid experimentation. This approach might seem slower at first, but it dramatically accelerates development in the long run by enabling teams to learn and adapt quickly.
The key metric for AI roadmaps isnât features shippedâitâs experiments run. The teams that win are those that can run more experiments, learn faster, and iterate more quickly than their competitors. And the foundation for this rapid experimentation is always the same: robust, trusted evaluation infrastructure that gives everyone confidence in the results.
By reframing your roadmap around experiments rather than features, you create the conditions for similar breakthroughs in your own organization.
Conclusion
Throughout this post, Iâve shared patterns Iâve observed across dozens of AI implementations. The most successful teams arenât the ones with the most sophisticated tools or the most advanced modelsâtheyâre the ones that master the fundamentals of measurement, iteration, and learning.
The core principles are surprisingly simple:
- Look at your data. Nothing replaces the insight gained from examining real examples. Error analysis consistently reveals the highest-ROI improvements.
- Build simple tools that remove friction. Custom data viewers that make it easy to examine AI outputs yield more insights than complex dashboards with generic metrics.
- Empower domain experts. The people who understand your domain best are often the ones who can most effectively improve your AI, regardless of their technical background.
- Use synthetic data strategically. You donât need real users to start testing and improving your AI. Thoughtfully generated synthetic data can bootstrap your evaluation process.
- Maintain trust in your evaluations. Binary judgments with detailed critiques create clarity while preserving nuance. Regular alignment checks ensure automated evaluations remain trustworthy.
- Structure roadmaps around experiments, not features. Commit to a cadence of experimentation and learning rather than specific outcomes by specific dates.
These principles apply regardless of your domain, team size, or technical stack. Theyâve worked for companies ranging from early-stage startups to tech giants, across use cases from customer support to code generation.
Resources for Going Deeper
If youâd like to explore these topics further, here are some resources that might help:
- My blog for more content on AI evaluation and improvement. My other posts dive into more technical detail on topics such as constructing effective LLM judges, implementing evaluation systems, and other aspects of AI development.1 Also check out the blogs of Shreya Shankar and Eugene Yan, who are also great sources of information on these topics.
- A course Iâm teaching, Rapidly Improve AI Products with Evals, with Shreya Shankar. It provides hands-on experience with techniques such as error analysis, synthetic data generation, and building trustworthy evaluation systems, and includes practical exercises and personalized instruction through office hours.
- If youâre looking for hands-on guidance specific to your organizationâs needs, you can learn more about working with me at Parlance Labs.
Footnotes
- I write more broadly about machine learning, AI, and software development. Some posts that expand on these topics include âYour AI Product Needs Evals,â âCreating a LLM-as-a-Judge That Drives Business Results,â and âWhat Weâve Learned from a Year of Building with LLMs.â You can see all my posts at hamel.dev.