

Microsoft的“ 1 -Pit” AI模型仅在CPU上运行,同时匹配较大的系统
尺寸重要吗?
记忆要求是降低模型内部权重的复杂性的最明显优势。比特网络B1.58模型只能使用0.4GB的内存运行,而对于其他大致相同的参数大小的开放式型号的2到5GB都可以使用2至5GB。
但是,简化的加权系统还可以在推理时间提高更有效的操作,而内部操作更多地依赖于简单的添加说明,而更少的是计算昂贵的乘法指令。研究人员估计,这些效率的提高与类似的全精度模型相比,比特网络B1.58使用的能量少85%至96%。
通过使用
高度优化的内核BITNET B1.58模型专为BITNET体系结构而设计,也可以比在标准的FullEcision Transformer上运行的类似型号快多次运行。研究人员写道,该系统足够有效地达到“速度与人类阅读速度相当(每秒5-7个令牌)”,研究人员写道(您可以自己下载并运行那些优化的内核在许多手臂和X86 CPU上,或使用这个网络演示)。
研究人员至关重要的是,这些改进并不是以各种基准测试推理,数学和“知识”功能的绩效成本来表现的(尽管该主张尚未独立验证)。研究人员在几个常见的基准上取消结果,发现比特网络“达到能力与大小类别的领先模型相当,同时提供了显着提高的效率”。
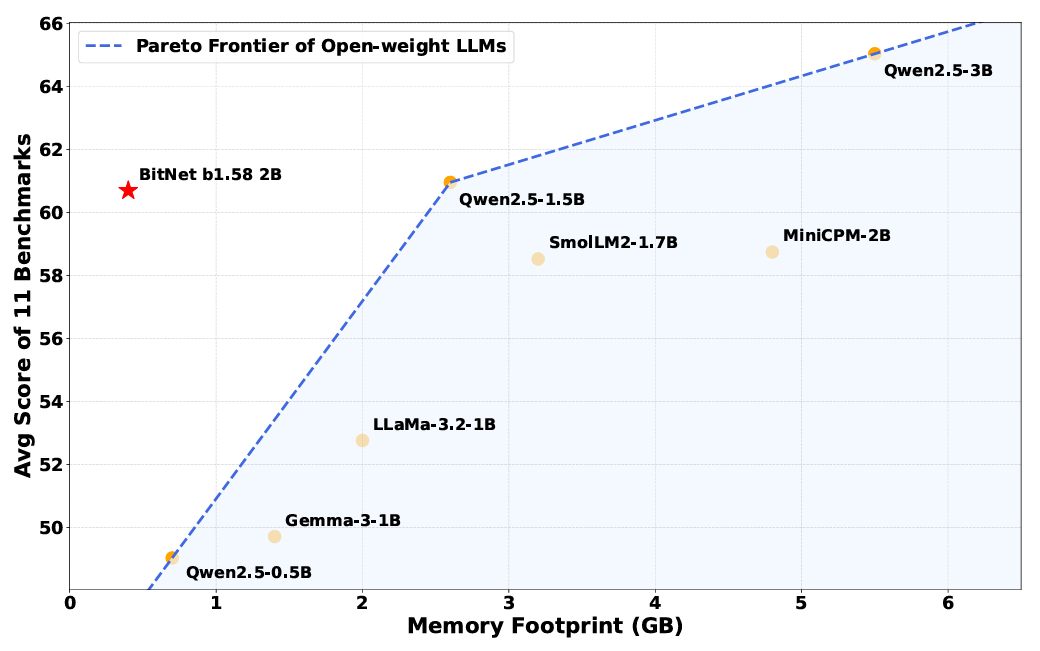
尽管记忆范围较小,但比特网仍然与许多基准上的“完整精度”加权模型相似。尽管记忆范围较小,但比特网仍然与许多基准上的“完整精度”加权模型相似。
尽管这种“概念证明”比特网模型显然取得了成功,但研究人员写道,他们不太了解该模型为何和这种简化的加权一样起作用。
他们写道:“深入研究为什么大规模培训有效的理论基础仍然是一个开放区域。”仍然需要进行更多的研究,以获取这些比特网模型与当今最大模型的整体尺寸和上下文窗口“内存”竞争。
尽管如此,这项新的研究还显示了面临的AI模型的潜在替代方法螺旋硬件和能源成本从昂贵且强大的GPU上运行。今天的“完整精度”模型可能就像肌肉车一样浪费大量精力和精力,而相当于良好的亚compact可以带来类似的结果。