

模式匹配机
AI模型在数学问题上表现出色,但缺乏数学奥林匹克证明所需的推理。
当今最有能力的AI模型的核心是一个奇怪的矛盾,该模型旨在以“原因”:他们可以以令人印象深刻的准确性来解决常规的数学问题,但是当面对竞争级别挑战中发现的更深入的数学证据时,他们常常失败。
那就是发现大开眼界研究进入模拟推理(SR)模型,最初于3月列出并于4月更新,主要属于新闻雷达。尽管有时来自AI供应商的营销主张,但该研究还是对SR模型的数学局限性的指导性案例研究。
什么设定模拟推理模型除了传统的大型语言模型(LLM)外,他们已经接受了训练以输出逐步的“思维”过程(通常称为”经过思考链”)要解决问题。请注意,在这种情况下,“模拟”并不意味着模型根本没有理由,而是他们不一定要使用与人类相同的技术来推理。这种区别很重要,因为人类推理本身很难定义。
新的研究论文名为“证明或虚张声势?评估2025年美国数学奥林匹克运动会上的LLM”,来自苏菲亚大学Eth Zurich的一组研究人员,由Ivo Petrov和Martin Vechev领导的索非亚大学的Insait。
在研究中,研究人员向SR模型提出了来自2025美国数学奥林匹克由美国数学协会,大多数模型在生成完整的数学证明时平均得分低于5%。该分数代表了模型在多次尝试中实现的总数总数的平均百分比(例如,每个问题的标准0量表,例如官方奥林匹克运动会)的平均百分比,专家人类分级人士为正确的步骤授予了部分信用。
证明与答案:另一种测试
要了解为什么此功能差距很重要,您需要了解回答数学问题和数学证明之间的区别。数学问题就像被问到:“ 2+2是什么?”或“在此方程式中求解X”。您只需要正确的答案。但是,数学证明就像被问到:“解释为什么使用逻辑步骤解释2+2 = 4”或“证明此公式适合所有可能的数字”。证明需要解释您的推理,并表明为什么某事必须是真实的,而不仅仅是给出答案。

2025年USAMO问题1的屏幕截图和一个解决方案,显示在Aopsonline网站上。信用:AOPSONLINE
美国数学奥林匹克(USAMO)是国际数学奥林匹克运动会的预选赛,并且比像这样的测试更高的标准美国邀请数学考试(Aime)。尽管AIME问题很困难,但它们需要整数答案。USAMO要求参赛者写出完整的数学证明,在九小时和两天内得分为正确,完整性和清晰度。
研究人员对2025年USAMO发布后不久的六个问题进行了评估,该模型在释放后不久就评估了六个问题,从而最大程度地减少了这些问题是模型培训数据的一部分。这些模型包括Qwen的QWQ-32B,,,,DeepSeek R1,Google的Gemini 2.0 Flash思维(实验)和双子座2.5 Pro,Openai的O1-Pro和O3米尼高,人类克劳德(Claude)3.7十四行诗和xai的Grok 3。
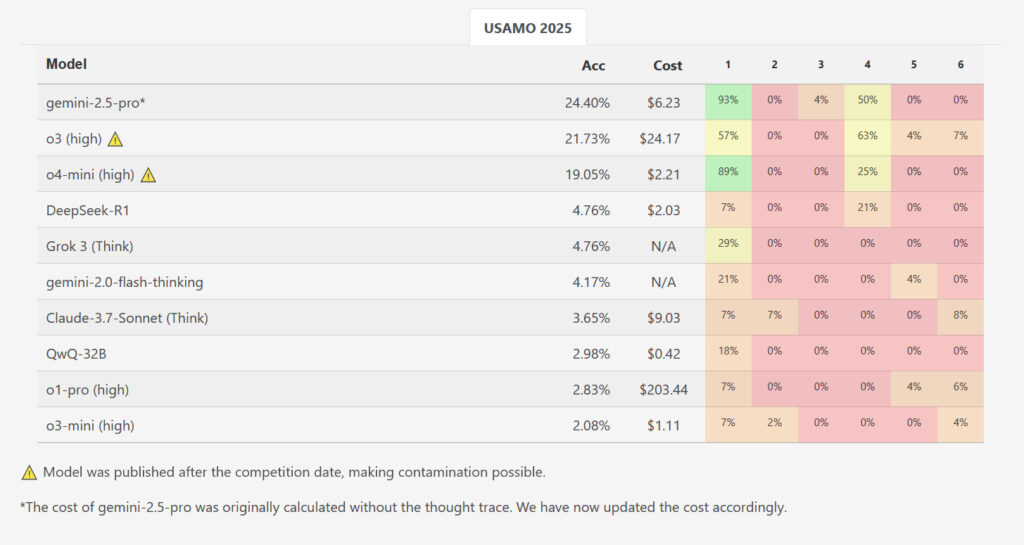
2025年4月25日,研究人员的Matharena网站的屏幕截图显示了USAMO中每个问题的SR模型的准确分数。信用:Matharena
虽然一种模型,Google的Gemini 2.5 Pro的平均得分较高,在42分(约24%)中,平均得分更高,但结果与AIME级别的基准相比,结果显示出大量的性能下降。其他评估的模型进一步落后了:DeepSeek R1和Grok 3平均分别为2.0点,Google的闪光思维得分为1.8,Anthropic的Claude 3.7管理1.5,而QWEN的QWQ和OpenAI的O1-Pro则平均为1.2分。Openai的O3米尼的平均得分最低,仅为0.9分(约2.1%)。在所有经过测试的模型和运行中,在近200个生成的解决方案中,没有一个问题获得任何问题的完美分数。
而Openai的新发布03和O4米尼高没有对这项研究进行检查,研究人员的基准测试Matharena网站显示,O3高分的整体得分为21.73%,O4-Mini-High得分为19.05%。但是,这些结果可能被污染,因为它们是在比赛发生后测量的,这意味着较新的OpenAI模型可能会将解决方案包括在培训数据中。
模型如何失败
在本文中,研究人员确定了几种关键的重复故障模式。AI输出包含缺乏数学理由的逻辑差距,包括基于未经证实的假设的参数,尽管产生了矛盾的结果,但仍会继续产生错误的方法。
涉及的特定示例USAMO 2025问题5。这个问题要求模型找到所有正数“ k”,以使涉及“ k”幂的二项式系数总和的特定计算始终会导致整数,无论使用哪种正整数“ n”。在此问题上,QWEN的QWQ模型出现了一个明显的错误:在问题陈述允许他们的阶段,它错误地排除了非直觉的可能性。尽管正确地确定了其推理过程中的必要条件,但这个错误导致模型取得了错误的最终答案。
也许最值得注意的是,这些AI模型通常使用肯定语言输出了错误的解决方案,没有表明其模拟推理过程中错误的不确定性或“意识”。研究人员注意到这种趋势,即使证据包含重大缺陷。
研究人员认为,这些失败可能部分源于模型的训练和优化方式。例如,他们观察到基准训练中常见的优化策略可能导致的伪影。模型有时与找到最终的“盒装”答案相关的约束(指基准中的共同实践都必须在模型中必须格式化其最终的数值结果,通常使用乳胶命令\\盒子{},即使自动化系统可以轻松提取并对其进行评分),即使在不适合过度元素的模式中,自动化系统也可以轻松提取并进行评分)。
数学流利的幻想
上述数学问题和证明之间的性能差距揭示了模式识别与真实数学推理之间的差异。当前的SR模型在训练数据中出现相似模式的任务中很好地发挥了作用,从而提供了相对准确的数值答案。但是他们缺乏基于证明的数学所需的更深入的“概念理解”,这需要在初始方法失败时构建新颖的逻辑论点,抽象概念的表示以及调整方法。
那为什么要这样做经过思考链如果他们不执行更深入的数学推理过程,则模拟推理会改善结果?答案在于研究人员所说的“推理时间计算”缩放。当LLM使用经过思考链技术时,他们将更多的计算资源以较小的,更有指向的步骤来穿越其潜在空间(在其神经网络数据中的概念之间的连接)。每个中间推理步骤都是下一个的背景,以有效地约束模型的输出,以提高准确性和降低骗子。
作为LLM研究工程师Sebastian Raschka解释在博客文章中:“推理模型要么明确显示他们的思维过程,要么内部处理它,这可以帮助他们在复杂的任务上更好地执行数学问题。”
但从根本上讲,所有基于变压器的AI模型都是模式匹配机器。他们从研究人员用来创建它们的示例数据中借用了推理技能。这解释了奥林匹克研究中的奇怪模式:这些模型在标准问题上表现出色,在标准问题中,逐步的程序与训练数据中的模式保持一致,但在面对新的证明挑战时崩溃,需要更深入的数学见解。改进可能来自多个较小预测任务的统计概率改进,而不是一个大型预测飞跃。
即便如此,正如我们在Gemini 2.5 Pro的结果中所看到的那样,SR模型可能会随着时间的推移而缩小此“推理”差距,因为它们变得更有能力,并且能够在潜在空间中建立更深的多维连接。未来的培训技术或模型架构最终可能会教授这些模型,以实现与最佳人类思想相提并论的一种深层推理。但这目前仍然是投机性的。
接下来会发生什么
即使有秩序的潜在改进,该研究的当前发现表明,简单地扩展当前的SR模型体系结构和训练方法可能不会弥合差距,以实现真正的数学推理。这些限制并非孤立:在另一项最近的研究(由加里·马库斯(Gary Marcus)指出他的博客文章在宾夕法尼亚州立大学的Hamed Mahdavi和合作者(来自纽约市,纽约市,纽约大学和Autodesk在内的机构)中,Hamed Mahdavi在“证明或虚张声势”的论文中)评估了LLMS对类似的高级数学挑战的评估,发现了有关这些限制的融合结论。
考虑到这些证明的缺点,一些研究人员是探索替代方法改善AI推理。这些包括整合符号推理引擎,开发更好的证明验证技术以及使用自洽检查。DeepMind的字母计量法提供了一个例子,将神经网络与符号AI中常见的形式方法相结合。而这样”神经符号系统“可能找不到证据,它们的结构阻止了它们对不正确的核对直接解决SR模型评估中观察到的关键故障模式。

本杰·爱德华兹(Benj Edwards)是ARS Technica的高级AI记者,也是该网站在2022年敬业的AI Beat的创始人。他还是一位具有近二十年经验的技术历史学家。在空闲时间里,他写下和录制音乐,收集老式计算机并享受大自然。他住在北卡罗来纳州罗利。