
西班牙语至墨西哥手语语言语料库用于自然语言处理任务
作者:Chairez, Isaac
背景和摘要
根据Besacier的说法1,低资源语言(LRL)是一种缺乏独特的写作系统,缺乏或缺乏网络存在,缺乏语言专业知识的语言,并且缺乏电子资源作为Corpora(单语和平行)。LRL是根据公开可用数据的数量进行分类的2。表中提供了相关LRLS的摘要 1,显示第三列中列出的此类语言的重要特征。
与口语相比,符号语言(SLS)被认为是LRL。这种特征源于以下事实:SLS通常缺乏标准化的书面形式和全面的词典,因此在发现语法关系时很难识别迹象。
SLS很复杂,而不是聋哑人使用的口头语言。通常,SLS是一个手动运动,面部表情,身体手势和各种象征用途的系统系统3。SLS根据地理区域和当地解释而有所不同。尽管SLS非常有用,但听力障碍的人与没有SLS知识的人之间存在障碍。解释上述障碍的重要原因之一是,可以使用较少的教育资源和训练有素的专家(语言学家,教师,口译员)可用于解释。此外,技术工具和资源(例如语音识别软件)主要是针对口语开发的,而对可容纳SLS的关注较少。从历史上看,它们在不同的技术和科学学科中没有与口语相同的认可4。
墨西哥的MSL是少数语言,在文化背景下呈现出劣势,因为水疗中心决定了交流的社会价值5。因此,需要采用现代方法来将MSL和类似的签名语言与更高级的翻译策略相结合。此类策略可以采用自动化的机器学习和NLP方法。但是,有必要开发可以在上述ML策略中使用的相应数据集。此外,考虑到口语和签名语言的语言规则,必须有效地合成此类数据库。
语言学工作的科学家通过类别的书面支持找到了一种捕获和设计语言数据集的方法,光泽6。具体而言,光泽的SL和水疗中心是词汇相似,但句法不同。光泽统治SLS执行的语法顺序。词法,如所定义7,是将自然语言转录为掩饰的。与原始语言相比,光泽由较少的令牌组成。例如,英语句子,你喜欢看电视吗?,转录美国手语(ASL)您喜欢的电视观看?。大多数SLS具有主题 - 对象 - SOV)结构,例如德语手语(GSL)和墨西哥手语(MSL)。
关于MSL的光泽,文献很少。一些语法词典,例如8,解释如何掩饰。例如,对于句子estélloviendoen la ciudad(“在城市正在下雨),是:Ciudad Ah Llover(“城市雨)。
如果是文本到文本(T-T)光泽,从语言到光泽有一些语料库,作为表格 2总结,包括对口语注释有光泽的语料库。广泛使用的SLT数据集RWTH-PHOENIX-WEATHER 2014T仅包含8,257个并行句子。进行比较:对于口语之间的翻译,6,000个平行句子被认为是微小的9。对于MSL光,不能使用经过验证的数据库来执行NMT,尤其是考虑到将SPA解释为MSL的允许规则。
我们已经开发了3000对的Spa-to-MSL光泽数据集。所提出的光泽的发展遵循认为对水疗语言有效的语言规则,具有相似的代表性,单词组织和结构相似性。光泽的开发还考虑了MSL的语言组织,该组织为进行自然语言处理研究提供了正式的数据源,以帮助聋哑人基于机器学习方法。
所提出的光泽可用于从头开始执行NMT或使用转移学习技术。在这项研究中,评估技术使用了在高资源语言对训练的NMT模型来初始化儿童模型。在这种情况下,我们培训了在SPA语料库中预先训练的两个变压器模型,并在我们的SPA-TO-MSL数据集上对其进行了微调,并在NMT指标中获得了可接受的性能。
该文章的组织如下。部分方法描述了在SPA-MSL数据集上微调所选预训练模型的方法。部分数据记录分析数据集,语言的词汇和句子长度,部分技术验证包括对M1和M2模型的数据集的验证,并通过可视化NMT指标(例如BLEU,Rouge和Ter)来评估其性能。
以下部分描述了NMT模型的一些基本原理,以及在被考虑的语言中具有完整且可用的语料库的必要性,以证明拟议语料库的发展和测试是合理的。
方法
神经机器翻译(NMT)
NMT开发并实施了人工神经网络模型,以两种不同语言的语言结构之间产生精确的关系。因此,在NMT中,语言对的语言资源由所考虑语言之间的语料库中可用的平行语料库确定。对平行语料库的规模没有最低要求,将语言对分类为高,低或高的资源。即使某种语言具有许多单语言语料库,同时仍然拥有另一种语言的小平行语料库,该语言也被视为NMT任务的LR。
正式演讲,NMT模型γ翻译句子xsrc在来源src语言ytgt在目标中TGT。与平行培训语料库c,模型γ通常通过最大程度地减少负模样损失来训练:
$$ {l} _ {\ gamma} = \ sum _ {{x} _ {src},{y} _ {tgt} \ in C} - \,\,\,\ log p({y} _} _ {y} _ {y {tgt} |
(1)
这里p((ytgt£xsrc;一个 γ)是获得的条件概率ytgt给出xsrc与模型γ。NMT模型通常从左到右生成目标句子。考虑到这一点y包含m单词,有条件的概率可以写为:$ p({y} _ {tgt} | {x} _ {src}; \ gamma)= \ Mathop {\ prod} \ limits_ {j = 1}^{m}^{m}(2)编码器架构架构经常用于NMT任务。
编码器将源转换为一系列隐藏状态,解码器生成了以源隐藏表示形式和先前生成的目标词为条件的目标单词。
编码器和解码器可以是经常性神经网络(RNN)
10或神经变压器11。低资源语言的NMT受益于神经网络理论中使用的技术,例如零击和转移学习。
零射
它是指翻译模型处理语言对的能力lγ在训练期间从未见过。通常使用多语言NMT和转移学习来实现它。例如,如果模型接受了英语对英语和英语对 - 对德语的培训,那么它仍然可以执行法语到英语的翻译,即使它没有明确培训12。零击学习很有用,因为它消除了每对语言之间的并行数据的要求。
转移学习NMT
它是ML的一个子区域,它通过解决一个自动学习问题,任务或模型而获得的知识转移或调整知识,并通过将其应用于相关的模型(称为子模型),以此为父。亲本模型接受了来自高资源语言对的大量并行数据的训练,然后将其用于初始化在小数据集(LRL)上训练的儿童模型的参数13。该技术的优点包括减少儿童数据培训的大小需求,提高儿童任务的表现以及与从头开始训练的儿童模型相比,收敛的速度更快。
进行转移学习有两种方法:温暖的开始和冷启动。第一个涉及利用相关任务的预培训模型或现有知识来初始化新模型的培训。这涉及使用预先训练的模型的权重和参数在大型数据集上训练模型,以使用特定于任务的数据来初始化最新模型并在特定任务或域上训练模型,从而调整预训练的权重14,,,,15,,,,16。后者涉及从头开始训练模型,而无需利用预训练的模型。此过程涉及随机初始化模型的权重和参数,并使用特定数据从头开始训练模型17,,,,18,,,,19。通常,父母和孩子具有相同的目标语言20,,,,21,,,,22,而其他人则为父母和孩子使用相同的源语言23,,,,24。但是,父母和孩子可能不共享语言25,,,,26。尽管转移学习提供了优势,但有必要引入一个补充过程,以完善孩子与母语之间的关系。这个过程称为微调。
微调是ML中的一个过程,其中在特定数据集中进一步培训了预训练的模型,以使其适应特定任务。这是一种利用该模型在初始培训阶段获得的知识的方法,并完善了该模型以在专业任务上执行得更好。在基于NLP的自动翻译中,微调使用了监督的培训表。此过程是在具有标记示例的较小的,特定于任务的数据集上对预训练的模型进行训练的地方。语言模型接受了大量一般文本数据的培训。然后,通过在带有标签样品的较小数据集上训练该预训练的模型来适应特定任务。该技术广泛用于LRL的MT20,,,,27,,,,28。
一旦评估了NMT的常规特征,数据集将详细描述,并将其验证为传统水疗中心和MSL之间的有用语料库进行验证。
数据集开发方法和评估方法
考虑到MSL词典29,,,,30,MSL语法书籍31,诸如Interseâ±a之类的应用32以及对MSL口译员的评估。总共有3000个水疗中心(温泉)到MSL对NMT任务。这些句子包括在水疗中心中的常见短语,例如问候,关于天气,情绪,一周的日子和问题的表达。
这项研究考虑了配置数据集中的所有句子以遵循水疗语言的语法规则。此外,考虑了数据集中语法句子的一般分布以及一般水疗语言中的语法句子。
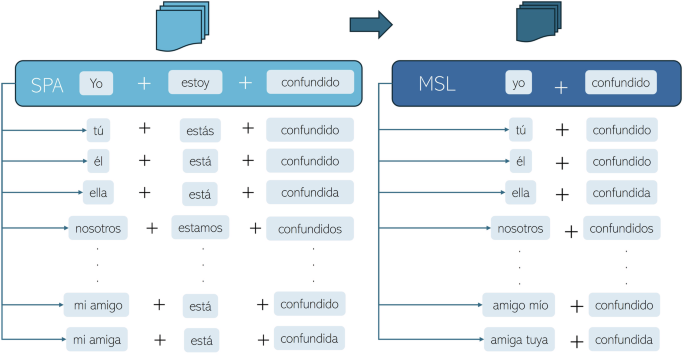
语料库设计策略考虑使用带有基本主题的句子源,然后以不同的时态和共同补语结合的动词。然后,以前的句子中选定的动词是固定的,将主题更改为考虑男女,奇异的,显式的毫不言语和个人界面句子。此外,选择了一些共同的补充来改变提议的受试者的一些替代动词。该策略在语料库中提供了完整的句子变体,为其提供了可能用于自动翻译的语料库的可变性复杂性。图 1显示如何完成一个SPA-TO-MSL对的变化:包含形容词(adj)的属性句子:yo(s)estoy(v)confundido(adj)(spa)(我很困惑(ENG))变成yo(S)Confundido(形容词)(MSL)。如果调整是固定的,并且s随不同代词而变化 -YO,Tu,El,Ella,Nosotros,...(Spa)(我,您,他,她,她,我们.....(ENG))该动词与S.的对应关系相结合,因此获得了同一SPA-TO-MSL对的不同版本。

语料库设计过程。
所有句子均提出,考虑了水疗语言中使用的常见句子。句子和短语与标准和官方语法规则相匹配。对于每天可能听到的口语句子,这看起来可能是人为的。然而,拟议的数据库必须包含与官方水疗语言相对应的句子。鉴于这种理由,拟议的句子满足了这样的条件,使其足以进行自然语言处理研究,如本研究所示的示例。
几个正式指标用于验证已发达的语料库。以下小节列出了应用于拟议语料库的那些指标的一般特征。
词汇相似性
免责声明
本文并非旨在反映水疗语言的真实使用。相反,目标是根据语法规则制定一组句子,这些句子不打算反映实际语言使用。这项研究还承认,语言使用包括对上下文的变化,其数据集不会试图镜像。
本节介绍了拟议的SPA-TO-MSL对的词汇相似性。这项研究考虑了两种用于词汇相似性分析的方法:jaccard的相似性和与单词嵌入的余弦相似性。
词汇相似性量化了两个词汇单元的相似性,通常是实际数字。词汇单元可以是单个单词,复合单词或文本段33。在计算语言学中,词汇相似性通常是指单词或文本集之间的相似性,可以使用诸如jaccard相似性和余弦相似性等指标来量化这些相似性。计算Jaccard的相似性和与单词嵌入的余弦相似性,以测量MSL和SPA句子之间的相似性得分。jaccard相似性得分测量集合之间的相似性;它被认为是简单有效的,但不会捕获语义关系。相比之下,余弦与单词嵌入的相似性捕获了语义关系,但需要通过单词训练的嵌入。jaccard的相似性
它是N-Gram类的算法。
测量两组数据之间的相似性。jaccard得分从0到1。得分越高,两组之间的相似性越高。jaccardJ(A,B)两组之间的相似性一个和b被定义为它们的交点的大小除以联合的大小。从数学上讲,它可以表示为:
$$ j(a,b)= \ frac {|a \ cap b |} {|a \ cup b |} $$
(3)
余弦与单词嵌入的相似性
tf - 我df代表术语频率 - 逆文档频率,因为它都是它们的乘积。tf - 我dfvectorizer是一种众所周知的NLP工具,可将文档集合转换为数值结果,即单词嵌入。此方法广泛用于信息检索和文本挖掘,以在文档中识别具有情感分析等应用程序的重要单词34,,,,35和文档分类36。
-
术语频率(TF)。这是文档中单词出现的次数。衡量一个单词的重要性w在文档中d。它是由等式定义的(4) 在哪里fw,,,,d是频率w在d和\({f} _ {{w}^{*},d} \)都是单词w*$$ tf(w,d)= \ frac {{f} _ {w,d}}} {{\ sum} _ {w* \ in d} {f} {f} _ {
(4)
逆文档频率(IDF)
-
。单词的IDF是该单词在文档中的罕见。它是通过等式描述的(5), 在哪里nd是文件的总数,其中d是所有文档w。$$ idf(w,d)= \ log \ frac {{n} _ {d}}} {|
\ {d \ in D:w \ in D \} |} $$
(5)
因此,tf - 我df由:
$$ tf-idf(w,d)= tf(w,d)\ cdot idf(w,d)$$
(6)
-
余弦相似性。这是两个向量之间的角度\(\ oftrightarrow {a} \)和\(\ oftrightarrow {b} \)在n维空间中。等式(7)表达的余弦相似性\(\ oftrightarrow {a} \)和\(\ oftrightarrow {b} \), 在哪里\(\ oftrightArrow {a} \ cdot \ oftrightarrow {b} \)是向量的点产物\(\ oftrightarrow {a} \)和\(\ oftrightarrow {b} \)和\(\ Parallel \ oftrightarrow {a} \ Parallel \)和\(\ Parallel \ oftrightarrow {b} \ Parallel \)是幅度。
$$ \ cos(\ theta)= \ frac {\ oftrightArrow {a} \ cdot \ cdot \ oftrightArrow {b}} {\ parallel \ parallet \ costrightArrow {a} \ parallel \ parallel \ parallel \ parallel \ pareleart \ parterrient \ costright \ costerright \ costerright \ costrightArrow {b} $ {b} $$
(7)
余弦相似性的值在1到1:a)1表示两个向量是相同的,b)0表示两个向量是正交的(无相似度),而c)1表示两个向量对立。
就像jaccard相似性一样xtr一个我n和xv一个l用Spacy Library®删除了象征性,下降,诱人的,停止单词和标点符号。tf - 我dfvector我zer从sc我k我tle一个rn安装了图书馆。
NMT验证模型
这项研究考虑了两个水疗预测的模型来验证拟议的语料库:helsinki-nlp/opus-mt-es-es和巴托。人工翻译模型,考虑到水疗和MSL光泽具有许多单词的直接对应关系。例如,这个词Libro(Spa)(书籍(ENG))在MSL光泽中是libro(MSL)。
helsinki-nlp/opus-mt-es-es(M1型)
该模型是Opus-MT项目的一部分37,由赫尔辛基大学语言技术研究小组开发的预培训的NMT模型集合38。它建立在Marian MT Framework网络上。它的基础体系结构是变压器编码器模型。它专为释义,在水疗中心内进行校正。该模型可以从HuggingFace®的在线存储库中检索39。这似乎是多余的,但是在语言的特定方言或变体需要专门处理或使用相同语言的双语数据的情况下,它很有用。该模型在释义,样式转移和域适应性方面具有潜在的应用,这是这项工作的目的:SPA至MSL适应。该模型的体系结构基于变压器体系结构。它使用句子(SP)方法作为令牌化。SP分析字符序列的频率和出现,以学习一组最佳的子词单元集。它使用Umigram语言模型来估计不同子词的概率。
巴托(M2)
提出了双向和自回旋变压器(BART)40。这是一款Denoing AutoCododer,将损坏的文档映射到其得出的原始文档。它被用在损坏的文本和从左到右的自动回归解码器上的双向编码器中作为SEQ2SEQ模型实现。该模型在编码器和解码器中使用了六层,各层都使用了12层。Bart使用多种损坏方法,包括令牌掩蔽,令牌删除,文本填充(随机替换文本的跨度)和句子排列(调整句子的顺序)。BART模型变体有不同的大小,包括:
-
BART-BASE:它带有六个编码层,六个解码器层和1.39亿个参数。
-
巴特大:它带有12个编码层,12个解码器层和4.06亿个参数。
BART使用SP,可以通过将其分解为亚基来处理OOV单词。
巴托41是巴特的变体模型;它遵循编码器和解码器的BART基本体系结构,各有六层。它具有十二个注意力头和768个隐藏尺寸。它是专门用水疗语言培训的,并使用了与Bart相同的腐败方法,但掩盖了30%的令牌。它使用SP来构建50,264个令牌的令牌,并且适用于诸如汇总,问答和MT之类的生成任务。
微调过程
预训练的NMT模型的微调涉及几个阶段,整体过程如图所示。 2。模型m1和m2在GoogleColab®中进行了微调,tr一个nsformers拥抱face®图书馆被使用:图2SPA-TO-MSL语料库的微调过程。1。数据集的准备:数据集将转换为逗号分离值,并分为培训80%,验证为20%(

tr
-
一个
我n,一个 xv一个l)。图 17显示了遵循预处理的方法的图。2。班级一个你toto
-
k
en我zer对于每个预训练模型而言,这是不同的。这以每个模型接受的正确格式输出句子。例如,M1格式为以下:\({X} _ {src} = [{{\ prime} \,<\,s \,> \,> \,{\ prime},{\ prime} \,\ _ soy {\ _ soy {\ prime},{\ prime},{\ prime},{\ prime} \,< /s> {\ prime}] \),,,,\({y} _ {src} = [<\,s \,>,{\ prime} \,\ _ yo {\ prime},{\ prime} \ _ \ \ \ \ \,oyen {\ prime},{\ prime} \,{\主要的} ]\)。通过预处理功能,整个数据集被标记化并截断为m一个x_length3。令牌仪的输出为字典的格式,该字典包含:我np你t_我d
-
s
,在这种情况下l一个bels场地。一个一个ttent我on_m一个sk还会创建并指示应参加哪个令牌,以及应忽略哪些令牌,以及decoder_我np你t_我ds是转移的版本的l一个bels。4。一个d一个t一个_coll一个tor是变压器拥抱面部库,准备用于模型训练或推理的数据批次,并确保动态填充,即确保批次中的所有序列的长度相同5。该模型是为SEQ2SEQ生成的加载,即将输入序列映射到输出序列。6。选择两个模型的超参数相等:
-
•评估策略:它设置为时代。
这意味着在每个时期的末尾评估模型•验证b一个tchs我ze= 64•培训b一个tchs我ze= 32
-
•培训数量
nepochs
-
= 20
•重量衰减= 0.01
•优化器= Adam with
-1= 0.9, -2= 0.9999和μ= 187。先前的超参数和加载模型传递给
tr一个我ner使用SPA-TO-MSL数据集开始培训和评估类API。这两个NMT模型都实施了这种微调过程。这种策略简化了拟议的语料库的验证。计算资源M1和M2型号都是从拥抱脸上下载的42使用tr一个
nsformers图书馆。
培训论点已定义
tr一个我n我ng一个rg你m
-
e
nts课堂,包含所有用于培训和评估的超参数。接下来,两种预训练的模型均在借助tr一个我ner
类API。
该评估使用了带有22.5 GB RAM的Colab L4 GPU。
COLAB后端环境提供53 GB的RAM并用途Python 3。评估指标评估和比较M1和M2模型的性能的指标是Sacrebleu,Rouge和Ter。这些经常在NMT中用于评估翻译质量。双语语言评估研究(BLEU)它是评估机器生成文本质量的工具43。BLEU分数评估了翻译与其参考的距离。它不能衡量可理解性或语法正确性。此外,由于令牌化,套管处理和平滑技术的不一致,BLEU的不同实现可能会产生不同的分数,并且通常需要对参数进行手动调整才能在特定数据集中进行最佳性能。Sacrebleu44解决了原始BLEU指标的几个缺点,因为它提供了标准化的实现。它指定了象征化,降低外壳和平滑方法以消除歧义。Sacrebleu将整个测试集作为一个单元,而不是像传统BLEU一样计算单个句子,直接在语料库级别计算BLEU。这利用现实世界的性能。该度量的范围从0到1。除非其与参考相同,否则很少的翻译得分为1。因此,每句话还有更多参考翻译。通常,NMT认为50%的BLEU被认为可以接受。N-Grams的精度计算为候选翻译与参考转换之间的重叠n-gram数量的比率pn是n-grams的精度。$$ {p} _ {n} = \ frac {{{\ sum} _ {n-gram \ in Cantidate} in min(count {t} _ {t} _ {tangiates}(n-gram),count {t} _ {t} _ {refermation} _ {remage}(refermation}(n-gram)(n-gram)}} {candidatecoun {t} _ {cantidate}(n-gram)}} $$(8)为了防止无义或不良翻译,有简短的惩罚(BP),以防止短期翻译获得高分。计算如下:$ bp = \ left \ {\ strag {array} {ll} 1,&\,{\ rm {if}}} \,\,\,\,\,\,\ \ \ \ \ \ \ \ frac {r} {r} {c} {c}&\,{(9)这里c是候选人翻译的长度r是参考翻译的长度。在不同的n克(通常为1至4)上的精度的几何平均值和wn是每个n-gram的重量通常设置为\(\ frac {1} {n} \)$$ {ln}(p)= \ mathop {\ sum} \ limits_ {n = 1}^{n} {w} {w} _ {n} \ log \,{p} _ {n} $$(10)最终的Sacrebleu得分是通过结合简短惩罚和计算精度的几何平均值来计算得出的。
翻译编辑率(TER)
ter
45
是通过计算将假设(候选句子)转换为参考句子所需的编辑数来评估机器翻译质量的度量。编辑类型如下:插入我:在假设中添加一个单词。删除
d:从假设中删除一个单词。替代s
:用不同的单词替换假设中的单词。
转移
sh
:将一系列连续的单词序列移至不同的位置。
TER的方程是以下内容。
$$ ter = \ frac {i+d+s+sh} {r} $$(12)低TER(接近0)表示高质量的翻译,而所需的编辑很少,而高TER表示匹配参考所需的许多编辑。以召回的研究为重要的评估(Rouge)胭脂46是一组指标,用于通过比较参考摘要和翻译任务来评估摘要的质量。衡量候选摘要和参考摘要之间N-gram的重叠。最常用的n-gram是Unigram(Rouge-1)和Bigrams(Rouge-2)。
$$ rouge-n = \ frac {{\ sum} _ {ref \ in References} {\ sum} _ {gra {m} _ {m} _ {n} \ in
ref} min \ left(\ right.coun {t} _ {cantiDates}(gra {m} _ {n}),{
ref} \,coun {t} _ {ref}(skip-bigram)} $$
(13)
数据记录数据记录存储库SPA-TO-MSL数据集
-
47可公开可用:https://doi.org/10.6084/m9.figshare.28519580
-
和https://doi.org/10.57760/sciencedb.21522。
-
它由不同格式的多个文件组成,以支持SPA-TO-MSL的使用和评估。ESP-LSM_GLOSSES_CORPUS.XLSX:主要数据集,其中包含3,000对西班牙语及其相应的MSL Glososs的主要数据集中.xlsx
-
扩大。第一列称为尤其
在第二列中包含spa中的句子,命名
MSL
,包含其相应的翻译到MSL。
ESP-LSM_GLOSSES_CORPUS.CSV:这是一个逗号分隔的值文件(
CSV
)ESP-LSM_GLOSSES_CORPUS.XLSX的版本,可在NLP管道中更容易处理。ESP_LSM_Analysis.ipynb:jupyter笔记本,其中包含数据集中的探索性数据分析(EDA),包括统计见解。MSL中的语法结构
考虑到以下语法结构,建立了SPA-TO-MSL数据集:
1。
性别:
真正的学术界Espaã±ola(rae)®定义性别
48作为名词和代词中固有的语法类别,在其他类别中通过一致性编码,在动画代词和名词中可以表达性爱。它分为雄性(M)和女性(F)。在MSL中,性别不存在。因此,定义的文章(ar
-
)EL,LA,LOS,LAS((这用英语)和非定义UNO,UNA,UNOS,UNAS((
-
a/an在英语中)在MSL中不存在。此外,对于性别,
-
穆杰尔((
女士
(英语)
)追随主题。在句子1(a)中,这个词
niã±a(温泉)((女孩(英语))由手势组成niã±o+穆杰尔(温泉)((男生+女士(英语)),对于单词相同,Esposa(温泉)((妻子(英语))Esposo+穆杰(丈夫+女士(英语))在MSL中。(一个)la(ar)niã±a(s)(温泉)/(AR)女孩(英语)/niã±o(s)+穆杰(S)(MSL)(b)la(ar)Esposa(S)(温泉)/(AR)妻子(英语)/esposo(S)
-
+
Mujer(S)(S)(MSL)2。复数:复数和单数确定名词的数量。复数意味着要表达的名词的一个以上实例。它们由添加词素组成-s或者-es
-
在单词的最后。
但是,这些词素在MSL中不存在。在MSL中,复数是使用不同方法构建的。以下句子中证明了这一点。在第一种方法中,复数是数字 +主题的形式(num+s)或反向顺序(s+num)就像带有字母(a)标记的句子tres(num)patos(s)
(温泉)
三(num)鸭子(S)(英语)变成tres(num)+帕托(S)(MSL)或者帕托(S)+tres(num)(MSL)。第二种情况使用手符号的重复。不必计算重复的数量。当手符号或其分类器(CL)的特性促进时,使用此方法。在标有字母(b)的样本中:las(ar)casas(s)(温泉)(((AR)房屋(S)(英语)),复数卡萨斯变成卡萨+卡萨+卡萨在MSL中。第三种方法涉及使用定量形容词(adj)添加有关主题数量的信息;有些例子很多,有些,都喜欢字母(c)标记的句子muchos(adj)gatos(s)(温泉)/many cats (ADJ) (S)(英语)变成gatos (S)muchos (ADJ) in MSL.The quantitative adjective is placed after S. A fourth method includes plural pronouns (PRONS): ellos (as), nosotros y ustedes (they,we and you).In this kind of sentence, S is signed first and the PRON is placed after.Sentence (d) is a clear example:los (Ar) maestros (S) (温泉)变成maestros (S) ellos (PRON) (MSL):(一个)Tres (num) patos (S) (温泉)/three (num) ducks (S)(英语)/tres (num)+pato (S)(MSL)
-
(b)
Las (Ar) casas (S) (温泉)/The (Ar) houses (S)(英语)/casa (S)+casa (S)+
-
casa (S) (
MSL)casa (S) + casa (S) + casa (S) (MSL)(C)Muchos (ADJ) gatos (S) (温泉)/many (ADJ) cats (S)(英语)/gatos (S) muchos (ADJ) (MSL)(d)Los (Ar) maestros (S) (温泉)/the (Ar) professors (S) (
-
工程)
/maestros (S) ellos (PRON) (MSL)。3。Attributive sentences/copular sentences:The structure of attributive sentences issubject (S)+verb (V)
-
+
adjective/attributive (ADJ)。Some examples of copular verbs are the verb to be (is, am, are, was, were), appear, seem, look, sound, smell, taste, feel, become, and get.The structure of an attributive sentence in MSL iss+一个, and the verb is omitted.Sentences 3 (a) and (b) are attributive sentences.Sentence 3 (a):Mi amiga (S) es (V) distraÃda (ADJ)(温泉)
whose order iss
+v+adj变成s+
adjin MSL:amigo mujer mÃa (S) distraÃda (A)(MSL)。(一个)Mi amiga (S) es (V) distraÃda (ADJ)(温泉)/My friend (S) is (V) distracted (ADJ)(英语)/Amigo mujer mÃa (S) distraÃda (ADJ)(MSL)。(b)El niño (S) es sordo (ADJ)(温泉)/The boy (S) is (V) deaf (ADJ)(英语)/
-
Niño (S) sordo (ADJ)
(MSL)。4。Circumstantial complement of place (CCP)。CCP comprises information about the place where the action in which the expressed verb takes place.CCP can be identified by issuing the question在哪里?。
-
In MSL this kind of sentence if the
CCPis made up of a noun phrase, the placepgoes first, then the adverb (ADV)ahÃ(温泉)((那里工程
),sand at the end the
v。This grammatical structure satisfies the following structure:CCP+ there (ADV) + S + V. As an example in sentence 4 (a):mi amigo (S) estudia (V) en la (ADV) Biblioteca (CCP)(温泉)((My friend (S) studies (V) (at the (ADV) library (CCP))(英语)) if the questionWhere does my friend study?is formulated, the answer will be the CCP of the sentence:at the (ADV) library。In MSL the order of the sentence is changed top + 一个dv + s + v:biblioteca (P) ahà (ADV) amigo mÃo (S) estudiar (V)。(一个)Mi amigo (S) estudia (V) en la (ADV) biblioteca (CCP)(温泉)/My friend (S) studies (V) (at the (ADV) library) (CCP)(英语)/Biblioteca (P) ahà (ADV) amigo mà (S) estudiar (V)(MSL)。(b)Mi amiga (S) va (V) (a la (ADV) universidad) (CCP)(温泉)/My friend (S) goes (V) to University (A)(英语)/Mi amiga (S) va (V) (a la (ADV) universidad) (CCP)
-
(MSL)
。 5。Transitive sentences (TS)As the word 传递indicates, a transitive verb转移 the action to something or someone- and object (o
-
or direct object (DO)).
Transitive verbs demand objects because they exert an action on them. In other words, if the transitive verb lacks an object to affect, the transitive verb is incomplete or does not make sense49。 The subject can be either a noun (N) or a pronoun (PRON).Examples of TS are 5 (a) and (b).Sentence 5 (a) : Ella (S) cocina (V) arroz (DO)(温泉)
(She (S) cooks (V) rice (DO) (ENG))with structures
+v+做变成s+做+vElla (S) arroz (DO) cocinar (V)in MSL.这里她is the PRON and thes是(一个)Ella (S) cocina (V) arroz (DO)(温泉)/She (S) cooks (V) rice (DO)(英语)/Ella (S) arroz (DO) cocinar (V)(MSL)。(b)Yo (S) aprendo (V) LSM (DO)(温泉)/I (S) learn (V) MSL (DO)
-
(英语)
/Yo (S) LSM (DO) aprender (V)(MSL)。6。Intransitive sentences (IS)IS do not include DO.Intransitive verbs do not require an object to act upon.Some examples of intransitive verbs are cry, sing, sleep, laugh, etc. Sentences 6 (a) and (b) demonstrate how SPA IS are turned to MSL structure.
-
Sentence 6 (a) with grammatical structure
s+vEl (S) corre (V)(温泉)((He (S) runs (V)(英语)) is similar in MSL:El (S) correr (V)
(MSL)。El (S)
corresponds to a PRON, and the verb is in a lemmatized form.(一个)El (S) corre (V)(温泉)/He (S) runs (V)(英语)/El (S) correr (V)(MSL)。(b)La (Ar) niña (S) canta (V)(温泉)/The (Ar) girl (S) sings (V)
-
(英语)
/niño (S) + mujer (S) cantar (V)(MSL)。7。Circumstantial Complement of Time (CCT)CCT offers information about the time when the verb takes action.Expressions like:Morning, at 6 P.M, Early, Yesterday
-
bring information about the exact instant in which the verb is occurring.
Sentences 7 (a) and (b) are examples of the usage of CCT.In both cases the orders+v+做+CCTswitches to
CCT+
s+做+vin MSL(一个)(Nosotros (as))Veremos (V) una pelÃcula (DO) mañana (CCT)(温泉)/We (S) will watch (V) a movie (DO) tomorrow (CCT) (工程)/mañana (CCT) nosotros (PRON) pelÃcula (DO) ver (V)(MSL)。(b)(yo) fui (V) a bailar (DO) ayer (CCT)
-
(温泉)
/I (PRON) went (V) dancing (DO) yesterday (CCT)(英语)/ayer (CCT) yo (S) bailar (DO) ir (V)(MSL)。技术验证Composition analysis of SPA-to-MSL datasetFigures 3
-
和
4show the frequency of tagged tokens for SPA and MSL sentences, respectively, after being processed as documents with Spacy® library.When comparing data sets, a clear difference is that SPA sentences contain more determiners (DET) than MSL sentences.Examples of DET in SPA areun, una, la, el, su, mi (a, an, the (ENG)), in contrast to MSLla, el, un, una不存在。In addition, auxiliary (AUX) such as
ser, estar, and conjugations of the same verb
是
in SPA do not exist in MSL.There are fewer AUXs in MSL.图3POS for SPA sentences.图4POS for MSL sentences.Common adjectives in the SPA dataset include:oyente, sordo, alegre, triste, etc. (温泉) (hearing, deaf, sad, happy (工程))。

yo, tú, el ella, nosotros, ustedes, ellos

PUNCT refers to punctuation like
?,¿, ()。Adverbs (ADV) in the dataset primarily represent place, time, and negation.There are more ADVs in the SPA dataset.Figure 5illustrates the distribution of sentence lengths for both languages.The median sentence length for SPA is four words per sentence, while for MSL it is three words per sentence.The interquartile range (IQR) for SPA sentences is wider than for MSL, indicating variation in sentence lengths.Some outliers are present in both datasets, represented by dots above the whiskers in the boxplot.图5
Distribution of sentence lengths of SPA-to-MSL pairs.Regarding sentence structures, SPA sentences may contain articles (el, la, los, las, un, una), auxiliary verbs (ser, estar), and other grammatical components that are not typically present in MSL glosses.Additionally, some structures in MSL involve classifiers or the fusion of multiple Spanish words into a single gloss representation.

Some outliers in MSL include structures with一个
 + s
articles (A) with subject (S) that become subject (S) in SPA: “La casa / El niño†("The house / The boyâ€), or impersonal sentences that do not have a specific subject likehace calor/ está haciendo calor ("It is hot†/ “It is warmâ€), become one word in MSL: “casa / niño†(house)and “卡路†(warm/hot) 分别。Plural forms that use classifiers are also included in these kind of sentences:hace calor/ está haciendo calor ("los autos†/ “las casasâ€), become one word in MSL: “汽车+汽车+汽车((车+车+车)//casa+casa+casa((房子+房子+房子)â€.Regarding samples with 6, 7, and 8 words.Sentences of 6 words include a variety of structures, some of them with circumstantial complement of place (CCP), circumstantial complement of time (CCT), Transitive sentences (TS), etc. Some examples are as follows.• Sentences with six words:TS:
Mi tÃa quiere aprender LSM (SPA) (my aunt wishes to learn MSL) → tÃo mujer mÃa lsm aprender querer (MSL) (uncle+woman mine MSL to learn to want)
-
。TCC:mi novio irá a la universidad la próxima semana (SPA) (my boyfriend will go to university next week) → próxima semana novio mÃo universidad ir (MSL) (next week boyfriend my university to go)
-
• Sentences with seven words:TCC:Los niños estudian inglés todos los dÃas (SPA) (The kids study english every day) → todos los dÃas niño ellos inglés estudiar (MSL) (every day boy them english to study)
CCP:
-
Las niñas juegan futbol en la calle (SPA) (The girls play soccer in the street) → calle ahà niño mujer ellas futbol jugar (MSL) (street there boy woman they soccer to play)• Sentences with eight words:
-
TCC:Mi hija va a la escuela de lunes a viernes (SPA) (My daughter goes to school from Monday to Friday) → Lunes a Viernes hijo+mujer mÃa universidad ir (MSL) (Monday to Friday son+woman my university to go)
Splitting data
-
Originally, the vocabulary size of SPA sentences was 820 tokens and 650 for MSL.The autotokenizer of the model simplified the process of loading the appropriate tokenizer for the pre-trained language model-in this case SP- and it loaded special tokens: <s
>Â -start of the sentence, <
你nk>Â -unknown words, <p一个d>Â -padding token, </s>Â - end of a sentence) that were specific to the chosen model.The data set was divided into 80% data for training and the rest for validation.We obtain the metrics of the dataset.Unique words
were obtained by computing the set of words, without considering punctuation;the total number of words (total words)) 和out of vocabulary (OOV)words present in validation data but not in training data (Table 3)。Table 3 Statistics of MSL Dataset.
According to the jaccard similarity, the data set was divided as follows: 80% for training defined as
xtr一个我n(2400 sentences) and 20% for validation defined asxv一个l(600 sentences).Given this dataset separation,J (A,B)was computed for each SPA-to-MSL pair inxv一个l。平均值J (A,B)resulted in0.35分数。The frequency distribution ofJ (A,B)score is shown in Fig. 6。To obtain the similarity score, the data set was tokenized, lowercased, lemmatized, punctuation, and stop words were excluded.More than 100 sentences had close to 0 scores.Most sentences were placed between 0.4 and 0.6, and a few sentences (approximately 30 sentences) presented a score of 1.0.The vectorizer was fitted onxtr一个我n, 然后xv一个lwas transformed intotf − 我df, a sparse matrix of size 600 × 564 (embeddings).With the embeddings, the cosine similarity was calculated with equation (7)。An average similarity score of0.61获得了。The distribution of the cosine similarity score is shown in Fig. 7where most SPA-to-MSL sentences ofxv一个lhave a score of 1.0, nearly 140 sentences have a score of 0.0 and there is no score of −1.Figure 8shows the percentage difference between the source and target sets of sentences.In the case of determiners (DET), the graph shows that SPA sentences have 68.83% more than MSL sentences;in the same way, the quantity of auxiliary elements (AUX) in SPA is 84.85% higher in SPA than in MSL.图6Distribution of jaccard similarity score of SPA-to-MSL sentences.图7

图8

Quantitative validation

decoder_input_ids
(tensor of integers), there are shifted versions of the
标签or the IDs associated with MSL sentences.During training, the model uses thedecoder_input_idswith an attention mask to ensure that it does not use the token it is trying to predict, so the model performs inference similarly.The decoder in the transformer model performs inference by predicting tokens one by one.The predictions produced a list of sentences and the references a list of lists.Here, we used one reference and one prediction.
The training arguments, including hyperparameters, were initially chosen on the basis of standard values rather than through systematic optimization.The selection of parameters such as batch size, learning rate, and number of epochs, without extensive fine-tuning, follows general practices commonly applied to transformer-based models.The model was trained using the Adam optimizer, which provided an efficient balance of learning adjustments during training.
Since hyperparameter optimization was not conducted, the validation dataset was used solely to monitor the model performance and prevent over-fitting during training rather than to guide hyperparameter tuning.This allowed the validation set to serve strictly for evaluation rather than influencing hyperparameter selection.
Figure 9shows the translation quality performance for M1 with the NMT metrics described in Section Evaluation metrics.BLEU converges to 70 after 20 epochs.TER score decreases from 70 to 15 and stabilizes at 7.5 epochs, ROUGE-1 reaches 92 scores, and ROUGE-2 goes approximately from 35 to 82. Figure 10shows the validation and training loss that indicates an optimal fit as both decrease and stabilize.The validation loss goes from 2.6 to 0.45 and the training loss from 3.62 to 0.21.Regarding the M2 model.Figure 11shows the performance of the translation metrics.The BLEU starts from 65 to 82 in 20 epochs, ROUGE-1 with 85 and converges close to 92, ROUGE-2 from 78 and reaches 90 and TER from 18 stabilizes at 8. Regarding validation and training loss, the training loss in M2 is higher at the beginning, rapidly decreases in one epoch, and converges to 0. The validation loss starts at 0.044 and converges to 0.001 in 20 epochs (Fig. 12)。

Translation metrics for M1.

Training and validation loss for model M1.

Translation metrics for M2.

Training and validation loss for model M2.
In addition, this analysis considers an experiment that includes a split ratio of 80% for training (xtr一个我n), 10% validation (xv一个l), and 10% test (xtest)。The samples for training were 2400, 300 for validation and testing.We obtained training and validation loss behavior, as well as translation metrics (TER, ROUGE1, ROUGE2 and BLEU).We chose the combination of the following hyperparameters along with Adam optimization:
-
learning rate: 1.5e − 05t
-
r一个我n我ngb一个tchs我ze:Â 32v一个
-
l我d一个t我onb一个tchs我ze: 16optimizer: Adam withβ1
-
 = 0.9, β2 = 0.999 andϵ = 1e − 08num epochs: 20In Fig. 13
-
it can be seen that the M1 translation metrics converged to the following validation values:
ble你: 85.22,ro你ge1: 94.59,ro你ge2: 88.35,ter: 8.95.Regarding the loss behavior, shown in Fig. 14, we obtained 0.5118 for validation and 0.0122 for training.图13Translation metrics for Model M1 after splitting dataset in train/test/validation.图14

The test data set reported the following results:

l
e你: 83.23,ro你ge1: 91.49,ro你ge2: 84.98,ter: 10.67 and we obtained 0.4978 in loss.We did the same for the M2 model.In Fig. 15it can be seen that after 20 epochs, the translation metrics converged to the following validation values:
ble你: 83.68,ro你ge1: 95.84,ro你ge2: 89.83,ter: 6.64.Regarding the loss behavior, shown in Fig. 16, we obtained 0.0069 for validation and 0.011871 for training.图15Translation metrics for model M2 after splitting dataset in train/test/validation.图16

The test data set for the evaluation of M2 reported the following metrics:

l
e你: 85.41,ro你ge1: 95.84,ro你ge2: 89.83,ter: 6.64.Regarding the loss, we obtained 0.0103.Although the BARTO and Helsinki models were designed for SPA paraphrasing tasks, the specific fine-tuning process applied to them on the SPA-to-MSL dataset allowed the model to adapt effectively to translation tasks.The models are available athttps://huggingface.co/vania2911/esp-to-lsm-model-splitfor the M1 model andhttps://huggingface.co/vania2911/esp-to-lsm-barto-modelfor the M2 model.The colab codes were updated in the repository47with the names:“Model_M1_split_version.ipynbâ€和“Model_M2_split_version.ipynbâ€。The translations generated by these models are in the same repository with the names:“translationsM1.txtâ€和“translationsM2.txtâ€
By training on a dataset that includes a variety of contexts and structures in SPA, the models aim to achieve a balanced representation appropriate for translating into MSL, mitigating potential biases toward certain linguistic patterns.Additionally, we partitioned the data to create a test dataset to evaluate the model’s ability to generalize new data.
Qualitative validation
The translation of the trained model was analyzed when uploading the model to the Hub.Hugging Face® Repos allows to run inferences directly in the browser.The corresponding pipeline was used for the translation task.The results of the fine-tuned model are compared to Ground Truth (MSL) of translation by human expertise in Table 4。
From Table 4sentences likeÉl estudia español (温泉) (He studies SPA(英语))that becomesHe studies SPA(MSL)。Sentences that include gender likeLa niña es sorda温泉(The girl is deaf(英语))that becomesniño mujer sorda(MSL)。Similarly, for CCT sentences:Mi amigo va a la universidad de Lunes a Viernes温泉(My friend goes to university from Monday to Friday(英语))whose translation in MSL isLunes a Viernes amigo mÃo universidad ir。TableÂ
5includes translation results that were not correct at all.The incorrect translations were highlighted in red.Some sentences that have implicit PRON likeVivo en México温泉(I live in Mexico工程)were mistakenly translated asMéxico vivo vivirby Model M1, while Model M2 correctly translated the previous sentence.Also, variations in sentences with plurals likeHay perros en el parque温泉(There are dogs in the park工程)were incorrectly translated asHay perros en el parqueby model M1 and model M2.The lack of examples of sentences with implicit PRON in the training dataset causes this.This issue can be fixed by augmenting the dataset with some backtranslation techniques in future work.
用法注释
The model cards ofm1和m2 are available at: the repository:https://huggingface.co/VaniLara/esp-to-lsm-mode和https://huggingface.co/VaniLara/esp-to-lsm-barto-model。To use both models with变压器library, there is a guide on how to use it onhow to use this modeltab on each model’s repository.As a demonstration: To loadm2 the model directly on Colab, the following lines of code are copied fromhow to use this modeltab on the model’s repository:
从变压器进口AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained ("VaniLara/esp-to-lsm-barto-model")
model = AutoModelForSeq2SeqLM.from_pretrained ("VaniLara/esp-to-lsm-barto-model")
Note that the transformer library must be installed beforehand.Our pre-trained model and tokenizer are loaded.
A pipeline will be required to execute the inference with M2.The pipeline is instantiated.
从变压器进口管道
pipe = pipeline ("text2text-generation", model="VaniLara/esp-to-lsm-barto-model")
The input is prefixed to run the inference in Colab.一个管道is instantiated, and a text in SPA is passed:Me gusta el suéter de color rosa (SPA)(I like the pink sweater) that outputs the MSL gloss translation:yo sueter rosa gustar
#text= "me gusta el sueter rosa"
result=pipe (text)result=
#['generated_text':' yo sueter rosa gustar']
M1 works the same way.
In addition, there is the option to execute the inference on the pytorch® and the tensorflow®.
存储库47包括.ipynbfiles, which contain the programming methodology for preprocessing and training the translation models.These notebooks provide a structured and interactive environment for executing Python® code, visualizing results, and documenting the process.
•Model_M1.ipynb: A Google Colab® notebook containing the code for fine-tuning the M1 transformer model for Spanish-to-MSL gloss translation.The data were split into 80% and 20% validation.It contains the code to fine-tune and evaluate with the pre-trained Modelm1,一个你totoken我zer, and thetr一个我ner班级。To run the program, one needs to sign up and create a profile on Hugging Face and then access it with a token that is provided when a security token is created on the settings tab.It is recommended to install the commented libraries.•
Model_M1_split_version.ipynb: A Google Colab® notebook containing the code for fine-tuning the M1 transformer model for Spanish-to-MSL gloss translation.The data were divided into 80% training, 10% testing, and 10% validation.
Model_M2.ipynb:A Google Colab® notebook implementing fine-tuning of the M2 model for the same translation task.he data were split into 80% and 20% validation.
•Model_M2_split_version.ipynb: A Google Colab® notebook containing the code for fine-tuning the M2 transformer model for Spanish-to-MSL gloss translation.The data were divided into 80% training, 10% testing, and 10% validation.
•translationsM1.txt:。TXTfile containing reference and predicted translations for model M1.
•translationsM2.txt:。TXTfile containing reference and predicted translations for model M2.
•readme.md: A documentation file that provides instructions on using the dataset and models.
The workflow data-processing of SPA-to-MSL dataset is depicted in the diagram of Fig. 17。

Data-processing workflow for using the proposed corpus from SPA to MSL.
代码可用性
The model cardsm1和m2 are available inhttps://huggingface.co/VaniLara/esp-to-lsm-model和https://huggingface.co/VaniLara/esp-to-lsm-barto-model。The code files are contained in Colab notebooks in a Figshare repository47(see Section Data records).
参考
Besacier, L., Barnard, E., Karpov, A. & Schultz, T. Automatic speech recognition for under-resourced languages: A survey.Speech Commun. 56, 85–100,https://doi.org/10.1016/j.specom.2013.07.008(2014)。
文章一个 Google Scholar一个
Joshi, P., Santy, S., Budhiraja, A., Bali, K. & Choudhury, M. The state and fate of linguistic diversity and inclusion in the NLP world.在计算语言学协会第58届年会论文集, 6282–6293,https://doi.org/10.18653/v1/2020.acl-main.560(2020)。
Ahmed, M., Zaidan, B. B., Zaidan, A. A., Salih, M. & Lakulu, M. M. A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017.传感器 18, 2208,https://doi.org/10.3390/s18072208(2018)。
文章一个 广告一个 PubMed一个 PubMed Central一个 Google Scholar一个
Moryossef, A., Yin, K., Neubig, G. & Goldberg, Y. Data augmentation for sign language gloss translation.enProceedings of the 1st International Workshop on Automatic Translation for Signed and Spoken Languages (AT4SSL), 1–11,https://aclanthology.org/2021.mtsummit-at4ssl.1/(2021)。
Escobar L.-Dellamary, L. La lengua de seÑas mexicana, ¿una lengua en riesgo?Contacto bimodal y documentación sociolingüÃstica.Estudios de LingüÃstica Aplicada 62, 125–152,https://doi.org/10.22201/enallt.01852647p.2015.62.420(2016)。
文章一个 Google Scholar一个
BURAD, V.La glosa: Un sistema de notación para la lengua de señasMendoza,https://cultura-sorda.org/la-glosa-un-sistema-de-notacion-para-la-lengua-de-senas(2011)。
Li, D.等。Transcribing natural languages for the deaf via neural editing programs.corr abs/2112.09600。https://arxiv.org/abs/2112.09600(2021)。López, B. D., Escobar, C. G. & MartÃnez, S. M.
Manual de gramática de la lengua de señas mexicana (LSM)。Editorial Mariángel.https://www.calameo.com/read/0001639034c5089940816(2016)。Gu, J., Hassan, H., Devlin, J. & Li, V. O. K. Universal Neural Machine Translation for Extremely Low Resource Languages.
Proc。2018 Conf.北部。Chapter Assoc.计算。Linguist.: Hum.朗。Technol。344–354,https://doi.org/10.18653/v1/N18-1032(2018)。
Dong, D., Wu, H., He, W., Yu, D. & Wang, H. Multi-task learning for multiple language translation.Proc。53rd Annu.见面。联合。计算。语言学家。& 7th Int.Joint Conf.纳特。朗。过程., 1723–1732.Association for Computational Linguistics, Beijing, China.https://doi.org/10.3115/v1/P15-1166(2015)。
Vaswani, A.等。注意就是您所需要的。ADV。神经信息。过程。系统。 30, 5998–6008,https://doi.org/10.48550/arXiv.1706.03762(2017)。
文章一个 Google Scholar一个
Blackwood, G. W., Ballesteros, M. & Ward, T. Multilingual Neural Machine Translation with Task-Specific Attention.ARXIV预印本abs/1806.03280.Preprint athttps://arxiv.org/abs/1806.03280(2018)。
Pan, S. J. & Yang, Q. A survey on transfer learning.IEEE Trans。知识。数据工程。 22, 1345–1359,https://doi.org/10.1109/TKDE.2009.191(2010)。
文章一个 Google Scholar一个
Zoph, B., & Knight, K.Multi-Source Neural Translation。Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 30–34.计算语言学协会。https://aclanthology.org/N16-1004(2016)。
Nguyen, T. Q. & Chiang, D. Transfer learning across low-resource, related languages for neural machine translation.Proc。8th Int.Joint Conf.纳特。朗。过程。2, 296–301.Asian Federation of Natural Language Processing.https://aclanthology.org/I17-2050(2017)。
Kocmi, T. & Bojar, O. Trivial Transfer Learning for Low-Resource Neural Machine Translation.Proc。3rd Conf.马赫。Transl.: Res.帕普。244–252.Association for Computational Linguistics, Brussels, Belgium.https://doi.org/10.18653/v1/W18-6325(2018)。
Kim, Y., Gao, Y. & Ney, H. Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies.Proc。57th Annu.见面。联合。计算。语言学家。1246–1257.Association for Computational Linguistics, Florence, Italy.https://doi.org/10.18653/v1/P19-1120(2019)。
Kocmi, T. & Bojar, O. Transfer Learning across Languages from Someone Else’s NMT Model.ARXIV预印本arXiv:1909.10955.Preprint athttps://arxiv.org/abs/1909.10955(2019)。
Lakew, S. M., Erofeeva, A., Negri, M., Federico, M. & Turchi, M. Transfer Learning in Multilingual Neural Machine Translation with Dynamic Vocabulary.arXiv:1811.01137。http://arxiv.org/abs/1811.01137(2018)。Liu, Y.
等。Multilingual Denoising Pre-training for Neural Machine Translation。2001.08210.https://arxiv.org/abs/2001.08210(2020)。Conneau, A.
等。无监督的跨语言表示学习。Proc。58th Annu.见面。联合。计算。语言学家。8440–8451,https://doi.org/10.18653/v1/2020.acl-main.747(2020)。
Aharoni, R., Johnson, M. & Firat, O. Massively Multilingual Neural Machine Translation.Proc。2019 Conf.北部。Chapter Assoc.计算。Linguist.: Hum.朗。技术。1 , 3874–3884,https://doi.org/10.18653/v1/N19-1388(2019)。文章
一个 Google Scholar一个 Kocmi, T. & Bojar, O. Efficiently reusing old models across languages via transfer learning.在
Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, 19–28,https://doi.org/10.18653/v1/2020.eamt-1.3(2020)。Khemchandani, Y.
等。Exploiting language relatedness for low web-resource language model adaptation: An Indic languages study.在Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 1312–1323,https://doi.org/10.18653/v1/2021.acl-long.105(2021)。
Kocmi, T. & Bojar, O. Trivial transfer learning for low-resource neural machine translation.在Proceedings of the Third Conference on Machine Translation: Research Papers, 244–252,https://doi.org/10.18653/v1/W18-6325(2018)。
Luo, G., Yang, Y., Yuan, Y., Chen, Z. & Ainiwaer, A. Hierarchical transfer learning architecture for low-resource neural machine translation.IEEE访问 7, 154157–154166,https://doi.org/10.1109/ACCESS.2019.2936002(2019)。
文章一个 Google Scholar一个
Jiang, Z. Low-resource text classification: A parameter-free classification method with compressors.In Rogers, A., Boyd-Graber, J. & Okazaki, N. (eds.)Findings of the Association for Computational Linguistics: ACL 2023, 6810–6828,https://doi.org/10.18653/v1/2023.findings-acl.426(Association for Computational Linguistics, Toronto, Canada, 2023).
Wang, R., Tan, X., Luo, R., Qin, T. & Liu, T.-Y.A Survey on Low-Resource Neural Machine Translation。2107.04239.https://arxiv.org/abs/2107.04239(2021)。
Flores, C. A. M., Westgaard, M. P., Dellamary, L. E., Aldrete, M. C. & del RocÃo G. RamÃrez Barba, M.Diccionario de Lengua de Señas Mexicana LSM Ciudad de México(Capital Social Por Ti, 2017).
Hernández, M. C.Diccionario Español-Lengua de Señas Mexicana (DIELSEME)(SEP, México, 2014).
Daniel López, B. E. S. & Mirna MartÃnez, S.Manual de Gramática de Lengua de Señas Mexicana (LSM)(2016)。
Interseña TeamInterseña: SPA Sign Language Translation App。Mobile application software.https://play.google.com/store/apps/details?id=intersign.aprender.lsm&hl=es_419&pli=1(2024)。
Oliva, J., Serrano, J. I., del Castillo, M. D. & Iglesias, Ã.SyMSS: A syntax-based measure for short-text semantic similarity.Data Knowl.工程。 70, 390–405 (2011).
文章一个 Google Scholar一个
Kumar, V. & Subba, B. A TfidfVectorizer and SVM based sentiment analysis framework for text data corpus.在Proceedings of the 2020 National Conference on Communications (NCC), 1–6,https://ieeexplore.ieee.org/document/9056085,,,,https://doi.org/10.1109/NCC48643.2020.9056085(2020)。
Eshan, S. C. & Hasan, M. S. An application of machine learning to detect abusive bengali text.在2017 20th International Conference of Computer and Information Technology (ICCIT), 1–6,https://doi.org/10.1109/ICCITECHN.2017.8281787(2017)。
Al-Obaydy, W. I., Hashim, H. A., Najm, Y. & Jalal, A. A. Document classification using term frequency-inverse document frequency and k-means clustering.Indonesian Journal of Electrical Engineering and Computer Science 27, 1517–1524,https://doi.org/10.11591/ijeecs.v27.i3.pp1517-1524(2022)。
文章一个 Google Scholar一个
Tiedemann, J.等。Democratizing Neural Machine Translation with OPUS-MT.Language Resources and Evaluation.58, 713–755.Springer Nature.1574-0218.https://doi.org/10.1007/s10579-023-09704-w(2023)。
University of Helsinki, Language Technology Group.Language Technology Blog。https://blogs.helsinki.fi/language-technology(2024)。
Helsinki-NLP.OPUS-MT Spanish-to-Spanish: Machine translation model from Spanish to Spanish.Hugging Face.可用https://huggingface.co/Helsinki-NLP/opus-mt-es-es(2024)。
Lewis, M.等。BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.arXiv:1910.13461。http://arxiv.org/abs/1910.13461(2019)。Araujo, V., Trusca, M. M., Tufiño, R., & Moens, M.-F.
Sequence-to-Sequence SPA Pre-trained Language Models。2309.11259.https://arxiv.org/abs/2309.11259(2023)。拥抱脸
Hugging Face - The AI Community Building the Future。https://huggingface.co/(2024)。Papineni, K., Roukos, S., Ward, T. & Zhu, W. BLEU: a method for automatic evaluation of machine translation.
Proc。40th Annu.见面。联合。计算。语言学家。311–318.Association for Computational Linguistics, Philadelphia, Pennsylvania.https://doi.org/10.3115/1073083.1073135(2002).
Post, M. A call for clarity in reporting BLEU scores.Proc。3rd Conf.马赫。Transl.: Res.帕普。186–191.Association for Computational Linguistics, Brussels, Belgium.https://doi.org/10.18653/v1/W18-6319(2018)。
Snover, M., Dorr, B., Schwartz, R., Micciulla, L. & Makhoul, J. A study of translation edit rate with targeted human annotation.Proc。7th Conf.联合。马赫。翻译。Am.: Tech.帕普。223–231.Association for Machine Translation in the Americas, Cambridge, Massachusetts, USA.https://aclanthology.org/2006.amta-papers.25(2006)。
Lin, C.-Y.ROUGE: A package for automatic evaluation of summaries.在Text Summarization Branches Out, 74–81.https://aclanthology.org/W04-1013/(2004)。
Lara Ortiz, D. V., Fuentes Aguilar, R. Q. & Chairez, I. Spanish to Mexican Sign Language (MSL) glosses corpus for NLP tasks.小花 https://doi.org/10.6084/m9.figshare.28519580(2025)。
Real Academia Española.género.Diccionario de la lengua española (DLE)。(2024)
Ellis, M. Transitive verbs: Definition and examples.语法。https://www.grammarly.com/blog/transitive-verbs/(2022)。
Agris, U. & Kraiss, K.-F.SIGnum Database: Video Corpus for Signer-Independent Continuous Sign Language Recognition InProceedings of the LREC2010 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Language Technologies, 243–246,https://www.sign-lang.uni-hamburg.de/lrec/pub/10006.pdf(2018)。
Neidle, C., Sclaroff, S. & Athitsos, V. Signstream: A tool for linguistic and computer vision research on visual-gestural language data.Behavior research methods, instruments, and computers : a journal of the Psychonomic Society, Inc 33, 311–20,https://doi.org/10.3758/BF03195384(2001)。
文章一个 CAS一个 Google Scholar一个
Othman, A. & Jemni, M. English-ASL Gloss Parallel Corpus 2012 (ASLG-PC12).在Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions between Corpus and Lexicon LREC, 22–23,https://www.sign-lang.uni-hamburg.de/lrec/pub/10006.pdf(2012年)。
Camgoz, N. C., Hadfield, S., Koller, O., Ney, H. & Bowden, R.Neural Sign Language Translation。Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).7784–7793.IEEE,https://doi.org/10.1109/CVPR.2018.00812(2018)。
Belissen, V., Braffort, A., & Gouiffès, M.Dicta-Sign-LSF-v2: Remake of a Continuous French Sign Language Dialogue Corpus and a First Baseline for Automatic Sign Language Processing。Proceedings of the Twelfth Language Resources and Evaluation Conference, Calzolari, N.等。European Language Resources Association, 6040–6048,https://aclanthology.org/2020.lrec-1.740(2020)。
Hanke, T., Schulder, M., Konrad, R. & Jahn, E. Extending the Public DGS Corpus in Size and Depth.Proc。LREC2020 9th Workshop on Representation and Processing of Sign Languages75–82.European Language Resources Association (ELRA), Marseille, France.https://aclanthology.org/2020.signlang-1.12(2020)。
道德声明
竞争利益
作者没有宣称没有竞争利益。
附加信息
Publisher’s note关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。
权利和权限
开放访问This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.您没有根据本许可证的许可来共享本文或部分内容的改编材料。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.要查看此许可证的副本,请访问http://creativecommons.org/licenses/by-nc-nd/4.0/。重印和权限
引用本文

Lara-Ortiz, V., Fuentes-Aguilar, R.Q.
& Chairez, I. Spanish to Mexican Sign Language glosses corpus for natural language processing tasks.Sci Data 12, 702 (2025).https://doi.org/10.1038/s41597-025-04871-7
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41597-025-04871-7