
深度学习研究的范围评论阐明了耳鼻喉科和颈部手术中的人工智能鸿沟
作者:Stankovic, Konstantina M.
介绍
人工智能(AI)技术有望增强耳鼻喉科手术(OHNS)中医生的护理服务。OHNS中的临床实践丰富了图像,音频,视频,遗传和神经生理学的半结构化数据,这些数据为AI分析提供了丰富的机会。确实,越来越多的出版物探讨了AI在OHNS中的概念证明应用程序1,,,,2,,,,3。
尽管有这些机会,但如今,耳鼻喉科医生将少量的AI工具用于临床工作,其中大多数是OHN并非特定的一般工具(例如,AI驱动的语音说法和诊所笔记的环境抄写)。这种做法的部分原因是,很少有OHNS特定的AI工具可以准备进行临床部署。截至2024年8月7日,在950个FDA批准的AI/机器学习的医疗设备中4仅针对OHN开发了两个5,,,,6。显然,开发OHN临床上有用的AI工具的机会与实现这一机会之间存在差异。这种趋势已被更广泛地称为医疗保健中的AIChasmâ7。
临床研究对于通过验证其在医疗保健环境中的效用和准备就绪来翻译AI工具很重要。我们假设临床验证是OHNS中AI应用开发的研究研究领域。如果是的,则该发现将确定需要在临床针对的AI研究中需要注意的领域。为了评估这一假设,我们对AI模型开发阶段(即概念证明,离线验证,临床验证阶段)和使用模型验证的方法进行了关注。
结果
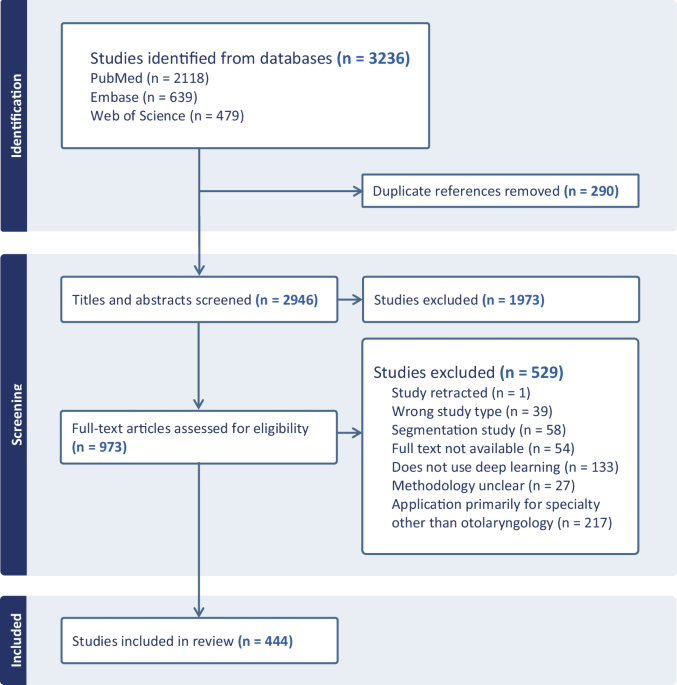
我们在数据库搜索中确定了3236个记录。删除后,我们筛选了2946个摘要和标题以及973篇全文文章。最终,有444个出版物符合纳入标准(图。1;补充数据)。此后,纳入的研究被称为OHN中的深度学习出版物,AI一词专门提到深度学习方法。

范围审查中总共包括444项研究。
OHN中深度学习出版物的时间和地理空间分布如图2所示。2。在2012年至2022年的10年期间,每年出版物的出版物从2012年的0个出版物呈指数增长增加到2022年的105个出版物,这是本综述中的最后一个全日历年(图。2a)。作者分支机构跨越了六大大洲的48个国家,证明了AI研究的全球范围(图。2b)。出版物数量最多的国家是美国(139个出版物),中国(95个出版物)和韩国(38个出版物)(补充图。1)。图2:OHN中深度学习出版物的时间和地理空间分布。一个

出版物的国家隶属关系的地理泡沫图表。对于每个国家,圈出的区域指出了至少有一位作者与该国的机构有关联的出版物的数量。该地图是使用自然地球创建的。OHN中深度学习出版物的其他描述性特征如图2所示。
3。深度学习研究跨越了所有OHNS亚专业,其耳鼻喉和神经学出版物数量最多(包括听力学)(28%)(图。3a)。AI应用的最常见目标是扩展医疗保健提供者的能力(56%),第二个最常见的目标是筛查医疗状况(30%)(图30%)。3b)。非放射学(36%)和放射学(19%)图像是AI模型分析的最常见数据类型。分析的最常见的非放射学图像是耳镜,喉镜检查,临床摄影,组织学,高光谱和鼻内镜检查图像(补充表1和补充图。2)。卷积神经网络(CNN)模型是用于分析图像,音频,视频和电生理学数据的最常用的深度学习模型类型(图。3C)。

AI在出版物中的主要OHNS子专业。b出版物中深度学习模型的应用类型。c数据类型的出版物中深度学习模型的输入类型,通过用于分析数据的深度学习模型的类型进行了分类。缩写:ANN人工神经网络,CNN卷积神经网络,GAN生成对抗网络,LLM大语言模型,LSTM Long-short术语记忆,RNN循环神经网络。
AI模型的阶段,遵守报告指南以及包括出版物中的验证方法如图2所示。4。医疗保健中AI的阶段为评估AI工具的验证研究的成熟度提供了有用的框架及其对临床部署的准备8。几乎所有研究(99.3%)处于概念验证阶段。三项(0.7%)的研究超越了硅发育中的脱机验证(图。4a)。这三项研究评估了语音denoising9,视觉语音识别10和扬声器分离11在实验环境中,人类受试者中的AI模型。令人惊讶的是,OHN的444个深度学习出版物中有零(0%)的临床验证研究。

出版物中AI模型开发的阶段。b出版物使用的报告指南。c出版物使用的评估方法。缩写:三脚架的透明报告,用于单个预后或诊断的多变量预测模型,具有非随机设计的评估的趋势透明报告,strobe增强了流行病学观察性研究的报告,星德的标准标准,用于诊断精确研究的报告标准,诊断研究,诊断 - ai ai ai综合标准的人工智能试验标准。
报告指南涉及通常以清单的形式提出的基本信息的建议,这些信息将包括在研究结果的传播中。报告指南对于医疗保健,快速发展的领域的AI研究尤其重要,并且可以提高可重复性,透明度和标准化。尽管有这一要求,但仅24项研究就很少使用报告指南(图。4b)。所使用的报告指南按顺序减少,是报告诊断准确性研究的标准(Stard)12(2.9%),个人预后或诊断多变量预测模型(三脚架)的透明报告13(1.3%),非随机设计的评估报告(趋势)14(0.7%),加强流行病学观察性研究的报告(Strobe)15(0.2%);以及报告试验人工智能(CONSORT-AI)的合并标准16(0.2%)。
单机构和回顾性验证方法最常使用(图。4C),只有10项研究(2.3%)使用单一机构(1.8%)或多机构(0.5%)数据集的前瞻性评估。值得注意的是,4项研究(0.9%)未描述其验证方法,73项研究(16%)报告了回顾性验证结果,既没有独立的测试集也不交叉验证,这是值得注意的,因为它限制了模型的可推广性评估17。
AI模型的解释性对于信任和可重复性很重要。四十一项研究(9.2%)描述了使用一种方法来解释AI模型的方法。解释性最常用的两种方法是梯度加权类激活映射(Grad-CAM)(3%)18和类激活图(CAM)19(2%)。
讨论
尽管AI技术有望改变精密医学和医疗保健,但在临床部署时,AI工具的潜在好处与它们的可变性能之间存在鸿沟7。我们证明了AI鸿沟在OHN领域尤其深入,因为在1996年2023年之间,OHN的440多个深度学习出版物之间存在明显的临床验证研究。增加临床验证研究以及超越概念验证研究的发展对于推动OHN中临床上有用的AI应用的开发至关重要。据我们所知,这是对深度学习应用程序的首次范围审查,该应用程序涉及OHNS的整个领域。
OHNS中的AI鸿沟反映了将AI技术转化为医疗保健的挑战。临床验证研究表明,使用电子健康记录数据,AI模型的败血症模型混合性能20,实时糖尿病性视网膜病变筛查21和胸部X射线筛选22。即使AI模型高度准确且超过人类诊断能力,它们也不一定能够提供更好的护理23。已经提出了模型设计,安全性和效用的三个实际方面,以帮助弥合AI鸿沟24。可能导致AI鸿沟的其他问题包括开发,实施和监视AI模型和责任的大量成本。医疗保健是一个高度监管的行业,遵守法规有助于部署和临床验证AI模型的成本和挑战25。
我们的评论为推进OHN临床上有用的AI模型的发展提供了以下建议。首先,我们建议对AI研究越来越多的努力和资金来解决低风险任务,因为这些应用程序有可能更早,更明确地提供现实世界的收益,而不是更高的复杂性,更高的风险任务。这可能涉及重新关注OHN中非诊断应用程序的AI研究,例如自动化常规任务和进行分三局工作流,而不是诊断应用,例如扩大医疗保健提供者的能力以及对医疗状况的筛查,这些病情构成了OHN中86%的深度学习出版物的医疗状况(图。3b)。但是,即使是自动化的常规任务也会带来风险,因为主要的健康保险公司面临着使用AI模型来自动化保险预授权的集体诉讼。
其次,我们建议遵守报告AI预测工具的指南。这些准则的数量正在增加26并提供标准化报告和透明度的框架,以提高AI模型的公平性,有用性和可靠性7,,,,27。指南可以帮助研究人员在设计和开发之前对AI模型的临床翻译提出挑战,并提高验证方法的质量和报告,这些方法可能是不足的(缺乏固定测试集或对交叉验证的使用)(17%)(图17%)(图。4C)。只有5.4%的研究使用报告指南的事实强调了这方面的改进机会(图。4b)。在确定要使用的几项报告指南中,需要更多的工作来塑造对公认的标准报告指南的理解,这仍然存在挑战。
第三,我们建议研究人员优先考虑对AI应用的临床验证。根据我们在OHN进行概念验证AI研究的经验28,,,,29,,,,30,,,,31,,,,32,,,,33,,,,34,,,,35,我们认识到翻译AI研究的障碍。一个可感知的挑战是,假设需要(通常是多个)外部机构对测试数据集的外部验证来评估AI模型的推广性。经常出现的本地验证已被认为是外部验证的潜在有利替代方案36。采用特定地点的本地验证标准可以鼓励研究人员在其机构进行小规模的临床验证研究,作为改善临床验证并降低启动临床研究障碍的迭代过程的一部分。同时,它可以防止模型漂移36,,,,37。为了确保验证仍然包括多样化的患者人群,我们仍然鼓励使用多机构数据进行初始模型培训。大规模验证AI模型的需求将加强以前的努力,以在OHNS中建立多中心数据共享合作38。使用框架,例如联邦39和群学习40可以帮助维持患者数据的机密性,并解决构建大型,代表性数据集并加速模型开发和临床验证的数据共享障碍。
最后,我们建议仔细注意OHNS数据集中地面真实标签的准确性,以促进预测性AI模型的成功。临床诊断并不总是作为AI培训数据集的最准确或最精确的地面真实标签。例如,在与语音障碍有关的基于喉咙的AI研究中,与功能过度功能的语音疾病分类的参与者可能包括在病变形成之前发声病理生理学的早期阶段的参与者,或者是在病变形成之前(即发声折叠水肿)或已经开发出结节性结节,或接触旋转,旋转,旋转ulcers,或接触旋转的ulcers,32。在将AI模型应用于预测目标时,病理学的上级分类可能会掩盖更精致的诊断类别的独特性。
尽管可解释性可以影响信任,但我们并不建议未来的研究必须尝试解释其AI模型,这一过程仅在41项研究中完成(9.2%)。可以解释AI模型可以安全地用于医学中的要求正在争论41,,,,42,尽管缺乏解释性可能会导致对AI模型的不信任。这项研究有几个局限性。首先,搜索词最初旨在捕获专注于开发而不是评估OHN中现有深度学习应用程序的研究。
这导致省略了一些经过同行评审的研究信,以评估CHAT-GPT在OHNS上的应用43。其次,尽管我们的七个审稿人团队独立筛选并从纳入的研究中提取了数据,但我们的过程依赖于一位具有AI和临床OHN专业知识的审稿人的裁决。如将来,这一审查过程可以改善,如《公平互式协议》(73%(Cohen s kappa 0.39))的标题和摘要筛选所证明。第三,数据提取的某些部分取决于主观判断,例如评估遵守报告指南,AI模型开发的阶段和验证方法。在数据提取表格中使用更明确的说明,例如列出所有相关报告指南,可以使数据提取更加一致。第四,除出版年外,在所有年份的出版物中都集体分析了这些数据,这些数据可能无意间掩盖了不同时间段深度学习研究的趋势。第五,此评论的数据库搜索是在2023年10月进行的,此后可能会错过重要的研究。未来的研究应更新此评论,以包括新的研究并监控OHNS中AI研究的快速进步。此类更新对于OHN的大型语言模型应用中的监视趋势非常重要44,,,,45和多模式AI46它为开发整体和临床上的模型提供了尖端的方法。第六次审查对OHN中的AI应用进行了广泛的调查,但在最近对听力学的AI评论中可以找到单个应用的进一步描述47,喉科3和其他OHNS子专业。
在AI应用程序中,OHNS的转化研究框架仍在建立。这篇评论确定了OHNS中的AI文献中的明显差距用于临床验证研究。我们的建议填补这一空白的建议包括专注于低复杂性和低风险任务,遵守报告指南以及优先考虑临床翻译,同时在我们的数据集中保持严格的多样性标准。如果成功,OHNS中AI技术的临床翻译可能是跨越AI鸿沟的更广泛的医疗社区的蓝图。
方法
搜索策略和纳入标准
在Prisma扩展程序范围范围范围后,我们对OHN中深度学习应用的文献进行了范围审查48(补充表2)。我们的搜索策略是与研究图书馆员合作制定的(补充表3)。选择搜索词是为了捕获开发或评估旨在主要应用于OHN领域的深度学习模型的研究。我们从2023年10月16日至10月25日执行了查询,以搜索Medline,Embase和Web of Science数据库。
纳入标准是对主要旨在应用于OHN领域的深度学习模型的开发或评估。深度学习模型包括神经网络(例如,人工,卷积,经常性,长期记忆,生成对抗性)和大语言模型。三类研究范围不在纳入标准之外,因此被排除在外。首先,排除了主要针对另一项专业的研究(例如,放射药物治疗放射肿瘤学后的睡眠医学或鼻咽癌患者生存期的呼吸暂停指数的预测)。根据AI应用程序针对的主要专业是根据临床上旨在使用AI应用程序的医师专业的。例如,OHN的应用包括放射学图像的分析,以帮助耳鼻喉科医生(例如,预测倒立乳头状乳状乳状体恶性转化对磁共振成像扫描的预测28)。其次,排除了不涉及深度学习的机器学习方法(例如,多层感知器,逻辑回归和支持向量机器)的研究。第三,即使这些任务涉及语音数据分析(例如,通用语音对文本预测模型),即使这些任务涉及分析语音数据,也排除了与耳鼻喉科的一般语音识别任务。最后,仅考虑了用英语发表的同行评审的原始研究文章,这些文章被考虑到了可检索的全文。
筛选过程
一个由七个审稿人组成的团队(G.S.L.,S.F.,M.C.L.,S.P.,J.H.,S.K。和M.S.),使用Covidence进行了文献评论,这是一个基于合作的网络平台49。搜索策略发现的参考文献是使用包含标准删除和筛选的,首先是标题和摘要,然后是全文。全文由一位审稿人审查,并由第二位审阅者检查。审稿人之间的差异是由具有深度学习和耳鼻喉科专业知识(G.S.L.)专业知识的裁决者决定的。通过全文筛选阶段的研究包括在评论中。
数据提取和分析
我们从纳入的研究中提取了以下数据:文章信息(例如,出版年份,作者附属机构的国家),深度学习方法,应用程序(即OHN中的应用程序和目标次数的目标),输入数据,模型验证的方法,模型开发阶段,模型开发阶段,使用报告指南和尝试解释模型。我们的数据提取表格可在补充表中获得4。如果一项研究研究了多种深度学习方法和数据类型,则选择研究中的主要模型和数据类型。我们根据是否从单个机构和多个机构收集数据对模型验证方法进行了分类,该方法是在回顾性的,和/或分区中获得的。省略使用独立的测试数据集或交叉验证限制限制模型的概括性能,未来,看不见的数据17。在不确定性的情况下,对验证质量提供上限的情况,对更强大的方法的验证方法的评估误解。例如,一项报告了测试结果但没有明确描述使用固定测试数据集的研究。
我们根据AI的医疗保健阶段对AI模型开发的阶段进行了分类8:在计算机评估(即概念证明)中,离线验证(即无声/阴影评估),小规模的临床验证,大规模的临床验证和市场后监视。为了保持一致性,我们在计算机评估中将AI模型的应用视为在从预期用途的上下文中删除的上下文中准备的数据(例如,评估在计算机上保存的音频记录上的语音denoising算法的评估);离线验证是在类似于预期用途的环境中应用于潜在数据的应用(例如,评估实验室的人工耳蜗植入受试者中的语音deno算法的评估);和临床验证作为预期用途的应用(例如,在实验室外的人工耳蜗植入受试者中评估语音授权算法的评估)。数据提取过程中的分歧是由裁决者(G.S.L.)决定的。
数据可用性
补充数据中提供了范围审查中包含的研究的完整数据集。
参考
Crowson,M。G.等。耳鼻喉科手术中的机器学习的当代综述。喉镜 130,45 -51(2020)。
文章一个 PubMed一个 Google Scholar一个
Bur,A。M.,Shew,M。&New,J。耳鼻喉科医生的人工智能:最先进的评论。耳鼻喉科。颈外科手术。 160,603 - 611(2019)。
文章一个 Google Scholar一个
刘G.耳鼻喉科。颈外科手术。 171,658â666(2024)。
文章一个 Google Scholar一个
人工智能和机器学习(AI/ML)支持的医疗设备。FDA https://www.fda.gov/medical-devices/software-medical-device-samd/arterch--intercer-intelligence-and-machine-learning-aiml-aiml-- andabled-medical-devices(2024)。
带有Brainlab的EM的ENT导航应用程序。Brainlabhttps://www.brainlab.com/surgery-products/overview-ent-products/ent-navigation-application/ 。重新构想医疗设备的设计方式。
PacificMD生物技术https://www.pmdbiotech.com/ 。Lu,J。H.等。
通过单个供应商的常用临床预测模型评估对报告指南的依从性:系统评价。JAMA NetW。打开 5,E2227779(2022)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Vasey,B。等。关于人工智能驱动的决策支持系统早期临床评估的报告指南:决定。纳特。医学 28,924 - 933(2022)。
文章一个 PubMed一个 CAS一个 Google Scholar一个
Gajecki,T.,Zhang,Y。&Nogueira,W。人工耳蜗的深层降级声音编码策略。IEEE Trans。生物。工程。 70,2700 2709(2023)。
文章一个 PubMed一个 Google Scholar一个
拉格万(A. M.耳鼻喉科。-头。颈外科手术。J. Am。学院。耳鼻喉科。-头。颈外科手术。 163,771 - 777(2020)。
文章一个 Google Scholar一个
Healy,E。W.,Taherian,H.,Johnson,E。M.&Wang,D。因果关系和与说话者无关的说话者分离/消除深度学习算法:与转换为实时操作相关的成本。J. Acoust。Soc。是。 150,3976(2021)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Cohen,J。F.等。Stard 2015报告诊断准确性研究指南:解释和阐述。BMJ开放 6,E012799(2016)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
柯林斯(G.BMC Med。 13,1(2015)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Des Jarlais,D.C.,Lyles,C。和Crepaz,N。提高行为和公共卫生干预措施的非随机评估的报告质量:趋势陈述。是。J.公共卫生 94,361 366(2004)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
冯·埃尔姆(E.等)。加强流行病学观察性研究的报告(Strobe)陈述:报告观察性研究指南。BMJ 335,806 - 808(2007)。
文章一个 Google Scholar一个
Liu,X.,Cruz Rivera,S.,Moher,D.,Calvert,M。J.&Denniston,A。K.临床试验报告指南涉及人工智能的干预措施:Collesort-AI扩展。纳特。医学 26,1364年1374(2020)。
文章一个 PubMed一个 PubMed Central一个 CAS一个 Google Scholar一个
Liu,Y.,Chen,P.-H。C.,Krause,J。&Peng,L。如何阅读使用机器学习的文章:用户指导医学文献。贾马 322,1806年1816年(2019年)。
文章一个 PubMed一个 Google Scholar一个
Selvaraju,R。R.等。Grad-CAM:通过基于梯度的本地化,深网的视觉解释。int。J. Comput。VIS。 128,336 359(2020)。
文章一个 Google Scholar一个
Zhou,B.,Khosla,A.,Lapedriza,A.,Oliva,A。&Torralba,A。学习歧视性定位的深度特征。在2016 IEEE计算机视觉和模式识别会议(CVPR)2921 2929(IEEE,2016年)。https://doi.org/10.1109/cvpr.2016.319。Kamran,F。等。
败血症预测模型的评估。nejm ai 1,AIOA2300032(2024)。
文章一个 Google Scholar一个
Ruamviboonsuk,P。等。通过深度学习在多站点国家筛查计划中进行实时糖尿病性视网膜病变筛查:一项前瞻性介入队列研究。柳叶刀数字。健康 4,E235 e244(2022)。
文章一个 PubMed一个 CAS一个 Google Scholar一个
Lind Plesner,L。等。可商购的胸部X光片AI工具,用于检测空域疾病,气胸和胸腔积液。放射学 308,E231236(2023)。
文章一个 PubMed一个 Google Scholar一个
戈麦斯·罗西(J.JAMA NetW。打开 5,E220269(2022)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
塞内维拉特(M. G.BMJ Innov。 6,45 -47(2020)。
文章一个 Google Scholar一个
Mennella,C.,Maniscalco,U.Heliyon 10,E26297(2024)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Crowson,M。G.&Rameau,A。耳鼻喉科和颈部手术中标准化机器学习手稿报告。喉镜 132,1698年1700(2022)。
文章一个 PubMed一个 Google Scholar一个
Callahan,A。等。站在Furm地面上:评估医疗保健系统中公平,有用且可靠的AI模型的框架。NEJM CATAL。创新。护理Deliv。5,,,,https://doi.org/10.1056/cat.24.013(2024)。Liu,G。S.等。
使用3D卷积神经网络和磁共振成像对反向乳头状瘤恶性转化的深度学习分类。int。论坛过敏性鼻。 12,1025 - 1033(2022)。
文章一个 PubMed一个 CAS一个 Google Scholar一个
Liu,G。S.等。Elhnet:用于用光学相干断层扫描成像的耳蜗内聚型水力水果进行分类的卷积神经网络。生物。选择。表达 8,4579年4594(2017)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Liu,G。S.,Shenson,J。A.,Farrell,J。E.&Blevins,N。H.信号与噪声比量化了使用深度学习和多光谱成像的光谱通道对人头和颈部组织分类的贡献。J. Biomed。选择。 28,016004(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Shenson,J。A.,Liu,G。S.,Farrell,J。&Blevins,N。H.自动化组织鉴定正常人类手术标本的多光谱成像。耳鼻喉科。头。颈外科手术。J. Am。学院。耳鼻喉科。头。颈外科手术。 164,328 335(2021)。
文章一个 Google Scholar一个
Liu,G。S.等。使用堆叠元音对人声病理学的端到端深度学习分类。喉镜研究。耳鼻喉科。 8,1312 - 1318(2023)。
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Liu,G。S.,Cooperman,S。P.,Neves,C。A.&Blevins,N。H.使用术后X射线和术前CT图像的2D-3D编码对耳蜗植入物插入深度的估计。耳醇。神经醇。 45,E156(2024)。
文章一个 PubMed一个 Google Scholar一个
Neves,C。A。等。使用对比度增强的T1加权和T2加权磁共振成像序列和人工智能对前庭造型和内耳的自动分析。耳醇。神经醇。 44,E602(2023)。
PubMed一个 Google Scholar一个
Liu,G。S.等。Artificial intelligence tracking of otologic instruments in mastoidectomy videos.Otol.Neurotol. 45, 1192 (2024).
文章一个 PubMed一个 Google Scholar一个
Youssef, A. et al.External validation of AI models in health should be replaced with recurring local validation.纳特。医学 29, 2686–2687 (2023).
文章一个 PubMed一个 CAS一个 Google Scholar一个
Granlund, T., Stirbu, V. & Mikkonen, T. Towards regulatory-compliant MLOps: Oravizio’s journey from a machine learning experiment to a deployed certified medical product.SN Comput.科学。 2, 342 (2021).
文章一个 Google Scholar一个
Beswick, D. M. et al.Design and rationale of a prospective, multi-institutional registry for patients with sinonasal malignancy.喉镜 126, 1977–1980 (2016).
文章一个 PubMed一个 Google Scholar一个
Crowson, M. G. et al.A systematic review of federated learning applications for biomedical data.PLOS Digit.健康 1, e0000033 (2022).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Warnat-Herresthal, S. et al.Swarm Learning for decentralized and confidential clinical machine learning.自然 594, 265–270 (2021).
文章一个 PubMed一个 PubMed Central一个 CAS一个 Google Scholar一个
Holm, E. A. In defense of the black box.科学 364, 26–27 (2019).
文章一个 PubMed一个 CAS一个 Google Scholar一个
Ghassemi, M., Oakden-Rayner, L. & Beam, A. L. The false hope of current approaches to explainable artificial intelligence in health care.Lancet Digit.健康 3, e745–e750 (2021).
文章一个 PubMed一个 CAS一个 Google Scholar一个
Ayoub, N. F., Lee, Y.-J., Grimm, D. & Balakrishnan, K. Comparison between ChatGPT and Google search as sources of postoperative patient instructions.JAMA Otolaryngol.Neck Surg. 149, 556–558 (2023).
文章一个 Google Scholar一个
Vaira, L. A. et al.Validation of the quality analysis of medical artificial intelligence (QAMAI) tool: a new tool to assess the quality of health information provided by AI platforms.欧元。拱。otorhinolaryngol。 281, 6123–6131 (2024).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Vaira, L. A. et al.Enhancing AI Chatbot responses in health care: the SMART prompt structure in head and neck surgery.OTO Open 9, e70075 (2025).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Judge, C. S. et al.Multimodal artificial intelligence in medicine.Kidney360 5, 1771 (2024).
文章一个 PubMed一个 Google Scholar一个
Frosolini, A. et al.Artificial intelligence in audiology: a scoping review of current applications and future directions.传感器 24, 7126 (2024).
文章一个 PubMed一个 PubMed Central一个 Google Scholar一个
Tricco, A. C. et al.PRISMA extension for scoping reviews (PRISMA-ScR): checklist and explanation.安。实习生。医学 169, 467–473 (2018).
文章一个 PubMed一个 Google Scholar一个
Covidence systematic review software.Veritas Health Innovation.
致谢
We thank Christopher Stave, M.L.S.for assistance with developing search strategies and extracting references, and Nigam Shah for helpful discussion.K.M.S.gratefully acknowledges funding support from the Bertarelli Foundation Endowed Professorship and the Remondi Foundation.
竞争利益
作者没有宣称没有竞争利益。
附加信息
Publisher’s note
关于已发表的地图和机构隶属关系中的管辖权主张,Springer自然仍然是中立的。补充信息
权利和权限
开放访问
本文允许以任何媒介或格式的使用,共享,适应,分发和复制允许使用,分享,适应,分发和复制的国际许可,只要您适当地归功于原始作者和来源,就可以提供与创意共享许可证的链接,并指出是否进行了更改。The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visithttp://creativecommons.org/licenses/4.0/。重印和权限
Cite this article

Liu, G.S., Fereydooni, S., Lee, M.C.
等。Scoping review of deep learning research illuminates artificial intelligence chasm in otolaryngology-head and neck surgery.NPJ数字。医学 8, 265 (2025).https://doi.org/10.1038/s41746-025-01693-0
已收到:
公认:
出版:
doi:https://doi.org/10.1038/s41746-025-01693-0