
The analysis of artificial intelligence knowledge graphs for online music learning platform under deep learning
作者:Liu, Chang
Introduction
Research background and motivations
As an emerging learning method, online music learning platforms have gained widespread popularity due to their convenience and accessibility1. Whether beginners or more advanced students, learners can access high-quality educational resources anytime and anywhere via the internet, greatly promoting personal interest and development in learning through this flexibility2,3. However, despite the success of online music learning platforms, traditional online platforms still have several significant limitations that hinder learners’ growth and progress4,5.
First, traditional online music learning platforms often lack personalized learning path recommendation features6. Since learners vary in background, skill level, and interests, a one-size-fits-all approach to teaching fails to meet individual learning needs. The absence of personalized learning paths may cause some students to find the courses either too simple or too difficult, which negatively impacts their motivation and learning efficiency7. Besides, many existing online music learning platforms fall short in offering interactive and adaptive learning experiences. Most platforms rely primarily on video tutorials and static text materials, with limited opportunities for real-time feedback and interaction8. This one-way information delivery makes it difficult for students to receive timely guidance or encouragement, which can adversely affect learning outcomes.
Moreover, with the advent of the big data era, an increasing amount of user behavior data is being collected and stored. However, these data have not been fully utilized to improve the learning experience9. By employing deep learning techniques, valuable insights can be extracted from vast amounts of user data to provide more personalized learning suggestions and services10. Meanwhile, knowledge graphs, an advanced knowledge management tool, have been increasingly applied across various fields in recent years. Knowledge graphs can visually represent complex concepts and the relationships between them, helping users build a more comprehensive knowledge system11,12,13. In the field of music education, knowledge graphs can be used to organize content related to music theory and instrumental performance techniques, making it easier for learners to understand andmaster complex concepts14,15,16.
In addition, combining deep learning with knowledge graph technology provides users with a more intelligent, personalized, and interactive learning experience. By analyzing a large amount of user behavior data through deep learning algorithms, the platform can automatically identify each learner’s habits, preferences, and skill levels. This allows for the creation of customized learning plans that spark interest and improve learning efficiency. Meanwhile, leveraging knowledge graph technology, the platform can build a structured and systematic network of music knowledge. This not only helps learners intuitively understand the connections between music theory and practical skills but also promotes the integration and application of interdisciplinary knowledge, further enriching the learning content. Therefore, incorporating deep learning and knowledge graph technology into the design of online music learning platforms is of great significance for enhancing the quality of music education and fostering educational innovation in the field.
Research objectives and innovations
The goal of this work is to design and implement an online music learning platform based on artificial intelligence knowledge graphs. The platform is expected to have the following key features: (1) Personalized Recommendations: By analyzing users’ interests and learning history, the platform provides customized course recommendations for each user. (2) Interactive Learning Experience: Leveraging natural language processing technology, the platform better understands and responds to users’ needs, enhancing the user experience. (3) Dynamic Adaptability: The platform dynamically adjusts course content according to users’ learning progress, ensuring content suitability. (4) Knowledge Graph-Assisted Learning: By constructing a music knowledge graph, the platform helps users more intuitively understand music theory and promotes deeper knowledge acquisition. By achieving these objectives, this work aims to improve the effectiveness of online music learning and provide valuable reference examples for future innovations in educational technology.
The innovation of this work is mainly reflected in the following aspects:
-
(1)
The combination of knowledge graph and deep learning: knowledge graph is combined with deep learning technology to construct a recommendation system that integrates audio, video features, and user behavior characteristics. The introduction of knowledge graphs enables the system to utilize rich semantic information in the music field, such as music works, artists, and their relationships, to enhance the accuracy and personalization of recommendations.
-
(2)
Multimodal feature fusion: By fusing the features of audio, video, and user behavior data, a comprehensive feature representation is constructed. Compared to traditional recommendation methods, it can better utilize multimodal data and enhance the performance and accuracy of recommendation systems.
-
(3)
Application of self-attention mechanism: self-attention mechanism is introduced in the model training process to help the model focus on the content most relevant to user needs. This mechanism improves the accuracy and relevance of recommendation results, especially when user interests change, and can dynamically adjust recommendation strategies. These innovations enable the propsoed method to outperform existing recommendation methods in multiple key performance metrics, especially when dealing with sparse data, demonstrating higher robustness and adaptability.
Literature review
In recent years, with the progress of deep learning and artificial intelligence technologies, these advanced techniques have begun to be introduced into the field of music education to enhance teaching quality and efficiency17. Especially in the research of music recommendation systems, significant achievements have been made. Firstly, music recommendation systems based on deep learning have been widely applied in music information retrieval, automatic composition, and style transfer. For instance, Liu18 demonstrated that deep learning technologies had significant advantages in music information retrieval, automatic composition, and music style transfer. Zhu et al.19 combined deep learning with music to construct a flipped classroom model applied in physical education, supported by the integration of music and deep learning. Wang et al.20 analyzed the necessity and contribution of university music teaching to ideological and political work. They proposed a fusion model that integrated music teaching and political education, where deep learning methods were introduced to minimize the impact of errors on the data related to university music teaching and ideological and political work. Deldjoo et al.21 proposed an onion model consisting of five layers, each layer corresponding to a specific type of music content: signals, embedded metadata, expert generated content, user generated content, and derived content. Bhaskaran and Marappan22 developed an enhanced vector space recommender that could automatically track users’ interests, requirements, and knowledge levels.
Additionally, knowledge graphs, as an effective means of organizing and representing knowledge, have also been widely applied in the education field. Sakurai et al.23 proposed a new music recommendation method based on deep reinforcement learning, utilizing a deep reinforcement learning algorithm on a dense knowledge graph to achieve efficient search. Gao et al.24 proposed a modeling strategy consisting of two parts to expand the expressive power of music recommendation models to adapt to datasets with different sparsity levels. Bertram et al.25 studied how knowledge graph embedding improved music recommendation. Firstly, they demonstrated how to derive collaborative knowledge graphs from open music data sources. Based on this knowledge graph, the music recommendation system placed special emphasis on recommendation diversity and interpretability. Finally, they conducted a comprehensive evaluation using real-world data, compared different embeddings, and investigated the impact of different types of knowledge.
In addition, research on music recommendation systems that combine deep learning and knowledge graphs has also achieved phased results. For example, Razgallah et al.26 introduced a music recommendation model based on neural networks. Bin and Sun27 examined how users of music recommendation platforms form complex networks through shared interests and interactions, collectively influencing the dissemination of information and its ultimate reach. Ma et al.28 further explored users’ potential interests by considering users (or projects) as semantic neighbors with other similar users (or projects) and incorporating them as positive pairings into contrastive learning.
In addition, the application of knowledge graphs in recommendation systems has become more extensive, especially in user interest modeling and recommendation interpretability. Guo et al.29 developed a tool that generated test sequences by analyzing the results of automated tests on Android applications and constructed a knowledge graph of the target application based on this. The research results show that this method can improve the comprehensibility of test requirements and enhance the quality of crowdsourced testing. This indicates that knowledge graphs can not only be applied to recommendation systems but also improve data organization and analysis capabilities in other tasks. In recommendation systems, the role of knowledge graphs is mainly reflected in enhancing the interpretability of recommendations and improving the cold start problem. The development of recommendation systems is accompanied by the challenge of protecting user data privacy. Yuan et al.30 studied interactive-level membership inference attacks, in which attackers could infer whether a user belongs to the training dataset through the user’s interaction information with the recommendation system. They adopted the Local Differential Privacy technology for defense and verified its effectiveness in defending against inference attacks.
Furthermore, Chen et al.31 proposed a method of generating adversarial examples using a Guided Diffusion Model, aiming to increase the exposure rate of long-tail items (less popular items). Thismethod models the normal image distribution through the diffusion model, and the generated adversarial examples are highly visually similar to the original images, thus affecting the output of the recommendation system. This research demonstrates the potential of adversarial examples in the optimization of recommendation systems. Zhang et al.32 proposed a new adaptive privacy protection method for Attribute Inference Attacks. This method minimizes the impact on the accuracy of the recommendation system while protecting users’ sensitive data. Experiments on real datasets show that this method can effectively defend against inference attacks while improving the recommendation performance. This research further indicates that in recommendation systems, balancing privacy protection and recommendation quality is a key issue that requires trade-offs through optimized algorithms and privacy protection mechanisms.
Despite progress in certain areas, several clear limitations remain. First, most existing online music learning platforms have not fully leveraged personalized recommendation technology to meet the diverse needs of learners. Many platforms still rely on traditional teaching syllabi and fail to dynamically adjust based on users’ learning history and preferences. This results in many learners not receiving the most suitable learning resources, which ultimately affects their learning outcomes. Given this situation, this work aims to address the following gaps. It explores how deep learning technology can be utilized to achieve more accurate personalized recommendations and to improve user experience on online music learning platforms. By incorporating natural language processing technology, this work plans to develop a more intelligent interactive interface that allows learners to interact more naturally with the platform. Additionally, this work further explores how to construct and maintain a comprehensive and dynamically updated music knowledge graph to provide learners with richer resources and support. Through these efforts, it aims to advance the development of online music education technologies and offer valuable insights for future research.
Research methodology
Overall framework
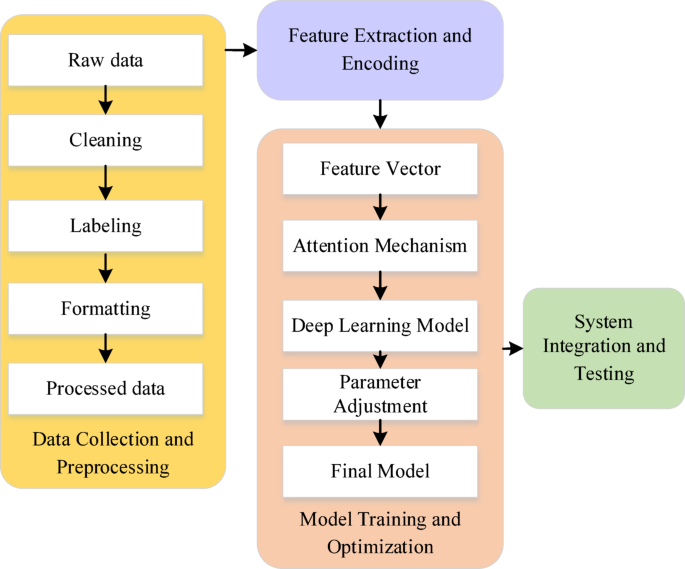
This work aims to design an online music learning platform based on deep learning and knowledge graph technologies to overcome the limitations of existing platforms in terms of personalized recommendations, interactivity, and adaptability. To achieve this goal, a comprehensive methodological framework from data collection to system integration has been proposed, as illustrated in Fig. 1:

Overall research framework.
The overall framework depicted in Fig. 1 consists of four main stages: data collection and preprocessing, feature extraction and encoding, model training and optimization, and system integration and testing. In the data collection and preprocessing stage, relevant music education data are gathered from various sources, including audio files, video tutorials, and user behavior records. These data are sourced from publicly available online music education repositories, user-shared content on social media, and more. Once the data are collected, the next step is preprocessing, which involves data cleaning, labeling, and formatting. For instance, audio data will be converted into spectrograms, video data will be segmented into frames, and user behavior data will be annotated and categorized. The purpose of this step is to remove irrelevant or erroneous data, ensuring the accuracy of subsequent processing.
During the feature extraction and encoding phase, deep learning techniques are employed to extract features from audio and video data, and a Multilayer Perceptron (MLP) is used to encode user behavior data. Specifically, a Convolutional Neural Network (CNN) is utilized to extract local features from the audio spectrograms, while a Long Short-Term Memory Network (LSTM) captures the temporal features of audio segments. CNN processes audio data through multi-layer convolutional kernel operations, which can effectively identify low-level features (such as pitch, frequency, etc.) in the audio and extract valuable local information for recommendation. LSTM processes the time series characteristics of audio segments and preserves long-term dependency information related to user interests through gating mechanisms. This combination enables the system to simultaneously consider local features in the audio and temporal dependencies in user behavior, thereby enhancing a deep understanding of audio content and accurate prediction of user preferences. To further enhance the semantic information of feature extraction, the knowledge graph is also integrated into this stage. By extracting entities (such as artists, instruments, music terminology, etc.) and their relationships (such as “composer creation work”) from resources in the music field to form a knowledge graph, the system can embed these entities and relationships into feature vectors, providing rich contextual information for subsequent recommendations. These knowledge graph embedding vectors are fused with audio and user behavior features to form a comprehensive feature vector, further enhancing the semantic understanding ability and recommendation accuracy of the recommendation system.
Model training and optimization is a crucial stage here. Based on the extracted feature vectors, a deep learning model incorporating attention mechanisms is trained. The attention mechanism helps the model focus on the most relevant parts, enhancing the accuracy of recommendations and user satisfaction. To achieve this goal, the embedding vectors of the knowledge graph will be input into the model along with the audio, video, and user behavior feature vectors. During the training process, the model can more accurately capture users’ interests and needs by focusing on important entities and relationships in the knowledge graph. For example, when a user shows interest in a composer, the model infers relevant works, styles, periods, and other content based on the knowledge graph, and optimizes the recommendation results accordingly. Moreover, different optimization algorithms and loss functions are used during the training process, and the model performance is continuously improved through hyperparameter adjustment and multiple rounds of iterative optimization. At this stage, knowledge graph not only enhances the semantic reasoning ability of the model, but also improves the effectiveness of cold start problem and long tail recommendation through path reasoning and relationship deduction. The ultimate goal of gradual learning and optimization is to develop a high-performance recommendation model that can accurately identify user needs and provide personalized, high-quality recommendation services.
Finally, in the system integration and testing phase, the trained model is integrated into the online music learning platform to enable personalized recommendations, interactive learning experiences, and other functionalities. System integration must consider how to seamlessly incorporate the model into the existing platform architecture while ensuring all features function properly. After integration, comprehensive functional and performance testing is conducted, including but not limited to evaluating recommendation accuracy, system response time, and user interface friendliness. Through the orderly connection of these four stages, a complete process from data collection to system integration is established, ensuring the effectiveness and coherence of each component.
Selection and integration of deep learning models
To achieve efficient data processing and provide a personalized learning experience, this section elaborates on the model selection and integration process based on the aforementioned framework. This work employs various machine learning models and techniques, including CNN, RNN, and MLP. Additionally, attention mechanisms are introduced to enhance the model’s performance.
In the feature extraction stage, CNN is utilized to process audio and video data. CNN can effectively extract local features from spectrograms of images and audio. The processing of audio data includes the following steps:
-
(1)
Audio to spectrogram: Firstly, the audio signal is converted into a spectrogram. A spectrogram is a time-frequency representation of an audio signal, generated using the short-time Fourier transform method. The spectrogram visualizes the time and frequency information of the audio signal as a two-dimensional image, providing CNN with the opportunity to extract local features.
-
(2)
CNN extracting local features: The generated spectrogram is used as input for CNN and processed through multiple convolutional layers. Convolutional layers can identify local patterns in spectrograms, such as pitch, rhythm, and timbre, and extract meaningful local features from audio signals through convolutional kernels. The convolution kernels of eachlayer will learn based on the frequency and time characteristics of the audio signal, extracting increasingly complex audio features.
-
(3)
Pooling layer dimensionality reduction: After being processed by convolutional layers, pooling layers are used to reduce the spatial dimension of features, thereby reducing computational complexity and avoiding overfitting. Pooling operations select the maximum or average value within a local area, preserving important information of the audio signal and reducing the dimensionality of feature vectors.
-
(4)
Fixed-length feature vector: After convolution and pooling, CNN finally outputs a fixed-length feature vector that contains key information from the audio signal, which is used for subsequent recommendation systems.
The processing procedure for video data is slightly different. Video data consists of a series of consecutive video frames, and CNN inputs one by one to extract the visual features of each frame.
-
(1)
Video frame feature extraction: Each frame of video is input into a CNN, and CNN extracts visual features (such as color, texture, and shape in the image) from that frame through convolutional layers. These frame level features are extracted frame by frame and provide rich information about the video content.
-
(2)
LSTM integrating temporal features: Due to the time-series nature of video data, LSTM is used to handle the temporal dependencies between video frames. LSTM can capture long-term dependencies and temporal information between frames through its internal gating mechanism, thereby combining the extracted features of each frame into a video level feature vector.
-
(3)
Generating video feature vectors: LSTM processes the features of all frames in chronological order, and finally outputs a fixed length feature vector containing the overall information of the video. This feature vector can effectively represent the content of the entire video and provide semantic information for subsequent recommendation systems. Figure 2 illustrates this process.

Audio/video feature extraction process.
As shown in Fig. 2, the audio signal first extracts local features through CNN, while the video signal extracts local features for each frame through CNN and forms a video level feature vector by combining LSTM with time information. The feature vectors of audio and video are fused with other user behavior features (such as user preferences and historical behavior) to ultimately form multimodal feature vectors, providing rich semantic information for recommendation systems. This feature fusion approach not only enhances the system’s understanding of audio and video content, but also improves the accuracy and personalization of recommendations.
For processing user behavior data, an MLP is employed for encoding. An MLP is a type of feedforward neural network that can handle data with nonlinear relationships. It consists of an input layer, an output layer, and one or more hidden layers, with a fully connected structure among the neurons. The goal of the MLP is to obtain a fitting function. Figure 3 illustrates the simplest structure of an MLP:

Diagram of a single hidden layer perceptron.
In this context, user behavior data, including click streams and search records, is represented as a vector U and encoded using the MLP.
$$\:{f}_{behavior}=\text{M}\text{L}\text{P}\left(U\right)$$
(1)
Here, fbehavior represents the user behavior feature vector. Specifically, this process begins by encoding user behavior data, such as click streams and search records, into a high-dimensional vector. For instance, each click or search record can be represented as a feature vector, and multiple behaviors can be concatenated to form a long vector. Subsequently, an MLP is employed to reduce the dimensionality and extract features from the user behavior vector, resulting in a lower-dimensional feature vector. This can be expressed by the following equation:
$$\:{f}_{behavior}={W}_{2}\cdot\:\sigma\:({W}_{1}\cdot\:U+{b}_{1})+{b}_{2}$$
(2)
In this context, W1 and W2 are the weight matrices for the first and second layers, respectively, while b1 and b2 are the corresponding bias terms. The symbol σ represents the activation function (ReLU). The MLP extracts high-level abstract features by applying multiple nonlinear transformations to the input data. The equation for the activation function is given by:
$$\:\text{R}\text{e}\text{L}\text{U}\left(x\right)=max(0,x)$$
(3)
To enhance the model’s performance in processing sequential data, an attention mechanism is introduced. The attention mechanism allows the model to focus on the important parts of the sequence data during processing. Given a sequence of data represented as X=[x1,x2,…,xn], the attention mechanism can be expressed as:
$$A\left( X \right) = \sum\limits_{{i = 1}}^{n} {\alpha _{i} x_{i} }$$
(4)
In this context, αi represents the weight assigned to the i-th element, and xi is the element in the sequence. By utilizing this approach, the model can focus more on the important information, thereby enhancing the accuracy of the recommendations. For each input sequence X, the corresponding attention weights αi are calculated using the equation:
$$\:{\alpha\:}_{i}=\frac{\text{e}\text{x}\text{p}\left({e}_{i}\right)}{\sum\:_{j=1}^{n}\:\text{e}\text{x}\text{p}\left({e}_{j}\right)}$$
(5)
In this context, ei is the score computed through a feedforward network. The calculated weights are then used to perform a weighted sum of the input sequence, generating a feature representation enhanced by the attention mechanism. Integrating the various extracted feature vectors can form a comprehensive feature vector F:
$$\:F=[{f}_{audio};{f}_{video};{f}_{behavior}]$$
(6)
In this context, \(\:{f}_{behavior}\) represents the user behavior feature vector, \(\:{f}_{audio}\) denotes the audio feature vector, and \(\:{f}_{video}\) refers to the video feature vector. Subsequently, a deep learning model incorporating the attention mechanism is employed to train the comprehensive feature vector F. The objective of the model training is to minimize the loss function L:
Knowledge graph construction and data integration
To enhance the intelligence level of the online music learning platform, this work introduces knowledge graph technology. Knowledge graphs effectively organize and represent complex domain knowledge, providing users with a more intuitive learning path. The construction of a knowledge graph involves several steps, including entity recognition, relationship extraction, graph construction, and graph maintenance. Figure 4 illustrates this specific process.

Knowledgegraph construction process.
The construction of the knowledge graph begins with entity recognition. Key entities such as instrument names, musical terms, and artists are identified from resources like music textbooks, tutorial videos, and articles. Entity recognition can be facilitated using NLP techniques, employing methods like word embeddings (Word2Vec) and Named Entity Recognition algorithms to label the entities in the text. This process enables the extraction of meaningful information from large amounts of textual data and converts it into a structured format.
The next step is relationship extraction. Using NLP techniques, relationships between entities are extracted from text and audio, such as “Beethoven composed Symphony No. 5.” This relationship extraction is achieved using an LSTM-based classifier. The goal of this step is to extract the relationships between entities from unstructured data, facilitating a better understanding of the intrinsic connections within the music domain.
The application process of LSTM in relation extraction is as follows:
-
(1)
Text and audio data preprocessing: Firstly, preprocess the input text data, including word segmentation, part of speech tagging, and named entity recognition. For audio data, the feature vectors obtained through the previous audio feature extraction process (such as converting the audio signal into a spectrogram) will be used for subsequent text parsing. In this way, the features of audio and text data can provide multimodal information for relationship extraction.
-
(2)
LSTM model training: A relationship extraction model based on LSTM requires training a network with sufficient levels and memory capabilities. The model learns how to recognize entities and their relationships in text by training on a large amount of labeled relational data. In this process, the LSTM network learns to extract useful information from long sequences through its gating mechanism and generates relationships between each pair of entities.
-
(3)
Relationship extraction: A trained LSTM model takes text data as input, identifies entity pairs in the text, and determines whether there is any relationship between them (such as “creation” and “performance”). The characteristics of LSTM enable it to capture potential relationships between entities in complex syntactic structures, especially when dealing with sentences containing long-range dependencies, effectively identifying connections in context.
-
(4)
Output relationship: After processing the input text data, the LSTM model outputs a structured information containing entity pairs and their relationships. For example, from the sentence ‘Beethoven composed the Fifth Symphony’, the LSTM model can recognize ‘Beethoven’ and ‘the Fifth Symphony’ as entities and extract ‘composed’ as the relationship between them. This relationship structure serves as the foundation for subsequent knowledge graph construction and recommendation systems.
Following this, the graph construction phase occurs. The results of entity recognition and relationship extraction are integrated into the graph, forming nodes (entities) and edges (relationships). Graph construction is implemented using a graph database (Neo4j), which supports the storage and querying of large-scale graph data. By building the graph, complex relationships are visualized, allowing for convenient queries and analysis. Finally, graph maintenance is essential. The graph needs to be regularly updated by adding new entities and relationships and removing outdated information. Graph maintenance is achieved through incremental learning techniques, gradually refining the graph by continuously incorporating new data. This process ensures that the knowledge graph remains current and accurately reflects the latest research findings and user needs.
Once the knowledge graph is constructed, it must be integrated with the previously extracted feature vectors to enable more efficient personalized recommendations and enhanced learning experiences. Feature fusion refers to the integration of audio feature vectors, video feature vectors, and user behavior feature vectors into a comprehensive feature vector, F. This approach combines different types of feature information to create a more holistic feature representation. Next is knowledge graph embedding, which converts the nodes and relationships in the knowledge graph into low-dimensional vector representations, known as graph embeddings. Finally, the comprehensive feature vector F is fused with the graph embedding vectors to produce the final feature vector F′. This fusion effectively leverages the semantic information provided by the knowledge graph, improving the accuracy of personalized music recommendations and increasing user satisfaction.
Deep integration of knowledge graph and recommendation system
In the feature extraction and encoding stages, the knowledge graph serves as an important external knowledge source, providing more dimensional semantic information for the recommendation system, thereby enhancing the system’s intelligence. By integrating entities and relationships in the music field into the feature space of recommendation systems, knowledge graphs not only improve the accuracy of recommendations, but also enhance the effectiveness of cold start problems and long tail recommendations. In the optimization stage of model training, the combination of knowledge graph and recommendation model is achieved through knowledge graph embedding and feature fusion. The integration method in this stage mainly includes the following key steps:
Knowledge graph construction and recommendation system data fusion
Firstly, in the feature extraction and encoding stage, the system extracts key entities (such as musicians, instruments, and music terminology) from various resources (such as music textbooks, video tutorials, and articles). These entities and their interrelationships (such as “Beethoven-composed- the Fifth Symphony”) form the foundation of the knowledge graph. At this stage, entities and relationships are extracted from unstructured text through natural language processing techniques. Next, entities and relationships are transformed into low dimensional vector representations, which are accomplished through knowledge graph embedding methods such as TransE, ComplEx, etc. The generated embedding vector is fused with other features (such as user behavior data and audio features) to form a comprehensive feature vector for recommendation models to use.
Feature fusion and recommendation model optimization
During the model training optimization phase, the knowledge graph embedding vector is fused with the embedding vectors of users and projects (music works, artists, etc.). Specifically, the recommendation model generates vector representations of users and items based on users’ preferences for music content, historical interaction records, and semantic relationships in the knowledge graph. The effectiveness of the recommendation model can be enhanced through the following feature fusion methods:
Merge the user embedding vector \(\:{f}_{user}\), item embedding vector \(\:{f}_{item}\), and knowledge graph embedding vector \(\:{f}_{graph}\) to obtain a unified comprehensive feature representation \(\:{F}_{combined}\).
$$\:{F}_{combined}=MLP\left(\left[{f}_{user},{f}_{item},{f}_{graph}\right]\right)$$
(7)
MLP is used to combine features through nonlinear transformation, ultimately generating a feature vector for recommendation decision-making. During the training process, knowledge graph embedding is jointly optimized with traditional recommendation algorithms such as matrix factorization, collaborative filtering (CF), and deep learning. For example, the structural information of knowledge graphs is used to guide the training of deep learning recommendation models and optimize the performance of recommendation systems. The objective function is expressed as:
$$\:L={L}_{rec}+\lambda\:{L}_{kg}$$
(8)
\(\:{L}_{rec}\) is the loss function of the recommendation model, \(\:{L}_{kg}\) is the optimization loss of knowledge graph embedding,and λ is a hyperparameter used to balance the contribution between the recommendation model and the knowledge graph.
Path reasoning and solving cold start problems
The recommendation system can achieve path inference through entity relationship paths in the knowledge graph. For example, if a user shows interest in a certain music genre, the knowledge graph can use path inference algorithms to find relevant artists, works, or genres, thereby improving the accuracy and diversity of recommendations. This path inference method can effectively solve the cold start problem. Especially when facing new users or projects, the system can recommend content related to user interests through inference without relying on a large amount of historical interaction data.
Long tail recommendation and diversity enhancement
Through knowledge graphs, the system can uncover long tail projects that users may not have encountered but may be interested in. The long tail recommendation extends through the rich relationship information in the graph, for example, through relationships such as “classical music-association-Chopin” or “Bach-composed-orchestration”, the knowledge graph can help the system find more works that are not often directly touched by users. In addition, knowledge graphs can guide recommendation systems to not only focus on popular items, but also enhance the diversity and personalization of recommendation results.
Dynamic updates of recommendation systems
The integration of knowledge graphs and recommendation systems requires dynamic updates to adapt to constantly changing data and user behavior. After each user interaction, new entities or relationships are extracted and integrated into the knowledge graph. Through incremental learning and online update mechanisms, recommendation systems can continuously optimize their recommendation accuracy. For example, as users’ learning behavior and preferences change, the knowledge graph dynamically adjusts the embedding vector and improves the accuracy and timeliness of the recommendation system through continuous training.
Explanatory recommendations driven by knowledge graph
In addition to improving traditional recommendation accuracy, knowledge graphs also provide interpretability for recommendations. Users can understand the reasons for recommendations, such as’ if you like Beethoven’s works, you may like Chopin because both belong to the romantic genre of classical music’. Through this explanatory recommendation, the system not only provides higher quality recommendation results, but also enhances user trust.
In short, the integration of knowledge graphs in recommendation systems not only improves the accuracy of recommendations, the ability to solve cold start problems, and the performance of long tail recommendations, but also enhances the interpretability and diversity of recommendation systems through path inference. In the framework, the knowledge graph enhances the accuracy of personalized recommendations by integrating with user and project embeddings, and ensures continuous optimization of the recommendation system through incremental learning mechanisms.
Results and discussion
Experiment design and datasets collection
The dataset used in this experiment comes from Last.FM, and it is an open-source dataset provided by a well-known music company. This dataset contains a large volume of user music listening records, specifically covering activity data from 1,880 users and involving 3,850 music tracks, with a total of 42,400 user-music interaction records. To make the data more suitable for the research work, the raw data are preprocessed, converting user-music interaction records into a binary format. This means that if a user has ever listened to a particular piece of music, it is marked as 1; if the user has not listened to it, it is marked as 0.
Additionally, to enable the model to be trained on the Last.fm dataset, a suitable music knowledge graph database is constructed. This knowledge graph database consists of two main components: one part is a mapping table that contains the correspondence between music IDs in Last.fm and entity IDs in the knowledge graph; the other part comprises entity relationship pairs, represented as triples, which indicate the relationships between entities in the knowledge graph. These data are stored in text file format, and both the entities and relationships are encoded using ID numbers. This method not only significantly speeds up entity linking but also reduces storage space usage. According to statistics, the knowledge graph database contains 9,400 entities, 62 types of relationships, and a total of 15,600 entity relationship pairs.
In addition, to validate the potential performance of recommendation systems in multimodal data fusion scenarios, this work further introduces two publicly available multimodal datasets: Music4All is a music dataset that contains multimodal information, including audio, lyrics, videos, and related label information. This dataset can provide important support for studying the application of multimodal feature fusion in music recommendation. Usage scenario: In the experiment, the audio and lyric features of the Music4All dataset are extracted and combined with the entity relationship information of the knowledge graph to explore the recommendation performance of the model in multimodal data scenarios. Music4All supports extracting multimodal features from audio and video for recommendation system optimization research.
The MuSe (Multimodal Sentiment in Songs) dataset focuses on sentiment analysis in songs, including audio, lyrics, and corresponding short video clips. This provides a unique perspective for studying emotion-driven multimodal recommendation systems. This work extracts video clips and audio features from the MuSe dataset and combines them with a knowledge graph to further analyze the applicability and performance of the recommendation system in emotion driven scenarios. This dataset focuses on emotional annotation and multimodal interaction data, and is suitable for research on the fusion of emotions and multimodal features. Introducing the above-mentioned multimodal dataset enriches the experimental scenarios and provides additional validation support for the diversity and wide applicability of research conclusions.
This work also further designs a joint experiment of multimodal data to verify the overall recommendation performance of the model when fusing audio, video, and user behavior data. During the experiment, this work evaluates the recommendation effects of the Last.fm, Music4All, and MuSe datasets when used separately. Moreover, it conducts comprehensive tests on the combined dataset to analyze the impact of multimodal fusion on recommendation accuracy. Specifically, this work constructs a multimodal joint experiment scheme. Among them, Last.fm provides user behavior and audio data, Music4All provides video and lyric information, and MuSe provides emotional labels and short video data. In the joint experiment, this work first extracts features from data of different modalities and associates and maps the multimodal features through a knowledge graph. Then, it adopts a weighted fusion strategy to input data from different modalities into the recommendation model and optimize the feature interaction process.
This work adopts the following four experimental schemes for comparative analysis: Unimodal-User Behavior + Audio (Last.fm): Only use the user behavior and audio data of Last.fm as inputs. Unimodal-Audio + Lyrics + Video (Music4All): Use the audio, lyric, and video features of the Music4All dataset for recommendation. Unimodal-Audio + Video + Emotional Labels (MuSe): Use the audio, video, and emotional label information of the MuSe dataset for recommendation. Multimodal Fusion (Last.fm + Music4All + MuSe): Integrate the information of the above three datasets, enhance the feature representation using the knowledge graph, and fuse the multimodal information for joint training. In order to comprehensively evaluate the performance of the recommendation system, this work adopts the following mainstream evaluation indicators: Precision@K: Calculate the proportion of relevant items among the top K recommended items. Recall@K: Calculate the proportion of the user’s true preference items covered by the top K recommended items. NDCG@K (Normalized Discounted Cumulative Gain): Consider the ranking weights of the recommended items and measure the quality of the recommendation results. Mean Reciprocal Rank (MRR): Calculate the mean of the reciprocal ranks of the first relevant item for user queries and evaluate the accuracy of the recommendations.
Table 1 provides some of the pseudocode of the research process here:
Experimental environment and parameters setting
The hardware and software environment configuration required for the experiment is as follows. It includes a server equipped with a high-performance Central Processing Unit (CPU) and Graphics Processing Unit (GPU) to ensure fast data processing capabilities and efficient model training. The operating system used is Ubuntu 18.04 LTS, with the primary programming language being Python 3.7. The deep learning framework uses PyTorch 1.7 for model training and testing. Additionally, Pandas and NumPy are employed for data processing, Matplotlib and Seaborn for data visualization, and Scikit-Learn for model evaluation. Table 2 presents the parameter settings:
Performance evaluation
To comprehensively evaluate the system’s performance, multiple evaluation metrics have been established, along with their calculation equations. Specifically, these metrics include Accuracy, Recall, F1 Score, and Mean Average Precision (MAP). Additionally, the performance of the recommendation lists under different TOP-K conditions is analyzed (Figs. 5, 6, 7 and 8) and the system’s ability to handle sparse data (Fig. 9). Accuracy takes into account all possible prediction outcomes, including True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). AP(i) represents the precision for the i-th query. The calculation equation is as follows:
$$\:\text{A}\text{c}\text{c}\text{u}\text{r}\text{a}\text{c}\text{y}=\frac{\text{T}\text{P}+\text{T}\text{N}}{\text{T}\text{P}+\text{T}\text{N}+\text{F}\text{P}+\text{F}\text{N}}$$
(9)
$$\:\text{R}\text{e}\text{c}\text{a}\text{l}\text{l}=\frac{\text{T}\text{P}}{\text{T}\text{P}+\text{F}\text{N}}$$
(10)
$${\text{F1}}\;{\text{Score = 2}} \cdot \frac{{{\text{Precision}} \cdot {\text{Recall}}}}{{{\text{Precision + Recall}}}}$$
(11)
$${\text{MAP}} = \frac{1}{{{\text{number~}}\;{\text{of}}\;{\text{~queries}}}}\mathop \sum \limits_{{i = 1}}^{{{\text{number}}\;{\text{~of}}\;{\text{~queries}}}} {\text{AP}}\left( i \right)$$
(12)

Accuracy at different TOP-K levels.
Figure 5 illustrates that as TOP-K increases, the accuracy of all methods declines. However, the proposed music platform consistently demonstrates a higher accuracy across the entire range. Notably, when TOP-K is relatively small, the accuracy of the proposed music platform reaches 0.90, which is 15% points higher than that of CF and 12% points higher than content-based recommendation (CBR). This indicates that by incorporating knowledge graphs and feature fusion techniques, the proposed method can more effectively capture users’ true preferences. The knowledge graph aids in constructing multi-layered relationships between users and music, while feature fusion enables the system to integrate more user behavior information, thereby enhancing the accuracy of recommendations.
The reason for this result can be attributed to the following points: by introducing a knowledge graph, the system is able to construct a multi-level network of relationships between users and music, helping the system better understand the complex associations between music and user interests. The semantic information in knowledge graphs can fill the gaps in sparse data, enabling recommendation systems to accurately capture users’ true preferences with small TOP-K values. Moreover, feature fusion technology integrates various data such as user behavior information and audio feature vectors into a comprehensive feature vector. This enables the system to comprehensively consider more dimensions of information in the recommendation process. This fusion approach not only enhances the understanding of user preferences, but also improves the accuracy of recommendation results. Especially in situations where TOP-K is small, it can accurately recommend suitable music for users.

Recall at different TOP-K levels.
Figure 6 shows that as TOP-K increases, the recall rate gradually rises. The proposed music platform demonstrates a consistently high recall rate across the entire range. When TOP-K is relatively small, the recall rate of the proposed music platform reaches 0.80, which is 20% points higher than that of CF and 15% points higher than CBR. This indicates that the proposed method not only excels in providing accurate recommendations but also ensures that the recommendation list includes as many relevant items as possible. The rich relationships in the knowledge graph and the feature fusion techniques help the system identify more potentially interesting items, thereby enhancing the recall rate.
This is because the integrated knowledge graph establishes richer and more diverse relationships between users and music, enabling the system to accurately recommend music that users like and discover other music that users may be interested in. The multi-level relationships in the graph help the recommendation system identify more potential interesting items, thereby improving the recall rate. Feature fusion not only enhances the model’s understanding of user preferences, but also improves the model’s ability to cover different types of music. By integrating audio features, user behavior characteristics, etc., the system can more comprehensively identify music genres that may attract users, thus including more relevant items in the recommendation list and improving the recall rate.

F1 score at different TOP-K levels.
The music platform shown in Fig. 7 achieves a high F1 score across all TOP-K ranges, reaching 0.84 at TOP-5, which is 17% points higher than CF and 13% points higher than CBR. This indicates that the proposed method not only excels in ensuring the accuracy and breadth of recommendations but also effectively balances these two aspects. The use of knowledge graphs and feature fusion techniques enables the system to provide recommendations with high accuracy while covering a wide range of user interests.
This is because by introducing knowledge graphs, recommendation systems can comprehensively discover more potential music interests while understanding user preferences. By combining feature fusion technology, the system can ensure accurate recommendations while also covering more user interests, thereby achieving an improvement in F1 score. Feature fusion technology can combine user behavior, music features, and semantic information in the knowledge graph to form multi-dimensional recommendation criteria. This not only increases the accuracy of recommendations, but also improves the diversity of recommendation lists, enabling the system to maintain a high level of F1 score under different TOP-K values.

MAP at different TOP-K Levels.
In Fig. 8, the MAP is a metric used to assess the ranking quality of recommendation systems, and the proposed music platform consistently achieves high MAP values across all scenarios. Notably, at TOP-5, the MAP reaches 0.75, which is 20% points higher than CF and 15% points higher than CBR. This indicates that the proposed method not only provides more accurate recommendations but also ensures that the items in the recommendation list are ranked according to user interests. The semantic relationships within the knowledge graph and the feature fusion techniques assist the system in better understanding user preferences, thereby improving the ranking of recommendation results.
This is because the introduction of knowledge graphs helps the system establish richer associations between users and music, improving the accuracy of recommendations and enhancing the ranking effect of recommendation results. The structured semantic information in the graph helps to understand users’ potential interests, enabling recommendation results to be sorted according to users’ true preferences, thereby improving the MAP value. Feature fusion technology further enhances the recommendation performance of the system, making the ranking of recommendation items more in line with users’ interests. By integrating multiple features, the system can better understand the correlation between different music projects, thereby improving the accuracy and ranking effect of recommendation results.
To evaluate the system’s performance under varying levels of data sparsity, five new sparse training sets are created by randomly sampling 10%, 20%, 30%, 40%, and 50% of the data from the original Last.fm training set. Figure 9 presents the testing results:

Accuracy under sparse datasets.
In Fig. 9, as the amount of data increases, the accuracy of all methods improves. However, the proposed music platform consistently demonstrates higher accuracy across all levels of sparsity. Even in the sparsest dataset (containing only 10% of the data), the music platform still achieves an accuracy of 0.80, significantly surpassing the 0.65 of CF and 0.68 of CBR. This indicates that the proposed method exhibits better robustness and adaptability when handling sparse datasets. The knowledge graph provides additional structured information, helping the system overcome the challenges posed by data sparsity, while the feature fusion techniques further enhance the system’s robustness by integrating multi-source information. The reasons for this phenomenon are as follows: Knowledge graphs can provide more structured information to the system by constructing multi-level relationships between users and music, filling the gaps caused by sparse data. The semantic information in the graph enables the system to maintain high recommendation quality even when data is sparse. In addition, feature fusion technology further enhances the robustness of the system by integrating data from different sources, such as user behavior, and music features. When data is sparse, the system can utilize the fused multidimensional information to enable the recommendation system to maintain high accuracy in a scarce data environment.
To further validate the effectiveness of the propsoed method, thie work conducts more experiments on the Music4All and MuSe datasets, and the experimental results are shown in Figs. 10 and 11.

Experimental results on Music4All dataset.

Experimental results on the MuSe dataset.
In the experimental results on the Music4All dataset shown in Fig. 10, the proposed algorithm outperforms CF and CBR methods in all metrics. Specifically, in terms of TOP-5 accuracy, the proposed algorithm achieves 0.88, significantly higher than CF (0.75) and content-based recommendation (0.78). In terms of recall rate, the proposed algorithm also shows significant advantages, with a TOP-5 recall rate of 0.82, while the recall rates for CF and content-based recommendation are 0.65 and 0.70, respectively. In terms of MAP value, the proposed algorithm outperforms the other two methods with a score of 0.77, further verifying its advantages in recommendation accuracy and ranking quality.
The experimental results on the MuSe dataset in Fig. 11 also show a similar trend. The proposed algorithm achieves a TOP-5 accuracy of 0.90, which is 10% and 5% higher than CF (0.80) and content-based recommendation (0.85), respectively. In terms of recall rate, the proposed algorithm achieves 0.84, which is higher than CF (0.72) and content-based recommendation (0.75). In terms of MAP value, the proposed method achieves 0.79, significantly better than CF (0.68) and content-based recommendation (0.72), further demonstrating the excellent performance of our method in ranking quality.
These experimental results reveal that the proposed algorithm consistently outperforms traditional CF and content-based recommendation methods on different datasets. Especially on the Music4All and MuSe datasets, significant advantages are observed in accuracy, recall, and MAP values. This indicates that recommendation platforms based on knowledge graphs and feature fusion play an important role in improving recommendation accuracy, coverage, and ranking quality. These results also indicate that the proposed algorithm has good generalization ability and stability when dealing with different types of datasets.
Figure 12 shows in detail the recommendation performance under different data combinations, with a focus on analyzing the contribution of multimodal data fusion.

Comparison of recommendation effectsbetween unimodal and multimodal.
The results of the joint experiment in Fig. 12 show that, in terms of the Precision@10 index, the multimodal fusion model reaches 0.920, which is a 4.3% increase compared to the highest value of 0.882 for a single modality. In terms of Recall@10, multimodal fusion increases to 0.615, a 6.4% increase compared to the highest value of 0.578 for a single modality. This indicates that multimodal data can effectively enhance the understanding of user preference information, thereby improving the accuracy and coverage of recommendations. For the NDCG@10 index, the multimodal fusion reaches 0.781, which is a 6.4% increase compared to the unimodal data of Last.fm and a 4.7% increase compared to Music4All. This shows that the fused knowledge graph and multimodal features can optimize the ranking of recommendation results, making highly relevant recommended items rank higher and enhancing the user experience. In addition, the multimodal fusion reaches 0.652 in the MRR index, a 5.7% increase compared to the highest value of 0.617 for a single modality. This indicates that after fusing multimodal information, the system can more accurately locate the user’s interest points, making the most relevant recommended items more likely to appear in the front positions.
In practical applications, the user interaction data often has the problem of sparsity. Especially in the Last.fm dataset, some users have fewer historical play records, making it difficult for the recommendation system to accurately model their preferences. The Music4All and MuSe datasets provide additional lyric, video, and emotional information. The modal information can serve as supplementary features to help the model more comprehensively understand the user’s interest preferences. The experimental results show that after multimodal fusion, the Precision@10 of the model among the low-active user group increases from 0.815 to 0.876. It indicates that the introduction of multimodal information effectively improves the recommendation quality, enabling the system to provide more accurate recommendation results for users with less data.
An unimodal recommendation system usually relies on limited information. For example, the method based on Last.fm mainly uses the user’s historical play records and audio features, while the Music4All and MuSe datasets introduce content information in more dimensions. After fusing data from different modalities, the system can comprehensively analyze the user’s preferences in different dimensions. For example, audio features can reflect the user’s tendency towards melody styles, lyrics can reveal their interest in content themes, and video features and emotional labels can further tap into the user’s emotional preferences. The experimental results show that the multimodal fusion model has increased by 6.4% in Recall@10, indicating that the user’s true interests are more fully mined, thus improving the recommendation coverage.
In the multimodal fusion process of this work, the knowledge graph plays a key role. The information of different modalities may have certain distribution differences, and direct fusion may lead to information conflicts or redundancies. To solve this problem, this work constructs a knowledge graph to structurally associate the features of different modalities such as users, songs, artists, and lyric themes, thereby improving the interpretability and generalization ability of the recommendation system. The experiment shows that after fusing the knowledge graph, the NDCG@10 of the model increases from 0.746 to 0.781, further verifying the effectiveness of the knowledge graph in optimizing the ranking quality of recommendations. In conclusion, the fusion of multimodal data not only effectively alleviates the problem of data sparsity but also enhances the ability to model user interests. Meanwhile, with the introduction of the knowledge graph, the effective association of cross-modal features is achieved, enabling the recommendation system to significantly improve in terms of accuracy, recall rate, and ranking quality.
Furthermore, the method proposed is compared with several baseline methods in terms of performance on different indicators. They include CF, Content-Based Recommendation (CBR), and deep learning recommendation models such as Wide & Deep and Neural Matrix Factorization (NeuMF). Figure 13 displays the results:

Results of the comparative experiments of different models.
Figure 13 suggests that the method proposed outperforms other comparative methods in both the Top-10 recommendation accuracy (Precision@10) and recall rate (Recall@10). Especially in terms of accurate recommendation, the method of this work has increased by nearly 12% (compared with CF). This indicates that the fusion of multimodal features and the knowledge graph can better capture user interests and recommend relevant content. In terms of the NDCG@10 index, the results reflect the advantage of the method of this work when considering the ranking of recommended content. The method proposed is about 4-5% higher than other methods in this index, verifying its ability to optimize the ranking of recommendation results. The performance of the method proposed in terms of the F1-Score is also higher than that of the baseline methods. This indicates that it can achieve a better balance between accuracy and recall rate and is suitable for recommendation scenarios with different user needs. When dealing with the problem of data sparsity, the method proposed still maintains a high accuracy. This is mainly due to the introduction of the knowledge graph, which provides rich semantic information to fill the gaps of traditional recommendation systems in the case of data sparsity. Compared with the CF method (0.72), the accuracy of the method proposed has increased by about 11%, demonstrating its stronger robustness.
By comparing with traditional baseline methods and advanced deep learning recommendation methods (such as Wide & Deep and NeuMF), the method proposed performs superiorly in multiple key indicators. Especially with the combination of multimodal data fusion and the knowledge graph, it can provide users with more personalized and accurate recommendation results. These results prove the effectiveness and innovation of the method proposed.
Discussion
The research presented above demonstrates that the proposed music platform excels in various metrics such as accuracy, recall, F1 score, and MAP across different TOP-K settings. This indicates that by incorporating knowledge graphs and feature fusion techniques, the system can more effectively capture the latent associations between users and music, resulting in more precise recommendations. This conclusion aligns with the findings of Li et al. (2023)33, which indicated that utilizing knowledge graphs could enhance the expressive power of recommendation systems, aiding them in understanding and reasoning about user preferences. Additionally, the application of feature fusion techniques is supported by the research of Deng et al. (2023)34, which suggested that integrating multi-source information can improve the performance of recommendation systems. Furthermore, the proposed music platform maintains high accuracy even in datasets with varying degrees of sparsity. Even with only 10% of the data available, the accuracy can reach 0.80, indicating that the proposed method exhibits robust performance and adaptability. This capability to handle data sparsity is consistent with the findings of Gaur et al. (2021)35, which pointed out that introducing external knowledge, such as knowledge graphs, could mitigate some of the negative effects of data sparsity. Knowledge graphs provide additional structured information for recommendation systems, which can help the system understand user preferences and provide reasonable recommendations even in the absence of a large amount of historical data.
Furthermore, the advantage of this work lies not only in solving the problem of data sparsity, but also in its ability to outperform traditional methods in various performance metrics. The introduction of knowledge graphs enables the system to construct more complex user item relationship graphs, which is crucial for capturing potential user needs. Feature fusion further enhances the adaptability of the system, enabling it to maintain high-level performance under different TOP-K conditions. By combining these two technologies, the system can more accurately understand and infer users’ interests and preferences, providing morepersonalized and diverse recommendation results. Overall, the proposed music recommendation platform effectively improves the overall performance of the recommendation system by combining knowledge graph and feature fusion technology, especially when dealing with sparse data and multi-dimensional information, demonstrating strong advantages. Future research can further explore how to apply these technologies in more dynamic environments, enhance the real-time response capability and user experience of the system, and provide users with more intelligent and personalized music recommendation services.
Conclusion
Research contribution
This work proposes an innovative music recommendation platform that significantly improves the performance of traditional recommendation systems by effectively combining knowledge graph and feature fusion techniques. The proposed music platform has demonstrated outstanding performance in multiple dimensions, particularly in metrics such as accuracy, recall, F1 score, and MAP. By introducing a knowledge graph, the system can build a richer multi-level relationship between users and music in the music field, thereby improving the accuracy and coverage of recommendations. Meantime, feature fusion technology can integrate multidimensional information from user behavior data, audio data, and video data, further enhancing the overall performance of the recommendation system. Through the deep integration of this knowledge graph and recommendation system, this work effectively solves the challenges of data sparsity and insufficient recommendation accuracy commonly found in traditional recommendation systems, opening up new research directions for future music recommendation systems.
Future works and research limitations
Although this work has achieved significant results, especially in the integration of knowledge graphs and recommendation systems, there are still some unresolved issues and room for improvement. Future research will further optimize the real-time capability, adaptability, and user experience of the recommendation system to provide more intelligent and personalized recommendation services. Specifically, future research directions include: enhancing the real-time response capability of the system to quickly respond to personalized user needs; considering the dynamic changes in user behavior and its impact on social networks, further strengthening the real-time capture and updating of user preferences; further expanding the dataset to validate the effectiveness of the proposed algorithm in a wider range of application scenarios, particularly in the transferability and effectiveness of knowledge graphs in cross domain recommendation; further integrating more contextual information into the system to enhance user experience, ensuring that the recommendation system can provide content that better meets user needs and interests, and ultimately improving overall user satisfaction.