
Cohesity wants AI to see everything – live, backed-up, and buried – Blocks and Files
作者:Chris Mellor
Analysis. Cohesity is moving beyond data protection and cyber-resilience by building a real-time data access and management facility alongside its existing data protection access pipelines so that it can bring information from both live and backed-up data to GenAI models.

This recognition came from a discussion with Cohesity’s VP for AI Solutions, Greg Stratton, that looked at metadata and its use in AI data pipelining.
An AI model needs access to an organization’s own data so that it can be used for retrieval-augmented generation, thereby producing responses pertinent to the organization’s staff and based on accurate and relevant data. Where does this data come from?
An enterprise or public sector organization will have a set of databases holding its structured and also some unstructured information, plus files and object data. All this data may be stored in on-premises systems – block, file, or object, unified or separate – and/or in various public cloud storage instances. AI pipelines will have to be built to look at these stores, filter and extract the right data, vectorize the unstructured stuff, and feed it all to the AI models.
This concept is now well understood and simple enough to diagram:

This diagram shows a single AI pipeline, but that is a simplification as there could be several being fed from different data resources, such as ERM applications, data warehouses, data lakes, Salesforce and its ilk, and so forth. But bear with us as we illustrate our thinking with a single pipeline.
We’re calling this data live data, as it is real-time, and as a way of distinguishing it from backup data. But, of course, there are vast troves of data in backup stores and an organization’s AI Models get another view of its data estate which they can mine for user request responses. Data protection suppliers, such as Cohesity, Commvault, Rubrik, and Veeam. All four, and others, are building what we could call backup-based AI pipelines. Again, this can be easily diagrammed:
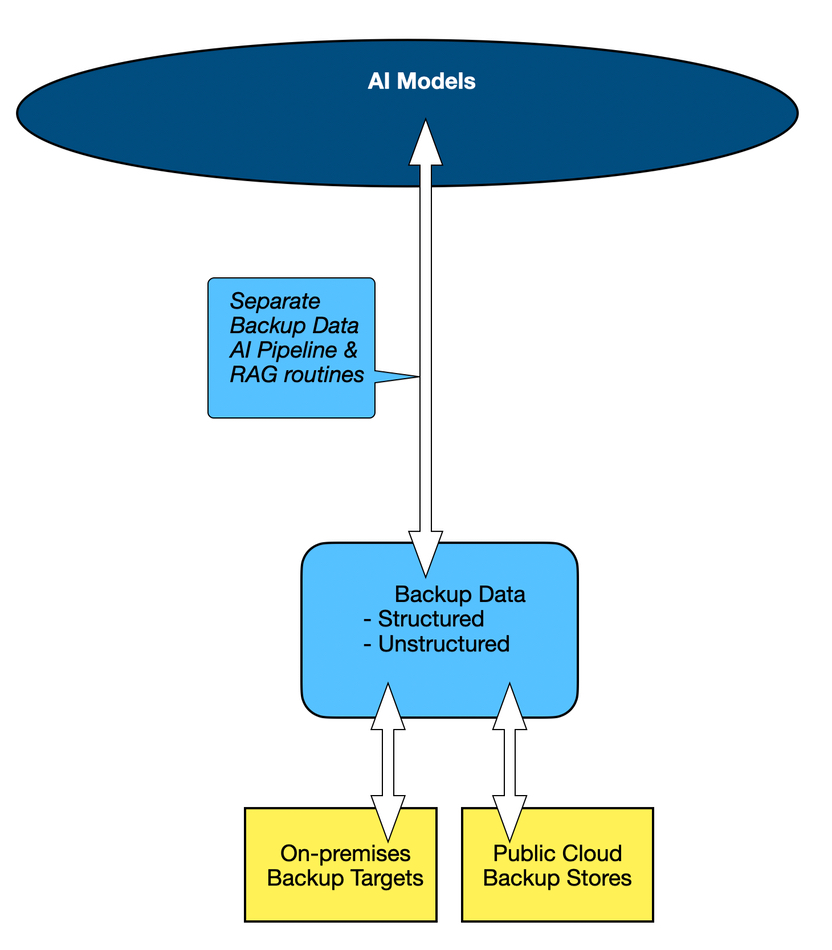
We now have two different AI data pipelines, one for live data and one for backup data. But that’s not all; there is also archival data, stored in separate repositories from the live and backup data. We can now envisage a third archival data AI pipeline is needed and, again, it is simple to diagram:
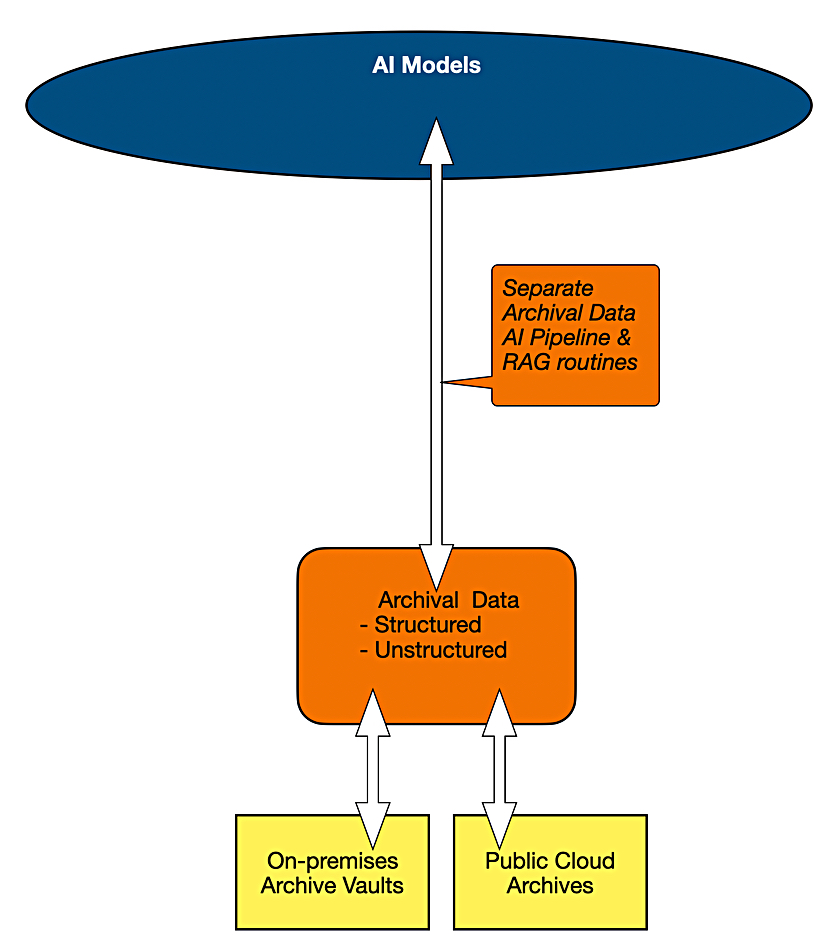
We are now at the point of having three separate AI model data pipelines – one each for live data, backup data, and archival data:

Ideally, we need all three, as together they provide access to the totality of an organization’s data.
This is wonderful but it comes with a considerable disadvantage. Although it gives the AI models access to all of an organization’s data, it is inefficient, will take some considerable time to build and also effort to maintain. As on-premises data is distributed between data centers and edge locations, and also the public cloud, and between structured and unstructured data stores, with the environment being dynamic and not static, ongoing maintenance and development will be extensive and necessary. This is going to be costly.
What we need is a universal data access layer, with touch points for live, backup and archive data, be it on-premises and distributed across sites and applications, in the public cloud as storage instances, or in SaaS applications, or a hybrid of these three.
Cohesity’s software already has touch points (connectors) for live data. It has to in order to back it up. It already stores metadata about its backups and archives. It already has its own AI capability, Gaia, to use this metadata, and also to generate more metadata about a backup item’s (database, records, files, objects, etc.) context and contents and usage. It can vectorize these items and locate them in vector spaces according to their presence or absence in projects for example.
Let’s now picture the situation as Cohesity sees it, in my understanding, with a single and universal access layer:
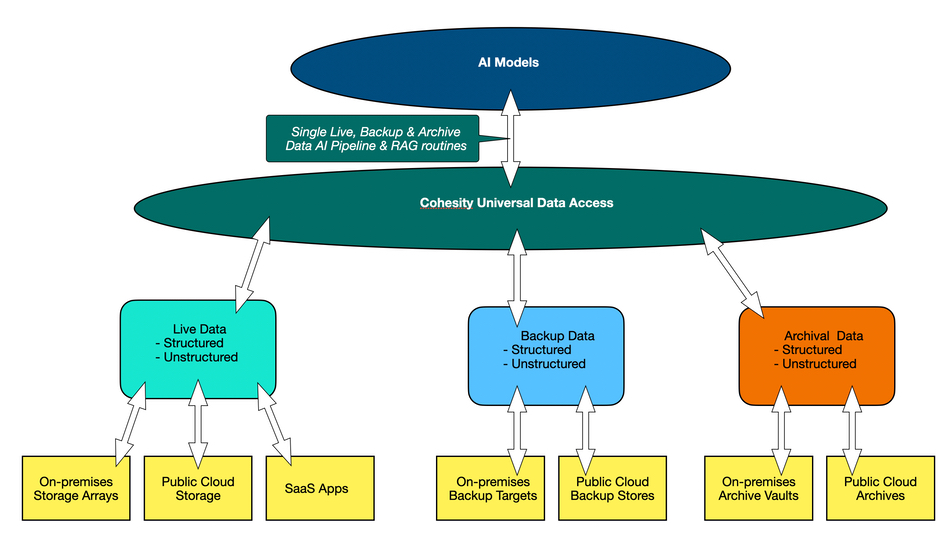
Cohesity can become the lens through which AI models look at the entirety of an organization’s data estate to generate responses to user questions and requests. This is an extraordinarily powerful yet simple idea. How can this not be a good thing? If an AI data pipeline function for an organization can not cover all three data types – live, backup, and archive – then it is inherently limited and less effective.
It seems to Blocks & Files that all the data protection vendors looking to make their backups data targets for AI models will recognize this, and want to extend their AI data pipeline functionality to cover live data and also archival stores. Cohesity has potentially had a head start here.
Another angle to consider – the live data-based AI pipeline providers will not be able to extend their pipelines to cover backup, also archive, data stores unless they have API access to those stores. Such APIs are proprietary and negotiated partnerships will be needed but may not be available. It’s going to be an interesting time as the various vendors with AI data pipelines wrestle with the concept of universal data access and what it means for their customers and the future of their own businesses.