

Hitachi Vantara primes partnership-driven AI push – Blocks and Files
作者:Chris Mellor
Hitachi has worked to re-evaluate the fit of its Hitachi Vantara subsidiary to respond faster to the market’s adoption of AI and AI’s accelerating development, according to its Chief Technology Officer.
In late 2023 Hitachi Vantara was reorganized with a services unit spun-off, a new direction set, and Sheila Rohra taking control as CEO.
It built a unified storage product data plane, a unified product control plane and an integrated data-to-agent AI capability. VSP One, the unified data plane, was launched in April last year and all-QLC flash and object storage products added late in the 2024. The unified control plane VSP 360 was announced a week ago. The soup-to-nuts AI capability is branded Hitachi iQ, not VSP One iQ nor Hitachi Vantara iQ, as it will be applied across the Hitachi group’s product portfolio.

Jason Hardy, Hitachi Vantara’s CTO for AI and a VP, presented Hitachi iQ at an event in Hitachi Vantara’s office.
VSP One
The data plane includes block, file and object protocols as well as mainframe storage. VSP One includes separate products for these, with:
- VSP One Block appliance – all-flash running SVOS (Storage Virtualization Operating System)
- VSP One SDS Block – all-flash
- VSP SDS Cloud – appliance, virtual machine or cloud offering running cloud-native SVOS
- VSP One File (old HNAS) and VSP SDS File
- VSP Object – the HCP (Hitachi Content Platform) product
A new VSP Object product is coming later this year, S3-based, developed in-house by Hitachi Vantara, and set to replace the existing HCP-based object storage product, which will be retired.
Hitachi Vantara is also unifying VSP One file and object with its own on-house development. This started a year ago. Up until now there has been no demand to unify block with file and object.
The data plane is hybrid, covering the on-premises world and will use the three main public clouds: AWS, Azure and GCP (Google Cloud Platform). The current public cloud support status is:
- VSP One SDS Block – available on AWS and GCP with Azure coming
- VSP One SDS Cloud – available on AWS
- VSP One File – roadmap item for AWS, Azure and GCP
- VSP One Object – roadmap item for AWS, Azure and GCP
VSP 360
The recently announced VSP 360 single control plane is an update or redevelopment of the existing Ops Center, and will play a key role in how AI facilities in the business are set up to use VSP One and how they are instantiated.
VSP 360 gives observability of and insight into VSP One’s carbon footprint. This is read-only now. The next generation of the product will enable user action. A user could, for example, choose a more sustainable option if VSP 360 reveals that the footprint is getting high and alternatives are available. This will be driven by agentic AI capabilities, implying that more than one agent will be involved and the interaction between the agents cannot be pre-programmed.
The VSP One integrated and hybrid storage offerings, managed, observed and provisioned through VSP 360, form the underlying data layer used by Hitachi iQ.
Hitachi iQ
Hitachi Vantara says it has been working with Nvidia on several projects, including engagements with Hitachi group businesses such as Rail where an HMAX digital asset management system, using Nvidia GPUs in its IGX industrial AI platform, has – we’re told – enabled a 15 percent lowering of maintenance costs and a 20 percent reduction in train delays. Hitachi Vantara also has an Nvidia BasePOD certification. A blog by Hardy provides some background here.

Hitachi Vantara says its iQ product set is developing so fast that the marketing aspect – ie, telling the world about it – has been a tad neglected.
Hardy told B&F that Hitachi iQ is built on 3 pillars: Foundation, Enrichment and Innovation. The Foundation has requirements aligned with Nvidia and Cisco and is an end-to-end offering equivalent to an AI Factory for rapid deployment. Enrichment refers to additional functionality, advisory services and varied consumption models. A Hammerspace partnership extends the data management capabilities, a WEKA deal provides high-performance parallel file capabilities, and the data lake side is helped with a Zetaris collaboration. Innovation refers to vertical market initiatives, such as Hitachi iQ AI Solutions use case documentation, and projects with partners and Nvidia customers.
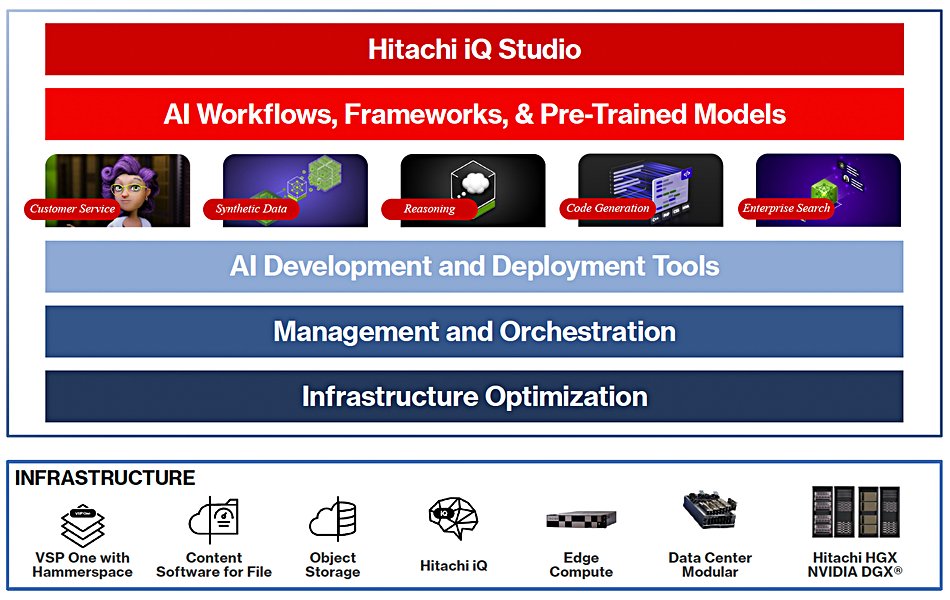
A Hitachi iQ Studio offering is presented as a complete AI solution stack spanning infrastructure to applications and running across on-prem, cloud, and edge locations. It comprises an iQ Studio Agent and Studio Agent runtime with links to Nvidia’s NIM and NeMO Retriever microservices extracting and embedding data from VSP One object and file, and storing the vectors in a Milvus vector database.
There is a Time Machine feature in iQ which is, we understand, unique to Hitachi V and developed in-house. This enables the set of vectors used by a running AI training or inference job to be modified, during the job’s execution and without topping the job.
As we understand it, incoming data is detected by iQ and embedding models run to vectorize it, with the vectors stored in a Milvus database. The embedding is done in such a way as to reserve, in metadata vectors, the structure of incoming data. For example, if a document file arrives, this has content and file-level metadata; author, size, date and time created, name, etc. The content is vectorized as is the metadata so that the vectorized document entity status is stored in the Milvus database as well.

This means that if, for some reason, a set of vectors which includes the content ones from the document becomes invalid during the AI inference or training run, because the document breaks a privacy rule, the document content vectors can be identified and removed from the run’s vector set in a roll back type procedure. That’s why this feature is called a Time Machine – note the time metadata notes in the iQ Studio graphic above.
What we’re taking away from this is that Hitachi iQ product set is moving the company into AI storage and agentic work, hooking up with Nvidia, joining players such as Cisco, Dell, HPE, Lenovo, NetApp and Pure Storage. It’s done this by a combo of partnering and in-house development, leaving behind its previous (Hitachi Data Systems) acquisition mindset – remember the Archivas, BlueArc, Cofio, ParaScale, Pentaho and Shoden Data Systems purchases?
Hitachi V is in a hurry and AI is its perceived route to growth, increased relevance and front rank storage system supplier status. It is hoping the iQ product range will give it that boost.