

更新苹果的设备和服务器基础语言模型
内容类型精选亮点
![]()
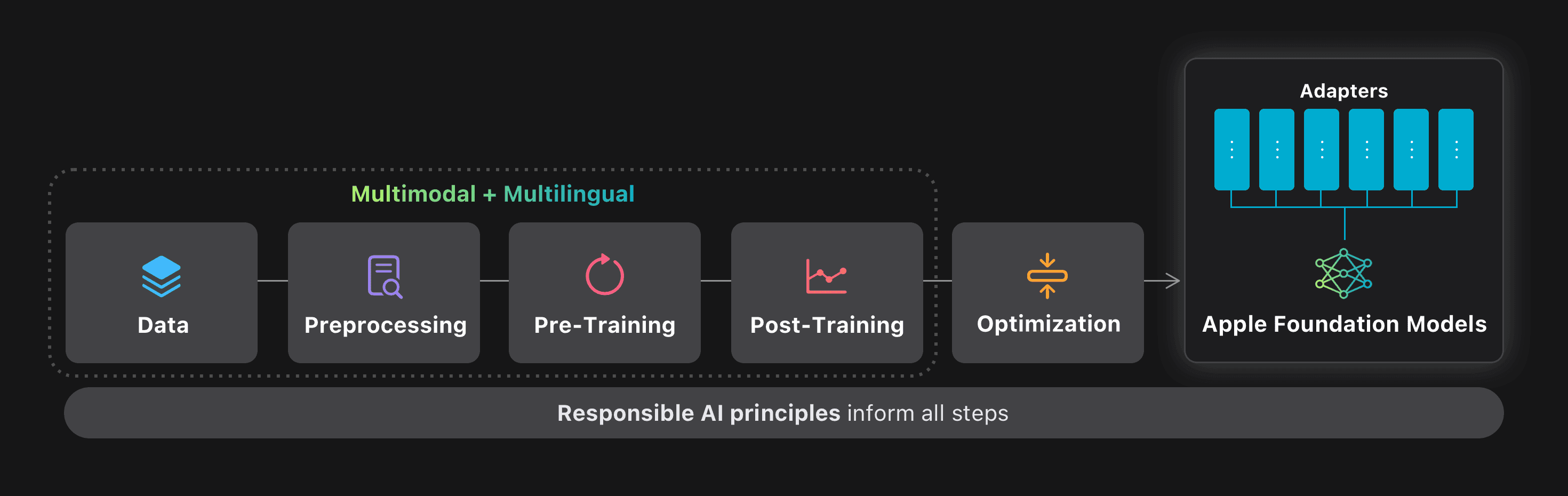
借助Apple Intelligence,我们将强大的生成AI纳入应用程序,并每天都在保护其隐私。在2025年全球开发人员会议上,我们引入了新一代语言基础模型,专门为增强我们最新软件发行的Apple Intelligence功能而开发。我们还介绍了新的基础模型框架,该框架使应用程序开发人员可以直接访问Apple Intelligence的核心核心基础语言模型。
我们制定了这些生成模型,为整个平台集成的广泛智能功能提供动力。这些模型具有改进的工具使用和推理功能,了解图像和文本输入,更快,更有效,并且设计为支持15种语言。我们最新的基础模型经过优化,可在Apple硅上有效运行,并包括一个紧凑的大约30亿参数模型,以及基于Experts服务器的混合物,并配有适合的新型建筑私有云计算。这两个基础模型是苹果为支持我们的用户而创建的较大生成模型系列的一部分。
在此概述中,我们详细介绍了我们设计的模型的体系结构,用于培训的数据,使用的培训配方,用于优化推理的技术以及与可比模型相比,我们用来优化推理的技术以及我们的评估结果。在整个过程中,我们强调了如何实现功能和质量改进的扩展,同时提高了速度和效率,并在私有云计算上。最后,在我们继续致力于维护我们的核心价值观的过程中,我们说明了负责AI原则如何在整个模型开发过程中集成。
模型体系结构
我们开发了设备和服务器模型,以满足广泛的性能和部署要求。在设备模型方面已针对效率进行了优化,并针对Apple Silicon量身定制,从而可以使用最少的资源使用,而服务器模型旨在为更复杂的任务提供高精度和可扩展性。它们共同形成了适合各种应用的互补解决方案套件。
我们通过开发新的模型体系结构来提高两种模型的效率。对于设备模型,我们将完整模型分为两个深度比的两个区块。块2的所有键值(KV)缓存都与块1的最后一层生成的密钥值共享,从而将KV缓存存储器的使用量减少了37.5%,并显着改善了第一端的时间。我们还通过引入并行轨道混合物(PT-MOE)设计开发了服务器模型的新体系结构(请参阅图2)。该模型由多个较小的变压器组成,称为轨道,该过程代币独立,仅在每个轨道块的输入和输出边界上应用同步。每个轨道块都有自己的MOE层集。结合通过轨道独立性实现的轨道级并行性,该设计显着降低了同步开销,并允许模型有效地扩展,同时保持低潜伏期而不会损害质量。
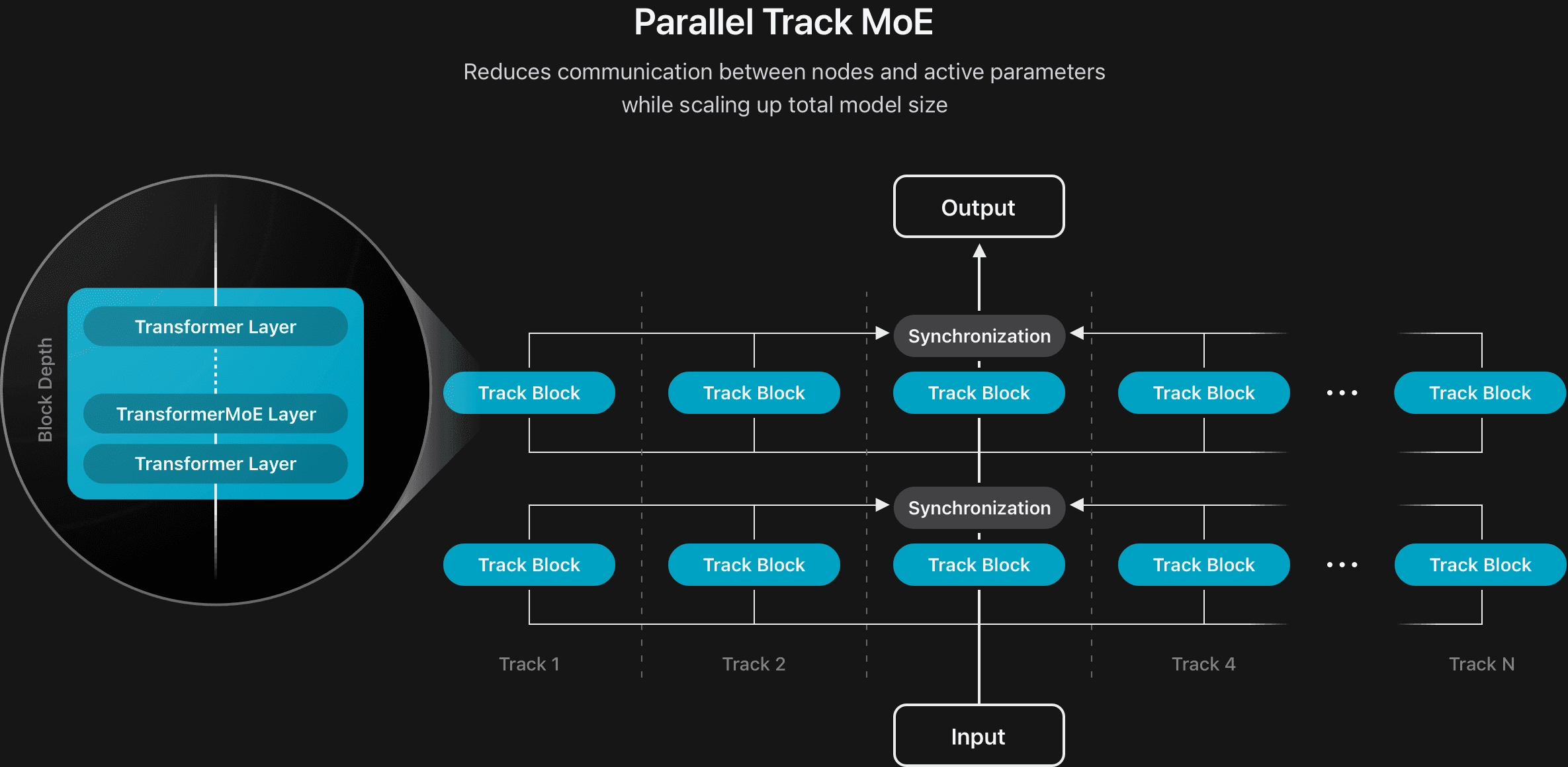
为了支持较长的上下文输入,我们设计了一个相互交织的注意结构,将滑动窗口的本地注意力层与旋转位置嵌入(绳索)(绳索)和无位置嵌入(不)的全球注意力层(nope)相结合。此设置可改善长度的概括,降低KV高速缓存的大小,并在长篇文化推断期间保持模型质量。
为了启用视觉功能,我们开发了一个在大规模图像数据上训练的视觉编码器。它由一个视觉主链组成,用于提取丰富的特征和一个视觉 - 语言适配器,以使特征与llmé的代币表示。我们将标准视觉变压器(VIT-G)用于服务器模型的1B参数,以及具有300m参数的更有效的VITDET-L主链用于设备部署。为了进一步有效地捕获和整合本地细节和更广泛的全球环境,我们在标准VITDET中添加了一种新颖的注册窗口(RW)机制,以便可以有效地捕获全球环境和本地细节。
培训数据
我们相信使用多样化和高质量的数据培训我们的模型。这包括我们已从出版商获得许可的数据,该数据是根据公开可用或开源数据集策划的,以及由我们的Web-Crawler Applebot抓取的公开信息。培训我们的基础模型时,我们不会使用用户私人个人数据或用户互动。此外,我们采取步骤应用过滤器以删除某些类别的个人身份信息,并排除亵渎和不安全的材料。
此外,我们继续遵循道德Web爬网的最佳实践,包括遵循广泛的机器人。TXT协议,以允许Web Publishers选择退出其用于培训Apple Apple Apple-Apple-appletage offerative Foundation Foundation Models的内容。Web发布者对Applebot可以看到的页面可以看到哪些页面以及如何使用,同时仍在Siri和Spotlight中出现在搜索结果中。
文本数据
在尊重上述选项时,我们继续从Applebot爬行的Web内容中为我们的模型提供了很大一部分的预培训数据,涵盖了数千亿页,并涵盖了广泛的语言,语录和主题。鉴于网络的嘈杂性,Applebot采用先进的爬行策略来优先考虑高质量和多样化的内容。特别是,我们专注于捕获高保真性HTML页面,该页面用文本和结构化元数据丰富了数据集,以使媒体与周围的文本内容对齐。为了提高相关性和质量,该系统利用多个信号,包括域级语言识别,主题分布分析和URL路径模式启发式方法。
我们特别谨慎地从文档和现代网站准确提取内容。我们通过无头渲染来增强文档集合,启用全页加载,动态内容交互和JavaScript执行,这对于从Web体系结构中提取数据至关重要。对于依赖动态内容和用户交互的网站,我们启用了完整的页面加载和交互模拟,以可靠地从复杂页面中提取有意义的信息。我们还将大型语言模型(LLM)纳入了我们的提取管道,尤其是对于特定于域的文档,因为它们通常超过了传统的基于规则的方法。
除了先进的爬行策略外,我们还显着扩大了培训数据的规模和多样性,并结合了大量高质量的通用域,数学和编程内容。我们还将多种语言支持扩展到今年晚些时候将提供的新语言。
我们认为,高质量的过滤在整体模型性能中起着至关重要的作用。我们通过减少对过度侵略性的启发式规则并结合更多基于模型的过滤技术来完善数据过滤管道。通过引入模型信息信号,我们能够保留更有信息的内容,从而产生更大质量的预训练数据集。
图像数据
为了增强我们的模型并为Apple Intelligence功能启用视觉理解功能,我们将图像数据引入了培训前管道中,利用高质量许可数据以及公开可用的图像数据。
使用我们的网络爬行策略,我们采购了与相应的Alt-Texts的图像对。除了过滤法律合规性外,我们还过滤了数据质量,包括图像文本对齐。删除后,此过程产生了超过10B高质量的图像文本对。此外,我们通过在最初观察到的文本上下文中从爬行的文档中保存图像来创建图像文本交织的数据。在过滤质量和法律合规性之后,这导致了17500万个交织的图像文本文档,其中包含超过550m的图像。由于具有Web爬行的图像文本对通常很短,并且通常不全面地描述图像中的视觉细节,因此我们使用了合成图像字幕字幕数据来提供更丰富的描述。我们开发了一个内部图像字幕模型,能够在不同级别的细节上提供高质量的字幕,从关键词到段落级别的综合描述,生成了超过5B图像捕获对,我们在整个训练阶段使用了这些对象。
为了提高模型的文本丰富的视觉理解能力,我们通过许可数据,Web Crawling和内部合成,策划了各种文本丰富的数据集,包括PDF,文档,手稿,信息图表,表格和图表。然后,我们从图像数据中提取了文本,并生成了转录和问答对。
我们策划了各种类型的图像文本数据:
- 高质量标题数据和接地标题:我们采用对比性语言图像预训练(剪辑)模型和光学特征识别(OCR)工具作为过滤器,以从上述合成图像标题数据中获取高质量的图像。然后,我们利用一个内部接地模型将名词定位在标题中,并在名词之后附加坐标以形成接地标题。
- 表,图表和图:对于图表和图,我们首先提示内部LLM生成综合数据字段和相应的值,然后要求LLM编写可以基于先前合成的数据示例生成各种类型的图表和图的代码。最后,我们将图表,图和数据样本馈送到教师模型中,以生成用于模型培训的QA。对于桌子,我们从公开可用的网站上解析了表,并将其转换为降价,然后使用了由教师模型生成的图像标记对和图像合成的QA进行模型培训。
预训练
我们的培训前食谱已演变为扩展Apple Intelligence功能,以支持更多语言以及更广泛的功能,包括需要图像理解的功能。
预训练是在多个阶段进行的,在该阶段,第一个也是最多的密集型阶段仅针对文本模式。我们使用蒸馏损失训练了启动模型,但是我们没有使用大量的教师进行大型密集模型并从头开始培训,而是使用少量的〜3B模型使用少量的最高质量文本数据来稀疏地缩短了一个64个expert,每2层的Expexperts(MOE)。这使培训教师模型的成本减少了90%。但是,我们在14T文本令牌上从头开始训练了稀疏的服务器模型。
为了更好地支持此阶段的新语言,我们将文本令牌从100k的词汇量扩展到150K,从而实现了许多其他语言的表示质量,而代币只有25%。为了启用视觉感知,我们使用夹子风格的对比度损失对6B图像文本对训练了内部设备和服务器的视觉编码器,从而使编码器具有良好的视觉接地。
在预训练的第二阶段中,我们使用小型模型解码器与视觉语言自适应模块共同训练了视觉编码器,使用高质量的文本数据,交织的图像text数据和域特异性图像 - Text数据将模型的图像特征与模型的表示空间相结合。然后,我们利用这些视觉编码器和预训练的模型来改善代码,数学,多语言,长篇文章的理解,并通过多个持续的持续预训练阶段结合图像理解。
在持续预训练的阶段,我们调整了数据集混合物比率,同时纳入了验证的合成数据,以提高代码,数学和多语言功能。然后,我们通过多模式适应来结合视觉理解,而不会损害模型的文本功能。在此阶段,我们从头开始训练了视觉适应模块,以将视觉编码器连接到两个模型。在最终的持续训练阶段,我们培训了模型,使用高达65K令牌的序列处理明显更长的上下文长度,这些序列是从天然发生的长格式数据,旨在针对特定功能的合成长格式数据中取样的,以及先前一轮预培训的混合数据。
训练后
与我们的预训练方法相似,我们发展了培训后的过程,以支持语言的扩展和视觉理解。
我们通过将人工编写的演示和合成数据结合起来,重点放在核心视力能力上来扩展监督的微调(SFT)。这包括一般知识,推理,文本丰富的图像理解,文本和视觉接地以及多图像推理。我们通过检索其他图像并综合相应的提示和响应来进一步引导视觉SFT数据的多样性。
我们利用这个SFT阶段来进一步启用工具使用和多语言支持。我们设计了一种过程划分的注释方法,其中注释者向工具使用代理平台发出查询,返回平台的整个轨迹,包括工具调用详细信息,相应的执行响应和最终响应。这使注释者可以检查模型的预测并纠正错误,从而产生了树结构的数据集用于教学。为了扩展到更多语言,我们默认情况下将输出语言与输入语言匹配,但是我们还启用了通过创建具有混合语言的多样化数据集来使用不同的语言来提示和响应。
在SFT阶段之后,我们从人体反馈(RLHF)中应用了加强学习,用于启动设备模型和服务器模型。同时,我们根据模型的多代奖励差异提出了一种新颖的及时选择算法,以策划提示数据集进行RLHF培训。我们的评估表明,人类和自动基准的RLHF显着增长。而且,尽管我们在SFT和RLHF阶段引入了多语言数据,但我们发现RLHF在SFT上提供了显着的提升,从而导致人类评估中的16:9赢/损失率。
为了继续提高我们的模型多语言性能的质量,我们将Arde后(IFEVAL)和羊驼毛的说明与GPT-4O一起作为法官。我们收集了每种由母语者写的支持语言的提示。通过仔细的及时调整,我们在自动evals和人类的evals之间达到了良好的一致性,从而更快地迭代了。
优化
在过去的一年中,我们扩大了Apple智能功能,并提高了推理效率并降低了我们的设备和服务器模型的功耗。
我们使用量化意识训练(QAT)与可学习的重量缩减和重量初始化的新型组合使用量化训练(QAT)将现实设备模型压缩到每个重量(BPW)2位。使用基于块的纹理压缩方法(称为自适应可伸缩纹理压缩(ASTC))压缩服务器模型,虽然最初是针对图形管道开发的,但我们发现对模型压缩也有效。ASTC解压缩是通过Apple GPU中的专用硬件组件实现的,该组件允许在不引入其他计算开销的情况下解码权重。
对于这两种模型,我们使用与基本权重的基本权重的联合训练将嵌入式表量化为4位,并使用QAT进行基本权重,以及服务器模型的训练后量化。KV缓存量化为每重量8位。然后,我们使用其他数据训练了低级适配器,以恢复由于这些压缩步骤而导致的质量损失。通过这些技术,我们观察到一些轻微的质量回归,甚至是微小的改进,例如大约4.6%的回归mgsm并提高了1.5%mmlu对于设备模型,服务器模型的MGSM和2.3%的MMLU回归。
| 设备 | 服务器 | |
|---|---|---|
| 解码器重量 | 2-bpw通过QAT | 3.56-BPW通过ASTC |
| 嵌入 | 4位通过QAT | 4位后培训 |
| KV缓存 | 8位8位 | 适配器恢复 |
| 是的 | 是的 | 表1。用于机上和服务器基础模型的压缩和位量。 |
新的基础模型框架使开发人员使用〜3b参数在设备上语言模型开始创建自己的可靠,生产质量的生成AI功能。
Apple Intelligence核心的〜3b语言基础模型在各种文本任务中都擅长,例如摘要,实体提取,文本理解,改进,简短对话,生成创意内容等等。它并不是为一般世界知识的聊天机器人而设计的。我们鼓励应用程序开发人员使用此框架来构建针对其应用程序量身定制的有用功能。
我们框架的亮点是一种直观的迅速方法,用于限制解码,称为引导生成。随着导游的一代,开发人员通过添加一个@groblect宏观注释迅速结构或枚举。这是因为与模型,操作系统和Swift编程语言的垂直集成而起作用。它从Swift编译器宏开始,该宏将开发人员定义的类型转换为标准化的输出格式规范。在提示模型时,该框架将响应格式注入提示,并且由于在具有指导生成规范设计的特殊数据集中进行后培训,该模型能够理解并遵守它。接下来,OS守护程序采用了高度优化的,互补的解码和投机解码来提高推理速度的实现,同时提供了强大的保证,该模型的输出符合预期的格式。基于这些保证,该框架能够从模型输出中可靠地创建Swift类型的实例。这通过让应用程序开发人员编写更简单的代码来简化开发人员体验,并在Swift类型系统的支持下。
工具呼叫为开发人员提供了通过创建为模型提供特定类型的信息源或服务的工具来自定义〜3B模型能力的能力。
该框架的工具调用方法建立在有指导性的基础上。开发人员提供了简单工具Swift协议的实现,框架可以自动,最佳地处理并行和串行工具调用的潜在复杂调用图。在工具使用数据上进行的模型培训提高了模型对此框架功能的可靠性。
我们已经仔细设计了该框架,以帮助应用程序开发人员充分利用设备模型。对于需要教授〜3B模型全新技能的专门用例,我们还为培训等级32个适配器提供了Python工具包。工具包生产的适配器与基础模型框架完全兼容。但是,必须使用每个新版本的基本模型重新培训,因此在彻底探索基本模型的功能后,应考虑部署一个用于高级用例。
评估
我们对使用人类分级机的离线模型进行了质量评估。我们沿着标准的基本语言和推理能力进行评估,包括分析推理,集思广益,聊天,分类,封闭的问答,编码,创造性写作,提取,数学推理,开放式问答和答案,重写,摘要,摘要和工具使用。
随着我们将模型支持扩展到其他语言和语言,我们将评估任务设置为特定地点。人类分级者评估了该模型产生对该语言环境中用户的原生响应的能力。例如,一个模型回答英国用户的英国体育问题,预计“足球”比“足球”更适合当地。分级者可以为许多问题(包括未定位的术语或不自然的短语)标记模型的响应。本地特定的评估使用类似于英国美国语言环境的类别,除了它们排除了数学和编码之类的技术领域,这些域名本质上是本质上的不可知论者。
我们发现,我们的设备模型在所有语言中对QWEN-2.5-3B稍大的Qwen-2.5-3b表现出色,并且与更大的QWEN-3-4B和GEMMA-3-4B具有竞争力。我们基于服务器的模型对Llama-4-Scout的性能有利,Llama-4-Scout的总尺寸和主动参数数与我们的服务器模型相当,但落后于QWEN-3-235B和专有GPT-4O等较大型号。
文本回应的人类评估
随着我们的模型支持扩展到图像方式,使用图像问题对的评估集来评估图像理解能力。该评估集包含与文本评估集类似的类别,以及图像特定类别(例如信息图表),这些类别挑战了模型以推理文本丰富的图像。我们将设备模型与相似大小的视觉模型进行了比较,即InternVL-2.5-4B,QWEN-2.5-VL-3B-INSTRUCT和GEMMA-3-4B,以及我们的服务器模型与Llama-4-SCOUT,QWEN-2.5-VL-VL-32B,以及GPTEN-4-SCOUT,以及GPTEN-4O。我们发现,Appleâs的设备模型对较大的Internvl和Qwen和竞争性对Gemma的表现良好,而我们的服务器模型的表现优于QWEN-2.5-VL,在不到一半的推理群中,但落后于Llama-4-Scout和Gpt-4-Scout和Gpt-4-4O。
人类对图像响应的评估
除了评估通才能力的基本模型外,还进行了适配器的特定功能评估。例如,考虑基于适应器的视觉智能功能,该功能从传单的图像创建日历事件。在广泛的环境环境,摄像头和其他具有挑战性的情况下,收集了一组传单的评估集。这用于评估模型从传单中准确提取信息(包括日期和位置)以正确创建日历事件的能力。
负责人AI
Apple Intelligence是由我们设计的核心值在每一步,并建立在行业领先的隐私保护基础上。此外,我们创建了负责任的AI原则,以指导我们如何开发AI工具以及支撑它们的模型。这些原则在体系结构的每个阶段都反映了,这些原则可以使Apple Intelligence并将功能和工具与专业模型联系起来:
- 授权用户使用智能工具:我们确定可以负责任地使用AI来创建用于满足特定用户需求的工具的区域。我们尊重用户如何选择使用这些工具来实现其目标。
- 代表我们的用户:我们建立了深刻的个人产品,其目标是真实地代表全球用户。我们不断地工作以避免在AI工具和模型中延续刻板印象和系统性偏见。
- 谨慎设计:我们在流程的每个阶段都采取预防措施,包括设计,模型培训,功能开发和质量评估,以确定我们的AI工具如何被滥用或导致潜在的伤害。我们将在用户反馈的帮助下不断监视并主动改进我们的AI工具。
- 保护隐私:我们通过强大的设备处理和开创性的基础架构(如私人云计算)来保护用户的隐私。培训我们的基础模型时,我们不会使用用户的私人个人数据或用户互动。
这些原则指导我们在整个产品开发周期中的工作,从而为我们的产品设计,政策,评估和缓解提供了信息。作为苹果对负责人AI的承诺的一部分,我们继续识别并减轻使用基础模型固有的风险,例如幻觉和敏感性提示注射。我们的安全分类法可以帮助我们确定应谨慎处理的敏感内容。
为了评估Apple Intelligence的安全性,我们评估了基础模型以及在部署前使用模型的每个功能。对于基础模型,我们将内部和外部人类评估与自动分级相结合,并将我们的模型与外部模型进行了基准测试。我们构建了针对性的安全评估数据集,以评估基础模型在诸如汇总,问题避开和集思广益之类的任务上的性能,因为它适用于高风险和敏感内容。对于个人功能,我们设计了专注于面向用户的风险的数据集,以专门识别有害或意外的结果,并测试当应用于敏感的应用程序特定内容时质量问题可能引起的任何影响。例如,我们注意设计新的基础模型框架和支持资源,以帮助提高应用程序的生成AI安全性。该框架通过内置的安全护栏实施了基本的安全水平,以减轻有害模型的输入和输出。为了帮助应用程序设计师和开发人员合并为其应用程序量身定制的AI安全,我们创建了教育资源,例如新的生成AI人类界面指南对于负责的AI原则。
随着我们将自己的功能扩展到新语言,我们扩大了跨地区和文化的安全代表,我们继续进行改进,以说明用户的广泛文化和语言多样性。除了遵守当地法律和法规外,我们还利用了与内部和外部法律,语言和文化专家互动的高质量外部代表性数据源的组合,并审查了先前产品决策的先例,以确保我们的方法在上下文上是尊重和相关的。为了设计用于多语言使用的缓解步骤,我们从基础模型级别的多语言训练后对齐开始,然后扩展到集成安全对准数据的特定功能适配器。此外,我们扩展了旨在通过语言特定的培训数据拦截有害提示的护栏模型,同时维护多语言适配器。我们开发了定制的数据集,以减轻模型输出中特定文化的风险,偏见和刻板印象。Similarly, we extended our evaluation datasets across languages and locales with tools such as machine translation and targeted synthetic data generation, all refined by native speakers.Finally, we conducted human red teaming across features to identify risks unique to each locale.
We continuously monitor and proactively improve our features with the help of user feedback.In Image Playground, for example, users can provide feedback on generated images by tapping "thumbs up" or "thumbs down", with the option to add comments.App developers can similarly offer feedback through反馈助手。Feedback from users and developers, along with evaluation data and other metrics, helps us continuously improve Apple Intelligence features and models.
结论
We're excited to make the language foundation models at the core of Apple Intelligence more efficient and more capable, unlocking a wide range of helpful features integrated across our software platforms, and available to our users around the globe across many languages.We are also giving app developers direct access to our on-device language foundation model with a new Foundation Models framework.App developers can take advantage of AI inference that is free of cost and accessible with just a few lines of code, and bring capabilities such as text extraction and summarization to their apps with just a few lines of code.Our latest foundation models are built with our core values at every step, like our commitment to privacy, as well as our Responsible AI approach.We look forward to sharing more details on updates to our language foundation models in a future technical report.
Related readings and updates.
We present foundation language models developed to power Apple Intelligence features, including a ∼3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute.These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly.This report describes the model architecture, the data used to train the model, the training process, how the…
At the 2024全球开发人员会议, we introduced Apple Intelligence, a personal intelligence system integrated deeply into iOS 18, iPadOS 18, and macOS Sequoia.
Apple Intelligence is comprised of multiple highly-capable generative models that are specialized for our users’ everyday tasks, and can adapt on the fly for their current activity.The foundation models built into Apple Intelligence have been fine-tuned for user experiences such as writing and refining text, prioritizing and summarizing notifications, creating playful images for conversations with family and friends, and taking in-app actions to simplify interactions across apps.