

已重塑人们如何创建,想象和与数字内容互动。随着AI模型的能力和复杂性的增长,它们需要更多的VRAM或视频随机访问存储器。
例如,基本稳定扩散3.5大型模型使用超过18GB的VRAM限制可以很好地运行它的系统的数量。
通过将量化应用于模型,可以以较低的精度去除非关键层或运行。NVIDIA GEFORCE RTX 40系列NVIDIA RTX Pro GPU的ADA Lovelace生成支持FP8量化以帮助运行这些量化模型,以及最新的一代Nvidia BlackwellGPU还增加了对FP4的支持。
NVIDIA与稳定性AI合作,量化其最新模型稳定扩散(SD)3.5大,以将VRAM消耗量减少40%。NVIDIA TENSORRT软件开发套件(SDK)双重性能对SD3.5大型和媒介进行进一步优化。
此外,张力已将RTX AI PC的重新构想,将其行业领先的性能与即时(JIT),设备发动机构建和较小的无缝AI部署的包装尺寸相结合,与超过1亿个RTX AI PC相结合。RTX的Tensorrt现在可以作为一个独立SDK对于开发人员。
RTX加速AI
NVIDIA和稳定性AI正在提高性能并减少VRAM要求稳定的扩散3.5,世界上最受欢迎的AI图像模型之一。使用NVIDIA Tensorrt加速和量化,用户现在可以在NVIDIA RTX GPU上更快,更有效地生成和编辑图像。

为了解决SD3.5大型的VRAM限制,将模型用Tensorrt量化为FP8,将VRAM要求降低了40%至11GB。这意味着五个GEFORCE RTX 50系列GPU可以从内存中运行模型,而不仅仅是一个。
SD3.5大型和中型模型还通过Tensorrt进行了优化,Tensorrt是AI的后端,可充分利用张量芯。Tensorrt优化了模型的权重和图形 - 有关如何专门针对RTX GPU运行模型的指令。
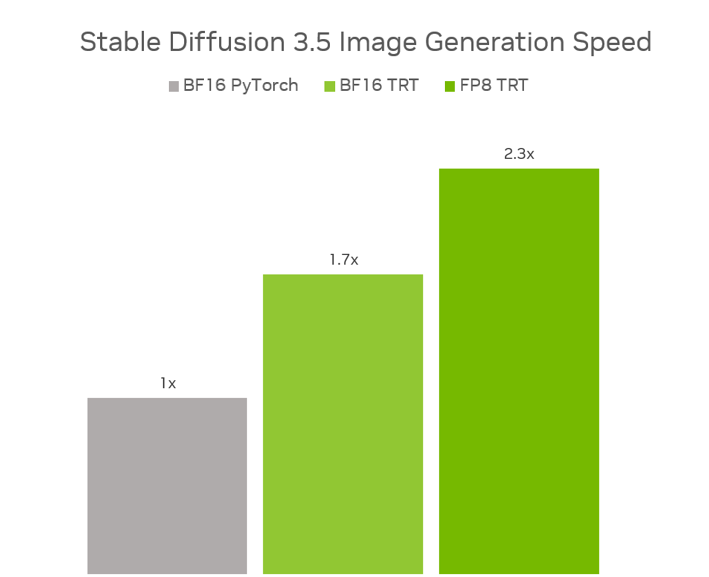
与在BF16 Pytorch中运行原始型号相比,FP8 Tensorrt在SD3.5上的2.3倍性能提升,同时使用40%的内存。在SD3.5培养基中,与BF16 Pytorch相比,BF16 Tensorrt的性能提高了1.7倍。
现在可以在稳定性的拥抱面页。
NVIDIA和稳定性AI也正在合作发布SD3.5作为NVIDIA NIM微服务,使创建者和开发人员更容易访问和部署各种应用程序的模型。NIM微服务预计将于7月发布。
RTX SDK发行的Tensorrt
在Microsoft Build宣布,并且已经作为新的Windows ML预览中的框架tensorrt for rtx现在可以作为开发人员独立的SDK提供。
以前,开发人员需要为每类GPU进行预生产和包装张力,该过程将产生GPU特定的优化,但需要大量时间。
借助新版本的Tensorrt,开发人员可以创建一个通用的Tensorrt引擎,该引擎在几秒钟内在设备上进行了优化。这种JIT汇编方法可以在安装过程中或初次使用该功能时在后台完成。
易于整合的SDK现在较小8倍,可以通过Windows Microsoft的Windows新的AI推理后端进行调用。开发人员可以从NVIDIA开发人员页面或在Windows ML预览中进行测试。
有关更多详细信息,请阅读此信息NVIDIA技术博客这Microsoft构建回顾。
加入GTC巴黎的NVIDIA
在NVIDIA GTC巴黎Vivatech欧洲最大的创业和技术活动 - NVIDIA创始人兼首席执行官Jensen Huang昨天在Cloud AI基础设施中的最新突破中发表了主题演讲,代理AI和物理AI。观看重播。
巴黎GTC将持续到6月12日(星期四),由行业领导者领导的动手演示和会议。无论是亲自参加还是在线加入在活动中有很多值得探索的地方。
每个星期,RTX AI车库 博客系列具有社区驱动的AI创新和内容,以了解有关NVIDIA NIM微服务和AI蓝图以及构建的人的更多信息人工智能代理,创意工作流程,数字人类,生产力应用程序等等,以及在AI PC和工作站上的更多信息。
插入NVIDIA AI PCFacebook,,,,Instagram,,,,蒂克托克和x并通过订阅RTX AI PC新闻通讯。
看注意关于软件产品信息。