


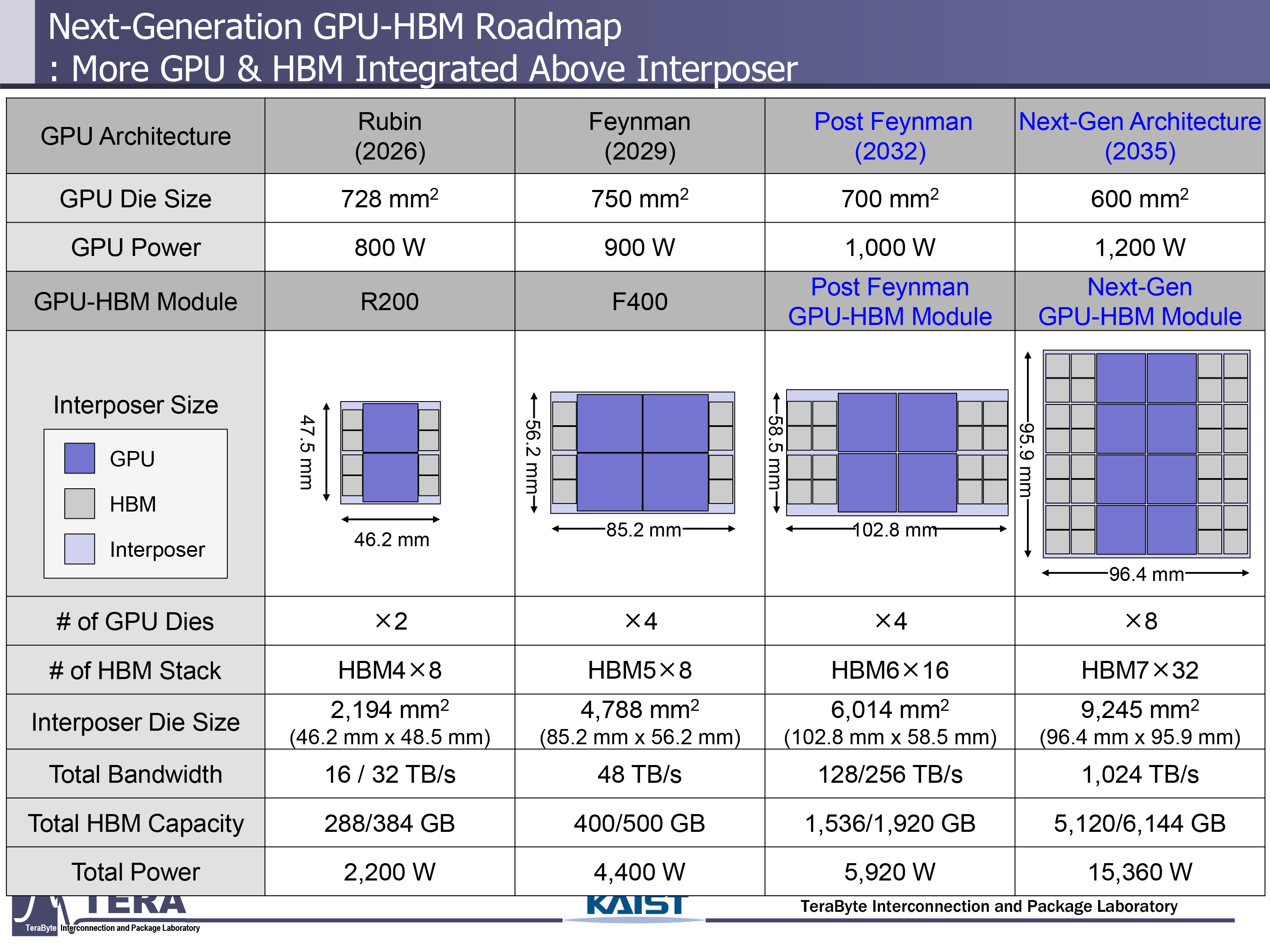
近年来,AI GPU的功耗已稳步增加,预计随着AI处理器融合了更多的计算机和HBM芯片,预计将继续上升。我们行业中的一些来源表明,NVIDIA的下一代GPU正在寻找6,000W至9,000W的热设计能力,但是来自领先的韩国研究所KAIST的专家认为,在未来10年中,AI GPU的TDP将一直提高到15,360W。结果,它们将需要相当极端的冷却方法,包括浸入冷却甚至嵌入式冷却。
直到最近,涉及铜散热器和高压风扇的高性能空气冷却系统足以使Nvidia的H100 AI处理器冷却。但是,随着NVIDIA的Blackwell将其热量耗散增加到1200W,然后Blackwell Ultra将其TDP提高到1,400W,液体冷却溶液几乎是强制性的。鲁宾(Rubin)的情况变得更热,鲁宾(Rubin)将其TDP增加到1,800W,而Rubin Ultra则将GPU chiplets和HBM模块的数量增加一倍,以及TDP将一直延伸到3,600W。来自凯斯特相信Nvidia及其合作伙伴将使用直接芯片(D2C)液体冷却使用鲁宾Ultra,但是对于Feynman,他们将不得不使用更强大的东西。
根据KAIST和行业来源的说法,AI GPU的预期散热
滑动以水平滚动
一代 | 年 | GPU包的总功率 | 冷却方法 |
布莱克韦尔超级 | 2025 | 1,400W | D2C |
鲁宾 | 2026 | 1,800W | D2C |
鲁宾Ultra | 2027 | 3,600W | D2C |
费曼 | 2028 | 4,400W | 浸入冷却 |
Feynman Ultra | 2029 | 6,000W* | 浸入冷却 |
邮政 | 2030 | 5,920W | 浸入冷却 |
近后超级超级 | 2031 | 9,000W* | 浸入冷却 |
? | 2032 | 15,360W | 嵌入式冷却 |
*行业来源
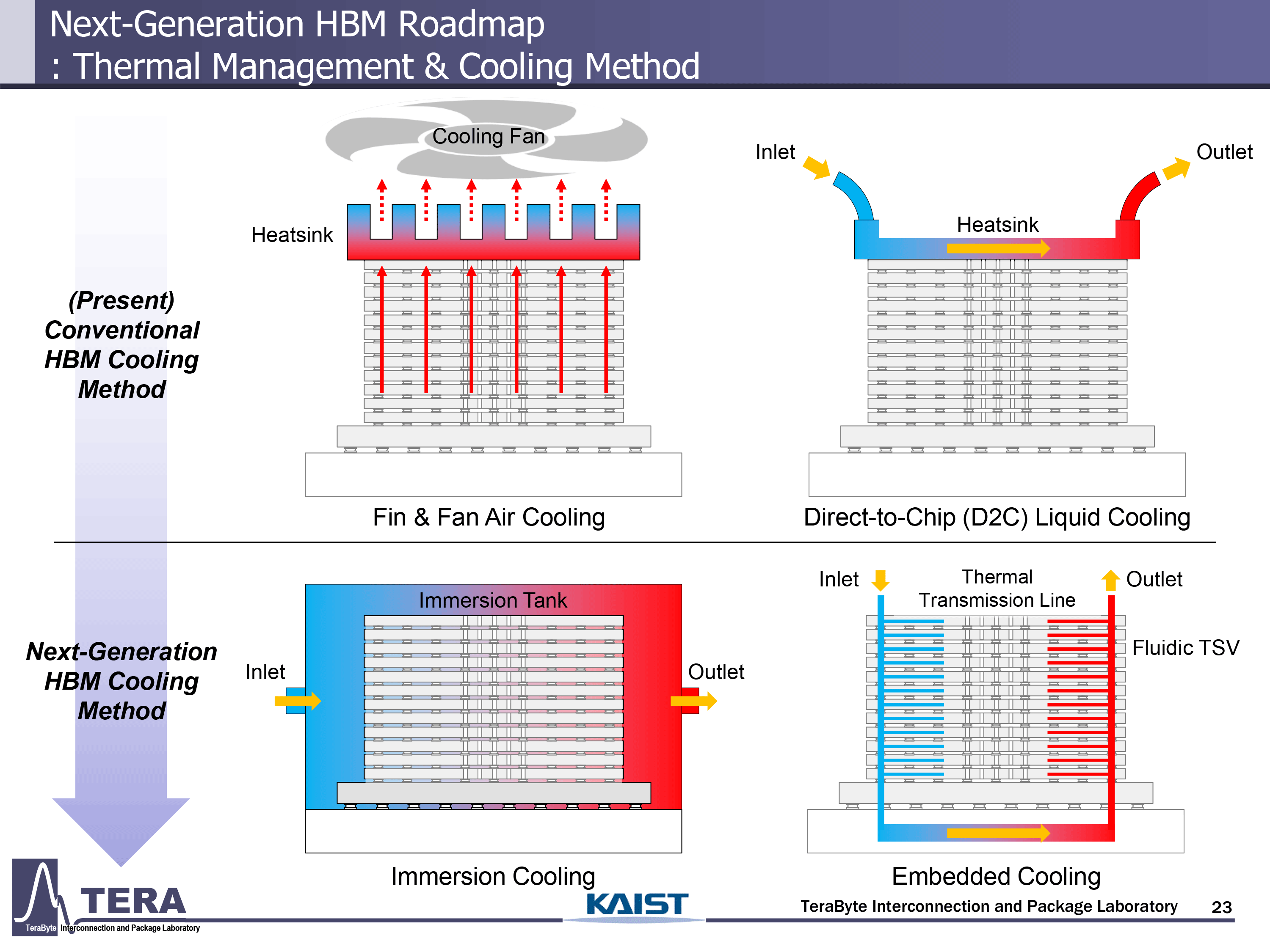
KAIST的研究人员预测,AI GPU模块(尤其是NVIDIA的Feynman)将消散4,400W,而该行业的其他一些来源则认为,NVIDIA的Feynman Ultra将将其TDP提高到6,000W。这样的极端热量将需要使用浸入冷却,其中整个GPU-HBM模块被浸入热流体中。此外,预计此类处理器及其HBM模块将通过热VIA(TTVS),用于热量耗散的硅底物中的垂直通道引入。这些将与HBM模块底座中嵌入的热键层和温度传感器配对,以实时监测和反馈控制。
浸入式冷却预计到2032年,当近距离的GPU架构将每包TDP增加到5,920W(后脑后)甚至9000W(近9000W)时(后 - 远高)。
图1 of 3

有必要注意的是,GPU模块中的主要消费者是计算芯片。但是,随着HBM堆栈的数量增加到16个,随着传染性后的数量,HBM6的每个堆栈功耗增加到120W,记忆的功耗大约为2,000W,大约是整个软件包的1/3。
来自Kaist的研究人员认为,到2035年,AI GPU的功耗将增加到15,360,这将要求嵌入式冷却结构用于计算和记忆chiplets。专家提到了两项关键创新:热传输线(TTL),它们从热点侧向移动热量到冷却界面,以及允许冷却液通过HBM堆栈垂直流动的流体TSV(F-TSV)。这些方法直接集成到插入器和硅中以维持热稳定性。
到2038年,完全集成的热溶液将变得更加广泛和先进。他们将使用双面插入器在两侧进行垂直堆叠,并嵌入流体冷却。此外,GPU-ON-TOP架构将有助于优先从计算层中去除热量,同时TSV有助于平衡信号完整性和热流量。
跟随汤姆在Google新闻上的硬件在您的提要中获取我们的最新新闻,分析和评论。确保单击“关注”按钮。