
在人工智能和深层神经网络下的女性歌剧中女性角色的歌唱风格
作者:Yang, Huixia
介绍
研究背景和动机
种族歌剧作为一种独特的艺术形式,深刻地反映了民族文化,语言和音乐的多样性。特别是,女性角色的歌唱风格通常包含复杂的情感表达和合理的特征。在民族歌剧中,女性角色不仅需要表现出微妙的情感转变,而且还具有丰富的人声技巧和艺术表现力。鉴于民族歌剧的音乐结构与西方歌剧和其他类型的中国歌剧有很大不同,因此女性角色的歌唱风格呈现出独特的技术和艺术特征1,,,,2,,,,3。但是,对歌唱风格的传统分析通常依赖于主观经验,缺乏系统的和客观的方法。在认识多样化和高度复杂的歌唱风格方面,这个问题变得更加具有挑战性4,,,,5,,,,6。
随着人工智能(AI)技术的快速发展,深度学习,尤其是深度神经网络(DNN),在音频分析和处理领域表现出巨大的潜力7,,,,8。近年来,诸如卷积神经网络(CNN)和经常性神经网络(RNN)等DNN模型在音乐风格分类和情感识别任务方面取得了重大成功9,,,,10。但是,尽管它们在分析西方音乐和流行歌曲中广泛应用,但这些技术在民族歌剧领域的有效应用仍然是尚未解决的挑战。这在分析女性角色的歌唱风格中尤其明显。该领域的研究不仅有助于推进音乐学和声乐研究的理论发展,而且还为歌剧表演者的培训提供了科学支持,从而提高了表演质量。因此,这项工作旨在探讨AI辅助DNN技术如何在女性在族裔歌剧中角色的唱歌风格的研究中发挥作用。
研究目标
这项工作的主要目的是开发一种基于AI技术的创新CNN-RNN模型,以帮助分析和认可女性在族裔歌剧中角色的歌唱风格。具体而言,这项工作旨在实现以下目标:(1)设计和实施混合模型,该模型集成了门控机制,残留连接和注意机制,以自动从音频信号中自动提取唱歌样式的多级特征;(2)利用双向复发性神经网络(BRNN)的时间学习能力进一步捕捉唱歌风格中的情感变化和节奏特征;(3)使用注意机制优化模型的特征学习过程,并将不同的权重分配给从不同时间段的音频数据,以更准确地确定歌唱风格的细微差异。这项工作旨在提供新的技术途径和理论基础,以系统地分析和数字表达女性在族裔歌剧中的作用。
文献综述
近年来,AI技术已在各个领域取得了突破性的进步。例如,Li等人。使用3185家上市公司的数据研究了AI对公司创新效率的影响。他们发现,AI显着提高了创新效率,尤其是在激烈的市场竞争和组织结构平坦的环境中11。Wang等。使用神经网络算法为文化和创意行业相关的企业家项目建立了建议和资源优化模型。他们的模型评估表明,随着训练期的增加,识别精度达到了81.64%。此外,当将矢量长度和隐藏特征的数量设置为200时,推荐系统的预测错误被最小化12。El Ardeliya等。探索了AI在生成艺术,音乐创作和设计中的应用。他们分析了AI如何推动创意领域的变革性变化,并强调了其在增强人类创造力方面的革命潜力13。
深度学习技术已经在音乐分类任务中表现出强大的功能提取和模式识别能力,从而逐渐成为该领域的主流方法。Prabhakar和Lee(2023)提出了五种新音乐类型分类方法。其中包括一个基于加权的视觉图弹性网稀疏分类器,堆叠的DeNoising自动编码器,Riemannian联盟转移学习,转移支持向量机算法以及结合两个网络的深度学习模型。他们发现,深度学习模型达到了最高分类的精度14。Faizan等。比较了长期短期内存(LSTM),CNN和CNN-LSTM模型的性能,并发现基于CNN的音乐类型分类系统表现最好15。Mehra等。引入了基于频谱图和歌词的多模式音乐表示方法。他们使用深度学习模型来编码歌曲并执行多元类别的分类实验。他们的研究表明,频谱图和歌词的简单线性组合在分类准确性方面均优于使用任何一个单独的一个。16。
尽管音乐分类取得了进展,但仍然存在一些缺点。许多模型未能完全合并时间信息和全球功能,从而导致分类性能有限。此外,注意机制的应用并不广泛,并且没有有效捕获关键的时间差异。为了解决这些问题,这项工作提出了一个基于残留门控卷积和BRNN的混合模型,并结合了一个注意机制,以提高歌唱样式分类的准确性。
研究模型
歌唱样式分类模型体系结构的概述
现有的音乐分类模型在处理复杂的频谱图和长期依赖性时通常会面临挑战。这些挑战包括对关键特征的捕获不足和有效过滤冗余信息的困难,这限制了其在民族歌剧歌剧歌剧风格的分类中的应用17。具体而言,传统的CNN可能会过度专注于功能提取过程中的详细功能,因此很难处理唱歌样式中的多层次依赖性。尽管RNN在处理时间依赖性方面具有一定的优势,但在捕获长期依赖性时,它易于消失的梯度问题,这限制了模型的性能。因此,为了解决这些问题,这项工作提出了一个引起注意的一维遗物门控卷积和双向RNN(ARGC-BRNN)模型。该模型将残留的封闭式线性单元与挤压和兴奋块(RGLU-SE)和BRNN相结合,并结合了一种注意机制,以有效提取和汇总歌唱样式的多级特征。
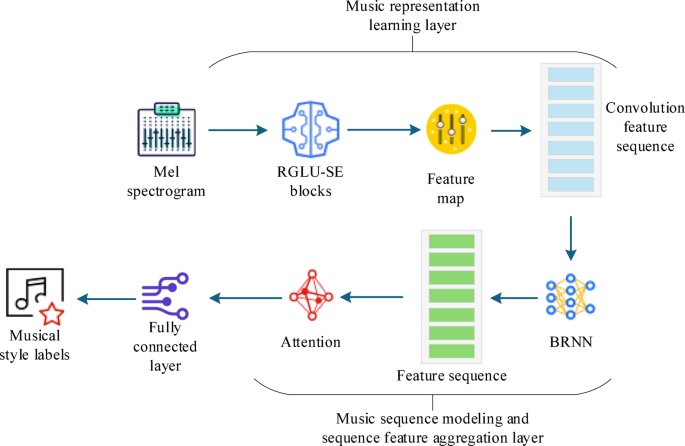
采用这种结构的原因是,一方面,残留的封闭式卷积单元可以有效地捕获多层次的本地特征,同时避免消失的梯度问题。在处理复杂的顺序数据时,这可以增强模型的性能。这项工作结合了挤压和兴奋(SE)模块,使网络可以自动关注重要的特征通道,从而进一步增强了特征提取过程。此外,BRNN可以通过输入数据的前进和向后传播在时间序列中对上下文信息进行建模,这对于捕获时间依赖时间的特征,例如在歌剧唱歌中的音调和节奏至关重要。当处理具有重要时间特征的音频数据时,BRNN的双向结构可以更全面地了解数据序列。注意机制动态着眼于输入数据的最相关部分,从而有效地改善了在全球特征聚合过程中的模型性能。在提出的模型中,注意机制有助于该模型更好地了解哪些音频段对于分类任务最重要,从而在分类准确性和训练效率方面具有显着优势。图 1说明其架构。

ARGC-BRNN模型结构的示意图。
在图 1,根据每个部分的功能和信息传输序列:音乐表示学习层,音乐序列建模和序列特征聚合层以及完全连接的分类层,将ARGC-BRNN模型分为三层。整个体系结构都是围绕中国国家歌剧中女性角色的人声风格的特征提取和序列建模要求设计的。它着重于靶向结构优化和残留门控卷积单元(RGLU)和BPNN的整合,以在复杂的光谱特征提取和时间依赖性建模中增强模型的性能。一方面,这项工作提出了RGLU-SE模块,该模块涉及对传统封闭卷积结构的多次改进。该模块集成了一维卷积,门控机制,残差连接,通道注意机制(SE)和最大池池操作,从而形成了具有很强能力的深层结构,可在提取局部频率特征和通道选择性方面具有很强的功能。一维卷积负责从音频信号中提取移位不变的局部频率特征,而门控机制则在功能级别动态抑制冗余信息,突出了关键的风格元素。在此基础上,引入了剩余连接,以增强网络的深层传播能力,并减轻训练过程中消失的梯度问题。此外,通过结合SE注意机制,该模型了解了不同通道之间的依赖性,并有选择地增强了与唱片风格相关的频段。这提高了模型感知不同样式特征之间细微差异的能力。最大池降低了尺寸,同时扩展了接受场,从而使模型在处理复杂的频谱图时更有效,稳健。
另一方面,在特征提取后,将所得的高维语义特征图展开为时间序列,并输入到BRNN中。与基于原始音频建模的传统方法不同,这项工作使用卷积注意提取的高级特征作为BRNN的输入,从而提高了时间建模的信息密度和表达效率。BRNN结构可以捕获历史和未来的上下文信息,使其适合于复杂的歌唱节奏和国家歌剧的情感变化。这项工作还集成了注意机制,以在BRNN输出上执行加权聚合。它允许该模型自动关注唱歌片段中最具代表性的时间节点,从而实现更精确且在全球的样式表示。最后,该全局功能向量传递到完全连接的层以完成分类任务。
总而言之,通过对残留门控卷积单元和BRNN的深层整合和结构优化,ARGC-BRNN模型增强了光谱信息提取的层次结构,时间依赖性建模的完整性以及整体样式分类的准确性。在处理国家歌剧的复杂音乐结构时,它克服了传统方法的富有表现力瓶颈,表现出良好的性能和应用潜力。
分析残留的门控卷积单位结构
在音乐分类任务中,RGLU-SE模块通过集成封闭式卷积单元,1D卷积,剩余连接,频道注意机制和最大池层层来解决梯度消失和网络退化的问题18。1D卷积有效地捕获了频率特征的翻译不变性,同时减少了计算负载。门控机制可确保仅保留与类别相关的信息,从而滤除无关的数据。剩余连接有助于减轻网络降低,并增强网络有选择地保留有意义功能的能力。SE结构实现了一种通道级的注意机制,该机制会自动学习跨不同通道的光谱特征的重要性。最大池层减少了特征图的大小,并在时域中扩展了卷积内核的接受场,从而有助于提取更深的特征。如图所示 2,RGLU-SE模块由两个残留的门控卷积单元,一个SE结构和最大池层组成。

RGLU-SE结构的示意图。
在图 2,残留的门控卷积单元的核心是封闭式线性单元(GLU)。GLU通过执行线性转换和非线性激活的点乘法来选择性地保留关键特征19,,,,20。输入频谱图序列设置为\(\:x = [{x} _ {1},{x} _ {2},\ cdots \:,{x} _ {n}] \)\),GLU的输出可以表示为:
$$ \:{y} _ {glu} = conv1 {d} _ {1} \ left(x \ right)\ odot \:\ sigma \:\ sigma \:\ left(conv1 {d} _ {2} _ {2} _ {2} \ thour
(1)
\(\:conv1 {d} _ {1} \)和\(\:conv1 {d} _ {2} \)代表两个不同的1D卷积操作,\(\:\ odot \:\)表示元素的乘法,并表示\(\:\ sigma \:\)是Sigmoid激活函数。在这种机制中\(\:conv1 {d} _ {1} \ left(x \ right)\)\)表示初始特征的线性转换,而\(\:\ sigma \:\ left(conv1 {d} _ {2} \ right(x \ left)\ right)\)\)\)通过Sigmoid函数对特征选择的重要性进行建模,从而有效地为每个特征通道添加了门控操作。该设计允许选择性保留与目标分类任务相关的重要信息,同时滤除无关或冗余信息。
随着DNN中的层数的增加,梯度消失或网络降解的问题变得更加突出。剩余网络的引入通过在每一层中合并身份映射来提供有效的解决方案,从而允许信息绕过某些卷积层并直接流向后续层。这可以防止特征在深网中过度转化或减弱21,,,,22。在RGLU-SE中,残留结构集成到封闭式卷积单元中。它的数学表达是:
$ \:y = x+conv1 {d} _ {1} \ left(x \ right)\ odot \:\ sigma \:\ left(conv1 {d} _ {2} _ {2} \ right(x \ weled(x \ weled)\ right)。$$
(2)
x表示输入功能,以及y表示最终输出功能。这种结构使原始输入特征可以直接参与随后的层的计算,同时利用卷积和门控机制提取更深的特征。在此框架内,网络的训练过程变得更加稳定,可以减轻反向传播过程中消失的梯度问题23。进一步的推导产量:
$ \:y = \ left(1- \ sigma \:\ right)\ cdot \:x+\ sigma \:\ cdot \:conv1 {d} _ {1} _ {1} \ left(x \ oyt)。$$
(3)
从上面的方程式来看,很明显,信息流有两种途径。一个是原始功能的直接传输x有可能\(\:1- \ sigma \:\),另一个是卷积和门控操作后特征的传输\(\:\ sigma \:\)。这种特征使网络可以灵活地跨多个通道传播信息,从而有效地增强了其特征表达能力。
就通道维度而言,不同的光谱特征对于分类任务的重要性程度不同。为了更好地在通道之间分配重量,RGLU-SE集成了SE模块。SE模块由两个部分组成:挤压和激发24。挤压操作通过全球平均池降低了维度,计算方程为:
$$ \:{w} _ {c} = \ frac {1} {h \ cdot \:w} \ sum \ \:_ {i = 1}^{h}^{h} \ sum \:_ {
(4)
h和w表示特征图的时间和频率维度,\(\:{x} _ {ijc} \)表示特定通道的特征值,并且\(\:{厕所}\)是频道的重量c。此过程从每个通道中提取重要的统计信息。
激发操作产生权重\(\:{s} _ {C} \)通过两个完全连接的层和激活功能(Relu和Sigmoid),然后使用这些权重重新校准原始通道特征。激发步骤的计算如下:
$$ \:{x^{\ prime \ \:}} _ {ijc} = {s} _ {c} _ {c} \ cdot \:{x} _ {ijc}。$$
(5)
这种通道级的动态注意力调整使RGLU-SE块可以根据不同音乐类型的特征来适应增强歧视性特征。为了进一步优化特征提取,RGLU-SE在其结构末端结合了最大池层。最大池层降低了特征地图大小。这不仅降低了模型的计算复杂性,而且间接扩大了卷积内核的接受场,从而有助于捕获整个时间维度的更深层次的模式25。
用BRNN建模时间依赖性
音乐信号是高度与时间有关的顺序数据。分类任务不仅依赖于各个时间点的功能,而且还需要考虑全球时间上下文以捕获更深的音乐模式26。为了更好地对音乐序列中的双向时间依赖性进行建模,这项工作采用了BRNN,并同时考虑了当前时间步骤的过去和将来功能,从而实现了音乐模式的全面建模。传统的RNN通过递归更新隐藏状态来捕获时间依赖性。数学表达是:
$$ \:{h} _ {t} = f({w} _ {h} {h} {h} _ {t-1}+{w} _ {x} {x} {x} _ {t}+{t}+{b} _ {b} _ {h} _ {h})
(6)
\(\:{w} _ {h} \)和\(\:{w} _ {x} \)分别表示隐藏状态和输入的重量矩阵。\(\:{b} _ {h} \)是偏见术语,\(\:f(\ cdot \:)\)是激活函数。但是,单向RNN只能捕获从过去到现在的依赖性,而未来时间步骤的信息对于理解音乐序列同样重要27。BRNN由两个经常性网络组成:一个向前和一个落后网络。在时间步骤t,向前和向后隐藏的状态由以下等式计算:$ \:\ oferrightArrow {{{h} _ {t}} = f({w} _ {h} \ oftrightArrow {{h} {h} _ {t-1}}}+{w}
(7)
$$ \:\ OverLeftarrow {{h} _ {t}}} = f({w^{\ prime \:}} _ {h} \ overleftarro
w {{h} _ {t-1}}}+{w^{\ prime \:}} _ {x} {x} {x} _ {t}+{b^{b^{\ prime \:}}} _ {h} _ {h})_ {h})
(8)
\(\:{w^{\ prime \:}} _ {h} \),,,,\(\:{w^{\ prime \:}} _ {x} \), 和\(\:{b^{\ prime \:}} _ {h} \)代表向后网络的重量矩阵和偏置项。向前和落后网络没有共享权重,使他们可以在不同方向上学习时间依赖性。最终输出是通过求和或串联获得的,产生BRNN输出\(\:{o} _ {t} \):$ \:{o} _ {t} = u \ oftrightArrow {{{h} _ {t}}}+u {\ prime \:} \ overleftarrow {{h} {
(9)
这里,
\(\:u \)和\(\:u^{\ prime \:} \)分别代表向前和向后隐藏状态的输出重量矩阵,并且\(\:{b} _ {o} \)是输出偏差项。为了将CNN提取的高级特征馈入BRNN,设计了一种特征序列构造方法。
卷积层生成的特征地图已经通过卷积内核的滑动来处理时间维度,并在不同时间点捕获特征响应。在构造输入序列时,特征映射的每一列被视为一个时间步的输入。每列包含该特定时间点所有内核的卷积结果。设置的卷积特征图的维度为\(\:c \ times \:w \ times \:h \)。c是卷积内核的数量,并且w和h分别表示沿时间轴和频率轴的大小。图 3说明了特征序列构造的步骤。

卷积特征序列的施工过程。
在图 3,首先按时间顺序按列扫描卷量图。然后,c每列中的卷积内核被串联成特征向量,该特征向量表示该时间步的输入。在此过程之后,特征映射转换为长度的时间序列w。每个时间步骤的输入维度是c。此输入格式与BRNN的建模要求更加一致,从而有效利用卷积层捕获的局部特征,同时进一步学习序列内的时间依赖性。
注意机制的整合
BRNN对音乐功能序列进行建模之后,每个时间步骤生成的功能描述了不同时间点音乐的深度特征。注意机制将权重分配给每个时间步骤,并动态调整从不同时间步骤到分类任务的功能的贡献28,,,,29,,,,30。BRNN的输出特征序列表示为\(\:x = [{x} _ {1},{x} _ {2},\ cdots \:,{x} _ {l}] \)\), 在哪里l是时间步骤的数量,以及\(\:{x} _ {t} \ in \:{\ mathbb {r}}}^{d} \)是每个时间步骤的特征向量。注意力重量的计算方程\(\:{在}\)是:
$$ \:{a} _ {t} = softmax \ left({w} _ {2} \ phi \:\ right({w} _ {1} _ {1} {x} _ {t} _ {t} \ left)\ left)\ right)
(10)
\(\:{W} _ {1} \)和\(\:{w} _ {2} \)是学习的重量矩阵,\(\:\ phi \:(\ cdot \:)\)\)代表tanh激活函数。SoftMax功能确保重量的归一化\(\:{在}\),使得所有时间步骤的权重总和等于1:
$$ \:\ sum \:_ {t = 1}^{l} {a} _ {t} =1。$$
(11)
获得注意力矢量后\(\:a = [{a} _ {1},{a} _ {2},\ cdots \:,{a} _ {l}] \)\),通过加权总和汇总了所有时间步骤的功能,以获得全局特征表示:
$$ \:v = \ sum \:_ {t = 1}^{l} {a} _ {t} {x} {x} _ {t} =ax。$$
(12)
\(\:v \ in \:{\ mathbb {r}}}^{d} \)是汇总的全局特征向量,它动态地表示序列中的重要信息。
汇总的全球功能v然后将其馈入完全连接的层。通过线性转换和激活功能进行进一步的集成和选择,为分类任务生成高级特征表示。注意机制通过动态重量调节来完善聚合过程,从而实现了判别全局特征的建模。
实验设计和性能评估
数据集集合
这项工作使用两个数据集进行了实验:公开可用的Magnatagatune数据集和一个自行构建的数据集,即自行构建的民族歌剧女性角色唱歌摘录数据集(SEOFRS)。Magnatagatune数据集是一个广泛使用的公共数据集,用于音乐分类和标记预测研究。它包含25,000多个音乐剪辑,每个剪辑长29张,并带有各种标签,例如情感,乐器和流派信息。所有音频文件均已处理为单声道格式,并以16 kHz的采样率重新采样。当转换为MEL频谱图时,傅立叶变换的窗口长度设置为512。它的滑动窗口步长为256和128个频率箱,导致最终的MEL频谱图的大小为(1813,128)。
SEOFRS数据集专注于中国传统歌剧,并包括由多位女歌手进行的人声段,涵盖了各种角色类型和情感表达。所有音频样本都遵循以下标准:首先选择了高质量的,未压缩的音频,以确保可以清楚地识别声乐功能。此外,从一系列传统的歌剧角色类型中选择了性能剪辑,从而捕获了各种情感表达和唱歌技巧。这样可以确保数据集的多样性和代表性,并具有平衡的样本,以避免任何单一类别的代表过多。在数据预处理过程中,所有音频文件首先转换为单声道格式并标准化为16 kHz采样率,以确保音频数据频率范围的一致性,从而增强了随后功能提取的稳定性和有效性。
接下来,将音频段分为固定的时间间隔,每个段的持续时间为5。选择此持续时间考虑了种族歌剧演唱的特征,因为它捕获了足够的声音差异,同时确保数据集的可操作性和训练效率。剪切后,所有音频样本都将进一步处理成MEL频谱图,这些谱图是输入深度学习模型的功能。MEL频谱图的产生使用常见的音频信号处理方法,包括傅立叶变换和MEL滤波器库的应用。在此过程中,窗口长度设置为512,窗口滑动步骤为256,频率箱计数为128。生成的MEL频谱图的尺寸为(313和128),满足处理顺序音频数据的共同要求。MEL被选为主要输入功能,因为它在音乐和声音分析领域的强烈感知相关性和计算效率。在初步实验中,除了MEL频谱图外,还探索并比较了其他常用的音频特征,例如MEL频率Cepstral系数(MFCC)和色度特征。实验结果表明,在处理族裔歌剧中女性角色的情绪表情和人声技术时,MEL频谱图可以更好地捕获微妙的频率变化。它表现优于其他功能,尤其是在情感和音色识别方面。桌子 1介绍了使用MEL频谱,MFCC和Chroma特征获得的实验结果:表1不同音频特征结果的比较。
表明MEL频谱图在Magnatagatune数据集上达到了0.912的AUC,并且在SEOFRS数据集上的精度为0.872,这两者都高于MFCC和Chroma特征的AUC。这表明MEL频谱图可以更好地提取并表示语音的关键特征。尤其是在认识到女性角色在族裔歌剧中的音色和情感变化时,其表演更加出色。因此,MEL频谱图最终被选为本研究的主要输入特征。The Mel scale is constructed based on the human auditory system’s sensitivity to different frequency bands, making it more aligned with how the human ear perceives sound during actual listening.This makes it particularly suitable for capturing variations in pitch, timbre, and intensity throughout the singing process.In the context of female vocal styles in traditional opera, emotional expression and vocal techniques are often accompanied by subtle and complex frequency changes.The Mel spectrogram can effectively capture key frequency-band information within these changes, thus providing more discriminative input features for subsequent style classification tasks.
To ensure the reliability and generalization of the data, all audio samples undergo strict quality control after splitting and processing.All audio segments are manually reviewed to ensure they are free from background noise, recording distortion, or other non-compliant issues.In the final construction phase of the dataset, all audio samples are divided into training, validation, and test sets with a ratio of 8:1:1.Additionally, to enhance the model’s generalization ability, the data are repeatedly split 10 times to perform ten-fold cross-validation.This approach not only ensures the balance of categories in the dataset but also helps the model better cope with potential overfitting issues during training.
Experimental environment and parameters setting
Tables 2和3shows the experimental environment and parameter settings for this work.
In this experiment, the selection of hyperparameters is determined through extensive tuning and aligns with best practices documented in current deep learning optimization literature.A small-scale grid search is conducted to determine the optimal values, focusing primarily on key hyperparameters such as hidden layer size, learning rate, and batch size.The work tests hidden layer sizes of [64, 128, 256], learning rates in the range of [0.001, 0.01, 0.1], and batch sizes of [32, 64, 128], exploring different combinations.Through this grid search process, the optimal configuration for each model is identified.The goal in selecting these parameters is to maximize model performance while ensuring efficient use of computational resources.For the convolutional layer configuration, 1D convolution is used, which proves highly effective for processing one-dimensional time-series data.The number of convolution kernels is set to 64 and 128. This is an optimal setting determined through experimentation, aiming to balance feature extraction capability with computational efficiency.A kernel size of 3 × 1 is chosen to effectively capture local frequency characteristics while maintaining low computational complexity.The convolution stride is set to 1 to ensure accurate feature extraction at each time step.In terms of the gating mechanism, the RGLU is employed, integrating a gating structure with a SE module.The gating mechanism enables the network to selectively retain important features and suppress redundant information, while the SE module dynamically adjusts channel-wise feature weights to enhance the model’s performance across different feature dimensions.ReLU is chosen as the activation function for the gating unit to enhance the model’s nonlinear representation capabilities.
The BRNN is configured with two layers and 128 hidden neurons.This is an optimal setup derived from repeated experiments, allowing the model to effectively capture the temporal dependencies in vocal performance styles.Tanh is used as the activation function for each layer and it can smoothly handle long-term dependencies in sequential data.The design of the fully connected layers takes into account the need for feature fusion.The first layer is set to 200 neurons and the second to 100 neurons.The number of neurons is progressively reduced to prevent overfitting while maintaining computational efficiency.To further mitigate overfitting, a dropout rate of 0.2 is applied, which is an optimal value verified through repeated experiments.The optimizer used is Adam, a widely adopted adaptive optimization algorithm that effectively improves model convergence speed.The batch size is set to 16, a choice that balances computational resource constraints with convergence speed during training.The selection and adjustment of these parameters rely primarily on experimentation and cross-validation, ensuring the model achieves optimal performance across different configurations while avoiding overfitting and enhancing computational efficiency.
The classification accuracy (Acc) and Area Under Curve (AUC) are selected as the evaluation metrics for the proposed music performance style classification method.The classification accuracy is calculated as follows:
$$\:Acc=\frac{{N}_{0}}{N}\times\:100\%.$$
(13)
nrepresents the total number of audio samples in the test set, and\(\:{N}_{0}\)denotes the number of audio samples correctly classified by the classifier.Since the MagnaTagATune dataset is a multi-label classification dataset, Recall@k is also used as an evaluation metric to more comprehensively evaluate the model’s performance,.The calculation is as follows:
$$\:Recall@k=\frac{|Y\cap\:{R}_{1:k}|}{\left|Y\right|}.$$
(14)
这里,yrepresents the actual label set of the test samples, and\(\:{R}_{1:k}\)denotes the set of the topklabels sorted by the predicted probabilities from the model, in descending order.
Performance evaluation
-
(1)
Impact of structure on model performance
First, the effectiveness of the RGLU-SE module is verified.The convolutional network part of the model is replaced with other forms of convolutional modules, while keeping the rest of the architecture unchanged.The convolutional modules include CNN, GLU, CNN with residual structure (Residual CNN, RCNN), and GLU with residual structure (Residual GLU, RGLU).The BRNN memory unit type is selected as LSTM.Experiments are conducted on both datasets.Figure 4shows the results.

Performance comparison of different convolutional structures on datasets.
数字4shows that the RGLU-SE module achieves significant performance improvements over other convolutional structures on both datasets.On the SEOFRS dataset, RGLU-SE achieves an accuracy of 0.872, outperforming CNN, GLU, RCNN, and RGLU by 2.5%, 1.7%, 1.3%, and 1.1%, respectively.On the MagnaTagATune dataset, RGLU-SE achieves an AUC of 0.912, which is an improvement of 1.5%, 1.3%, 1.4%, and 0.5% over CNN, GLU, RCNN, and RGLU, respectively.This demonstrates that the RGLU-SE module has strong generalization capability and is more effective than other convolutional structures in extracting music features.This performance improvement is mainly attributed to the design of the residual gated convolutional units in the RGLU-SE module.It allows the model to more effectively filter out irrelevant information while the channel attention mechanism enhances its focus on key features.As a result, the model’s ability to represent complex musical data and its classification accuracy are significantly improved.The strength of this module enables the proposed model to better capture the multi-level features of female vocal styles in ethnic opera, ultimately leading to superior classification performance.
Next, the impact of the RNN structure on the performance of the ARGC-BRNN model is compared.The performance of models with one and two layers of Gated Recurrent Unit (GRU), LSTM, Bidirectional GRU (BGRU), and Bidirectional LSTM (BLSTM) is compared on the two datasets.Figure 5displays the results.

Performance comparison of different RNN structures on datasets.
数字5reveals that different RNN structures have varying impacts on the performance of the ARGC-BRNN model.On the SEOFRS dataset, a 1-layer BLSTM structure achieves the highest accuracy of 0.872.On the MagnaTagATune dataset, BLSTM also demonstrates the best performance, with an AUC of 0.912.Overall, BRNN (BGRU and BLSTM) have certain advantages in capturing sequence context information, especially in more complex datasets, where BLSTM performs particularly well.This phenomenon suggests that BLSTM can better model long-range dependencies in the sequence by processing information in both the forward and backward directions of the sequence.Especially in complex singing style sequences, BLSTM is able to capture more contextual information, which leads to superior performance in classification tasks.Compared to traditional unidirectional RNN structures, BLSTM has a stronger contextual modeling capability, enabling the model proposed to achieve better results when handling the singing styles of female roles in ethnic opera.
-
(2)
Comparison of ARGC-BRNN with other models
On the two datasets, the performance of the Timbre CNN, End-to-end, Convolutional RNN (CRNN), CRNN with Temporal Features (CRNN-TF), RGLU-SE, as well as the models in references16和31is compared with that of the proposed ARGC-BRNN model.The Timbre CNN is a timbre recognition model based on the CNN, focusing on the extraction of local patterns in the audio.The End-to-end is a model that directly inputs the audio signal into a deep neural network for end-to-end training.The CRNN is a method that combines the CNN and the RNN, enabling the extraction of both local and time series features.The CRNN-TF enhances the ability to model temporal features on the basis of the CRNN.The RGLU-SE is a model that combines the residual gated linear unit with the Squeeze-and-Excitation mechanism to improve the multi-level feature extraction ability.The model in reference16uses a multi-modal spectrogram-lyric embedding method, combining deep visual and language models to achieve music style classification, emphasizing the joint representation of audio and lyrics.The model in reference31is a model based on functional data analysis, using the latent representation of the original audio to classify the style of traditional Irish music, emphasizing the capture of cultural and structural features.Table 4presents the results.
To provide a more intuitive comparison of the performance of each model, Fig. 6is drawn based on Table 4。

Comparison of performance results across different models.
Table 4;Fig. 6show that on the MagnaTagATune dataset, the ARGC-BRNN model achieves an AUC of 0.912 and performs excellently in Recall@k, demonstrating its strong global feature recognition ability.Compared to Timbre CNN, End-to-End, CRNN, CRNN-TF, and RGLU-SE, the AUC of ARGC-BRNN is improved by 2.13%, 3.52%, 2.13%, 0.44%, and 1.45%, respectively.On the SEOFRS dataset, ARGC-BRNN achieves an accuracy of 0.872, which is at least 0.46% higher than the other models, indicating its good classification ability on this dataset.All the results are better than those in reference16(SEOFRS accuracy is 0.861, AUC on MagnaTagATune is 0.905) and reference31(SEOFRS accuracy is 0.830, AUC on MagnaTagATune is 0.887).Overall, ARGC-BRNN performs exceptionally well on both datasets, proving its superiority in the music performance style classification task.These relatively small improvements still hold significant value in practical applications.First, these enhancements demonstrate that ARGC-BRNN can more accurately capture and recognize multi-level features in complex music singing style classification tasks.In particular, when the dataset has higher diversity and complexity, the model’s classification capability is improved.Second, the impact of these small improvements in real-world applications should not be overlooked.In environments with high-dimensional features and significant noise, even slight performance boosts can effectively improve the model’s robustness and stability, ensuring more reliable classification results.Therefore, these results suggest that ARGC-BRNN holds considerable practical value and application potential for the automated analysis of music singing styles.
Additionally, Fig. 7shows a comparison of accuracy, recall, and F1 score results for each model on the SEOFRS dataset.

Accuracy comparison of different models on the SEOFRS dataset.
数字7suggests that the ARGC-BRNN model performs exceptionally well across all metrics on the SEOFRS dataset.It achieves accuracy, recall, and F1 scores of 0.874, 0.869, and 0.871, respectively, all surpassing the other comparative models.This indicates that ARGC-BRNN effectively balances accuracy and recall in classification tasks, particularly in the classification of ethnic opera female character singing styles, demonstrating strong discrimination ability.The superior performance can be primarily attributed to the ARGC-BRNN model’s ability to better extract and model singing style features through the combination of the RGLU-SE module and BRNN structure.First, the RGLU-SE module enhances feature extraction efficiency and robustness through the integration of residual gated convolution units and channel attention mechanisms, effectively capturing subtle differences in singing styles.Additionally, the BRNN structure (particularly the BLSTM) is capable of capturing temporal information from both forward and backward directions.This enables the model to have stronger contextual modeling capabilities when processing complex musical data, especially in handling long-range dependencies.
As a result, ARGC-BRNN can effectively balance accuracy and recall.This ensures the model’s high discrimination between different styles while also avoiding the loss of sensitivity to minority class samples due to overfitting.This makes the model excel in classification tasks.These design choices provide significant advantages in classifying the singing styles of female roles in ethnic opera.Figure 8shows the confusion matrix for the ARGC-BRNN model on different emotional singing styles in the SEOFRS dataset.

Confusion matrix on the SEOFRS dataset.
From the confusion matrix in Fig. 8, it can be observed that the ARGC-BRNN model performs well in recognizing different emotional singing styles.For the five emotions, “Calm,†“Joy,†“Anger,†“Sadness,†and “Excited,†the model is able to accurately predict the correct emotion most of the time.However, some misclassifications still occur.For example, 8% of “Calm†samples are misclassified as “Joy,†and 10% of “Joy†samples are misclassified as “Calm.†These misclassification rates are relatively low, indicating that the model has a strong ability to differentiate between emotions, but there is still some confusion when classifying similar emotions.Finally, a comparison of the model parameters and training time for CRNN, CRNN-TF, and ARGC-BRNN on the MagnaTagATune dataset is made.The results can be attributed to the ARGC-BRNN model’s exceptional ability in emotion feature extraction and modeling.First, the model incorporates the RGLU-SE module, which effectively enhances the extraction of emotional features through gating and attention mechanisms, allowing it to highlight the prominent emotional characteristics.Additionally, the BRNN structure, particularly the BLSTM, captures bidirectional information in the time series, which is crucial for classifying emotional singing styles, as emotions often exhibit temporal dependencies.While the model can distinguish most emotions, occasional misclassification occurs when emotional features are closely similar, which remains a common challenge in emotion classification tasks.The parameters and training time of CRNN, CRNN-TF and ARGC-BRNN on MagnaTagATune dataset are compared.Figure 9shows the results.

Comparison of different model parameters and training time.
数字9demonstrates that the CRNN model has the smallest number of parameters, totaling 390,000, with a training time of 5.1 h.The CRNN-TF model has a larger parameter count, reaching 1 million, with a training time of 5.8 h.In contrast, the ARGC-BRNN model has the largest number of parameters, totaling 4.74 million, but its training time is only 3.6 h.Although the number of parameters in the ARGC-BRNN model is significantly higher than that of CRNN and CRNN-TF, its training time is considerably shorter due to the use of a 1D convolutional structure.This is mainly attributed to the design of the gated convolutional structure.Compared to traditional CNN, the ARGC-BRNN model introduces gating mechanisms and residual connections, which effectively enhance the computational efficiency of the convolutional layers and reduce unnecessary computation.As a result, while maintaining high model performance, the training time is optimized.Therefore, despite the larger number of model parameters, the design of the gated convolution significantly shortens the training time, and demonstrates the model’s advantage in computational efficiency.This design allows the ARGC-BRNN to maintain relatively low training time costs while achieving high performance levels when handling complex tasks.
-
(3)
Ablation experiment and results
To validate the contribution of each key module in the ARGC-BRNN model to the overall performance, a series of systematic ablation experiments are conducted.This work progressively trims the model structure to assess the practical impact of different modules on the vocal style classification task.The experiments are primarily based on the custom-built dataset of ethnic opera female character vocal segments, and the evaluation metrics were accuracy and AUC value.
The following model variants are constructed for comparison: Baseline-CNN: Uses a traditional 1D convolutional network without gating, residual, or attention mechanisms.Residual: Removes the residual connection from the RGLU module.Gate: Removes the gating mechanism from the RGLU module.SE: Removes the Squeeze-and-Excitation channel attention mechanism from the RGLU module.BRNN: Removes the BRNN structure, keeping only the convolutional features.Attention: Removes the final attention-based feature aggregation module.ARGC-BRNN (Full Model): Retains all modules as a performance upper bound reference.Table 5shows the results of the ablation experiments.
As shown in Table 5, the complete ARGC-BRNN model achieves optimal performance in both accuracy and AUC, with values of 0.872 and 0.912, respectively, demonstrating the synergistic advantages of all the modules.In contrast, models with key modules removed show varying degrees of decline in accuracy and AUC, proving the critical importance of these modules for overall performance.After removing the residual connection, the model’s accuracy decreases by about 0.29%, and the AUC drops by 0.026.The residual connection plays a vital role in alleviating the vanishing gradient problem and feature degradation in deep networks, facilitating effective information propagation and further feature extraction.Without the residual connection, the network struggles to consistently pass low-level information, leading to a reduction in feature representation capability, which negatively impacts the model’s classification performance.After removing the gating mechanism, the accuracy drops by about 0.33%, and the AUC decreases by 0.030.The gating mechanism dynamically adjusts the information flow, helping the network filter out irrelevant or redundant features.In complex acoustic environments, especially in ethnic opera with its varying timbres and complex vocal techniques, the gating mechanism helps emphasize crucial information.Its removal weakens the network’s ability to selectively process information, reducing the model’s accuracy.
After removing the SE module, the model’s accuracy drops by about 0.27%, and the AUC decreases by 0.025.The SE module models the inter-channel dependencies and dynamically adjusts the importance of each channel, thereby enhancing focus on key frequency bands.In ethnic opera, subtle differences in timbre and pitch often define the vocal style, and the removal of the SE mechanism reduces the model’s ability to capture these crucial features, affecting the final classification performance.After removing the BRNN structure, the accuracy decreases by 0.52%, and the AUC drops by 0.020.The BRNN structure is crucial for modeling both past and future temporal dependencies, which is essential for capturing the complex emotional expressions and rhythmic structures in ethnic opera.Features such as tonal shifts, pitch variations, and emotional fluctuations rely on contextual information processing.Therefore, removing the BRNN structure causes the model to lose its ability to model long-term dependencies in the time series, which subsequently impacts recognition accuracy.
After removing the attention mechanism, the model’s accuracy drops by 0.43%, and the AUC decreases by 0.018.The attention mechanism improves classification accuracy by focusing on the features of key time steps in the sequence, especially when dealing with complex inputs that contain noise or redundant information.It helps the model effectively concentrate on important regions of the input.Without this mechanism, the model distributes processing resources evenly across the time sequence, leading to the loss of critical information and thus reducing classification performance.In comparison to the basic CNN model, which achieves an accuracy of only 0.832 and an AUC of 0.873, significantly lower than the other variants, this further demonstrates the necessity and effectiveness of each module proposed.Through these ablation experiments, this work has validated the significant advantages of the RGLU-SE module, BRNN structure, and attention mechanism in feature extraction, temporal dependency modeling, and global feature aggregation.The effective combination of these modules has significantly improved the model’s performance and robustness, particularly in handling complex audio data such as ethnic opera, allowing it to better capture the subtle differences in vocal styles.
-
(4)
Statistical analysis and results
To validate the stability and significant performance improvement of the proposed model, multiple trainings are conducted under different experimental settings, and the model’s performance is recorded across various metrics.Each model undergoes five independent trainings, and the average and standard deviation of the results are calculated.To further ensure the significance of the results, statistical methods such as t-tests are used to determine whether the performance differences between the models are statistically significant.Table 6presents the average values and standard deviations for each experiment, and also provides the upper and lower bounds of the 95% confidence interval to further confirm whether the results are statistically meaningful.
Table 6suggests that on both datasets (SEOFRS and MagnaTagATune), the RGLU-SE and ARGC-BRNN models demonstrate superior performance in terms of accuracy and AUC values compared to other models, and the differences are statistically significant.Specifically, on the SEOFRS dataset, the accuracy of RGLU-SE reaches 87.2%, which shows a clear advantage over other models such as CNN and RCNN.Similarly, on the MagnaTagATune dataset, RGLU-SE achieves an AUC of 91.2%, improving by 1.5% and 1.3% compared to CNN and GLU, respectively.Moreover, the relatively low standard deviations indicate that the RGLU-SE and ARGC-BRNN models exhibit high consistency across multiple experiments.This also demonstrates the stability of the models across different runs, as their performance remains excellent even with different random initializations and training data splits.
The low standard deviation further enhances the reliability of the results, indicating that the performance improvements obtained are stable and reproducible.Statistical significance tests (such as t-tests) further validate the effectiveness of the results.On both the SEOFRS and MagnaTagATune datasets, the performance differences between RGLU-SE and ARGC-BRNN and other models exceed the standard error, with p-values smaller than 0.05, meaning that these differences are statistically significant.Therefore, the RGLU-SE and ARGC-BRNN models not only outperform traditional models in terms of performance but also demonstrate better stability and reliability.
-
(5)
案例分析
In order to evaluate the performance of ARGC-BRNN model more comprehensively and deeply understand its advantages and disadvantages, several typical samples in SEOFRS dataset are analyzed.Table 7lists the outstanding samples and misjudged samples of some models, and analyzes their causes.
In this study, the MSA-Class model demonstrated exceptional multimodal fusion capabilities, particularly in teacher emotion recognition and classroom behavior assessment, significantly outperforming traditional models such as RF and SVM.This finding is consistent with previous research.Wang等。(2024) showed that multimodal fusion models could effectively enhance the accuracy of sentiment analysis and behavior prediction16。Compared with single-modality research results, the multimodal fusion strategy proposed here is evidently more adaptable to the dynamic classroom environment.The model’s superior performance in multiple regression metrics such as MSE, MAE, and correlation reflects the in-depth mining and expressive power of multimodal information in teaching assessment.In classification metrics, the MSA-Class model also outperformed comparison methods.The significant increase in accuracy indicates that the model has unique advantages in fine-grained teaching behavior recognition and emotion state classification.This is in line with the multimodal analysis method proposed by Ezzameli and Mahersia (2023), who also found that multimodal models could better capture the subtle connections between emotions and behaviors.Especially in scenarios with significant emotional fluctuations, the model’s sensitivity and accuracy are enhanced31。The results of the ablation experiments also provided in-depth insights into the model.When the text modality was removed, the model’s performance dropped significantly, verifying the core role of linguistic information in classroom assessment.This result is consistent with Zhao et al.(2023)’s research on emotions and language expression, who pointed out that the language modality was crucial for emotion judgment.The absence of visual and audio modalities also led to varying degrees of performance degradation, further emphasizing the synergistic effect of multimodal information.These findings not only validate the importance of multimodal fusion in teacher emotion and behavior assessment but also provide new ideas and methods for future educational data analysis.
讨论
The ARGC-BRNN model proposed effectively improves the accuracy and generalization ability of ethnic opera female role singing style classification by incorporating RGLU-SE, BRNN, and the attention mechanism.Similarly, Ashraf et al.proposed a hybrid architecture combining CNN and RNN for music genre classification.Through a comparison of the Mel spectrogram and Mel-frequency cepstral coefficient features, experiments demonstrated that the CNN and Bi-GRU hybrid architecture using Mel spectrograms achieved the best accuracy of 89.30%32。KoÅŸar and Barshan proposed a new hybrid network architecture combining LSTM and 2D CNN branches.They used wearable motion sensors and deep learning techniques to recognize human activities, and their model outperformed other common network models, achieving an accuracy improvement of 2.45% and 3.18% on two datasets, respectively33。Jena et al.proposed a deep learning-based hybrid model combining multimodal and transfer learning methods for music genre classification.The results showed that this hybrid model outperformed traditional deep learning models and other existing models in terms of training and validation accuracy, loss, precision, recall, and other metrics34。In summary, these studies demonstrate the effectiveness of hybrid networks in feature extraction.Overall, the ARGC-BRNN model shows significant advantages in the application of ethnic opera female role singing style classification, providing new insights for music genre classification and singing feature analysis.
结论
Research contribution
This work focuses on ethnic opera female role singing excerpts as the research object and constructs the ARGC-BRNN model based on residual gated convolution, BRNN, and attention mechanisms.It explores the model architecture design, module performance analysis, and comparisons with other models, drawing the following conclusions: (1) On the SEOFRS dataset, the RGLU-SE module achieves an accuracy of 0.872, which improves by 2.5%, 1.7%, 1.3%, and 1.1% compared to CNN, GLU, RCNN, and RGLU, respectively.On the MagnaTagATune dataset, RGLU-SE achieves an AUC of 0.912, surpassing other convolutional structures, indicating its advantage in feature extraction.(2) The BLSTM structure achieves the highest accuracy of 0.872 on the SEOFRS dataset and an AUC of 0.912 on the MagnaTagATune dataset.It outperforms GRU and LSTM, demonstrating that BRNN is better at capturing sequential contextual information, particularly in complex datasets.(3) The ARGC-BRNN model performs the best on both datasets, achieving the highest AUC and accuracy, surpassing other models.Despite having the largest number of parameters, it exhibits the shortest training time, demonstrating high computational efficiency.In summary, the ARGC-BRNN model shows great potential in extracting and analyzing the singing style features of ethnic opera female characters.Although the current experimental results demonstrate its strong classification capability, future validation with more extensive datasets and diverse musical styles is needed to further enhance its application prospects in the field of music intelligence analysis.
Future works and research limitations
Although the ARGC-BRNN model performs exceptionally well on two datasets, its generalization ability and adaptability to unseen data or different singing styles still need further evaluation.The current experiments are limited to the classification of ethnic opera female character singing styles, and the model’s ability to classify other types of ethnic opera or different music styles has not been fully validated.Future research should expand to a wider range of musical styles and singing styles to assess the model’s performance in different contexts and optimize its generalization ability to unseen data.Additionally, the ARGC-BRNN model has a relatively large number of parameters, which could impact its deployment in resource-constrained practical applications.For example, in mobile devices or low-computational environments, the model’s computational demands may result in reduced processing efficiency, and limit its feasibility for real-time processing and large-scale deployment.Therefore, future studies could explore lightweight model designs, model pruning, and quantization techniques to reduce the computational resource requirements, and enhance its flexibility and deployability in practical applications.Furthermore, to address the model’s computational efficiency and processing speed, algorithms can be further optimized to shorten response time for real-time analysis, meeting the needs for fast and real-time processing.